最近、バイブコーディング(Vibe coding)「AIに指示を出してコードを書いてもらうこと」を色々と試みています。
どうせやるならノーコードでより便利に!
ということで、バイブコーディング(Vibe coding)で生成したコードにノーコード/ローコードプラットフォームであるDifyを組み込んで活用してみました。
今回は、ウェブ検索、ナレッジデータの作成~利用についての記事になります。
LLMへの質問に対する返答は、結構まちがっていることも多く、今回はより正確性を高めるため、ウェブ検索を最初に行い、その結果をLLMにまとめてもらうという形にしました。
作成手順
1. Difyをはじめる
開始するにあたっての記事は沢山あるので、ここでは詳細な説明は割愛します。
はじめかたの大まかな流れ
1. Difyの公式HPを開く
2. 任意の方法でログイン
3. 初期設定を行う
①ワークスペース名と言語
②LLMのモデル(OpenAIとかGeminiとか)選択、APIキー取得・登録
以下の記事がよくまとまっていると思います。
Dify入門ガイド:チャットフローでRAGを実装
https://note.com/weel_media/n/na550526d8985
この記事内の、
ログイン後に必須!初期設定でやるべき3つのこと の
「2. AIの頭脳となる「APIキー」を登録する」 にて、OpenAIを利用していますが、Geminiの方がお勧めです(無料枠が多い)。
☛右上の検索窓へ「gemini」と入力し検索、geminiを選択しインストール。
(以下の記事を参照)
APIキーを取得して張り付けて登録するのは、どのモデルでも同じです。
Dify に AIモデル(Gemini)を設定する
https://qiita.com/b-wind/items/f45afb8a0cb4a43a1f60
2. ウェブ検索の設定
ウェブ検索「Serper」を使えるようにする
検索サービスはGoogle、その他ありますが、今回は、調べる限り一番検索機能が安定してそうな「Serper」を利用します。
①DifyにSerperをインストール
②Serper APIを取得
③DifyのSerperへ、Serper APIを登録する
①DifyにSerperをインストール
Difyのページで、上部の「ツール」をクリックし、ツール一覧の画面を表示。
以降、流れに従い、インストールします。

②Serper APIを取得
Serper APIを使うにはアカウントを作成します。
Serperサイト:https://serper.dev/
●右上の「Sign up」をクリック

●Sign upを選択すると以下の画面になるので、必要情報を入力後、メールが届きます。

●届いたメールに記載されているURLをクリックすると、Playgroundのページに遷移するのでこれで登録は完了です。
●ダッシュボードを開き、左側メニューのAPI keysを選択
●右上の「+ Create New Key」ボタンをクリック

●Key Nameを入力し、「Create」ボタンをクリック
●作ったAPIキーをコピー(右側のボタンをクリックしてクリップボードへコピー)
③DifyのSerperへ、Serper APIを登録する
●Difyの画面に戻り、「ツール」画面を表示、インストールされている「Serper」をクリック
●右側に小画面が現れるので、「APIキー認証設定」ボタンをクリック
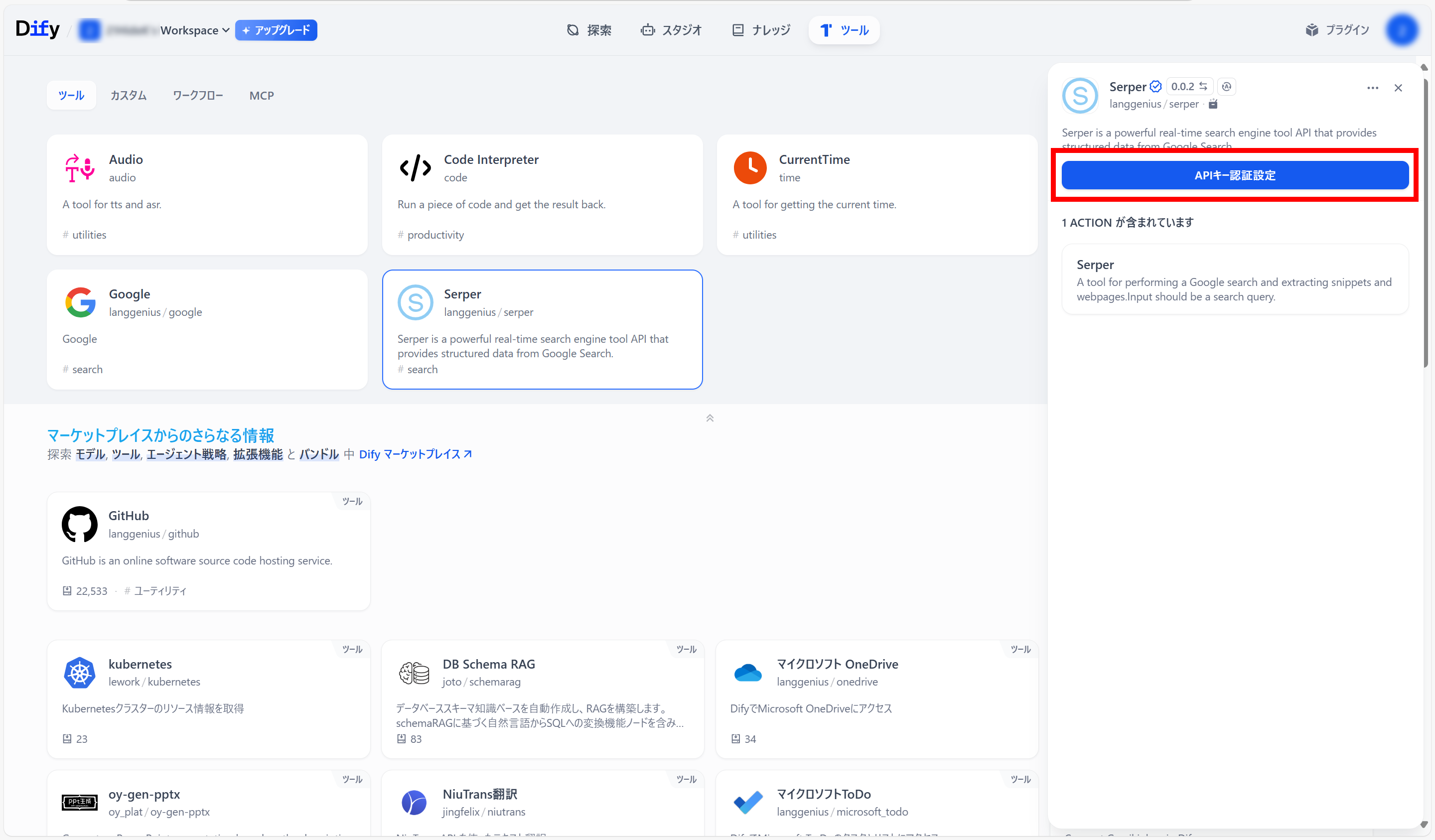
●認証名、Serper API keyを入力し、「保存」ボタンをクリック

これで、Serper(ウェブ検索)の準備はできました。
3. ナレッジデータの登録、利用設定
①データの入ったCSVファイルを用意
②ナレッジデータのキーワードを編集
③Difyの知識検索ブロック前のLLMにローマ字変換のプロンプトを登録
①データの入ったCSVファイルを用意
●以下のようなデータの入ったCSVファイルを用意します。

