背景・目的
Sparkではメモリ内のデータセットを永続化する事が可能です。この機能を試してみたいと思います。
まとめ
- Sparkでは、キャッシュを使用してデータセット(RDD)を保存し再利用することが可能です。
- キャッシュ関連の関数(メソッド)には、下記が用意されています。
- cache()
- persist()
- キャッシュはLRUアルゴリズムによって追い出されるが、明示的に開放するには、下記を実行します。
- unpersist()
- キャッシュする際に、Storage Levelを指定することが可能。Storage Levelは下記のようなものがあります。
- メモリのみ
- メモリとディスクの組み合わせ
- ディスクのみ
- キャッシュする場合、上記のどこに保存するかに加えて、下記も選択可能です。
- 別のノードへのレプリケーション
- シリアライゼーション/デシリアライゼーション
概要
RDD Persistence
キャッシュされたデータセットは他のアクションの中で再利用でき、複数回再計算されることを防ぐことができます。また、永続化にはレベルを指定することが可能です。
関数
永続化するには、下記の2つの関数があります。
- cache()
- persist()
cache()は、デフォルトのストレージ レベルである StorageLevel.MEMORY_ONLY (逆シリアル化されたオブジェクトをメモリに格納する) を使用するための短縮形です。 これ以外を使用する場合は、persist()に次に示すStorage Levelを設定して使用します。
Storage Level
| Storage Level | Meaning | 格納場所 | 格納される形態 | 格納領域の使用量※1 | CPU負荷※2 |
|---|---|---|---|---|---|
| MEMORY_ONLY | RDD をデシリアル化された Java オブジェクトとして JVM に保存します。 RDD がメモリに収まらない場合、一部のパーティションはキャッシュされず、必要になるたびにオンザフライで再計算されます。 デフォルトのレベルです。 | メモリ(JVM) | デシリアライズ化済みJavaオブジェクト | 多 | 低 |
| MEMORY_AND_DISK | RDD を逆シリアル化された Java オブジェクトとして JVM に保存します。 RDD がメモリに収まらない場合は、ディスクに収まらないパーティションを保存し、必要なときにそこから読み取ります。 | メモリ(JVM)とディスク | 同上 | 多 | 低 |
| MEMORY_ONLY_SER (Java and Scala) |
RDD をシリアル化された Java オブジェクトとして保存します (パーティションごとに 1 バイトの配列)。 これは一般に、特に高速シリアライザーを使用する場合、逆シリアル化されたオブジェクトよりもスペース効率が高くなりますが、読み取りに CPU 負荷が高くなります。 | メモリ(JVM) | シリアライズ化済みJavaオブジェクト | 少 | 高 |
| MEMORY_AND_DISK_SER (Java and Scala) |
MEMORY_ONLY_SER と似ていますが、メモリに収まらないパーティションは、必要になるたびにその場で再計算するのではなく、ディスクに書き込まれます。 | メモリ(JVM)とディスク | 同上 | 少 | 高 |
| DISK_ONLY | RDD パーティションはディスク上にのみ保存します。 | ディスク | 明記されていないため不明 | 明記されていないため不明 | 明記されていないため不明 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 上記のレベルと同じですが、各パーティションを 2 つのクラスター ノードに複製します。 | 上記のレベルと同様 | 上記のレベルと同様 2つのノードに保存される |
上記のレベルと同様 | 上記のレベルと同様 |
| OFF_HEAP (experimental) | MEMORY_ONLY_SER と似ていますが、データをオフヒープ メモリに保存します。 これには、spark.memory.offHeap.enabledを有効にする必要があります。 |
メモリ(Off-Heap) | ? | ? | ? |
※1 格納領域の使用量については、格納される形態でシリアライズ化 or デシリアライズ化されているかで判断し付加している。シリアライズ化されている場合は、バイナリ化され小さくなっているため「少」としています。
※2 CPU付加については、格納される形態でシリアライズ化 or デシリアライズ化されているかで判断し付加している。シリアライズ化されている場合は、シリアライズ化による計算コストが多いため「高」としています。
実践
本検証では、メモリへの保存やディスクへ保存されているか確認が難しいため、cache やpersist、unpersitの違いにより
物理計画がどのように変わるかを確認します。
事前準備
事前に、データを作成しS3にアップロードします。
$ rm -f 20230520.json;for i in `seq 0 1000`;do ID=`echo $i`; VALUE=$RANDOM ;CATEGORY=`expr $VALUE % 10`;echo \{\"id\":"$ID"\,\"group\":\"$CATEGORY\",\"value\":$VALUE\} >> 20230520.json ;done; ls -l 20230520.json;head 20230520.json; tail 20230520.json
# ls -l の結果
-rw-r--r-- 1 XXX XXX 36619 5 20 18:44 20230520.json
# head の結果
{"id":0,"group":"2","value":1322}
{"id":1,"group":"6","value":18246}
{"id":2,"group":"1","value":32501}
{"id":3,"group":"4","value":9894}
{"id":4,"group":"6","value":24356}
