さくらインターネット Advent Calender 2016 その1 の、1日目を担当している @zembutsu こと、前佛雅人です。( その2 もあります!)
「複数のサーバやスイッチを、コマンド1つで一括管理しよう!」というコンセプトのもと、さくらのクラウドでも Terraform が使えるのを伝えたい、その一心で本日の記事を書きました。
クラウドや Terraform に至る登場背景(どうして Terraform が必要となったのか)から、クラウドの GUI 上で面倒な作業を行わずに、コマンド1つでスイッチを含む複数台のシステムを、作成・変更・削除する方法をご紹介します。
「もう Terraform は知っている、すぐに試したい!」というかたは、後半のチュートリアル編からお読みください。

インフラ管理の課題を解決する Terraform
クラウドと仮想化と API
「クラウド・コンピューティング」や、「IaaS」(Infrastructure as a Service:サービスとしてのシステム基盤)という言葉が 2009 年頃から広く伝わりはじめ、今日のコンピュータやインターネットに関わる技術者であれば、知らない人がいない概念になっているでしょう。
このクラウドを構成する技術要素は様々ですが、重要なのは2つです。1つは、ハードウェアの仮想化技術です。仮想化により、1つの物理システム上で複数の OS を利用できます。そのため、CPU やメモリやディスクといったシステム・リソースに空きがあれば、無駄なく有効利用できるようになりました。
この仮想化技術は、インターネット上のサーバだけでなく、皆さんの開発環境におけるパソコン上でも一般的に利用されています。これは、パソコンの CPU 性能や搭載メモリ容量、ディスク容量が増えたことにより、余剰リソースを有効活用できるようになったからです。
そしてもう1つ重要な要素は、クラウドのシステムが API を備えている点。ここが単なる仮想化との大きな違いです。クラウドのシステムは API のエンドポイントを備えています。そのため、ブラウザなど GUI やコマンドライン上を通さず、システム操作が可能となりました。
つまり、人間が操作しなくても、プログラムを通してシステム基盤を操作できる土壌が登場したのです。あるいは API の連携により、システムとシステムのつなぎこみも可能となったのです。
SNS の拡散と、止まらない世界
私たちのシステム構築のありかたを変えたのは、単にクラウド・コンピューティングが登場したからではありません。ある種、世の中からの要請があったからと言えるのではないでしょうか。
それは携帯電話やスマートフォンを通したインターネットの普及です。かつて、ネットワークを触れるには、パソコンなど何らかの据え置き型の端末を必要としました。しかし、電話と通信のネットワークが融合したことにより、どこでもネットにアクセスできるようになりました。そして、新しい需要が生まれます。SNS(ソーシャル・ネットワーキング・サービス)の登場です。
SNS の登場は、ゆるやかな変化ではありますが、私たちの生活を大きく変えつつあります。24時間、世界中のどこにいても誰かと誰かがコミュニケーションをとれる環境の登場。かつて、24時間営業のコンビニが世の中に出たことにより、私たちの生活の利便性が高まりました。同様に、24時間コミュニケーション可能な環境の登場は、新しいサービスに対する需要、すなわち、より豊かで幸せな生活を送りたい欲求を高めるものとなるでしょう。
そうなりますと、常にシステムでは以下の点を考える必要が出てきます。