②Difyのナレッジへ登録
●Difyのナレッジのページを開く。

●作成したCSVファイルをドラッグ&ドロップ。
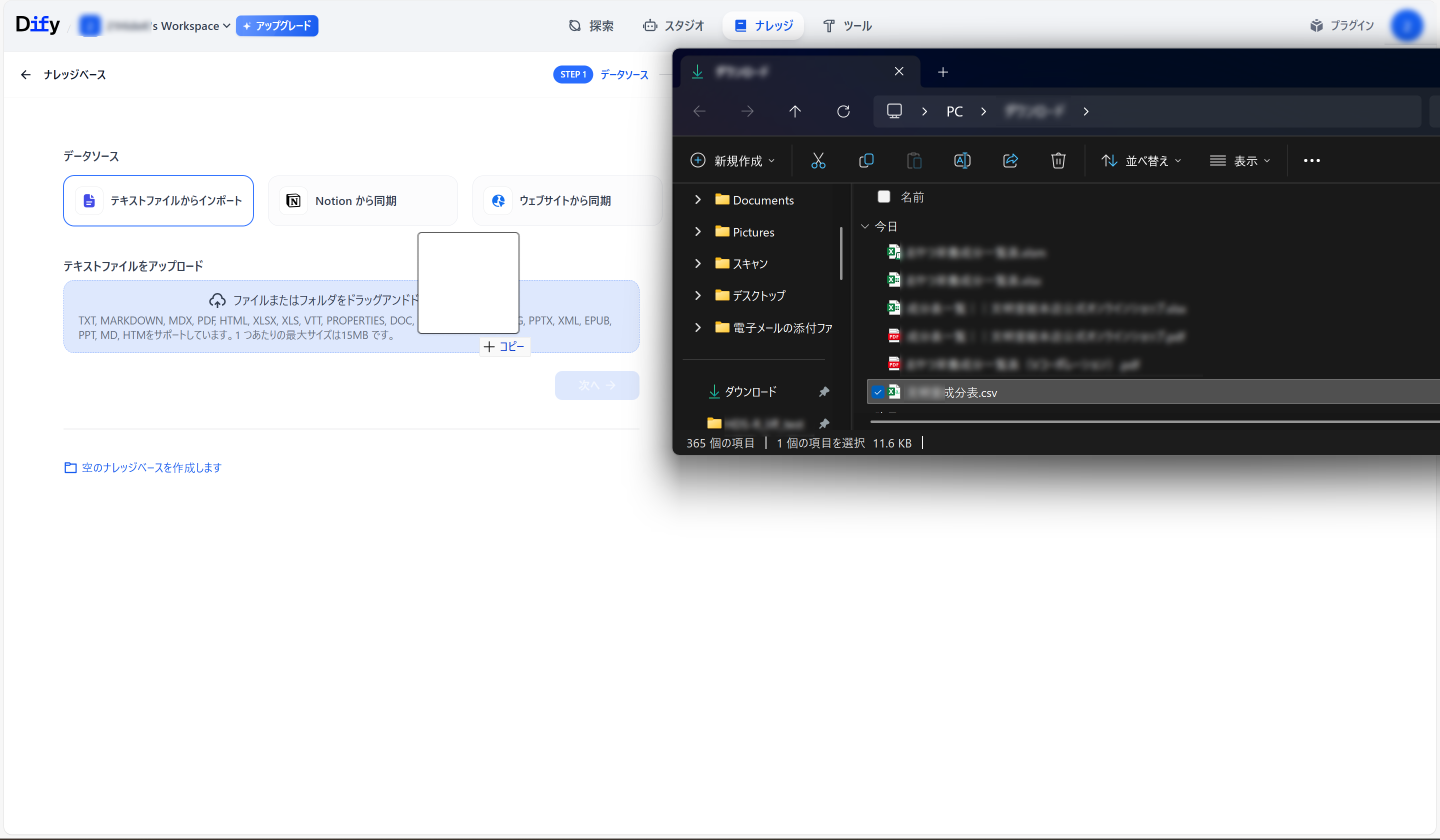
●ファイルがアップロードされたことを確認し、「次へ」をクリック
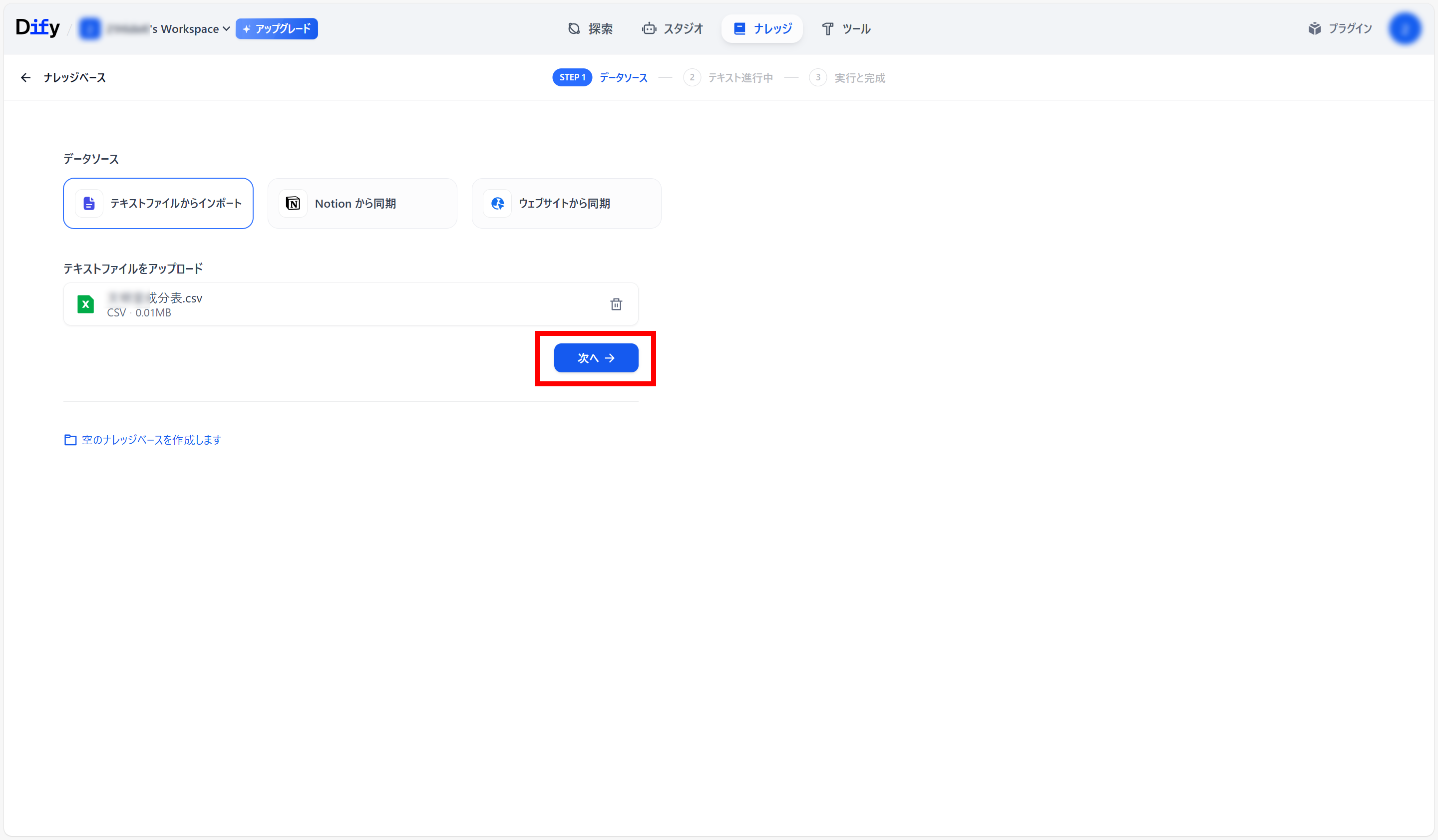
●インデックス方法は、簡単な検索であれば「経済的」で十分。
「高品質」は、無料枠があるが、それを超えると、cohere APIを取得し有料となる。
●「チャンクをプレビュー」をクリックし、右側のプレビューを確認
●「保存して保存」をクリック

【つまづきポイント1】
(詳細と対応方法は、最後に記述しています)
Difyのナレッジデータへの検索は、
〇:アルファベット、漢字
✖:ひらがな、カタカナ
4. フローをつくる
今回は、作成するフローは、以下の形になります。
入力された検索ワードに対し、
① ウェブ検索をして必要な情報を取り出す
② 自分で作成したナレッジデータを検索し
必要な情報を取り出す
③ ①, ②の情報を統合して、最後に出力する
①の流れ
「ウェブ検索」
↗ ↘ ③の流れ
「開始」 「LLM」→ 「終了(出力)」
↘ ②の流れ ↗ (情報を統合し出力)
「知識検索」

① ウェブ検索をして必要な情報を取り出す
以下の部分のフローを作成します。
●Difyの「スタジオ」画面を開き、左側の「アプリを作成する」内の「最初から作成」をクリック。

●開いた画面に情報を入力
アプリタイプ:ワークフロー
アプリのアイコンと名前:お好きな名前を付けてください
「作成する」をクリック

●「開始」ブロックをクリック
右側に開いた画面の、入力フィールドの右側の「+」をクリック

●開いた画面に情報を入力
入力タイプ:短文
ラベル名:お好きな名前
「保存」をクリック
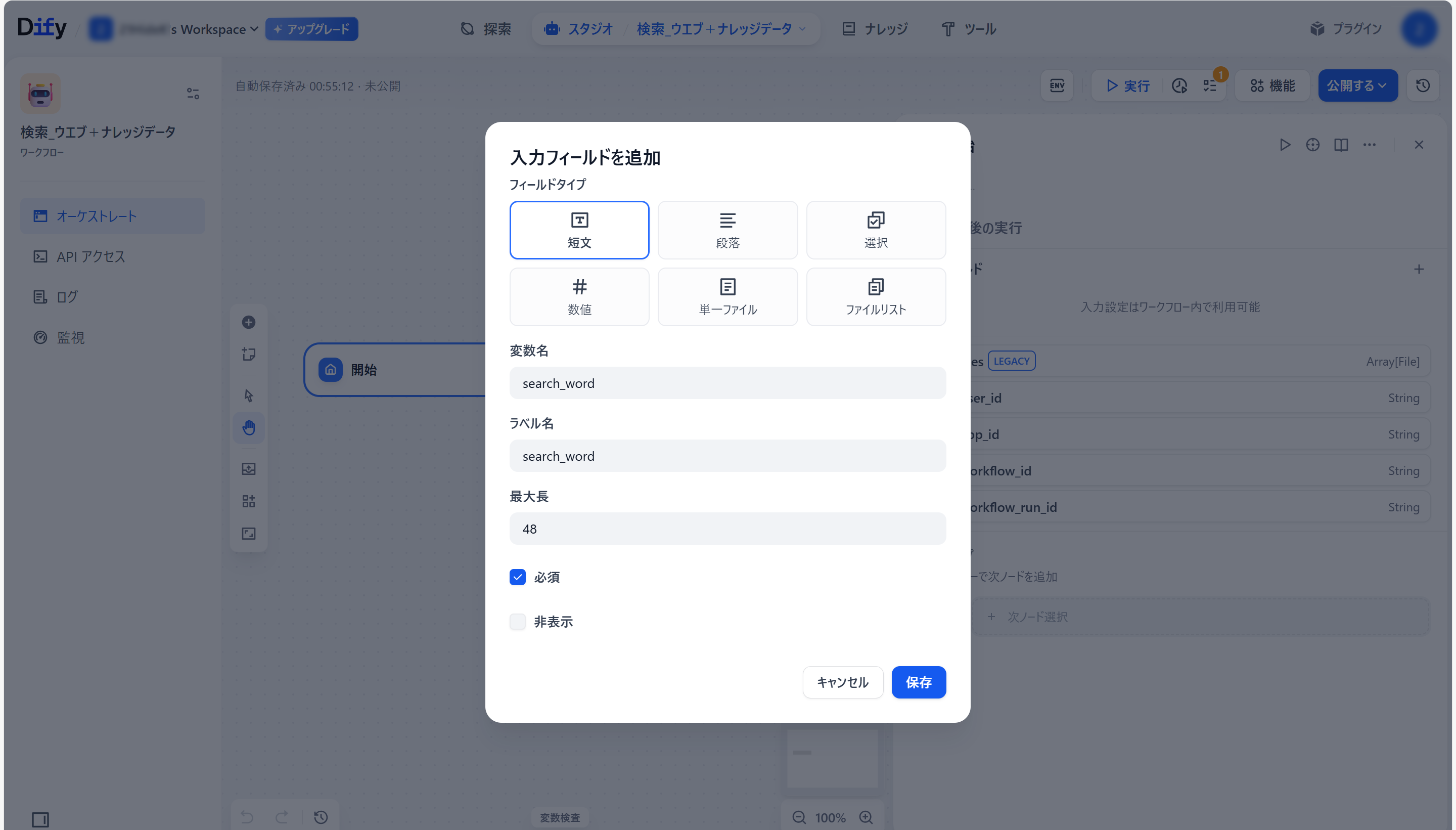
●「開始」ブロック右側の「+」をクリックし、現れたメニュー内の「LLM」をクリック(「LLM」ブロックを作る)。

