前回記事「ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編)」の続きです。この記事は第2部です。
作るものは「ザッカーバーグの顔を識別するAI」です。GoogleのディープラーニングライブラリのTensorFlowを使います。今回作ったもののサンプル動画等はこちら。
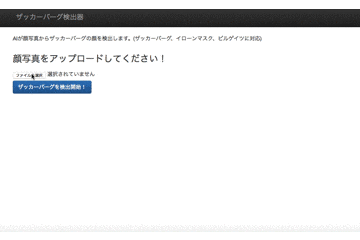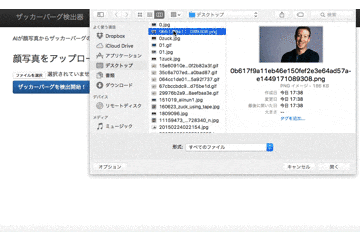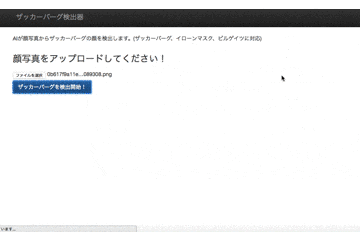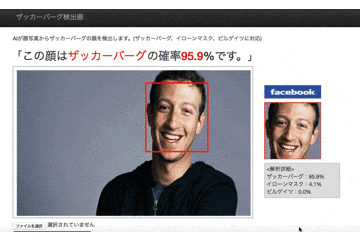
前回の記事でTensorFlowに学習させる顔画像データが集まったので、今回はTensorFlowのAIモデルを構築していきます!
TensorFlow部分の作業はざっくり
「①TensorFlowの学習モデルの設計→②顔データたちを学習させて訓練する→③学習結果を使って任意の画像の顔を判定できるようにする」
という流れで進めていきます。今回は**「TensorFlowの学習モデルの設計(ニュラールネットワークの設計)」**の手順について記載にしていきます。
それでは前回は学習用の顔画像データを集めたので、学習モデル設計は以下!
②TensorFlowの学習モデルを設計する
1.TensorFlowを使う前に
実際にTensorFlowでディープラーニングするのに前提知識がないとほぼ以下が意味不明だと思うので、初心者の僕が学習した際に特に参考になり、強く記憶に残っているものを紹介します。
【ディープラーニング関連】
①ニューラルネットワークと深層学習
裏側で起きていることなどを数式レベルで詳細に解説してくれていて非常に勉強になりました。「なんとなくディープラーニングについてわかったけどよくわからん」くらいになった後に読むといい思います。ただ、詳細すぎて筆者は10%くらいしか理解していません。
②人工知能は人間を超えるか(書籍)
日本で「ディープラーニングと言えばこの人!」みたいになっている(??)東大の松尾さんの書籍。2年ほど前に読んでKindleに入っていたのでもう一度読みました。難しい言葉や数式を一切使わないで誰でもわかるように「ディープラーニングとは何か?」というのを解説しており、大変わかりやすいです。一番わかりやすいかも。
【TensorFlow関連】
③すぎゃーんメモ
TensorFlowを使った様々事例などを書いてくださっていてメモレベルを超えています。
(こちらのメモを見すぎていたら本人のインタビュー記事がFacebookを開く時に毎回広告としてリコメンドされるようになりましたw)
④TensorFlowチュートリアル和訳
TensorFlow公式のチュートリアルを和訳してくれています。初級と上級どちらも和訳してくださっているので有り難かったです。
⑤特にプログラマーでもデータサイエンティストでもないけど、Tensorflowを1ヶ月触ったので超分かりやすく解説
⑥Tensorflowを2ヶ月触ったので"手書きひらがな"の識別95.04%で畳み込みニューラルネットワークをわかりやすく解説
上記2つはTensorFlowのチュートリアルを解説してくださっていて学習の際大変助かりました!
