DeepLearning Advent Calendar 2016の17日目の記事です。
はじめに
はじめまして。
Liaroという会社でエンジニアをしている@eve_ykと申します。
今年もあと僅かとなりました。
ここらで、今年のDeepLearningの主要な成果を振り返ってみましょう。
この記事は、2016年に発表されたDeepLearning関係の研究を広く浅くまとめたものです。今年のDeepLearningの研究の進歩を俯瞰するのに役立てば幸いです。
それぞれの内容について、その要点や感想なんかを簡単にまとめられたらと思います。
特に重要だと思った研究には★マークをつけておきます。
非常に長くなってしまったため、興味のある分野だけ読んでいただければと思います。
言い訳とお願い
- 見つけたものはコードへのリンクも示すので、プログラミングに関係ある記事ということで…
- 分野的にかなり偏ったまとめになりましたが、ご容赦ください。
- まとめを始めた時期の関係で、2016年の研究の中でも比較的新しいものが多い点もご容赦ください
- 注意はしておりますが、内容の正確性は無保証です。誤りや不適切な点がありましたら、ご指摘いただけると幸いです。
- 他に重要なものがあれば「こんな研究もあるよ!」という紹介をしていただけるととても嬉しく思います。
まとめのまとめ (※12/24 追記)
年末ということで、この記事に以外にもたくさんのまとめ記事が投稿されています。
どれも素晴らしいまとめですので、これらもご覧ください。
[2016年のディープラーニング論文100選] (http://qiita.com/sakaiakira/items/9da1edda802c4884865c)
より幅広い分野の論文がまとめられています。
本記事で扱っていない分野に興味がある人も、この記事を読めば満足するはずです。
foobarNet: ディープラーニング関連の○○Netまとめ
これまで発表された◯◯Netの総まとめです。
圧倒的な情報量で、ひとつずつ眺めていくだけでいくらでも時間が潰せそうです。
2016年の深層学習を用いた画像認識モデル
近年の画像認識モデルのまとめ+実装+比較+解説です。
ほぼすべてのモデルにchainer実装があります。画像認識は本記事よりもこちらを読んだほうが良いです。
Deep Learningの理論的論文リスト【随時更新】
深層学習の理論的に解析した論文のまとめです。
深層学習そのものを理解するために行われている様々な解析が、非常に参考になります。
画像処理系
画像の分野では、昨年に引き続き画像認識に関する研究が人気だと感じました。
また、GANの登場により画像生成系の研究も非常に盛んであったと思います。
ResNetの進化
2015年にMSRAが提案したResidual Networks(ResNet)は、より深いニューラルネットワークを訓練することの出来るアーキテクチャです。シンプルな改良で大きな成果を上げたこのモデルについて、様々な応用がなされました。
ResNet自体の解説は以下の記事を参考ください。
参考:MSRAの解説スライド
参考:日本語の解説記事1
参考:日本語の解説記事2
Deep Networks with Stochastic Depth (2016/5)★
ResNetの訓練時に、ランダムに幾つかの層をskip(ResNetにおけるidentity skip connection pathのみ残す)させる手法を提案した論文です。
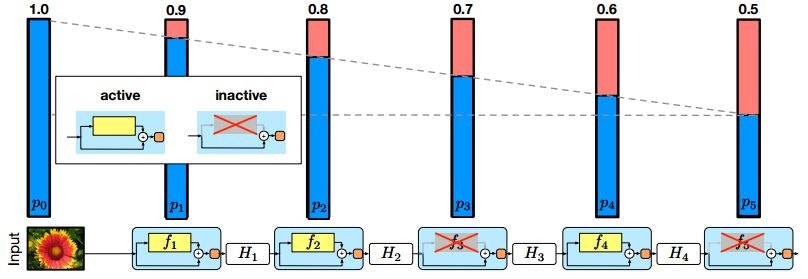
Deep Networks with Stochastic Depth Fig. 2.
CIFAR-100等の画像分類のタスクにおいて、精度が向上することを示しました(2016/3時点のSOTA?)。また、訓練時の計算量が減るため、訓練時間が短縮されることもメリットになります。
Deep Neural Networkの訓練によく使用されるDropoutに似た考え方の手法だと思います。
参考:日本語のサーベイ記事
FractalNet: Ultra-Deep Neural Networks without Residuals (2016/5)
(ResNetの仲間ではありませんが…)
複数の階層の深さが異なる畳み込み層の結果を結合するFractal Netを提案した論文です。以下の図のようなアーキテクチャです。
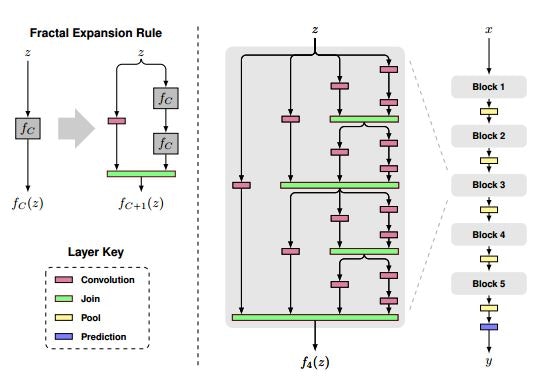
FractalNet: Ultra-Deep Neural Networks without Residuals Fig. 1.
"Deep Networks with Stochastic Depth"のようにいくつかの層をskipする訓練方法も示しています。
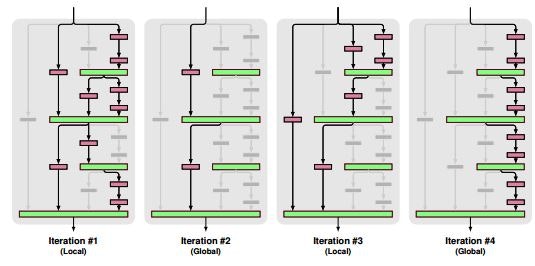
FractalNet: Ultra-Deep Neural Networks without Residuals Fig. 2.