●作成された「LLM」ブロックをクリックし、設定する。
入力モデル:Gemini 2.5 Flash-Lite(お好きなものを)
コンテキスト:開始/search_word
SYSTEM(プロンプト):
以下の形式で出力してください。
開始/search_word 成分 アレルギー
USER(プロンプト):{開始/{x}search_word}
※注 2025年9月上旬より、この「USER」枠を作成しキーワードを
入力しないと、LLMは動かなくなりました(Geminiだけ?)
※開始/search_wordは、枠内の{x}をクリックし、その中から選択。
尚、LLMのトークン消費がもったいないという方は、「コード入力」ノードで十分対応できます(多少コードが書ける方)。
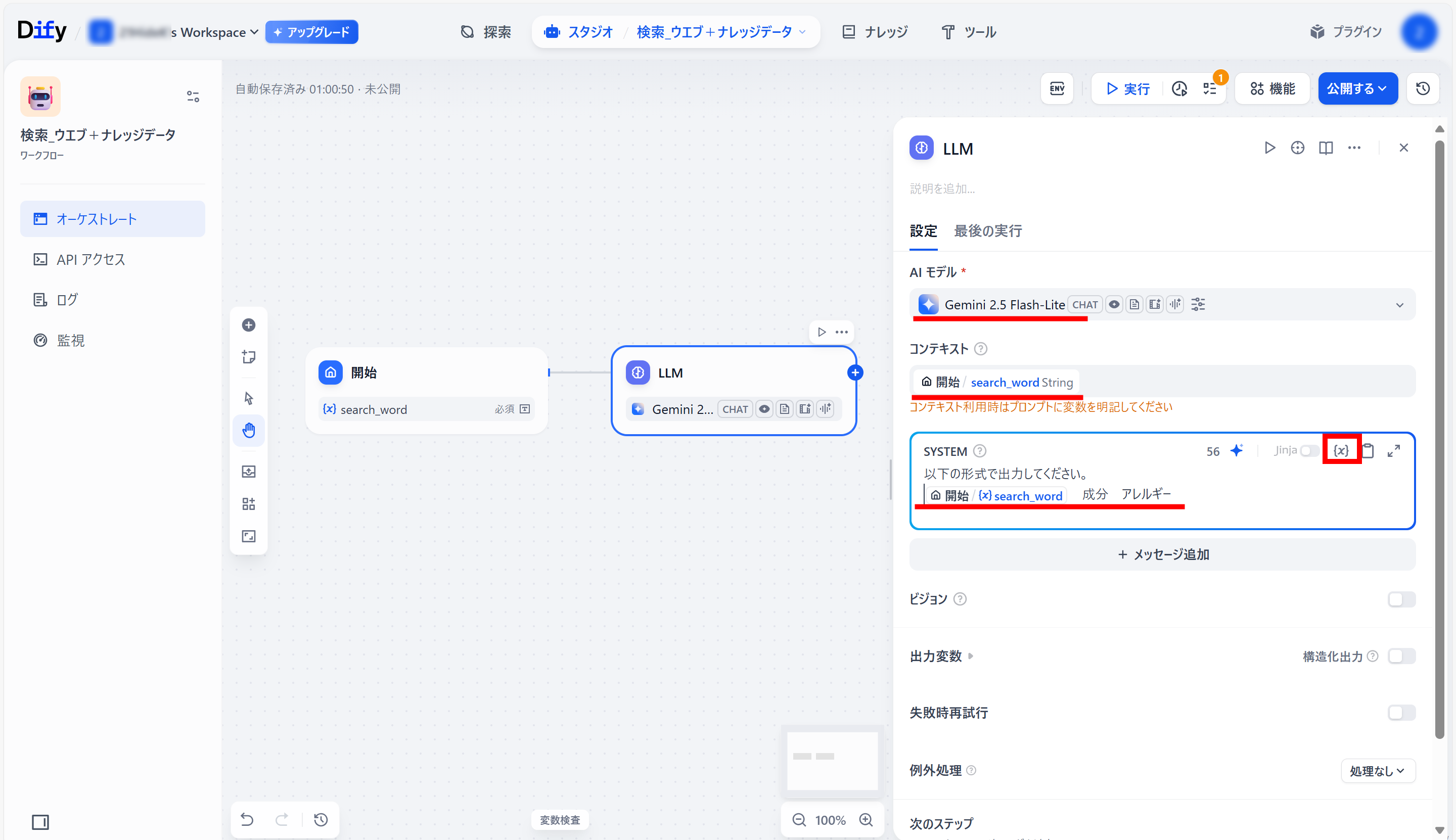
●「LLM」ブロック右側「+」メニューの上部の、「ツール」をクリック
「Serper」をクリックし、更に現れた「Serper」をクリック
(「Serper」ブロックを作る)

●「Serper」ブロックの設定をする
入力変数:LLM/{x}text

●「Serper」ブロック右側「+」メニューの、「テンプレート」をクリック(「テンプレート」ブロックを作成)
●設定 入力変数:{x}Serper/ json Array[Object]
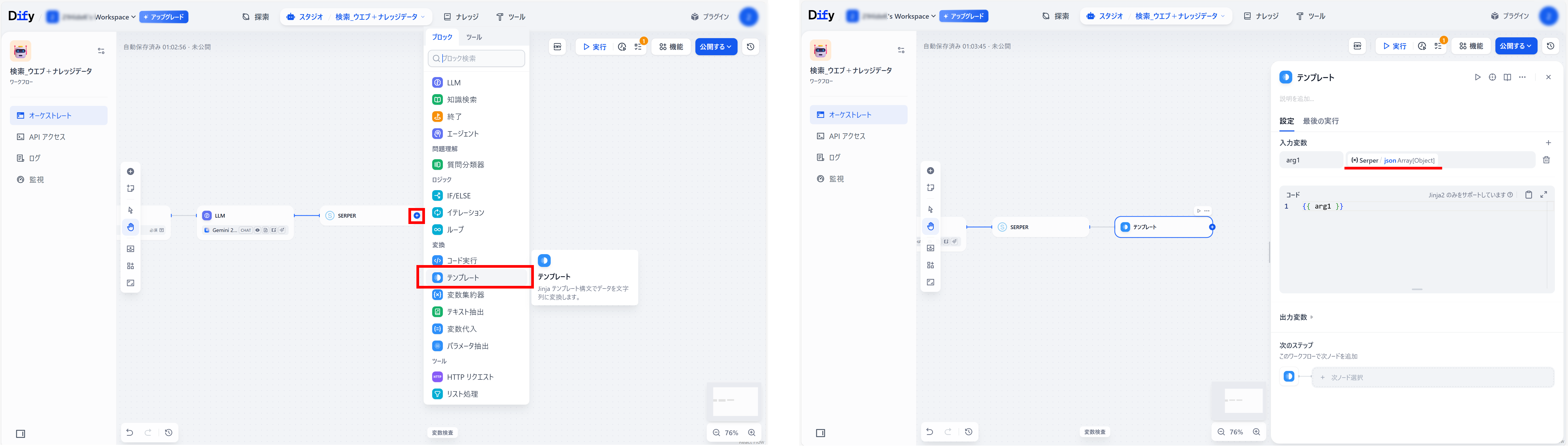
【つまづきポイント2】
検索ブロック(SerperでもGoogleでも)で得られた結果は、テキスト化しないと、次のLLMでは読み込めない。
「テンプレート」ブロックでテキスト化することにより利用できる。
② 自分で作成したナレッジデータを検索し必要な情報を取り出す
以下の部分のフローを作成します。

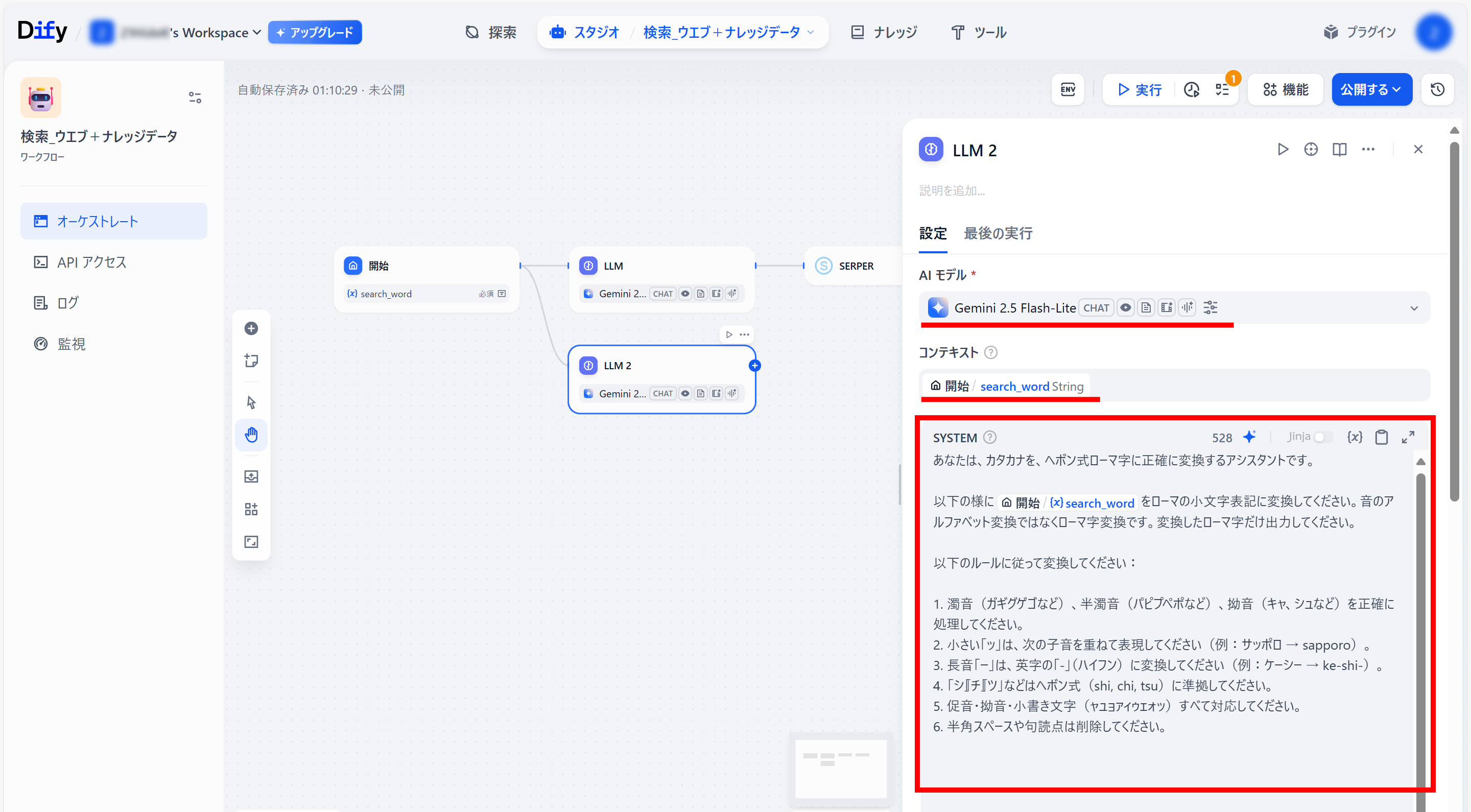
●「開始」ブロックに戻り、右側「+」メニューより「LLM」をクリック(「LLM 2」ブロックを作成)

