概要
個人的な備忘録を兼ねたPyTorchの基本的な解説とまとめです。テキスト分類問題の4回目となります。テキストがどのような属性を持っているのか、いわゆるマルチラベル分類の演習をしてみたいと思います。利用するデータは上場企業の有価証券報告書の文章をベースに作成されたchABSAデータセットを利用してみます。
方針
- できるだけ同じコード進行
- できるだけ簡潔(細かい内容は割愛)
- 特徴量などの部分,あえて数値で記入(どのように変わるかがわかりやすい)
演習用のファイル
- データのファイル: MultiLabelDataSample.json
- コード: sample_24.ipynb
1. マルチラベル分類

第22回のTransformerによる文章分類
「りんご、いちご、さくらんぼ」が写っている画像があるとします。この画像は、「りんご」「いちご」「さくらんぼ」の3つのラベルを同時に持っていますが、「バナナ」や「みかん」といった他の果物のラベルは持っていません。このように、マルチラベル分類とは、1つのデータに対して複数のラベル(属性)を同時に付与する問題です。通常の分類問題が「どれか1つのクラスに分類される」のに対し、マルチラベル分類は「どのラベルを持っているか」で判断します。
ポケモンの「リザードン」といえば「ほのお」「ひこう」タイプを持つようなイメージか?なにか違う気がするのですが![]()
テキストデータでは、1つの文章から読み取れる複数の感情(喜び、驚き、不安など)を同時に検出するような応用例が代表的です。
今回は、chABSAデータセットを利用して、テキストデータから「否定的」「中立的」「肯定的」の3種類の感情を検出するタイプのマルチラベル分類を扱ってみたいと思います。
ネットワークの基本構造は記述が短いので第22回で紹介したTransformer Encoderを利用したタイプのみを扱います。マルチラベル分類の損失関数として二値交差エントロピー損失(Binary Cross Entropy Loss)を使うのが最大のポイントとなります。
テキストデータのマルチラベル分類の演習を通じて仕組みを実際に体験できればと思っています。まあマルチラベルといっても事前学習なしで3種類のラベルだしね。
【主要な結果】
- Exact Match: 0.7782
- Hamming: 0.9079
- Macro F1: 0.7270
PyTorchによるプログラムの流れを確認します。基本的に下記の5つの流れとなります。Juypyter Labなどで実際に入力しながら進めるのがオススメ
- データの読み込みとtorchテンソルへの変換 (2.1)
- ネットワークモデルの定義と作成 (2.2)
- 誤差関数と誤差最小化の手法の選択 (2.3)
- 変数更新のループ (2.4)
- 検証 (2.5)
2. コードと解説
2.0 chABSAデータについて
利用するデータchABSA-datasetについて簡単に紹介します。chABSA-datasetとは、TIS株式会社が作成・公開した感情分析用のデータセットです。上場企業の有価証券報告書(2016年度)の文章をベースに、単語を利用した「否定的 (negative)」「肯定的 (positive)」「中立的 (neutral)」の3種類情報が追加された高品位なデータセットです1。GitHubの「chakki-works /chABSA-dataset」ではMITライセンスが付与されています。
マルチラベル分類として利用するために、テキストデータに付与された3種類のラベルの有無を使い、(否定的,中立的,肯定的)というベクトルでラベルを作成しました。具体的には表1のようなデータとなります。
| text | labels |
|---|---|
| わが国経済は、世界経済の緩やかな回復等を背景に... | [0, 0, 1] |
| 営業利益においては、物流部門と食品部門で増益、... | [1, 1, 1] |
表1:マルチラベル化したchABSA
