背景・目的
- Kinesis Data StreamsやKinesis Data Firehoseは利用したことはありましたが、Kinesis Data Analyticsは触ったことがなかったので、試してみました。
サマリ
- SQLで、リアルタイム分析ができます。
- ストリーム処理では、入出力のリソースと、アプリケーション内入出力ストリームを使用します。SQLではDDLがこれに該当するようでした。
- 次は、Flinkを使って試す予定です。
概要
Amazon Kinesis Data Analytics for SQL Applicationsとは?
- SQLを使用してストリーミングデータを処理、分析できます。
- 時系列分析の実行、リアルタイムでのダッシュボードへのフィード、リアルタイムでのメトリクス作成を行うSQLコードをストリーミングソースに対してすぐに作成、実行できます。
Amazon Kinesis Data Analytics(以降、KDAという) が適している用途
- ほぼリアルタイムでデータを連続して読み取り、処理、保存するSQLコードを素早く作成できます。
- 以下、使用するシナリオの一例です。
- 時系列分析を生成する
- 時間ウィンドウに対してメトリクスを算出し、Kinesis Data Deliveryストリームを介して値をS3、Redshiftにストリーミングできる。
- リアルタイムダッシュボードをフィードする
- 集約された処理済みのストリーミングデータの結果を下流に送信し、リアルタイムのダッシュボードをフィードできる。
- リアルタイムのメトリクスを作成する
- リアルタイムのモニタリング、通知、アラームに使用するカスタムメトリクスを作成してトリガーできる
- 時系列分析を生成する
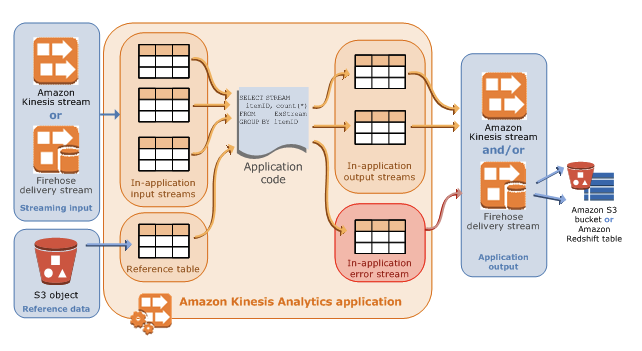
仕組み
- KDAは、ストリーミングデータをリアルタイムで継続的に読み取り処理します。
- SQLを使用して入力ストリームを処理し、出力を生成するアプリケーションを作成します。
- 各アプリケーションは、名前、説明、バージョンID、ステータスがあります。
- バージョンID
- KDAは最初にアプリケーションを作成するときに、バージョンIDを割り当てる。
- このバージョンIDは、アプリケーション設定の更新時に更新される。
- タイムスタンプ
- アプリケーションの作成時、最終更新時のタイムスタンプも保持する。
- バージョンID
- アプリケーションは、以下で構成されます。
| 構成要素 | 説明 | 備考 |
|---|---|---|