⑦TensorFlowによるももクロメンバー顔認識
⑧TensorFlowでアニメゆるゆりの制作会社を識別する
今回、コードレベルで上記の2つを参考にさせていだきました。こちらの記事がなかったら動作するものは作れなかったです。深く感謝ですm(_ _)m
こうして見ると意外と日本でもTensorFlow触っている人はいるなー。という印象でした。参考にさせていただいた方々ありがとうございましたm(_ _)m
2.TensorFlowの学習モデルを設計する
さぁ、いよいよTensorFlowの処理を書いていきます。TensorFlowの**「学習モデルの設計」はディープラーニングする上において最も重要と思われる作業部分です。多分、この「学習モデル(ニューラルネットワーク)の設計こそディープラーニングである」**と言っても過言ではないのでしょうか。
ここに突入する前に、TensorFlowチュートリアルなどをやってみて、最低限TensowFlowがインストールされていて、正常に動作すること確認してから実施してください。(応用編のCNNのチュートリアルもやってみると尚よしです)
TensorFlowセットアップやチュートリアルなどはここでは省略します。
参考:TensorFlow MNIST For ML Beginners チュートリアルの実施
今回のTensorFlowの学習モデル(ニューラルネットワーク)の構造はTensorFlowチュートリアルのエキスパート編で解説されている**畳み込みニューラルネットワーク(CNN)**にしていきます。隠れ層の1層の構造で進めるので、チュートリアルと全く同じ構造になっているかと思います。
ディレクトリ構造は公式に沿ってtensorflowをインストールしてできた、tensorflowというフォルダに顔画像データフォルダとtensorflow関連の処理ファイルを突っ込みました。
(今回、学習モデル設計と学習実施関連の処理はmain.pyというファイルにまとめました。下記のコードはmain.pyの一部分です。)
/tensoflow
main.py(ここに学習モデルと学習の処理を書いていく)
eval.py(任意の画像の判例結果を返すファイル)
/data(前回記事で集めた顔データ)
/train
/zuckerbuerg
/elonmusk
/billgates
data.txt
/test
/zuckerbuerg
/elonmusk
/billgates
data.txt
後はtensorflowをインストールした時にできたフォルダとかファイルがtensorflowフォルダ内にある
(コードの中で頑張ってコメントを残しておきましたが、完璧に理解できているわけではなく、語弊がある点などはご指摘いただけると幸いですm(_ _)m
とにかくTensorFlowで用意されている関数が細かい計算などは全部やってくれてすげーという印象でした。)
# AIの学習モデル部分(ニューラルネットワーク)を作成する
# images_placeholder: 画像のplaceholder, keep_prob: dropout率のplace_holderが引数になり
# 入力画像に対して、各ラベルの確率を出力して返す
def inference(images_placeholder, keep_prob):