ラベルは「否定的・中立的・肯定的」の順に並んでいます。各属性に対応する内容があれば「1」をない場合は「0」を割り当てています。
ID化・演習用データへ絞り込み
文章についてはMeCabなどで形態素解析を行い、単語IDの辞書を作成します。4種類のタグを準備しました。<unk>は辞書にない単語、<bos>は文の開始記号、<eos> は文の終端記号、<pad>は文の長さを調整する記号をそれぞれ表しています。
<unk> : 0
<bos> : 1
<eos> : 2
<pad> : 3
︙
辞書を利用して、文章をIDベクトルで表現します。IDベクトル化したデータの状況ですが、表2でわかるように、文章の長さにかなりばらつきがあります。恣意的ではあるのですが、演習が目的なので、20単語以上55単語以下の文章のみ採用することにしました![]()
事前学習なしの状態で学習をするので、さすがに数単語のみでの判定は厳しい〜![]()
| 項目 | 数値 |
|---|---|
| count | 6119 |
| mean | 39.8 |
| std | 26.9 |
| min | 1 |
| 25% | 21 |
| 50% | 37 |
| 75% | 54 |
| max | 355 |
表2:系列長に関する統計
20単語以上55単語以下(25%〜75%の範囲)の文章のみ集めるとデータ数は3300個とほぼ半減します。ラベル情報をグラフにすると、表3や図1からもわかるように、かなり不均衡になっています2。
| ラベル | 000 | 001 | 100 | 101 | 010 | 110 | 011 | 111 |
|---|---|---|---|---|---|---|---|---|
| データ数 | 1238 | 954 | 602 | 372 | 55 | 34 | 28 | 17 |
表3:ラベルのデータ数
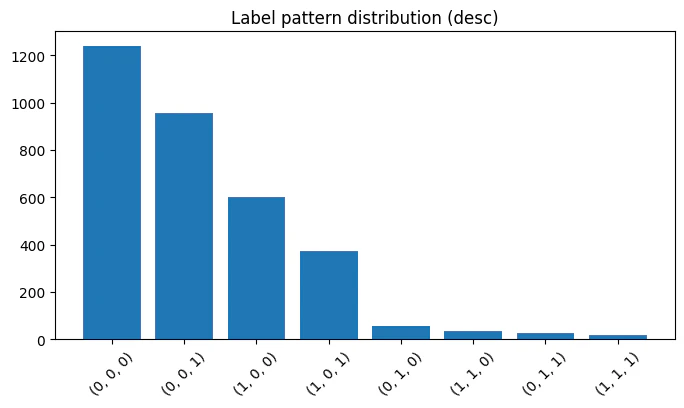
図1:ラベルの頻度
これまでのテキスト分類と同様に、文頭に<bos>、文末に<eos>、文章の長さを整えるのに<pad>トークンを使い、すべてのテキストを等長化します。<pad>トークンIDは「3」に設定しました。実際に使うデータは表4のようになります。
| text | labels | ids |
|---|---|---|
| わが国経済は、世界経済の緩やかな回復等を背景に... | [0, 0, 1] | [1, 4409, 6323, 3117,...,3] |
| 営業利益においては、物流部門と食品部門で増益、... | [1, 1, 1] | [1, 3824, 3469, 1404,...,3] |
表4:実際に利用するデータの例
等長化されたIDベクトルのidsが入力データ、labelsが教師データとなります。
2.1 データの読み込みとtorchテンソルへの変換
まず利用するライブラリを読み込みます。
import json
import numpy as np
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
データの読み込み
特に深い理由はないのですが、今回はCSVではなくて、json形式でデータファイルを準備しました。import jsonを使います。$x$ がIDベクトルになった文、$t$ がラベルで(0,1,1)というラベル毎の判定となります。train_test_splitを利用して、学習に利用するデータとテスト(検証)に利用するデータとに分割します。
# (1) デバイスの選択
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("利用デバイス:", device.type)
# (2) JSONファイルを読み込む
with open("data/MultiLabelDataSample.json", "r") as f:
