背景・目的
Sparkの実装について、目的別にまとめていきます。(随時更新します。)
まとめ
GlueのSparkについて、目的別にまとめました。
| 分類 | 目的 |
|---|---|
| ファイル操作(読み込み) | JSONフォーマットの読み込み |
| CSVフォーマットを読み込み | |
| ファイル操作(書き込み) | JSONフォーマットで書き込み |
| Parquetフォーマットで書き込み | |
| パーティションキーを指定して書き込み | |
| 分割して書き込み(バケッティング) | |
| RDDとDataFrame間の変換 | RDDからDataFrameへ変換 |
| DataFrameからRDDへ変換 | |
| DynamicFrameとDataFrame間の変換 | DataFrameに変換 |
| DynamicFrameに変換 | |
| RDDを生成 | リストからRDDを生成する |
| タプルからRDDを生成する | |
| パーティション操作 | パーティション数の確認 |
| パーティション内のデータを確認 | |
| Repartion(パーティション数指定) | |
| Repartition(キー指定) | |
| Repartition(キー+パーティション数指定) | |
| Coalesce | |
| データの確認 | 簡易的に確認 |
| 列ごとの統計値を確認 | |
| 列ごとのカーディナリティを確認 | |
| 列の比較 | Whenで列を比較 |
| データ操作(結合) | Inner Join |
| Left Outer Join | |
| データ操作(ソート) | 昇順 |
| 降順 | |
| データ操作(列追加) | withColumn |
| データ操作(集計) | 合計 |
| カウント | |
| データ操作(Window処理) | 採番(シンプル) |
| 採番(グルーピング) | |
| 値の範囲内で最大、最小、合計、カウントを取得(定数を使用) | |
| 値の範囲内で最大、最小、合計、カウントを取得(任意の値を使用) | |
| 行数の範囲内で最大、最小、合計、カウントを取得 | |
| 前後のレコードを取得 | |
| データ操作(型の変更) | ApplyMapping |
| データ操作(行ごとの処理) | mapPartitions |
| 計測・実行計画 | 実行時間 |
| Physical Plan | |
| Physical PlanとLogical Plan |
実践
前提
- Glue Spark3.0を使用しています。
- 検証はGlue Sutdioを使用しています。
事前準備
S3バケット
- 事前にインプットとアウトプット用に2つのバケットを用意しています。
データ
sum-test-data.json
インプット用のバケットに以下のデータを用意しています。
{"id":"00001","category":"c001","value":"test1","num":1,"timestamp":"2022-10-01T10:00:00+0900"}
{"id":"00002","category":"c001","value":"test2","num":2,"timestamp":"2022-10-02T10:00:00+0900"}
{"id":"00003","category":"c002","value":"test3","num":3,"timestamp":"2022-10-03T10:00:00+0900"}
{"id":"00004","category":"c003","value":"test4","num":4,"timestamp":"2022-10-04T10:00:00+0900"}
{"id":"00005","category":"c004","value":"test5","num":5,"timestamp":"2022-10-05T10:00:00+0900"}
実装
共通処理
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.window import Window as W
import pyspark.sql.functions as F
from pyspark.sql.functions import *
from awsglue.dynamicframe import DynamicFrameCollection
from awsglue.dynamicframe import DynamicFrame
import time
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
ファイル操作
読み込み
JSONフォーマット
- connection_typeにs3を指定
- formatにJSONを指定
S3bucket_node1 = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False},
connection_type="s3",
format="json",
connection_options={"paths": ["s3://バケット名/partitions/"], "recurse": True},
transformation_ctx="S3bucket_node1",
)
CSVフォーマット
- formatにcsvを指定
- ヘッダーがある場合はformat_optionsのwithHeaderをTrueとする。
# Script generated for node S3 bucket
S3bucket_order = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": False
,"withHeader": True
},
connection_type="s3",
format="csv",
connection_options={"paths": ["s3://バケット名/partitions/"], "recurse": True},
transformation_ctx="S3bucket_node1",
)
書き込み
JSONフォーマット
write_dynamic = glueContext.write_dynamic_frame.from_options(\
frame = dyn,\
connection_options = {'path': 's3://バケット/json'},\
connection_type = 's3',\
format = 'json')
S3 selectの結果
===
{
"id": "00001",
"category": "c001",
"value": "test1",
"num": 1,
"timestamp": "2022-10-01T10:00:00+0900"
}
{
"id": "00002",
"category": "c001",
"value": "test2",
"num": 2,
"timestamp": "2022-10-02T10:00:00+0900"
}
{
"id": "00003",
"category": "c002",
"value": "test3",
"num": 3,
"timestamp": "2022-10-03T10:00:00+0900"
}
{
"id": "00004",
"category": "c003",
"value": "test4",
"num": 4,
"timestamp": "2022-10-04T10:00:00+0900"
}
{
"id": "00005",
"category": "c004",
"value": "test5",
"num": 5,
"timestamp": "2022-10-05T10:00:00+0900"
}
Parquetフォーマット
- formatにparquetを指定します。
write_dynamic = glueContext.write_dynamic_frame.from_options(\
frame = dyn,\
connection_options = {'path': 's3://バケット/parquet'},\
connection_type = 's3',\
format = 'parquet')
S3 selectの結果
===
{
"id": "00001",
"category": "c001",
"value": "test1",
"num": 1,
"timestamp": "2022-10-01T10:00:00+0900"
}
{
"id": "00002",
"category": "c001",
"value": "test2",
"num": 2,
"timestamp": "2022-10-02T10:00:00+0900"
}
{
"id": "00003",
"category": "c002",
"value": "test3",
"num": 3,
"timestamp": "2022-10-03T10:00:00+0900"
}
{
"id": "00004",
"category": "c003",
"value": "test4",
"num": 4,
"timestamp": "2022-10-04T10:00:00+0900"
}
{
"id": "00005",
"category": "c004",
"value": "test5",
"num": 5,
"timestamp": "2022-10-05T10:00:00+0900"
}
※ S3出力結果
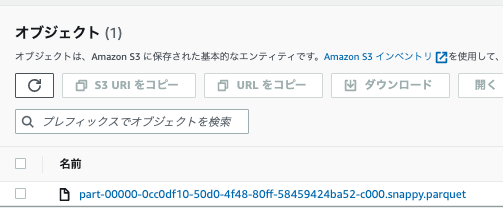
パーティショニング
DynamicFrameを使用してデータを使用して分散して書き込みます。
- connection_optionsに「parititionKeys」を指定します。
- パーティションでは、データの内容を指定してパスに書き込まれます。
# 事前確認
df.show()
===
| id|category|value|num| timestamp|
+-----+--------+-----+---+--------------------+
|00001| c001|test1| 1|2022-10-01T10:00:...|
|00002| c001|test2| 2|2022-10-02T10:00:...|
|00003| c002|test3| 3|2022-10-03T10:00:...|
|00004| c003|test4| 4|2022-10-04T10:00:...|
|00005| c004|test5| 5|2022-10-05T10:00:...|
# 書き込み
write_dynamic = glueContext.write_dynamic_frame.from_options(\
frame = dyn,\
connection_options = {'path': 's3://バケット/partition','partitionKeys':["timestamp"]},\
connection_type = 's3',\
format = 'parquet'
)
# S3 selectの結果(一部)
# 2022-10-1配下のファイル
# ===
{
"id": "00001",
"category": "c001",
"value": "test1",
"num": 1
}
※ S3出力結果
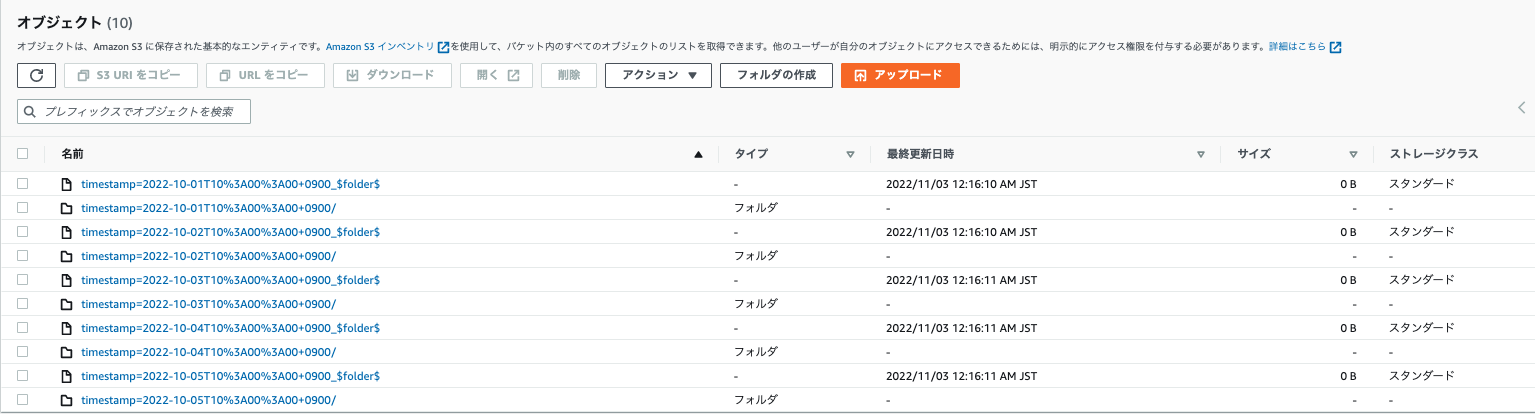
バケッティング
DataFrameを使用してデータを使用して分散して書き込みます。
# 事前に確認
df = S3bucket_node1.toDF()
df.show()
===
+-----+--------+-----+---+--------------------+
| id|category|value|num| timestamp|
+-----+--------+-----+---+--------------------+
|00001| c001|test1| 1|2022-10-01T10:00:...|
|00002| c001|test2| 2|2022-10-02T10:00:...|
|00003| c002|test3| 3|2022-10-03T10:00:...|
|00004| c003|test4| 4|2022-10-04T10:00:...|
|00005| c004|test5| 5|2022-10-05T10:00:...|
+-----+--------+-----+---+--------------------+
writedf = df.write.option("path","s3://バケット/bucketing/").mode("overwrite").bucketBy(2, "num").format("parquet").saveAsTable("bucketing")
S3出力結果を確認します。ファイルが2つに分割されています。

S3 SELECTでそれぞれのファイルの内容を確認します。分散されていることがわかります。
# 1つ目のファイル
SELECT * FROM s3object s LIMIT 5
# ===
{
"id": "00002",
"category": "c001",
"value": "test2",
"num": 2,
"timestamp": "2022-10-02T10:00:00+0900"
}
{
"id": "00004",
"category": "c003",
"value": "test4",
"num": 4,
"timestamp": "2022-10-04T10:00:00+0900"
}
{
"id": "00005",
"category": "c004",
"value": "test5",
"num": 5,
"timestamp": "2022-10-05T10:00:00+0900"
}
# 2つ目のファイル
===
{
"id": "00001",
"category": "c001",
"value": "test1",
"num": 1,
"timestamp": "2022-10-01T10:00:00+0900"
}
{
"id": "00003",
"category": "c002",
"value": "test3",
"num": 3,
"timestamp": "2022-10-03T10:00:00+0900"