●「LLM 2」ブロック設定
AI モデル:Gemini 2.5 Flash-lite
コンテキスト:開始/search_word String
SYSTEM(プロンプト):以下のプロンプト
USER(プロンプト):{開始/{x}search_word}
※注 2025年9月上旬より、この「USER」枠を作成しキーワードを
入力しないと、LLMは動かなくなりました(Geminiだけ?)
Difyの知識検索ブロック前のLLMブロックへ登録するプロンプト
あなたは、カタカナを、ヘボン式ローマ字に正確に変換するアシスタントです。
以下の様に{ここにDifyで変数「開始/search_word」を入れる}をローマの小文字表記に変換してください。音のアルファベット変換ではなくローマ字変換です。変換したローマ字だけ出力してください。
以下のルールに従って変換してください:
1. 濁音(ガギグゲゴなど)、半濁音(パピプペポなど)、拗音(キャ、シュなど)を正確に処理してください。
2. 小さい「ッ」は、次の子音を重ねて表現してください(例:サッポロ → sapporo)。
3. 長音「ー」は、英字の「-」(ハイフン)に変換してください(例:ケーシー → ke-shi-)。
4. 「シ」「チ」「ツ」などはヘボン式(shi, chi, tsu)に準拠してください。
5. 促音・拗音・小書き文字(ャュョァィゥェォッ)すべて対応してください。
6. 半角スペースや句読点は削除してください。
上手くいかないときは、色々と工夫してみてください。また、Difyにはプロンプト作成を頼む機能もあります。
尚、LLMのトークン消費がもったいないという方は、「コード入力」ノードで十分対応できます(コードが書ける方)。
●「LLM 2」ブロック右側「+」メニュー内の「知識検索」をクリック(「知識検索」ブロックをつくる)
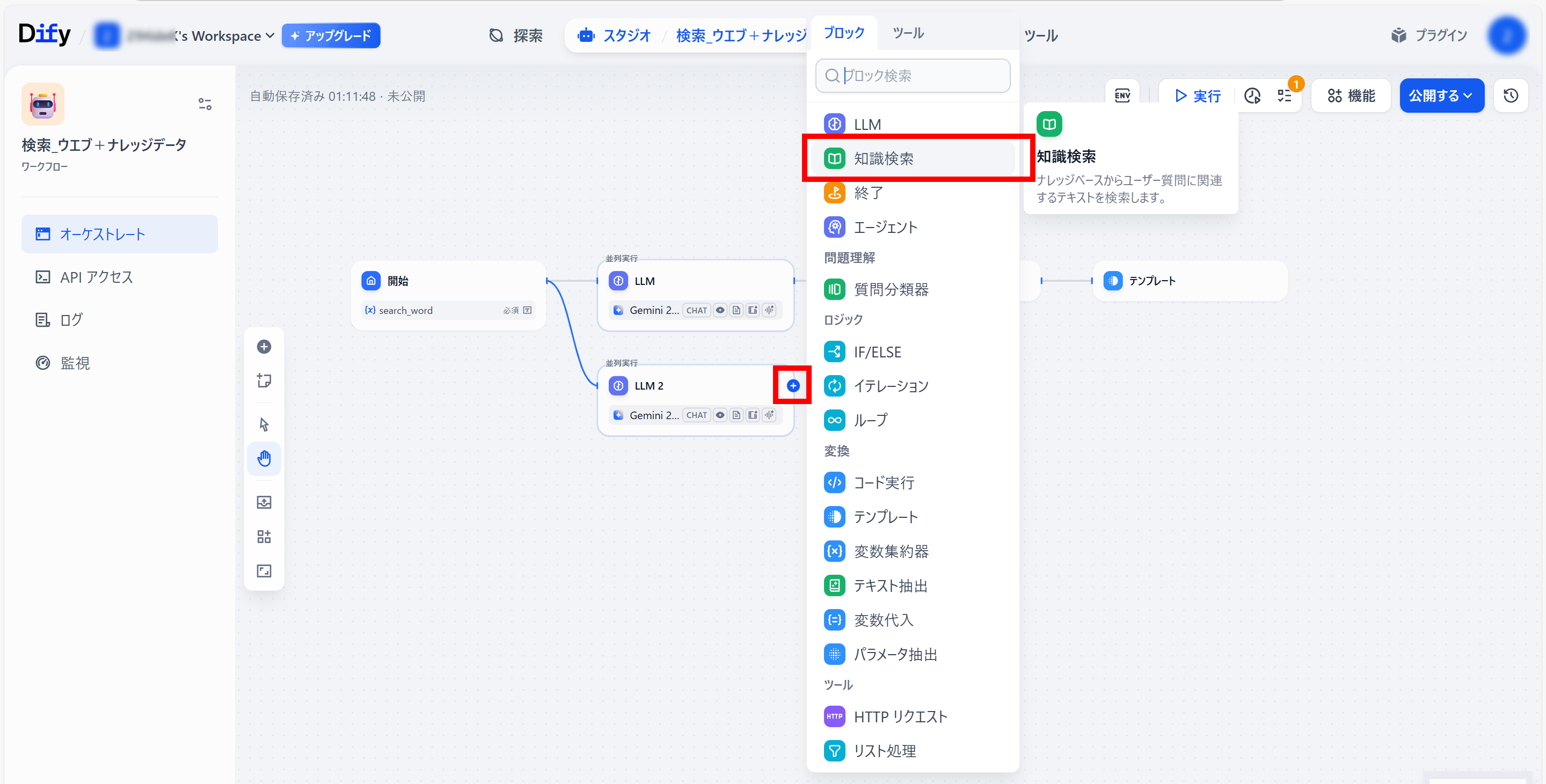
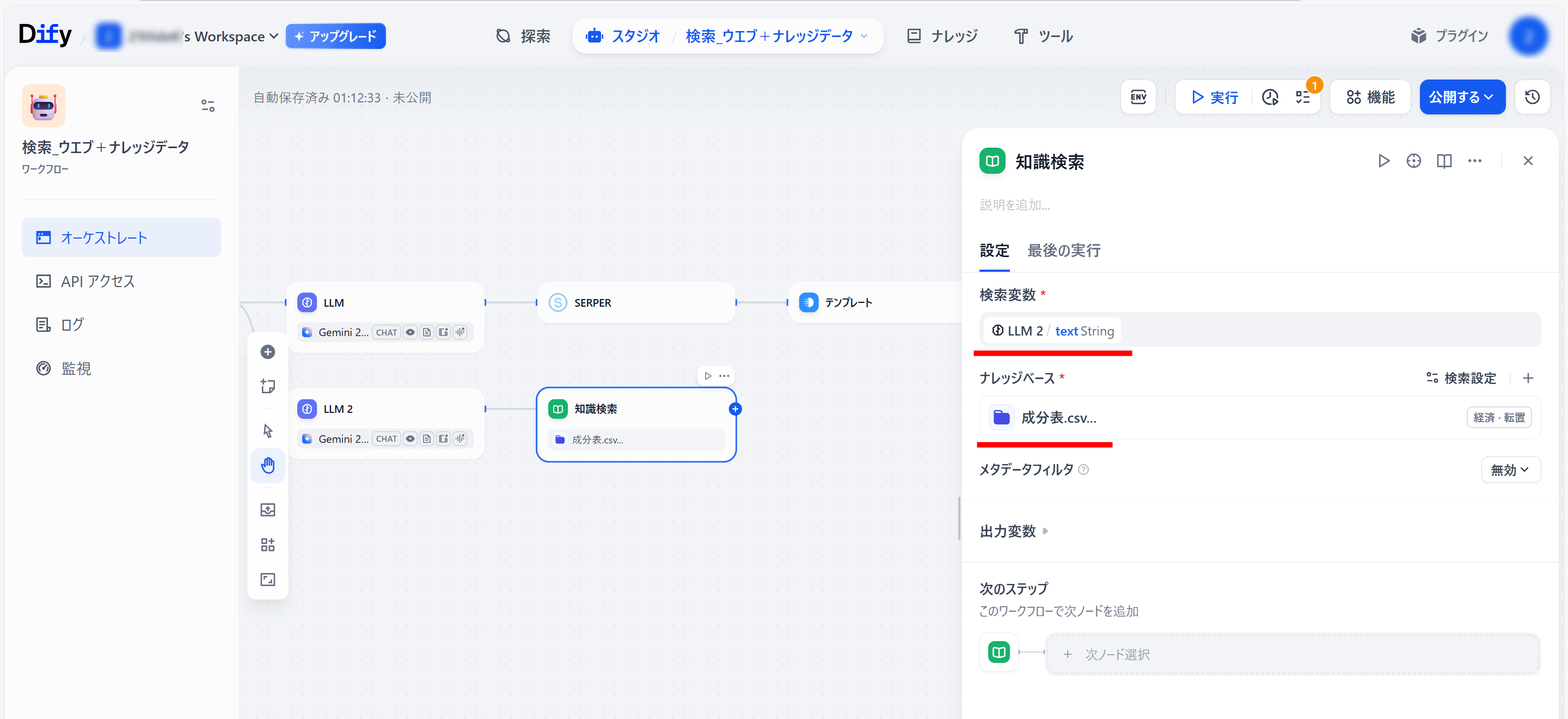
●「知識検索」ブロック設定
検索変数:開始/search_word String
ナレッジベースの右側の「+」をクリック
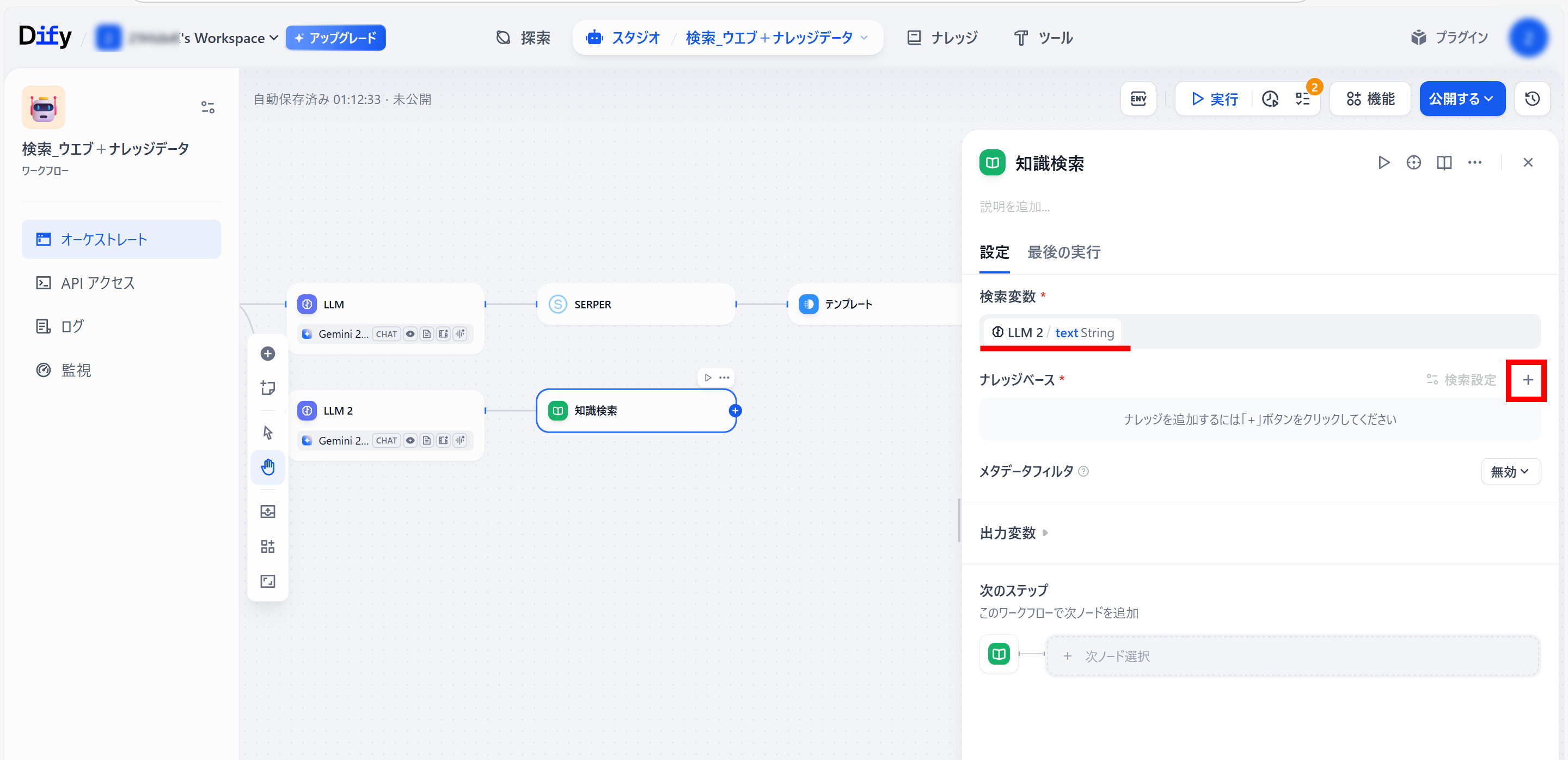
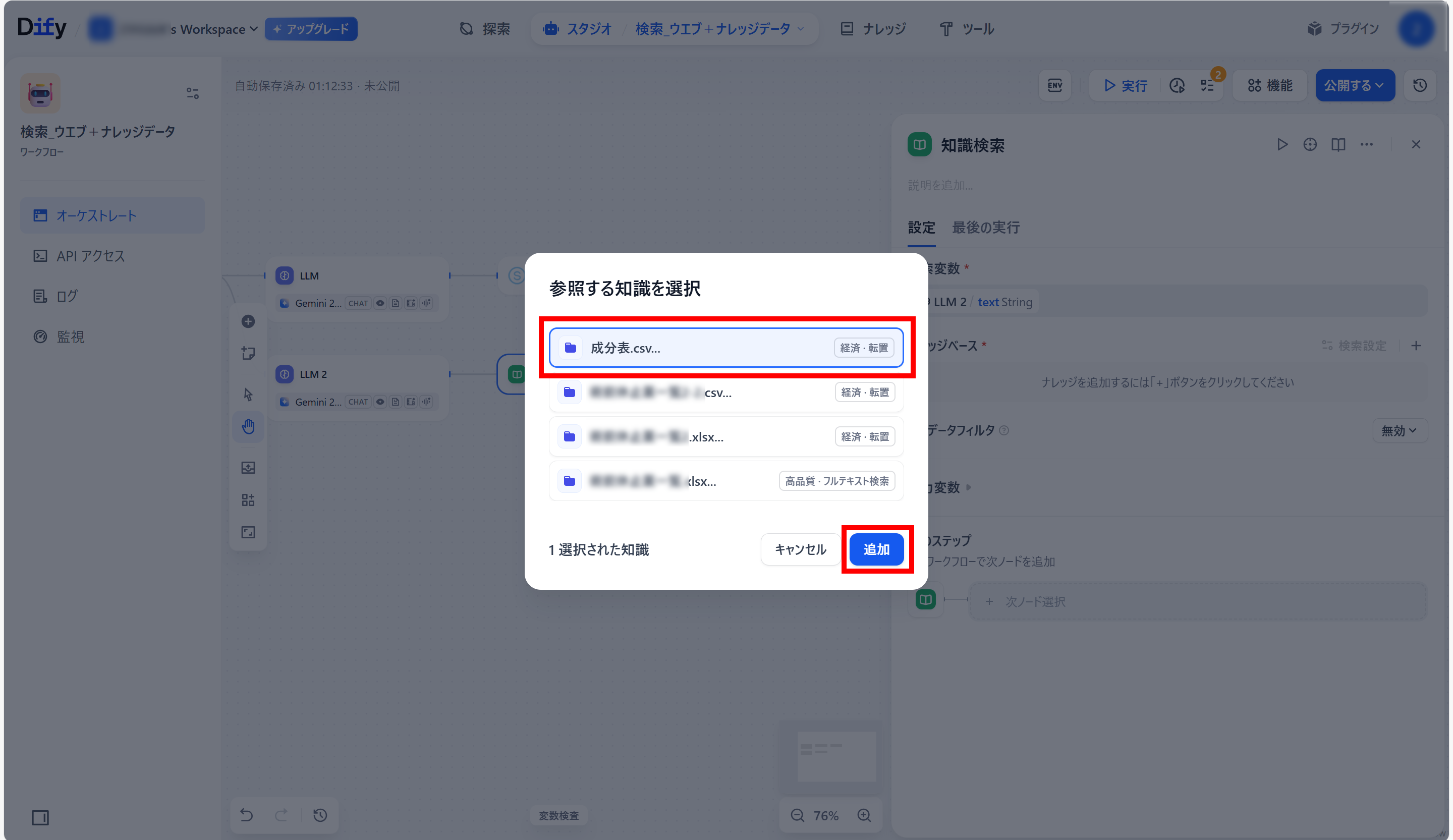
●「参照する知識を選択」が開くので、
使用するナレッジデータを選択(クリック)し、「追加」をクリック。
③ ①, ②の情報を統合して、最後に出力する

