Deep Networks with Stochastic Depth
この論文は、Very Deep なネットワークの学習を効率よく行うためのもので、特にResNetを対象としています。
この論文では確率的にLayer数(Depth)を変えることにより、汎化性能を高め同時に計算時間を短縮することで学習の効率をあげています。DropoutがノードをOffさせることで横方向にネットワークを小さくしているのに対し、Stochastic DepthはLayer数を変更することで縦方向にネットワークを小さくしています。
近年はより性能を向上させるためにLayer数を増やしてよりDeepなネットワークにする傾向にあります。しかしvery deepなモデルは以下の問題があります。
- 勾配の消失
繰り返し小さなWeightが乗算されることにより勾配が消失するというもの
対策には、「careful initialization」、「hidden layer supervision」、「Batch Normalization」がある。 - featureの再利用の減少
勾配消失はBack Propagationの時の問題にですが、こちらはForward Porpagationの時の同様の問題を指しています。forward propagation時に、randomに初期化されたWeightが何度も乗算されることにより伝わる情報が消失するという問題です。対策としてはResNetで用いられているIdentity mappingがあります。 - training時間の増大
ネットワークがVery Deepになるほど学習時間が問題になります。152layerのResNetは学習に数週間を要します。
shorter networkは情報の伝播が効率よく行われ、学習も効率的かつ実用的な時間で行える反面、複雑な問題に対してNetwork自体の表現能力が十分でないという問題があります。逆にDeepなNetworkは構造を複雑にすることができる反面、学習が非常に難しく時間も沢山かかります。
この論文では、学習時はNetworkをShortにし、Test時はNetworkをDeepするというのがコンセプトです。Deep ResNetの構造を利用して実現しています。
Residual Networks(ResNets)
ネットワークをidentity functionのPathと残差のPathに分岐、合流させることで勾配の消失を抑え、よりDeep な構成が可能になるというものです。
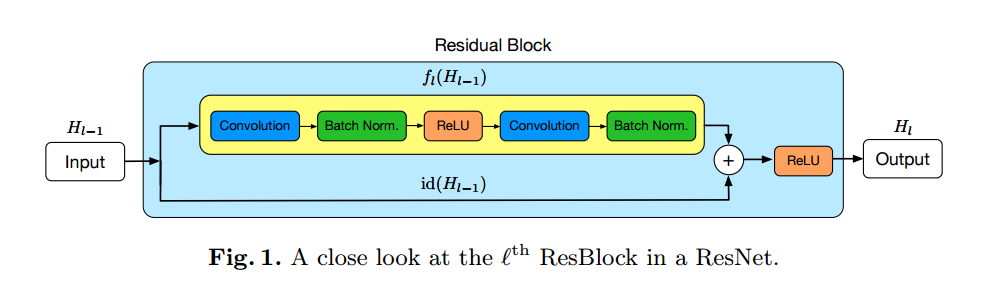
式で書くと下記のようになります。
$H_{l-1}$は入力、$H_l$は出力、$id(\cdot)$はidentity transformation、$f_l(\cdot)$はconvolutional transformationです。
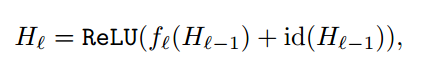
Dropout
Dropoutは確率的にhidden nodeやconnectionをdropさせることにより汎化性能を向上させるというものです。
Deep Networks with Stochastic Depth
・基本はminibatch毎にrandomにlayerをskipさせます
