はじめに
こんにちは。
この記事は、沖縄高専 Advent Calender 2022 17日目の記事です。
また、10日目の記事の後編となっています。
実は、記事が長くなってしまったことだけではなく、前編投稿時にはまだプログラムが未完成だったことが前編と後編に分けた理由です。先延ばしの先延ばしでした。
参加者の皆さん本当に申し訳ありません。
機械学習初心者+Qiita初投稿のため所々意味不明かもしれませんが、温かく見守っていただければと思います。
前編の要約
前編では、GPT-2でツイッターのトレンドから論文タイトルを生成するためには、実際の論文のタイトルで日本語の事前学習モデルをファインチューニングすればいいのでは?という至極当たり前の考えで、データセットの作成を行いました。
また、試行錯誤の結果、入力したトレンドの単語に続くように論文タイトルっぽいデタラメな文章を生成する、単純なテキストジェネレーターを作る方針にしました。
データセットは、CiNiiでスクレイピングした論文タイトルを、タイトルの始まりと終わりを示す特殊トークン、<s>と</s>を付与した形で保存しています。
それに加えて、自前のGPUで学習を行うために必要なドライバーやライブラリのインストールを行いました。
後編の要約
この記事では、日本語の事前学習モデルをファインチューニングして、トレンドの単語から論文タイトルを生成・ツイートしていきたいと思います。
また、タスクスケジューラを用いた定期ツイートもしていきたいと思います。
今回やったこと
全体の流れは大きく分けて、
- データセットの作成
- 機械学習の準備
- モデルの作成
- トレンド取得とタイトル生成・ツイート
の4つで、今回は、モデルの作成とトレンド取得とタイトル生成・ツイートを行います。
3. モデルの作成
モデルは前述したとおり、日本語の事前学習モデルを、前編で作成したデータセットでファインチューニングすることで作ります。
日本語の事前学習モデルはrinnaの、japanese-gpt-2-smallを使います(本当はmediumを使いたかったけど、3070TiのVRAMが8GBなので足りなかった...)。
1. ファインチューニングの準備
ファインチューニングにはいくつかのライブラリ等が必要で、まずはそれらをインストールしていきます。
Hugging FaceのTransformersリポジトリを作業ディレクトリにclone
git clone https://github.com/huggingface/transformers
また、必要なライブラリもそれぞれインストール
pip install transformers
pip install sentencepiece
pip install datasets
今回使うrinnaの日本語事前学習モデルでは、T5というTokenizerを使うため、作業ディレクトリにcloneしたTransformersの中のスクリプトファイル、run_clm.pyを少し修正する必要があります。
