SQLを使えば、100万行のデータも処理可能です。
やりたいのに、できないを解消する
ある商品の月ごとの売上をエクセルで集計してレポートすることはよくあります。
でも、エクセルは、100万行までしか扱えません。CSVファイル(※)というエクセルに読み込める形式でデータが渡されても、100万行を超えていたら、読み込むこともできません。やりたいことは、はっきりわかっているのに、できない状態です。この文章は、そういったできないを解消するための独習用教材です。
想定する読者
- エクセルをつかっているWindows ユーザ。
- エクセルで集計できない大きさのデータを集計する必要性をつよく感じている。
- メモリ8G積んでいるPCを使える。
- 集計の対象となる大きなCSVファイルでデータをもらうことができる。
- データの整理や、検算などの前処理(※)に手間や費用はかけたくない。
- フリーソフトのダウンロード、インストールはできる
- 英語のメニューしかないソフトでも基本的な機能はなんとか使える
※CSVファイルとは、
カンマ区切りで、データを並べたテキストファイル形式(メモ帳で開くことのできるファイル形式)です。データとしてエクセルに取り込むことができます。データベースからデータを出力するときには、CSVにすることができます
※前処理
データは、きちんとそろっていることはまれです。項目名が想定されていたものと違ったり、抜けているデータ(欠損値)があったり、数値がはいるところに文字列がはいっていたり、さらに、意味的に明らかにおかしいデータがまざっていることがあります。そこで、データの問題点を取り除く作業が必要になります。それが前処理です。実際にデータ分析をした人はわかりますが、この前処理はかなり手間がかかる作業です。
前々処理(ぜんぜんしょり)
実際の前処理は、欠損しているデータを補完まで含む、とても難易度の高い処理です。この教材では、もっと基本的な前処理の前処理をあつかいます。名づけて「前々処理(ぜんぜんしょり)」です。前々処理は、前処理がほとんどいらない100万行以上のCSVファイルを処理して、エクセル(でなくてもいいですが、)でグラフ化できるまでもっていくことができることです。目の前にちゃんとしたデータがある。でもエクセルでは扱えないという不全感を解消する処理です。具体的には、エクセル(表計算)のスキル+100万行以上のCSVファイルの検索、抽出、単純集計です。100万行以上のデータは、**いわゆるBIツール(Tableau、PowerBIなど)**で扱うことはもちろん可能です。ただそれらのBIツールは機能が豊富すぎるので、学習に時間がかなりかかります。明日の会議で必要な資料を今日つくるという状況に間に合いません。そこで、この教材(前々処理)では、すぐに簡単に使えるSQLというデータベース問い合わせ言語を教材として選びました。
SQLのすすめ
SQLとは
SQLは、表形式のデータを扱う問い合わせ言語(仕組み)です。エスキューエルとか、シーケルと呼びます。名前は聞いたことはありますね。テーブルという名称のデータ(表形式)の検索、選択、集計を行います。実際にはどんなものなのでしょう。
例えば、1988年から2016年の貿易統計から輸出入をSQLで集計してみましょう。次のようにSQL文を書いて、SQLを実行できるソフトから実行します。
select exp_imp,sum(Value) as Value ← データ項目を選ぶ
from year_1988_2016 ←対象となるテーブル(データ)
group by exp_imp,Year ←グループにまとめます。
exp_imp は輸出入(1が輸出、2が輸入)です。Valueは金額で、sum(Value)は、金額の集計です。as Value とあるのは、集計も、金額と同じ変数名に変更する指示です。指定しないと、sum(Value) という変数名になるので表記上わかりやすくするためです。year_1988_2016 は、1988年から2016年のデータのテーブルです。輸出入、年でグループわけするのが、group by exp_imp,Year の部分です。日本語では、**「1988年から2016年の貿易統計のデータを、年、輸出入でグループわけして、グループごとに、金額で集計する」**という意味になります。