# 重みを標準偏差0.1の正規分布で初期化する
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# バイアスを標準偏差0.1の正規分布で初期化する
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 畳み込み層を作成する
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# プーリング層を作成する
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# ベクトル形式で入力されてきた画像データを28px*28pxの画像に戻す(多分)。
# 今回はカラー画像なので3(モノクロだと1)
x_image = tf.reshape(images_placeholder, [-1, IMAGE_SIZE, IMAGE_SIZE, 3])
# 畳み込み層第1レイヤーを作成
with tf.name_scope('conv1') as scope:
# 引数は[width, height, input, filters]。
# 5px*5pxの範囲で画像をフィルターしている
# inputが3なのは今回はカラー画像だから(多分)
# 32個の特徴を検出する
W_conv1 = weight_variable([5, 5, 3, 32])
# バイアスの数値を代入
b_conv1 = bias_variable([32])
# 特徴として検出した有用そうな部分は残し、特徴として使えなさそうな部分は
# 0として、特徴として扱わないようにしているという理解(Relu関数)
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# プーリング層1の作成
# 2*2の大きさの枠を作り、その枠内の特徴を1*1の大きさにいい感じ変換する(特徴を圧縮させている)。
# その枠を2*2ずつスライドさせて画像全体に対して圧縮作業を適用するという理解
# ざっくり理解で細分化された特徴たちをもうちょっといい感じに大まかにまとめる(圧縮する)
with tf.name_scope('pool1') as scope:
h_pool1 = max_pool_2x2(h_conv1)
# 畳み込み層第2レイヤーの作成
with tf.name_scope('conv2') as scope:
# 第一レイヤーでの出力を第2レイヤー入力にしてもう一度フィルタリング実施
# 5px*5pxの範囲で画像(?)をフィルターしている
# inputが32なのは第一レイヤーの32個の特徴の出力を入力するから
# 64個の特徴を検出する
W_conv2 = weight_variable([5, 5, 32, 64])
# バイアスの数値を代入(第一レイヤーと同じ)
b_conv2 = bias_variable([64])
