Bytenetとは2016/10/31にDeepMindから投稿された論文,"Neural Machine Translation in Linear Time"にて提案された機械翻訳をするニューラルネットワークです.音合成をするニューラルネットワークとして提案されたWaveNetと同じように,Dilationを導入することによって,遠い時系列の相関を学習することができます.さらに,学習にかかる時間が,文章の長さにたいして線形となっており,比較的速いと言われています.
Bytenetの概要
翻訳タスクをするニューラルネットワークです.元の言語の文字列を${\bf s}=s_0,\dots,s_{N_s}$として,翻訳後の言語の文字列を${\bf t}=t_0,\dots,t_{N_t}$とすると,$p({\bf t}|{\bf s})$を推定するタスクです.
この確率分布をByteNetでは
p({\bf t}|{\bf s})=\prod_{i=0}^{N_t} p(t_i|t_{<i},{\bf s})
として$N_t$個の確率分布に分けて推定を行います.
著者は以下の図を用いて,ByteNetについて説明しています.
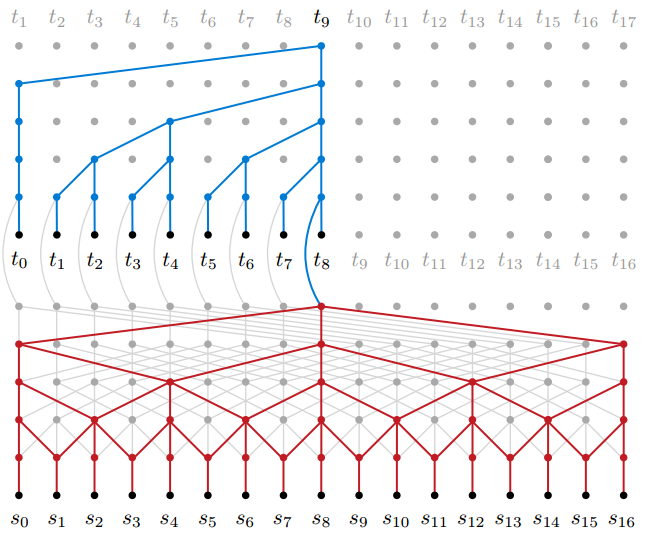
下半分はsource network,上半分をtarget networkといいます.言語翻訳ではエンコーダー-デコーダーモデルという考え方を行います.エンコーダーは翻訳前の文から,その文の意味を抽出して別の表現に変換するもので,デコーダーはその表現を翻訳後の文に変換するものです.ByteNetではsource networkがエンコーダー,target networkがデコーダーになります.
どちらも,Dilationという仕組みを利用して,畳み込みを行っています.Dilationのメリットは比較的少ない層,少ない結合でかなり遠い場所との相関をモデリングできることです.1層目では1つ隣のユニットの出力と一緒に次の層への入力としています.さらに2層目では2つ隣のユニットの出力,3層目では4つ隣のユニットの出力,・・・というように,次の層へいくごとに,入力の数は変化させずに,入力に使うユニットとの距離を指数的に増やしています.これによって層の数を増やすごとに指数的により遠い場所との相関を学習することができます.
source networkの良いところは,文の長さによって,出力する中間表現のサイズも変化することです.リカレントニューラルネットワークでこれを行うと,同じサイズの中間表現になってしまいます.長い文も,短い文も同じサイズの表現に変換すると,文の解像度が文の長さによって違ってきてしまうという問題が生じてしまいます.長い文の方が多くの情報を持っているはずなのに,それが中間表現に変換すると,短い文のそれと情報の量が同じになってしまいます.しかし,ByteNetでは文の解像度が保たれたまま翻訳を行うことができます.
下半分のsource networkと比較して,上半分のtarget networkでは右のユニットの入力は使っていないことがわかります.これは,masked convolutionと言われるものです(maskは隠すの意).なぜこのようなことをしているのかというと,未来の情報は使いたくないからです.上半分のtarget networkの出力は,$p(t_i|t_{<i},{\bf s})$を表しており,$t_{i+1},t_{i+2},\dots$は$t_i$には関係ないです.masked convolutionをすることで,未来の関係がない情報を使わずにモデリングしています.
まとめ
Dilationやmasked convolutionなどを適用することにより,速く動く,遠い時系列の相関を取り込める,文の解像度が保たれるといったことがByteNetによって可能になりました.今後は機械翻訳以外の自然言語のタスクでの応用が期待できるかもしれません.とても面白いので近いうちに実装できればと思っています.