深くは理解できていないのですが、こちらの記事を参考にAutoTokenizer関連のプログラム
from transformers import AutoTokenizer
# ...
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
を、下のようにT5Tokenizerに書き換えています。
from transformers import T5Tokenizer
# ...
tokenizer = T5Tokenizer.from_pretrained(model_args.model_name_or_path)
tokenizer.do_lower_case = True
2. ファインチューニング
以下のコマンドで、実際にファインチューニングを実行しました。
作業ディレクトリにあるtransformesの中の先ほど修正したrun_clm.pyを使って、rinnaのjapanese-gpt-2-smallに、前編で作成したトレーニングデータとテストデータでファインチューニングしています。
今回使用したのがmediumではなくsmallだったため、気持ちバッチサイズを多めに(ほんとに気持ち)、エポック数は10回で実行しました。
python ./transformers/examples/pytorch/language-modeling/run_clm.py --model_name_or_path=rinna/japanese-gpt2-small --train_file=train_title.txt --validation_file=test_title.txt --do_train --do_eval --num_train_epochs=10 --save_steps=10000 --save_total_limit=3 --per_device_train_batch_size=2 --per_device_eval_batch_size=2 --output_dir=output/ --use_fast_tokenizer=False
学習にかかった時間は約1.5時間ほどだったと思います。
3. タイトル生成
以下のプログラムでいくつかタイトルを生成できます。
論文タイトルの長さっぽく15文字以上で、ツイートに収まるように140文字以内で生成しています。
from transformers import T5Tokenizer, AutoModelForCausalLM
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-small")
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("output/")
def generate_paper_title(word):
input_text = word