}
上書き
特定のパス配下の結果を上書きする。
DynamicFrameでは上書きはサポートされていないため、DataFrameで実装します。
# mode("overwrite")で上書きモードになります。
df.write.mode("overwrite").format("parquet").save("s3://{バケット名}/stock/")
RDDを生成
parallelizeを使用する。
リストからRDDを生成する
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
rdd = sc.parallelize(list)
for row in rdd.collect():
print(row)
タプルからRDDを生成する
tuple = [
("k1",1)
,("k2",2)
,("k3",3)
,("k4",4)
,("k5",5)
,("k6",6)
,("k7",7)
,("k8",8)
,("k9",9)
,("k10",10)
]
rdd = sc.parallelize(tuple)
for row in rdd.collect():
print("key:{} value:{}".format(row[0],row[1]))
テストデータを作成する場合
parallelizeを使用する
t = (0,10,)
list=[]
for i in range(100):
list.append(t)
sc.parallelize(list).toDF().show()
===
+---+---+
| _1| _2|
+---+---+
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
+---+---+
createDataFrameを使用する
t = (0,10,)
list=[]
for i in range(100):
list.append(t)
spark.createDataFrame(list).show()
===
+---+---+
| _1| _2|
+---+---+
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
| 0| 10|
+---+---+
only showing top 20 rows
RDDとDataFrame間の変換
RDDからDataFrameへの変換
print(type(rdd))
# toDFで変換可能
df4 = rdd.toDF()
print(type(df4))
===
<class 'pyspark.rdd.RDD'>
<class 'pyspark.sql.dataframe.DataFrame'>
RDDからDataFrameへの変換(スキーマを定義)
ドキュメントを見ると、rddでは、カラム名を直接指定したtoDF()はサポートされていない。そのため、Schemaを指定することで同時にスキーマを定義できる。
(DataFrameのtoDFはサポートされている。)
from pyspark.sql import types as T, functions as F
schema = T.StructType([
T.StructField('id', T.StringType()),
T.StructField('value', T.LongType())
])
df = sc.parallelize([
('AAA', 1),
('BBB', 2),
('CCC', 3),
]).toDF(schema).show()
===
+---+-----+
| id|value|
+---+-----+
|AAA| 1|
|BBB| 2|
|CCC| 3|
+---+-----+
以下は、エラー(ParseException)となるケースです。
df = sc.parallelize([
('AAA', 1),
('BBB', 2),
('CCC', 3),
]).toDF("id","value").show()
DataFrameからRDDへの変換
df = sc.parallelize([
('AAA', 1),
('BBB', 2),
('CCC', 3),
]).toDF()
print(type(df))
rdd = df.rdd
print(type(rdd))
===
<class 'pyspark.sql.dataframe.DataFrame'>
<class 'pyspark.rdd.RDD'>
DynamicFrameとDataFrame間の変換
DynamicFrameからDataFrameへの変換
df = S3bucket_node1.toDF()
DataFrameからDynamicFrameへの変換
dyn = DynamicFrame.fromDF(df, glueContext, "DynamicFrame")
パーティション操作
パーティション数の確認
DataFrameで実行する。
print('Number of partitions: {}'.format(df.rdd.getNumPartitions()))
===
Number of partitions: 1
パーティション内のデータを確認
print('Partitions structure: {}'.format(df.rdd.glom().collect()))
# 見やすいように整形しています。
===
Partitions structure: [
[
Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
, Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
]
]
Repartition(パーティション数を指定)
Repartitionにより、パーティション数を増減させます。シャッフルが発生するコストが高く、性能に影響を与えるため注意が必要です。
- 実行前の確認
print('Number of partitions: {}'.format(df.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(df.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 1
Partitions structure: [
[
Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
, Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
]
]
- 実行(2つのパーティションに分散されていることがわかります。)
repartitioned = df.repartition(2)
print('Number of partitions: {}'.format(repartitioned.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(repartitioned.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 2
Partitions structure: [
[
Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
]
,[
Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
]
]
Repartition(キーを指定)
- 実行前の確認
print('Number of partitions: {}'.format(df.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(df.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 1
Partitions structure: [
[
Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
, Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
]
]
- 実行
- categoryで分散し、同一パーティションに同一カテゴリに格納されていることがわかります。
- パーティション数が40に分けられています。
repartitioned = df.repartition("category")
print('Number of partitions: {}'.format(repartitioned.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(repartitioned.rdd.glom().collect()))
# 見やすいように整形しています。
Number of partitions: 40
Partitions structure: [
[]
, []
, []
, []
, []
, []
, []
, []
, []
, []
, []
, []
, []
, [
Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
]
, []
, []
, []
, []
, []
, []
, []
, []
, [
Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
]
, []
, []
, []
, []
, []
, []
, []
, [
Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
]
, []
, []
, []
, []
, []
, []
, []
, [
Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
]
, []
]
Repartition(キーとパーティション数を指定)
上記の「Repartition(キーを指定)」では、40パーティションで分けられていました。キーを指定しつつパーティション数を制御したい場合に利用します。
- 実行前の確認
print('Number of partitions: {}'.format(df.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(df.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 1
Partitions structure: [
[
Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
, Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
]
]
- 実行
- num、同一パーティションに同一カテゴリに格納されていることがわかります。
- パーティション数を2に変更します。
spark.conf.set("spark.sql.shuffle.partitions",2)
repartitioned = df.repartition("num")
print('Number of partitions: {}'.format(repartitioned.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(repartitioned.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 2
Partitions structure: [
[
Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
, Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
],
[
Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
, Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
]
]
Coalesce
パーティションを減らす場合に利用します。
- 実行前の確認
print('Number of partitions: {}'.format(repartitioned.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(repartitioned.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 2
Partitions structure: [
[
Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
]
,[
Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
]
]
- 実行(1つのパーティションに結合されていることがわかります。)
coalesced = repartitioned.coalesce(1)
print('Number of partitions: {}'.format(coalesced.rdd.getNumPartitions()))
print('Partitions structure: {}'.format(coalesced.rdd.glom().collect()))
# 見やすいように整形しています。
===
Number of partitions: 1
Partitions structure: [
[
Row(id='00004', category='c003', value='test4', num=4, timestamp='2022-10-04T10:00:00+0900')
, Row(id='00005', category='c004', value='test5', num=5, timestamp='2022-10-05T10:00:00+0900')
, Row(id='00002', category='c001', value='test2', num=2, timestamp='2022-10-02T10:00:00+0900')
, Row(id='00003', category='c002', value='test3', num=3, timestamp='2022-10-03T10:00:00+0900')