data = json.load(f)
# (3) リストに変換してからtensorに
# x: IDベクトル
# t: ラベルだけど、BCE損失を使うので、FloatにFloatにしておく。
x = torch.LongTensor([item["ids"] for item in data])
t = torch.FloatTensor([item["labels"] for item in data])
# (4) 各クラスごとのnegative/positiveの比率を求めておく。後で使います。
num_positives = t.sum(dim=0)
num_negatives = len(t) - num_positives
# negative/positiveの比率をpos_weightに
pos_weight = torch.FloatTensor(num_negatives / num_positives)
# (5) 学習データと検証データに分割
x, x_test, t, t_test = train_test_split(x,t, stratify=t, random_state=55)
x = x.to(device)
t = t.to(device)
x_test = x_test.to(device)
t_test = t_test.to(device)
pos_weight = pos_weight.to(device)
# pos_weight tensor([ 2.2195, 23.6269, 1.4070], device='cuda:0')
# x.shape torch.Size([2475, 58]),
# x_test.shape torch.Size([825, 58]))
説明メモ
- (1) 利用するデバイスの設定。GPUあるときは使うぞ。
- (2) with openでファイルを開いて、json.load()でその内容を読み込んで辞書型やリスト型でアクセスできる形に変換します。
- (3) 入力データは整数なので、torch.LongTensor()を使います。教師データである、ラベルも整数としたいところですが、今回は、BCE損失を使うので、FloatTensor() を使います。
- (4) 各クラスごとに「1」の数である num_positives と「0」の数である num_negativesの比率をpos_weightとしておきます。この重みを利用して不均衡なデータに無駄な抵抗をしてみます。厳密に比率にこだわる必要はなさそうで、(2.0, 30.0, 1.5)と大雑把に決めても良さそうです3。
- (5) train_test_splitで学習用データと検証用データに分割します。
2.2 ネットワークモデルの定義と作成
今回は図2のように埋め込み層などから抽出された特徴量をTransformer Encoder層で関連度を考慮した特徴量に変換、特徴量の平均を求めて、全結合層により3種類のラベルそれぞれに属するかどうかの判定を行います。それぞれのラベルに対してロジスティック回帰(2値分類)を行う形になります4。第22回のTransformerによる文章分類のように、<bos>に情報を集約してから分類する方法でも良さそうです。
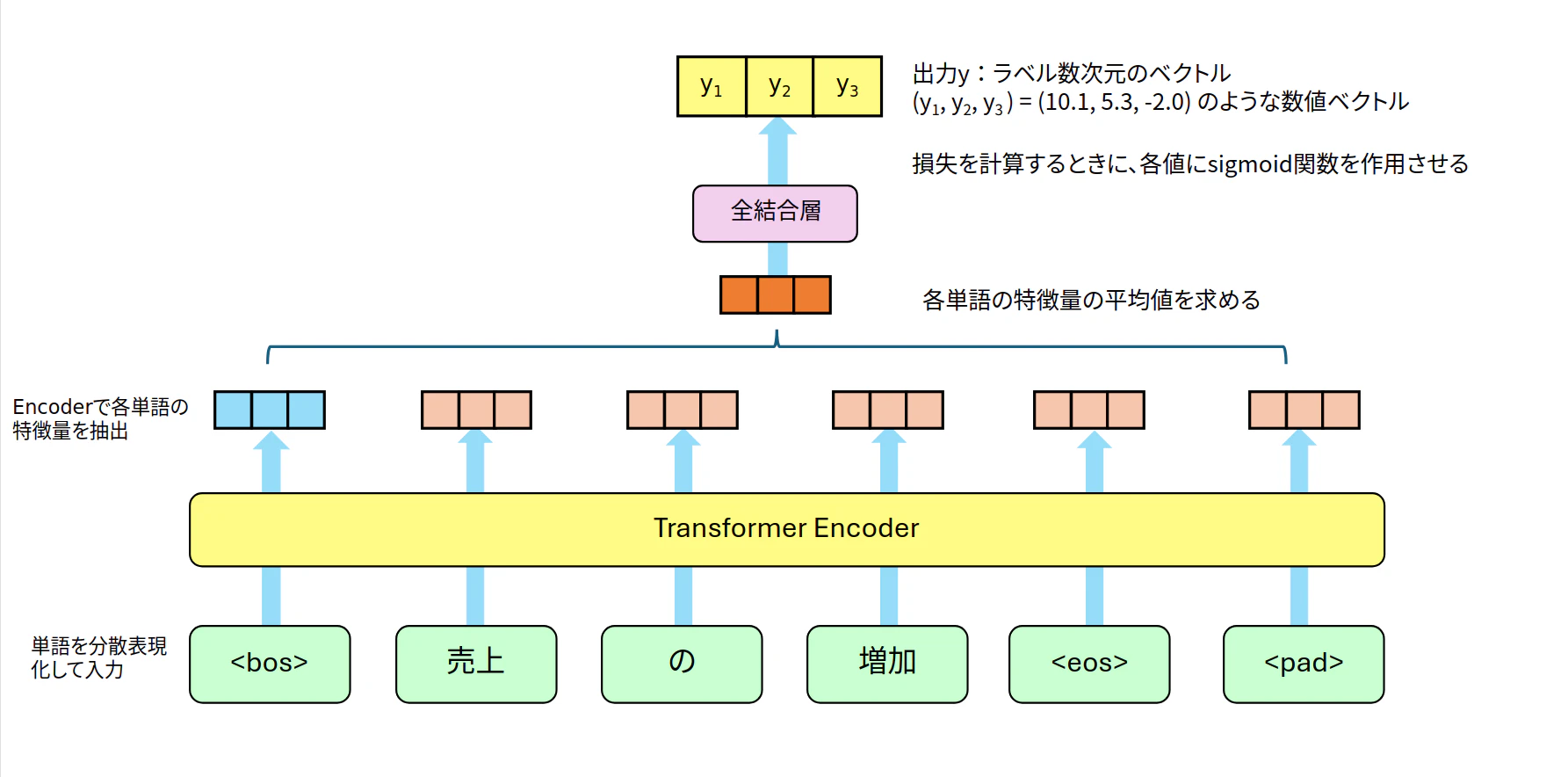
図2:ネットワークの概要
ネットワークの書き方はこれまで同様にクラスを利用して記述します。
(1) __init__() : 利用するネットワーク名・活性化関数をすべて記述
(2) forward() : 実際の流れを記す
ネットワーク構造の概要は
(x:単語IDベクトル)→【埋め込み層】→【Transformer】→【全結合層】→(y:3種類)
という3ブロックから構成されます。複雑なTransformerもPyTorchのTransformerEncoderLayerを使えば数行で表現できます![]()