input = tokenizer.encode(input_text, add_special_tokens=False, return_tensors="pt")
output = model.generate(input, do_sample=True, num_return_sequences=10, min_length=15, max_length=140)
titles = '\n'.join(tokenizer.batch_decode(output)).replace('</s>', '')
print(titles)
トレンドに『男性と育休』が入っていたので、試しに10件生成してみます。
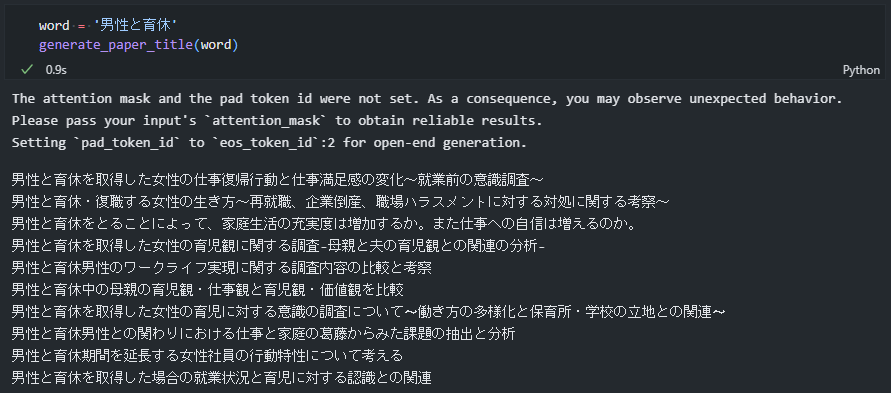
それっぽい論文タイトルが生成できているのではないでしょうか。
CiNiiで同様のタイトルの論文があるか検索してみましたが見つかりませんでした。
また、最近チェンソーマンを読んでいたのでチェンソーマンでも生成してみます。
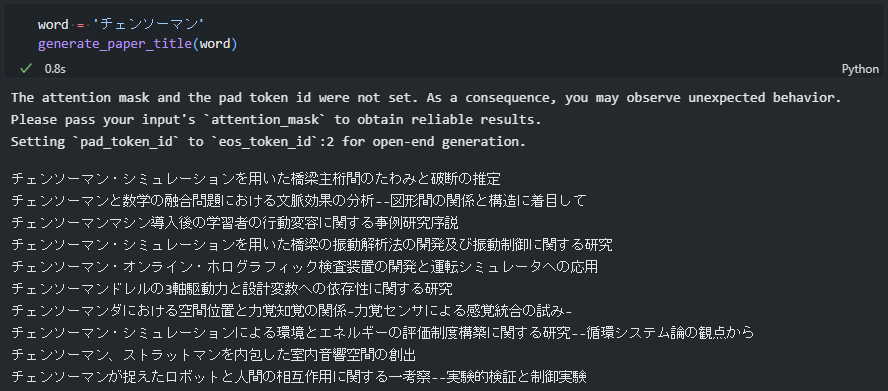
それっぽい意味不明なタイトルが生成できていますね!
ただ、『くん』や『さん』などの敬称を含む人名ぽいものを入力すると...

rinnaの学習データに結構引っ張られてしまいます...
そこはトレンド取得の時点で避けようかと思います(人名で論文書くことなんてほとんどないですからね)
4. トレンドからタイトルを生成して定期ツイート
ツイッターのトレンドの取得やツイートには、Twitter DevelopersでのAPI申請が必要となります。
自分は何度かbotを作成したことがあったため手順は省略させていただきますが、こちらの記事が分かりやすくて参考になると思います。
1. トレンドの取得とツイート
以下のプログラムでトレンドの取得とツイートを行います。
今回は日本語の論文タイトルを学習させているため、英数字のみで構成されているトレンドは省くようにしています。
また、トレンド検索に引っかかるように#を、自然な文章にするためにゼロ幅スペースを付与しています。
import re
import tweepy
from transformers import T5Tokenizer, AutoModelForCausalLM
CONSUMER_KEY = 'xxxxx'
CONSUMER_SECRET = 'xxxxx'
ACCESS_TOKEN = 'xxxxx'
ACCESS_SECRET = 'xxxxx'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
api = tweepy.API(auth)
def get_trends():
woeid = 23424856 #日本のトレンドID
trends_data = api.get_place_trends(woeid)