, Row(id='00001', category='c001', value='test1', num=1, timestamp='2022-10-01T10:00:00+0900')
]
]
データの確認
全ての列を簡易的に確認
calendarDF.show()
===
+--------+-------+---------+
| ymd| type|DayOfWeek|
+--------+-------+---------+
|20221001|Weekend| Sat|
|20221002|Weekend| Sun|
|20221003|Weekday| Mon|
|20221004|Weekday| Tue|
|20221005|Weekday| Wed|
|20221006|Weekday| Thu|
|20221007|Weekday| Fri|
|20221008|Weekend| Sat|
|20221009|Weekend| Sun|
|20221010|Holiday| Mon|
|20221011|Weekday| Tue|
|20221012|Weekday| Wed|
|20221013|Weekday| Thu|
|20221014|Weekday| Fri|
|20221015|Weekend| Sat|
|20221016|Weekend| Sun|
|20221017|Weekday| Mon|
|20221018|Weekday| Tue|
|20221019|Weekday| Wed|
|20221020|Weekday| Thu|
+--------+-------+---------+
only showing top 20 rows
全ての列を確認(途中で表示が切れないように表示する)
カラムに含まれる値が長い場合、下記のように途中で切れてしまい最後まで確認できません。
これは、truncateというパラメータがデフォルトで有効で、20文字で切り落としているためです。
t = (0,"abcdefghijklmnopqrstu",)
list=[]
for i in range(100):
list.append(t)
dataframe = spark.createDataFrame(list)
dataframe.show()
===
+---+--------------------+
| _1| _2|
+---+--------------------+
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
| 0|abcdefghijklmnopq...|
+---+--------------------+
show(truncate=False)とすることで、最後まで表示されます。
dataframe.show(truncate=False)
===
+---+---------------------+
|_1 |_2 |
+---+---------------------+
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
|0 |abcdefghijklmnopqrstu|
+---+---------------------+
列ごとの統計値を確認
from pyspark.sql import SparkSession
from pyspark.sql import types as T, functions as F
from pyspark.sql.functions import *
t = (0,10,)
list=[]
list.append((1,100))
list.append((2,101))
list.append((3,103))
list.append((4,104))
list.append((5,105))
schema = T.StructType([
T.StructField('id', T.IntegerType()),
T.StructField('value', T.IntegerType()),
])
spark = SparkSession \
.builder \
.appName("Python example") \
.getOrCreate()
df2 = spark.createDataFrame(list,schema)
df2.describe(['id','value']).show()
===
+-------+------------------+------------------+
|summary| id| value|
+-------+------------------+------------------+
| count| 5| 5|
| mean| 3.0| 102.6|
| stddev|1.5811388300841898|2.0736441353327706|
| min| 1| 100|
| max| 5| 105|
+-------+------------------+------------------+
列のカーディナリティを確認する
from pyspark.sql import SparkSession
from pyspark.sql import types as T, functions as F
from pyspark.sql.functions import *
t = (0,10,)
list=[]
list.append((1,100))
list.append((2,100))
list.append((3,101))
list.append((4,101))
list.append((5,101))
schema = T.StructType([
T.StructField('id', T.IntegerType()),
T.StructField('value', T.IntegerType()),
])
spark = SparkSession \
.builder \
.appName("Python example") \
.getOrCreate()
df2 = spark.createDataFrame(list,schema)
df2.agg(approx_count_distinct(df2.value)).show()
===
+----------------------------+
|approx_count_distinct(value)|
+----------------------------+
| 2|
+----------------------------+
列の操作
重複行の削除
ApplyMappingDynamicFrame.toDF().select("order_parts_id").show()
ApplyMappingDynamicFrame.toDF().select("order_parts_id").distinct().orderBy("order_parts_id").show()
===
+--------------+
|order_parts_id|
+--------------+
| G-000000|
| G-000000|
| G-000000|
| G-000000|
| G-000000|
| G-000000|
| G-000001|
| G-000002|
| G-000002|
| G-000002|
| G-000002|
| G-000002|
| G-000002|
| G-000003|
| G-000003|
| G-000003|
| G-000003|
| G-000003|
| G-000003|
| G-000003|
+--------------+
only showing top 20 rows
+--------------+
|order_parts_id|
+--------------+
| G-000000|
| G-000001|
| G-000002|
| G-000003|
| G-000004|
| G-000005|
| G-000006|
| G-000007|
| G-000008|
| G-000009|
| G-000010|
| G-000011|
| G-000012|
| G-000013|
| G-000014|
| G-000015|
| G-000016|
| G-000017|
| G-000018|
| G-000019|
+--------------+
only showing top 20 rows
別名をつける
orderDF.groupBy("order_date","order_parts_id").agg(sum(orderDF.order_num).alias("total_order_num"),count(orderDF.order_date).alias("clients")).show()
===
+----------+--------------+---------------+-------+
|order_date|order_parts_id|total_order_num|clients|
+----------+--------------+---------------+-------+
|2022-10-01| G-611310| 390| 7|
|2022-10-01| G-611668| 270| 4|
|2022-10-01| G-611933| 456| 9|
|2022-10-01| G-612167| 189| 4|
|2022-10-01| G-612464| 429| 10|
|2022-10-01| G-612470| 169| 3|
|2022-10-01| G-612819| 545| 9|
|2022-10-01| G-613731| 99| 2|
|2022-10-01| G-614382| 272| 7|
|2022-10-01| G-615200| 73| 2|
|2022-10-01| G-615410| 416| 7|
|2022-10-01| G-615664| 414| 10|
|2022-10-01| G-615840| 179| 4|
|2022-10-01| G-617716| 67| 2|
|2022-10-01| G-617791| 239| 5|
|2022-10-01| G-618164| 360| 7|
|2022-10-01| G-618390| 342| 7|
|2022-10-01| G-619069| 364| 6|
|2022-10-01| G-619519| 114| 3|
|2022-10-01| G-620028| 193| 4|
+----------+--------------+---------------+-------+
列の比較
事前に確認
calendarDF.show()
===
+--------+-------+---------+
| ymd| type|DayOfWeek|
+--------+-------+---------+
|20221001|Weekend| Sat|
|20221002|Weekend| Sun|
|20221003|Weekday| Mon|
|20221004|Weekday| Tue|
|20221005|Weekday| Wed|
|20221006|Weekday| Thu|
|20221007|Weekday| Fri|
|20221008|Weekend| Sat|
|20221009|Weekend| Sun|
|20221010|Holiday| Mon|
|20221011|Weekday| Tue|
|20221012|Weekday| Wed|
|20221013|Weekday| Thu|
|20221014|Weekday| Fri|
|20221015|Weekend| Sat|
|20221016|Weekend| Sun|
|20221017|Weekday| Mon|
|20221018|Weekday| Tue|
|20221019|Weekday| Wed|
|20221020|Weekday| Thu|
+--------+-------+---------+
列(When)で比較
calendarDF.withColumn('JapaneseType',
F.when( \
F.col("type")=="Holiday" \
,"祝日" \
)\
.when( \
F.col("type")=="Weekend" \
,"休日" \
) \
.when( \
F.col("type")=="Weekday" \
,"平日" \
) \
).show()
===
+--------+-------+---------+------------+
| ymd| type|DayOfWeek|JapaneseType|
+--------+-------+---------+------------+
|20221001|Weekend| Sat| 休日|
|20221002|Weekend| Sun| 休日|
|20221003|Weekday| Mon| 平日|
|20221004|Weekday| Tue| 平日|
|20221005|Weekday| Wed| 平日|
|20221006|Weekday| Thu| 平日|
|20221007|Weekday| Fri| 平日|
|20221008|Weekend| Sat| 休日|
|20221009|Weekend| Sun| 休日|
|20221010|Holiday| Mon| 祝日|
|20221011|Weekday| Tue| 平日|
|20221012|Weekday| Wed| 平日|
|20221013|Weekday| Thu| 平日|
|20221014|Weekday| Fri| 平日|
|20221015|Weekend| Sat| 休日|
|20221016|Weekend| Sun| 休日|
|20221017|Weekday| Mon| 平日|
|20221018|Weekday| Tue| 平日|
|20221019|Weekday| Wed| 平日|
|20221020|Weekday| Thu| 平日|
+--------+-------+---------+------------+
結合
DataFrame同士を結合します。事前にデータを確認します。
calendarDf = S3bucket_calendar.toDF()
calendarDf.show()
===
+----------+-------+---------+