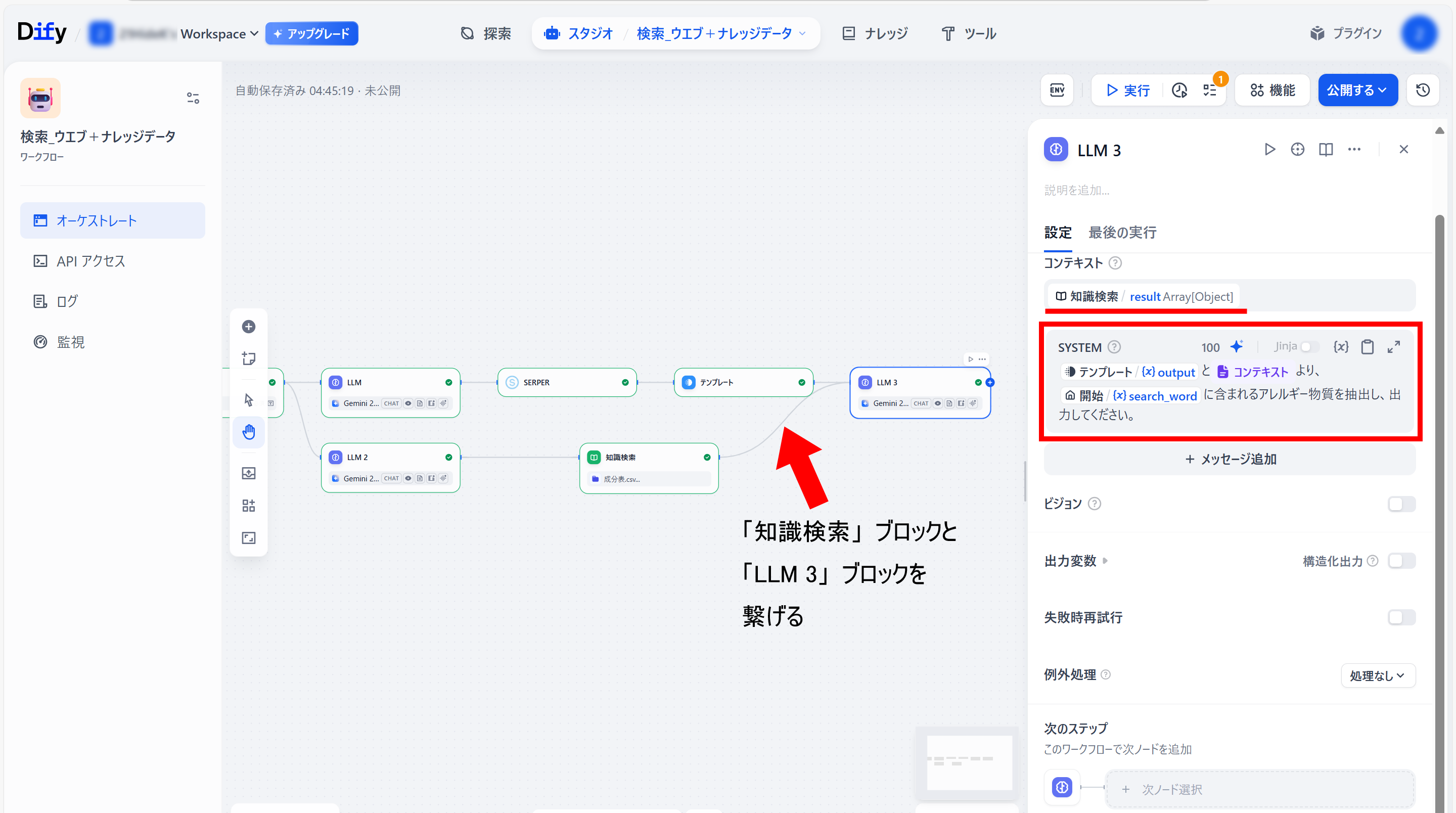
●「テンプレート」ブロックの右側の「+」メニュー内の「LLM」をクリック(「LLM 3」ブロックを作成)

●「LLM 3」ブロック設定
コンテキスト:知識検索/ result Arrey[Object]
SYSTEM(プロンプト):
{テンプレート {x}output}と{コンテキスト}より、
{開始/{x}search_word}に含まれるアレルギー物質を抽出し、
出力してください。
USER(プロンプト):
{テンプレート {x}output}{開始/{x}search_word}
※注 2025年9月上旬より、この「USER」枠を作成しキーワードを
入力しないと、LLMは動かなくなりました(Geminiだけ?)
※{テンプレート {x}output}、{コンテキスト}、{開始/{x}search_word}は、
枠内の{x}をクリックしてそれぞれ挿入してください。
●「知識検索」ブロックと、「LLM 3」ブロックを繋げる。
●「LLM 3」ブロックの右側「+」メニュー内の「終了」をクリック(「終了」ブロックをつくる)