trends_list = trends_data[0]['trends']
trends = [trend['name'].replace('#', '') for trend in trends_list]
return trends
def generate_paper_title(word):
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-small")
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("output/")
input = tokenizer.encode(word, add_special_tokens=False, return_tensors="pt")
output = model.generate(input, do_sample=True, num_return_sequences=1, min_length=15, max_length=140)
title = '\n'.join(tokenizer.batch_decode(output)).replace('</s>', '')
return title
def main():
trends = get_trends()
for trend in trends:
if re.match(r'^[a-zA-Z0-9!-/:-@¥[-`{-~\s]*$', trend) is None: #英数字・記号を含むかの判定
if re.search('くん|さん|ちゃん', trend) is None: #人名敬称を含むかの判定
title = generate_paper_title(trend)
title = title.replace(trend, '#' + trend + '') ##とゼロ幅スペースの付与
api.update_status(title)
break
if __name__ == "__main__":
main()
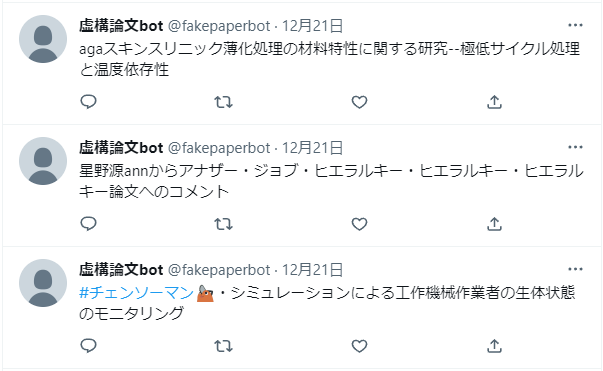
虚構論文botというbotを作ってテスト投稿してみました。
2. 定期ツイート
定期ツイートは、Windowsに標準搭載されている定期実行アプリ、タスクスケジューラで行います。
Unix系(Macなど)では、cronで代用できると思います。
仮想環境を使っていて少し手間取ったところもあったため、仮想環境を使った定期実行の手順を簡単に紹介します。
-
パスを通す
ユーザー環境変数のPathに、anaconda3の仮想環境のパスを指定します。
これをしないと仮想環境のPythonを使ってのプログラムの実行ができません。
今回は、fakepaperbotという仮想環境で開発していたため、そこのパスを通しています。
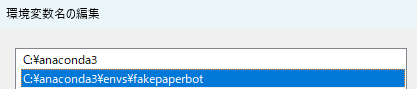
-
基本タスクの作成