CIFAR-100等の画像分類のタスクにおいて、精度が向上することを示しました(2016/5時点のSOTA)。
"without Residuals"とありますが、多くの層を飛ばす図中の左端の経路の部分が、ResNetでいうidentity skip connection pathに似た働きをするのではないかと思います。
Residual Networks of Residual Networks: Multilevel Residual Networks (2016/8)
ResNetにおいて、複数のResidual Blockをまたがるshortcutを追加したResidual Networks of Residual Networks(RoR)を提案した論文です。
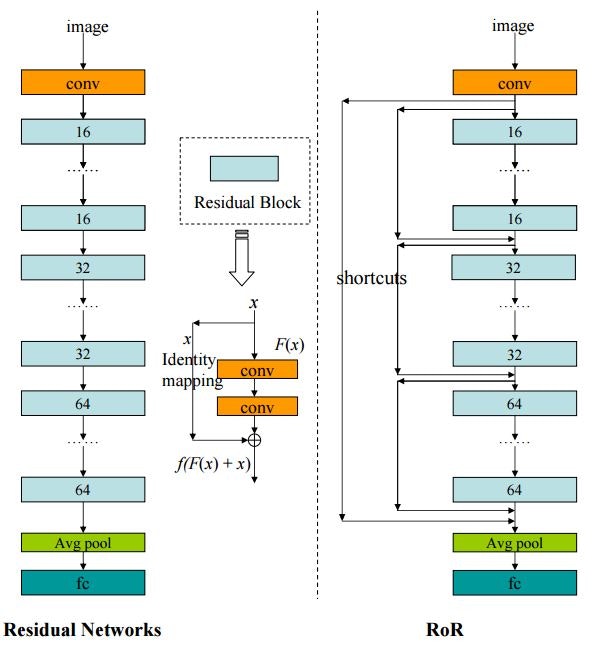
Residual Networks of Residual Networks: Multilevel Residual Networks Fig. 1.
CIFAR-100等の画像分類のタスクにおいて、ResNetと比較して精度が向上することを示しました。
Densely Connected Convolutional Networks (2016/8)★
複数の畳み込み層が密に結合するdense blockを取り入れたDenseNetを提案した論文です。
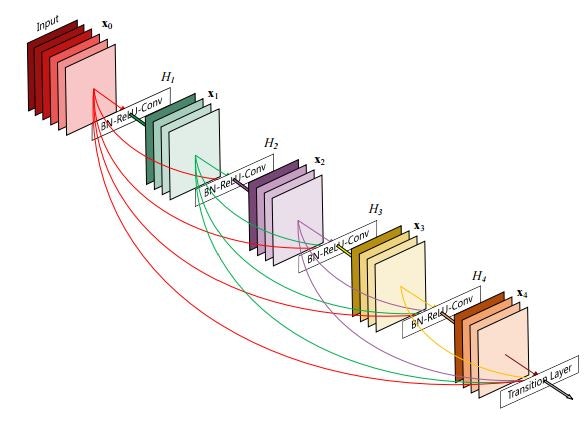
Densely Connected Convolutional Networks Fig. 1.
CIFAR-100等の画像分類のタスクにおいて、ResNetと比較して精度が向上することを示しました (こればっかり…)(2016/8時点のSOTA?)。
構造といい、アイデアがRoRとほとんど同じに感じます…。
論文を詳しく読んでいないので詳しくはわからないのですが、どこに違いがあるのでしょうか?
同じ時期に似たアイデアの論文が出ているところに、競争率の高さを感じます。
参考:DenseNetの実装まとめ。公式の実装はCaffeとTorchですが、Tensorflow, Lasagne, Keras Chainerの実装へのリンクもあります。
Aggregated Residual Transformations for Deep Neural Networks (2016/11)
ResNetのResidual Blockを改良したResNeXtを提案した論文。画像分類のコンペティションであるILSVRC 2016で2位となったモデルです。
Residual Block内の畳み込み層を並列にしている?
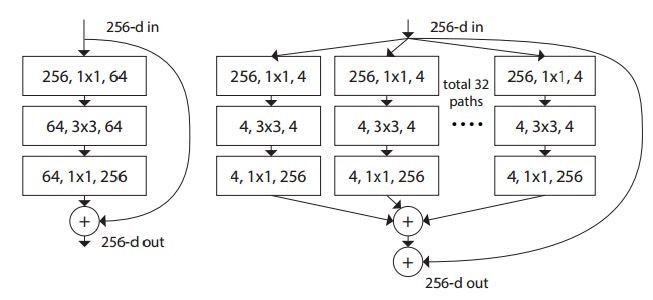
(https://arxiv.org/pdf/1611.05431v1.pdf)
DenseNetもResNeXtもFacebook AI Researchの論文です。
参考:モデルの実装(MXNet)。訓練済みのモデルはここで公開されています。
画像生成
昨年末にDCGANが登場してから、非常に盛り上がっている分野だと感じます。
生成系は私にはとても理解できないので、要点のまとめもふわふわしています。
Pixel Recurrent Neural Networks(2016/1)★
あるピクセルの値をその周囲のピクセルから予測して画像生成を行うPixel RNNを提案した論文です。

Pixel Recurrent Neural Networks Fig. 1.
この手法では、画像の左上のピクセルから右のピクセルを見ていき、右端まで見たら次の段の一番左のピクセルへ…という順にピクセルを順に見ていきます。あるピクセル値の予測には、これまでに見たピクセルの"文脈"を利用します。
様々な"文脈"の使い方を提案・検証したこと、モデルの並列化方法を提案したことなどが貢献になります。
評価では、MNISTやCIFAR-10のデータセットの画像生成を行い、その対数尤度を比較しています。
このモデルのような、「ある時点の値を予測するためにその周囲(それ以前)の値を利用するモデル」のことを自己回帰モデルと言うそうです(間違っていたら指摘お願いします…)。
この自己回帰モデルは画像以外の分野でも成功しています。詳しくは後述します。
参考:日本語解説記事。この記事の内容はもちろん、記事中で引用されているスライドも非常にわかりやすいです。
参考:tensorflow実装
Image-to-Image Translation with Conditional Adversarial Nets(2016/11)★
従来はタスクごとに独自のアプローチを検討する必要があった画像対画像変換について、汎用的なモデルであるConditional GANを提案し検証している論文です。通称pix2pix。
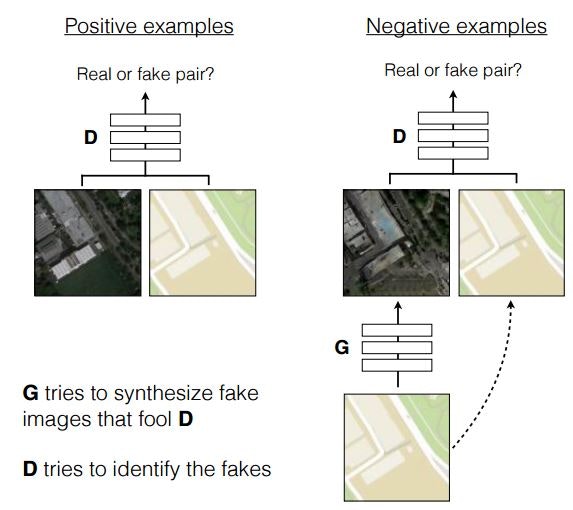
Image-to-Image Translation with Conditional Adversarial Nets Fig. 2.
