はじめに
この記事は ちゅらデータ Advent Calendar 2021 14日目の記事です。
こんにちは!ちゅらデータで勉強させて頂いてます。Yokoです。
今日は最近、勉強がてら遊んでみたことを紹介していきます!
(初学者なもので、間違い多いかもです。ごめんなさい><)
コードはこちらに置いてあります。
Google Colabにてやってみてください。(所要時間目安 20分)
なぜ作ろうと思ったのか。
僕の友達にY君という子がいるのですが、めちゃくちゃ天然で面白いんです。
毎日LINEをしていたいところですが、もうすぐ進学活動。。。
「もしかしたら、忙しくてLINEが直ぐに返ってこない日が来るかもしれない。」
今のうちに許可を貰い、第2のY君を作っておけば寂しくなくなるのでは?と思い、作ることにしました。
GPT-2とは!
2021年にrinna社が日本語の大規模言語モデルを公開し、話題となりました。
単語の組み合わせから、次の単語を予測していく言語モデルです。
BERTでは、前後の単語から隠された単語を予測するのに対し、
GPT-2は、予測する単語より前の単語から予測します。
そのため、文章生成タスクに用いられるようです。
注意!!
1. 安易にBotやモデルを公開してはいけない!
- LINEのチャットデータには個人情報が含まれます。
- そのデータによって作られたモデルにも個人情報が入っています。
- 全部削除できる自信が無いなら個人使用に留めましょう。
2. 許可は取りましょう。
- Y君は「ええよw」と言ってくれましたが、みんながみんな、快く思ったりしているわけではありません。
3. クラスの女子にバレないようにする。
- Y君Botで遊んでいることがバレると引かれます(ました)。
モデルの作成
今回は、この記事を参考にGPT-2をファインチューニングしてモデルを作成しました。
わかりやすく、大変参考になりました。ありがとうございました。
1. LINEのトークデータをダウンロード
スマホでトーク画面を開き、右上の三本線から、
"その他" > "トーク履歴を送信"
AirDropや、メールなど、任意の方法でtxtファイルをPCに送ってください。
2. 学習用データの整形
以下の形に整えます。
GPT-2が、次のセンテンスを予測していきます。
そこで、入力文と出力文を学習させ、入力文から出力文を予測できるようにします。
<s>入力文(私)[SEP]出力文(Y君)</s><s>...
今回、Y君から送られてきたURLや、スタンプ、写真データなどは学習から省きました。
(僕からスタンプなどが送られたときには反応する様に、残してあります。)
# ・・・
# 送信取り消し(英語の場合)
elif "unsent a message" in line:
pass
# 電話
elif "Missed call" in line:
pass
elif "Canceled call" in line:
pass
elif "Call time" in line:
pass
# ・・・
※↑ここの部分、私の場合、英語表記となっていましたが。整形時に確認し&適宜変更してください。
注意点としては、データが足りないと感じたので、最期に、
txt = "".join(tmp) * 2
をしてデータをかさ増ししています。
これにより、同ディレクトリ内にgpt2_train_data.txtが生成されます。
3. ファインチューニング
今回は、先程も紹介した記事の通りにファインチューニングしました。
こちらの記事が大変わかりやすいので、割愛させていただきます。
※変更点としては、りんなちゃんの学習済みモデルを mediumではなく、smallを使用しました。
(GPUメモリと学習時間の問題で。)
transformerのサンプルコードをクローン & チューニングしました!
!git clone https://github.com/huggingface/transformers.git
!pip install sentencepiece
!pip install datasets
!python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-small \
--train_file=drive/MyDrive/ColabNotebooks/qiita/gpt2_train_data.txt \
--validation_file=drive/MyDrive/ColabNotebooks/qiita/gpt2_train_data.txt \
--do_train \
--do_eval \
--num_train_epochs=10 \
--save_steps=10000 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--output_dir=drive/MyDrive/ColabNotebooks/qiita/output/ \
--use_fast_tokenizer=False
(GPU使い、4分程度で終わっちゃいました。早い。。。)
4. 応答確認
# 返事を生成する関数
def generate_reply(inp, num_gen=1):
input_text = "<s>" + str(inp) + "[SEP]"
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
out = model.generate(input_ids, do_sample=True, max_length=64, num_return_sequences=num_gen,
top_p=0.95, top_k=20, bad_words_ids=[[1], [5]], no_repeat_ngram_size=3)
print(">", "あなた")
print(inp)
print(">", "Y君")
for sent in tokenizer.batch_decode(out):
sent = sent.split('[SEP]</s>')[1]
sent = sent.replace('</s>', '')
sent = sent.replace('<br>', '\n')
print(sent)
model.generate() 部分の引数が、生成する文字のバライティー性を請け負っているので、軽く説明します。
- top_p:サンプリング時、単語の確率に制限をかける。
- top_k:サンプリング時、単語の確率上位に制限をかけて絞り込む。
- bad_words_ids:NGワードを設定。ここでは、
[SEP]と<s>が出てこないように。 - no_repeat_ngram_size:繰り返しの単語が出ないように。
結果
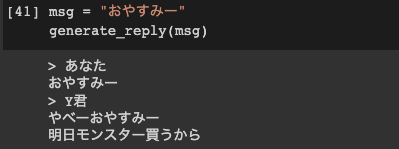
(1) 寝る前から魔剤の接種宣言。
普段からカフェインを摂りまくっているのがしっかり出ています。
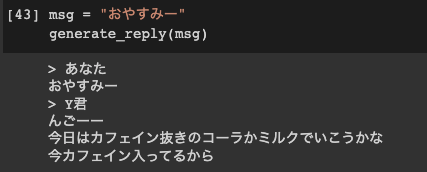
(2) カフェイン抜きのコーラかミルク
いつもはどんな飲み物を飲んでいるのでしょうか。気になります。
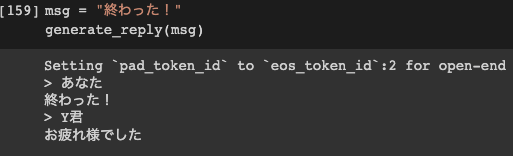
(3) 完成の報告
ありがとう!
まとめ
今回は「とりあえず作ってみよう!」という感じだったので、後でゆっくりエポック数やデータ数、処理方法を再検討してみようと思います。
やはり「百聞は一見にしかず」で、実際に遊んでみてが理解が進みました!
smallなら最短10分ほどでできてしまうので、実際に動かしてみてはいかがでしょうか。
次回予告!
「GASでサーバーレスのY君LINEBot作ってみた。」
参考にしたサイト
- GPT-2をファインチューニングしてニュース記事のタイトルを条件付きで生成してみた。
- transformers - GitHub
- HuggingFace - ドキュメント
- 【LINE】トーク履歴はテキストで保存できる!方法と注意点をご紹介
- gpt2-japaneseの使い方 (2) - GPT-2のファインチューニング