背景・目的
私は最近、機械学習(※1)を学び始めているデータエンジニアです。
まだまだ初心者ですが、機械学習では学習前にデータの欠損や外れ値の除去、およびスケーリング等の処理が重要と学びました。
そこで、2020年の11月頃に発表されたAWS Glue DataBrewを使用して、機械学習の前処理として何ができるを確認したいと思います。
※1 最近まとめた記事は以下のとおりです。
まとめ
- Databrewを使うことで、データの特徴をインタラクティブに、素早く把握することが出来ます。
概要
Glue Data Brewとは
- AWS Glue DataBrew(以降、DataBrewと呼びます。)は、コードを書かずに以下のことができる視覚的なデータ準備ツールです。
- クリーンアップ
- 正規化
- 分析と機械学習(ML)用のデータの準備にかかる時間を最大80%短縮できるとのこと。
- 250を超える既製の変換から選択して、以下を自動化できるらしいです。
- 異常のフィルタリング
- データの標準形式への変換
- 無効な値の修正
- ビジネスアナリスト、データサイエンティスト、およびデータエンジニアなどの各ロールのコラボレーションを助け、生データから洞察をることができるとのことです。
- DataBrewはサーバーレスのため、インフラ管理が不要。
- 直感的なDataBrewインターフェースで、、生データをインタラクティブに検出、視覚化、クリーンアップ、および変換できる。
- DataBrewは、見つけるのが難しく、修正に時間がかかる可能性のあるデータ品質の問題を特定するのに役立つ提案を行う。
- DataBrewがデータを準備することで、時間を使って結果に基づいて行動し、より迅速に反復することができます。
- 変換をレシピのステップとして保存できます。これは、後で他のデータセットで更新または再利用でき、継続的に展開できます。
コンセプト
- DataBrewには、以下のコンセプトがあるようです。
Project
- DataBrewのインタラクティブなデータ準備ワークスペースはプロジェクトと呼ばれます。
- データプロジェクトを使用して、関連するアイテムのコレクション(データ、変換、スケジュールされたプロセス)を管理します。
Dataset
- データセットとは、単にデータのセット、つまり列またはフィールドに分割された行またはレコードを意味します。
- DataBrewプロジェクトを作成するときは、変換または準備するデータに接続するか、データをアップロードします。
- DataBrewは、フォーマットされたファイルからインポートされた任意のソースのデータを処理でき、増え続けるデータストアのリストに直接接続します。
- DataBrewの場合、データセットはデータへの読み取り専用接続です。
- DataBrewは、データを参照するための一連の記述メタデータを収集します。 DataBrewが実際のデータを変更または保存することはできない。
Recipe
- レシピは、DataBrewに作用させたいデータの一連の指示またはステップです。
- レシピには多くのステップを含めることができ、各ステップには多くのアクションを含めることができます。
- レシピの完成品を確認する準備ができたら、このジョブをDataBrewに割り当ててスケジュールします。
- DataBrewはデータ変換に関する指示を保存しますが、実際のデータは保存しません。
- 他のプロジェクトでレシピをダウンロードして再利用できます。レシピの複数のバージョンを公開することも可能とのこと。
Job
- レシピを作成したときに設定した命令を実行することにより、データを変換する仕事を引き受けます。
- これらの命令を実行するプロセスは、ジョブと呼ばれる。
- ジョブは、事前設定されたスケジュールに従ってデータレシピを実行に移すことができる。(オンデマンドでジョブを実行することも可能。)
- 一部のデータをプロファイリングする場合は、レシピは必要なく、その場合は、プロファイルジョブを設定してデータプロファイルを作成できる。
Data lineage
- ビジュアルインターフェイスでデータを追跡して、データリネージと呼ばれるその起源を特定する。
- このビューは、データが最初に来た場所からさまざまなエンティティをどのように流れるかを示しています。その起源、影響を受けた他のエンティティ、時間の経過とともに何が起こったか、どこに保存されたかを確認が可能とのこと。
Data profile
- データをプロファイリングすると、DataBrewはデータプロファイルと呼ばれるレポートを作成する。
- このサマリでは、以下を説明する。
- コンテンツのコンテキスト
- データの構造
- 関係
- データプロファイルジョブを実行することにより、任意のデータセットのデータプロファイルを作成可能とのこと。
実践
- Getting started with AWS Glue DataBrewを参考に実践してみます。
Prerequisites
- 設定済みなのでスキップします。
Step 1: Create a project
トップページ
- DataBrewのマネコンで、「プロジェクトを作成」をクリックします。
プロジェクトの作成
-
プロジェクトの詳細で、以下を入力します。
- プロジェクト名:chess-project
- レシピ名:chess-project-recipe(※サジェストで勝手に入ります。)