- サービスを常に安定して提供し続けなくてはいけない(可用性)
- システムに対するアクセスのピークが、人間の生活と連動する(キャパシティ・プラニング)
このシステムとは、提供するサービスにより必要となるシステム要件が異なるでしょう。しかも、いかに迅速にサービスを提供できるかが、他のサービスに対する差別化となり、企業における競争力なり利益につながります。
それに、何よりも重要なのは、日々の機能追加やサービス改善に伴い「システムも変化し続ける」必要が出てきました。もはや、「システムを構築して終わり」のような時代ではありません。
この状況にシステム開発現場が対応するには、いかに速く環境を構築し、切り替えをし、システムのリソースを有効活用するかが課題となり、まさにこの点を解決するのがクラウド・コンピューティングだったのです。
手作業と生産性と(人類がボトルネックになりました)
一方で新しい課題も発生します。クラウドの登場により、システム基盤を迅速に準備できるようになりましたが、それを準備する人間に課題が出てきます。たとえば GUI や CLI を通した操作の場合は、時間がかかったり、操作ミスが起こることもありえます。
また、システム構成が常に変化し続けると、誰がどのようにシステム基盤を管理するかという問題も発生します。システムの安定稼働には、最新の情報を保つ必要性と、正確さの維持が欠かせません。仮に手順書なりシステム構成図を作成・維持するとしても、どのチームの誰が(開発エンジニア?運用エンジニア?)それを常にメンテナンスするのでしょうか。そして、どのように最新の構成情報かつ正確性を担保するのでしょう。
せっかくクラウド基盤を導入しても、介在する人が増えれば増えるほど(アムダールの法則のように)課題が増えるため、生産性の妨げとなってしまいます。なぜ妨げになるのかといえば、人間の手作業や管理が介在するから、その調整のために時間がかかり、それがボトルネックとなるからです。理想としては人間の完全なる排除こそが、生産性向上には欠かせないのかもしれません。
その理想を目指すには、クラウドが提供する API の利用こそが活路となります。API を備えているクラウドであれば、人間が操作をしなくても機械的(プログラマブル)に操作できるからです。とはいえ、API を使うためには当然何らかのプログラムを記述する必要がありますし、クラウドごとに勉強したり、プログラムを開発・使い分ける必要が出てきてしまいます。
人間の管理する手間を排除しつつ、どのように効率的に変化するインフラを活用しうるのか。
この問いに対する答えの1つこそが、、 Terraform というソフトウェアの目指す所なのです。
Terraform (テラフォーム)とは?
Terraform とはシステム基盤をコードで管理するためのコマンドライン・ツールです。Terraform はオープンソース・プロジェクトとして開発されており、コードそのものもオープンです。開発主体は Vagrant や Packer などを開発している HashiCorp です。
Terraform はサイト上の定義では、次のように説明されています。
Terraform enables you to safely and predictably create, change, and improve production infrastructure. (Terraform はプロダクションのインフラを安全かつ正確に作成・変更・改良できるます)
