■ はじめに
今回は下記コンペに、LigthGBMで取り組みましたので
簡単にまとめてみました。
【概要】
・Titanic: Machine Learning from Disaster
・沈没する船「タイタニック号」の乗客情報をもとに、助かる人とそうでない人について判別する
【対象とする読者】
・Kaggle初心の方
・LightGBMの基礎コードについて学びたい方
1. モジュールの用意
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import confusion_matrix, classification_report
## 2. データの準備
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
print(train.shape)
print(test.shape)
# (891, 12)
# (418, 11)
train.head()

【データ項目】
・PassengerId:乗客ID
・Survived:生存したかどうか(0:助からない、1:助かる)
・Pclass – チケットのクラス(1:上層クラス、2:中級クラス、3:下層クラス)
・Name:乗客の名前
・Sex:性別
・Age:年齢
・SibSp:船に同乗している兄弟・配偶者の数
・parch:船に同乗している親・子供の数
・ticket:チケット番号
・fare:料金
・cabin:客室番号
・Embarked:船に乗った港(C:Cherbourg、Q:Queenstown、S:Southampton)
test.head()

testデータの乗客番号(PassengerId)を保存しておきます。
PassengerId = test['PassengerId']
実際にはtrainデータのみでモデルの作成を行いますが
train・testデータをまとめて前処理したいので、結合を考えます。
trainデータは項目が1つ多い(目的変数:Survived)ので分離します。
y = train['Survived']
train = train[[col for col in train.columns if col != 'Survived']]
print(train.shape)
print(test.shape)
# (891, 11)
# (418, 11)
これでtrain データとtest データの項目(特徴量)数が同じになったので、結合します。
X_total = pd.concat([train, test], axis=0)
print(X_total.shape)
X_total.head()
# (1309, 11)