-
データセットを選択で、サンプルファイルを選択し、有名なチェスゲームの動きを選択します。
-
データセット名は、chess-gamesが自動で入ります。

-
パーミッションで、「新しいIAMロールを作成」を選択し、新しいIAMロールのサフィックスで「Tutorial」を入力します。

-
最後に、「プロジェクトを作成」をクリックすると、画面が切り替わります。

-
数分以内に、完了します。
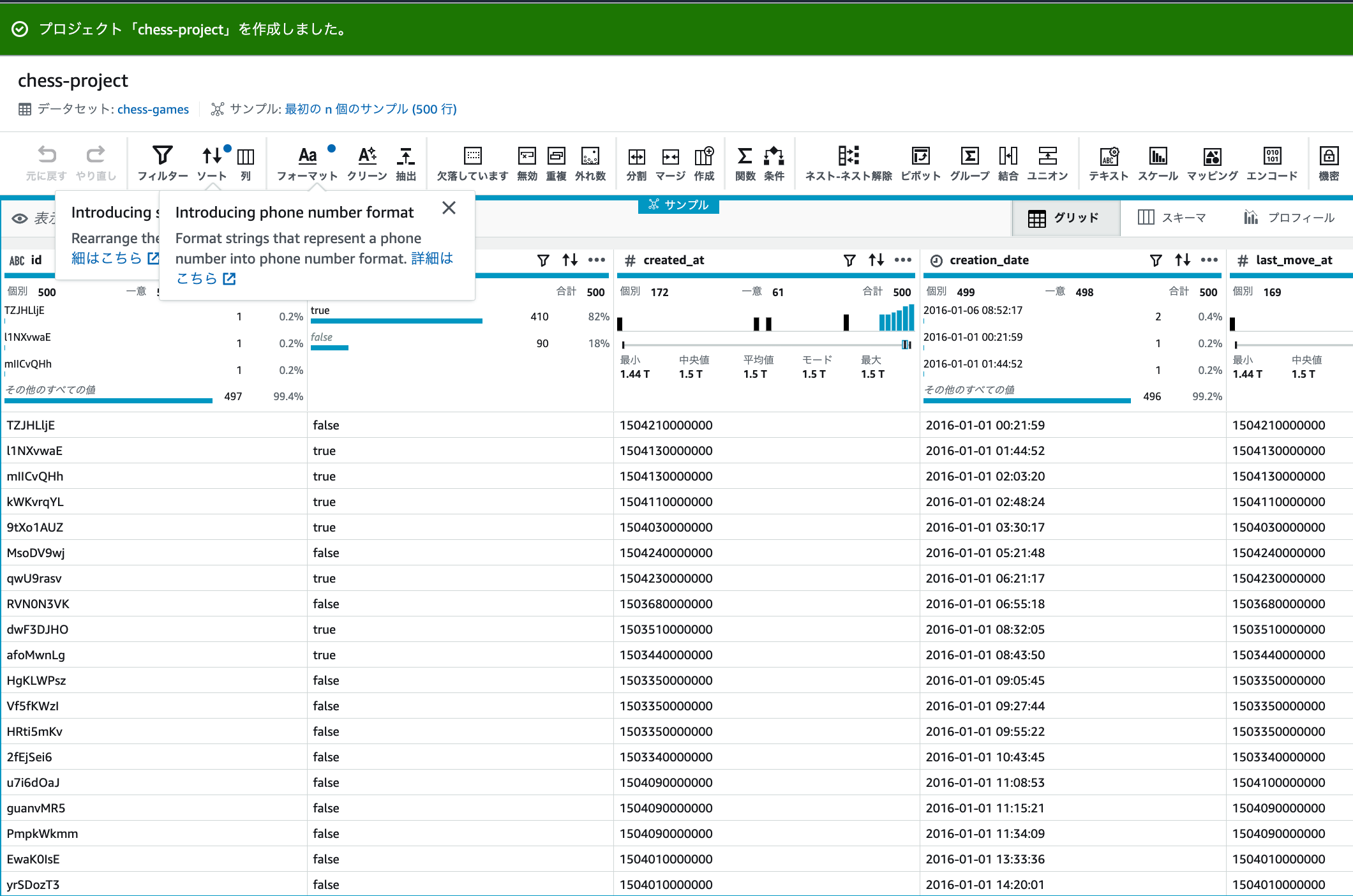
眺めてみる
-
画面上部を見ると、17カラム、500行のデータセットがあることが分かります。