# 初期設定(方針の3番目がだんだん一般化)
WORDS = 6950 # 単語数 len(word2id)
SEQ_LEN = 58 # x.shape[1] # 入力するIDベクトルの長さ
D_MODEL = 64 # 分散表現の次元
N_HEAD = 8 # マルチヘッドのヘッド数
DIM_FEEDFORWARD = 256 # TransformerEncoder層の中間層の特徴量の次元
CLASSES = 3 # t.shape[1] ラベルの数
class DNN(nn.Module):
def __init__(
self,
pad_token_id: int=3, # <pad>idの指定:デフォルト値0ではなくわざと変更してあるよ
):
super().__init__()
self.pad_token_id = pad_token_id
# (1) トークン埋め込み
self.token_embedding = nn.Embedding(num_embeddings=WORDS, embedding_dim=D_MODEL,padding_idx=self.pad_token_id)
# (2) 学習可能な位置埋め込み(0〜max_len-1)
self.pos_embedding = nn.Embedding(num_embeddings=SEQ_LEN, embedding_dim=D_MODEL)
# (3) Layer Normalization と Dropout
self.layer_norm = nn.LayerNorm(D_MODEL)
self.dropout = nn.Dropout(0.1)
# (4) Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(
d_model=D_MODEL,
nhead=N_HEAD,
dim_feedforward=DIM_FEEDFORWARD,
dropout=0.1,
batch_first=True, # [batch, seq, d_model] で扱えるように
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer,num_layers=6)
# (5) 文ベクトル → クラス数
self.classifier = nn.Linear(in_features=D_MODEL, out_features=CLASSES)
def forward(self, x):
# (6) マスクの変換 TransformerEncoder 用: PAD ID=3でPAD のところが True になる mask
src_key_padding_mask = (x == self.pad_token_id)
# (7) 埋め込み
# トークン埋め込み
tok_emb = self.token_embedding(x) # [batch, seq_len=58, d_model=64]
# 位置埋め込み(broadcastingで自動拡張)
pos_emb = self.pos_embedding(torch.arange(SEQ_LEN, device=x.device)) # [seq_len=58, d_model=64]
# トークン埋め込み + 位置埋め込み
x = tok_emb + pos_emb.unsqueeze(0) # [batch, seq_len=58, d_model=64]
# (8) Layer Normalization と Dropout
x = self.layer_norm(x)
x = self.dropout(x)
# (9) Transformer Encoder
h = self.transformer_encoder(x, src_key_padding_mask=src_key_padding_mask)
