第1部:ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編)
第2部:ディープラーニングでザッカーバーグの顔を識別するAIを作る②(AIモデル構築編)
の続きで、この記事は第3部です。作るものは「ザッカーバーグの顔を識別するAI」です。GoogleのディープラーニングライブラリのTensorFlowを使います。今回作ったもののサンプル動画等はこちら。
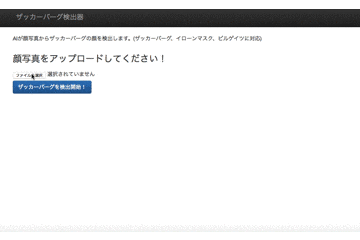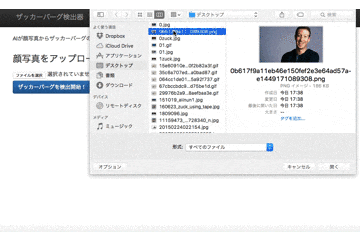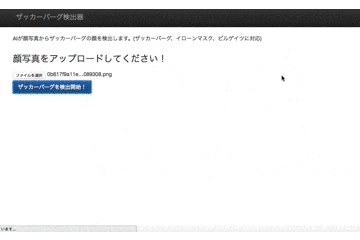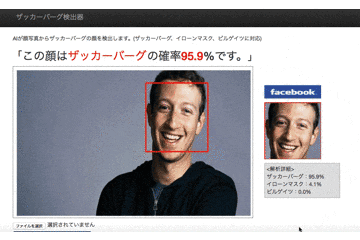
前回に引き続きTensorFlowでの処理を書いていきます。TensorFlow部分の作業は、**「①TensorFlowの学習モデルの設計(done!)→②顔データたちを学習させて訓練する→③学習結果を使って任意の画像の顔を判定できるようにする」**という大体の流れです。
第2部で**「①TensorFlowの学習モデル(ニューラルネットワーク)の設計」が完了したので、今回はその学習モデルに第1部で集めた大量のザッカーバーグとビルゲイツとイーロンマスク3人の顔データたちを元に、実際に「顔画像データたちを学習させる」**ということをやります。
いよいよTensorFlowを用いたディープラーニングも大詰めという感じ。
(ディープラーニングやTensorFlowの前提に最低限必要そうな文献や参考にさせて頂いた記事などは第2部にまとめたので、そちらを参考にして頂ければと思います。)
それでは、実際にAIにデータを学習させていきましょう!楽しみ!
③集めた顔画像データたちを学習させる
1.TensorFlowのデータ訓練部分の処理を書く
学習用データを実際に学習させるTensorFlowの部分の処理を作っていきます。前回の記事に書きましたが、今回のプロジェクトのディレクトリ構造はこんな感じです。
/tensoflow
main.py(ここに学習モデルと学習の処理を書いていく)
eval.py(任意の画像の判例結果を返すファイル)
/data(前回記事で集めた顔データ)
/train
/zuckerbuerg
/elonmusk
/billgates
data.txt
/test
/zuckerbuerg
/elonmusk
/billgates
data.txt
後はtensorflowをインストールした時にできたフォルダとかファイルがtensorflowフォルダ内にある
前回使ったmain.pyファイルに学習部分の処理を追加していきます。
(前回作った学習モデルの構築部分のコードはこのmain.pyファイルに含まれますが、重複する&長くなるので、前回部分のコードは下には記載を省きましたが、実際に動かす時はこのファイルに前回の学習モデル部分のコードも挿入してください。別ファイルに分けてimportするとかもいいかも。)
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import cv2
import random
import numpy as np
import tensorflow as tf
import tensorflow.python.platform
# 識別ラベルの数(今回は3つ)
NUM_CLASSES = 3
# 学習する時の画像のサイズ(px)
IMAGE_SIZE = 28
# 画像の次元数(28px*28px*3(カラー))
IMAGE_PIXELS = IMAGE_SIZE*IMAGE_SIZE*3
# Flagはデフォルト値やヘルプ画面の説明文を定数っぽく登録できるTensorFlow組み込み関数
flags = tf.app.flags
FLAGS = flags.FLAGS
# 学習用データ
flags.DEFINE_string('train', './data/train/data.txt', 'File name of train data')
# 検証用データ
flags.DEFINE_string('test', './data/test/data.txt', 'File name of train data')
# TensorBoardのデータ保存先フォルダ
flags.DEFINE_string('train_dir', './data', 'Directory to put the training data.')
