Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
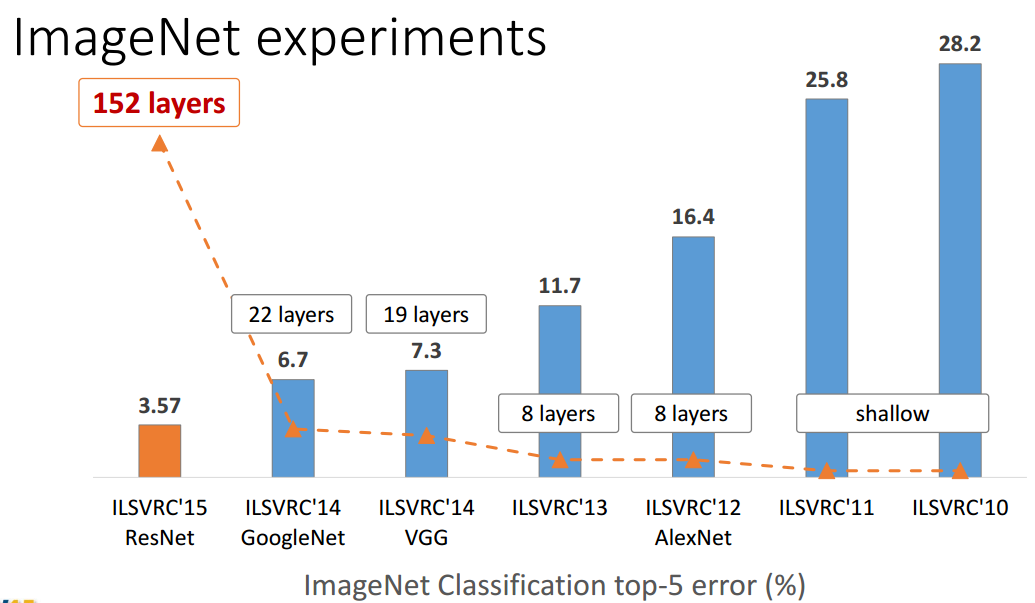
ImageNetのCompetitionで1位になったMSRAの論文
・network層をdeepにすることは性能向上に欠かせない。
・しかし、Deepにすると性能が向上せずに悪くなることが知られている。(下のグラフ)
・これらはOverfittingによるものではなく、勾配が0になったり、発散したりするため。
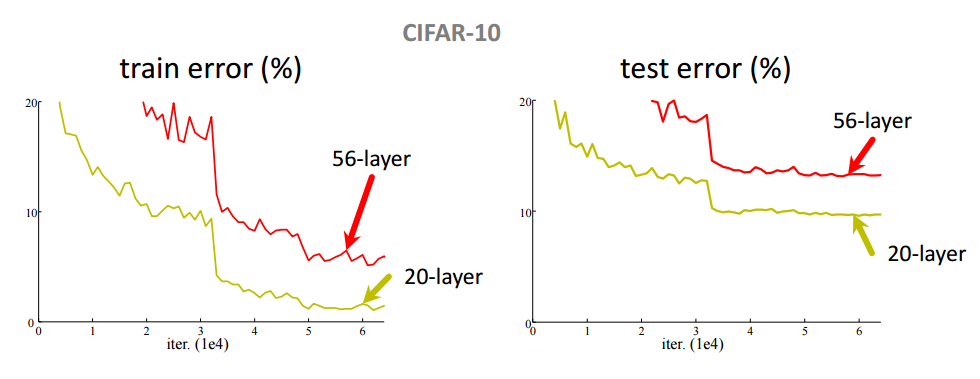
これを解決しようというのがこの論文の趣旨
Residual Network
普通のNetwork
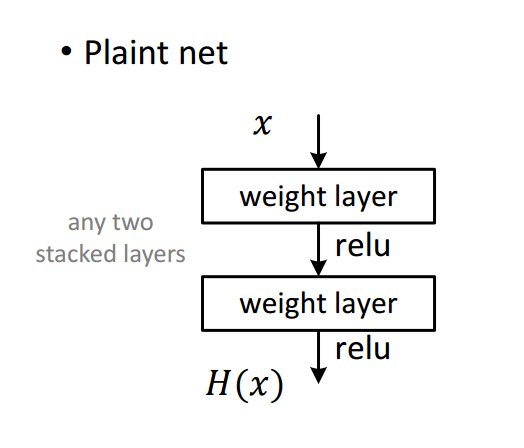
$H(x)$が所望するmapping(求めたい変換)
2 weight layerをH(x)になるように学習する
Residual Network
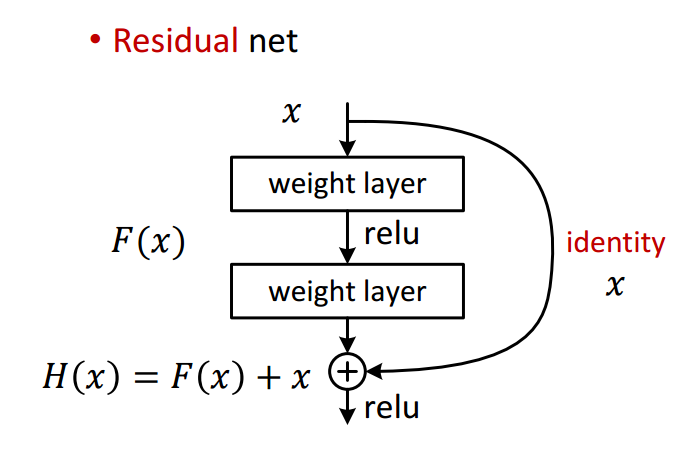
・$x$をshortcutして足し合わせると$H(x)=F(x)+x$とおける。
・2 weight layerを$H(x)$になるように学習するのではなく、$F(x)$になるように学習する