・残差のPathをrandomにskipさせ、identity skip connection pathは変えません。
式で書くと下記のようになります。
ここで$b_l$はbernoulli random 変数です。
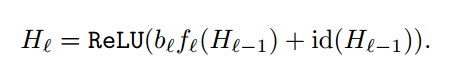
残差のPathを残すかSkipするかは、survival probability $p_l$によって決めます。$p_L$をhyper parameterとして、後段になるほど$p_l$が小さくなる(skip されやすくなる)ようにします。
式で書くと下記のようになります。
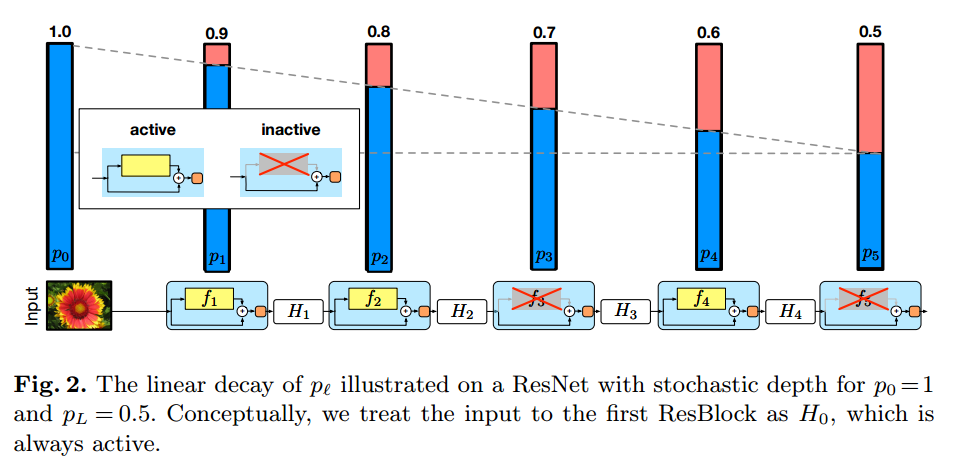
Training time saving
$p_L=0.5$の時に学習時間は約25%短縮されます。$p_L=0.2$の時は40%短縮されます。
Stochastic depth during testing
test時は出力を$p_l$でre-calibrationします。Dropoutと同じ感じです。
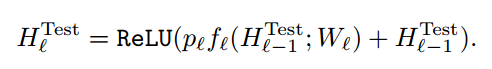
Results
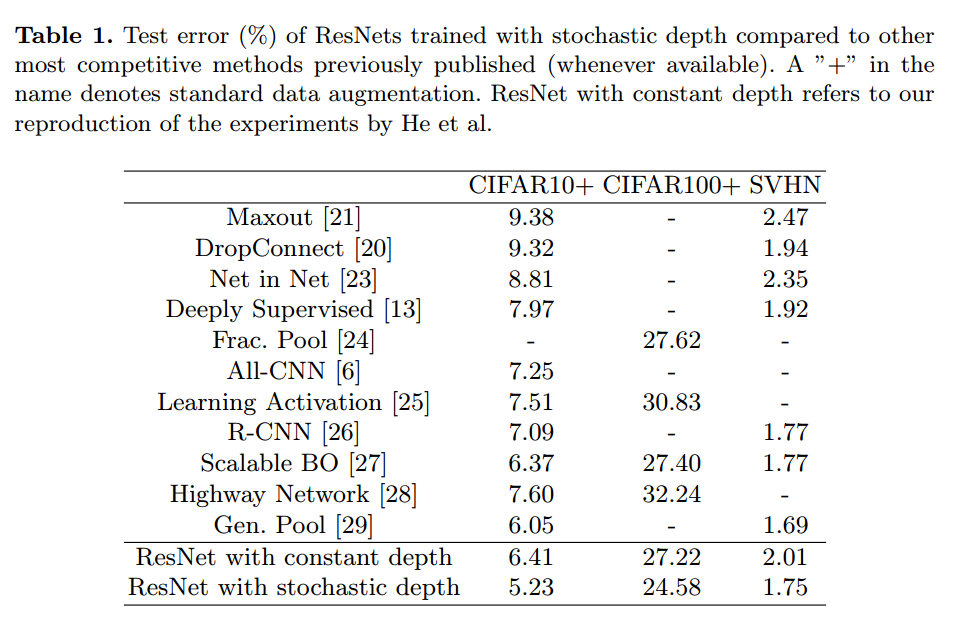
CIFAR-10
CIFAR-10による性能比較です。Test Error Rateが6.41%から5.23%になっています。他の手法でbestは6.05%でそれよりも良くなっています。
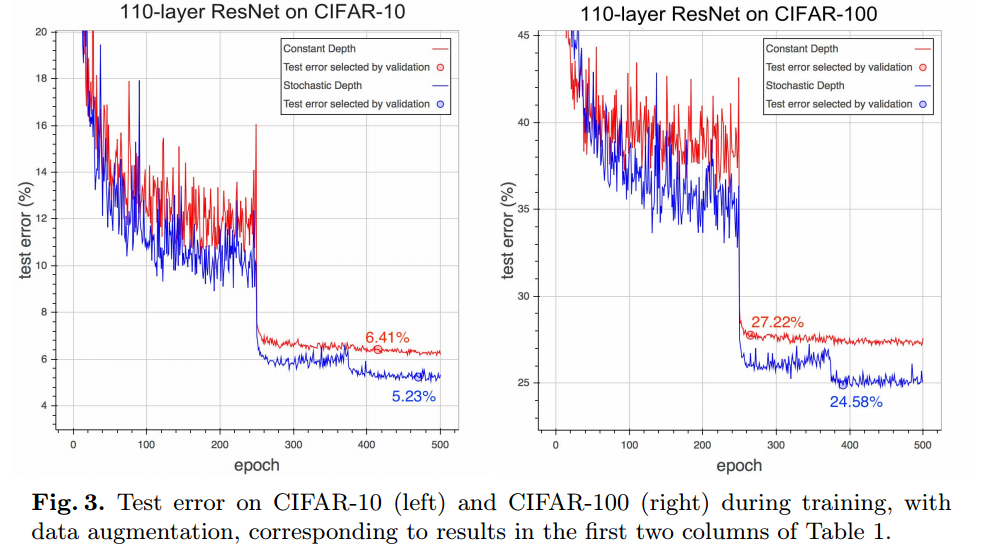