-
グリッド。各カラムのサマリが上部に、下には、各データが確認できます。

-
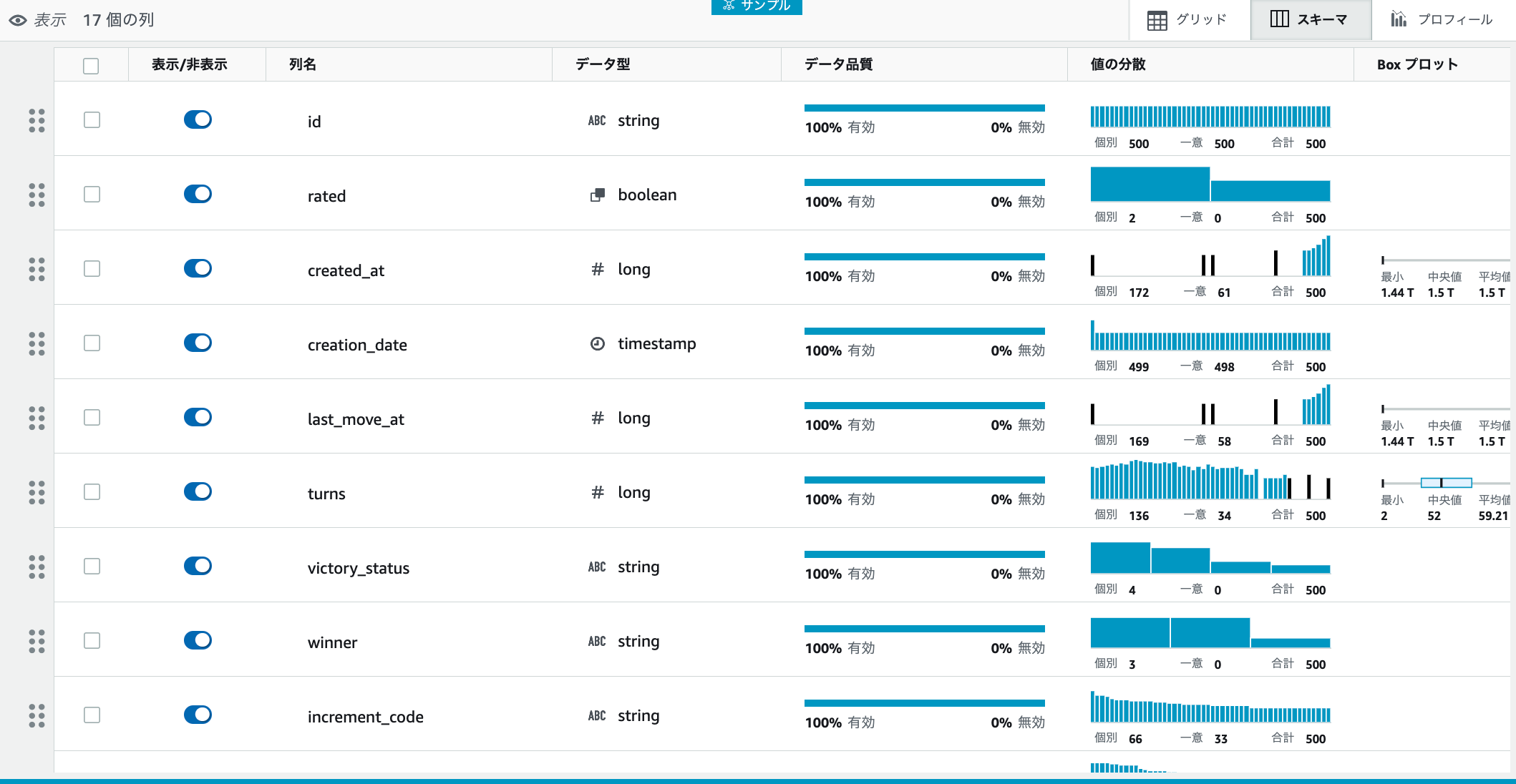
スキーマ。各カラムのデータ型、品質(これはなんだ?)、値の分散、数値については、Boxプロットが確認できます。
-
プロフィール。データプロファイルを実行のボタンがある。この先のチュートリアルで実行しそうなので、現時点では触れるのは控えておく。
Step 2: Summarize the data
フィルタリング
-
WhiteとBlackのレーティング1800以上のデータに絞り込みます。
-
フィルタを選択し、条件別>次以上をクリックします。