# (10) 文ベクトルへの Pooling (PADを除外した平均)
mask = (~src_key_padding_mask).unsqueeze(-1).float() # [batch, seq_len, 1]
pooled = (h * mask).sum(dim=1) / mask.sum(dim=1).clamp(min=1) # [batch, d_model]
# (11) 文ベクトルへの Pooling <BOS>トークン(先頭)に情報を集約
#pooled = h[:, 0, :] # [batch, d_model]
# (12) 分類
y = self.classifier(pooled) # [batch, num_labels=3]
return y
model = DNN()
model.to(device)
<bos>に情報を集約させる部分を除けば、第22回のTransformerによる文章分類と同じ構造になっています。詳細な説明は第22回も参照してください![]()
グローバルな変数を利用してみました。数値設定の部分をまとめておけば、数値を変更するだけで、ネットワークの細かな数値を変更することが容易になりそうです。
WORDS = 6950 # 単語数 len(word2id)
SEQ_LEN = 58 # x.shape[1] # 入力するIDベクトルの長さ
D_MODEL = 64 # 分散表現の次元
N_HEAD = 8 # マルチヘッドのヘッド数
DIM_FEEDFORWARD = 256 # TransformerEncoder層の中間層の特徴量の次元
CLASSES = 3 # t.shape[1] ラベルの数
説明メモ1 (__init__の部分)
- (1) トークンの埋め込み:単語を分散表現ベクトルへ変換します。
- (2) 位置の埋め込み:単語の出現位置の番号を分散表現ベクトルへ変換します。
- トークンの埋め込みベクトルと位置の埋め込みベクトルを足し算して、位置情報を考慮した単語の分散表現とします。
- (3) レイヤー正規化とドロップアウトを利用してモデルの安定度を高めてみた。
- (4) PyTorchのTransformerEncoderLayerとTransformerEncoderを利用してエンコーダー用のTransformerネットワークを作成します。ヘッド数(n_head)や途中で利用される特徴量の次元(dim_feedforward)、Transformerの繰り返し回数(num_layers)を適当に指定します。
- (5) マルチラベル分類問題なので最後に分類するための全結合層を付け加えます。出力がラベル数の3であることとなっています。
説明メモ2 (forwardの部分)
- (6) TransformerEncoderを使うとき、<pad>の部分を利用しないようにマスクをつけます。マスクの作成方法はいくつか考えられると思います。入力されたIDベクトルのIDがpad_token_idならマスクする(maskがTrue)という形で書いてみました。
- (7) 単語の分散表現と単語の位置の分散表現を足し算します。
- (8) 正規化とドロップアウト
- (9) padのマスクと位置情報を考慮した分散表現行列がTransformerの入力に利用されます。
- (10) ここがポイント!文章分類では<bos>の特徴量のみ利用しましたが、今回はすべての単語の特徴量を平均してFCへ入力する方法にしてみました。もちろん、<bos>に特徴量を集約させることも可能です。<bos>集約タイプは(11)を使います。このあたりは精度を見て判断するのが良さそうです

- (12) 出力された3次元ベクトルの値を利用して、それぞれのラベルに所属するか否かの2値判定となります。
2.3 誤差関数と誤差最小化の手法の選択
分類問題なのでおなじみのCrossEntropyLoss()ではありません。ロジスティック回帰で登場する BCEWithLogitsLoss() という二値交差エントロピー損失を使い演習に取り組んでみます。