{"id":5,"group":"2","value":16852}
{"id":6,"group":"1","value":661}
{"id":7,"group":"4","value":5224}
{"id":8,"group":"5","value":17355}
{"id":9,"group":"7","value":18017}
# tail の結果
{"id":991,"group":"7","value":31227}
{"id":992,"group":"5","value":30825}
{"id":993,"group":"2","value":21012}
{"id":994,"group":"2","value":10362}
{"id":995,"group":"7","value":3697}
{"id":996,"group":"2","value":17422}
{"id":997,"group":"7","value":9567}
{"id":998,"group":"4","value":9814}
{"id":999,"group":"2","value":31152}
{"id":1000,"group":"4","value":21284}
$
# S3にアップロード
$ aws s3 cp 20230520.json s3://${バケット名}/input/persist/20230520/
upload: ./20230520.json to s3://${バケット名}/input/persist/20230520/20230520.json
# アップロードされたファイルを確認
$ aws s3 ls s3://${バケット名}/input/persist/20230520/20230520.json
2023-05-20 18:47:21 36619 20230520.json
$
検証
1つのDataFrameを再利用するケースにおいて、cacheの有無で実行計画がどの様に変化するか確認します。
cache無し
-
df2までは共通で、df2を元にdf3と、df4〜df5で分岐させるコードです。こちらを実行します。
df = spark.read.json("s3://XXXXX/input/persist/20230520/") df2 = df.filter((df.group==1) | (df.group==2)) df3 = df2.groupBy('group').count() df3.show() df4 = df2.filter(df.id>100) df5 = df4.groupBy('group').count() df5.show() df3.explain() df5.explain() -
実行結果と、PhysicalPlanを確認します。df3、df5のアクションではそれぞれファイルからデータを読み込むところから2回実行されていることが分かります。
+-----+-----+
|group|count|
+-----+-----+
| 1| 106|
| 2| 114|
+-----+-----+
+-----+-----+
|group|count|
+-----+-----+
| 1| 96|
| 2| 98|
+-----+-----+
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[group#571], functions=[count(1)])
+- Exchange hashpartitioning(group#571, 1000), ENSURE_REQUIREMENTS, [plan_id=794]
+- HashAggregate(keys=[group#571], functions=[partial_count(1)])
+- Filter ((cast(group#571 as int) = 1) OR (cast(group#571 as int) = 2))
+- FileScan json [group#571] Batched: false, DataFilters: [((cast(group#571 as int) = 1) OR (cast(group#571 as int) = 2))], Format: JSON, Location: InMemoryFileIndex(1 paths)[s3://XXXXX/input/persist/20230520], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<group:string>
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[group#571], functions=[count(1)])
+- Exchange hashpartitioning(group#571, 1000), ENSURE_REQUIREMENTS, [plan_id=820]
+- HashAggregate(keys=[group#571], functions=[partial_count(1)])
+- Project [group#571]
+- Filter ((isnotnull(id#572L) AND ((cast(group#571 as int) = 1) OR (cast(group#571 as int) = 2))) AND (id#572L > 100))
+- FileScan json [group#571,id#572L] Batched: false, DataFilters: [isnotnull(id#572L), ((cast(group#571 as int) = 1) OR (cast(group#571 as int) = 2)), (id#572L > 1..., Format: JSON, Location: InMemoryFileIndex(1 paths)[s3://XXXXX/input/persist/20230520], PartitionFilters: [], PushedFilters: [IsNotNull(id), GreaterThan(id,100)], ReadSchema: struct<group:string,id:bigint>
