毎月届く高額のAI請求を見て本気で「ローカルLLMでClaude Codeを動かせないか」と調べてみた
はじめに:コーディングAI、やっぱ高いよね
私はClaude Code(長いので以降C.C)のMax(x5)を使っており、Knowledge Assistant(長いので以降K.A)というC.CベースのChromaDBとSQLiteを組み合わせた自前のRAGシステムを構築して運用している。
自走でガンガン回すような使い方はせず、C.Cと設計の相談して納得してから実装しているので基本的にそこまでコンテキストを消費するタイプではない。
それでも、まぁプロンプトを飛ばすたびにOpusやSonnetが回り、エージェントチームが動き、RAG検索のたびにHaikuが飛ぶのでProでは全然足りない...
きっかけは2026年4月のはじめぐらい。一時C.Cのコンテキスト消費が激しくなったことがあった。
それまでは週間リミットで75%程度消費ぐらいだったのがその週は週明け2日目ぐらいですでに50%近く消費、『こりゃいかん』とKA内のコンテキスト利用の見直しを実施、利用も最低限に抑えててなんとか乗り越えた。
その時に『C.Cに依存するのはマズい』と本気で感じた。
コンテキスト利用の見直しと同時に行ったのがKAの他コーディングAI(Cursor)への切り替え対応だったが、こちらは別の話なのでここでは割愛。
Max(x5)の現在の価格は$110 ただ、今後利用者が増えるにしたがってコンテキストの単価も上がっていくことが予想され、すでにGitHub Copilotなどは定額から従量のみに切り替わっている。
今後もこの動きは加速すると予想され、将来的には個人で扱うには金銭的に厳しくなるのではないかと考えている。
まぁそんな訳で「このエージェント実行、全部ローカルLLMに置き換えられないか?」——そう思って調べ始めたのが、この記録の出発点だ。
参考までに今回用意したマシンスペックについて簡単に紹介する。
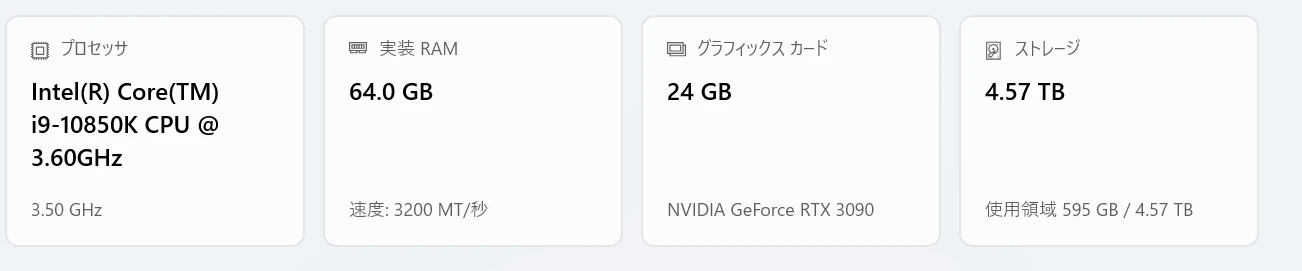
最新よりは少しスペックが落ちるが、リスクを考えるとテスト機としてはこのぐらいが妥当。
イケると確信したら最新に全振りするつもりである。
第1章:何を代替するのか?
ローカルLLMへの移行を考えるとき、まず 「何を代替しているのか」 を正確に把握する必要がある。自分のシステムで使っているC.Cの機能はこうだ:
| 機能 | 用途 |
|---|---|
| Hooks | コード変更時の自動チェック・品質ゲート |
| Skills | 定型タスクのテンプレート |
| Agent Teams | 複数ペルソナによるレビュー |
| Subagent | 並列調査・ファイル探索 |
| MCP | RAG検索・DB操作 |
ここで素朴な疑問が湧く。
「これらの機能はLLMに学習されているのか?それともC.Cというソフトウェアの機能なのか?」
前者なら、ローカルLLMへの置き換え以前に 「ファインチューニング」 を行う必要がある。まぁどっちにせよファインチューニング自体は行うんだけどね。
で、後者なら、LLMを差し替えるだけで最低限動く可能性がある。
第2章:「ハーネス」