これがわかれば、あとはぐっと楽です。結果をグラフにすると、こうなります。(グラフは、jupyter でつくっています。SQLの次は、jupyter を学びましょう)
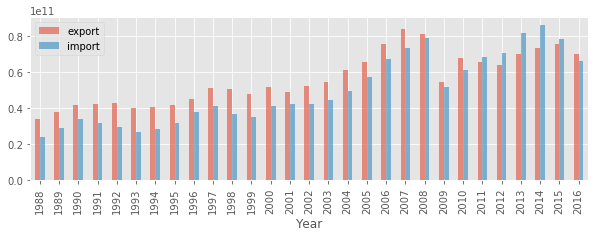
リーマン・ショックで落ち込んで、回復してきたけど、少し失速しているようですね。また、意外と、2011年の震災の影響はないみたいですね。
sqliteなら、手軽にSQLを使えます
SQLは、データベースシステムの中で使われることが多いので、使いはじめるようになるのがすごく大変だと思っている人が多いでしょう。ソフトも高価なものが多くオラクルなどはとても個人が使える金額ではありません。また、オープンソースで無料のMySQLも広くつかわれていますが、サーバシステムなために、**サーバとクライアントのアプリケーションが2つ必要です。設定と環境構築が、MySQLでも結構手間です。**CSVファイルを読み込んで手軽に集計したいという前々処理の要求には、合致しません。でも、大丈夫です。SQLでも、手軽に扱えるsqlite というのもがあります。sqlite は、実は、世の中で広くつかわれています。sqliteは、実はスマホやブラウザーで広くつかわれています。サーバ不要が一番の特徴です。データの読み書きは、SQLを使います。CSVファイルのように簡単で、機能は豊富です。それで、知られないところですが、広く使われています。
sqliteはデータ形式(CSVみたいなもの)
sqliteを使うには、sqlite形式のデータと、それを読み書きするアプリケーションが必要です。sqlite形式を扱うアプリケーションは、たくさんあります。CSVを読み込むアプリケーションがたくさんあるのと同じです。CSVと同じに、データを渡すときに、sqlite形式で渡すこともできます。**SQLすなわちデータベースアプリケーションと思っている人にはここが少しとっつきにくいかもしれません。**でも、sqlite形式は、便利なCSVファイルのようなものだと理解しましょう。sqlite形式は、今後の普及が確実です。kaggleという有名なデータサイエンティストのコミュニティサイトでしっかりつかわれています。配布用のデータ形式としてCSVファイルと並んで,sqlite形式が推奨されています。アプリケーションは、流行り廃りが激しいですが、基本的なデータ形式は、いちど普及するとそれほど変化はありません。sqlite形式のデータの扱いは、覚えても、無駄ではないでしょう。
いきなり課題(貿易統計)から
課題優先
通常のSQLの学習教材では、SQLとは何かというのを説明します。でも、ここでは、いきなり課題からはいります。SQLは、課題をこなすのに必要な部分だけを学びます。課題で使うデータは、政府統計のひとつである貿易統計です。課題から入り、ある程度わかってから、SQLとはこんなものだったんだなと実感してもらうのがこの教材の方針です。
課題(大きなCSVを取り込む)
課題のデータは、適度に大きく、新鮮でかつ面白いものとして、貿易統計を選びました。貿易統計は、財務省が作成している政府統計で、一番アクセスが多い政府統計です。内容的にも面白いです。データ量ももちろん、100万行を簡単に超えて、かつ毎月更新されます。貿易統計に関するレポートは、税関ごとに特集(例、東京税関)としてまとまっています。こういったレポートのためのデータをつくるのが、この教材の目的です。
実際の作業
メモリ8GのwindowsPCを使うのが前提ですが、Macでももちろんできます。結果をグラフ化するのは、エクセルが前提ですが、google spredsheet でも、オープンソースのLibreOfficeでも十分です。ソフトをインストールしてまずは、使えるようになりましょう
作業一覧
- ソフトのインストール
- データをインポート
- データのブラウジング
- 総数、新規
- データの保存
- 集計
作業1 ソフトのインストール
前提
- windows10(7でもできますが、画面は、10でいきます。)
- 64ビットOS メモリが、8Gなので
- エクセルが使える(LibreOffice,google spredsheet で代用可)
- 圧縮ファイルの解凍可能(zipファイル)
- 英語のページ、ソフトでも基本的な用語(File open など)は理解できる
DLLダウンロード
