
こんにちは。
本記事は NTTドコモ R&D AdventCalendar2021 の3日目の記事です。
本記事では,論文タイトルから学会流行をみつつ、タイトル生成をやってみたいと思います。
※記事は 2021/11 時点の内容です。
モチベーション
近年,機械学習の研究・技術の発展がめざましく,日々新しい情報が入ってきます。普段から学会に参加している方々は分野の研究・技術流行をご存知かと思います。しかし,先端研究・技術の社会実装が進むにつれて,普段は開発をやっている人や,新しいプロジェクトに取り組む人が,新しい研究分野に触れることが増えており,そのような方々は流れがわからないと思います。
先端研究・技術の流行を俯瞰する際に,サーベイ論文を眺めることも珍しくないと思います。ただ,特定の一分野に関するサーベイであって,分野の流行までは知ることは難しいんじゃないでしょうか。
手元に論文タイトルさえあれば,流行がわかるんじゃないか,というのが今回のモチベーションです。ということで,簡単に調べてみました。
対象ドメインと集めたデータ
今回は,言語処理学会を対象ドメインとし,webページで公開されている言語処理学会の過去5年分の年次大会の論文発表タイトルを活用し,流行がわかるか,みてみることにしました。
| 年度 | 収集した論文発表タイトルの数 |
|---|---|
| 2017 | 307 |
| 2018 | 332 |
| 2019 | 398 |
| 2020 | 397 |
| 2021 | 361 |
| 合計 | 1,795 |
流行の調査
今回は,タイトルに出現する名詞の,年度ごとの出現回数と合計スコアを算出し,流行ワードを出しました。
手順
- Sudachiの長単位(C)で単語分割し,連続する名詞の単語系列を抽出
- 抽出された単語の出現回数をカウント
- 年度ごとに出現回数を重み付けし,合計スコアを流行スコアとして算出。スコア上位単語の,年度ごとの出現回数の増減の確認
今回,古い年度に出現した単語は価値が下がる,という仮定のもと,出現回数に,年度ごとの重み付けを行いました。2021年度の流行スコアを1としたとき,1年古くなるごとに,以下のように値を小さくしました。それぞれの年度の出現頻度に,年度ごとの重み付けを行なったのち,5年分を合計し,流行スコアとして算出しました。流行スコアを算出するにあたり,名詞の長さが4以上のものを抽出しています。年度ごとの重みは以下の2パターンで試してみました。
| 年度の重み | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|
| 0.1 刻み | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
| 0.2 刻み | 0.2 | 0.4 | 0.6 | 0.8 | 1 |
※ あくまでも,今回の趣旨は,論文タイトルの文字情報から読み取るということなので,実際に論文の中身に基づいて調べた場合と結果が異なる部分があると思います。あらかじめご承知ください。加えて,今回は Sudachi の長単位分割結果に基づく名詞かつ、連続する名詞の単語系列を1単語とするカウントをしているため,「日米ニューラル機械翻訳」と「ニューラル機械翻訳」と「機械翻訳」は別物としてカウントしています。そこもご注意ください。
抽出結果
重み付け(0.1刻み)の場合のTOP20
| ワード | 流行(合計)スコア | 出現回数(2017) | 出現回数(2018) | 出現回数(2019) | 出現回数(2020) | 出現回数(2021) |
|---|---|---|---|---|---|---|
| ニューラル機械翻訳 | 42.7 | 8 | 11 | 18 | 12 | 5 |
| 分散表現 | 26.8 | 10 | 14 | 8 | 4 | 1 |
| BERT | 21.3 | 0 | 0 | 4 | 9 | 10 |
| 自動生成 | 19.5 | 7 | 4 | 6 | 3 | 5 |