Conditional GANの訓練方法は上図の通り。
Positive example(実際の画像)を与えるときは、変換前と変換後の画像のペアを与えて、実際の画像かどうかをDiscriminatorに解かせます。Negative example(pix2pixが生成する画像)を与えるときは、変換前の画像をGeneratorに入力して生成した画像と変換前の画像のペアを与えて、実際の画像かどうかをDiscriminatorに解かせます。
また、よりリアルな画像生成のために、L1正規化やPatchGANといった工夫を取り入れているそうです。より詳細な解説は参考の解説記事を参照ください。
評価では、「航空画像→地図画像」、「灰色画像→カラー画像」、「日中の画像→夜間の画像」「線画→カラー画像」など様々な画像変換について、アンケート評価やFCN-scoreという尺度で行っています。

Image-to-Image Translation with Conditional Adversarial Nets Fig. 1.
個々のタスクでは独自に作成したモデルに負けていますが、汎用的に様々な画像変換を行える柔軟性はすごすぎます。
参考:プロジェクトページ。公式の実装(Torch)へのリンクもあります。
参考:日本語の解説・検証記事。より詳しい解説があります。
参考:chainer実装
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks(2016/12)
GANを二段階に分けることで高画質な画像生成を実現するStackGANを提案した論文です。
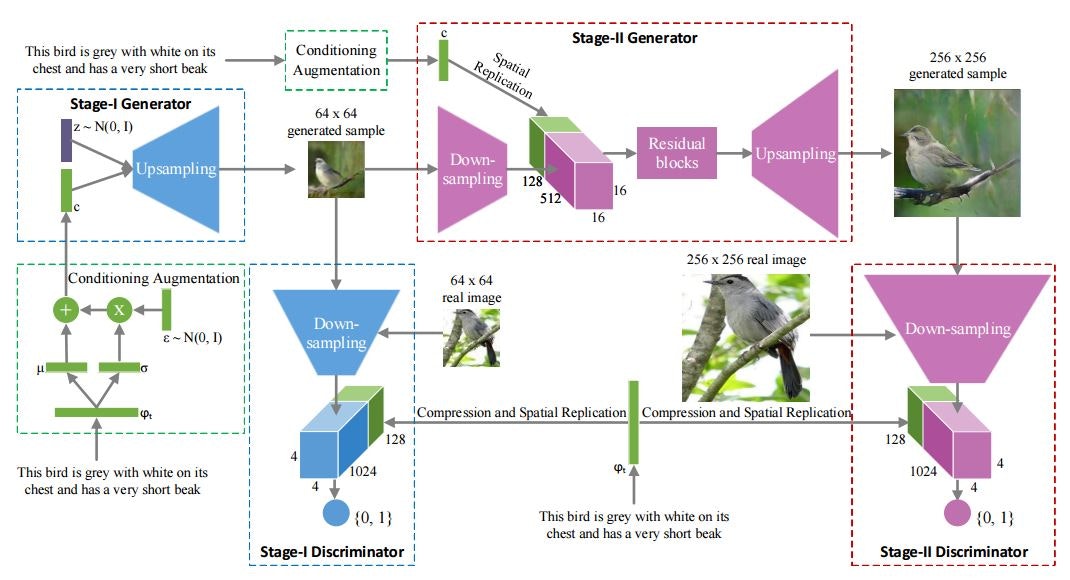
pix2pixは「画像→画像」の変換についての研究でしたが、StackGANは「テキスト→画像」の変換について取り組んだものです。
最も特徴的なのは生成過程を二段階にしたところで、初めに低解像度(64x64)の画像を生成し、その画像を高画質(256x256)な画像生成のためのGeneratorの入力として与えます。
その他の詳細についてはまだ追えていません…。
評価では、人間に対するアンケートに加えて、Inception scoresという指標を用いて行っています。

「2つのGANを積み重ねて上手くいくなら、もっとたくさん積み重ねればもっと良いものができるのでは?」と誰もが考えますが、より多層なGANがこの論文の3日後(12/13)に公開されました。タスクが異なっており、また引用もされていないので別のチームが似たアイデアを同時期に出したもの思われますが、なんという競争率の高さ…。
動画処理系
生成系のタスクが動画でも成功(?)し始めたことがこの分野で一番大きな出来事でしょうか?
動画生成
こいつ…動くぞ!
Deep Predictive Coding Networks for Fideo Prediction and Unsupervised Learning(2016/5)★
ある時刻の画像から次の時刻の画像を予測するPredNetを提案した論文です。(厳密には動画生成ではないかもしれません…)
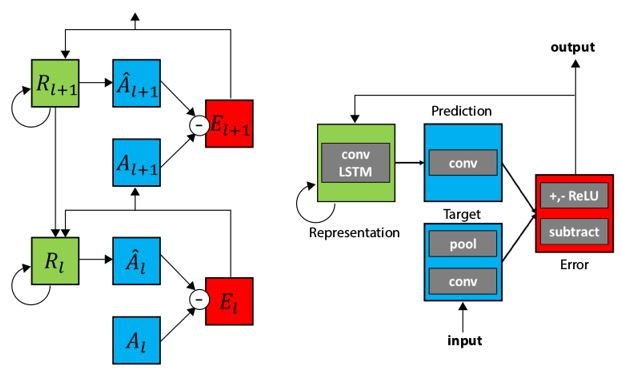
Deep Predictive Coding Networks for Fideo Prediction and Unsupervised Learning Fig. 1.
PredNetはConvLSTMというアーキテクチャ(図の緑色のブロック)を用いて中間表現を生成します。その中間表現を用いて1時刻後の画像を予測(図の青色のブロック)します。予測結果と実際の画像のL1lossを計算(図の赤色のブロック)し、出力とします(次の時刻の予測が出力ではない)。また、この誤差は次の時刻の画像の予測に用います。
処理の流れは、公式のページにあるこちらの動画がわかりやすいです。
実験では、自作した3Dモデルが回転する映像や、車載カメラの映像を用いて画像の予測を行い結果を可視化して結果の検討を行っています。可視化結果の具体例は公式のページから確認できます。
教師なし訓練ができる点が面白く感じました。
モデルの性質が脳の新皮質に類似しているそうで、わりと話題になったと記憶しています。
参考:日本語の解説記事。わかりやすい良記事です。
参考:日本語の検証報告スライド
参考:keras実装
参考:chainer実装
Generating Videos with Scene Dynamics
GANを用いて画像から1秒程度の動画を生成する手法を提案した論文です。
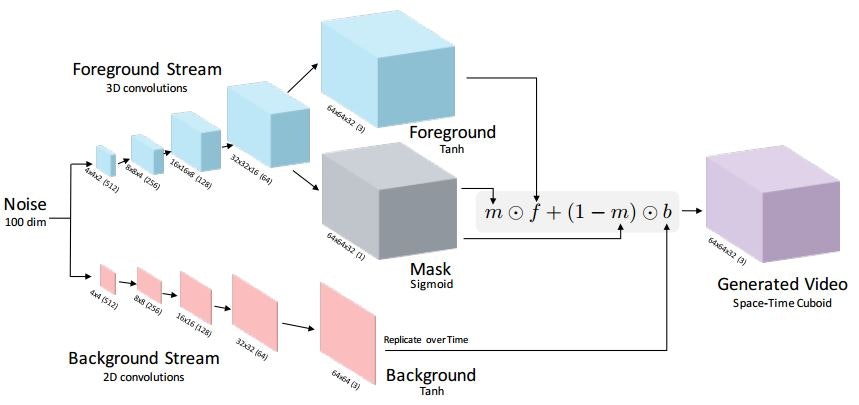
Generating Videos with Scene Dynamics Fig. 1.