-
右にフィルター値のペインが表示されるので、カラムをwhite_rating、フィルター条件に1800を入力し、適用をクリックします。


-
上記と同様の手順で、カラムをblack_ratingを選択し、フィルター条件に1800を入力し、適用をクリックします。

サマライズ
-
各サイド(ブラック、ホワイト)が勝った数をサマライズします
-
ツールバーのグループをクリックします。
-
グループに以下を入力します。
- 1行目の列:winner、集計:グループ化
- 2行目の列:victory_status、集計:グループ化
- 3行目の列:winner、カウント(数)

-
グループタイプを「新しいテーブルとしてグループ化」を選択すると、プレビューが表示されます。

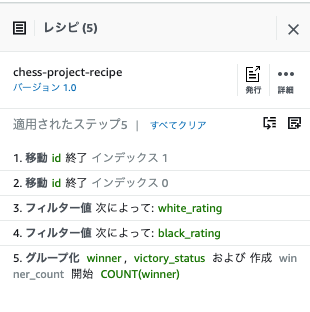
- 最後に、終了をクリックすると、画面が切り替わります。

- レシピペインで発行をクリックします。
- レシピの公開でバージョンの説明欄に「First version of my recipe」と入力し、発行をクリックします。

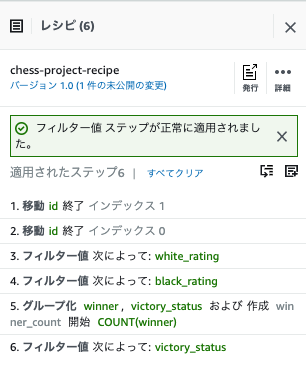
Step 3: Add more transformations
- 条件を変更し、別バージョンとしてレシピを公開します。
フィルターの追加
-
フィルターをクリックし、条件別>「次ではない」をクリックします。

-
フィルター値に、以下の条件を入力し「適用」をクリックします。
- ソース列をvictory_statusを選択する。
- フィルター条件に、次ではない
- 個別の値でdrawを選択する。

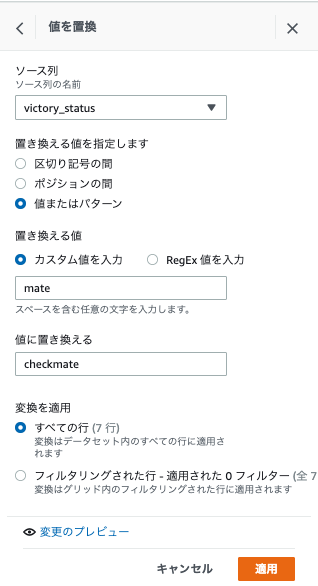
値の置換
-
意味のある値に置換します。mateをcheckmateに置換します。
-
クリーン>値またはパターンの置き換えをクリックします。