| INPUT | ・ アプリケーションのストリーミングソース ストリーミングソースとして、Kinesis Data Stream(以降、KDSという。)または、Kinesis Data Firehose(以降、KFHという。)が選択できる。 ・入力設定でストリーミングソースと、アプリケーション内入力ストリームをマッピングする。 |
|
| アプリケーション内入力ストリーム | ・継続的に更新されるテーブルのようなもの。 ・SELECT、INSERT SQLが実行可能。 ・アプリケーションコードで、中間クエリ結果を保存するための追加のアプリケーション内ストリームを作成することもできる。 ・各アプリケーションストリームにタイムスタンプ列が提供される。この列を使ってタイムベースウィンドウのクエリが実行できる。(※詳細はこちら) ・オプションでリファレンスデータソースを設定できる。 |
・オプションで、スループットを向上させるために単一のソースストリーミングを複数のアプリケーション内ストリーミングに分割できる。 |
| リファレンスデータソース | アプリケーション内リファレンステーブル。 ・リファレンスデータはS3バケット内のオブジェクトとして保存する必要がある。 ・アプリケーション起動に伴い、KDAはS3を読み込み、アプリケーション内テーブルを作成する。 |
|
| アプリケーションコード | 入力を生成し、出力を生成する一連のSQLステートメント。 アプリケーション内ストリーム、およびリファレンステーブルに対してSQLステートメントを書くことができる。 JOINクエリを書いて、これらのソース両方からデータを結合できる。 |
|
| OUTPUT | ・アプリケーションコードは、クエリ結果はアプリケーション内ストリームに入力される。 ・中間結果を保存する1つ以上のアプリケーション内ストリームを作成することもできる。その後、オプションでアプリケーション出力を設定してアプリケーション内ストリームデータを永続化し、アプリケーション出力を外部宛先に保持する。 ・外部宛先には、KFH、KDSを指定できる。 |
出力先に、S3、Redshift、OpenSearchを指定する場合、KFHを設定できる。 または、任意の宛先に出力する場合、KDSを指定し、Lambdaをにより宛先に書き出すことができる。 |
- KDAは、自動的に各アプリケーションに、アプリケーション内エラーストリームを提供します。エラーが発生したら後ほど原因分析できるように外部宛先で永続化するようにできる。
- アプリケーション出力レコードを設定された宛先に確実に書き込む。(at least once)詳細はこちら。
実践
ステップ 1: アカウントのセットアップと管理者ユーザーの作成