| ymd| type|DayOfWeek|
+----------+-------+---------+
|2022-10-01|Weekend| Sat|
|2022-10-02|Weekend| Sun|
|2022-10-03|Weekday| Mon|
|2022-10-04|Weekday| Tue|
|2022-10-05|Weekday| Wed|
|2022-10-06|Weekday| Thu|
|2022-10-07|Weekday| Fri|
|2022-10-08|Weekend| Sat|
|2022-10-09|Weekend| Sun|
|2022-10-10|Holiday| Mon|
|2022-10-11|Weekday| Tue|
|2022-10-12|Weekday| Wed|
|2022-10-13|Weekday| Thu|
|2022-10-14|Weekday| Fri|
|2022-10-15|Weekend| Sat|
|2022-10-16|Weekend| Sun|
|2022-10-17|Weekday| Mon|
|2022-10-18|Weekday| Tue|
|2022-10-19|Weekday| Wed|
|2022-10-20|Weekday| Thu|
+----------+-------+---------+
only showing top 20 rows
orderDf = S3bucket_order.toDF()
orderDf.show()
===
+----------+--------------+---------+-----------+
|order_date|order_parts_id|order_num|customer_id|
+----------+--------------+---------+-----------+
|2022-10-01| G-000000| 62| C-000|
|2022-10-01| G-000001| 89| C-000|
|2022-10-01| G-000002| 70| C-000|
|2022-10-01| G-000003| 80| C-000|
|2022-10-01| G-000004| 33| C-000|
|2022-10-01| G-000005| 32| C-000|
|2022-10-01| G-000006| 23| C-000|
|2022-10-01| G-000006| 71| C-001|
|2022-10-01| G-000007| 49| C-000|
|2022-10-01| G-000007| 81| C-001|
|2022-10-01| G-000008| 46| C-000|
|2022-10-01| G-000009| 81| C-000|
|2022-10-01| G-000009| 94| C-001|
|2022-10-01| G-000009| 60| C-002|
|2022-10-01| G-000010| 86| C-000|
|2022-10-01| G-000011| 58| C-000|
|2022-10-01| G-000012| 70| C-000|
|2022-10-01| G-000012| 91| C-001|
|2022-10-01| G-000012| 40| C-002|
|2022-10-01| G-000013| 3| C-000|
+----------+--------------+---------+-----------+
only showing top 20 rows
INNER JOIN
orderDf.join(calendarDf,orderDf.order_date == calendarDf.ymd,'inner').show()
===
+----------+--------------+---------+-----------+----------+-------+---------+
|order_date|order_parts_id|order_num|customer_id| ymd| type|DayOfWeek|
+----------+--------------+---------+-----------+----------+-------+---------+
|2022-10-01| G-000000| 62| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000001| 89| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000002| 70| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000003| 80| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000004| 33| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000005| 32| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000006| 23| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000006| 71| C-001|2022-10-01|Weekend| Sat|
|2022-10-01| G-000007| 49| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000007| 81| C-001|2022-10-01|Weekend| Sat|
|2022-10-01| G-000008| 46| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000009| 81| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000009| 94| C-001|2022-10-01|Weekend| Sat|
|2022-10-01| G-000009| 60| C-002|2022-10-01|Weekend| Sat|
|2022-10-01| G-000010| 86| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000011| 58| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000012| 70| C-000|2022-10-01|Weekend| Sat|
|2022-10-01| G-000012| 91| C-001|2022-10-01|Weekend| Sat|
|2022-10-01| G-000012| 40| C-002|2022-10-01|Weekend| Sat|
|2022-10-01| G-000013| 3| C-000|2022-10-01|Weekend| Sat|
+----------+--------------+---------+-----------+----------+-------+---------+
only showing top 20 rows
LEFT OUTER JOIN
calendarDf.join(orderDf,calendarDf.ymd == orderDf.order_date,'left').filter(calendarDf.ymd == '2022-10-02').show()
===
+----------+-------+---------+----------+--------------+---------+-----------+
| ymd| type|DayOfWeek|order_date|order_parts_id|order_num|customer_id|
+----------+-------+---------+----------+--------------+---------+-----------+
|2022-10-02|Weekend| Sun| null| null| null| null|
+----------+-------+---------+----------+--------------+---------+-----------+
DataFrameの列をリストに変換する
df.show()
calendar_list = [row['ymd'] for row in df.select("ymd").distinct().orderBy("ymd").collect()]
for ymd in calendar_list:
print(ymd)
===
+----------+-------+---------+
| ymd| type|DayOfWeek|
+----------+-------+---------+
|2022-10-01|Weekend| Sat|
|2022-10-02|Weekend| Sun|
|2022-10-03|Weekday| Mon|
|2022-10-04|Weekday| Tue|
|2022-10-05|Weekday| Wed|
|2022-10-06|Weekday| Thu|
|2022-10-07|Weekday| Fri|
|2022-10-08|Weekend| Sat|
|2022-10-09|Weekend| Sun|
|2022-10-10|Holiday| Mon|
|2022-10-11|Weekday| Tue|
|2022-10-12|Weekday| Wed|
|2022-10-13|Weekday| Thu|
|2022-10-14|Weekday| Fri|
|2022-10-15|Weekend| Sat|
|2022-10-16|Weekend| Sun|
|2022-10-17|Weekday| Mon|
|2022-10-18|Weekday| Tue|
|2022-10-19|Weekday| Wed|
|2022-10-20|Weekday| Thu|
+----------+-------+---------+
only showing top 20 rows
2022-10-01
2022-10-02
2022-10-03
2022-10-04
2022-10-05
2022-10-06
2022-10-07
2022-10-08
2022-10-09
2022-10-10
2022-10-11
2022-10-12
2022-10-13
2022-10-14
2022-10-15
・・・・
集計
こちらのデータを元に実装します。
## ApplyMapping
orderDf = S3bucket_order.toDF()
orderDf.printSchema()
orderDf.show()
ApplyMappingDynamicFrame = ApplyMapping.apply(frame=S3bucket_order, mappings=[
("order_date", "string", "order_date", "date")
,("order_parts_id","string", "order_parts_id", "string")
,("order_num","integer", "order_num", "integer")
,("customer_id","string", "customer_id", "string"),
],transformation_ctx="transformation_ctx",)
ApplyMappingDynamicFrame.printSchema()
ApplyMappingDynamicFrame.show()
# DFに変換
df = S3bucket_order.toDF()
===
root
|-- order_date: string (nullable = true)
|-- order_parts_id: string (nullable = true)
|-- order_num: integer (nullable = true)
|-- customer_id: string (nullable = true)
+----------+--------------+---------+-----------+
|order_date|order_parts_id|order_num|customer_id|
+----------+--------------+---------+-----------+
|2022-10-01| G-000000| 28| C-000|
|2022-10-01| G-000000| 41| C-001|
|2022-10-01| G-000000| 39| C-002|
|2022-10-01| G-000000| 19| C-003|
|2022-10-01| G-000000| 88| C-004|
|2022-10-01| G-000000| 3| C-005|
|2022-10-01| G-000001| 59| C-000|
|2022-10-01| G-000002| 26| C-000|
|2022-10-01| G-000002| 63| C-001|
|2022-10-01| G-000002| 68| C-002|
|2022-10-01| G-000002| 35| C-003|
|2022-10-01| G-000002| 61| C-004|
|2022-10-01| G-000002| 66| C-005|
|2022-10-01| G-000003| 28| C-000|
|2022-10-01| G-000003| 92| C-001|
|2022-10-01| G-000003| 77| C-002|
|2022-10-01| G-000003| 5| C-003|
|2022-10-01| G-000003| 34| C-004|
|2022-10-01| G-000003| 55| C-005|
|2022-10-01| G-000003| 76| C-006|
+----------+--------------+---------+-----------+
only showing top 20 rows
root
|-- order_date: date
|-- order_parts_id: string