Terraform はプラグインを通し、様々なクラウドや仮想化システム上の API と通信可能です。単に通信できるだけでなく、インフラを構成する要素を「リソース」という単位で抽象化して扱えます。たとえば、仮想サーバやネットワークの1つ1つをリソースとして扱います。そして、これらのリソースをテキスト形式の設定ファイル上で管理できるのです。
また、Terraform の操作には terraform という名前のコマンドライン・ツールを使います。Terraform は Go 言語で開発されており、実行可能なバイナリは Linux だけでなく、macOS 版、Windows 版などが提供されています。
Terraform は計画(plan)と適用(apply)の繰り返し
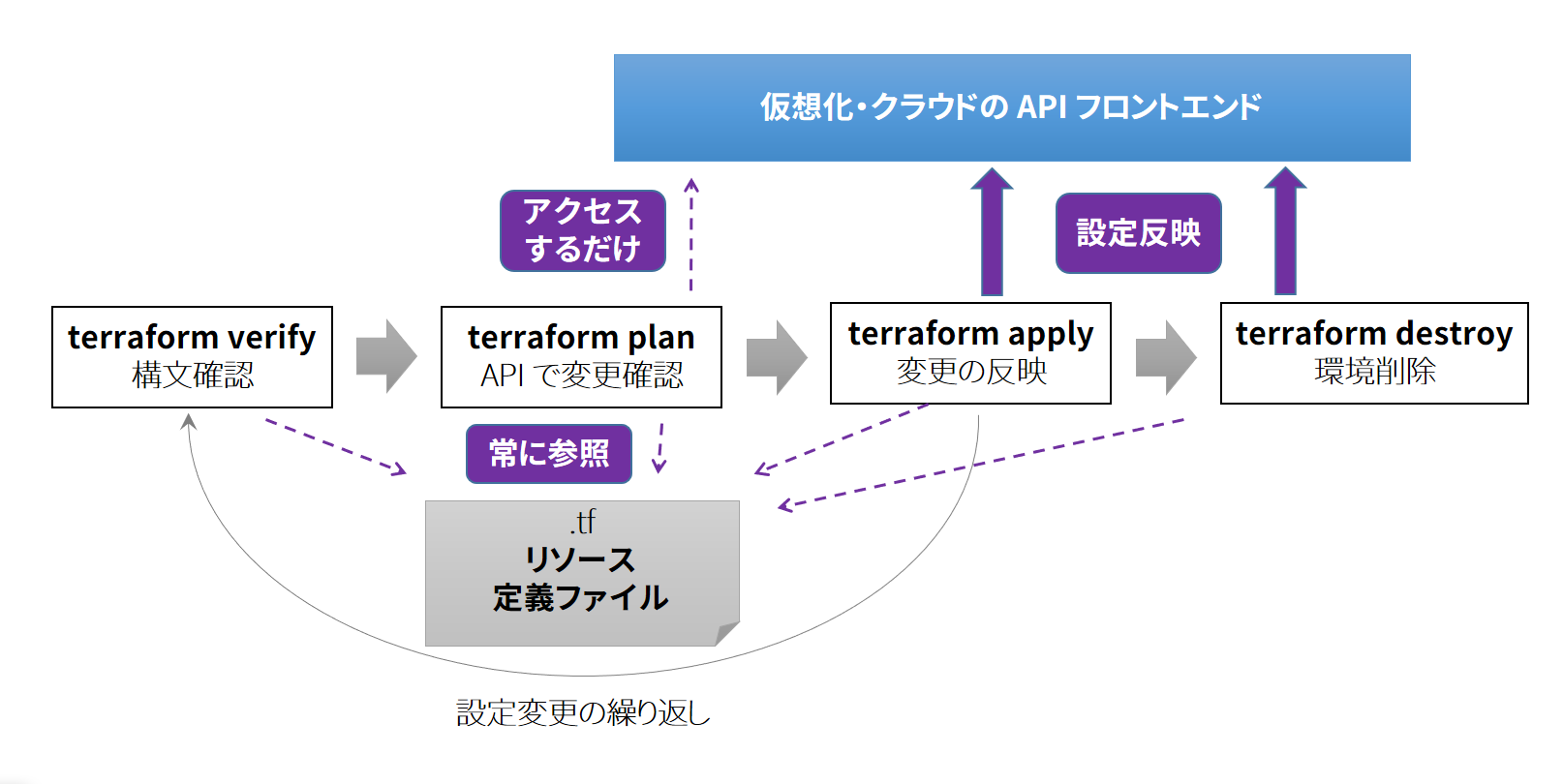
Terraform を使うには、まず、設定ファイルを準備します。テキスト形式の設定ファイル上にリソースを独自 DSL である HCL 形式(HashiCorp Configuration Language=HashiCorp 構成言語)で記述します。ここでは必要となる各リソース(サーバやディスクなど)の望ましい状態を、拡張子 .tf ファイルの中で定義します。
準備が整えば、はじめに実行するコマンドは「terraform validate」です。HCL の記述が正しいかどうか構文チェックを行います。次に「terraform plan」コマンドでも同様に構文チェックは行えますが、原因の切り分けが構文なのかシステム側なのか切り分けるためにも、こちらのvalidate(検証)はオススメのコマンドです。
次に「terraform plan」コマンドを実行します。terraform がプラグインを通してクラウドの API にアクセスします。そして、terraform の設定ファイルとクラウド上のリソース情報を比較し、どのリソースを追加・変更・削除するのかを画面に表示します。これはドライ・ランの一種であり、plan コマンドを実行した時点では、何らシステムに対する影響を与えません。この時点で、問題があれば設定ファイルを見直す必要があります。
設定変更に問題がなければ「terraform apply」を実行します。先ほどの「terraform plan」と同様の表示が画面に表示されますが、システム上のリソースを実際に操作します。あとは、必要に応じて設定ファイルの変更を行うたびに、コマンド繰り返して実行していきます。最後に環境が不要になれば、「terraform destroy」コマンドで一括削除できます。
このように terraform コマンドを使うだけで、GUI を操作することなく、簡単にインフラの作成ができるようになります。Terraform for さくらのクラウドは、Terraform に対応したプラグインの1つです。こちらを導入するだけで、様々なクラウド環境と同じように、さくらのクラウドの IaaS 環境が、コードを通して管理できるようになります。
セットアップ
さくらのクラウドで Terraform を使うためには、以下の手順を進めます。
1. Terraform のバイナリを入手
2. Terraform for さくらのクラウドをセットアップ
3. API の取得
4. 環境変数への反映
1. Terraform のセットアップ
以降では Linux の設定例をご紹介しますが、macOS や Windows 用のバイナリは、ダウンロード用ページをご覧ください。
ホームディレクトリ以下に terraform ディレクトリを作成し、そこにバイナリを置きます。それからパスを通して、設定対象アカウントであれば、どこでも terraform コマンドを実行可能にします。