| 機械翻訳 | 18.3 | 3 | 3 | 6 | 4 | 6 |
| アノテーション | 16.0 | 6 | 3 | 1 | 5 | 5 |
| 言語モデル | 14.0 | 2 | 0 | 4 | 4 | 6 |
| クラウドソーシング | 13.1 | 4 | 4 | 5 | 1 | 3 |
| 取り組み | 12.5 | 3 | 4 | 2 | 7 | 0 |
| 事前学習 | 12.2 | 2 | 1 | 1 | 5 | 5 |
| 単語分散表現 | 12.1 | 3 | 2 | 4 | 3 | 3 |
| 精度向上 | 10.9 | 2 | 2 | 2 | 3 | 4 |
| テキスト | 10.5 | 1 | 3 | 4 | 4 | 1 |
| Transformer | 10.2 | 0 | 0 | 2 | 4 | 5 |
| ニューラルネットワーク | 9.8 | 6 | 4 | 2 | 2 | 0 |
| コーパス | 9.4 | 2 | 3 | 4 | 1 | 2 |
| 文法誤り訂正 | 9.1 | 2 | 0 | 3 | 5 | 1 |
| 学術論文 | 9.1 | 2 | 1 | 3 | 2 | 3 |
| データ拡張 | 9.0 | 1 | 0 | 1 | 4 | 4 |
| Wikipedia | 9.0 | 2 | 1 | 4 | 1 | 3 |
重み付け(0.2刻み)の場合のTOP10
| ワード | 流行(合計)スコア | 出現回数(2017) | 出現回数(2018) | 出現回数(2019) | 出現回数(2020) | 出現回数(2021) |
|---|---|---|---|---|---|---|
| ニューラル機械翻訳 | 31.4 | 8 | 11 | 18 | 12 | 5 |
| BERT | 19.6 | 0 | 0 | 4 | 9 | 10 |
| 分散表現 | 16.6 | 10 | 14 | 8 | 4 | 1 |
| 機械翻訳 | 14.6 | 3 | 3 | 6 | 4 | 6 |
| 自動生成 | 14.0 | 7 | 4 | 6 | 3 | 5 |
| 言語モデル | 12.0 | 2 | 0 | 4 | 4 | 6 |
| アノテーション | 12.0 | 6 | 3 | 1 | 5 | 5 |
| 事前学習 | 10.4 | 2 | 1 | 1 | 5 | 5 |
| Transformer | 9.4 | 0 | 0 | 2 | 4 | 5 |
| 単語分散表現 | 9.2 | 3 | 2 | 4 | 3 | 3 |
重み付け(0.2刻み)の場合のTOP10について,グラフにしてみました。
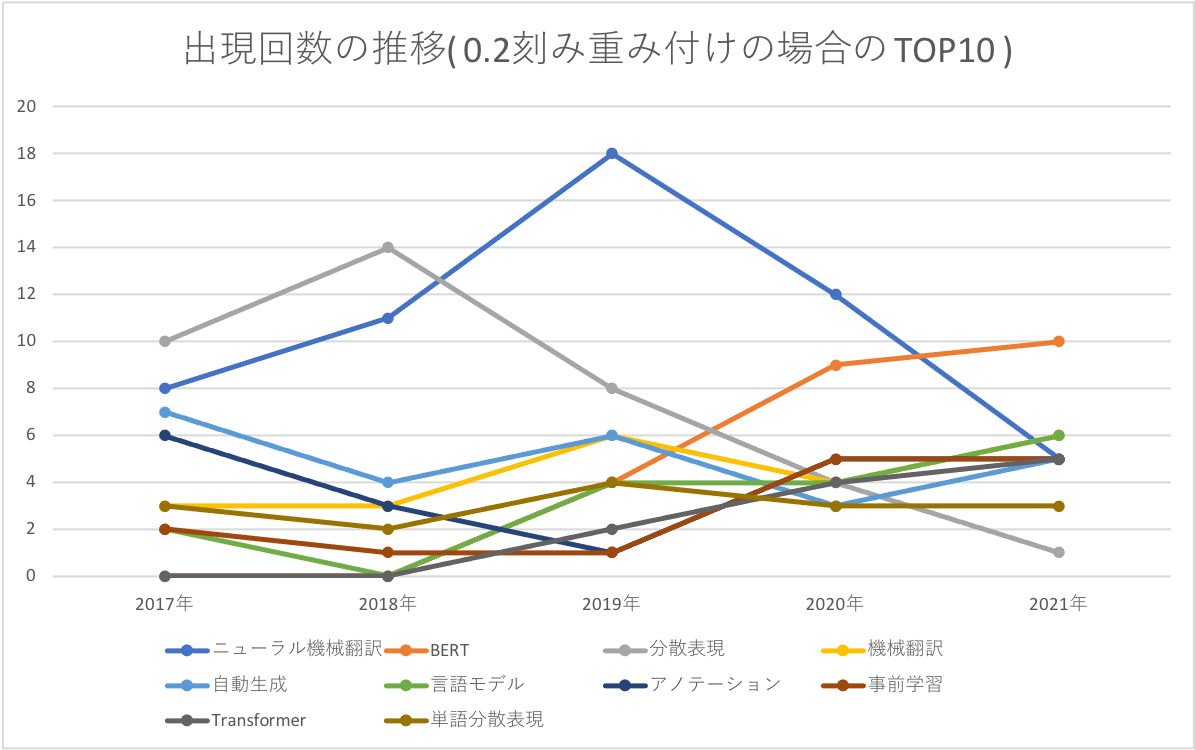
それっぽいワードが出現しました。せっかくなので,これら上位10ワードを,単純なキーワード抽出でも抽出し,カウントしてみましょう。
| ワード | 出現回数(2017) | 出現回数(2018) | 出現回数(2019) | 出現回数(2020) | 出現回数(2021) |
|---|---|---|---|---|---|
| ニューラル機械翻訳 | 8 | 14 | 25 | 17 | 7 |
| BERT | 0 | 0 | 4 | 20 | 16 |
| 分散表現 | 16 | 17 | 15 | 7 | 4 |
| 機械翻訳 | 17 | 21 | 39 | 28 | 20 |
| 自動生成 | 8 | 7 | 9 | 10 | 5 |
| 言語モデル | 5 | 5 | 6 | 8 | 10 |
| アノテーション | 11 | 4 | 4 | 9 | 9 |
| 事前学習 | 2 | 1 | 1 | 12 | 9 |
| Transformer | 0 | 0 | 4 | 5 | 9 |
| 単語分散表現 | 4 | 3 | 5 | 3 | 3 |
