はじめに
「ローカルLLMをClaude Codeで動かせるんじゃないか?」 そう考えて実際に試してみたのがこの記事の内容。
コスト削減、プライバシー保護、制約のないオフライン動作 —— ローカルLLMを利用出来ることによる魅力は計り知れない。
私もその魅力に取りつかれ禁断の道へと突き進んだ。そしてその過程でさまざまな壁にぶつかった。試してみて初めて分かることもある。この記事は、その試行錯誤の記録だ。
この記事で分かること
- ローカルLLMをClaude Codeフレームに組み込む際の技術的な落とし穴
- MCP(Model Context Protocol)がローカルLLMで使えないことが実際に何を意味するか
- KAシステム(自作RAG)をCCKAとLLKAに分離するという設計判断に至るまでの経緯
- ローカルLLMが「今できること」と「まだできないこと」の現実
前提知識
この記事を読む上で、以下の概念や関連記事を知っていると理解しやすい。
| 概念 | 簡単な説明 |
|---|---|
| Claude Code | Anthropicが提供するCLIベースのAIコーディングエージェント。Hooks、Skills、Agent Teamsなどの拡張機能を持つ |
| MCP | Model Context Protocol。LLMが外部ツール(DBやAPIなど)と連携するためのプロトコル。いわば「LLMのUSBポート」のようなもの |
| Ollama | ローカルマシン上でLLMを動かすためのランタイム。ollama pull qwen2.5:14b のように手軽にモデルを取得・実行できる |
| Knowledge Assistant | 通称KA RAG知識ベースと組み合わせたAIアシスタントシステム |
| CCKA / LLKA | この記事で登場する概念。前者はClaude Code Knowledge Assistant 後者はLocal LLM Knowledge Assistant
|
関連記事
- 「記憶」を持つAIエージェントを自作した | 【Knowledge Assistant】
- 月々の高額AI請求を見て本気で「ローカルLLMでClaude Codeを動かせないか」ためした話
- 13モデル実測比較:HumanEval/HumanEval+でわかるLLMコーディング実力ランキング2026
1.Claude CodeフレームにローカルLLMを組み込もうとした
1-0.最初の動機
きっかけはシンプルだった。日常的な知識検索、要約、簡易QAといった処理を、毎回Claude APIに投げるのはコストがかかりすぎる。「軽い処理だけローカルLLMに逃がせばいいんじゃないか」という発想だ。
この辺りの詳細は 月々の高額AI請求を見て本気で「ローカルLLMでClaude Codeを動かせないか」ためした話 に記載したので割愛。
1-1.最初の壁:/v1 ハックとツール呼び出しの崩壊
ローカルLLMをClaude Codeに繋ぐ最も手軽な方法として、こんな設定がよく紹介されていた。
export ANTHROPIC_BASE_URL="http://localhost:11434/v1"
export ANTHROPIC_API_KEY="dummy"
OllamaのOpenAI互換エンドポイント(/v1)に向けるという方法だ。「一応動く」という声は多い。でも、いざエージェント機能——ファイルを読む、検索する、ツールを呼び出す——を使おうとすると壊れる。