$ cd
$ mkdir terraform
$ cd terraform
$ curl -o terraform.zip -L https://releases.hashicorp.com/terraform/0.7.13/terraform_0.7.13_linux_amd64.zip
$ unzip terraform.zip
$ export PATH=$PATH:~/terraform/
$ echo `export PATH=$PATH:~/terraform/` >> ~/.bashrc
terraform が利用可能かどうかは、次のようにバージョン情報が表示されるかどうかで確認します。
$ terraform version
Terraform v0.7.13
このようにバージョン情報が表示されていれば、動作は正常です。
2. Terraform for さくらのクラウドをセットアップ
Terraform は様々な仮想化システムやクラウド事業者のサービスに対応しています。また、「プラグイン」形式で拡張可能なため、サードパーティ製のプラグイン開発も活発です。
今回使用する Terraform for さくらのクラウドも、サードパーティ製プラグインの1つであり、@yamamoto-febc さんが作成されたものです。
プラグインは、Terraform にあわせて、ファイルを追加ダウンロードするだけで、すぐに利用可能となります。
$ cd ~/terraform
$ curl -o terraform-provider-sakuracloud_linux-amd64.zip \
-L https://github.com/yamamoto-febc/terraform-provider-sakuracloud/releases/download/v0.5.1/terraform-provider-sakuracloud_linux-amd64.zip
$ unzip terraform-provider-sakuracloud_linux-amd64.zip
3. API キーの発行と確認
Terraform がさくらのクラウドを制御するには、API キーが必要です。API キーは ACCESS TOKEN(アクセス・トークン)と ACCESS TOKEN SECRET (アクセス・トークン・シークレット)の組み合わせです。
初期状態では API キーは発行されていません。まだ API を作っていない場合は、次の手順のように新規作成します。
1. 「設定」 をクリックします。
2. 「API キー」をクリックします。
3. 「追加」をクリックします。
4. API キーの「名前」に任意の名前を入力し、「追加」をクリックします(アクセスレベルは「作成・削除」が有効のまま、他サービスへのアクセス権はないままです)。
5. 画面にトークンが表示されますので、ACCESS TOKEN と ACCESS TOKEN SECRET の内容を確認します。画面を閉じた後も、API キーの一覧画面から確認できます。
4. 環境変数の設定
トークンを確認した後は、シェル上で環境変数を使えるようにしします。以下は設定例です(「」は入力しません)。
export SAKURACLOUD_ACCESS_TOKEN=「ACCESS TOKEN の文字列」
export SAKURACLOUD_ACCESS_TOKEN_SECRET=「ACCESS TOKEN SECRET の文字列」