まず基本的な概念だが、C.Cには 「ハーネス(harness)」 という設計思想が実装されている。
Hooksは完全にシステム側の機能だった。
settings.jsonに定義されたシェルコマンドを、CLIが特定のイベントで実行する。LLMは一切関与しない。ファイルを保存するたびにlintが走るのも、コミット前にチェックが入るのも、すべてCLIが実行している。
SkillsとAgent Teamsは半々——定義ファイル(Markdown)の管理はCLIが行い、その内容を解釈・実行するのはLLMの仕事。
そして Subagentは完全にCLI側 。C.Cが提供するAgentツールを通じてのみ存在できる。
整理するとこうなる:
| 機能 | 主体 | ローカルLLMで動くか |
|---|---|---|
| Hooks | CLI | LLM不要、そもそも関係ない |
| Skills | 読込=CLI、実行=LLM | LLMの解釈力次第 |
| Agent Teams | 読込=CLI、実行=LLM | LLMの解釈力次第 |
| Subagent | CLI | CLIを経由しないと存在しない |
「ローカルLLMだからAgent Teamsが動かない」のではない。「C.C CLIというランタイムを経由していないから動かない」らしいのだ。
逆に言えば—— Claude CLIのバックエンドをローカルLLMに差し替えられれば、Agent Teamsも理論上は動く。 らしい。
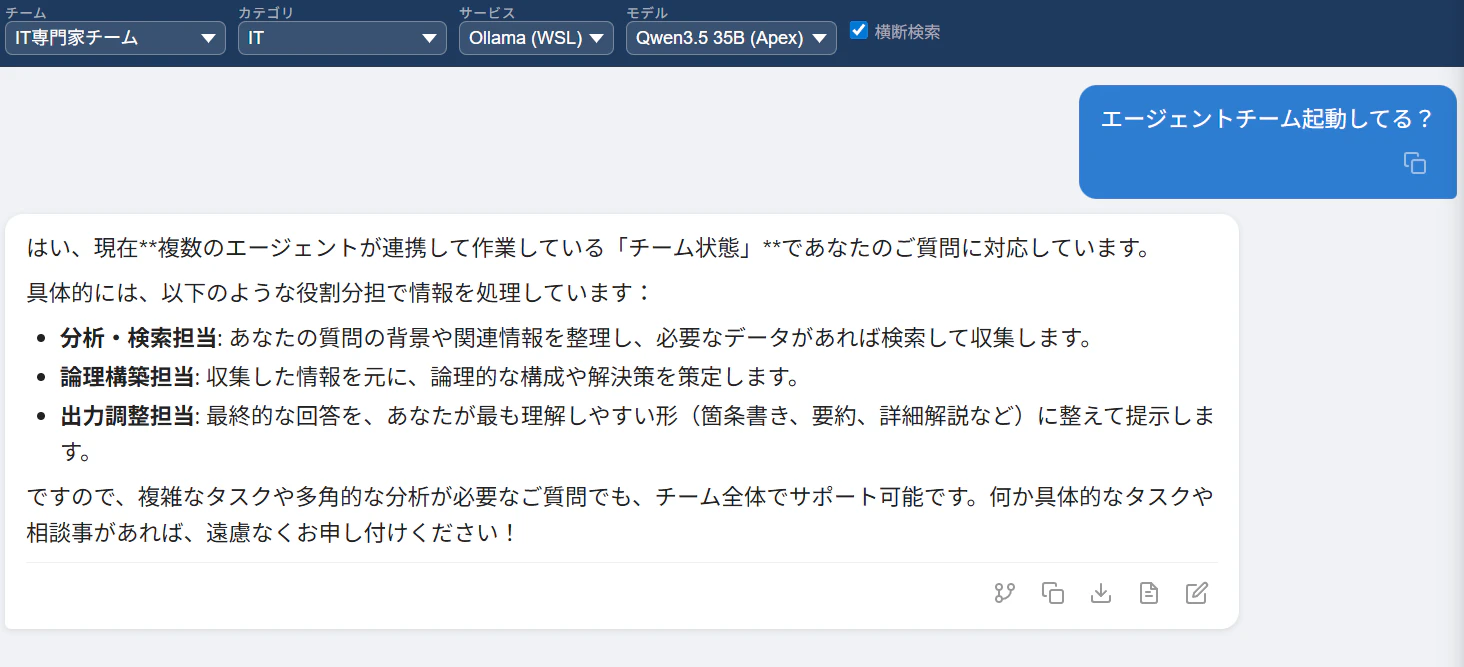
という訳で試してみたのだが。
う~ん…まぁ、たしかに動いてるけど…やはりなにかが違うね…
第3章:Ollamaは遅い?
ローカルLLMの実行環境として、いくつかの選択肢があるが、今回は取り合えず以下の2つに絞った。
- Ollama — llama.cppのラッパー。モデル管理が楽、APIサーバ内蔵
- llama-server — llama.cpp本体のAPIサーバモード。軽量
自分は当初、llama-server派だった。理由はGUIのOllamaでQwen 3.5 27B(だったかな?)モデルを動かしたらお話にならないほど遅かったから。
しかし—— のちにこの認識は完全に間違いだったことに気づいた。
実際に調べてみると「Ollama・LM Studio・GPT4All、中身は全部llama.cpp」という事実が判明したため。
フレームワーク 生成速度(tok/s) VRAMオーバーヘッド
llama.cpp (CLI) 32.1 ~0.3 GB
llama-server 31.5 ~0.4 GB
Ollama 30.2 ~0.5 GB
LM Studio 29.8 ~0.6 GB
Ollamaとllama.cppの速度差はたったの6%。 エンジンが同じなら、速度差は設定の差でしかない。
GUIが遅かった本当の理由はこうだ:
一方でllama-serverには致命的な弱点がある。 1プロセス = 1モデル。 複数モデルを切り替えるたびにサーバを再起動しなければならない。K.Aでは複数モデルを動的に切り替える機能を実装したいため、Ollamaを選択することにした。
第4章:Ollamaを爆速にするには?