原因は、API形式の根本的な不一致にある。Claude Codeがツールを呼び出す際、モデルのレスポンスには構造化された tool_calls オブジェクトが必要だ。
{
"role": "assistant",
"content": [],
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "read_file",
"arguments": "{\"path\": \"./src/main.py\"}"
}
}
]
}
しかし /v1 モード(OpenAI互換)では、OllamaはこれをJSON文字列としてプレーンテキストの content フィールドに詰め込んでしまう。Claude Codeはそれを「ツール呼び出しの意図」として認識できず、テキストとして素通りする。
「動いてるように見えてエージェントとして機能していない」という、最も厄介なパターンだ。
1-2.Ollama 0.18 ネイティブAPI:一歩前進
2026年3月14日にリリースされたOllama 0.18から、Claude Codeのネイティブプロバイダーとして /api/chat エンドポイント経由の接続が可能になった。これは大きな前進だ。
/v1 と /api/chat の主な違いを整理するとこうなる。
| 項目 |
/v1(OpenAI互換) |
/api/chat(ネイティブ) |
|---|---|---|
| tool_calls の形式 | テキスト文字列に変換 | 構造化オブジェクトをそのまま通す |
| ストリーミング | 基本的なチャンク | 真のデルタストリーミング |
| レイテンシ | 基準 | 約15〜20%改善 |
| 推奨用途 | OpenAI SDK との互換が必要な場合のみ | Claude Code との接続 |
/v1 は「使えるように見えて使えない」、/api/chat が「本来の統合方法」だということだ。
1-3.見落としやすい地雷:サイレントフォールバック
ここで一つ、見落としやすい問題がある。デフォルト設定ではローカルLLMが失敗した時に、Claude APIへ自動でフォールバックする挙動だ。
プライバシーの観点からローカルLLMを選んでいる場合、気づかないうちに社内情報がAnthropicのAPIに送信されている、という最悪のパターンがあり得る。これはセキュリティホールと言っていいと思う。
対策は必須だ。
{
"fallbackProvider": "none"
}
この設定を明示的に入れることで、ローカルLLMが失敗した際にエラーとして明示的に通知され、サイレントに外部へ流れることを防げる。
2.MCPが使えない —— 本当の壁
Ollama 0.18のネイティブAPIで基本的なツール呼び出しは動くようになった。では「KAにローカルLLMを組み込む」という当初の目標は達成できるのか?
ここで思わぬ現実に直面した。
2-1.Claude CodeのKA依存機能を棚卸しした結果
KA(Knowledge Assistant)がClaude Codeのどの機能に依存しているかを一つひとつ洗い出した。すると、想定以上に多くの機能がClaude Code固有だということが分かってきた。
| # | 機能 | ローカルLLMでの代替 |
|---|---|---|
| 1 | MCP(Model Context Protocol) | ローカルLLMの一部で利用可 |
| 2 | Hooks | Claude Code固有。代替不可 |
| 3 | Skills(カスタムコマンド) | Claude Code固有。代替不可 |