3. 前処理
まず、欠損値がどの程度あるのかを確認します。
print(X_total.isnull().sum())
'''
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 1014
Embarked 2
dtype: int64
'''
LightGBMでは、文字列データのままモデルの作成が可能なため
数値変換は行わずに前処理をしていきます。
X_total.fillna(value=-999, inplace=True)
print(X_total.isnull().sum())
'''
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
'''
ここで、文字列データのカラム(以降、カテゴリカル)を調べます。
categorical_col = [col for col in X_total.columns if X_total[col].dtype == 'object']
print('categorical_col:', categorical_col)
# categorical_col: ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']
各カテゴリカルのデータ型を調べます。
for i in X_total[categorical_col]:
print('{}: {}'.format(i, X_total[i].dtype))
'''
Name: object
Sex: object
Ticket: object
Cabin: object
Embarked: object
'''
LightGBMは、文字列データのままモデリングできますが
object型ではなくcategory型にする必要があるため、データ型を変換していきます。
for i in categorical_col:
X_total[i] = X_total[i].astype("category")
全体データ(X_total)のデータ型を見ておきます。
for i in X_total.columns:
print('{}: {}'.format(i, X_total[i].dtype))
'''
PassengerId: int64
Pclass: int64
Name: category
Sex: category
Age: float64
SibSp: int64
Parch: int64
Ticket: category
Fare: float64
Cabin: category
Embarked: category
'''
# 4. モデルの作成 trainデータのみでモデルを作成したいですが X_totalはtestデータも含んでしまっているため、必要な部分のみを抽出します。
train_rows = train.shape[0]
X = X_total[:train_rows]
print(X.shape)
print(y.shape)
# (891, 11)
# (891,)
trainデータに該当する特徴量と目的変数が揃ったので
さらに学習データとテストデータに分けて、モデルの作成をしていきます。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# (623, 11)
# (623,)
# (268, 11)
# (268,)
パラメータを設定し、辞書型の引数としてLGBMClassifier()に渡します。
params = {
"random_state": 42
}
cls = lgb.LGBMClassifier(**params)
cls.fit(X_train, y_train, categorical_feature = categorical_col)
'''
LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31, objective=None,
random_state=42, reg_alpha=0.0, reg_lambda=0.0, silent=True,
subsample=1.0, subsample_for_bin=200000, subsample_freq=0)
'''
次に予測値を求めます。
y_probaに[ : , 1]を指定することで、Class1(Survived=1)になる確率を予測します。
y_predは0.5よりも大きければ1に、小さければ0に変換しています。
y_proba = cls.predict_proba(X_test)[: , 1]
print(y_proba[:5])
y_pred = cls.predict(X_test)
print(y_pred[:5])
# [0.38007409 0.00666063 0.04531554 0.95244042 0.35233708]
# [0 0 0 1 0]
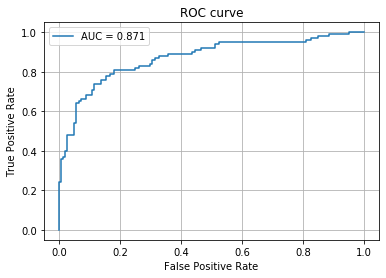
## 5. 性能評価 ROC曲線とAUCを用いて評価します。
fpr, tpr, thresholds = roc_curve(y_test, y_proba)
auc_score = roc_auc_score(y_test, y_proba)
plt.plot(fpr, tpr, label='AUC = %.3f' % (auc_score))
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
print('accuracy:',accuracy_score(y_test, y_pred))
print('f1_score:',f1_score(y_test, y_pred))
# accuracy: 0.8208955223880597
# f1_score: 0.7446808510638298
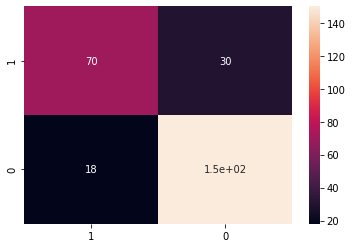
また、混同行列も用いて評価してみます。
classes = [1, 0]
cm = confusion_matrix(y_test, y_pred, labels=classes)
cmdf = pd.DataFrame(cm, index=classes, columns=classes)
sns.heatmap(cmdf, annot=True)
print(classification_report(y_test, y_pred))
'''
precision recall f1-score support
0 0.83 0.89 0.86 168
1 0.80 0.70 0.74 100
accuracy 0.82 268
macro avg 0.81 0.80 0.80 268
weighted avg 0.82 0.82 0.82 268
'''
6. Submit
trainデータを用いて、モデルの作成・評価ができたので
testデータの情報を与えて、予測値を出していきます。
まず全体データ(X_total)のうち、testデータに該当する部分を抽出します。
X_submit = X_total[train_rows:]
print(X_train.shape)
print(X_submit.shape)
# (623, 11)
# (418, 11)
モデルを作成したX_trainと比較して、同じ特徴量数(11)になっているので
X_submitをモデルに投入して、予測値を出します。
y_proba_submit = cls.predict_proba(X_submit)[: , 1]
print(y_proba_submit[:5])
y_pred_submit = cls.predict(X_submit)
print(y_pred_submit[:5])
# [0.00948223 0.02473048 0.01005387 0.50935871 0.45433965]
# [0 0 0 1 0]
KaggleへSubmit(提出)するCSVデータを用意します。
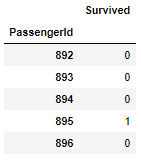
まず、必要な情報を揃えたデータフレームを作成します。
df_submit = pd.DataFrame(y_pred_submit, index=PassengerId, columns=['Survived'])
df_submit.head()
その後、CSVデータに変換します。
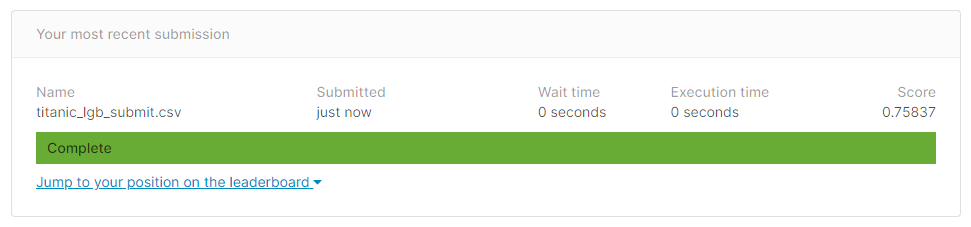
df_submit.to_csv('titanic_lgb_submit.csv')
これで、Submitをして終了です。
■ 最後に
今回はKaggle初心者の方に向けて、記事をまとめさせていただきました。
少しでもお役に立てたようでしたら幸いです。
ご精読いただきありがとうございました。