# 検出した特徴の整理(第一レイヤーと同じ)
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# プーリング層2の作成(ブーリング層1と同じ)
with tf.name_scope('pool2') as scope:
h_pool2 = max_pool_2x2(h_conv2)
# 全結合層1の作成
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# 画像の解析を結果をベクトルへ変換
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
# 第一、第二と同じく、検出した特徴を活性化させている
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropoutの設定
# 訓練用データだけに最適化してしまい、実際にあまり使えないような
# AIになってしまう「過学習」を防止の役割を果たすらしい
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 全結合層2の作成(読み出しレイヤー)
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
# ソフトマックス関数による正規化
# ここまでのニューラルネットワークの出力を各ラベルの確率へ変換する
with tf.name_scope('softmax') as scope:
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 各ラベルの確率(のようなもの?)を返す。算出された各ラベルの確率を全て足すと1になる
return y_conv
学習モデルの設計はこれだけですが、やってることは
①特徴化したいものを入力として、一番上の(次への)層に伝える→②その層の学習モデルに沿って色々学習して特徴を検出して出力する→③1つ前の層の出力(特徴)を次の層への入力として伝え①〜③を層の数だけ繰り返す→④最後に一番最初に入力されたものが用意されたラベルにどれくらいマッチしているのかの確率を返す
みたいな感じなのかなと認識しています。
TensorFlowではデータをテンソル形式(行列のようなデータ)にして、各階層へどんどんデータが流れていくので、「TensorFlow」なんですね。そしれ、この階層が深くなるたびにどんどん特徴を学習していくので、**「Deep Learning」**なんですね。なるほど!わかりやすい命名。w
3.設計した学習モデル(ニューラルネットワーク)を可視化してみる
TensorFlowに付属しているTensorBoardという機能で、この設計したニューラルネットワーク構造で視覚的に見ることができます。
tensorboard --logdir=./dataでTensorBoardで起動。ブラウザでlocalhost:6006へアクセス!
./dataは学習データが置いてあるディレクトリを指定してください。僕はdataというディレクトリに画像を置いていました。