| 4 | Agent Teams | Claude Code固有。代替不可 |
| 5 | Subagent(Agent tool) | Claude Code固有。代替不可 |
| 6 | CLAUDE.md | 概念は移植可能だが別実装が必要 |
| 7 | Claude CLI呼び出し | 代替不可(ローカルLLMとCLIは別物) |
| 8 | Plan Mode | Claude Code固有。代替不可 (ただしKAでは不要) |
| 9 | Memory | 概念は移植可能。実装が必要 |
調査結果を見てあらためて考えさせられた。Claude Codeの機能がほとんどそのまま使えない。
「LLMを差し替えればなんとかなるかも?」と軽い気持ちで考えていたが、まさかここまで酷いとは…
特にMCPとHooks、Skillsが使えないことについては絶望すら感じる。
2-2.MCPが使えないとは、具体的にどういうことか
MCPのことを「LLMのUSBポート」と表現している話を聞いたことがある。USB機器を繋いで機能を拡張できるように、MCPでLLMに外部ツールを接続できる、という意味だ。この比喩はとてもイメージしやすいが分かりやすい。
たとえばKAには「unified_search」という知識ベースへアクセスするための以下のようなMCPが存在するが、このMCPが利用出来なくなる。
ローカルLLMでもPython SDKを通じてChromaDBやSQLiteに直接接続することはできる。しかし、MCPが提供するのはそれだけではない。add_knowledgeといった高レベルのRAG操作、それにHooksによる品質チェックやSkillsによるタスクの自動化——これらがまるごと使えなくなる。
KAの処理フローをシンプルに書くと、こうなる。
このフローのうち、ローカルLLMで代替できるのは「LLM推論」の部分だけだ。それ以外はClaude Code固有の仕組みに依存している。
「MCPを呼べなければ現在のKAの価値の7割は使えない」——これは誇張ではなく、棚卸しをして実感した現実だ。
2-3.モデル品質の壁
機能面の問題だけではない。品質面の壁も無視できない。
RTX 3090上でqwen2.5:14bを動かすと、推論速度は211〜215 tok/sと実用的だ。速度は十分だ。問題は速さではなく、「何を理解できるか」だ。
コーディングエージェントとしての動作(複数ツールの連携、コンテキストを跨いだ理解、自律的な判断)には、現状の14Bクラスのオープンモデルでは品質が不足していると感じた。「速い」と「役立つ」は別の話だ。
2026年5月時点で、tool calling精度が比較的高いモデルとしてはGemma 4 26B(約86.4%精度)やQwen3系が注目されているが、それでもClaude Claude Code上での多段階エージェント動作にはまだまだ補いきれない品質差がある。
3.決断:「差し替え」ではなく「分離」へ
3-1.ハイブリッドアプローチの複雑さ
当初は「一部だけローカルに逃がせばいい」という考えだった。単純な作業、コーディングは安いローカルLLMで、複雑な推論はClaudeで——というハイブリッド方式だ。
しかし設計を進めるほど、制御は複雑になっていく。「このクエリはローカル」「あのクエリはClaude」など分岐判断のロジックが増え障害時の切り分けも難しくなる。「エレガントさ」が失われていく感覚があった。
3-1.転換点:「同一KA内で切り替える」という前提を疑う
「やはり同じKAの中で毛色の違うLLMを切り替えようとするのは無理がある」