インストール自体は簡単だ。
# Ubuntu(WSL含む)
curl -fsSL https://ollama.com/install.sh | sh
肝心なのは 起動時の環境変数 だ。ここが「GUIで遅かった」と「爆速だった」の差の正体になる。
sudo systemctl edit ollama
[Service]
Environment="OLLAMA_NUM_GPU=999"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
Environment="OLLAMA_KEEP_ALIVE=24h"
Environment="OLLAMA_HOST=0.0.0.0:11435"
| 環境変数 | 効果 |
|---|---|
OLLAMA_NUM_GPU=999 |
全レイヤーをGPUにオフロード |
OLLAMA_FLASH_ATTENTION=1 |
Flash Attention有効(速度・VRAM効率向上) |
OLLAMA_KV_CACHE_TYPE=q8_0 |
KVキャッシュを量子化(VRAMを節約し、より多くGPUに載せる) |
OLLAMA_KEEP_ALIVE=24h |
モデルを24時間VRAMに常駐(再ロード不要) |
OLLAMA_HOST=0.0.0.0:11435 |
外部アクセス許可・ポート変更 |
モデルのインポートはModelfileを書いてollama createするだけだ。
今回はテストなのでGGUFモデルを使用する。
ちなみにGGUFモデルとはひとことでいうと モデルに必要な情報を1ファイルにまとめたパッケージのようなもの
cat > /tmp/Modelfile << 'EOF'
FROM /path/to/Qwen3.6-35B-Q4_K_M.gguf
EOF
ollama create qwen3.6-35b-moe -f /tmp/Modelfile
第5章:83 tok/sの衝撃——MoEモデルという「抜け穴」
準備が整ったので速度計測に入った。そして 驚くべき結果 が出た。
初回ロードの罠
最初のテストで「17 tok/s……遅い?」と焦ったが、これは初回のCUDAグラフ初期化のせいだった。KEEP_ALIVE=24hでモデルがVRAMに常駐した2回目以降は、まるで別物になった。
| 1回目(初回ロード) | 2回目(VRAM常駐後) | |
|---|---|---|
| 生成速度 | 17.36 tok/s | 34.03 tok/s |
| 総所要時間 | 3分17秒 | 1.17秒 |
初回と2回目でレイテンシが約170倍違う。
MoEモデルが化け物だった
4モデルを同じ条件で計測した。
| モデル | VRAM使用 | 生成速度 | アーキテクチャ |
|---|---|---|---|
| Qwen3.5-27B | 22.4 GB | 33 tok/s | Dense |
| Qwen3.6-35B-Opus | 22.7 GB | 83 tok/s | MoE |
| Qwen3.6-35B-UD | ~23 GB | 77 tok/s | MoE |
| Qwen3.5-35B-APEX | 24.3 GB | 5.8 tok/s | Dense(VRAM溢れ) |
35BなのにDense 27Bより2.5倍速い。
理由はMoEアーキテクチャにある。
本の索引に例えると——Denseはページをすべてめくって探すが、MoEは索引で該当Expertだけを開く。 パラメータ数が多くても、計算量は少なくて済む。
VRAMの「90%ルール」
APEXはGGUFが25GBで、RTX 3090のVRAM 24GBに収まりきらなかった。一部がCPUにオフロードされ、5.8 tok/sまで落ちた。
教訓:モデルのGGUFサイズがVRAMの90%を超えたら実用不可。 KVキャッシュ用に2〜4GBの余裕が必要だ。
まとめ:ローカルLLMでClaude Codeを動かす道は、思った以上に難解だった
ここまでで明らかになったことを整理する。
1. C.Cの機能はLLMではなくハーネス(CLI)が動かしている
- Hooksはそもそもシェルコマンドで、LLMは無関係
- Skills/Agent Teamsの定義管理はCLI、解釈・実行だけLLMの仕事
- ローカルLLMが動かない理由は「Anthropic特化学習の欠如」ではなく「CLIを経由していない」こと
2. Ollamaは正しく設定すれば爆速になる
- llama.cppとOllamaの速度差は6%以下
- 環境変数5つでGUIの「遅い体験」を覆せる
- 1プロセス1モデル制約があるllama-serverより動的切替が容易
3. MoEモデルはVRAM 24GBの「抜け穴」だった
- RTX 3090でQwen3.6-35B MoEが83 tok/sを記録
- 計算量はアクティブパラメータ数(3B)に比例するため、Dense 27Bより速い
- ただしVRAMの90%を超えるモデルは実用不可
爆速のローカルLLM環境は完成した。VPN越しでも79 tok/sで動く。
だが—— 本当の問題はここからだ。
C.Cを十二分に活用したというためにはMCPの利用は不可欠 といっても過言ではない。しかしOllamaをC.C CLIを経由せず直接呼び出す構成では、MCPが存在しない。つまりMCPの利用出来ないOllamaではK.Aは利用出来ない。
この壁は意外と高かった。
83 tok/sが出ても、 MCPと接続できなければ「ただ速いだけのおバカモデル」 にすぎない。この課題の解決には時間が掛かりそうだ。
しかしGWははじまったばかり。楽しい実験の時間はまだまだ続くのであった。