このTensorBoardはTensorFlowの特徴的な機能の1つなそうで、確かに色々な結果を簡単に見れて凄いです。TensorBoardについてはググると色々出てきます。実際にデータを学習させるまでグラフは見れないかも(?)
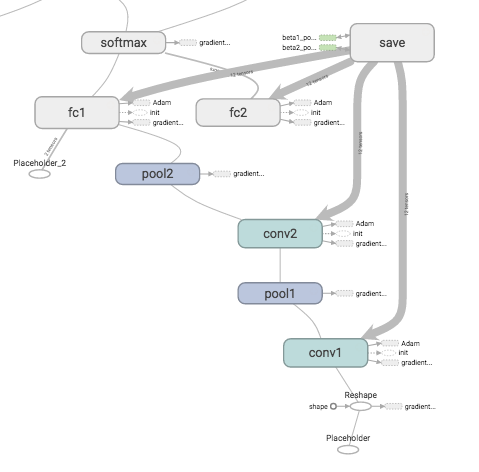
ふむふむふむ。確かに
imageplaceholderとして入力された画像をReshapeして→第1レイヤー(conv1)に入力して→第1プーリング(pool1)して→第2レイヤー(conv2)に渡して→……
と、確かに設計した学習モデルのニューラルネットワーク構造通りになっているようです。凄い。わかりやすい。
各層の名称(conv1とか)は先ほどの学習モデルのコードのwith tf.name_scope('conv1') as scope:の部分で名前を命名しています。TensorBorad自体の設定は後程のコードで出てくるsummary_writer = tf.train.SummaryWriter(FLAGS.train_dir, sess.graph_def)の部分でやってくれているようです。
今回の学習モデルの隠れ層は1層ですが、世界最強のAI囲碁ソフト「AlphaGo」はこのニューラルネットワーク構造を見てみるととんでもなく複雑になっているとか。(どこかの記事に載っていた気がする。)
③学習モデルに実際にデータを学習させる
ここまでで、TensorFlowを使う上で、最も大事であると思われる学習モデルの設計が終わりました。(とは言っても、今回チュートリアルと同じですが。)
次は実際にこの設計した学習モデルに、先ほど集めた大量の顔データたちを学習してもらいます。続きはまた長くなりそうなので、下記事より↓
続きの第3部はこちら:ディープラーニングでザッカーバーグの顔を識別するAIを作る③(データ学習編)
「ディープラーニングでザッカーバーグの顔を識別するAIを作る」<記事全編>
第1部:ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編)
第2部:ディープラーニングでザッカーバーグの顔を識別するAIを作る②(AIモデル構築編)
第3部:ディープラーニングでザッカーバーグの顔を識別するAIを作る③(データ学習編)
第4部:ディープラーニングでザッカーバーグの顔を識別するAIを作る④(WEB構築編)
GitHub:https://github.com/AkiyoshiOkano/zuckerberg-detect-ai
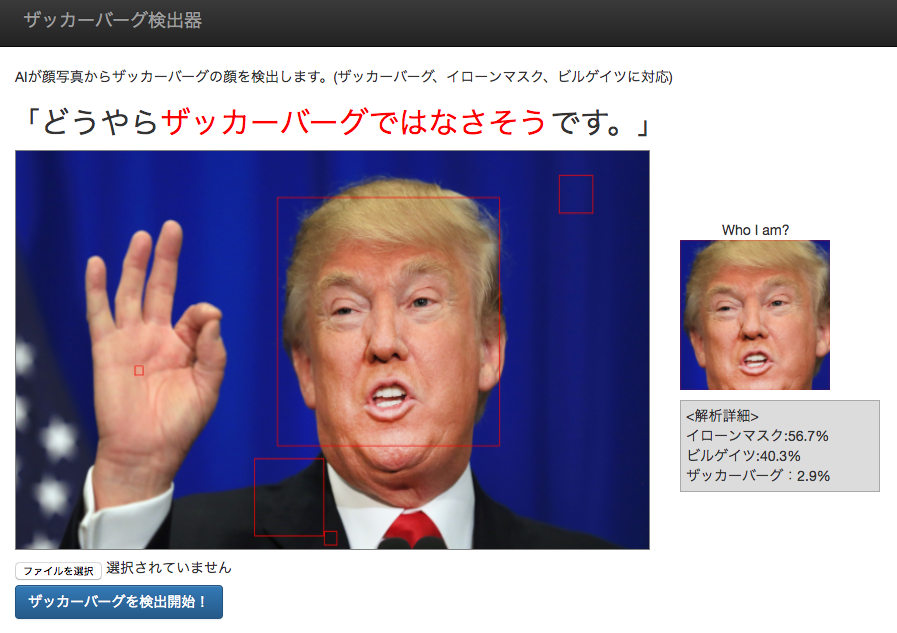
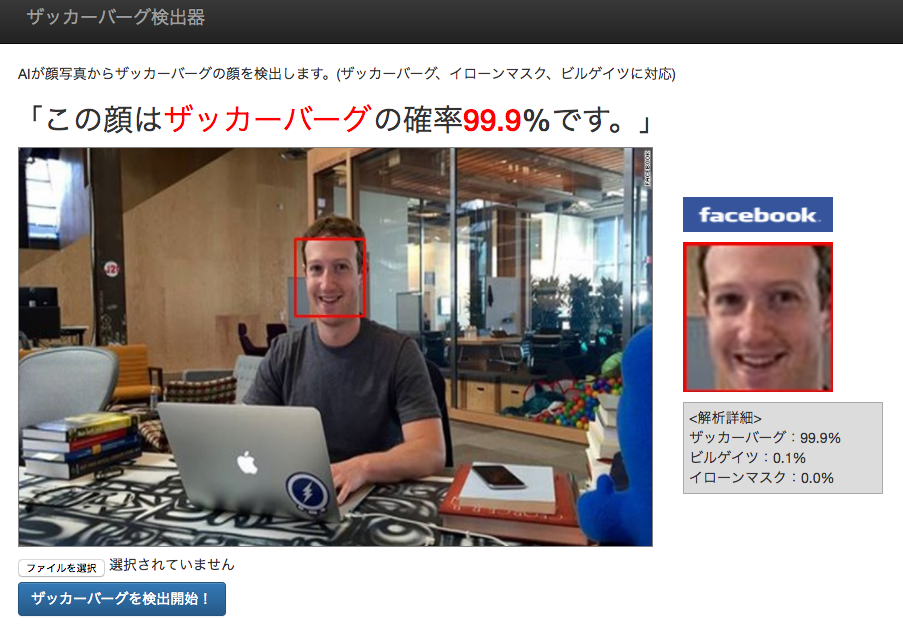
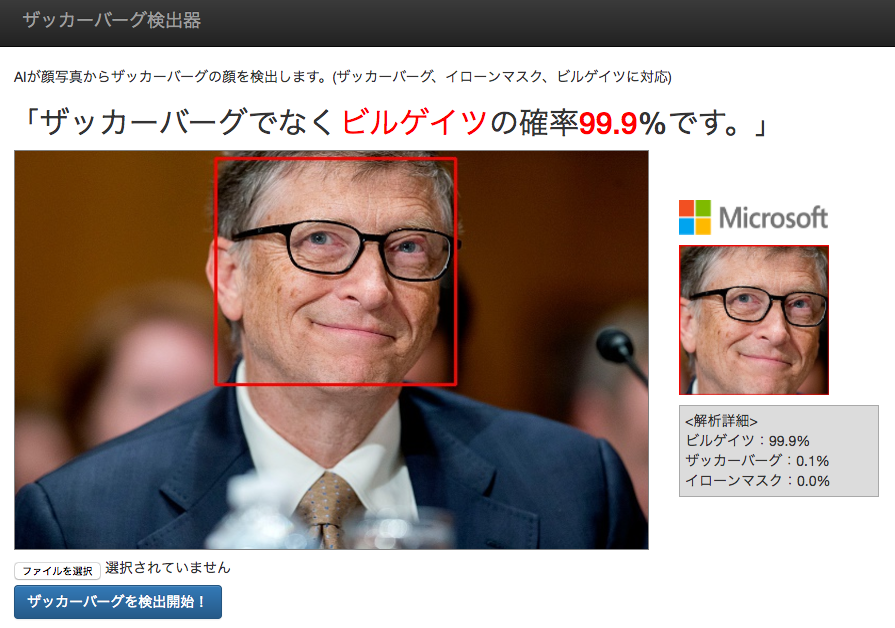
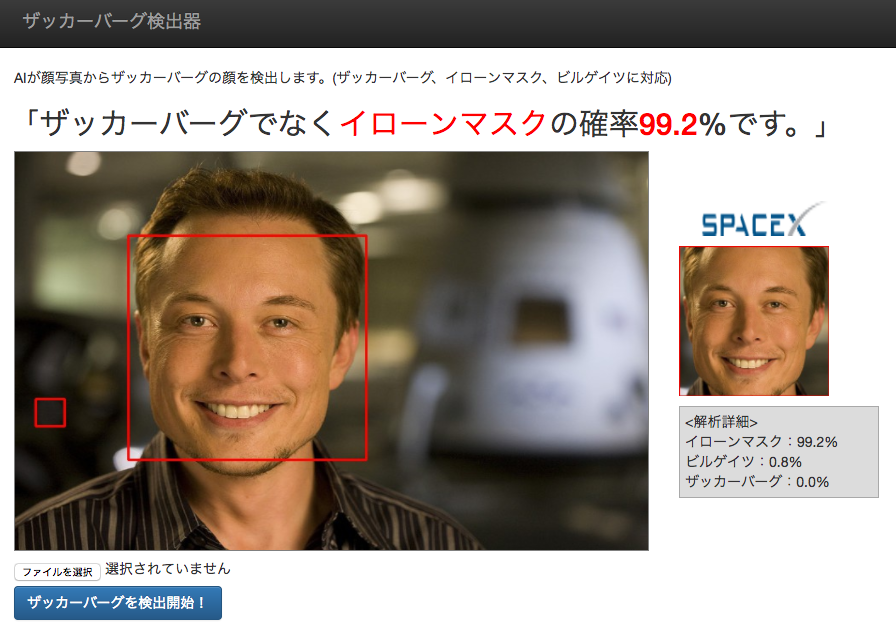
おまけ判定結果
できたザッカーバーグ検出器で遊んだ判定結果
開発の流れで判定できるようになったビルゲイツ氏
同じくイローンマスク氏
トランプ大統領を判定