モデルの入力となるのは100次元のノイズのベクトルです。モデルは二つのストリームから成っており、一つは画像の前景の時刻による変化を、もうひとつは画像の背景をそれぞれ生成します。前景を処理するストリームでは画像のマスクも生成し、それらの結果を組み合わせて最終的な短時間の動画を生成します。前景の処理では" fractionally-strided spatio-temporal convolutions"(要調査…)、背景の処理では"fractionally-strided spatial convolutions"を用いているそうです。
モデルの訓練時は、前景を処理するストリーム部分の入出力を反転した構造(最終層だけ0or1のバイナリを出力するレイヤーに変更)のDiscriminator Networkを構築し、GANの要領で訓練を行います。
評価では、「ベースライン手法の生成した動画(または実際の動画)と提案手法で生成した動画のどちらがよりリアルか」をアンケートしています。
ベースライン手法と比較したときは平均して82%の人が、実際の動画と比較すると平均して18%の人が、「提案手法の動画がよりリアルだ」と答えたそうです。
画像中の動きそうな部分(前景)と動かない部分(背景)を分けて訓練したところが賢いと感じました。(アンケートの結果では大きな差は出ていませんでしたが…)
参考:プロジェクトページ
音声処理系
詳しくない分野ですので、門外漢の私の耳にも届いたものでお茶を濁します。
WaveNet: A Generative Model for Raw Audio (2016/9)★
自己回帰モデルを用いて音声を生成するWaveNetを提案した論文です。
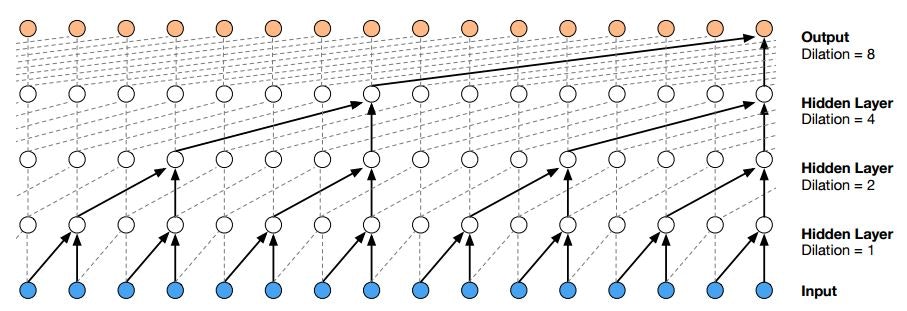
WaveNet: A Generative Model for Raw Audio Fig. 3.
WaveNetは、ある時刻の波形(の値)をそれ以前の波形データから予測する自己回帰モデルです。より古い情報も効率よく利用するために、Dilated Convolutionという手法を使っています。また、Dilated Convolutionを利用すると非常に深いネットワークになるため、Residual Networksでネットワークを構築しています。
評価では、比較手法とWaveNetで生成した音声のどちらが自然かアンケートを取っています。結果は比較手法を大きく上回りました。また、音声認識のタスクも評価し、TIMITというコーパスで最も良いスコアを示しました。
自己回帰モデルの一番の成功例と感じます。
自己回帰モデルの欠点として、生成に時間がかかる(WaveNetの場合、1秒の音声を生成するのに90分かかるそうです)ことがありますが、その欠点を解消した手法も登場しています。進歩が速すぎます。
参考:Deepmindの紹介記事。デモが聞けます。またDilated Convolutionの動作がわかりやすいgifがあります。
参考:日本語の解説記事。図が直感的で非常にわかりやすいです。
参考:tensorflow実装。
参考:高速化した実装。生成処理を高速化した手法の実装です。
参考:chainer実装。
SoundNet: Learning Sound Representations from Unlabeled Video(2016/10)
何のラベルも付与されていない動画の音声から、音声認識のための高品質な表現を獲得する手法を提案した論文です。
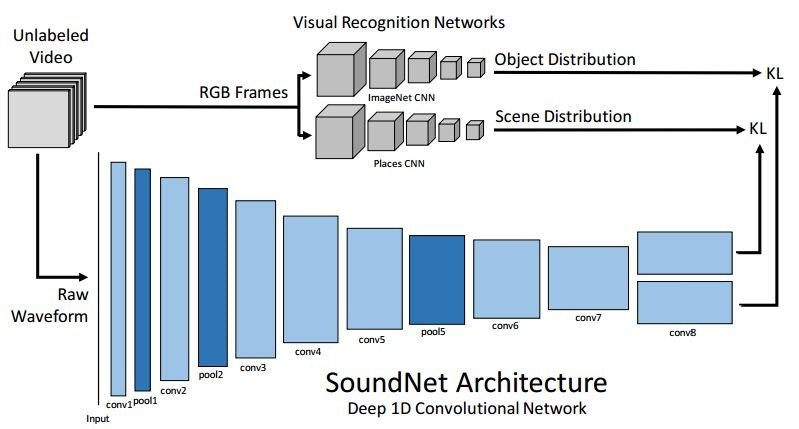
SoundNet: Learning Sound Representations from Unlabeled Video
SoundNetでは、ラベル無し動画の音声と画像をそれぞれ独立したCNNに入力します。
画像を処理するCNNは、ImageNetで訓練された「画像中の物体を認識するCNN」とPlaces2で訓練された「画像のScene(撮影場所?)を認識するCNN」です。
音声を処理するCNN(SoundNet)は、畳み込み層とプーリング層のみで構成された8層のものです。8層目は二又に分かれており、それぞれ画像中の物体と撮影場所を表現する値を出力します。全結合層を利用しないことで、可変長のデータにも対応できるようになります。
画像のCNNの結果とSoundNetの結果とのKL-divergenceを最小化するように、SoundNetの訓練を行います。
評価では、訓練後のSoundNetから出力される表現を用いて音声(楽器)認識のタスクを行い、既存手法を上回る正答率を示しています。
また、動画の音声のみから動画中に映る物体とその撮影場所を予測しています。
高精度な画像認識技術が確立しているからこその手法だと感じました。
非常にシンプルなアプローチですが、画像認識のモデルを転用して高品質な音声表現を獲得できているのがすごいと思います。
参考:プロジェクトページ。様々なデモが見られます。また、実装と訓練済みモデル、使用したデータセットが公開されています。
自然言語処理系
2016年は機械翻訳が大きく進歩した年だったと思います。
言語モデル
コンピュータに「言葉らしさ」を判定させる重要な研究分野です。
Pointer Sentinel Mixture Models(2016/9)
直近の文脈に出現した未知語も利用することが出来るPointer Sentinel Mixture Modelを提案した論文です。
また、言語モデルの評価のための大規模なデータセットであるWikiTextの作成・公開も行っています。
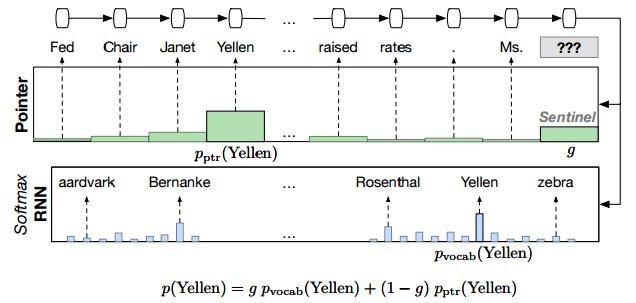
Pointer Sentinel Mixture Models Fig. 1.