- 既に設定済みなので省略。
ステップ 2: AWS Command Line Interface (AWS CLI) のセットアップ
- 既に設定済みなので省略。
ステップ 3: スターター Amazon Kinesis Data Analytics アプリケーションを作成する
ステップ 3.1: アプリケーションを作成します。
1.Kinesisのマネコンで画面右上の、今すぐ始めるでKDAを選んで「アプリケーションの作成」をクリックします。

2.レガシーSQLアプリケーションの作成画面でアプリケーション名と説明に「ExampleSQLApp」を指定し、「レガシーSQLアプリケーションの作成」をクリックします。
3.しばらくすると作成が完了し、ステータスは準備完了になります。

ステップ 3.2: 入力の設定
1.作成したSQLアプリケーションで、ソースストリームの「設定」をクリックします。
2.デモストリームを使用をクリックします。
3.「スキーマを検出」をクリックします。しばらくするとスキーマにサンプルデータが表示されます。

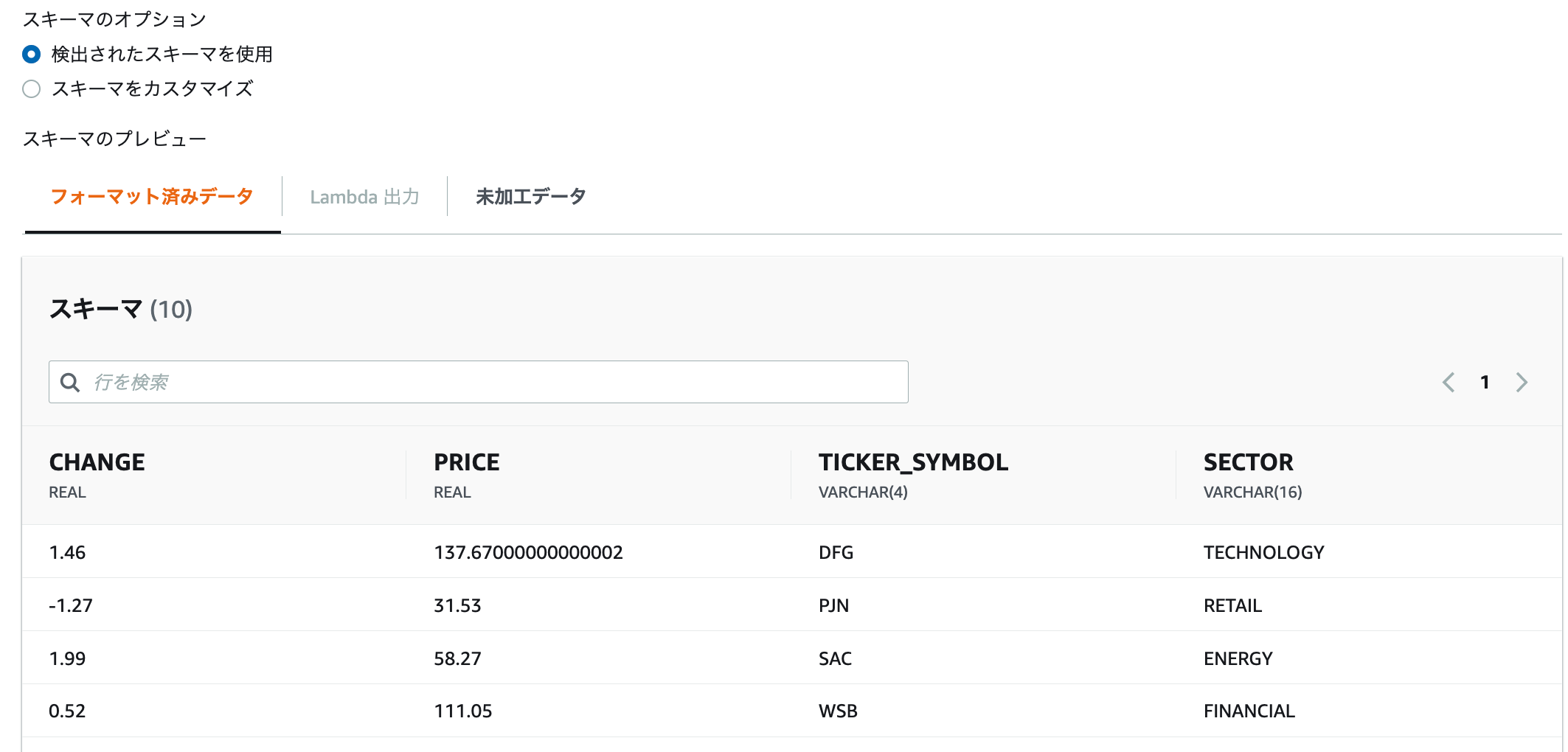
4.最後に「変更を保存」をクリックして終了します。
ステップ 3.3: リアルタイム分析の追加 (アプリケーションコードの追加)
1.リアルタイム分析のタブをクリックし、「設定」をクリックします。
2.「テンプレートからSQLを追加」をクリックします。
3.SQLテンプレートで「連続フィルター」を選択肢、「SQLをエディタに追加する」をクリックします。
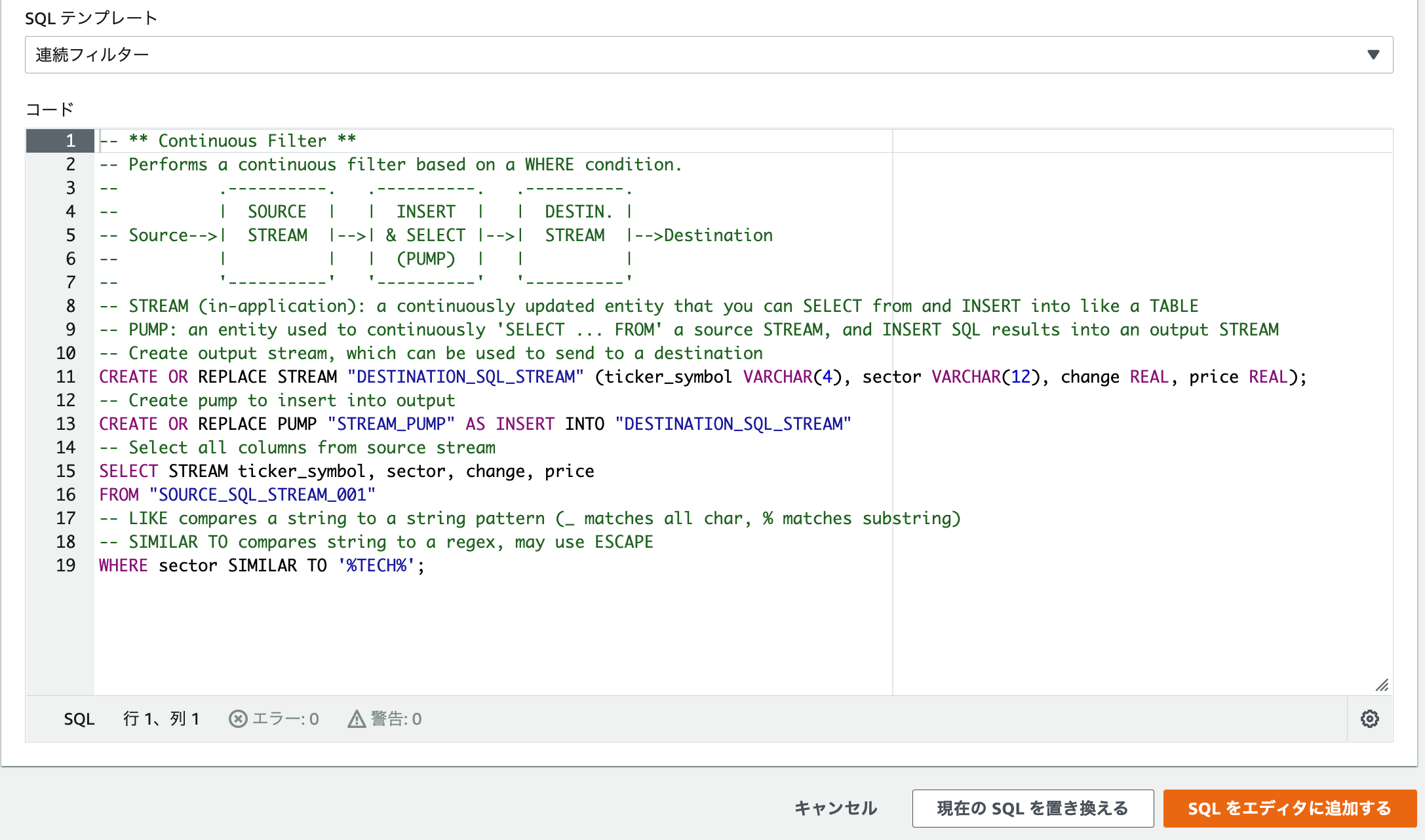
テンプレート「連続フィルター」のクエリ
/**
* Welcome to the SQL editor
* =========================
*
* The SQL code you write here will continuously transform your streaming data
* when your application is running.
*
* Get started by clicking "Add SQL from templates" or pull up the
* documentation and start writing your own custom queries.
*/
-- ** Continuous Filter **
-- Performs a continuous filter based on a WHERE condition.