# 学習訓練の試行回数
flags.DEFINE_integer('max_steps', 100, 'Number of steps to run trainer.')
# 1回の学習で何枚の画像を使うか
flags.DEFINE_integer('batch_size', 20, 'Batch size Must divide evenly into the dataset sizes.')
# 学習率、小さすぎると学習が進まないし、大きすぎても誤差が収束しなかったり発散したりしてダメとか。繊細
flags.DEFINE_float('learning_rate', 1e-4, 'Initial learning rate.')
# ------------------------------------------------
##################################################
# ここの間に前回書いたmain.pyの学習モデル構築のコードが入る。 #
# ここだけ別ファイルにして、importして読み込むとかもいいかも。 #
##################################################
# ------------------------------------------------
# 予測結果と正解にどれくらい「誤差」があったかを算出する
# logitsは計算結果: float - [batch_size, NUM_CLASSES]
# labelsは正解ラベル: int32 - [batch_size, NUM_CLASSES]
def loss(logits, labels):
# 交差エントロピーの計算
cross_entropy = -tf.reduce_sum(labels*tf.log(logits))
# TensorBoardで表示するよう指定
tf.scalar_summary("cross_entropy", cross_entropy)
# 誤差の率の値(cross_entropy)を返す
return cross_entropy
# 誤差(loss)を元に誤差逆伝播を用いて設計した学習モデルを訓練する
# 裏側何が起きているのかよくわかってないが、学習モデルの各層の重み(w)などを
# 誤差を元に最適化してパラメーターを調整しているという理解(?)
# (誤差逆伝播は「人工知能は人間を超えるか」書籍の説明が神)
def training(loss, learning_rate):
#この関数がその当たりの全てをやってくれる様
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
return train_step
# inferenceで学習モデルが出した予測結果の正解率を算出する
def accuracy(logits, labels):
# 予測ラベルと正解ラベルが等しいか比べる。同じ値であればTrueが返される
# argmaxは配列の中で一番値の大きい箇所のindex(=一番正解だと思われるラベルの番号)を返す
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
# booleanのcorrect_predictionをfloatに直して正解率の算出
# false:0,true:1に変換して計算する
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# TensorBoardで表示する様設定
tf.scalar_summary("accuracy", accuracy)
return accuracy
if __name__ == '__main__':
# 学習用画像をTensorFlowで読み込めるようTensor形式(行列)に変換
# ファイルを開く
f = open(FLAGS.train, 'r')
# データを入れる配列
train_image = []
train_label = []
for line in f:
# 改行を除いてスペース区切りにする
line = line.rstrip()
l = line.split()
# データを読み込んで28x28に縮小
img = cv2.imread(l[0])
img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE))
# 一列にした後、0-1のfloat値にする
train_image.append(img.flatten().astype(np.float32)/255.0)
# ラベルを1-of-k方式で用意する
tmp = np.zeros(NUM_CLASSES)
tmp[int(l[1])] = 1
train_label.append(tmp)
# numpy形式に変換
train_image = np.asarray(train_image)
train_label = np.asarray(train_label)
f.close()
# 同じく検証用画像をTensorFlowで読み込めるようTensor形式(行列)に変換
f = open(FLAGS.test, 'r')
test_image = []
test_label = []
for line in f:
line = line.rstrip()
l = line.split()
img = cv2.imread(l[0])
img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE))
test_image.append(img.flatten().astype(np.float32)/255.0)
tmp = np.zeros(NUM_CLASSES)
tmp[int(l[1])] = 1
test_label.append(tmp)
test_image = np.asarray(test_image)
test_label = np.asarray(test_label)
f.close()