●「終了」ブロック設定
出力変数:LLM 3/text String
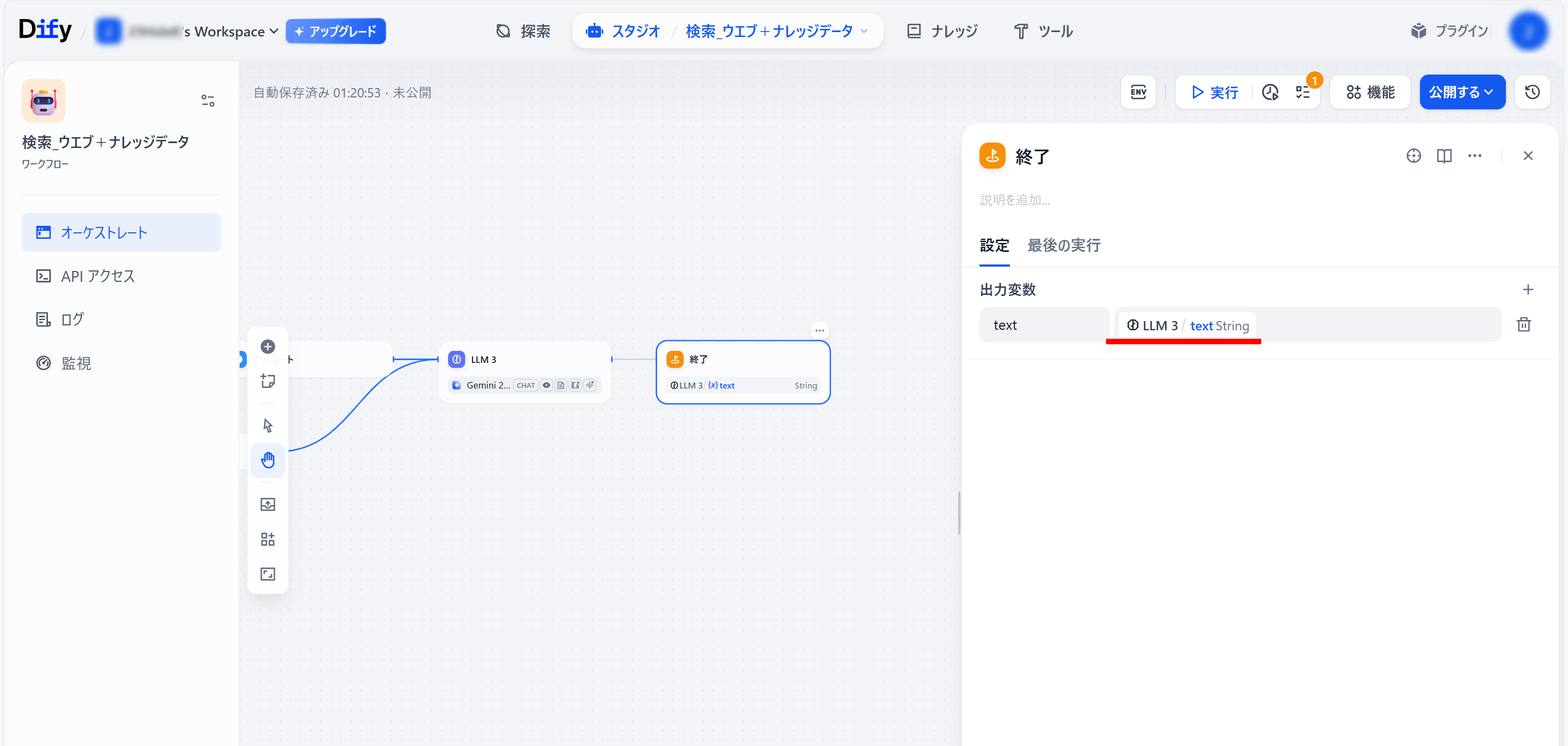
以下のような、フローが出来ていると思います。

5. 公開する
●右上の「公開する」をクリック

●「更新を公開」をクリック

6. APIキーの獲得(生成したコードとDifyをつなぐ)
Difyの左側メニュー内の「API アクセス」をクリック
右上の「API キー」をクリック

開いた画面の「新しいシークレットキーを作成」をクリック
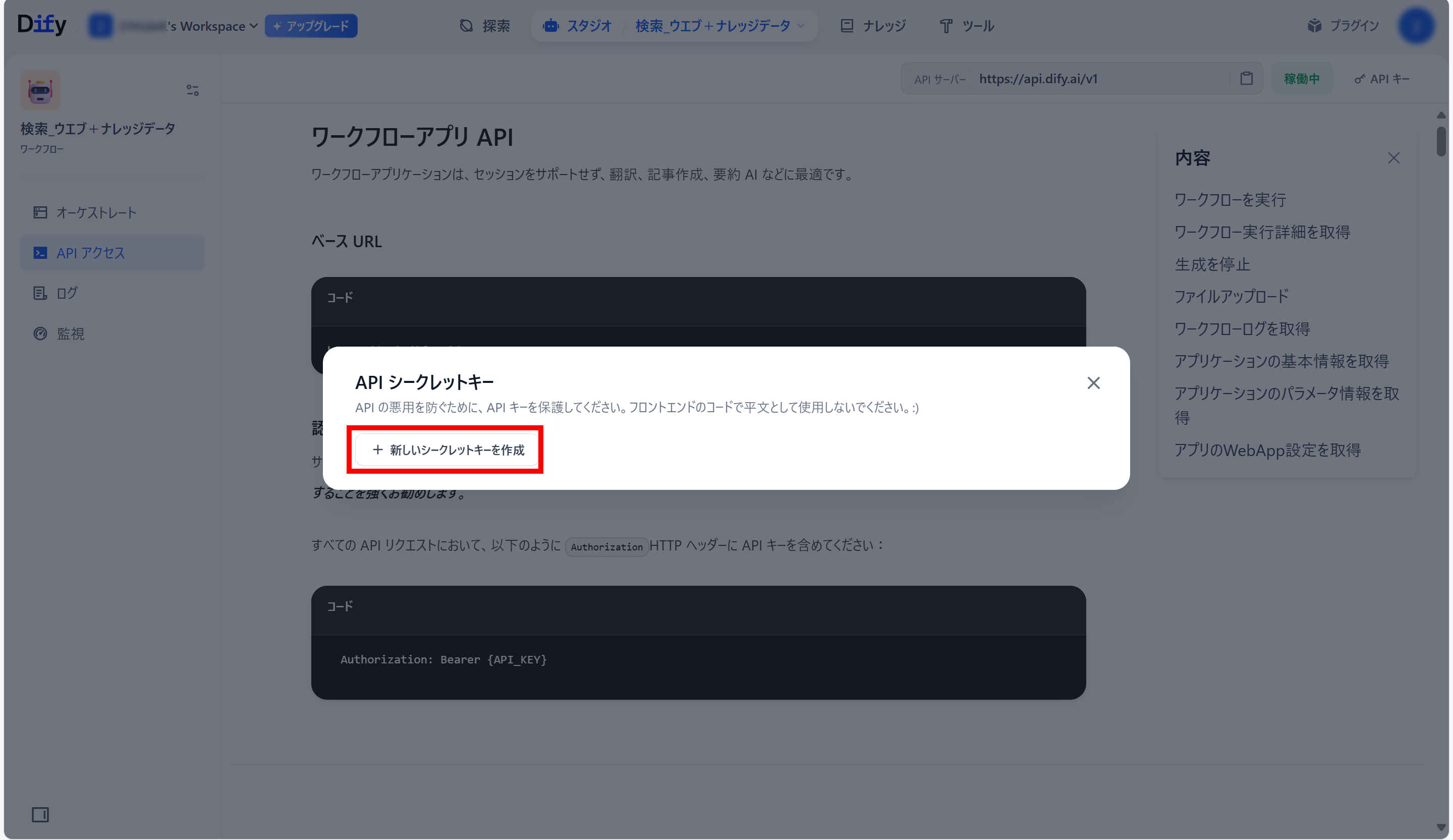
作成されたシークレットキーをコピー(右側のコピーボタンをクリック)