-- .----------. .----------. .----------.
-- | SOURCE | | INSERT | | DESTIN. |
-- Source-->| STREAM |-->| & SELECT |-->| STREAM |-->Destination
-- | | | (PUMP) | | |
-- '----------' '----------' '----------'
-- STREAM (in-application): a continuously updated entity that you can SELECT from and INSERT into like a TABLE
-- PUMP: an entity used to continuously 'SELECT ... FROM' a source STREAM, and INSERT SQL results into an output STREAM
-- Create output stream, which can be used to send to a destination
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (ticker_symbol VARCHAR(4), sector VARCHAR(12), change REAL, price REAL);
-- Create pump to insert into output
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
-- Select all columns from source stream
SELECT STREAM ticker_symbol, sector, change, price
FROM "SOURCE_SQL_STREAM_001"
-- LIKE compares a string to a string pattern (_ matches all char, % matches substring)
-- SIMILAR TO compares string to a regex, may use ESCAPE
WHERE sector SIMILAR TO '%TECH%';
- 1つ目の
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (ticker_symbol VARCHAR(4), sector VARCHAR(12), change REAL, price REAL);で、出力ストリームを指定。 - 2つ目の
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"で
DESTINATION_SQL_STREAMにINSERTするPUMPを作成。 - 3つ目の以下のクエリで、入力ストリームから、sectorにTECHが含まれるレコードでフィルターする。
SELECT STREAM ticker_symbol, sector, change, price
FROM "SOURCE_SQL_STREAM_001"
WHERE sector SIMILAR TO '%TECH%';