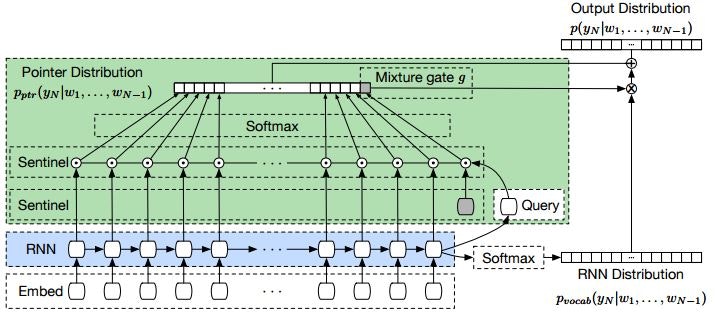
Pointer Sentinel Mixture Models Fig. 2.
ニューラルネットを用いた言語モデルでは、Softmax層を用いて次に出現する単語の確率を予測しますが、事前に決めた語彙からしか単語を予測できないという問題点があります。つまり、語彙にない未知語は全く予測を行えません。
この解決のために提案されたPointer Networkでは、以前に出現した単語にAttentionを行い、以前に出現した単語(語彙に無くても良い)も出力可能にします。
この研究ではそれをさらに発展させ、次に出現する単語を「事前に定めた語彙から決定する」か「以前に出現した単語から決定する」かを、現在の文脈から判定することを行います。どちらを重視するかはMixture gate の出力gによって重み付けを行います。
また、この研究では言語モデルの評価用データセットであるWikiTextを作成・公開しています。このデータセットは、言語モデルの評価によく使われるPenn Treebank dataset(PTB)よりも、より現実的で多くの語彙数のあるデータセットで評価を行えるようにする目的で作成したそうです。
評価では、PTBとWikiTextを用いて比較実験を行っています。過去のState of the artの手法に比べて少ないパラメータ数でより良いperplexityを示しました。
Pointer Networkの存在を知らなかったため、未知語にも対応できるようになっていることに大変驚きました。Attentionの応用力の高さはすごいですね。
LightRNN: Memory and Computation-Efficient Recurrent Neural Networks(2016/10)★
より効率的なRNNのコンポーネント、LightRNNを提案した論文です。

LightRNN: Memory and Computation-Efficient Recurrent Neural Networks Fig. 1.
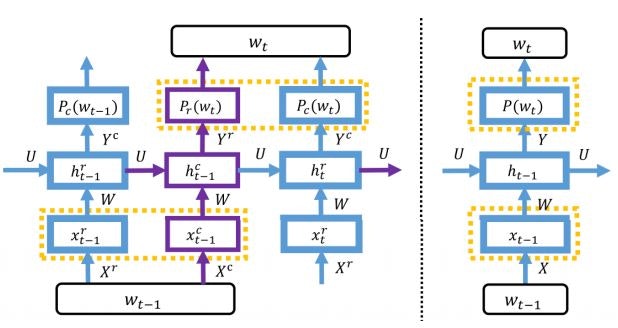
LightRNN: Memory and Computation-Efficient Recurrent Neural Networks Fig. 2.
従来のRNNを用いた言語モデルは、語彙数が多くなるとパラメータの数も非常に多くなり、学習が非効率的なものになります。
そこで、単語の分散表現を二種類のコンポーネントを用いたEmbeddingの複合により求めます。これにより、|V|個の単語を2√V個のベクトルで表現することができるようになり、パラメータ数の大幅な削減ができます。
このアプローチでは、「どのようなベクトルのペアでどの単語を表現するようにするか(上図Fig.1.のテーブルをどのように作るか)」が重要な課題になります。この論文では、ランダムに単語を割り当てた後、"一定回数訓練を繰り返す→単語の配置を変更する"という処理を繰り返すことで単語の配置を決定しています。
評価では、既存手法とパラメータ数とperplexityを比較しています。BlackOut for RNNでは4.1G個のパラメータ数が必要なのに対して、LightRNNでは41M個のパラメータでこれを上回るperplexityを示しています。また、訓練時間も既存手法の半分以下となっています。
応用性のとても高そうなアプローチだと感じます。
QUASI-RECURRENT NEURAL NETWORKS(2016/11)★(2016/11)
RNN(LSTM)の機構をCNNで再現するQRNNを提案した論文です。
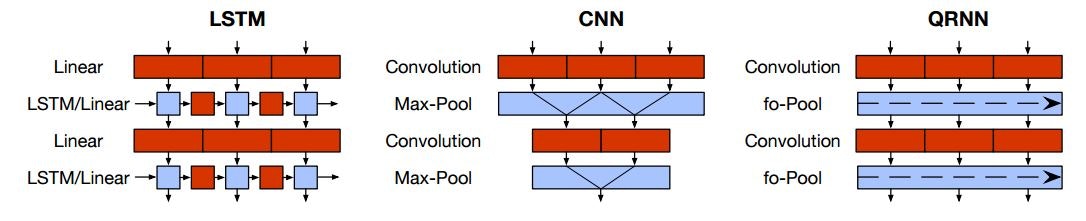
QUASI-RECURRENT NEURAL NETWORKS Fig. 2.