export SAKURACLOUD_ZONE=tk1v
最後の SAKURACLOUD_ZONE は操作対象リージョンです。 tk1v はサンドボックスを指定しています。サンドボックスとは無償でリソース作成を試すことができる環境です。
サンドボックスは、あくまでリソースを「お試し」として追加するだけであり、実際にログイン可能なサーバなどのリソースは作成されません。ですが、動作の確認であったり、Terraform での構成確認には役立つリージョンです。
動作確認が問題無ければ、あとで環境変数を各リージョンに切り替え、実際にサーバやスイッチなどのリソースを追加することもできます。
-
tk1a… 東京第1ゾーン -
is1a… 石狩第1ゾーン -
is1b… 石狩第2ゾーン
Terraoform 入門チュートリアル
最小限の構成(サーバ1台)の作成をはじめ、サーバ2台とローカル側スイッチを接続した構成を試していきましょう。
まずは1台の仮想サーバを立ててみる
準備するリソースとデータ・ソースについて
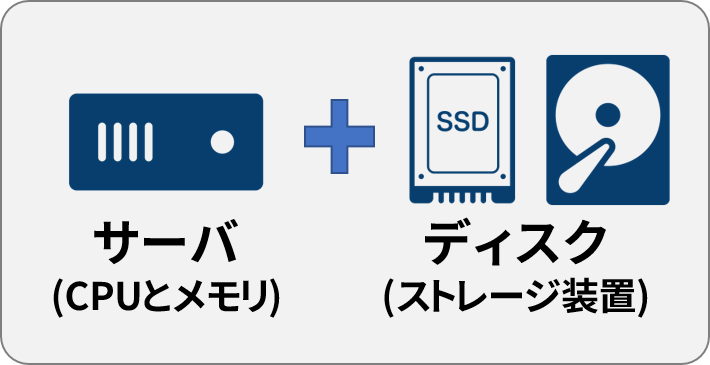
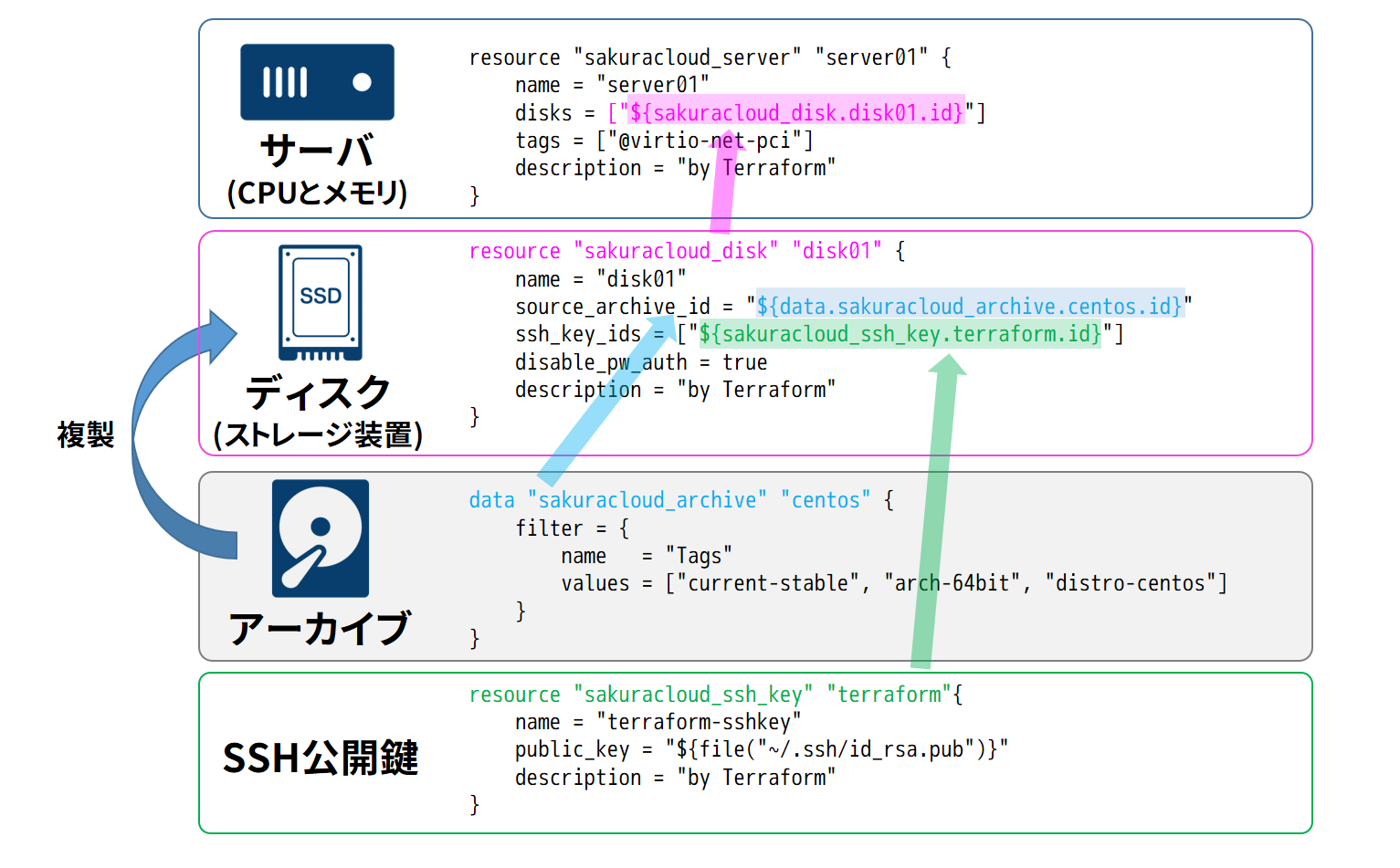
Terraform を使って仮想サーバを動かすためには、「サーバ」と「ディスク」のリソースが必要です。さくらのクラウドは、実際のサーバのように、ディスクの取り付け、取り外しといった概念があるからです。
他にも、「ディスク」の元になる「アーカイブ」は CentOS 7.2 (current-stable のタグが付いているアーカイブ ・イメージを使用します。
さらに、ここではサーバにログインするための SSH 公開鍵の指定を行います。 ~/.ssh/id_rsa.pub をサーバのディスクに書き込みます。鍵ペアがなければ ssh-keygen -t rsa で作成しておきます。あるいは、その他のパスに書き換えることもできます。
以上のリソースを整理しますと、仮想サーバを準備するには4つのリソースが必要です。
- サーバ
- (ストレージとして、何も入っていない状態の)ディスク
- (ディスクのコピー元になる)アーカイブ
- (作成したディスクに追加する)SSH 鍵
Terraform では、それぞれ作成するリソースのことをリソース・タイプ(resource type)と呼びます。ただし、ディスクの元となるアーカイブのように、既存リソースが対象の場合は、そのリソースをデータ・ソース(deta source)と呼びます。さくらのクラウドで、Terraform で指定できるリソース・タイプとデータ・ソースとの対応は、それぞれ以下の通りになります。
- サーバ → リソース:
sakuracloud_server - ディスク → リソース:
sakuracloud_disk - SSH 鍵 → リソース:
sakuracloud_ssh_key - アーカイブ → データソース:
sakuracloud_archive
必要なリソースがわかりましたので、次は設定ファイルを記述します。
server.tf ファイルの作成
まずは設定ファイルを作成します。 sample1 というディレクトリを作成し、その中に移動後、 server.tf ファイルを作成します。
$ mkdir sample1
$ cd sample
server.tf ファイルの中身は、以下の通りにします。
resource "sakuracloud_server" "server01" {
name = "server01"