下はepoch毎のtest error rateを示したものです。stochastic depthの方が性能は良くなっていますが値の変動が大きいです。
CIFAR-100
27.22%→24.58%
data augmentationなしの場合は、CIFAR-10,CIFAR-100それぞれ、13.63%→11.66%、44.74%→37.8%になります。
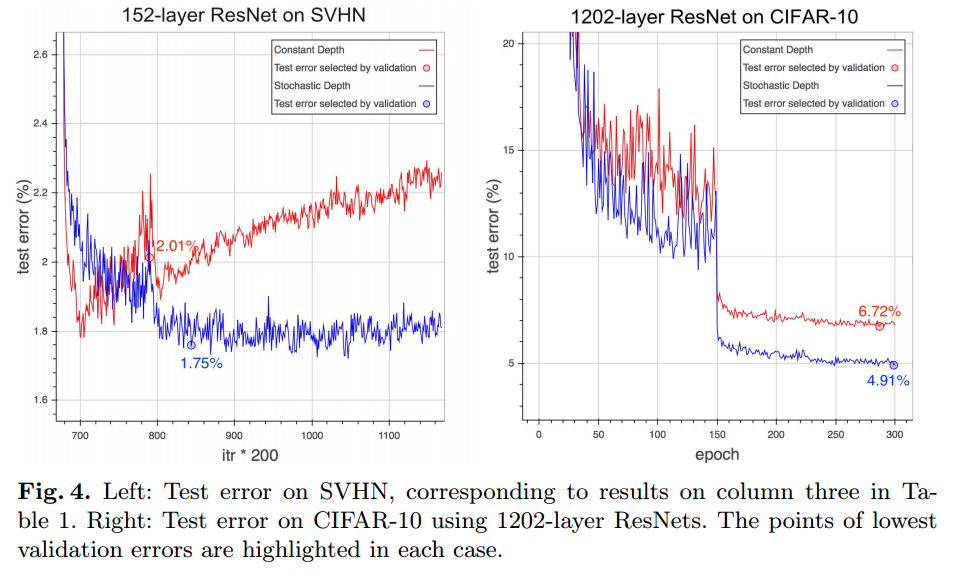
SVHN
Stochastic Depthなしの場合、最初のほうでOverfitしています。
Training time comparison
$p_L=0.5$で25%削減されます。

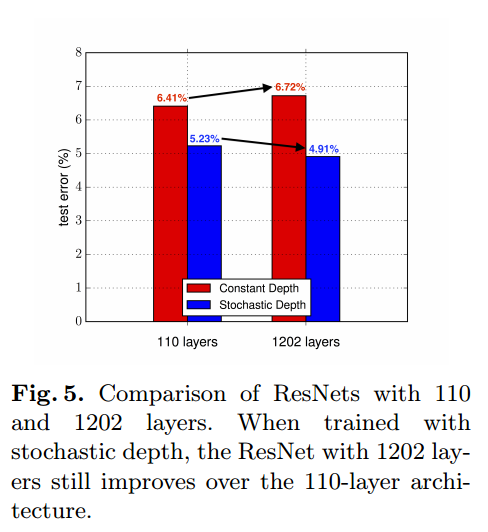
Training with a 1202-layer ResNet
layer数を1202にすると、通常の方法では6.72%と値が劣化しています。Stochastic Depthありでは性能が向上しています。
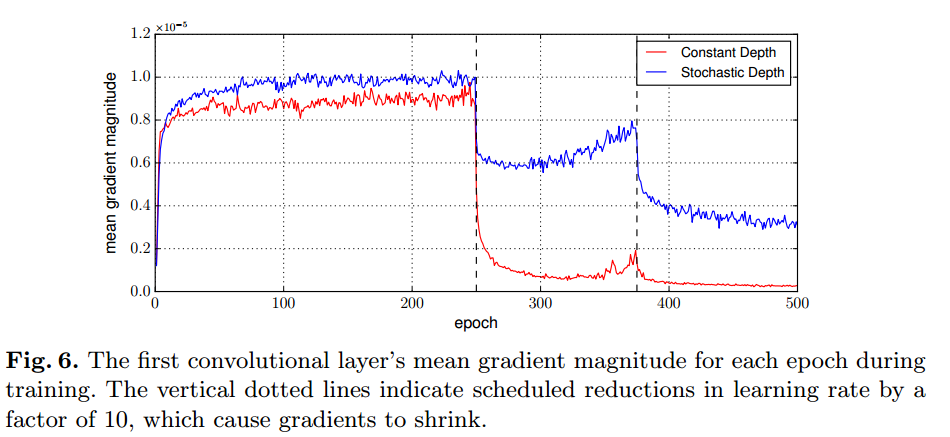
Vanishing gradients
勾配の絶対値平均を示した図です。
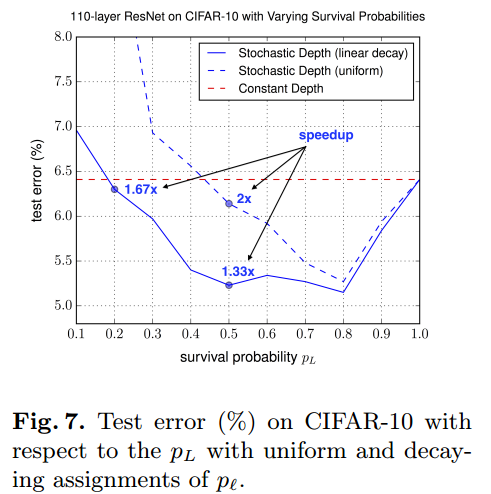
Hyper parameter sensitivity
Hyper parameter $p_L$を変化させた時のグラフです。
Stochastic Depthで実線は線形変換させたもの、点線は固定にしたものです。
感想
本論文は、Dropoutをlayer方向にしたものと捉えることができる。
それにより汎化性能の向上と計算量の削減を実現している。