#TensorBoardのグラフに出力するスコープを指定
with tf.Graph().as_default():
# 画像を入れるためのTensor(28*28*3(IMAGE_PIXELS)次元の画像が任意の枚数(None)分はいる)
images_placeholder = tf.placeholder("float", shape=(None, IMAGE_PIXELS))
# ラベルを入れるためのTensor(3(NUM_CLASSES)次元のラベルが任意の枚数(None)分入る)
labels_placeholder = tf.placeholder("float", shape=(None, NUM_CLASSES))
# dropout率を入れる仮のTensor
keep_prob = tf.placeholder("float")
# inference()を呼び出してモデルを作る
logits = inference(images_placeholder, keep_prob)
# loss()を呼び出して損失を計算
loss_value = loss(logits, labels_placeholder)
# training()を呼び出して訓練して学習モデルのパラメーターを調整する
train_op = training(loss_value, FLAGS.learning_rate)
# 精度の計算
acc = accuracy(logits, labels_placeholder)
# 保存の準備
saver = tf.train.Saver()
# Sessionの作成(TensorFlowの計算は絶対Sessionの中でやらなきゃだめ)
sess = tf.Session()
# 変数の初期化(Sessionを開始したらまず初期化)
sess.run(tf.initialize_all_variables())
# TensorBoard表示の設定(TensorBoardの宣言的な?)
summary_op = tf.merge_all_summaries()
# train_dirでTensorBoardログを出力するpathを指定
summary_writer = tf.train.SummaryWriter(FLAGS.train_dir, sess.graph_def)
# 実際にmax_stepの回数だけ訓練の実行していく
for step in range(FLAGS.max_steps):
for i in range(len(train_image)/FLAGS.batch_size):
# batch_size分の画像に対して訓練の実行
batch = FLAGS.batch_size*i
# feed_dictでplaceholderに入れるデータを指定する
sess.run(train_op, feed_dict={
images_placeholder: train_image[batch:batch+FLAGS.batch_size],
labels_placeholder: train_label[batch:batch+FLAGS.batch_size],
keep_prob: 0.5})
# 1step終わるたびに精度を計算する
train_accuracy = sess.run(acc, feed_dict={
images_placeholder: train_image,
labels_placeholder: train_label,
keep_prob: 1.0})
print "step %d, training accuracy %g"%(step, train_accuracy)
# 1step終わるたびにTensorBoardに表示する値を追加する
summary_str = sess.run(summary_op, feed_dict={
images_placeholder: train_image,
labels_placeholder: train_label,
keep_prob: 1.0})
summary_writer.add_summary(summary_str, step)
# 訓練が終了したらテストデータに対する精度を表示する
print "test accuracy %g"%sess.run(acc, feed_dict={
images_placeholder: test_image,
labels_placeholder: test_label,
keep_prob: 1.0})
# データを学習して最終的に出来上がったモデルを保存
# "model.ckpt"は出力されるファイル名
save_path = saver.save(sess, "model.ckpt")
ここまででTensorFlowの学習部分の処理は完了です。
因みに今回はTensorFlowでアニメゆるゆりの制作会社を識別するのkivantiumさんと、ほぼ、というか、全く同じ構成です。最初自分で色々やっていましたが、(イマイチいい感じにできず)最終的に力及ばす、全く同じにさせて頂きました。m(_ _)m
データ読み込みの部分はOpenCVでなく、TensorFlow組み込みの tf.TextLineReaderやdecode_jpeg関数を使うともっといい感じに書けるっぽいですが、そちらもイマイチうまくできず結局やれず…orz
「流石に記事にするのに全く同じなのはちょっとあれだな…」と思い、せめてもの気持ちとしてコード解説部分のコメントを、僕のようなスーパー初心者用に更に細かく記載しておきました。
(説明に語弊等があった場合は教えてくださいm(_ _)m)
2.実際に顔データを学習させる
学習モデルの設計とデータ学習部分の処理が出来たので、これでmain.pyファイルを顔画像データと合わせてディレクトリに設置して、source bin/activateでTensorFlowを起動してpython main.pyでmain.pyファイルを実行してあげると、実際に学習が開始され、最終的な学習成果のmodel.ckptファイルが出力されるはずです。実際にデータ学習を実行しましょう!