disks = ["${sakuracloud_disk.disk01.id}"]
tags = ["@virtio-net-pci"]
description = "by Terraform"
}
resource "sakuracloud_disk" "disk01" {
name = "disk01"
source_archive_id = "${data.sakuracloud_archive.centos.id}"
ssh_key_ids = ["${sakuracloud_ssh_key.terraform.id}"]
disable_pw_auth = true
description = "by Terraform"
}
data "sakuracloud_archive" "centos" {
filter = {
name = "Tags"
values = ["current-stable", "arch-64bit", "distro-centos"]
}
}
resource "sakuracloud_ssh_key" "terraform"{
name = "terraform-sshkey"
public_key = "${file("~/.ssh/id_rsa.pub")}"
description = "by Terraform"
}
これらのリソースのなかで ${リソース名.名前.id} とあるものは、別のリソースやデータソースを参照しています。
そして、ファイル作成後は terraform validate コマンドを実行します。
$ terraform validate
実行しても何も表示さなければ、文法上の間違いはありません。
リソースの作成
次にリソースをクラウド上で作成します。作成前には terraform plan コマンドを実行し、どのような変更を加えるか確認します。
$ terraform plan
(省略)
+ sakuracloud_disk.disk01
connection: "virtio"
description: "by Terraform"
disable_pw_auth: "true"
name: "disk01"
plan: "ssd"
server_id: "<computed>"
size: "20"
source_archive_id: "112700934837"
ssh_key_ids.#: "<computed>"
zone: "<computed>"
+ sakuracloud_server.server01
base_interface: "shared"
base_nw_address: "<computed>"
base_nw_dns_servers.#: "<computed>"
base_nw_gateway: "<computed>"
base_nw_ipaddress: "<computed>"
base_nw_mask_len: "<computed>"
core: "1"
description: "by Terraform"
disks.#: "<computed>"
macaddresses.#: "<computed>"
memory: "1"
name: "server01"
tags.#: "1"
tags.0: "@virtio-net-pci"
zone: "<computed>"
+ sakuracloud_ssh_key.terraform
(省略)
Plan: 3 to add, 0 to change, 0 to destroy.
