RNN「これってもしかして」
CNN「わたしたちのモデルが・・・」
「「入れ替わってる~~~!?」」
というわけでQRNN、QUASI-RECURRENT NEURAL NETWORKSとは、RNNの機構をCNNで「疑似的(QUASI)に」実装するというモデルです。これにより、既存のRNN(というかLSTM)が抱えていたいくつかの問題の解決を試みています。
元論文は以下となります。
作者の方のブログにChainerのサンプルコードがあったので、それを元にTensorFlowで実装してみました。早く動かしたい!という方はこちらを見てみてください。
icoxfog417/tensorflow_qrnn
(Starを頂ければ励みになります m(_ _)m)
本記事では、この研究のモチベーションとそのアプローチについて、順を追って解説していきたいと思います。
背景
RNNはその仕組み上、一要素(一単語)ごとに処理しないといけないので並列処理ができません(下図参照)。

また、前回隠れ層からの入力を「重みをかけて」受けとることで、隠れ層はいろんな単語の情報がミックスされた、謎の何かに変貌していきます。ここは少しわかりにくいので、図解します。
以下の図はベクトル(隠れ層=左の縦棒)に行列(重み=U)をかける様子を図式化したものです。計算後の右のベクトルの第一要素は、元のベクトルのすべての要素に重みをかけて計算されているのがわかると思います。
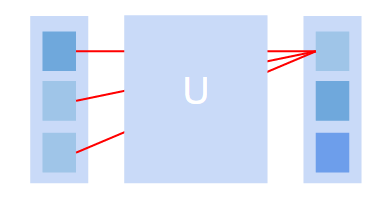
こんなことをすると、もはやベクトルの第一要素が何を意味していたのかなんて、だんだんとあいまいというかいろんな情報がミックスされた謎の何かになってきます。これは、中の仕組みを理解しようとするとき大きな障害になります。
こうした問題を解決しよう!として提案されたのが、CNNを活用したQUASI-RECURRENT NEURAL NETWORKS、QRNNになります。
ポイント
論文におけるポイントは、以下の2点になります。何れも「新規」というわけではないのですが、伝搬の構成などは先行研究と異なります。
- RNNではなく、CNNを連続的なデータ(文章など)に対して適用する
- これにより並列計算が可能になります
- 重みを使わず伝搬することで、隠れ層の中の各要素を、他要素からの影響から独立した状態でキープする
- これにより隠れ層の分析(どの場所が活性しているかなど)が行いやすくなる
全体図としては、以下のような感じになります(ちょっと端折っている箇所もありますが)。

中では、畳みこんだ後にLSTMライクな処理をいかに要素積で済ませるか、というところが述べられています。ここからは、論文中の式を追ってみていきます。
{\bf
Z = tanh(W_z * X)\\
F = \sigma(W_f * X)\\
O = \sigma(W_o * X)
}
これらはすべて、畳みこみの処理です。Z, F, Oの3つを作るということですね。これらは、ちょうどLSTMのinput, forget, outputに相当します。これらは時系列方向への畳みこみなので、フィルターのサイズが2の場合で、LSTMライクに書くと以下のようになります。
{\bf
z_t = tanh(W^1_z x_{t-1} + W^2_z x_t)\\
f_t = \sigma(W^1_f x_{t-1} + W^2_f x_t)\\
o_t = \sigma(W^1_o x_{t-1} + W^2_o x_t)\\
}
さて、これで並列計算はOKなので、あとはどう時系列を処理していくかです。当然、行列積は使いたくありません(↓これ)。


畳みこみの処理では、よくプーリングという手法を使います。これは、4つの領域があったらその中の最大を取る、など複数の領域があった場合に最大や平均などを取って値を集約するという手法です。こいつをうまく応用して、時系列(t-1とtなど)をいい感じにミックスさせます。
具体的に提案されているのは、以下のような手法です(dynamic average poolingというらしい)。
{\bf
h_t = f_t \odot h_{t-1} + (1 - f_t) \odot z_t \\
}
${\bf f_t}$(forget)の割合で、過去の${\bf h_{t-1}}$と${\bf z_t}$をミックスさせてやるということですね。これを論文中ではf-poolingと読んでいます。この他に、以下2つの変形が提案されています。
一つ目は、コンテキストを経由するfo-pooling
{\bf
c_t = f_t \odot c_{t-1} + (1 - f_t) \odot z_t \\
h_t = o_t \odot c_t
}
もう一つが、${\bf 1-f}$という適当な感じではなく、inputを書き込む割合をちゃんと考えるパターンです。
{\bf
c_t = f_t \odot c_{t-1} + i_t \odot z_t \\
h_t = o_t \odot c_t
}
これがifo-poolingになります。
基本はこの3タイプで、これ以外に論文中ではdropoutを組み込んだものや、DenseNetの機構を組み込む、Encoder-Decoderへの拡張といったことが述べられています。
結果
以下3つのタスクで効果を見ています。すべて、LSTMと同等かちょっと良いスコアになっています。
- Sentiment Classification: 感情分類
- IMDbという映画のレビューのデータセットを使用して検証
- Language Modeling: 言語モデル
- おなじみのPenn Treebankで検証
- Character-level Machine translation: 機械翻訳
- IWSLTという英語-ドイツ語のデータセットで検証
また、ベクトルを要素独立にしたおかげで、隠れ層の分析も行いやすくなりました。以下は、Sentiment Classificationを行っている際の隠れ層の様子です。色は、隠れ層の活性化を表しています。
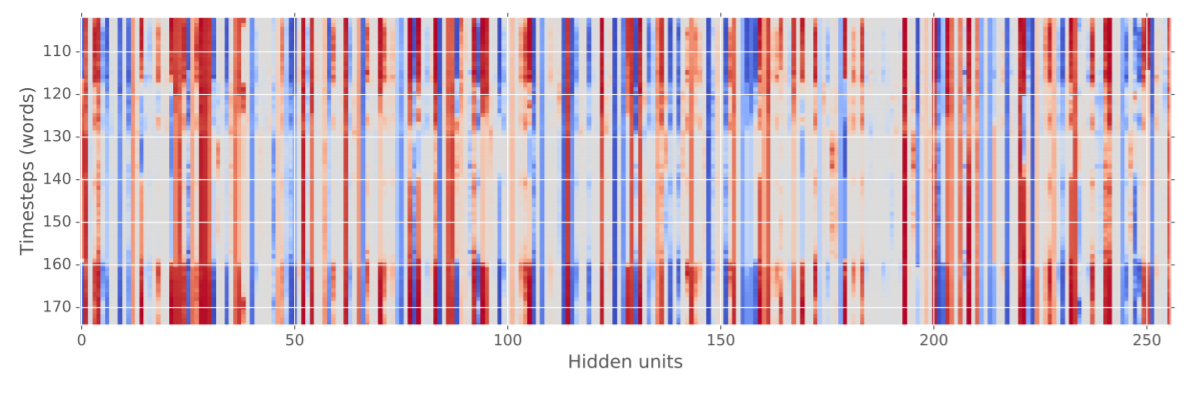
120~160近辺で全体的に薄くなっていると思いますが、この時word的に「否定的な」文言が出ていたらしく、そのあとおすすめだよ!みたいな文言が登場したことで再度活性化しています。こうした分析ができるようになったというのも、大きな利点の一つになります。
いかがだったでしょうか。このQRNNを使うことで、ニューラルネットワークがどのように学習をしているのかより理解することができるかもしれません。