①cd tensorflow(tensorflowディレクトリへ移動)
②source bin/activate(tensorflowを起動)
③python main.py(学習実行!)
④最終的な学習結果のmodel.ckptファイルを生成
処理さえ書けば非常に簡単に実行できますね。僕の場合、200STEPだと30分くらいは学習にかかりました。10000万回とか学習させるとかなり時間がかかるんだろうなと思います。
3.学習の結果を見てみる
学習を実行した際の正解率(accuracy)や誤差(cross_entropy)の推移は、TensorBoardでグラフとして出力されるので見ることができます。
学習結果は同じ学習モデルでも学習データによって変わってくるかと思いますが、僕の場合はこんな感じでした。学習中の正解率はコンソールにも出力されるかと思います。因みに訓練回数とバッチ数は他の方々の記事などを参考に、訓練回数を100~200、バッチ数10~20とかにしてみたり結構適当に決めました。どういう値設定がいいんだろう。
accuracy(正解率)のグラフ
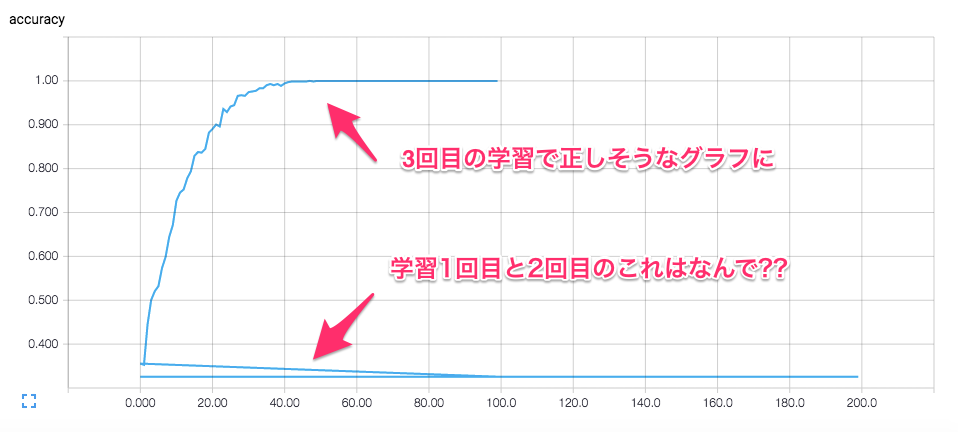