|-- order_num: int
|-- customer_id: string
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 28, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 41, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 39, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 19, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 88, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 3, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000001", "order_num": 59, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 26, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 63, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 68, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 35, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 61, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 66, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 28, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 92, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 77, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 5, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 34, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 55, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 76, "customer_id": "C-006"}
合計
df.groupBy("order_parts_id").agg({"order_num": "sum"}).show()
===
+--------------+--------------+
|order_parts_id|sum(order_num)|
+--------------+--------------+
| G-000008| 187|
| G-000012| 614|
| G-000028| 517|
| G-000043| 310|
| G-000063| 119|
| G-000094| 277|
| G-000120| 212|
| G-000157| 116|
| G-000162| 402|
| G-000223| 259|
| G-000256| 98|
| G-000277| 89|
| G-000285| 51|
| G-000305| 637|
| G-000349| 141|
| G-000398| 57|
| G-000400| 282|
| G-000407| 401|
| G-000439| 77|
| G-000470| 407|
+--------------+--------------+
only showing top 20 rows
カウント
df.groupBy("order_parts_id").count().show()
===
+--------------+-----+
|order_parts_id|count|
+--------------+-----+
| G-366517| 3|
| G-366520| 7|
| G-366570| 2|
| G-366571| 3|
| G-366573| 7|
| G-366628| 10|
| G-366734| 6|
| G-366749| 3|
| G-366773| 1|
| G-366860| 2|
| G-366958| 4|
| G-367153| 8|
| G-367157| 8|
| G-367175| 1|
| G-367233| 9|
| G-367236| 2|
| G-367267| 3|
| G-367281| 3|
| G-367324| 10|
| G-367364| 7|
+--------------+-----+
only showing top 20 rows
ソート
DataFrameのデータセットをソートします。
キーを指定
デフォルトで昇順を確認します。
df.orderBy("id").show()
===
+-----+--------+-----+---+--------------------+
| id|category|value|num| timestamp|
+-----+--------+-----+---+--------------------+
|00001| c001|test1| 1|2022-10-01T10:00:...|
|00002| c001|test2| 2|2022-10-02T10:00:...|
|00003| c002|test3| 3|2022-10-03T10:00:...|
|00004| c003|test4| 4|2022-10-04T10:00:...|
|00005| c004|test5| 5|2022-10-05T10:00:...|
+-----+--------+-----+---+--------------------+
明示的に昇順を指定
df.orderBy(asc("id")).show()
===
+-----+--------+-----+---+--------------------+
| id|category|value|num| timestamp|
+-----+--------+-----+---+--------------------+
|00001| c001|test1| 1|2022-10-01T10:00:...|
|00002| c001|test2| 2|2022-10-02T10:00:...|
|00003| c002|test3| 3|2022-10-03T10:00:...|
|00004| c003|test4| 4|2022-10-04T10:00:...|
|00005| c004|test5| 5|2022-10-05T10:00:...|
+-----+--------+-----+---+--------------------+
降順を指定
df.orderBy(desc("id")).show()
===
+-----+--------+-----+---+--------------------+
| id|category|value|num| timestamp|
+-----+--------+-----+---+--------------------+
|00005| c004|test5| 5|2022-10-05T10:00:...|
|00004| c003|test4| 4|2022-10-04T10:00:...|
|00003| c002|test3| 3|2022-10-03T10:00:...|
|00002| c001|test2| 2|2022-10-02T10:00:...|
|00001| c001|test1| 1|2022-10-01T10:00:...|
+-----+--------+-----+---+--------------------+
カラム追加
withColumnを使用する
- 既存のデータフレームに、"addColumn"というカラムで、値をリテラル(0)を追加する。
df.select("*").withColumn("addColumn",lit(0).cast(IntegerType())).show()
Window処理
事前確認
使用するデータ①
実行前の状態を確認します。
## ApplyMapping
ApplyMappingDynamicFrame = ApplyMapping.apply(frame=S3bucket_order, mappings=[
("order_date", "string", "order_date", "date")
,("order_parts_id","string", "order_parts_id", "string")
,("order_num","integer", "order_num", "integer")
,("customer_id","string", "customer_id", "string"),
],transformation_ctx="transformation_ctx",)
ApplyMappingDynamicFrame.printSchema()
ApplyMappingDynamicFrame.show()
===
root
|-- order_date: date
|-- order_parts_id: string
|-- order_num: int
|-- customer_id: string
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 28, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 41, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 39, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 19, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 88, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 3, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000001", "order_num": 59, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 26, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 63, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 68, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 35, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 61, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 66, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 28, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 92, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 77, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 5, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 34, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 55, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 76, "customer_id": "C-006"}
使用するデータ②
実行前の状態を確認します。
S3bucket_calendar.printSchema()
S3bucket_calendar.show()
===
root
|-- ymd: string
|-- type: string
|-- DayOfWeek: string
{"ymd": "2022-10-01", "type": "Weekend", "DayOfWeek": "Sat"}
{"ymd": "2022-10-02", "type": "Weekend", "DayOfWeek": "Sun"}
{"ymd": "2022-10-03", "type": "Weekday", "DayOfWeek": "Mon"}
{"ymd": "2022-10-04", "type": "Weekday", "DayOfWeek": "Tue"}
{"ymd": "2022-10-05", "type": "Weekday", "DayOfWeek": "Wed"}
{"ymd": "2022-10-06", "type": "Weekday", "DayOfWeek": "Thu"}
{"ymd": "2022-10-07", "type": "Weekday", "DayOfWeek": "Fri"}
{"ymd": "2022-10-08", "type": "Weekend", "DayOfWeek": "Sat"}
{"ymd": "2022-10-09", "type": "Weekend", "DayOfWeek": "Sun"}
{"ymd": "2022-10-10", "type": "Holiday", "DayOfWeek": "Mon"}
{"ymd": "2022-10-11", "type": "Weekday", "DayOfWeek": "Tue"}
{"ymd": "2022-10-12", "type": "Weekday", "DayOfWeek": "Wed"}
{"ymd": "2022-10-13", "type": "Weekday", "DayOfWeek": "Thu"}