-
右のペインが表示されるので、以下を入力し適用をクリックします。
- ソース列:victory_status
- 置き換える値を指定します:値またはパターン
- 置き換える値:カスタム値を入力で「mate」
- 値に置き換えられる:「checkmate」

-
真ん中の列「victory_status」の値が、checkmateに置きかわりました。
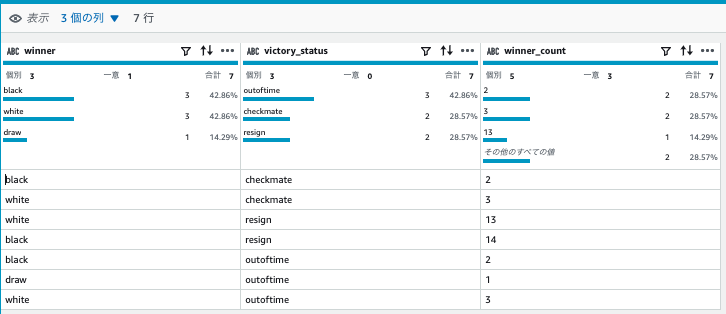
2つ目の置換(regign → other player resigned)
- 上記と同様に、置換します。

- 変わりました。

3つ目の置換(outoftime → time ran out)
-
上記と同様に、置換します。

-
変わりました。

-
最後に発行をクリックし、レシピを公開します。

Step 4: Review your DataBrew resources
- DataBrewリソースを確認します。
データセットの確認
- ナビゲーションペイン(画面左)のデータセットをクリックします。

- S3にxlsx形式で保存されています。

- データセット名をクリックすると、詳細が確認できます。

- データ系列タブをクリックすると、系統が確認できます。

- CloudTrailログをクリックすると、イベントが確認できます。

プロジェクトの確認
-
ナビゲーションペイン(画面左)のプロジェクトをクリックします。
-
プロジェクトの一覧が確認できます。
- 先程作成した、プロジェクト、関連付けたデータセット、アタッチされたレシピが確認できます。

- 先程作成した、プロジェクト、関連付けたデータセット、アタッチされたレシピが確認できます。
-
レシピ名をクリックすると、以下の内容が確認できます。
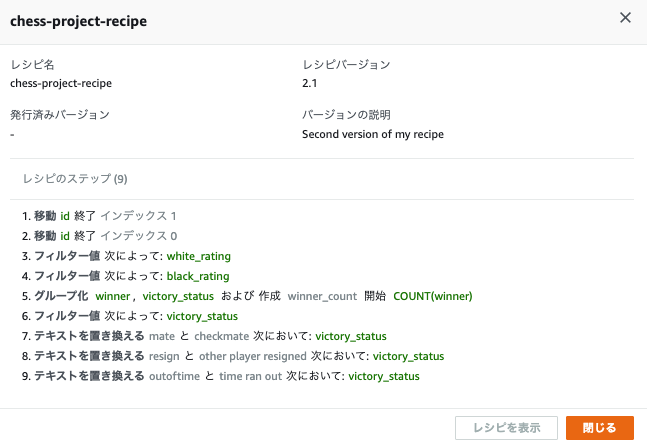
レシピの確認
- ナビゲーションペイン(画面左)のレシピをクリックします。
- レシピの一覧が確認できます。