僕はバッチ数と学習回数を変えて3回学習実行させましたが、1回目と2回目はaccuracyが0.33(1/3)から最後まで全く変わらず、2回目と同じ条件でもう一度3回目の学習を実行したら、ちゃんとSTEPの回数に合わせてaccuracyが上がって行きました。
(今回3回目の学習で突然ちゃんと正解率が上がり始めたという、この挙動だけが腹落ちしていなくて、どなたか何が起きたのか教えて欲しいですm(_ _)m)
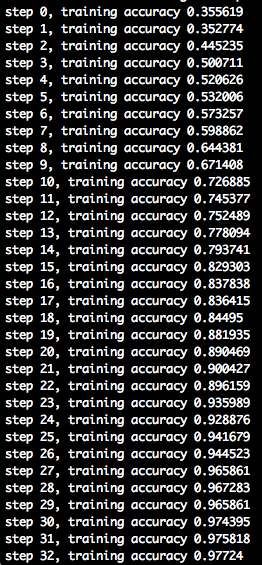
(3回目の学習時のコンソールの出力。40STEPくらいで正解率1になった。)
僕の場合、40STEPくらいで正解率が1になり、他の人の事例とかと比べて妙に早い気がしたので、訓練データだけに最適化してしまい実際には使えないモデルが出来上がってしまうという**「過学習」**か?と疑いましたが、その後の検証用のテストデータでの正解率も97%ほどだったので、別に問題はないのかな?と判断して先に進めました。
(「ってか果たして正解率って1になっていいのかな?w」とも思いました。そのまま進めたけどよかったのだろうか…)
cross_entropy(誤差)のグラフ
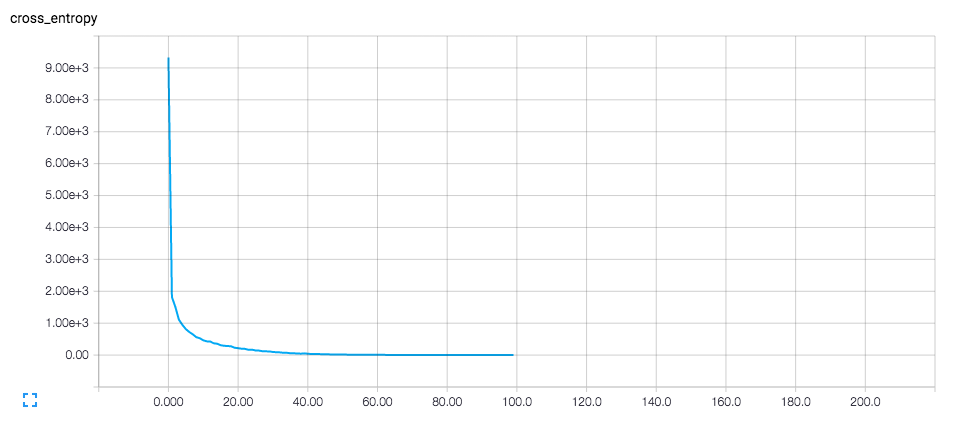
cross_entropyのグラフはこんな感じ。(3回目の学習実行時)