6.「アプリケーションを保存して実行」をクリックします。

7.しばらくすると出力ストリームの「DESTINATION_SQL_STREAM」を選択すると、サンプル結果が表示されます。
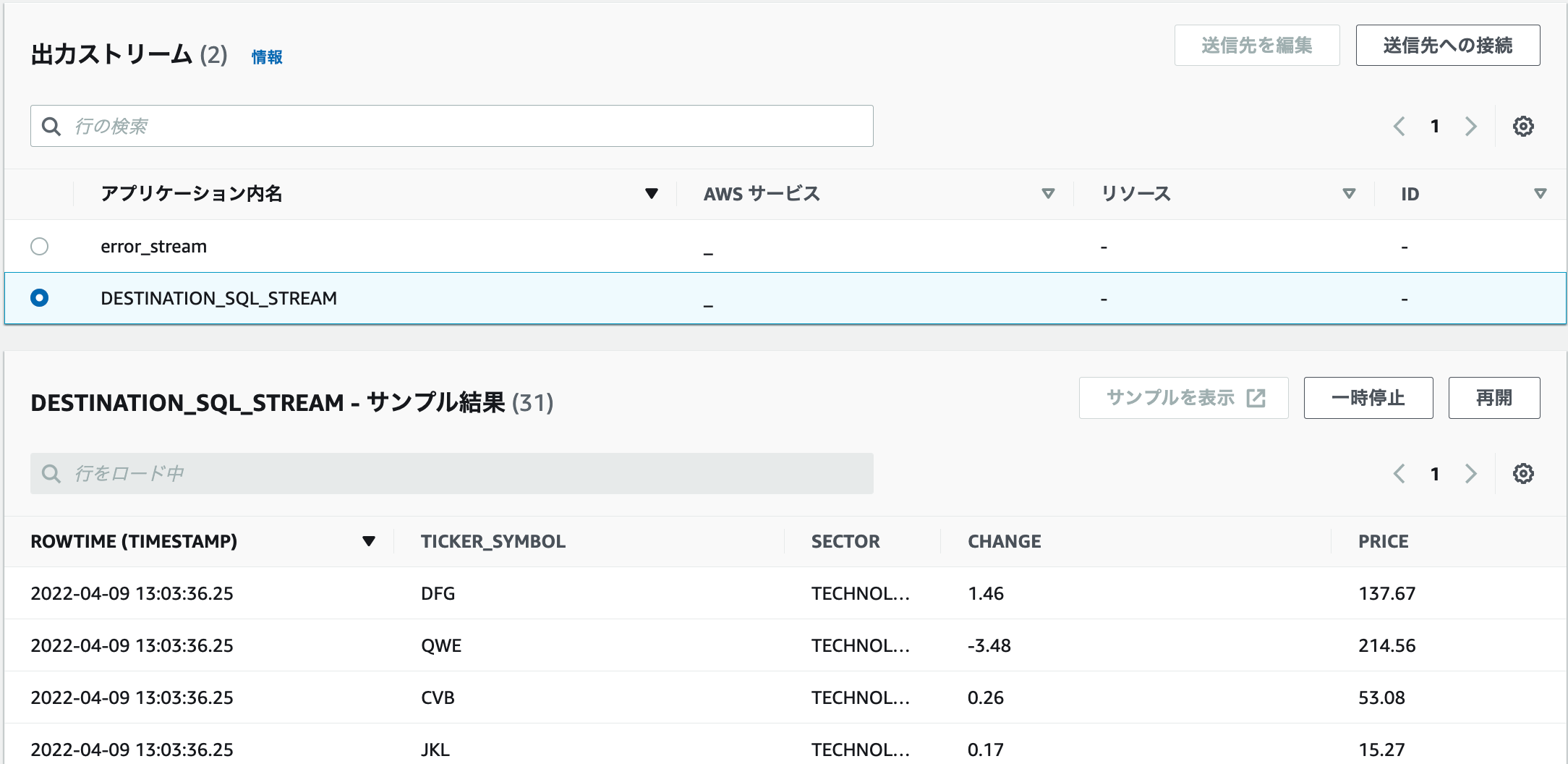
ステップ 3.4: (オプション) アプリケーションコードを更新する
- アプリケーションコードを更新します。
1.以下のコードを追加し、保存して実行します。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM_2"
(ticker_symbol VARCHAR(4),
change DOUBLE,
price DOUBLE);
CREATE OR REPLACE PUMP "STREAM_PUMP_2" AS
INSERT INTO "DESTINATION_SQL_STREAM_2"
SELECT STREAM ticker_symbol, change, price
FROM "DESTINATION_SQL_STREAM";
- DESTINATION_SQL_STREAM_2のアプリケーション内出力ストリームを作成します。
- DESTINATION_SQL_STREAMからSELECTし、DESTINATION_SQL_STREAM_2にINSERTします。
2.先ほどと同様に、DESTINATION_SQL_STREAMを選択すると、サンプル結果が表示されます。
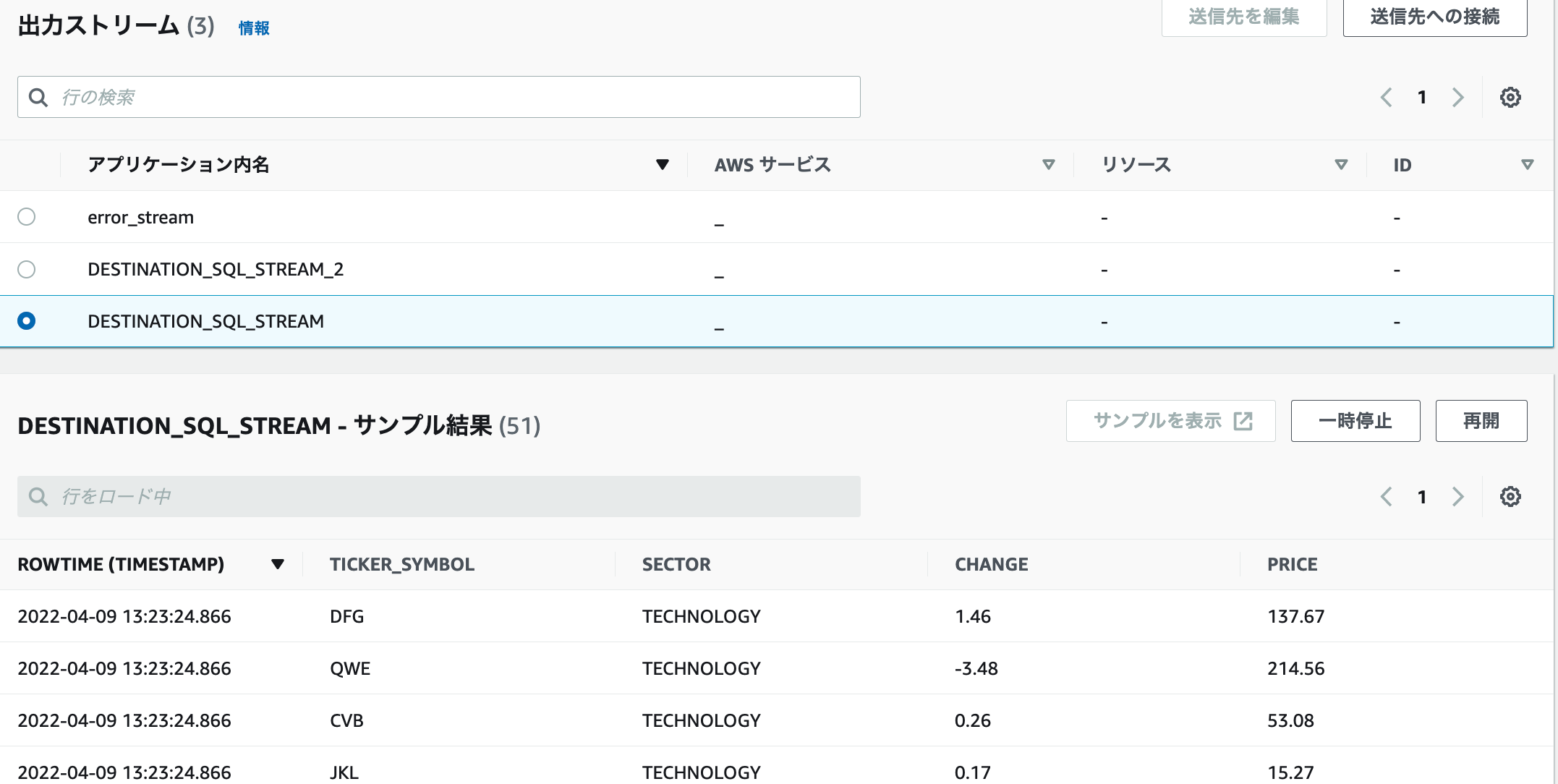