・もしidentity $x$が最適なら、weightは0になる
・かりに最適な関数がidentityに近いなら、微小な変化を見つけやすくするべき
入力から最適な出力学習するという問題を残差を学習するという問題に置き換えることで最適化しやすくした。
特徴
・Residual NetworkはShortcut connections付きfeed-forward neural network
・Shortcutは1から数Layer飛ばしてつなぐ
・これにより新たなパラメータも増えないし、入力をShortcutして足しているだけなので計算も複雑にならない。
・今までどおり、Backpropagationもできるし、実装も簡単だし、変更なしで今までのフレームワークが使える
・$F(x)$と$x$は同じ次元でなくてはならない
・$F(x)$と$x$の次元が異なる場合は以下の方法を使う
1. Zero Paddingで同じ次元にする
2. Projectionで同じ次元にする
・Residual Networkは、2または3層にする。1層だとLinear Layerになってあまり意味がない。
Network Architecture
・3x3のConv Filter
・入力と出力は同じサイズで、Filter数も同じにする
・出力サイズが1/2になる時は、Filterの数を2倍にする
・最終Layerはaverage pooling layerを介して、1000 unitのfully connected layerにつなぐ
・max pooling,hidden fully connected layer, dropoutはなし
・Simple Designでdeepにする。これにより計算コストはVGG netと比べて少ない
34Layerの時
| Network | FLOPs |
|---|---|
| VGG | 19.6 billion FLOPs |
| Residual Net | 3.6billion FLOPs |
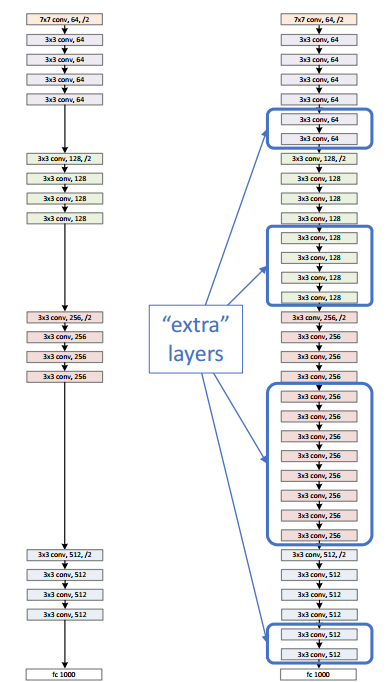
左が18layer、右が34layer
Experiments
ImageNet Classification
Training 1.28 million
Validation 50K
Test 100K
18layerと34layerでのPlainNetとResNetの比較
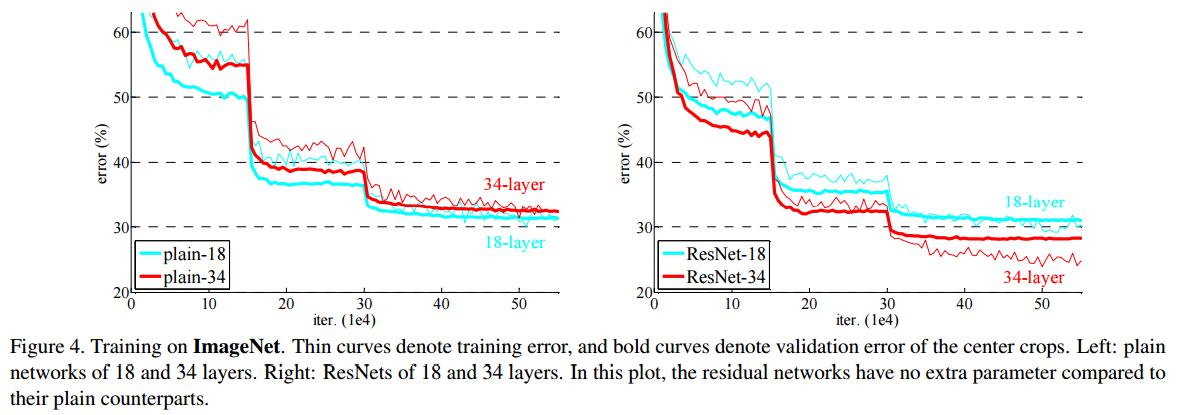
・細線がTraining Set、太線がValidation Setの結果
・左がPlainNetで右がResNetの結果
・PlainNetでは、34layerの方が結果が悪いが、ResNetでは34layerの方が結果が良い