こちらもグラフにしてみました。多言語BERTを含む論文タイトルのBERT部分がカウントされ,BERTの出現回数が増加しました。加えて,ニューラル機械翻訳の機械翻訳や,単語分散表現の分散表現が部分一致となるため,その分もプラスでカウントされています。

やはり,機械翻訳と言語モデルに関するワードが上位に来ました。
ニューラル機械翻訳は2021年に下がってますが,関連ワード(機械翻訳・Transformer)が多いままなので,流行が続いていそうです。機械翻訳 = ニューラル機械翻訳という認識が広がったため,ニューラル機械翻訳ではなく,機械翻訳という単語だけを使うようになっている,というのも理由の一つかもしれないですね。
タイトルとしては,BERT と Transformer が同じ年に初めて出て来ていますね(Transformerは2017年,BERTは2018年に元論文が発表されています)。
BERT が起因しているのか,言語モデル・事前学習・データ拡張も2019,2020年から増えています(多分 ELMo とかも関係していると思いますが)。
逆にニューラルネットワークや分散表現は減ってますね。ニューラルを手法として使うことが当たり前になっているので,こちらも,わざわざタイトルに入れる必要がなくなったため,減っているのではないでしょうか。加えて,数年前までは,word2vec や fasttext など,分散表現だけを別で取り出して後段タスクに利用していましたが,最近では end2end のモデルが増えたためか,分散表現の出現頻度が大きく減っているみたいです(タイトルとして出現頻度が減っているだけで,今も様々な研究がおこわれています)。
上位ワードだけ見ると,最近の言語処理学会界隈の大きな流行は,機械翻訳・言語モデル・データ作成(生成),といったところでしょうか。
ワードのピックアップ紹介
-
ニューラル機械翻訳/Transformer
ニューラル機械翻訳(ニューラルネットワークを用いた言語処理)の登場により,言語処理タスクの精度は飛躍的に向上しました。その中でも,もっとも恩恵を受けたのが機械翻訳分野でしょう。皆さんも翻訳サービスを利用する中で実感しているかと思います。加えて,モデルやデータのオープンソース化が進んだことで,研究にも参入しやすくなり,上位に入っているものだと思われます。 -
BERT/言語モデル/事前学習
近年,大規模言語モデルに関する研究がかなり増えました。現在に至るまで,さまざまな派生亜種が生まれているものの,デファクトとなっているのは,やはり BERT でしょう。BERT は Transformer のエンコーダ側のアーキテクチャを持つモデルで,後段の言語処理タスクの精度・性能を飛躍的に向上させました。最近では,多言語の事前学習済みモデルがオープンソースとして配布されています。ライブラリとしては,Transformers が有名ですね。 -
自動生成/データ拡張
大規模事前学習済み言語モデルが,誰でも利用できるようになり,それらを活用して,汎用ドメインの学習データの自動生成によるデータ拡張をおこなったり,少量の対象ドメインのデータでファインチューニングすることで,対象ドメインのデータ拡張をする研究なども増えました。 -
アノテーション
事前学習済みの言語モデルからの自動生成で得られるデータは,あくまでも擬似的な学習データであり,学習していないドメインのテキストがうまく生成される保証はありません。そのため,対象ドメインの高品質なテキストデータや,高度なタスクの学習データを生成することが難しいこともあります。そのようなタスクのデータをクラウドソーシング等で収集し,整備してデータセットとして公開する研究なども増えています。2017年から,学会で言語資源賞が設立されて,表彰されています。何かのモデルを作ったり,評価するには,データがないと始まりませんからね。
タイトル生成モデルを作ってみよう
今回,せっかく論文タイトルを集めたので,GPT-2(日本語事前学習済みモデル)をファインチューニングしてみます。