いくらレイヤーを切り替えようとも、責務を分離しようとも、LLMの特性により同じ処理をMCP用とAPI用に分けるような設計は正直全然イケてないと思う。
ならば 無理やり同一システムの中に混在するのではなく、派生して別のシステムとして設計する。そう発想を変えた方がシンプルになると思った。
「差し替え」は既存の前提を崩す。「分離」は前提を保ったまま新しい軸を追加する。この違いは根本的だ。
3-2.CCKA/LLKA分離アーキテクチャ
こうして生まれたのが、CCKAとLLKAの完全分離アーキテクチャだ。
| 項目 | CCKA | LLKA |
|---|---|---|
| 正式名称 | Claude Code Knowledge Assistant | Local LLM Knowledge Assistant |
| 稼働場所 | VPS(クラウド) | WSL(RTX 3090マシン) |
| LLM接続 | Claude CLI経由 | Python SDK直接接続(Ollama) |
| MCP | 利用可 | 利用不可 |
| Hooks / Skills | 利用可 | 利用不可 |
| Agent Teams | 利用可 | 利用不可 |
| データストア | ChromaDB + SQLite | ChromaDB + SQLite |
| 主な用途 | 高度な推論・設計・コード生成 | 要約・分類・簡易QA・ドラフト |
データストア(ChromaDB + SQLite)を共有しているのが設計の肝だ。処理エンジンは異なるが、「記憶は一つ」だ。CCKAで蓄積した知識をLLKAでも検索できるし、LLKAで処理した結果もCCKAから参照できる。 ※ただし、当面はデータ破損の恐れがあるためそれぞれ分けて管理する予定
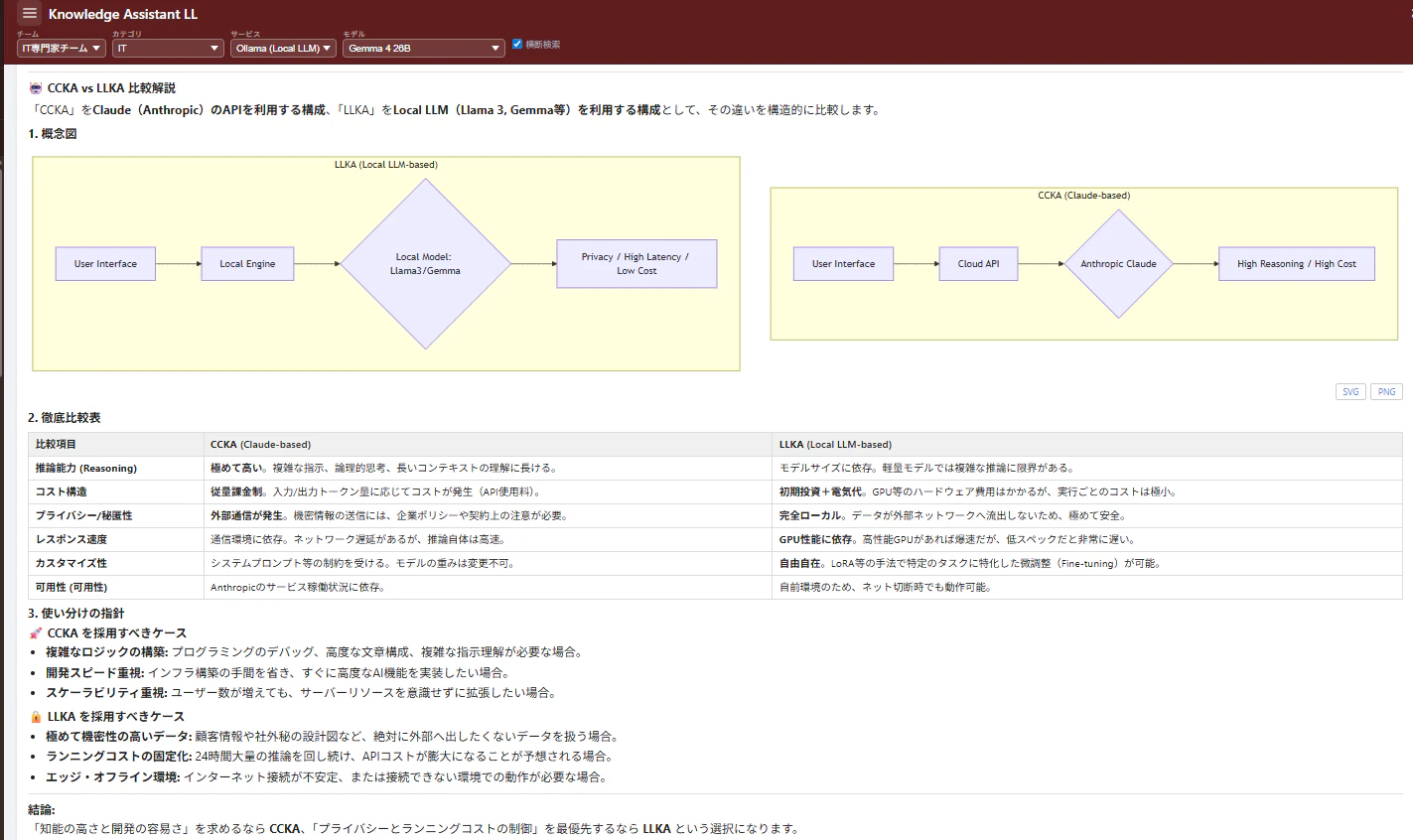
※分離してチューニングすることにより、それなりの品質の回答が得られるようになった。
4.KA + ローカルLLM統合の最終形
4-1.インフラ構成の全体像
4-2.モデル選択の考え方
RTX 3090(VRAM 24GB)で動かす際のモデル選択は、用途別に考えるのが実用的だ。
| 用途 | 推奨モデル | 理由 |
|---|---|---|
| 汎用会話・RAG | Qwen3.5 27B / Gemma 4 26B | tool calling精度が高い(Gemma 4は約86.4%) |
| コーディング支援 | deepseek-coder-v2:lite | コーディング特化、軽量 |
| 高速応答が必要 | Qwen3 30B MoE | MoEで活性パラメータが少なく高速 |
2026年5月時点では、tool calling精度という観点ではGemma 4 26BとQwen3系が一歩抜け出しているという印象だ。ただし、クラウドLLM(Claude)との品質差は依然として大きく、特に複雑なマルチステップのタスクで顕著だ。
4-3.実測した性能データ
PoCで計測した実測値をまとめておく。
| メトリクス | 値 | 備考 |
|---|---|---|
| 推論速度 | 211〜215 tok/s | qwen2.5:14b、RTX 3090 |
| モデル切替コスト | 108〜160 ms | qwen2.5:14b ↔ deepseek-coder-v2:lite |
| 外部割り込み時の劣化 | 35〜55秒 | GPU共有時のリソース競合 |