{"ymd": "2022-10-14", "type": "Weekday", "DayOfWeek": "Fri"}
{"ymd": "2022-10-15", "type": "Weekend", "DayOfWeek": "Sat"}
{"ymd": "2022-10-16", "type": "Weekend", "DayOfWeek": "Sun"}
{"ymd": "2022-10-17", "type": "Weekday", "DayOfWeek": "Mon"}
{"ymd": "2022-10-18", "type": "Weekday", "DayOfWeek": "Tue"}
{"ymd": "2022-10-19", "type": "Weekday", "DayOfWeek": "Wed"}
{"ymd": "2022-10-20", "type": "Weekday", "DayOfWeek": "Thu"}
連続値を採番
order_numで並び替えて、連番を振ります。
from pyspark.sql.functions import *
from pyspark.sql import Window
df = ApplyMappingDynamicFrame.toDF()
df.withColumn("rownum",row_number().over(Window.orderBy("order_num"))).show()
===
+----------+--------------+---------+-----------+------+
|order_date|order_parts_id|order_num|customer_id|rownum|
+----------+--------------+---------+-----------+------+
|2022-10-01| G-244599| 1| C-005| 1|
|2022-10-01| G-244628| 1| C-001| 2|
|2022-10-01| G-244631| 1| C-004| 3|
|2022-10-01| G-244636| 1| C-000| 4|
|2022-10-01| G-244643| 1| C-005| 5|
|2022-10-01| G-244708| 1| C-005| 6|
|2022-10-01| G-244717| 1| C-003| 7|
|2022-10-01| G-244740| 1| C-000| 8|
|2022-10-01| G-244748| 1| C-004| 9|
|2022-10-01| G-244753| 1| C-004| 10|
|2022-10-01| G-244763| 1| C-008| 11|
|2022-10-01| G-244775| 1| C-004| 12|
|2022-10-01| G-244781| 1| C-000| 13|
|2022-10-01| G-244789| 1| C-004| 14|
|2022-10-01| G-244794| 1| C-001| 15|
|2022-10-01| G-244800| 1| C-004| 16|
|2022-10-01| G-244807| 1| C-000| 17|
|2022-10-01| G-244814| 1| C-000| 18|
|2022-10-01| G-244827| 1| C-000| 19|
|2022-10-01| G-244845| 1| C-004| 20|
+----------+--------------+---------+-----------+------+
指定した列単位に連続値を採番
ここでは、order_parts_id毎に連番を採番します。
from pyspark.sql.functions import *
from pyspark.sql import Window
df = ApplyMappingDynamicFrame.toDF()
df.withColumn("rownum",row_number().over(Window.partitionBy("order_parts_id").orderBy("order_num"))).show()
===
# order_parts_idごとに連番が振られている事がわかります。(G-000008=1〜3、G-000012=1〜9)
+----------+--------------+---------+-----------+------+
|order_date|order_parts_id|order_num|customer_id|rownum|
+----------+--------------+---------+-----------+------+
|2022-10-01| G-000008| 57| C-002| 1|
|2022-10-01| G-000008| 65| C-000| 2|
|2022-10-01| G-000008| 65| C-001| 3|
|2022-10-01| G-000012| 5| C-000| 1|
|2022-10-01| G-000012| 13| C-006| 2|
|2022-10-01| G-000012| 60| C-002| 3|
|2022-10-01| G-000012| 72| C-004| 4|
|2022-10-01| G-000012| 75| C-005| 5|
|2022-10-01| G-000012| 93| C-003| 6|
|2022-10-01| G-000012| 97| C-008| 7|
|2022-10-01| G-000012| 99| C-001| 8|
|2022-10-01| G-000012| 100| C-007| 9|
|2022-10-01| G-000028| 13| C-003| 1|
|2022-10-01| G-000028| 27| C-008| 2|
|2022-10-01| G-000028| 28| C-000| 3|
|2022-10-01| G-000028| 37| C-004| 4|
|2022-10-01| G-000028| 56| C-007| 5|
|2022-10-01| G-000028| 57| C-006| 6|
|2022-10-01| G-000028| 62| C-009| 7|
|2022-10-01| G-000028| 70| C-005| 8|
+----------+--------------+---------+-----------+------+
指定した値の範囲内で最大値、最小値、合計値、カウントを求める(1)
order_parts_id単位で、order_numの値で並び替えて、値を取得する。
- 下限:Window.unboundedPreceding = -9223372036854775808
- 上限:Window.unboundedFollowing = 9223372036854775807
Window.currentRow = 0も利用できる。
from pyspark.sql.functions import *
from pyspark.sql import Window
df = ApplyMappingDynamicFrame.toDF()
window = Window.partitionBy("order_parts_id").orderBy("order_num").rangeBetween(Window.unboundedPreceding, Window.unboundedFollowing)
df.withColumn("max_order_num",max("order_num").over(window)).withColumn("min_order_num",min("order_num").over(window)).withColumn("sum_order_num",sum("order_num").over(window)).withColumn("count_order_num",count("order_num").over(window)).show()
===
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
|order_date|order_parts_id|order_num|customer_id|max_order_num|min_order_num|sum_order_num|count_order_num|
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
|2022-10-01| G-000008| 57| C-002| 65| 57| 187| 3|
|2022-10-01| G-000008| 65| C-000| 65| 57| 187| 3|
|2022-10-01| G-000008| 65| C-001| 65| 57| 187| 3|
|2022-10-01| G-000012| 5| C-000| 100| 5| 614| 9|
|2022-10-01| G-000012| 13| C-006| 100| 5| 614| 9|
|2022-10-01| G-000012| 60| C-002| 100| 5| 614| 9|
|2022-10-01| G-000012| 72| C-004| 100| 5| 614| 9|
|2022-10-01| G-000012| 75| C-005| 100| 5| 614| 9|
|2022-10-01| G-000012| 93| C-003| 100| 5| 614| 9|
|2022-10-01| G-000012| 97| C-008| 100| 5| 614| 9|
|2022-10-01| G-000012| 99| C-001| 100| 5| 614| 9|
|2022-10-01| G-000012| 100| C-007| 100| 5| 614| 9|
|2022-10-01| G-000028| 13| C-003| 90| 13| 517| 10|
|2022-10-01| G-000028| 27| C-008| 90| 13| 517| 10|
|2022-10-01| G-000028| 28| C-000| 90| 13| 517| 10|
|2022-10-01| G-000028| 37| C-004| 90| 13| 517| 10|
|2022-10-01| G-000028| 56| C-007| 90| 13| 517| 10|
|2022-10-01| G-000028| 57| C-006| 90| 13| 517| 10|
|2022-10-01| G-000028| 62| C-009| 90| 13| 517| 10|
|2022-10-01| G-000028| 70| C-005| 90| 13| 517| 10|
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
only showing top 20 rows
指定した値の範囲内で最大値、最小値、合計値、カウントを求める(2)
order_parts_id単位で、order_numの値で並び替えて、値を取得する。
- 下限:-10
- 上限:10
from pyspark.sql.functions import *
from pyspark.sql import Window
df = ApplyMappingDynamicFrame.toDF()
window = Window.partitionBy("order_parts_id").orderBy("order_num").rangeBetween(-10, 10)
df.withColumn("max_order_num",max("order_num").over(window)).withColumn("min_order_num",min("order_num").over(window)).withColumn("sum_order_num",sum("order_num").over(window)).withColumn("count_order_num",count("order_num").over(window)).show()
===
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
|order_date|order_parts_id|order_num|customer_id|max_order_num|min_order_num|sum_order_num|count_order_num|
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
|2022-10-01| G-000008| 57| C-002| 65| 57| 187| 3|
|2022-10-01| G-000008| 65| C-000| 65| 57| 187| 3|
|2022-10-01| G-000008| 65| C-001| 65| 57| 187| 3|
|2022-10-01| G-000012| 5| C-000| 13| 5| 18| 2|
|2022-10-01| G-000012| 13| C-006| 13| 5| 18| 2|
|2022-10-01| G-000012| 60| C-002| 60| 60| 60| 1|
|2022-10-01| G-000012| 72| C-004| 75| 72| 147| 2|
|2022-10-01| G-000012| 75| C-005| 75| 72| 147| 2|
|2022-10-01| G-000012| 93| C-003| 100| 93| 389| 4|
|2022-10-01| G-000012| 97| C-008| 100| 93| 389| 4|
|2022-10-01| G-000012| 99| C-001| 100| 93| 389| 4|
|2022-10-01| G-000012| 100| C-007| 100| 93| 389| 4|
|2022-10-01| G-000028| 13| C-003| 13| 13| 13| 1|
|2022-10-01| G-000028| 27| C-008| 37| 27| 92| 3|
|2022-10-01| G-000028| 28| C-000| 37| 27| 92| 3|