このAPIキーを、バイブコーディングしたコードなどでご使用ください。
まとめ
以上がDifyの活用法の一つ、検索、ナレッジデータの使い方になります。
皆様にご活用いただければ幸いです。
つまづきポイント
【つまづきポイント1】
Difyのナレッジデータへの検索は、
〇:アルファベット、漢字
✖:ひらがな、カタカナ
ひらがな、カタカナはキーワードに登録しても検索にはかからないです。
(これに気付くまで数日かかりました)
これはウェブを検索しても現段階では情報はないので、個人的には大発見だと思います。もしかすると、何か設定があるのもしれませんが・・・。
検索にかかるようにするための工夫
①CSVファイルに、検索したい用語のローマ字表記の列をつくる。
②Difyのナレッジへ登録
①CSVファイルに、検索したい用語のローマ字表記の列をつくる。
- カタカナ→ローマ字変換する関数を作成(AIで生成)
- エクセルにVBAを登録し、セルに関数を書く
- CSVファイルを保存する
1. カタカナ→ローマ字変換する関数を作成(AIで生成)
ChatGPT等で、カタカナをローマ字へ変換するVBAで動く関数を生成します。
以下にVBAを生成するためのプロンプトと、生成したVBAを用意しました。
VBAを作成するためのプロンプト
以下の様にローマの小文字表記に変換するためのVBAで動くエクセル関数を作成してください。音のアルファベット変換ではなくローマ字変換です。変換したローマ字だけ出力してください。
以下のルールに従って変換してください:
1. 濁音(ガギグゲゴなど)、半濁音(パピプペポなど)、拗音(キャ、シュなど)を正確に処理してください。
2. 小さい「ッ」は、次の子音を重ねて表現してください(例:サッポロ → sapporo)。
3. 長音「ー」は、英字の「-」(ハイフン)に変換してください(例:ケーシー → ke-shi-)。
4. 「シ」「チ」「ツ」などはヘボン式(shi, chi, tsu)に準拠してください。
5. 促音・拗音・小書き文字(ャュョァィゥェォッ)すべて対応してください。
6. 半角スペースや句読点は削除してください。
【入力】にカタカナの商品名が与えられますので、それをローマ字に変換して、【出力】のみを返してください。
---
【入力】:ケーシー
【出力】:ke-shi-
【入力】:ヨウカン
【出力】:youkan
VBA
Function KanaToRomaji(text As String) As String
Dim dict As Object
Set dict = CreateObject("Scripting.Dictionary")
' 促音+拗音
dict.Add "ッキャ", "kya": dict.Add "ッキュ", "kyu": dict.Add "ッキョ", "kyo"
dict.Add "ッシャ", "sha": dict.Add "ッシュ", "shu": dict.Add "ッショ", "sho"
dict.Add "ッチャ", "cha": dict.Add "ッチュ", "chu": dict.Add "ッチョ", "cho"
dict.Add "ッニャ", "nya": dict.Add "ッニュ", "nyu": dict.Add "ッニョ", "nyo"
dict.Add "ッヒャ", "hya": dict.Add "ッヒュ", "hyu": dict.Add "ッヒョ", "hyo"
dict.Add "ッミャ", "mya": dict.Add "ッミュ", "myu": dict.Add "ッミョ", "myo"
dict.Add "ッリャ", "rya": dict.Add "ッリュ", "ryu": dict.Add "ッリョ", "ryo"
dict.Add "ッギャ", "gya": dict.Add "ッギュ", "gyu": dict.Add "ッギョ", "gyo"
dict.Add "ッジャ", "ja": dict.Add "ッジュ", "ju": dict.Add "ッジョ", "jo"
dict.Add "ッビャ", "bya": dict.Add "ッビュ", "byu": dict.Add "ッビョ", "byo"
dict.Add "ッピャ", "pya": dict.Add "ッピュ", "pyu": dict.Add "ッピョ", "pyo"
dict.Add "ッヴァ", "va": dict.Add "ッヴィ", "vi": dict.Add "ッヴェ", "ve": dict.Add "ッヴォ", "vo": dict.Add "ッヴ", "vu"
' 促音+清音・濁音系
dict.Add "ッカ", "kka": dict.Add "ッキ", "kki": dict.Add "ック", "kku": dict.Add "ッケ", "kke": dict.Add "ッコ", "kko"
dict.Add "ッサ", "ssa": dict.Add "ッシ", "ssi": dict.Add "ッス", "ssu": dict.Add "ッセ", "sse": dict.Add "ッソ", "sso"
dict.Add "ッタ", "tta": dict.Add "ッチ", "tti": dict.Add "ッツ", "ttu": dict.Add "ッテ", "tte": dict.Add "ット", "tto"
dict.Add "ッハ", "hha": dict.Add "ッヒ", "hhi": dict.Add "ッフ", "hhu": dict.Add "ッヘ", "hhe": dict.Add "ッホ", "hho"
dict.Add "ッマ", "mma": dict.Add "ッミ", "mmi": dict.Add "ッム", "mmu": dict.Add "ッメ", "mme": dict.Add "ッモ", "mmo"
dict.Add "ッヤ", "yya": dict.Add "ッユ", "yyu": dict.Add "ッヨ", "yyo"
dict.Add "ッラ", "rra": dict.Add "ッリ", "rri": dict.Add "ッル", "rru": dict.Add "ッレ", "rre": dict.Add "ッロ", "rro"
dict.Add "ッガ", "gga": dict.Add "ッギ", "ggi": dict.Add "ッグ", "ggu": dict.Add "ッゲ", "gge": dict.Add "ッゴ", "ggo"
dict.Add "ッザ", "zza": dict.Add "ッジ", "zzi": dict.Add "ッズ", "zzu": dict.Add "ッゼ", "zze": dict.Add "ッゾ", "zzo"
dict.Add "ッダ", "dda": dict.Add "ッヂ", "ddi": dict.Add "ッヅ", "ddu": dict.Add "ッデ", "dde": dict.Add "ッド", "ddo"
dict.Add "ッバ", "bba": dict.Add "ッビ", "bbi": dict.Add "ッブ", "bbu": dict.Add "ッベ", "bbe": dict.Add "ッボ", "bbo"
dict.Add "ッパ", "ppa": dict.Add "ッピ", "ppi": dict.Add "ップ", "ppu": dict.Add "ッペ", "ppe": dict.Add "ッポ", "ppo"
' 拗音(清音・濁音)
Dim baseKana As Variant, baseRoma As Variant
baseKana = Split("キャ キュ キョ シャ シュ ショ チャ チュ チョ ニャ ニュ ニョ ヒャ ヒュ ヒョ ミャ ミュ ミョ リャ リュ リョ ギャ ギュ ギョ ジャ ジュ ジョ ビャ ビュ ビョ ピャ ピュ ピョ ヴァ ヴィ ヴェ ヴォ ヴ", " ")
baseRoma = Split("kya kyu kyo sha shu sho cha chu cho nya nyu nyo hya hyu hyo mya myu myo rya ryu ryo gya gyu gyo ja ju jo bya byu byo pya pyu pyo va vi ve vo vu", " ")
Dim i As Long
For i = 0 To UBound(baseKana)
dict.Add baseKana(i), baseRoma(i)
Next
' 小書き文字
dict.Add "ッ", "xtsu": dict.Add "ャ", "xya": dict.Add "ュ", "xyu": dict.Add "ョ", "xyo"
dict.Add "ァ", "xa": dict.Add "ィ", "xi": dict.Add "ゥ", "xu": dict.Add "ェ", "xe": dict.Add "ォ", "xo"
' 清音・濁音・半濁音
Dim kana, roma
kana = Split("ア イ ウ エ オ カ キ ク ケ コ サ シ ス セ ソ タ チ ツ テ ト ナ ニ ヌ ネ ノ ハ ヒ フ ヘ ホ マ ミ ム メ モ ヤ ユ ヨ ラ リ ル レ ロ ワ ヲ ン ガ ギ グ ゲ ゴ ザ ジ ズ ゼ ゾ ダ ヂ ヅ デ ド バ ビ ブ ベ ボ パ ピ プ ペ ポ", " ")
roma = Split("a i u e o ka ki ku ke ko sa shi su se so ta chi tsu te to na ni nu ne no ha hi hu he ho ma mi mu me mo ya yu yo ra ri ru re ro wa wo n ga gi gu ge go za zi zu ze zo da di du de do ba bi bu be bo pa pi pu pe po", " ")
For i = 0 To UBound(kana)
dict.Add kana(i), roma(i)
Next
' ひらがな対応
Dim hira, kata
hira = Split("あ い う え お か き く け こ さ し す せ そ た ち つ て と な に ぬ ね の は ひ ふ へ ほ ま み む め も や ゆ よ ら り る れ ろ わ を ん", " ")
kata = Split("ア イ ウ エ オ カ キ ク ケ コ サ シ ス セ ソ タ チ ツ テ ト ナ ニ ヌ ネ ノ ハ ヒ フ ヘ ホ マ ミ ム メ モ ヤ ユ ヨ ラ リ ル レ ロ ワ ヲ ン", " ")
For i = 0 To UBound(hira)
If dict.Exists(kata(i)) Then
dict.Add hira(i), dict(kata(i))
End If
Next
' 長音記号
text = Replace(text, "ー", "-")
' 実行:辞書のキーを長い順に並び替え、先に置換
Dim key As Variant
For Each key In SortByLength(dict.Keys)
text = Replace(text, key, dict(key))
Next
KanaToRomaji = text
End Function
' ↓キーを長さ順で降順ソートする関数
Private Function SortByLength(arr As Variant) As Variant
Dim i As Long, j As Long, tmp
For i = LBound(arr) To UBound(arr) - 1
For j = i + 1 To UBound(arr)
If Len(arr(i)) < Len(arr(j)) Then
tmp = arr(i)
arr(i) = arr(j)
arr(j) = tmp
End If
Next j
Next i
SortByLength = arr
End Function
2. エクセルにVBAを登録し、セルに関数を書く
●VBAを開く
エクセルのメニュー内の「開発」を開き、「Visual Bacsic」をクリックし開く。
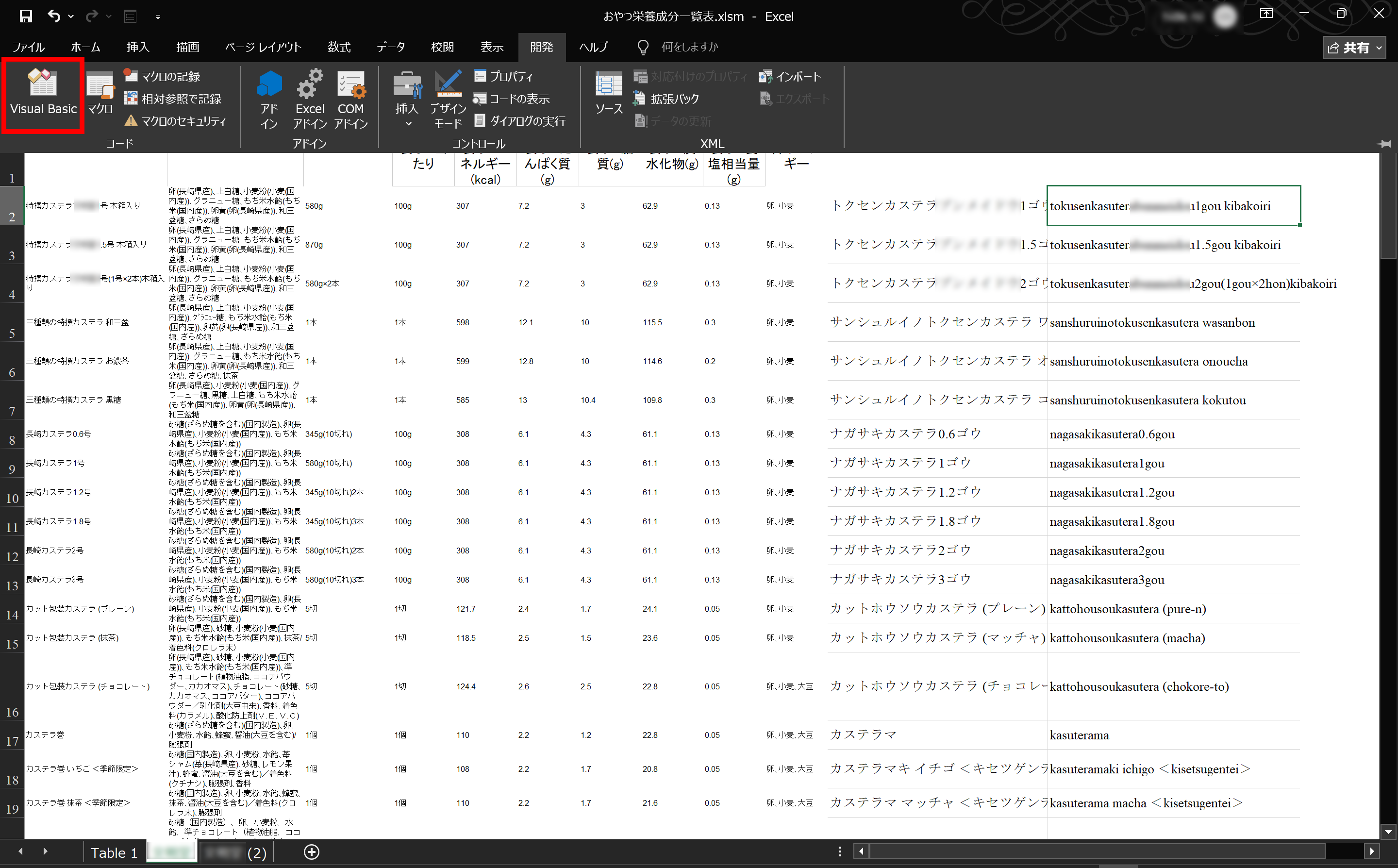
※メニュー内に「開発」が無い方は、以下の手順で「開発」を表示させてください。
- エクセルのメニューの「ファイル」をクリック
- 表示された画面の左メニューの一番下の「オプション」をクリック
- 開いたウインドウの左メニュー「リボンのユーザー設定」をクリックし、その中の「開発」にチェックをつける。