去年,英語でファインチューニングした記事を参考にしつつ,同じような感じで学習データを加工します。今回は,ドメイン文の識別と,論文タイトル特有の,体言止めの識別を期待し,論文タイトルの前後に特殊トークンを付け足してみました。
日本語の事前学習済みの GPT-2 は Transformers で利用可能な rinna の 事前学習済みモデルがあり,こちらのモデルを利用させていただきました。
日本語のファインチューニングの手順は,こちらの記事を参考にさせていただきました。
ファインチューニング
以下のコマンドでファインチューニングを実行しました。
今回,ファインチューニング用の学習データが少ないので,紹介されていた手順のままでは学習がうまく進まないので,実行コマンドの引数を変更しました。具体的には,モデルサイズ(一番小さい xsmall を利用),学習率(少し大きく),エポック数(増やす)を変更しました。これによって,少ないデータでも多少はファインチューニングされるようになりました(もちろん,これら以外にも工夫・方法があると思います)。
1点,日本語モデルを動かす際の注意として,通常の設定では英語アルファベット大文字は 未知語( <unk> )
扱いになるので,run_cls.py の T5Tokenzer への変更はもちろんのこと, tokenizer.do_lower_case = True は絶対にお忘れなく。こちらの記事に記載されているように,同じ轍を踏んではならない…(先人に感謝)
python transformers/examples/language-modeling/run_clm.py --model_name_or_path=rinna/japanese-gpt2-xsmall --train_file=./data/train.txt --validation_file=./data/valid.txt --do_train --do_eval --num_train_epochs=10 --save_steps=5000 --save_total_limit=3 --per_device_train_batch_size=2 --per_device_eval_batch_size=2 --output_dir=./output/ --use_fast_tokenizer=False --learning_rate 2e-3
ファインチューニングモデルを用いた文生成
以下 generate.py としてスクリプトを作成して実行するか,transformers/examples/text-generate/run_generation.py の中身をいじりましょう。
こちらも tokenizer.do_lower_case = True をお忘れなく
from transformers import T5Tokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
dokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("output/")
# 推論
words = "事前学習" # 入力系列。用意されていない特殊トークンを自分で決めて学習した場合は、特殊トークンをこちらにも入れることになると思います。
input = tokenizer.encode(words, add_special_tokens=False, return_tensors="pt")
output = model.generate(input, do_sample=True, num_return_sequences=4, stop_token="") #stop_token は,明示的に学習させているならつける。
print(tokenizer.batch_decode(output))
タイトルの生成結果
-
事前学習を入れて生成された一例
事前学習とは何か? _ 談話特徴間の関係分析の試み
事前学習者コーパス構築の検討
事前学習済みモデルのソースコードの精度向上を目指した