- レシピをクリックすると、レシピの内容が確認できます。左側には、現在のバージョンと、最初(1.0)のバージョンが確認できます。

- バージョン1.0をクリックすると、以前のレシピのステップが確認できました。

- データ系列タブをクリックすると、系統が確認できます。

Step 5: Create a data profile
-
プロファイルを作成します。
-
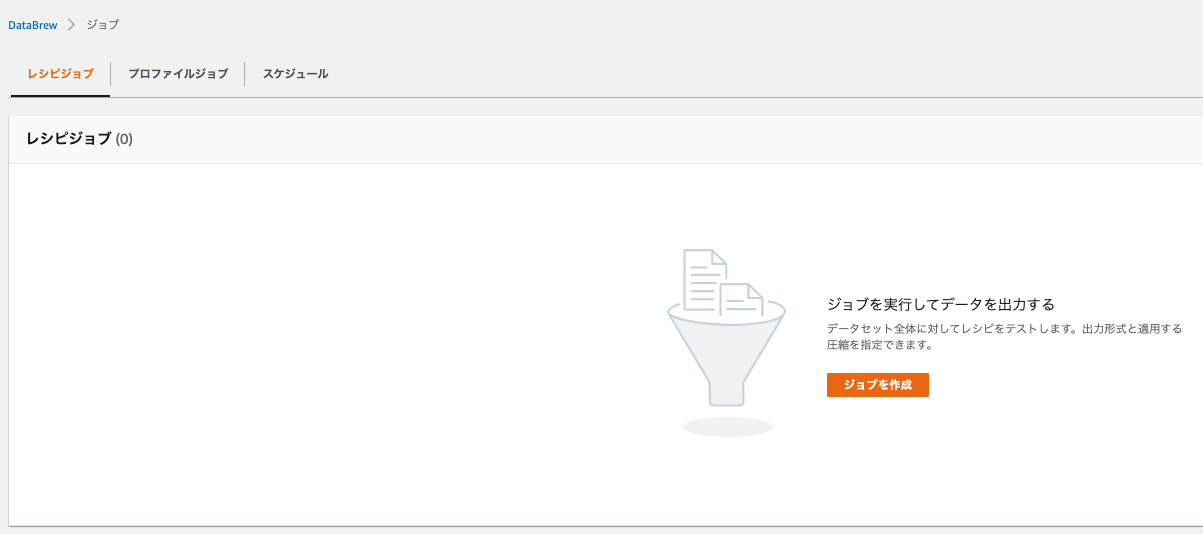
ナビゲーションペイン(画面左)のジョブをクリックします。

-
未だ何もありません。ここでプロファイルジョブのタブをクリックします。
-
「ジョブを作成」をクリックします。
-
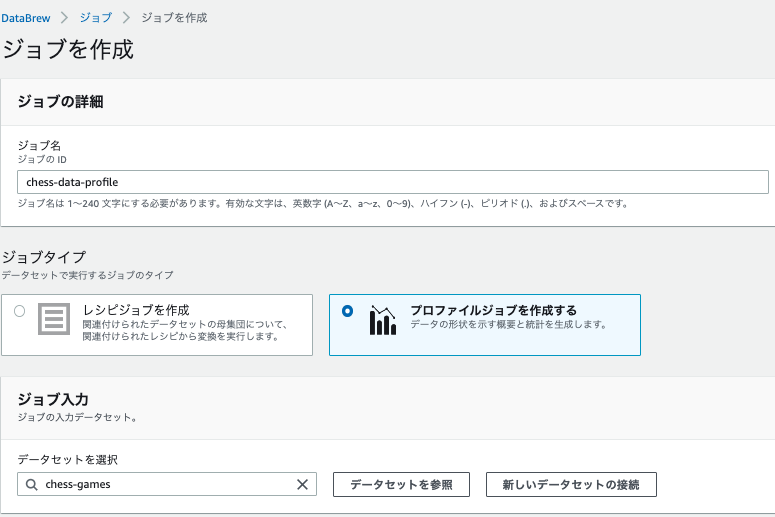
以下を入力します。