3.DESTINATION_SQL_STREAM_2を選択すると、ROWTIME(TIMESTAMP)が出てきました。
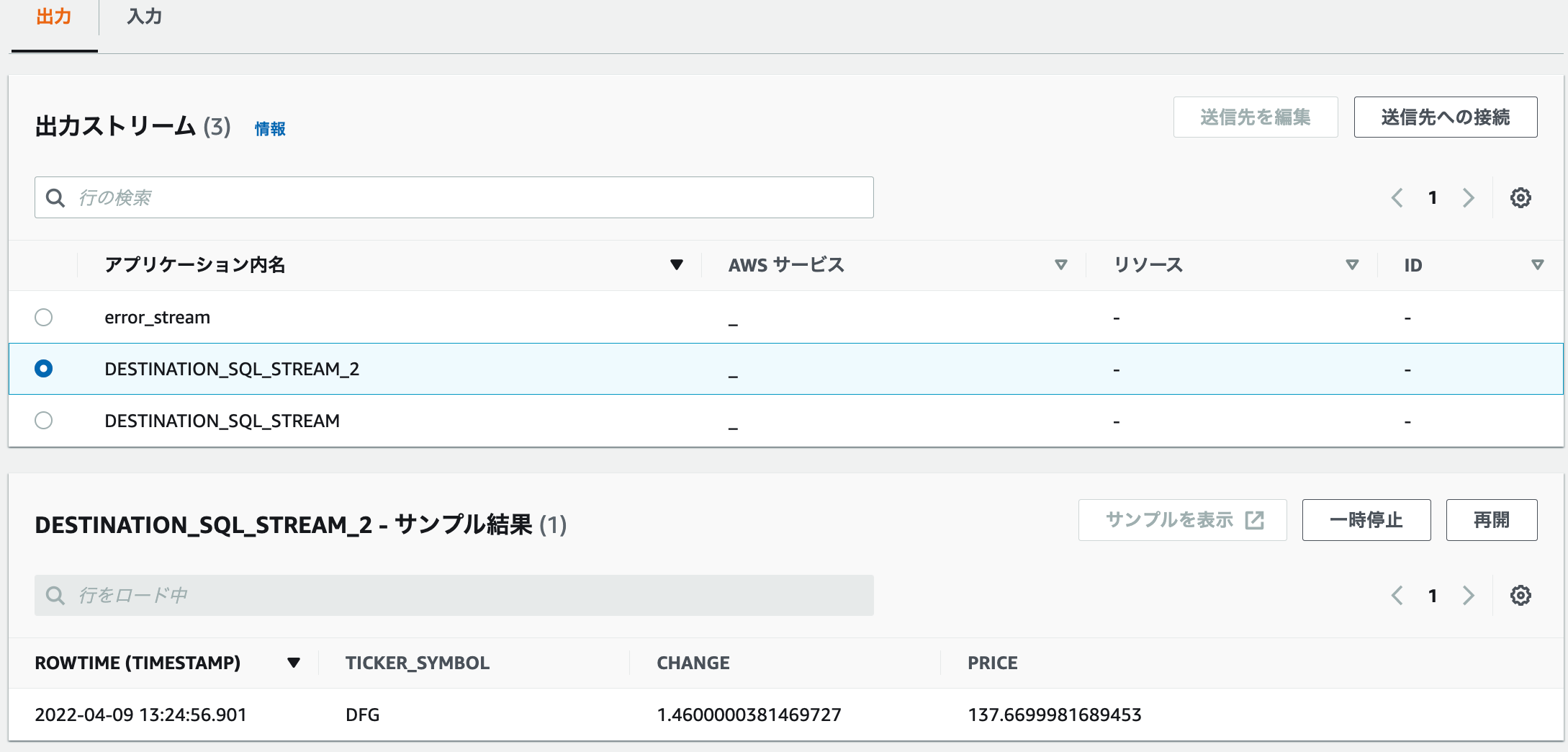
3.以下のコードを追加し、保存して実行するをクリックします。
CREATE OR REPLACE STREAM "AMZN_STREAM"
(ticker_symbol VARCHAR(4),
change DOUBLE,
price DOUBLE);
CREATE OR REPLACE PUMP "AMZN_PUMP" AS
INSERT INTO "AMZN_STREAM"
SELECT STREAM ticker_symbol, change, price
FROM "SOURCE_SQL_STREAM_001"
WHERE ticker_symbol SIMILAR TO '%AMZN%';
CREATE OR REPLACE STREAM "TGT_STREAM"
(ticker_symbol VARCHAR(4),
change DOUBLE,
price DOUBLE);
CREATE OR REPLACE PUMP "TGT_PUMP" AS
INSERT INTO "TGT_STREAM"
SELECT STREAM ticker_symbol, change, price
FROM "SOURCE_SQL_STREAM_001"
WHERE ticker_symbol SIMILAR TO '%TGT%';
- 出力ストリーム「AMZN_STREAM」を作成します。