事前学習した化合物名を用いた化学ラベリングモデルを利用した超球面上への自然
事前学習済み文生成手法の検討
事前学習モデルを用いた単語辞書アノテーションの品質推定
事前学習による単語埋め込みコーパスの構築
事前学習モデルを用いた質問応答生成モデルの有効性検証
-
ニューラル機械翻訳を入れて,生成された一例
ニューラル機械翻訳におけるリランキング
ニューラル機械翻訳のための機械翻訳の自動評価
ニューラル機械翻訳における文字情報を識別可能な固有表現の検出手法の検討
ニューラル機械翻訳の品質チェックのための学習済みデータセット
ニューラル機械翻訳における問題検出
ニューラル機械翻訳における未知語処理の省略と気遣いの豊富さ
ニューラル機械翻訳のための高性能な文法誤り訂正データセット
ニューラル機械翻訳におけるタグなしフレーズのカテゴリ推定手法の提案
-
Transformerを入れて,生成された一例(大文字が lowercase されます)
transformerによる日本語学習者のための日本語文法誤り訂正のための発話の日
transformerによる翻訳・翻訳の品質の推定
transformer を用いた分散表現を用いたニューラル機械翻訳
transformer-auto
transformerを導入したマルチエージェントモデルの構築
transformerを用いた文書作成における日本語単語クラスタリング
transformer questions indones in fine-sequence
transformerによる日本語文章からの音声ドキュメント抽出
-
BERTを入れて,生成された一例(大文字が lowercase されます)
bertに基づく構文解析データの学習および分析
bertを用いた対話システムの改善
bertを用いた日本語文法誤り訂正モデルの検討
bertによる日本語固有表現抽出手法の検討
bertによるbert 翻訳における日本語固有表現に対する語彙表作成
bertの学習モデル
bertによる分散表現を考慮した単語分割の類似性に基づく単語分散表現を考慮した語・並び
bertの脳活動推定によるニューラルネットワーク
-
ドコモを入れて,生成された一例
ドコモオンライン掲示板におけるユーザー投稿の発話順序に関するツイート評価の検討
ドコモオンライン百科辞典
ドコモの決算報告書からの事業セグメント予測に向けたアノテーション―
ドコモの契約書の読みやすさの比較
ドコモオンラインで利用可能なテキストフレームの有用性検証
ドコモメールからのマルチタスク翻訳システム
- "論文タイトルっぽい"文が生成されました。もちろん,学習データが少ないため,おかしな文も散見されます。
- 逆転の発想で,言語モデルに生成させたタイトルから,どんな研究内容なのかを想像してみると,新しい研究アイディアに繋がったりするかもしれませんね。
- 最後の例では,ファインチューニングの学習データとして入れていませんが,
ドコモを入力してみました。ドコモを使いながら,言語処理の論文タイトルっぽくなってますね。
まとめ
- 論文タイトルに出現する名詞から,学会流行を簡単に眺めてみました。
- 論文タイトルで GPT-2 をファインチューニングし,タイトル生成してみました。
- 日本語の事前学習モデルを使うときには,設定にも注意しましょう(重要!)。
参考文献・サイト
言語処理大会年次大会
SudachiPy
Transformers(HuggingFace)
日本語事前学習済みGPT-2モデル
日本語GPT-2の学習方法
日本語GPT-2を使って「小説家になろう」に掲載されていそうなタイトルを生成してみた
GPT-2のファインチューニング(去年のアドベントカレンダーの記事)
WordCloud(TOP画作成のためにのみ利用。普段は使わない派です。)
その他所感
- 最近は,BERT をはじめ,言語処理技術の社会実装が進んできたなと思うことが増えてきました。
- 知の高速道路を整備してくださっている方や,たくさんの情報に感謝しながら,自分も役立つ楽しいものを作っていきたいなと思います。