●左側の表示内で右クリックし、右クリックメニューの「挿入」→「標準モジュール」をクリックする。
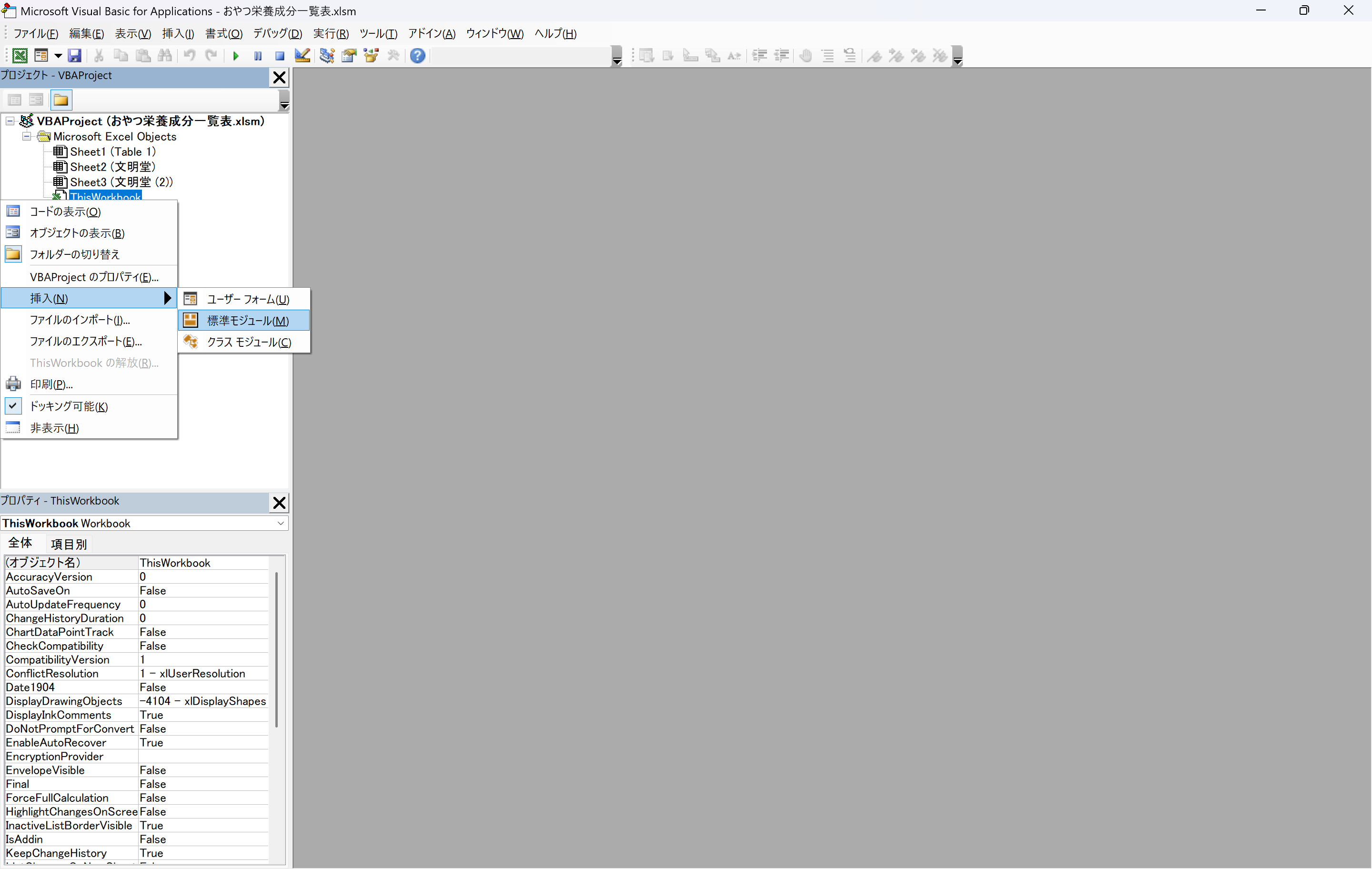
●作成したモジュール(Module1)内に、生成したVBAをペーストする。

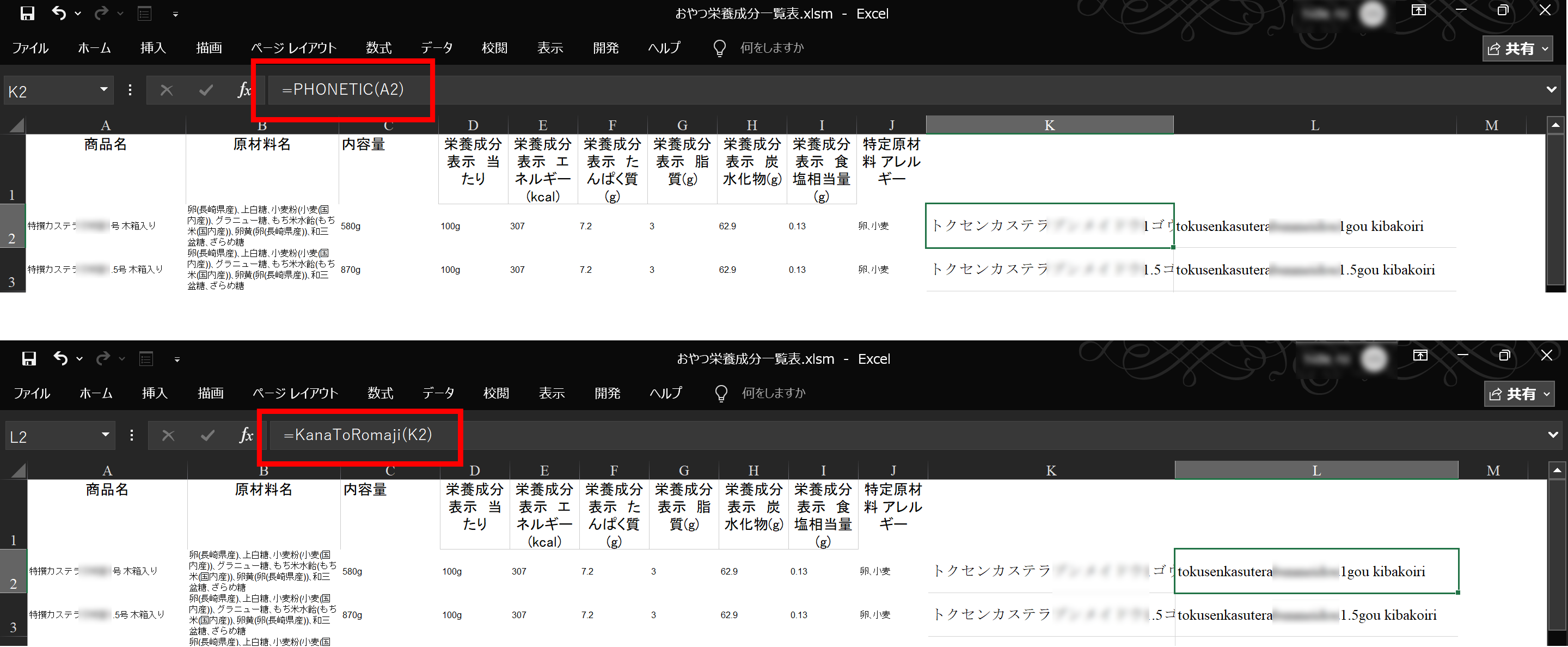
セルに関数を書く
情報の入っているセルの後ろの列(この図ならばK列より後ろ)に関数を記載。
(記入例)
K列:=PHONETIC(A2)
(ひらがな、漢字をカタカナへ変換する関数)
L列:=KanaToRomaji(K2)
(VBAで作ったオリジナル関数)
と記載し、一番下の列までコピー(セル右下の四角(フィルハンドル)で
オートフィルしても良いです)
※K列でカタカナへ変換し、それをL列でローマ字変換
3. CSVファイルを保存する
新たにシートを作成し以下の様に張り付ける。
- データの整理
- A列に作成した商品名のローマ字表記を張り付け(張り付けオプションで「値」を選択)。
- B列に商品名を張り付け
- C列、D列などに必要な情報を張り付け

- CSVファイルで保存
エクセルのメニュー「ファイル」→「名前を付けて保存」→ファイルの種類(ファイル形式)を「CSV(コンマ区切り)(*.csv)」にして保存。
②ナレッジデータのキーワードを編集
●Difyの「ナレッジ」内の、先ほど作成したナレッジベースの画面を開き、登録したCSVファイルの行をクリック
(登録されたチャンク一覧の画面を開く)
●下の画面が開くので、一つのチャンクをクリックし編集画面へ。
右下のキーワードを編集し、「保存」をクリック。
CSVファイルをナレッジデータに登録すると、自動的にキーワードが作成されますが、ローマ字のキーワードを登録する必要があります。

登録数(チャンク数)が多いと、この修正は地味に大変な作業ですが、これを行うことにより、格段に検索にかかりやすくなります!
③Difyの知識検索ブロック前のLLMにローマ字変換のプロンプトを登録
後述の「4. フローをつくる」内で、知識検索ブロックの前にLLMのブロックを置き、そのLLMに以下の「LLMにて入力した用語をローマ字表記へ変換する」ためのプロンプトを記入する。
Difyの知識検索ブロック前のLLMブロックへ登録するプロンプト
あなたは、カタカナを、ヘボン式ローマ字に正確に変換するアシスタントです。
以下の様に{ここにDifyで変数「開始/search_word」を入れる}をローマの小文字表記に変換してください。音のアルファベット変換ではなくローマ字変換です。変換したローマ字だけ出力してください。
以下のルールに従って変換してください:
1. 濁音(ガギグゲゴなど)、半濁音(パピプペポなど)、拗音(キャ、シュなど)を正確に処理してください。
2. 小さい「ッ」は、次の子音を重ねて表現してください(例:サッポロ → sapporo)。
3. 長音「ー」は、英字の「-」(ハイフン)に変換してください(例:ケーシー → ke-shi-)。
4. 「シ」「チ」「ツ」などはヘボン式(shi, chi, tsu)に準拠してください。
5. 促音・拗音・小書き文字(ャュョァィゥェォッ)すべて対応してください。
6. 半角スペースや句読点は削除してください。
上手くいかないときは、色々と工夫してみてください。また、Difyにはプロンプト作成を頼む機能もあります。
【つまづきポイント2】
検索ブロック(SerperでもGoogleでも)で得られた結果は、テキスト化(jsonデータ⇒テキストデータ)しないと、次のLLMでは読み込めない。
「テンプレート」ブロックでテキスト化することにより利用できる。
ウェブで検索しても、これに関する情報は出てきませんでした。あれこれ試行錯誤しこの形にたどり着いたのですが、気付くまでに数日かかりました。つまづきポイント1と同様、自分としては大発見と思っています。
とはいえ、エンジニアの方であれば、jsonデータをテキスト化しないと利用できないことは容易にわかるものと思います。そして他に方法があるかもしれませんが・・・。
参考文献
Dify入門ガイド:チャットフローでRAGを実装
https://note.com/weel_media/n/na550526d8985
Dify に AIモデル(Gemini)を設定する
https://qiita.com/b-wind/items/f45afb8a0cb4a43a1f60