ここまでやってみて思ったのは**「学習モデル(ニューラルネットワーク)設計もそうですが、訓練回数とかバッチ数とかの調整はセンスとか、経験とかが問われる部分な気がする」**という感想でした。ムズい!
学習はこれで終わりです。TensorFlowの組み込み関数で学習用データを反転させたり、色調を変えたりしてデータの水増しが簡単にできる関数などもあるっぽいので、使ってみたかったですが、今回は3回目の学習実行で水増しを使わずとも、とりあえず求めていた感じの学習結果っぽくなったので、今回は見送りました。
(参考:画像の水増し方法をTensorFlowのコードから学ぶ)
初めてのTensorFlowの学習なんでかなり手探りでしたが、「ここはもっとこうした方がいいよ〜」みたいのあれば教えて頂きたいですm(_ _)m
④任意の画像の顔を判定できるようにする
最後に学習後のモデルデータを使って、任意の画像の顔を判定できるようにします。TensorFlowとPythonのWEBアプリケーションフレームワークのFlaskを使って、WEBインタフェースで実行できるように実装していきます。
続きの第4部はこちら→ディープラーニングでザッカーバーグの顔を識別するAIを作る④(WEB構築編)
「ディープラーニングでザッカーバーグの顔を識別するAIを作る」<記事全編>