図3:二値交差エントロピー
$y_k\in\mathbb{R}$をラベル$k$の予測値、$t_k\in \{ 0, 1 \}$をラベル$k$の所属判定教師データとします。ラベル$k$のBCEWithLogitsLossは
l_k = \text{loss}(y_k,t_k) = -\Bigl[ t_k \log \sigma(y_k) + (1-t_k) \log(1- \sigma(y_k)) \Bigr]
と計算されます。σはシグモイド関数だよ![]()
マルチラベルなので、ラベル$k$での損失$l_k$について、その平均値 ($\text{mean}\{ l_1,...,l_n\}$) や合計値 ($\sum l_k$) を使って全体の損失とします。詳細は公式のドキュメントを参考にしてください。
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005)
pos_weightsで頻度の低い所属判定の「1」を拾いにいくように損失に重み付けをします。$p_k$をあるラベルのpos_weight=negative/positiveとします。重み$p_k$を使って、
−\Bigl[p_k \cdot t_k\log \sigma(y_k)+(1−t_k)\log(1−\sigma(y_k))\Bigr]
と計算するのが、pos_weights付きのBCEWithLogitsLossとなります。$p_k$の値を大きさだけ、ラベル$k$で「1」の時の損失値を大きく評価することになります。
2.4 変数更新のループ
LOOPで指定した回数、
- y=model(x) で予測値を求め、
- criterion(y, t) で指定した誤差関数を使い予測値と教師データの誤差を計算、
- 誤差が小さくなるようにoptimizerに従い変数をアップデートします。
LOOP = 300
for epoch in range(LOOP):
optimizer.zero_grad()
y = model(x)
loss = criterion(y, t)
acc = accuracy(y,t)
loss.backward()
optimizer.step()
print(f"{epoch+1}:\tloss:{loss.item():.3f}\tacc:{acc:.3f}")
精度について
予測値と教師データで等しい値なら正解として、正解数/問題数で精度を求める単純な精度を使います。ただし、教師データが (0,1,1)のようなベクトルの形なので、3つすべて同じ値になる時のみ、正解とします。まさに完全一致ですね5。
# 出力されたyの値を0.5で分割
# 0.5以上なら1と判定
# 0.5未満なら0と判定
def label_prediction(y, threshold=0.5):
probs = torch.sigmoid(y)
predictions = (probs >= threshold).float()
return predictions
# 精度の計算
def accuracy(y,t, threshold=0.5):
prediction = label_prediction(y, threshold=threshold)
num_correct = (prediction == t).all(-1).sum().item()
accuracy = num_correct/t.shape[0]
return accuracy
- label_prediction関数の predictions = (probs >= threshold).float() で出力値$y$の値から「0, 1」の判定をします。
\text{prediction} = \left\{
\begin{array}{ll}
1 & \text{if}~~y \geq 0.5 \\
0 & \text{otherwise}
\end{array}
\right.