実行すると、このように「サーバ」「ディスク」「SSH鍵」の3つのリソースを追加(3 to add)するのが分かります。内容に問題がないか確認しておきます。
正常であれば terraform apply コマンドを実行し、設定を反映します。Terraform は .tf を参照し、特に指定が無ければ Terraform 自身でリソースの優先度を判別し、設定ファイルで指定されたとおり、自動的にリソースの作成を試みます。
$ terraform apply
data.sakuracloud_archive.centos: Refreshing state...
sakuracloud_ssh_key.terraform: Creating...
description: "" => "by Terraform"
(省略)
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
The state of your infrastructure has been saved to the path
below. This state is required to modify and destroy your
infrastructure, so keep it safe. To inspect the complete state
use the `terraform show` command.
State path: terraform.tfstate
このようにエラーが出なければ、リソースは作成完了です。そして、 terraform show コマンドを実行すると、作成したリソースに関する情報(IP アドレスなど)をブラウザで表示しなくても確認可能です。ブラウザで画面を開けば、サーバやディスクなどのリソースが自動作成されているのが分かるでしょう。ブラウザで確認するときは「sandbox」リージョンをご指定ください。

今回は「sandbox」でしたが、環境変数 SAKURACLOUD_ZONE と tk1a (東京第1ゾーン)や is1b (石狩第2ゾーン)に指定すると、実際にログイン可能なサーバを作れます。
あとは、サーバの作成・追加をお試しください。記述を変更するたびに terraform plan と terraform apply を繰り返します。
環境の削除
最後に使い終わった環境は terraform destroy コマンドで一括削除できます。確認プロンプトでは yes を入力すると、作成した環境を自動で削除します。
$ terraform destroy
Do you really want to destroy?
Terraform will delete all your managed infrastructure.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes ←ここで「yes」と入力
(省略)
Destroy complete! Resources: 3 destroyed.
これだけでリソースの削除が終わりました。ブラウザで画面を確認しても、キレイさっぱり消えている状態です。
より複雑な構成
リソースの変更
先ほどの例では、CPU やメモリのパラメータを指定しなかったので、デフォルトの1コア、1GB メモリのサーバが起動しました。もし、2 コア 2 GB のメモリのサーバを必要であれば、次のように core と memory のパラメータを指定します。
resource "sakuracloud_server" "server01" {
name = "server01"
description = "by Terraform"
core = "2"
memory = "2"
disks = ["${sakuracloud_disk.server01.id}"]
tags = ["@virtio-net-pci","Terraform"]
}
スタートアップスクリプトとの組み合わせ
サーバの起動時、様々な処理を自動的に行うには「スタートアップスクリプト」の機能が使えます。このスタートアップスクリプトも Terraform で自動追加できます。
注意点としては「スタートアップスクリプト」用のリソース適用対象が「ディスク」だという点です。「アーカイブ」から「ディスク」を作成するとき、「スタートアップスクリプト」が実行される仕組みです。
Terraform では、ディスクとスタートアップスクリプト(note_ids)のリソースを指定できます。以下は docker_setup という名前のスタートアップスクリプト・リソースタイプ sakuracloud_note を、CentOS 7 用のディスクに適用しています。こちらを指定するだけで、サーバ起動後に Docker が自動的にセットアップされ、かつ、起動した状態で利用可能です。
resource "sakuracloud_disk" "server01"{
name = "server01"
hostname = "server01"
description = "by Terraform"
source_archive_id = "${data.sakuracloud_archive.centos.id}"
note_ids = ["${sakuracloud_note.docker_setup.id}"]
ssh_key_ids = ["${sakuracloud_ssh_key.key.id}"]
disable_pw_auth = true
tags = ["Terraform"]
}
resource "sakuracloud_note" "docker_setup" {