- ジョブの詳細:ジョブ名に「chess-data-profile」
- ジョブタイプ:「プロファイルジョブを作成する」
- ジョブ入力:データセットを選択「chess-games」
- ジョブ実行サンプル:そのまま
-
ジョブ出力設定では、以下を入力します。
- S3バケット所有者アカウント:現在のAWSアカウント
- S3の場所:自分のバケット
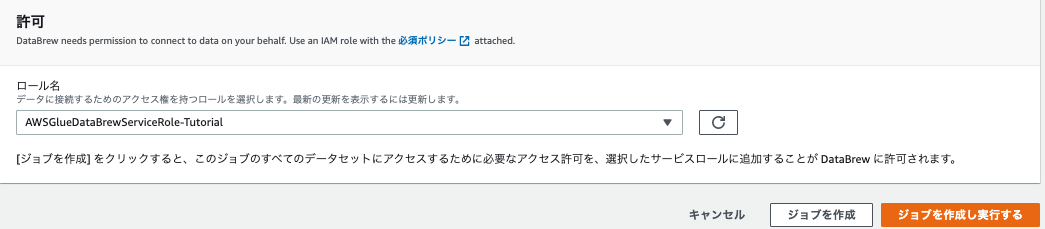
-
Permissionでは、事前に作成したロールを選択します。
-
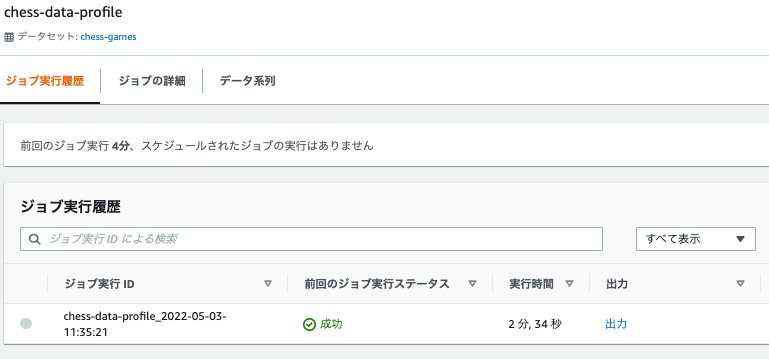
ジョブを作成し実行するをクリックし、しばらくするとジョブ実行履歴画面に切り替わり、実行ステータスが「実行中」であることが分かります。