- accuracy関数の
(prediction == t).all(-1).sum()でpredictionとtがすべて一致している状況のみを数え上げています。いままでのaccuracy関数からの変更点となります。
2.5 検証と精度について
2.1のデータ分割で作成したテストデータ x_test と t_test を利用して学習結果をテストしてみましょう。x_testをmodelに入れた値 y_test = model(x_test) が予測値となります。accuracyで精度を求めれば完成です。
model.eval()
with torch.inference_mode():
y_test = model(x_test)
acc = accuracy(y_test, t_test)
print(f"検証精度: {acc}")
# 検証精度: 0.7782
上記で計算した検証精度は、すべてのラベルが等しい時のみ扱うという非常に厳しい評価と考えられます。3ラベル中2個あたっていても、間違え判定となるからです。検証精度について少しだけ広げてみたいと思います。
今回のラベルを確認すると、表のようになります。ラベル(0,0,0)と(0,0,1)を正確に予測するだけで、およそ66%以上を正確に的中させることになります。この感じで学習が進むと(0,1,1)や(1,1,1)という稀な(もしかして非常に重要な)状況をうまく予測することができなくなってしまいます。他の方面からも指標を見てみたいと思います5。
| ラベル | 000 | 001 | 100 | 101 | 010 | 110 | 011 | 111 | 合計 |
|---|---|---|---|---|---|---|---|---|---|
| データ数 | 1238 | 954 | 602 | 372 | 55 | 34 | 28 | 17 | 3300 |
表5:ラベルとデータ数
演習の結果例
検証結果の数値例には多少の誤差があります。Exact MatchやマクロF1はだいたい0.7台が多いかな。いろんな数値を変更すると指標の数値もかなり上下します。
全体での指標
| 指標 | 値 |
|---|---|
| Exact Match | 0.7782 |
| Hamming | 0.9079 |
| Macro F1 | 0.7270 |
ラベル3個を通してだと、無難な精度になっていると思えるのですが![]()
ラベル毎で検証した精度のHammingが90%くらいだから、3個のラベル全部が正解のExact Matchの確率は$(0.9)^3 \fallingdotseq0.73$くらいのはず。
ラベル毎の評価
| 指標 | ラベル0 | ラベル1 | ラベル2 |
|---|---|---|---|
| f1 per label | 0.8291 | 0.5075 | 0.8444 |
| precision per label | 0.8307 | 0.5000 | 0.8348 |
| recall per label | 0.8275 | 0.5152 | 0.8542 |
ラベル毎で評価すると、やはり、ラベル1が難しい〜。中立的な要素を当てるのが難しいっぽい。ラベル1の正例が極端に少ないのが最大の影響のように感じます。pos_weightでラベル1の重みを大きくする、もしくは、判定しきい値の0.5を変更するなどの手段を使って、ラベル1の数値を改善することも可能です。いろいろ試すのも醍醐味の一つ![]()
次回
もう少し気合の入ったマルチラベルか、単語を数値に変換するトークナイズの部分を掘り下げて勉強したいなぁ〜
目次ページ
注
-
具体的なデータの取得や前処理・加工方法はについては、【自然言語処理】【感情分析】chABSA-datasetを扱いやすいように整形するや自然言語処理の日本語用データセット【chABSA-dataset】あたりが参考になると思います
 ↩
↩ -
すべての属性が存在しない(0,0,0)ラベルとそれ以外の2値判定を行い、それ以外の場合は、[(001)〜(111)]の7種類でマルチラベル判定を行うほうが精度面では優れているように思います。 ↩
-
マルチラベルの損失関数に関する研究も進んでいるようです。Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, Dahua Lin (2020)"Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets"というのを発見しました。DBLossという損失関数なのですが
 ↩
↩ -
「25回くらい進んでもまだ初回の頃と同じ回帰分析😱😱😱」問題の捉え方が違うだけで、実は何も進歩がなかったのでは😱😱😱 ↩
-
その他の基本的な指標については、多クラス分類における F値: macro-F1 & micro-F1や二値、多値、多ラベル分類タスクの評価指標などを参考にしてください。 ↩ ↩2