第1部:ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編)
第2部:ディープラーニングでザッカーバーグの顔を識別するAIを作る②(AIモデル構築編)
第3部:ディープラーニングでザッカーバーグの顔を識別するAIを作る③(データ学習編)
第4部:ディープラーニングでザッカーバーグの顔を識別するAIを作る④(WEB構築編)
GitHub:https://github.com/AkiyoshiOkano/zuckerberg-detect-ai
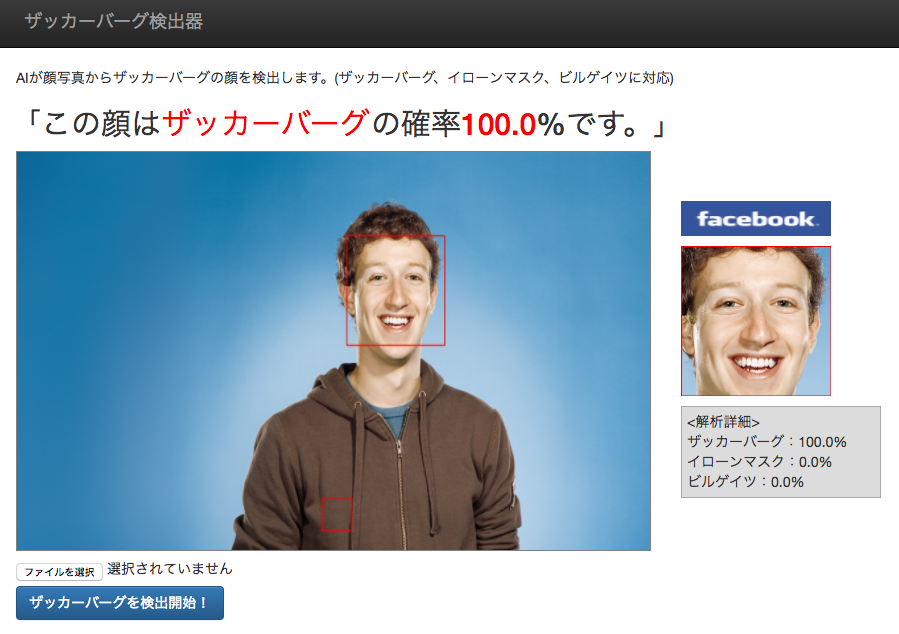
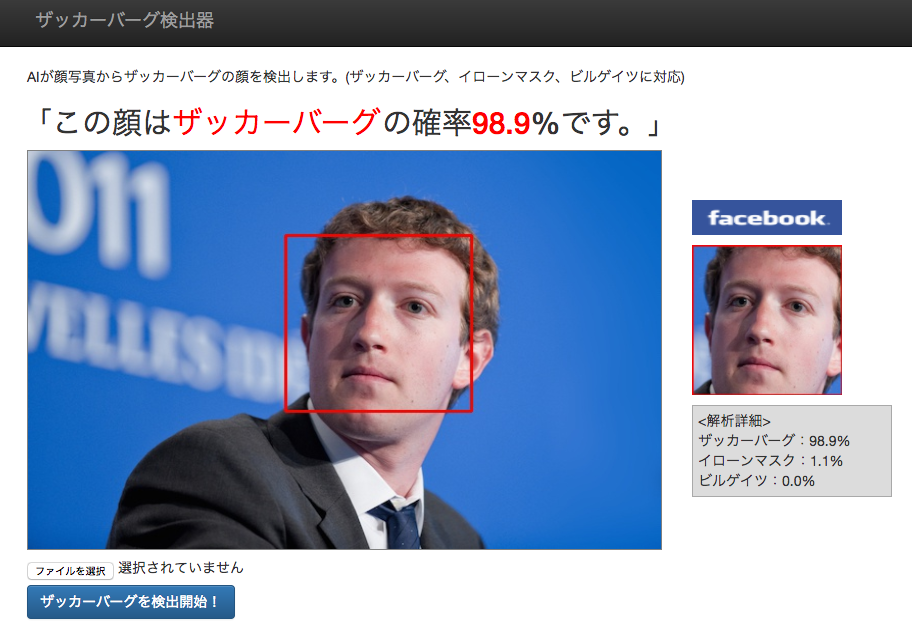
おまけ判定結果
おまけ判定画像たち。
今回はザッカーバーグ、ビルゲイツ、イローンマスクの3人のうち誰も90%以上を超えなかったら「3人のうち誰でもない」と表示する仕様にしました。
ザッカーバーグに似てるでいじられるサバンナ高橋氏1
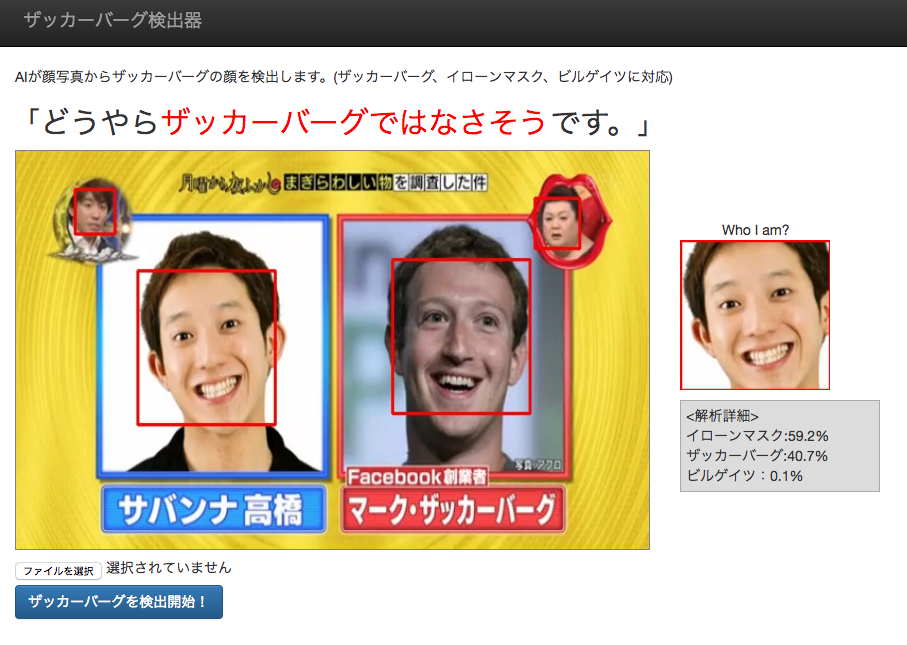
ちゃんとザッカーバーグとサバンナ高橋氏を識別するAI
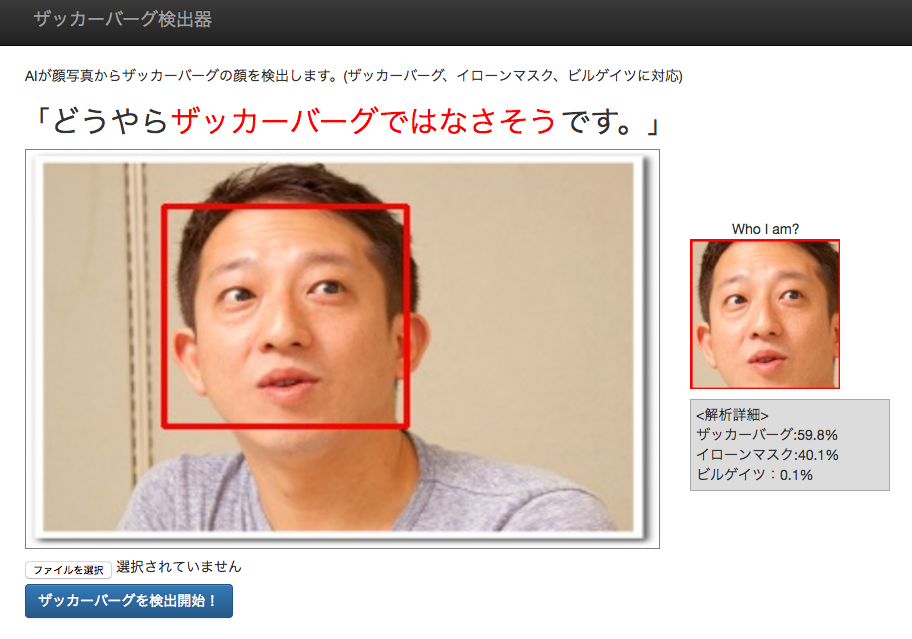
ザッカーバーグ氏