タスクスケジューラを開き、操作から基本タスクの作成に進みます。
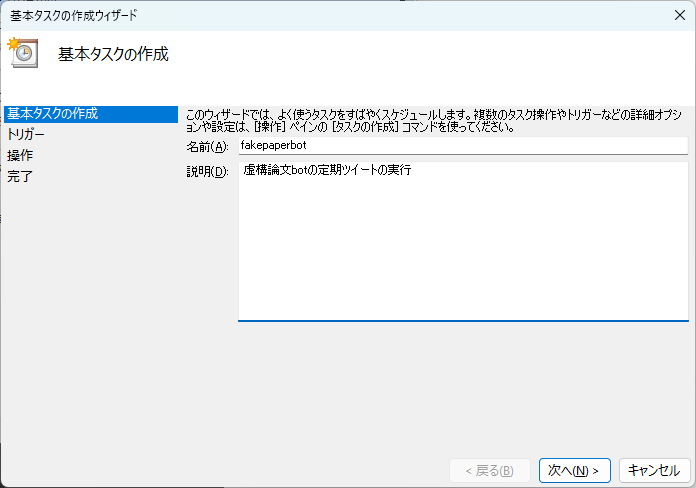
トリガーでは、実行日や実行頻度を指定できます。
一旦1回限りに指定しておきます(後で変更します)。

プログラムの開始を選択し、

プログラム/スクリプトに、先ほどパスを通した仮想環境内のpython実行ファイルを指定
引数の追加には、実行するプログラム(今回はmain.py)を指定
開始には、引数の追加で指定したプログラムがあるディレクトリを指定

完了を押します。
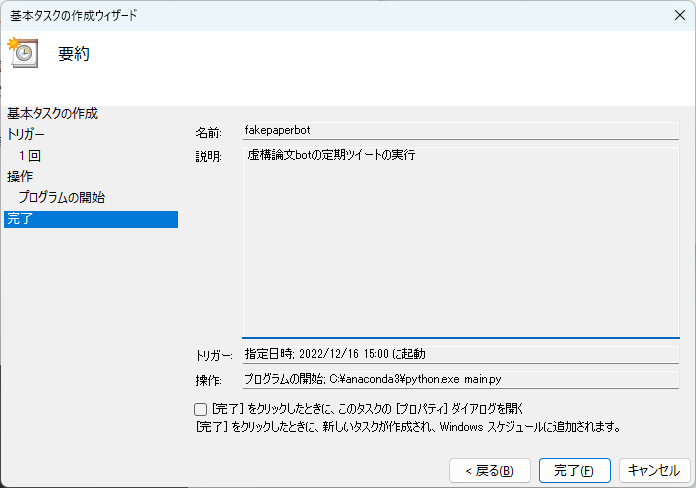
-
トリガーの変更
アクティブなタスクから、先ほど作ったタスクを探し、開きます。

プロパティから、
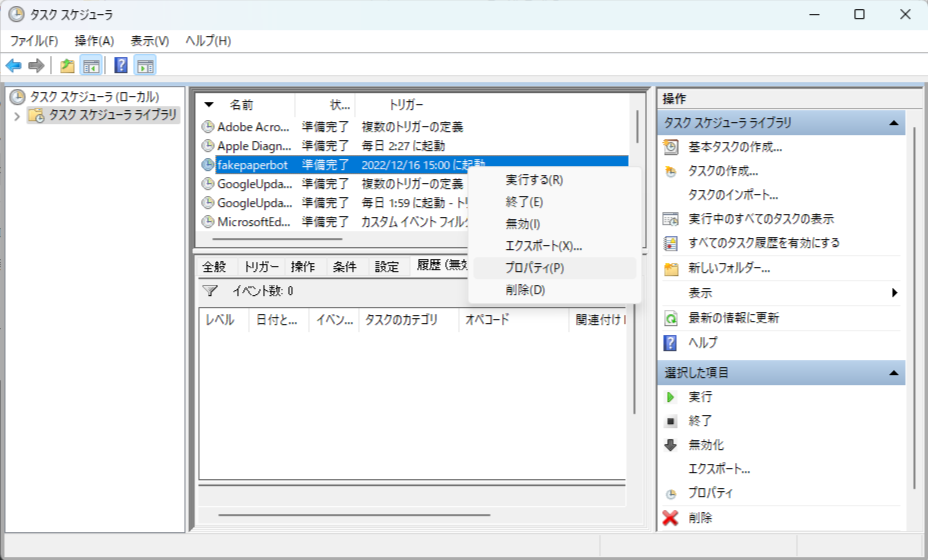
トリガーの編集を押し、

繰り返し間隔にチェックを入れ、1時間に指定、継続時間を無期限にしました。
また、開始時刻は直近で一番近い切りのいい時刻に設定しました。
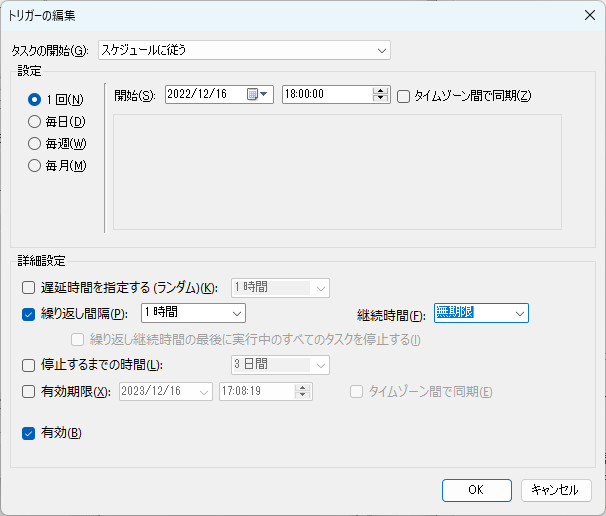
これで1時間置きに定期ツイートが実行されます。
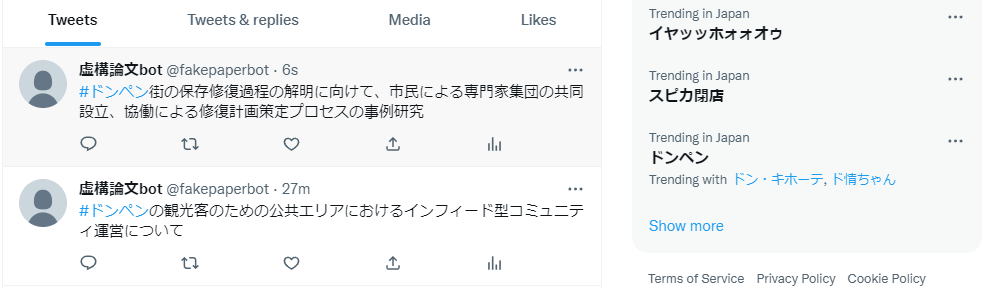
3. 結果
ちゃんと1時間置きに定期ツイートできていました!(今出先なので取り急ぎスマホのスクリーンショットでですが)

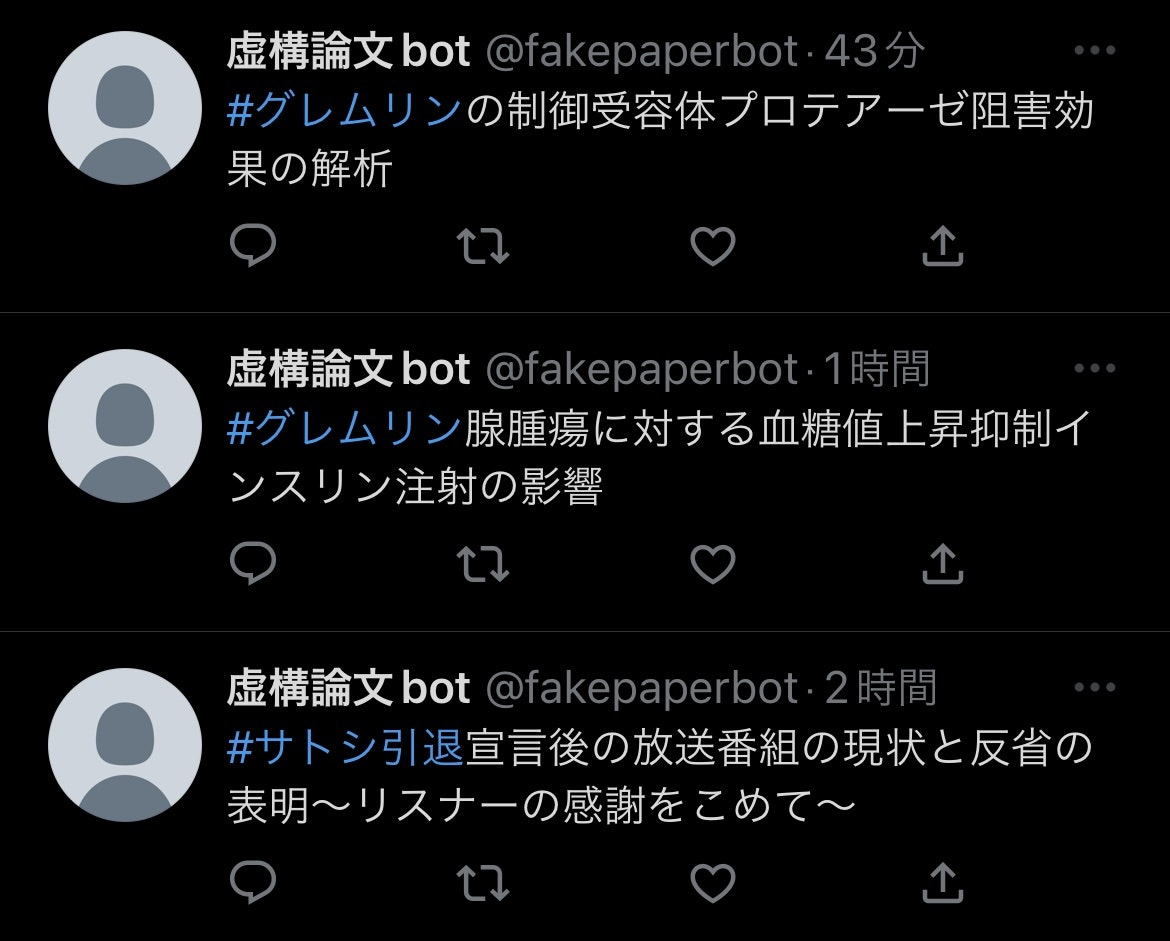
#サトシ引退に関しての出力は少し怪しい(というか明らかに論文っぽくない)ものもありますが、他はそれっぽくできていると思います。
このままこのbotは定期ツイートし続けるので、良かったらフォローしてみてください!
おわりに
今回は、GPT-2の日本語事前学習モデルに、CiNiiからスクレイピングして集めた論文タイトルでファインチューニングして、ツイッターのトレンドの単語から論文タイトルを生成してツイートするbotを作ってみました。
モチベが出た時にちまちま進めていたので、完成するのにすごく時間がかかりましたが、一応完成できてよかったです。
また、記事を書くのも初めてだったので、要領が掴めず、Advent Calenderの日程をずらしたり前編と後編に分けたりしちゃいましたが、ちゃんと書ききれてよかったです(これを記入しているのは記事公開日)。
今回はrinnaのsmallを利用しましたが、今度はmediumを、より多くの論文タイトルでファインチューニングできたらいいなと思っています。
モデルと虚構論文botはずっと公開しているので、ぜひ遊んでみてください。
次回、GPT-3でツイッターのトレンドから論文を生成してみた!
追記
たまに画像のように、英単語を含むトレンドに#とゼロ幅スペースを付与できないことがあります。
原因が分からないため、有識者の方が入れば教えていただきたいです。
よろしくお願いします。