-
しばらくすると、成功に変わりました。
-
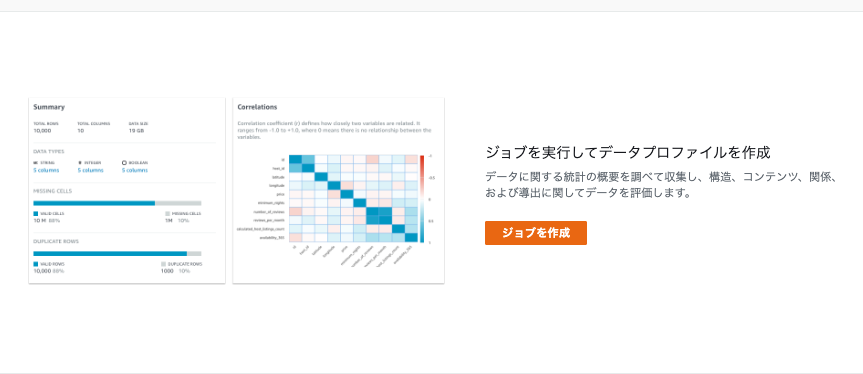
プロフィールを表示をクリックします。

プロファイルの確認
サマリと相関関係
- 重複行が5件あることがわかりました。欠損はありませんでした。

値の分布を比較
- スケーリング(正規化)されて表示されています。

列の統計
- 列の統計タブをクリックします。
- データインサイトでUnique、外れ値、欠落が分かります。

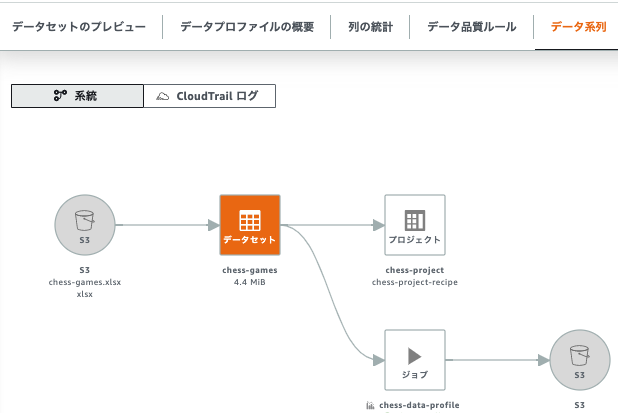
データ系列
- データ系列タブをクリックします。
- 系列が分かります。
Step 6: Transform the dataset
- データセット全体を書き換えるジョブを作成します。
To create an S3 bucket and folder to capture job output
- 出力用のs3バケットに、databrew-outputフォルダを作成します。
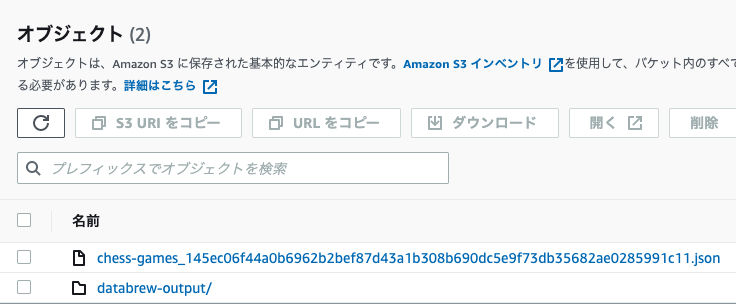
To create and run a recipe job
-
レシピジョブを作成します。
-
ナビゲーションペインで、ジョブを選択>レシピジョブタブで、ジョブを作成をクリックします。

-
ジョブの作成画面では、以下を入力します。
- ジョブ名「chess-winner-summary」
- ジョブタイプ:レシピジョブを作成
- ジョブ入力:データセット
- データセット名:chess-games
- レシピ名とバージョン:chess-project-recipe2.0

-
ジョブ出力設定では、以下を入力します。
- 出力先:S3
- ファイルタイプ:CSV
- 区切り文字:カンマ
- 圧縮:None
- S3の場所:s3://バケット名/databrew-output/
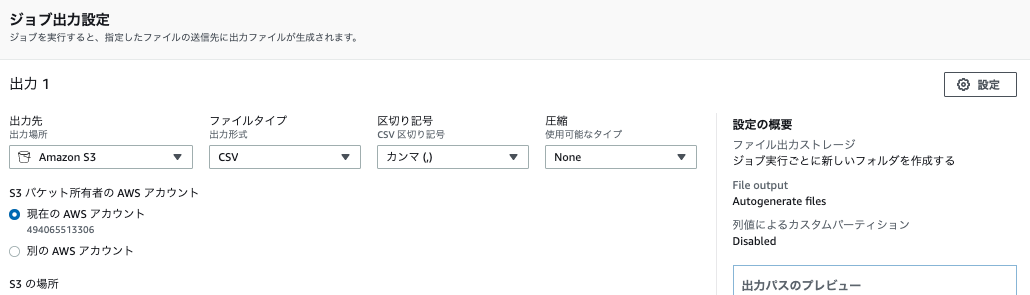
- Permissionにロール名を指定して、ジョブを「作成して実行する」をクリックします。

- 完了しました。
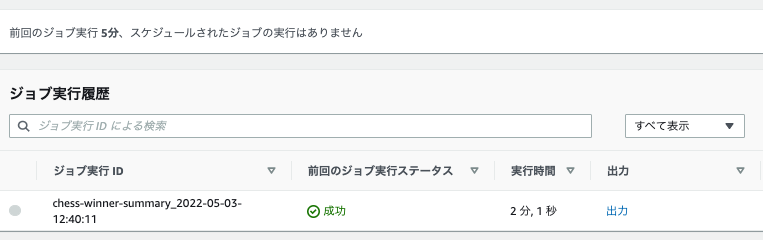
ファイルの確認
-
出力先バケットのフォルダに、CSVファイルが出来ていました。一つ選びS3SELECTを実行します。

-
結果が確認できました。

考察
- Databrewを使うことにより、データの特徴が可視化され、探索的データ解析が簡単に楽にできると感じました。
- また、ジョブを実行することで前処理も簡単にできそうです。
- 今回、チュートリアルとして動かしましたが、次回以降は、プロダクションレベルで利用ができるか。具体的には、GlueのPySparkなどと組み合わせながら実行できるか。またはどのような前処理ができるのか等を確認したいと思います。
参考