単語の分散表現に対して畳み込みを行い、LSTMでいうinput, forgat, output gateに対応する値を計算します。過去の値と現在の値をマージする部分は、fo-poolingというアプローチを提案しており、Linear(行列積)を用いずにLSTMの動作を再現しています。
CNNを使って行列積を使わずLSTMを再現することで、並列計算が可能になる、隠れ層の分析が容易になるなどのメリットが有ります。
評価では感情分類、言語モデル生成、機械翻訳のタスクで行われています。いずれのタスクも短い訓練時間でLSTMと同等かそれ以上のスコアを示しました。
非常に高速で動作も良好ですので、今後の応用が期待されます。
参考:公式の紹介ブログ。chainerコード付き。
参考:日本語解説記事+コード。解説が背景から書かれており非常にわかりやすいです。tensorflowのコード付き。
機械翻訳
GoogleがGoogle翻訳をDeepLearningベースのモデルに変更したことで話題になりました。
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation(2016/9)
機械翻訳のための大規模なモデルであるGNMT(Google's Neural MAchine Translation)を提案した論文です。
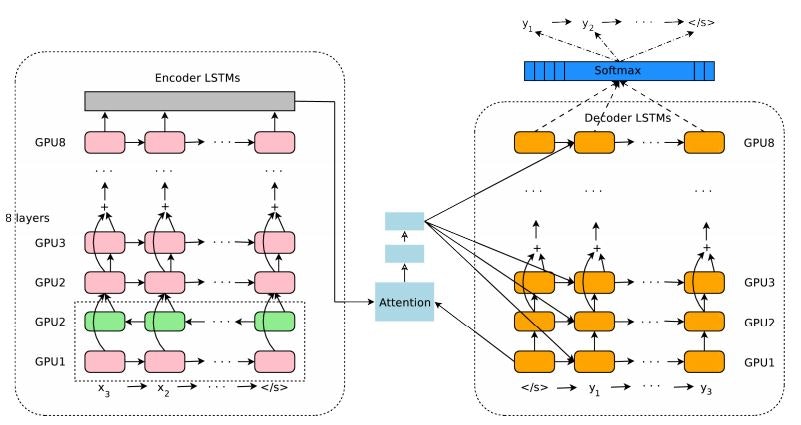
GNMTはEncoder-Decoder型のモデルです。Encoder、Decoder共に8層のLSTM(Encoder側は最初の層だけBi-directional)を用いており、Decoderへの入力はEncoderの出力から計算したAttentionを用いています。非常に深いモデルのため、Residual Connectionを活用しています。
使われている手法はいずれも特に新しいものではありませんが、とにかくモデルがでかい、深い。このモデルの訓練方法を提案したことが大きな貢献かと思われます。
評価では、BLUEを用いてGNMTが既存手法より良い精度であることを示しています。
ここまでするのか、と思いました。
参考:英語の解説記事。GNMTを理解するために非常に良い記事です。
+αの話題
GNMTで作成した中間表現を用いることでZero-Shot な翻訳(A⇔B、B⇔Cの翻訳モデルを訓練し組み合わせることでA⇔Cを翻訳)がある程度行えると報告されています。非常に興味深い話題です。
参考:Zero-Shot Translationの論文
参考:英語の紹介記事
参考:日本語の紹介記事
Neural Machine Translation in Linear Time(2016/10)
Dilated Convolution Networkを用いた機械翻訳モデルであるByteNetを提案した論文です。
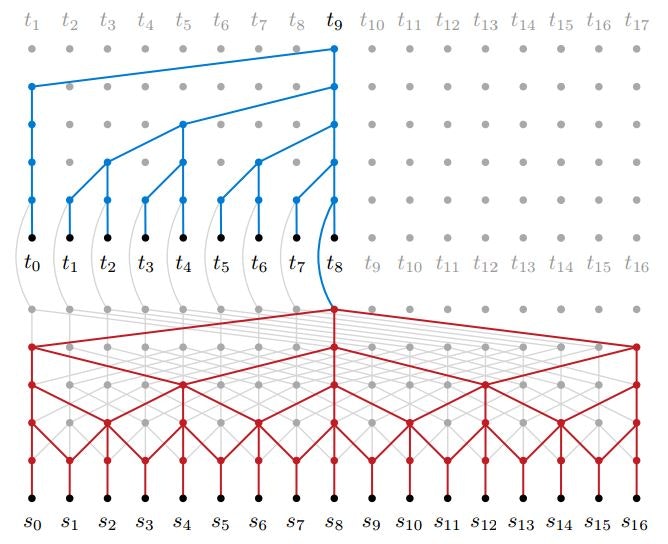
Neural Machine Translation in Linear Time Fig. 1.
ByteNetもEncoder-Decoder型のモデルです。どちらにもDilated Convolution Networkを用いており、より多くの文脈の情報を用いて翻訳を行うことができるようになります。
Decoder側のネットワークは過去から未来の方向の情報は使っていません(Mask Convolutionというそうです)。
評価では既存手法と負の対数尤度やBLUEの尺度で比較をしています。GNMTなどには負けていますが、Attentionを用いたRNNによるEncoder-Decoder型のモデルよりも高い精度を示しました。
機械翻訳など言語処理系のニューラルネットはRNNを用いるアプローチが多いですが、QRNNやByteNetなど畳み込みを用いたアプローチでも十分に使えることがわかりました。
今後の主流となっていくのでしょうか?
