Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, Yoshua Bengio
BinaryNetは、weightとactivationを2値化したhardware friendlyな**DNN(Deep Neural Network)**です。
論文ではactivationと書かれていますが、たぶん活性化関数の出力のことかなと思います。
要は重みにかけられる方の値です。
これにより以下の特徴が得られます。
・1bitなのでメモリを劇的に減らせる
・掛け算器をXNORに置き換えられる(回路規模、処理速度の両方の面で効果がある)
Algorithm
forward propagation
・weight $W_k$,activation $\alpha_k$は$-1$,$+1$に2値化する
・weightとactivationの積算値$s_k\leftarrow\alpha^b_{k-1}W^b_k$は2値化せずに、Batch Normalizationを行う
・Batch Normalizationの出力$\alpha_k$は、最終層以外2値化する。
back propagation
・$\alpha_k$での偏微分$g_{a_k}$では、$|\alpha_k|\le1$の時はスルーで、それ以外は遮断する。
・gradientは2値化しない
詳細は以下の通り。

Benchmark results
MLP on MNIST
・3 hidden layer
・4096 binary units
・LS-SVM output layer
・Batch Normalization
・Minibatchサイズは100
・ADAM Optimization
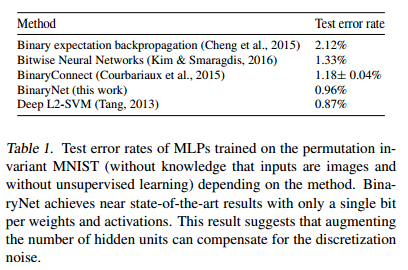
下記表はError Rateで値が小さいほど性能が良い。上3つもBinaryを使ったNetworkで、一番下はBinaryではないNetworkです。BinaryNetの結果がBinaryを使ったものの中では一番よく、BinaryではないDeep L2-SVMに近い値が出ている。
ConvNet on CIFAR-10
・Batch Normalization
・Minibatchサイズは50
・ADAM Optimization
・Data augmentationは使っていない(Datasetそのまま)
下記がアーキテクチャの詳細

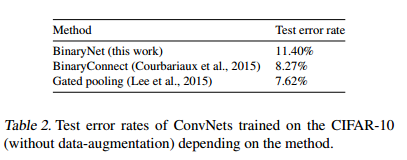
1番上が本手法、2番目が別の手法(論文の著者が前に発表したもの),3番目はBinary以外の手法。
結果を見ると他の手法の方が性能が良い。
ConvNet on SVHN
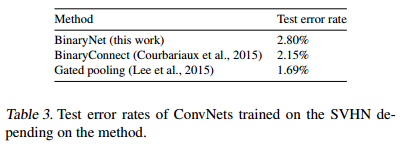
前述のConvNetと同じ構成だが、Convolution LayerのUnit数が半分になっている。
性能は前と同様に他の手法の方がよい。
高速化手法
話の内容は、
・掛け算器はXNORに置き換えられる
| A | B | Y |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
回路の$0/1$を数字の$-1/+1$と置き換えて考えると下記のようになり確かに掛け算がXNORで置き換えられます。
(@ashitani さんからコメントいただきました。ありがとうございます。)
| A | B | Y |
|---|---|---|
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| 1 | 1 | 1 |
・1ビットずつ愚直に計算しないで、32bitレジスタにデータを詰め込んで、いっぺんに計算すると速くなる
・1層目だけ入力が画像なので、binaryデータではないが、画像だと3channelで他の層に比べて少ないから、そんなに影響ない
・8bit入力データを1bitデータの集まりと考えて下記のよう、積算する順番を入れ替えるとさらに高速化できる
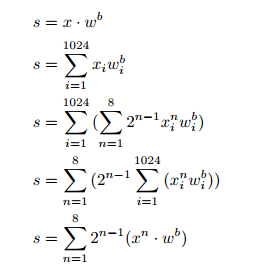
・積算はpopcountで高速化できる
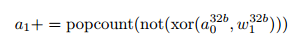
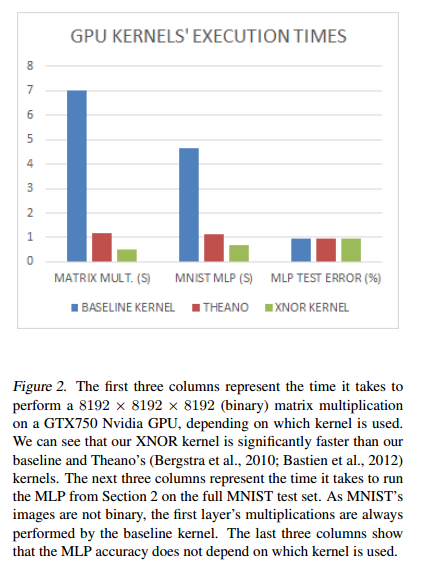
速度比較した結果は下記の通り。グラフは、左から、「行列の積の部分の速度比較」、「MNISTの速度比較」、「Error Rateの比較」になっている。
縦軸は、Theanoを基準に何倍になっているかを示している。これをみるとBinaryNetは、Baseline Kernelを使用した時と比べて、「MATRIX MULTI」で14倍速くなっている。Theanoと比べても2.5倍速くなっている。MNISTで比べると、Baseline Kernelを使用した場合と比べて、7倍速くなっている。
他の手法との比較
以下著者曰く
・Courbariaux et al. (2015); Lin et al. (2015)
・activationのしかも部分的にbinaryを使っているのに対し、こちらはweightもactivationもbinaryだからより効果的。
・BinaryConnectは学習が遅い
・MNISTの結果はBinaryNetの方がいい。
・ConvNetはBinaryNetの方が悪い。
・Soudry et al. (2014); Cheng et al. (2015)
・BackPropagationで学習していない(Expectation BackPropagationで学習)
・weightとactivationを2値化している
・weightの事後分布を最適化している
・性能を良くするために、複数の出力を平均している。(計算コストが大きくなる)
・binary expectation backpropagationは、MNISTではいい結果を出している
・Hwang & Sung (2014); Kim et al. (2014)
・3値化
・Kim & Smaragdis (2016)
・binary weightとactivationを使ったDNN手法で良い性能を出している
最後に
クラウドでGPUガンガン使ってやれればいいけど、限られた資源でDeep Learningを使おうとするとこういう技術が必要でしょう。
やっていることは単純なのに性能が出ているのが不思議です。
詳細はわかりませんが、Batch Normalizationで常に平均0、分散1になるように正規化しているのがいいのかなという気がします。ちがうかな?
論文のコードが公開されています。
https://github.com/MatthieuCourbariaux/BinaryNet
さらに、すでにPFIの岡野原さんによってchainerの実装も公開されています。
https://github.com/hillbig/binary_net