|2022-10-01| G-000028| 37| C-004| 37| 27| 92| 3|
|2022-10-01| G-000028| 56| C-007| 62| 56| 175| 3|
|2022-10-01| G-000028| 57| C-006| 62| 56| 175| 3|
|2022-10-01| G-000028| 62| C-009| 70| 56| 245| 4|
|2022-10-01| G-000028| 70| C-005| 77| 62| 209| 3|
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
only showing top 20 rows
指定した行数の範囲内で最大値、最小値、合計値、カウントを求める
order_parts_id単位で、order_numの値で並び替えて、値を取得する。
from pyspark.sql.functions import *
from pyspark.sql import Window
df = ApplyMappingDynamicFrame.toDF()
window = Window.partitionBy("order_parts_id").orderBy("order_num").rowsBetween(-10, 10)
df.withColumn("max_order_num",max("order_num").over(window)).withColumn("min_order_num",min("order_num").over(window)).withColumn("sum_order_num",sum("order_num").over(window)).withColumn("count_order_num",count("order_num").over(window)).show()
===
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
|order_date|order_parts_id|order_num|customer_id|max_order_num|min_order_num|sum_order_num|count_order_num|
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
|2022-10-01| G-000008| 57| C-002| 65| 57| 187| 3|
|2022-10-01| G-000008| 65| C-000| 65| 57| 187| 3|
|2022-10-01| G-000008| 65| C-001| 65| 57| 187| 3|
|2022-10-01| G-000012| 5| C-000| 100| 5| 614| 9|
|2022-10-01| G-000012| 13| C-006| 100| 5| 614| 9|
|2022-10-01| G-000012| 60| C-002| 100| 5| 614| 9|
|2022-10-01| G-000012| 72| C-004| 100| 5| 614| 9|
|2022-10-01| G-000012| 75| C-005| 100| 5| 614| 9|
|2022-10-01| G-000012| 93| C-003| 100| 5| 614| 9|
|2022-10-01| G-000012| 97| C-008| 100| 5| 614| 9|
|2022-10-01| G-000012| 99| C-001| 100| 5| 614| 9|
|2022-10-01| G-000012| 100| C-007| 100| 5| 614| 9|
|2022-10-01| G-000028| 13| C-003| 90| 13| 517| 10|
|2022-10-01| G-000028| 27| C-008| 90| 13| 517| 10|
|2022-10-01| G-000028| 28| C-000| 90| 13| 517| 10|
|2022-10-01| G-000028| 37| C-004| 90| 13| 517| 10|
|2022-10-01| G-000028| 56| C-007| 90| 13| 517| 10|
|2022-10-01| G-000028| 57| C-006| 90| 13| 517| 10|
|2022-10-01| G-000028| 62| C-009| 90| 13| 517| 10|
|2022-10-01| G-000028| 70| C-005| 90| 13| 517| 10|
+----------+--------------+---------+-----------+-------------+-------------+-------------+---------------+
only showing top 20 rows
前後のレコードを取得する
- lag:前レコードを取得する
- lead:後レコードを取得する
全てのレコードを対象にするため、ダミーでカラムを追加している。もっと良いやり方があるかもしれない。
df = df.withColumn("dummy_column",lit("dummy"))
window = Window.partitionBy("dummy_column").orderBy("ymd")
from pyspark.sql.functions import *
from pyspark.sql import Window
df = S3bucket_calendar.toDF()
df = df.withColumn("dummy_column",lit("dummy"))
window = Window.partitionBy("dummy_column").orderBy("ymd")
df.withColumn("day_before",lag("ymd",default="N/A").over(window)).withColumn("next_day",lead("ymd",default="N/A").over(window)).orderBy("ymd").show()
===
+----------+-------+---------+------------+----------+----------+
| ymd| type|DayOfWeek|dummy_column|day_before| next_day|
+----------+-------+---------+------------+----------+----------+
|2022-10-01|Weekend| Sat| dummy| N/A|2022-10-02|
|2022-10-02|Weekend| Sun| dummy|2022-10-01|2022-10-03|
|2022-10-03|Weekday| Mon| dummy|2022-10-02|2022-10-04|
|2022-10-04|Weekday| Tue| dummy|2022-10-03|2022-10-05|
|2022-10-05|Weekday| Wed| dummy|2022-10-04|2022-10-06|
|2022-10-06|Weekday| Thu| dummy|2022-10-05|2022-10-07|
|2022-10-07|Weekday| Fri| dummy|2022-10-06|2022-10-08|
|2022-10-08|Weekend| Sat| dummy|2022-10-07|2022-10-09|
|2022-10-09|Weekend| Sun| dummy|2022-10-08|2022-10-10|
|2022-10-10|Holiday| Mon| dummy|2022-10-09|2022-10-11|
|2022-10-11|Weekday| Tue| dummy|2022-10-10|2022-10-12|
|2022-10-12|Weekday| Wed| dummy|2022-10-11|2022-10-13|
|2022-10-13|Weekday| Thu| dummy|2022-10-12|2022-10-14|
|2022-10-14|Weekday| Fri| dummy|2022-10-13|2022-10-15|
|2022-10-15|Weekend| Sat| dummy|2022-10-14|2022-10-16|
|2022-10-16|Weekend| Sun| dummy|2022-10-15|2022-10-17|
|2022-10-17|Weekday| Mon| dummy|2022-10-16|2022-10-18|
|2022-10-18|Weekday| Tue| dummy|2022-10-17|2022-10-19|
|2022-10-19|Weekday| Wed| dummy|2022-10-18|2022-10-20|
|2022-10-20|Weekday| Thu| dummy|2022-10-19|2022-10-21|
+----------+-------+---------+------------+----------+----------+
ループ処理
Rowごとに処理するなど、Sparkでは苦手です。PySparkではなく、Pythonで処理することもありますが、一旦Driverに集約して処理する必要があるので分散処理ができません。
そのような場合、rddのmapPartitionsを使用できます。
def func(p):
i = 0
for row in p:
i = i + 1
yield [row._key+",", row._value, i]
df = sc.parallelize([
('AAA', 1),
('BBB', 2),
('CCC', 3),
]).toDF()
df2=df.toDF("_key","_value").repartition(1)
df2.rdd.mapPartitions(func).toDF().show()
===
+----+---+---+
| _1| _2| _3|
+----+---+---+
|BBB,| 2| 1|
|AAA,| 1| 2|
|CCC,| 3| 3|
+----+---+---+
データ型の変更
ApplyMappingを使用する
DynamicFrameのスキーマを変更します。order_dateカラムをstringからdate型に変更します。
- 実行前の状態
orderDf = S3bucket_order.toDF()
orderDf.printSchema()
orderDf.show()
===
root
|-- order_date: string (nullable = true)
|-- order_parts_id: string (nullable = true)
|-- order_num: integer (nullable = true)
|-- customer_id: string (nullable = true)
+----------+--------------+---------+-----------+
|order_date|order_parts_id|order_num|customer_id|
+----------+--------------+---------+-----------+
|2022-10-01| G-000000| 28| C-000|
|2022-10-01| G-000000| 41| C-001|
|2022-10-01| G-000000| 39| C-002|
|2022-10-01| G-000000| 19| C-003|
|2022-10-01| G-000000| 88| C-004|
|2022-10-01| G-000000| 3| C-005|
|2022-10-01| G-000001| 59| C-000|
|2022-10-01| G-000002| 26| C-000|
|2022-10-01| G-000002| 63| C-001|
|2022-10-01| G-000002| 68| C-002|
|2022-10-01| G-000002| 35| C-003|
|2022-10-01| G-000002| 61| C-004|
|2022-10-01| G-000002| 66| C-005|
|2022-10-01| G-000003| 28| C-000|
|2022-10-01| G-000003| 92| C-001|
|2022-10-01| G-000003| 77| C-002|
|2022-10-01| G-000003| 5| C-003|
|2022-10-01| G-000003| 34| C-004|
|2022-10-01| G-000003| 55| C-005|
|2022-10-01| G-000003| 76| C-006|
+----------+--------------+---------+-----------+
- 実行と結果
ApplyMappingDynamicFrame = ApplyMapping.apply(frame=S3bucket_order, mappings=[
("order_date", "string", "order_date", "date")
,("order_parts_id","string", "order_parts_id", "string")
,("order_num","integer", "order_num", "integer")
,("customer_id","string", "customer_id", "string"),
],transformation_ctx="transformation_ctx",)
ApplyMappingDynamicFrame.printSchema()
ApplyMappingDynamicFrame.show()
===
root
|-- order_date: date
|-- order_parts_id: string
|-- order_num: int
|-- customer_id: string