name = "docker_setup"
#content = "${file("docker_setup.sh")}"
content = <<EOF
curl -sSL https://get.docker.com/ | sh
systemctl enable docker
systemctl start docker
EOF
}
スイッチもコマンド1つで
複数台のサーバ構成や、スイッチを含む構成ですら、Terraform があれば簡単です。
resource "sakuracloud_switch" "local-sw01" {
name = "local-sw01"
description = "by Terraform"
tags = ["Terraform"]
}
resource "sakuracloud_server" "web01" {
name = "web01"
description = "by Terraform"
core = "1"
memory = "1"
disks = ["${sakuracloud_disk.web01.id}"]
tags = ["@virtio-net-pci","Terraform"]
base_interface = "shared"
additional_interfaces = ["${sakuracloud_switch.local-sw01.id}"]
}
resource "sakuracloud_disk" "web01"{
name = "web01"
hostname = "web01"
description = "by Terraform"
source_archive_id = "${data.sakuracloud_archive.centos.id}"
ssh_key_ids = ["${sakuracloud_ssh_key.terraform.id}"]
disable_pw_auth = true
tags = ["Terraform"]
}
resource "sakuracloud_server" "db01" {
name = "db01"
description = "by Terraform"
core = "1"
memory = "1"
disks = ["${sakuracloud_disk.db01.id}"]
tags = ["@virtio-net-pci","Terraform"]
base_interface = "shared"
additional_interfaces = ["${sakuracloud_switch.local-sw01.id}"]
}
resource "sakuracloud_disk" "db01"{
name = "db01"
hostname = "db01"
description = "by Terraform"
source_archive_id = "${data.sakuracloud_archive.centos.id}"
ssh_key_ids = ["${sakuracloud_ssh_key.terraform.id}"]
disable_pw_auth = true
tags = ["Terraform"]
}
data "sakuracloud_archive" "centos" {
filter = {
name = "Tags"
values = ["current-stable", "arch-64bit", "distro-centos"]
}
}
resource "sakuracloud_ssh_key" "terraform"{
name = "terraform-sshkey"
public_key = "${file("~/.ssh/id_rsa.pub")}"
description = "by Terraform"
}
terraform plan と terraform apply を実行後、さくらのクラウドのコントロールパネル上から「マップ」を選ぶと、次のようなネットワーク構成も確認できます。
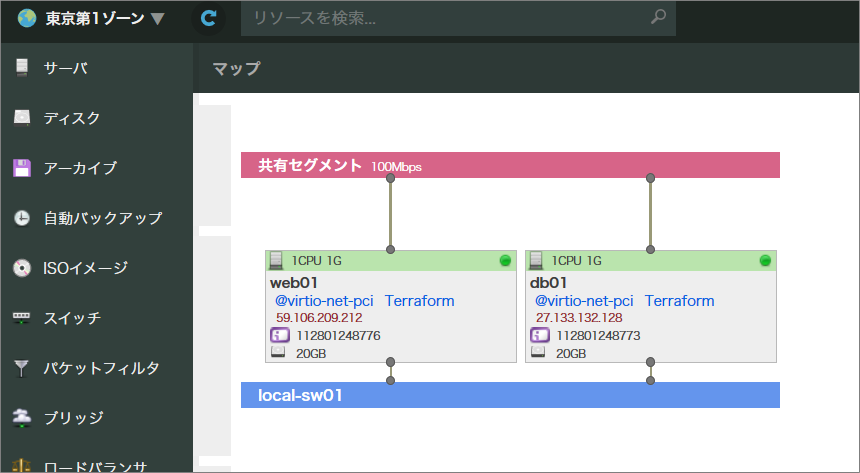
この例では、各サーバはローカルスイッチにつながっているだけで、ネットワーク設定を手動で行う必要があります。しかし、スタートアップスクリプトとの組み合わせにより、このあたりの設定も自動でできるかもしれませんので、ご興味がありましたらお試しいただければと思います。
更なる理解のために
本記事で紹介した使い方は Terraform のほんの一側面でしかありません。
他にも様々なリソースを利用可能です。たとえば、サーバの起動時にシンプル監視を自動的に有効にすることもできます。複数台のサーバをまとめて管理できるかもしれませんし、DNS と組みあわせれば、サーバを追加したら自動的にホスト名用の A レコード追加も、手軽に行えるようになるでしょう。
このあたりは是非みなさんもお試しいただき、ブログなどに記事を掲載して情報を共有いただければ幸いです。本記事をお読みいただき、Terraform をご活用いただくことで、皆さまの生産性向上に寄与できたらと思います。
リファレンス
- yamamoto-febc/terraform-provider-sakuracloud: Terraform for さくらのクラウド
- https://github.com/yamamoto-febc/terraform-provider-sakuracloud
- Terraform by HashiCorp
- https://www.terraform.io/