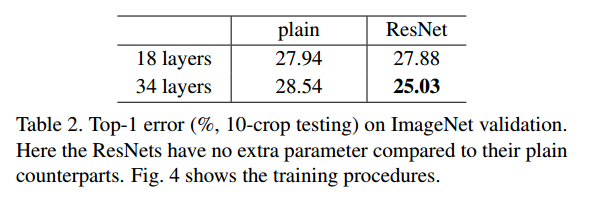
Validation の結果からResNetでは、よりDeepな方が性能がよくなっている
Identity vs Projection Shortcuts
A. Zero Padding
B. Dimensionの変化があるところだけProjection
C. 全部Projection
3つの性能比較
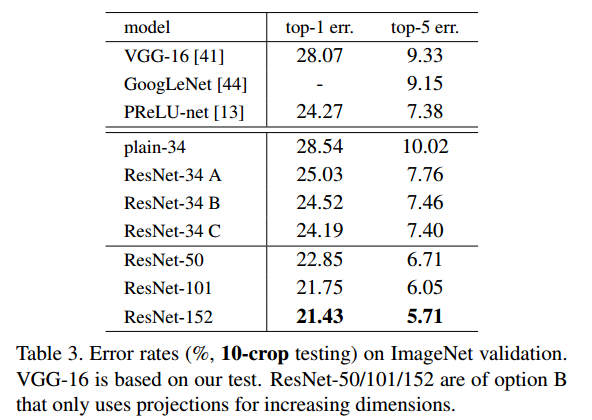
Cが一番結果が良いが、CはParameterがすべてのLayerで増えるので、それに見合うほと性能がよくなっていないということで、これ以降はAとBだけ使う
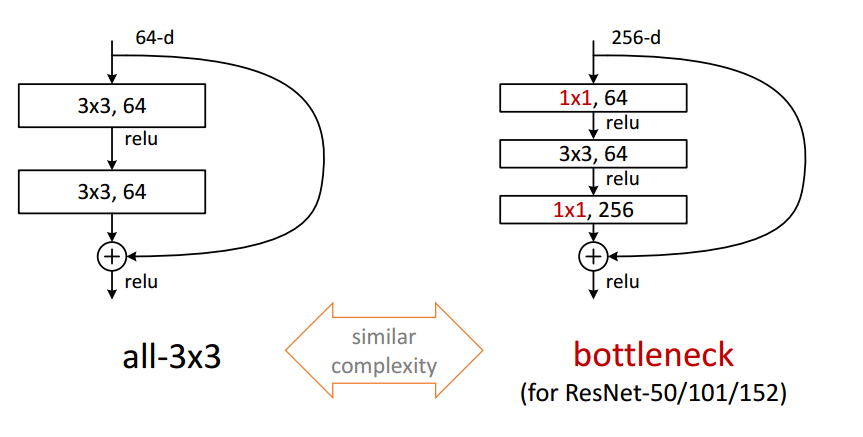
Deeper Bottleneck Architectures
右と左では計算コストはほとんど同じなので、よりDeepなbottleneckを使う
Bottleneckといっても性能がボトルネックではなくFilter数が中間で少なくなっているという意味

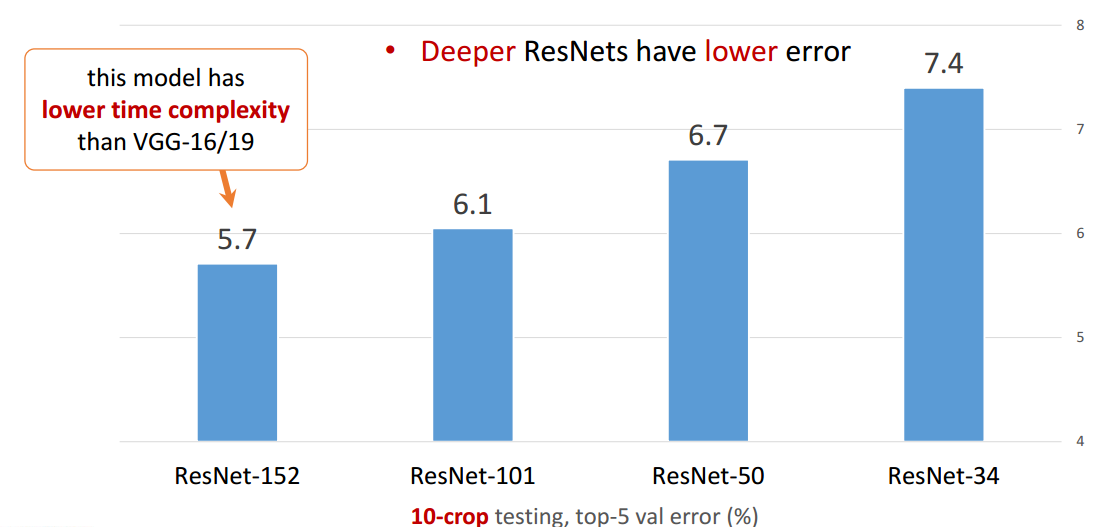
Validation Setの結果
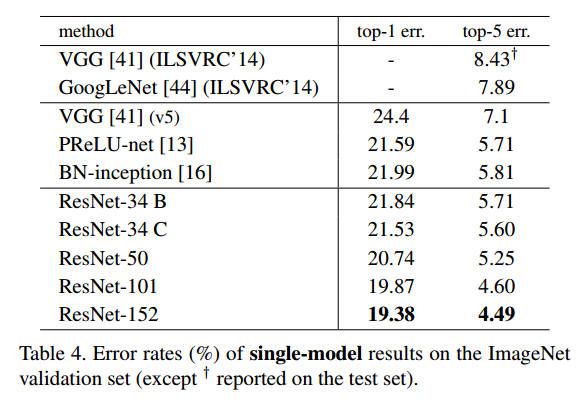