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 28, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 41, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 39, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 19, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 88, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000000", "order_num": 3, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000001", "order_num": 59, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 26, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 63, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 68, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 35, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 61, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000002", "order_num": 66, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 28, "customer_id": "C-000"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 92, "customer_id": "C-001"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 77, "customer_id": "C-002"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 5, "customer_id": "C-003"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 34, "customer_id": "C-004"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 55, "customer_id": "C-005"}
{"order_date": 2022-10-01, "order_parts_id": "G-000003", "order_num": 76, "customer_id": "C-006"}
計測・実行計画
実行時間計測
以下は、10秒スリープしています。
- import timeが必要です。
start = time.time()
time.sleep(10)
print(time.time() - start)
===
10.004319667816162
実行計画
事前準備。以下のデータを作成する。
from py4j.java_gateway import java_import
java_import(spark._sc._jvm, "org.apache.spark.sql.api.python.*")
# DF変換
calerndarDF = S3bucket_calendar.toDF()
calerndarDF.printSchema()
calerndarDF.show(3)
orderDF = S3bucket_order.toDF()
orderDF.printSchema()
orderDF.show(3)
stockDF = S3bucket_stock.toDF()
stockDF.printSchema()
stockDF.show(3)
===
root
|-- ymd: string (nullable = true)
|-- type: string (nullable = true)
|-- DayOfWeek: string (nullable = true)
+----------+-------+---------+
| ymd| type|DayOfWeek|
+----------+-------+---------+
|2022-10-01|Weekend| Sat|
|2022-10-02|Weekend| Sun|
|2022-10-03|Weekday| Mon|
+----------+-------+---------+
only showing top 3 rows
root
|-- order_date: string (nullable = true)
|-- order_parts_id: string (nullable = true)
|-- order_num: integer (nullable = true)
|-- customer_id: string (nullable = true)
+----------+--------------+---------+-----------+
|order_date|order_parts_id|order_num|customer_id|
+----------+--------------+---------+-----------+
|2022-10-01| G-000000| 28| C-000|
|2022-10-01| G-000000| 41| C-001|
|2022-10-01| G-000000| 39| C-002|
+----------+--------------+---------+-----------+
only showing top 3 rows
root
|-- parts_id: string (nullable = true)
|-- parts_num: integer (nullable = true)
+--------+---------+
|parts_id|parts_num|
+--------+---------+
|G-000000| 3|
|G-000001| 4|
|G-000002| 29|
+--------+---------+
only showing top 3 rows
ジョイン
joinedDF = orderDF.join(stockDF,orderDF.order_parts_id == stockDF.parts_id,'left').select("order_date","order_parts_id","order_num","parts_num")
joinedDF.show(3)
===
+----------+--------------+---------+---------+
|order_date|order_parts_id|order_num|parts_num|
+----------+--------------+---------+---------+
|2022-10-01| G-000008| 65| 67|
|2022-10-01| G-000008| 65| 67|
|2022-10-01| G-000008| 57| 67|
+----------+--------------+---------+---------+
only showing top 3 rows
Physical Plan
joinedDF.explain(extended=False)
===
== Physical Plan ==
*(5) Project [order_date#16, order_parts_id#17, order_num#18, parts_num#38]
+- SortMergeJoin [order_parts_id#17], [parts_id#37], LeftOuter
:- *(2) Sort [order_parts_id#17 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(order_parts_id#17, 40)
: +- *(1) Project [order_date#16, order_parts_id#17, order_num#18]
: +- Scan ExistingRDD[order_date#16,order_parts_id#17,order_num#18,customer_id#19]
+- *(4) Sort [parts_id#37 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(parts_id#37, 40)
+- *(3) Filter isnotnull(parts_id#37)
+- Scan ExistingRDD[parts_id#37,parts_num#38]
Physical PlanとLogical Planの2つ
joinedDF.explain(extended=True)
===
== Parsed Logical Plan ==
'Project [unresolvedalias('order_date, None), unresolvedalias('order_parts_id, None), unresolvedalias('order_num, None), unresolvedalias('parts_num, None)]
+- Join LeftOuter, (order_parts_id#17 = parts_id#37)
:- LogicalRDD [order_date#16, order_parts_id#17, order_num#18, customer_id#19], false
+- LogicalRDD [parts_id#37, parts_num#38], false
== Analyzed Logical Plan ==
order_date: string, order_parts_id: string, order_num: int, parts_num: int
Project [order_date#16, order_parts_id#17, order_num#18, parts_num#38]
+- Join LeftOuter, (order_parts_id#17 = parts_id#37)
:- LogicalRDD [order_date#16, order_parts_id#17, order_num#18, customer_id#19], false
+- LogicalRDD [parts_id#37, parts_num#38], false
== Optimized Logical Plan ==
Project [order_date#16, order_parts_id#17, order_num#18, parts_num#38]
+- Join LeftOuter, (order_parts_id#17 = parts_id#37)
:- Project [order_date#16, order_parts_id#17, order_num#18]
: +- LogicalRDD [order_date#16, order_parts_id#17, order_num#18, customer_id#19], false
+- Filter isnotnull(parts_id#37)
+- LogicalRDD [parts_id#37, parts_num#38], false
== Physical Plan ==
*(5) Project [order_date#16, order_parts_id#17, order_num#18, parts_num#38]
+- SortMergeJoin [order_parts_id#17], [parts_id#37], LeftOuter
:- *(2) Sort [order_parts_id#17 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(order_parts_id#17, 40)
: +- *(1) Project [order_date#16, order_parts_id#17, order_num#18]
: +- Scan ExistingRDD[order_date#16,order_parts_id#17,order_num#18,customer_id#19]
+- *(4) Sort [parts_id#37 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(parts_id#37, 40)
+- *(3) Filter isnotnull(parts_id#37)
+- Scan ExistingRDD[parts_id#37,parts_num#38]
Glue Notebook
WorkerタイプとWorker数を変更する
G.2Xとワーカー数を149に変更
事前に、ワーカータイプをG.2Xに変更していたため、「Previous worker type:G.2X」と表示されています。
%worker_type 'G.2X'
%number_of_workers 149
===
You are already connected to session 92779871-832e-4124-8725-f071f2c8a0fc. Your change will not reflect in the current session, but it will affect future new sessions.
Previous worker type: G.2X
Setting new worker type to: G.2X
You are already connected to session 92779871-832e-4124-8725-f071f2c8a0fc. Your change will not reflect in the current session, but it will affect future new sessions.
Previous number of workers: 5
Setting new number of workers to: 149
参考