cacheあり
-
df2までは共通で、df2をキャッシュしたdf_cacheを作成します。キャッシュされたDataFrameを元にdf3と、df4〜df5で分岐させるコードです。こちらを実行します。
df = spark.read.json("s3://XXXXX/input/persist/20230520/") df2 = df.filter((df.group==1) | (df.group==2)) df_cache = df2.persist() df3 = df_cache.groupBy('group').count() df3.show() df4 = df_cache.filter(df_cache.id>100) df5 = df4.groupBy('group').count() df5.show() df3.explain() df5.explain() -
実行結果と、PhysicalPlanを確認します。cacheの有無で比較すると下記に違いがありました。cache済みのDataFrameからデータを読み込んでいることが分かります。
- InMemoryTableScan
- InMemoryRelation
+-----+-----+ |group|count| +-----+-----+ | 1| 106| | 2| 114| +-----+-----+ +-----+-----+ |group|count| +-----+-----+ | 1| 96| | 2| 98| +-----+-----+ == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[group#2215], functions=[count(1)]) +- Exchange hashpartitioning(group#2215, 1000), ENSURE_REQUIREMENTS, [plan_id=1703] +- HashAggregate(keys=[group#2215], functions=[partial_count(1)]) +- InMemoryTableScan [group#2215] +- InMemoryRelation [group#2215, id#2216L, value#2217L], StorageLevel(disk, memory, deserialized, 1 replicas) +- *(1) Filter ((cast(group#631 as int) = 1) OR (cast(group#631 as int) = 2)) +- FileScan json [group#631,id#632L,value#633L] Batched: false, DataFilters: [((cast(group#631 as int) = 1) OR (cast(group#631 as int) = 2))], Format: JSON, Location: InMemoryFileIndex(1 paths)[s3://XXXXX/input/persist/20230520], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<group:string,id:bigint,value:bigint> == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[group#2215], functions=[count(1)]) +- Exchange hashpartitioning(group#2215, 1000), ENSURE_REQUIREMENTS, [plan_id=1727] +- HashAggregate(keys=[group#2215], functions=[partial_count(1)]) +- Project [group#2215] +- Filter (isnotnull(id#2216L) AND (id#2216L > 100)) +- InMemoryTableScan [group#2215, id#2216L], [isnotnull(id#2216L), (id#2216L > 100)] +- InMemoryRelation [group#2215, id#2216L, value#2217L], StorageLevel(disk, memory, deserialized, 1 replicas) +- *(1) Filter ((cast(group#631 as int) = 1) OR (cast(group#631 as int) = 2)) +- FileScan json [group#631,id#632L,value#633L] Batched: false, DataFilters: [((cast(group#631 as int) = 1) OR (cast(group#631 as int) = 2))], Format: JSON, Location: InMemoryFileIndex(1 paths)[s3://XXXXX/input/persist/20230520], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<group:string,id:bigint,value:bigint> -
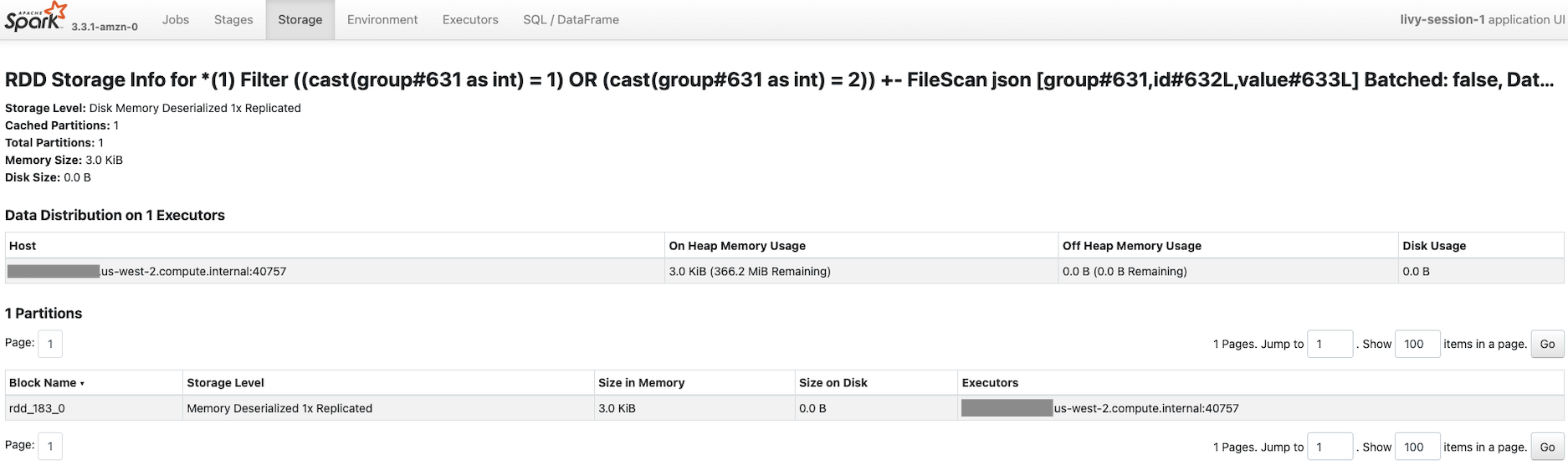
Spark UIでキャッシュされているか確認します。StorageタブをクリックするとRDDがキャッシュされていました。また、Fraction Cached が100%となっていました。

-
Memory Deserialized 1x Replicatedから分かるように、メモリにそのままの状態(3KiB)で格納されていることが分かりました。
考察
今回、cacheの有無で実行計画と、Spark UIのStorageで、実際にキャッシュされているか確認できました。
参考