Test setの結果
CIFAR-10
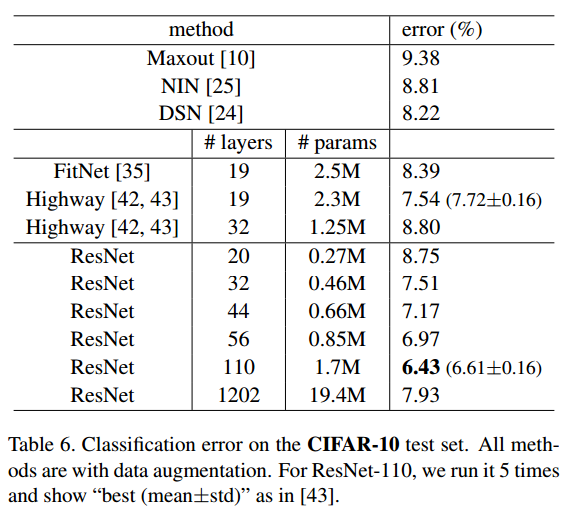
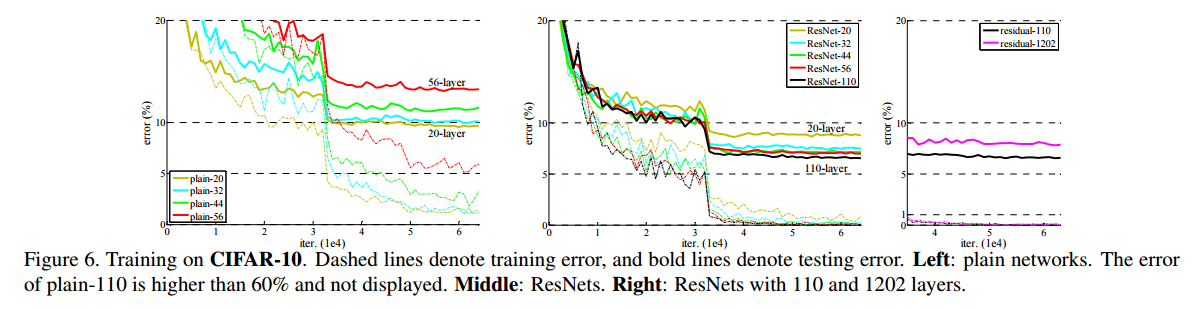
・左がPlainNet,真ん中がResNets、右はResNetsの110layerと1202layerの結果
・こちはもImageNetと同様にPlainNetではDeepな方が性能が悪くなっているがResNetではDeepな方がよくなっている
・1202layerの時は性能が悪くなっている。これはDataSetの大きさに対してDeepすぎるためかもしれないとのこと。
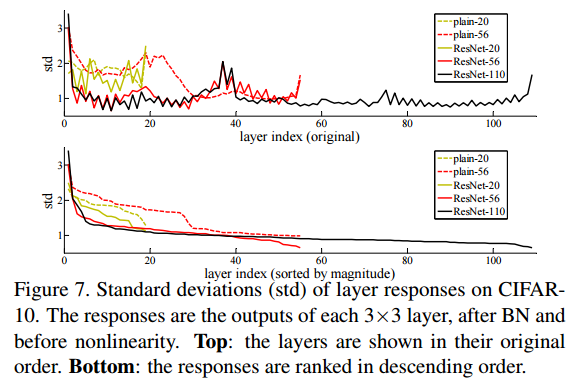
・Layer Responseの標準偏差
・ResNetの値は0に近く、小さい値になっている
・上は、Layerの順番のまま並べたとき、下はソートして並べた時
最後に
Deeperな方がWiderより性能がいいらしいです。最近の論文に書かれているとのことです。(読んでないので詳細は不明)
論文中にも出てきますが、Shortcutな方式は、ResNetの他にHighway netやInception netがあるそうです。
ただ深くではなく、問題を解きやすいようにreformulationしたのがポイントのようです。