参考:日本語解説記事
参考:実装その1
参考:実装その2
どちらもtensorflow実装です。
強化学習系
DeepMindが強すぎます。
Mastering the game of Go with deep neural networks and tree search
深層強化学習を用いて"碁"のプレイを学習する手法を提案した論文(Natureに掲載)です。"AlphaGo"という名前で有名になりました。
このシステムは膨大なデータと訓練時間が必要になるいくつものステップを経て構築されています。おおよその手順は以下の通り。
- 大量の盤面データ(多い場合で3000万)を用いて、ある盤面の次の一手を予測するSL policy networkを訓練する
- 1.で作成したネットワーク同士を自己対戦させて強化学習を行い、より良い次の一手を予測するRL policy networkを訓練する。
- 1.と2.で作成したネットワークを用いて訓練データ(3000万盤面)を自動生成し、盤面の良し悪しを評価するvalue netwrokを訓練する。
実戦では、上記の手順で訓練したネットワークに、将棋や囲碁のAIで良く用いられるモンテカルロ木探索を適用し、有効手の検索を行っています。
評価では、既存の様々な囲碁のプログラムと対戦し、その結果を出しています。また、その結果からプログラムの強さをレーティングで表しています。最終的には、囲碁のトッププロであるイ・セドル氏を超えるレーティングを示しました。
参考:日本語の解説記事
解説が非常に詳しいとても良い記事です。AlphaGoの訓練の途方も無さを感じられます。
Neural Architecture Search with Reinforcement Learning(2016/11)★
あるタスクを解くためのニューラルネットのより良い構造を強化学習で獲得する手法を提案した論文です。
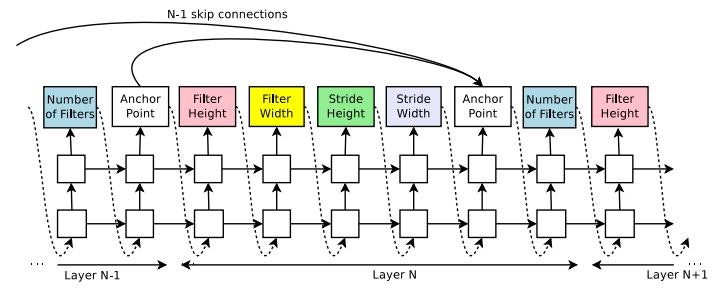
Neural Architecture Search with Reinforcement Learning Fig. 4.
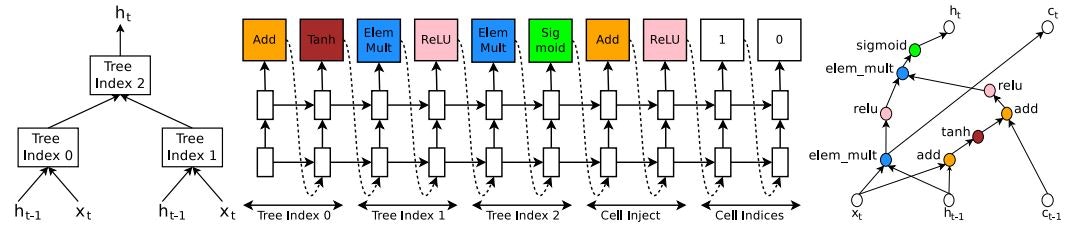
Neural Architecture Search with Reinforcement Learning Fig. 5.
pix2pixでも述べた通り、現在は人間がタスクに合わせてニューラルネットの構造を設計しています。この研究は、ニューラルネットの構造自体もニューラルネットで設計してしまおう、という非常に挑戦的なものです。
ネットワークの構造の設計にはRNNを用います。ニューラルネットの構造の要素(各種パラメータ、使用する演算や活性化関数等)を一つずつ予測し、それを1層ずつ繰り返すようなモデルになっています。上図Fig.4.はCNNの、Fig.5.はRNNの構造を設計する例です。
このモデルの訓練のための報酬は、設計したニューラルネットで任意のデータセットを評価したときのAccuracyを用います。つまり、報酬の計算の為にネットワークの訓練が必要になります。当然、膨大な訓練時間がかかってしまうため、モデルを非同期で並列に訓練するためのアプローチも示しています。
評価ではCIFAR-10を用いた画像分類と、PTBを用いた言語モデル作成の二種類のタスクに取り組んでいます。CIFAR-10のタスクでは、DenseNetに匹敵するError rateを示しました。PTBのタスクでは過去の比較手法を上回るPerplexityを示しました。
ただし、いずれのモデルも人間が設計したモデルよりも多いパラメータ数となっていました。
まだまだ根本的な問題は多いですが、シンギュラリティの可能性を感じました。
論文内で「訓練時にはGPU800枚をぶん回した」という怖い記述があり呆然としました。やってることを考えるとこのくらいしないとだめそうですが…。
ニューラルネット応用系
特定の分野に拘らずに精度や速度の向上を図る等、DeepLearning自体の可能性を追求する研究をまとめました。
汎用的なDeepLearning手法
汎用的というと語弊がありますが、ある特定のタスクに拘らずに使用できる手法です。
Hybrid computing using a neural network with dynamic external memory (2016/10)★
メモリ構造を持った汎用性の高いモデルであるDNC(Differentiable Neural Computers)を提案した論文です。
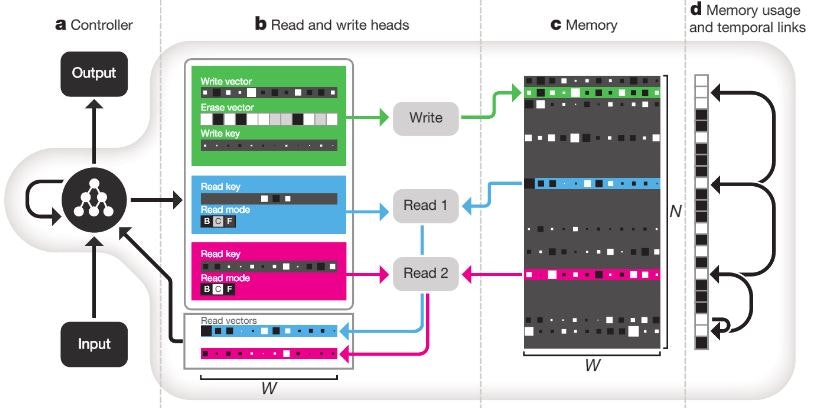
Hybrid computing using a neural network with dynamic external memory Fig. 1.