速度は十分実用的だ。切替コストも100ms台なら許容範囲だと思う。問題は速さではなく、品質と機能連携だという結論はここでも変わらない。
4-4.「使い分け」が明確になった
分離したことで、かえって運用がシンプルになった。「どちらを使うか」の判断基準が明確になったからだ。
CCKAを使う場面:
✅ 複雑な設計判断が必要
✅ MCPツール連携が必要(知識検索・追加)
✅ Agent Teamsで専門家チームを動かしたい
✅ コード生成・レビュー・リファクタリング
LLKAを使う場面:
✅ シンプルな要約・分類
✅ 簡易QAやドラフト生成
✅ APIコストを抑えたい処理
✅ 社内情報を外部に出したくない処理
5.今回の学び
試行錯誤を経て、いくつかの学びが整理できた。
5-1.フレームの価値はモデルと切り離せない
Claude Codeのエージェントフレームの強さは、「フレームの設計」だけではなく「フレーム × モデル品質」の掛け算で実現されている。ローカルLLMを「エンジンだけ載せ替えたClaude Code」として使おうとしても、トランスミッション(MCPやHooks)を外した車のようになってしまう。
5-2./v1 vs /api/chat の差は決定的
Ollama 0.18以前の「/v1 ハック」は見落としやすいが、ツール呼び出しの成否を分ける決定的な違いがある。ローカルLLMをClaude Codeと繋ぐなら、必ずネイティブAPIを使うこと。
5-3.サイレントフォールバックはセキュリティ問題
fallbackProvider: none の設定を忘れると、ローカルLLMを使っているつもりがいつの間にかクラウドAPIに流れている。プライバシー目的で使っている場合は致命的だ。
5-4.「差し替え」と「分離」は根本的に違う設計判断
差し替えは既存の前提を崩す。今回の場合、「Claude CLIを前提に設計されたKA」のLLMバックエンドを差し替えると、MCPやHooksへの依存がすべて壊れる。分離ならば、既存のCCKAの前提を崩さずに新しいLLKAを独立して構築できる。
5-5.ローカルLLM導入の正直な現在地
色々試してみた結果、2026年5月時点でのローカルLLMは以下のような状況だと思う。
| 評価軸 | 現在地 |
|---|---|
| 速度 | ✅ 実用的(14Bクラスで200tok/s超、RTX 3090なら) |
| コスト | ✅ 初期投資後はほぼゼロ |
| プライバシー | ✅ 適切に設定すれば完全にローカル処理 |
| 複雑な推論・設計 | ❌ 現状はまだ難しい |
| MCPエコシステム連携 | ❌ 「ローカルLLM単体では使えない」 と考えた方が良い |
| マルチエージェント動作 | ❌ Claude Code固有の仕組みに依存 |
6.まとめ
今回の検証で、現状のローカルLLMはClaude Codeフレームとして機能させることができないことが分かった。MCPもHooksも、Claude CodeのエージェントフレームはClaude専用に設計されており、LLMを差し替えるだけでは再現できない壁がある。
ただ、この結果をもって開発を止めるつもりはない。Claude Codeフレームの機能をさらに調査・解析し、LLKAがそれに近しいシステムになるよう開発を続けていく。今回明らかになった「何が使えないのか」という知識そのものが、次のステップの設計図になる。
次に取り組む実装は、MCP・Hooks・Skills機能の独自実装だ。Claude Code固有の仕組みをLLKA上で再現していくことで、ローカルLLMでも本格的なエージェントフレームとして動作するシステムを目指す。