- 入力ストリームSOURCE_SQL_STREAM_001から読み込み、ticker_symbolにAMZNが含まれるものをフィルターし、AMZN_STREAMにINSERTするPUMPを作成します。
- 出力ストリーム「TGT_STREAM」を作成します。
- 入力ストリームSOURCE_SQL_STREAM_001から読み込み、ticker_symbolにTGTが含まれるものをフィルターし、TGT_STREAMにINSERTするPUMPを作成します。
4.出力ストリーム「AMZN_STREAM」を選択します。なかなか出てこない。。
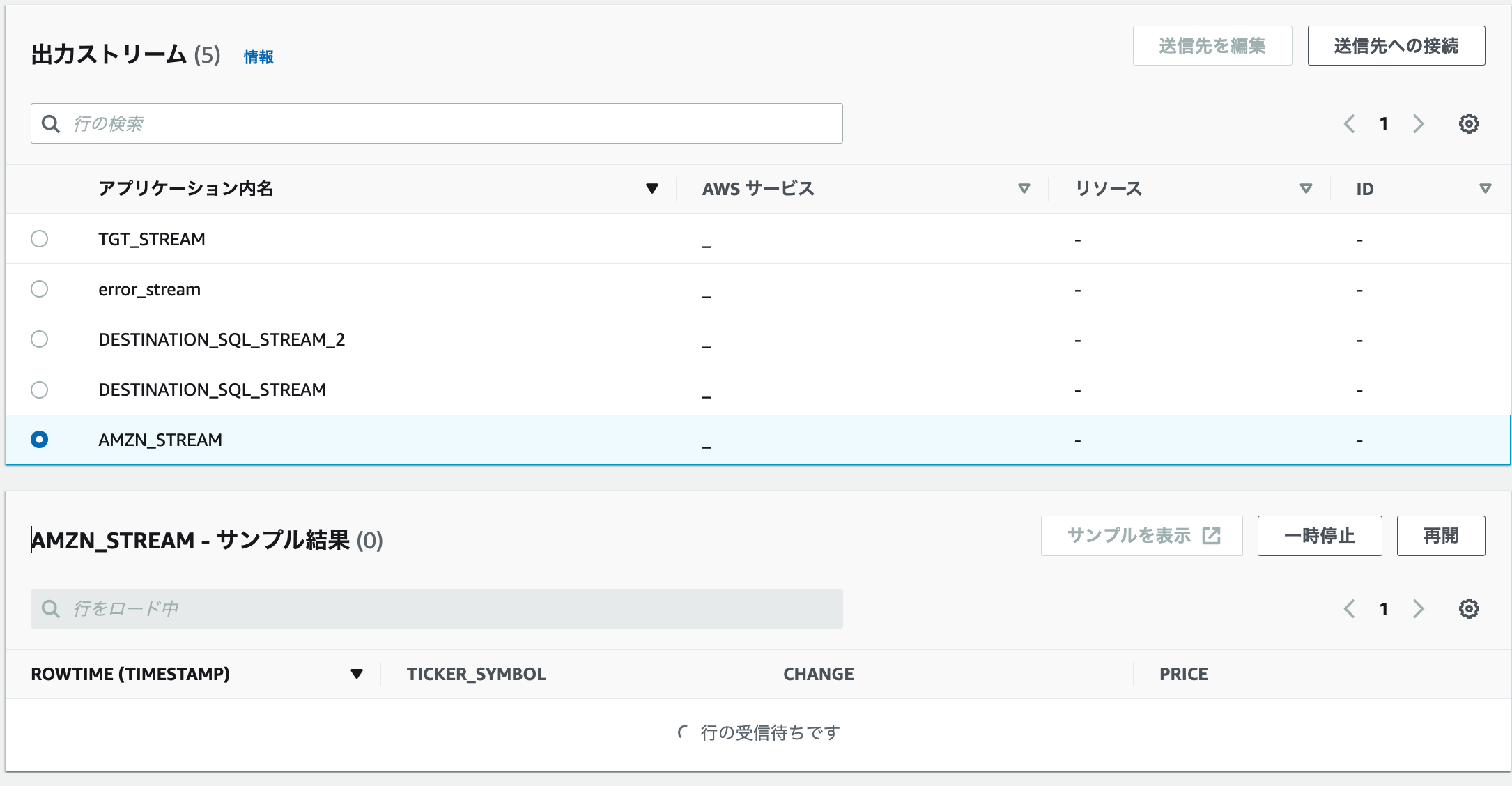
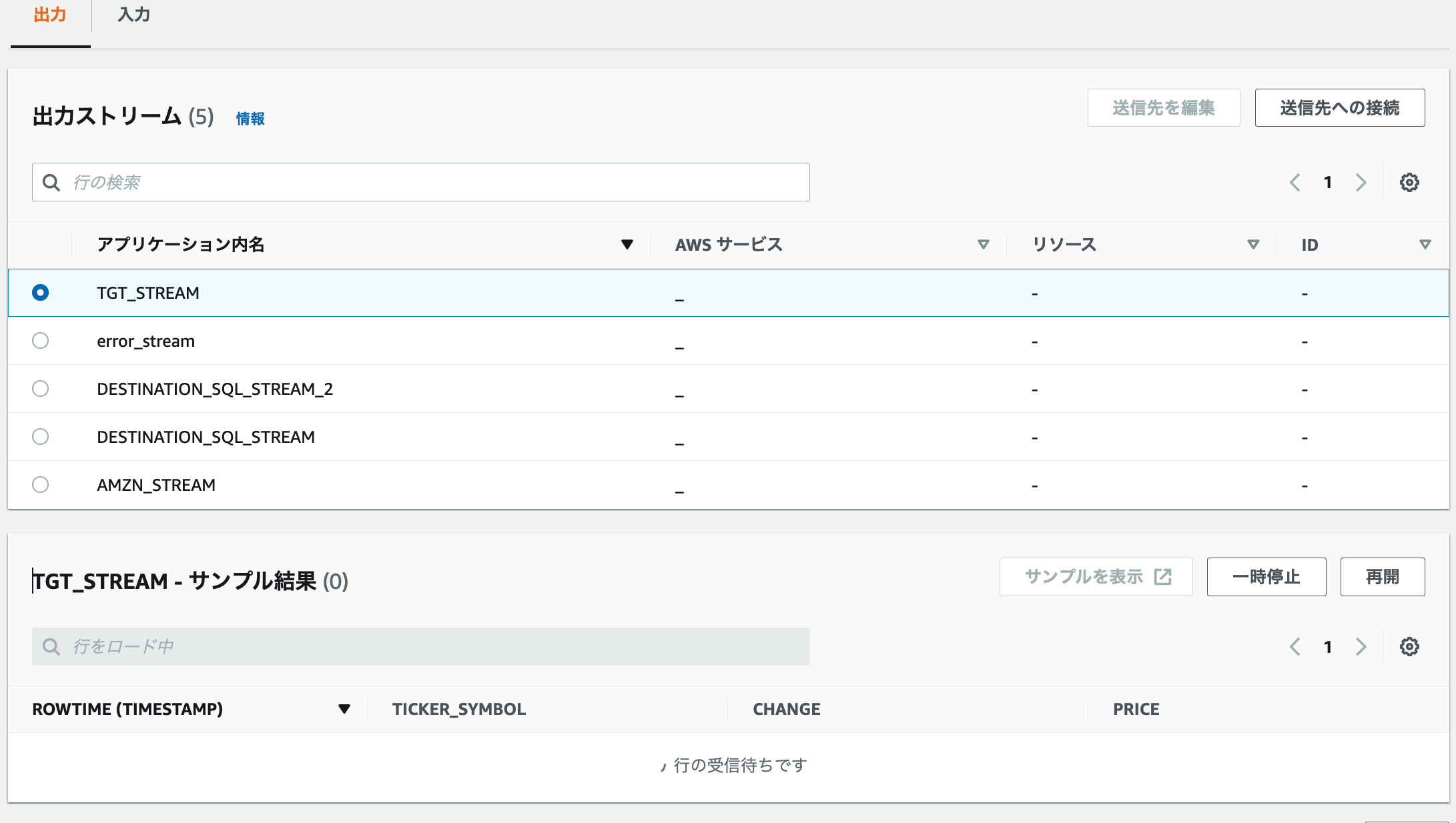
5.出力ストリーム「TGT_STREAM」を選択します。なかなか出てこない。。
考察
- 今回、KDA for SQLを試したが、SQL アプリケーション(レガシー)ではなく、Kinesis Data Analytics Studioを使うのが主流らしいです。
- 最後のAMZN_STREAM、TGT_STREAMでサンプルが出てこなかったのは、適したデータが入ってこなかったのか設定をミスしていたのかわからなかったが、SQLでのストリームアプリケーションの作り方のイメージはなんとなく持てました。
参考
https://docs.aws.amazon.com/ja_jp/kinesisanalytics/latest/dev/what-is.html
https://docs.aws.amazon.com/ja_jp/kinesisanalytics/latest/dev/getting-started.html