こちらの研究の概要紹介は他の記事を参照ください。
力尽きました…。
参考:Deepmindの紹介記事
参考:日本語解説記事1
参考:日本語解説記事2+chainer実装
参考:日本語解説記事3(未完)
最適化アルゴリズム
いずれもDeepLearningに必要不可欠な要素です。
多くの研究が出ていますが、特にインパクトのあったものをまとめます。
Learning to learn by gradient descent by gradient descent
ニューラルネットの訓練にどの最適化アルゴリズムを使用するかを学習する手法を提案した論文です。
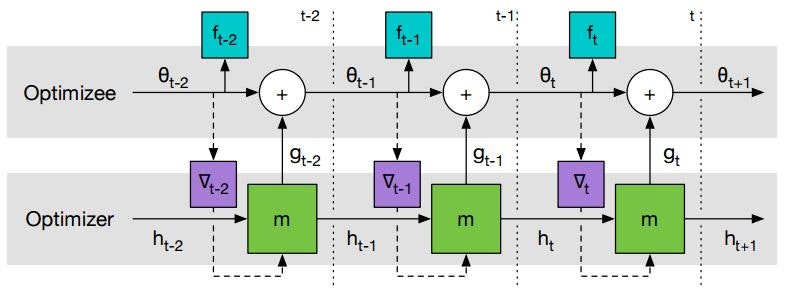
Learning to learn by gradient descent by gradient descent Fig. 2. (2016/6)
この手法ではLSTMを用いたRNNを使用します。図の二層目(Optimizer)でRNNを用いて最適化のための最適なパラメータ(の差分)を予測します。一層目(Optimizee)で実際にそのパラメータを使用して勾配の計算を行います。
Optimizerのネットワークを訓練することで、どのような場合にどのようにパラメータを更新すれば良いのか、ということをネットワークに学習させることが目的です。
評価ではCIFAR-10などのタスクを解く際に、様々な最適化アルゴリズムを用いてネットワークの訓練を行い、lossの下がり方の比較を行っています。提案手法が最も安定してlossを最小化できることを示しています。
どのような誤差関数でもこの手法が適用できるかが気になりました。
※12/18 追記
参考:tensorflow実装
Improving Stochastic Gradient Descent with Feedback (2016/11)★
目的関数からのフィードバックを用いる最適化アルゴリズム、Eveを提案した論文です。
最適化アルゴリズムについて、まだキチンと理解できていないため、概要は省略します。申し訳ありません…。
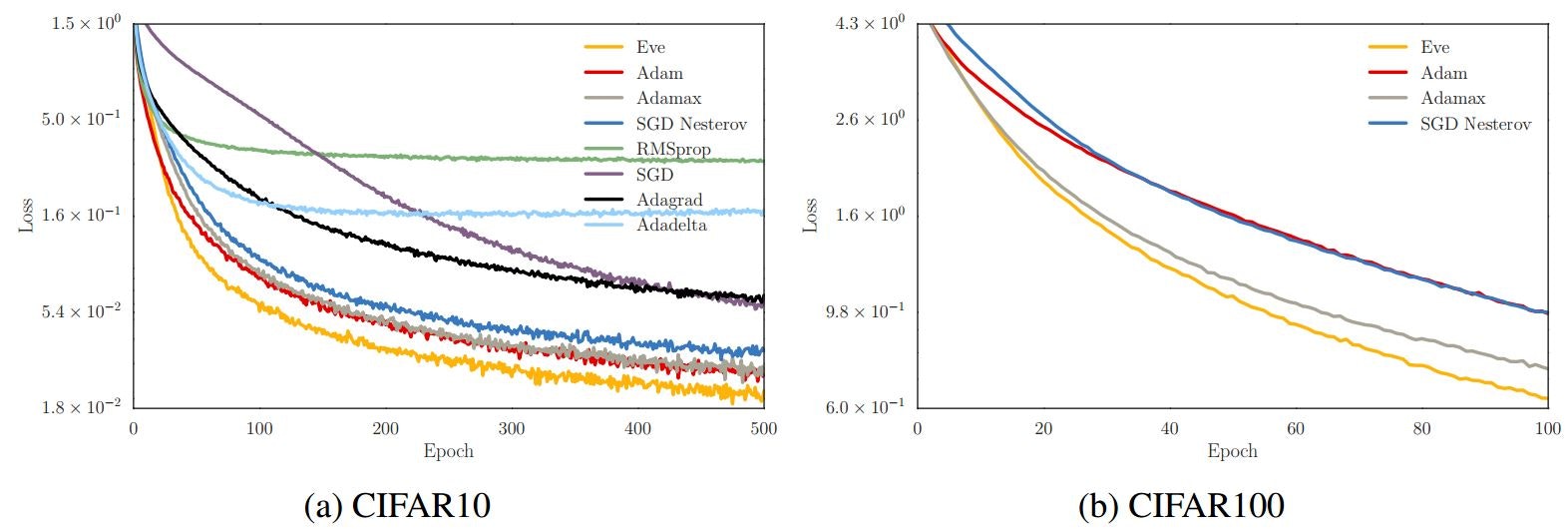
Improving Stochastic Gradient Descent with Feedback Fig. 1.
評価ではCIFAR-10,100の訓練に様々な最適化アルゴリズムを用いて、提案手法が最も安定して訓練ができたことを示しています。
ニュールネットの訓練のための新しいデファクトスタンダードになりそうです。
私事ですが、私はこの手法の名前が大好きです。
参考:tensorflow実装
参考:chainerでのPR。私はchainerを主に使っているため、マージが待たれます。
ニューラルネットの圧縮・高速化
サイズが大きくなりがちなDeepLearningのモデルを精度を保ちつつ圧縮する技術は、モバイル端末への適用や訓練等の省力化に関わる重要なものだと感じます。
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1 (2016/2)
[XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks] (2016/3)(https://arxiv.org/abs/1603.05279)
非常に似ているため二本続けて。
1本目はモデルのパラメータをすべて+1と-1のみで表現するBinaryNetを提案した論文です。一つのパラメータを1bitで表現できるため、メモリ使用量が大幅に削減できます。また、掛け算器をXNORに置き換えることができ、処理の高速化ができます。2016/2月に公開。
2本目はBinaryNetを改良して精度と計算速度を向上させたXNOR-Netを提案した論文です。内容はあまり理解できていないため、参考記事を参照してください…。2016/3月に公開。
評価では、XNOR-Netを用いることでAlexNetと比較して画像分類タスクの精度が11%落ちるかわりに、メモリ使用量が1/64(AlexNetが倍精度の場合)、計算速度が58倍(CPUを用いた場合)となることを示しました。
パラメータが二値のみでもある程度予測が行えることがすごいと思いました。
訓練後のフィルタがテトリスっぽいと思いました。

参考:BinaryNet 日本語解説記事
参考:BinaryNet 公式実装
参考:BinaryNet chainer実装
参考:XNOR-Net 日本語解説記事1
参考:XNOR-Net 日本語解説記事2
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
非常に省メモリなネットワークであるSqueezeNetを提案した論文です。
BinaryNetと同時期に出た研究ですが、こちらは畳み込み層のフィルタサイズやチャネル数を変更するなどしてパラメータの削減を試みています。
評価ではImageNetを用いた画像認識のタスクに取り組み、AlexNetと比較して同程度の精度を保ちつつメモリサイズを最大1/461(0.5MB)に出来ることを示しました。
おわりに
本当はまだまだ書きたい内容があったのですが、分量と体力の関係で断念しました…。
改めて見返してみると、とても趣味の出ている選択になってしまったと反省しています。
この記事を書いている最中にも新しい話題がどんどん出てくるのがこの分野の怖いところです。
最先端の手法は中々追えないですが、今後も頑張ってキャッチアップして話題についていきたいです。