sqliteのダウンロードページから、DLLをダウンロードして、解凍します。
ダウンロードするDLLは、
Precompiled Binaries for Windows -> 64-bit DLL (x64) for SQLite versionです。
DLLは、ライブラリと呼ばれるアプリケーションのための部品です。sqlite形式のデータを使うときにつかいます。アプリケーションごとに、sqlite形式のデータを扱うプログラムを用意するのは、無駄です。そこで共通部分のプログラム部分をライブラリーとして、アプリケーションの外に出して、共通にしてつかいます。
DLLを置くフォルダ (ユーザ名\Destop\app)
DLLは、あなたのデスクトップに、appというフォルダをつくり、DLLをおきます。どこにおくかは、もちろん任意です。決めておいた方がいいので決めているだけです。自分なりのポリシーがある人は、自由に配置してくださ
sqlitebrowser インストール
sqlite形式のデータを扱うアプリケーションをインストールします。sqlitebrowserといいます。
http://sqlitebrowser.org/ から、windows.exe 64ビットをダウンロードします。インストーラがあるので、画面の指示にしたがってインストールしてください。
DLLにPATHを通す(ちょっと難しい)
単にインストールしただけでは、sqlitebrowserは使えません。先にダウンロードしたDLLを、sqlitebrowserから使えるようにする作業が必要です。これがPATHを通すです。環境変数のPATHに、%USERPROFILE%\Desktop\app を設定する作業です。設定したことがない人には、少しむずかしい作業なので、少し詳しく説明します。Windows 10 での説明です。
まず、左下の検索のところに、環境変数をいれて検索すると、環境変数を編集がでてきます。(Window7でも、でてきます。)
環境変数の編集を開けて、PATHを選んで、開けます。
新規を開けて、%USERPROFILE%\Desktop\appを設定、OKを押して、設定終了です。
PATHを通すのは、普段しない作業なので、難しいですが、頑張ってやりましょう。普段から、PATHを通すという作業を知っている人はあっという間の作業ですね。今後、アプリケーションにPATH を通す必要があるときは、このapp 内直下にいれておけば手間なしです。
sqlitebrowserの起動確認
作業2 データのインポート
データ(1988年から、2016年までの年別の集計)をダウンロードして、sqlitebrowserで、操作できるようにインポート(取り込み)ます。ダウンロード3分くらいかかり、とりこみも3分くらいです。実際の作業は、次のように行います。
作業一覧
- データダウンロード
- 新規データベース作成
- インポート
- データ項目変更
- データを眺める
- 保存する
データダウンロード
年で集計してある貿易統計データ(1988−2016)をダウンロードします。zip 形式に圧縮されているので、ダウンロード後、解凍します。
新規データベース作成して、CSVの取り込み
CSVファイをsqlbrowser にインポート(取り込み)してテーブルを作成します。まず、テーブルを格納する場所(データベース)が必要です。データベースは既存のをつかってもいいですし、新規に作成することもできます。ここでは、新規に作成します。データベースの名前はなんでもよいで、思いつかないなら、test としておきましょう。
新規作成すると、まず、下記の画面がでてきますので、キャンセルします。
データインポート
csv のインポートを選びます。
ファイルを選択
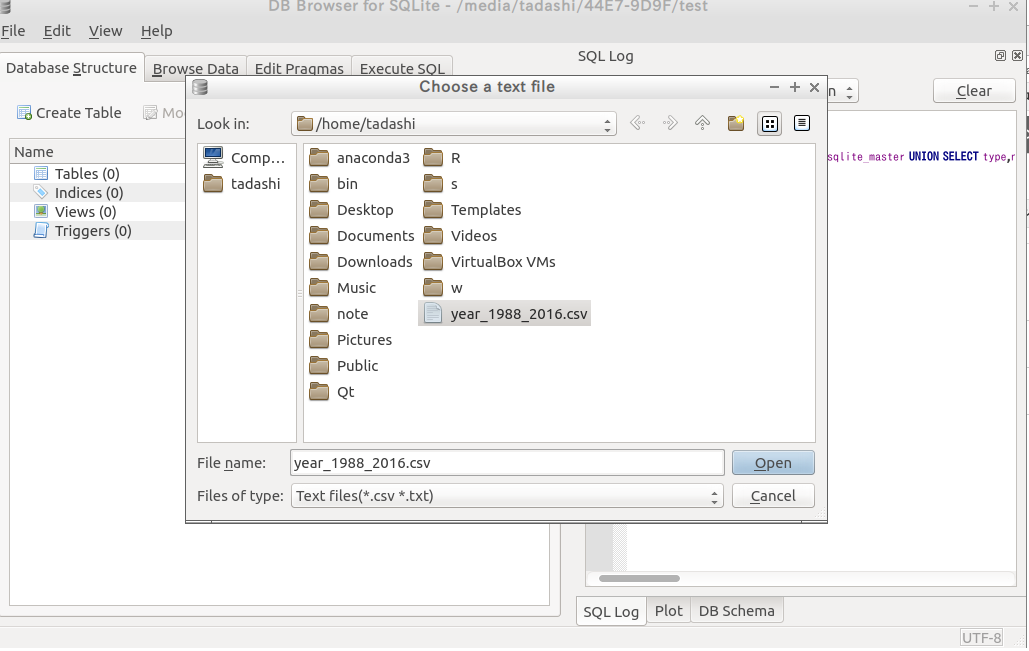
ファイルを指定するとこの画面があきます。Table name を設定、取り込みます
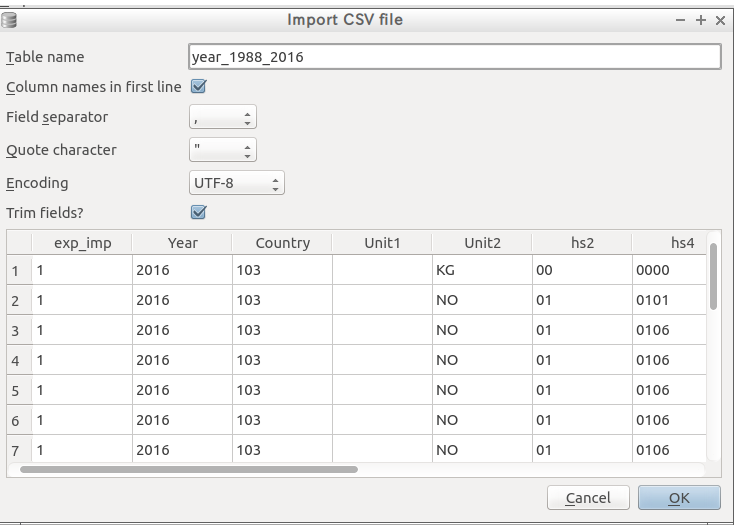
インポート開始
※ column names in first line にチェックがはいっていること。!
作業3 データを眺める(ブラウジング)
データをさっと眺めてみましょう。
データの項目は、sqlitebrowser の 左の Database Structure で見ることができます。
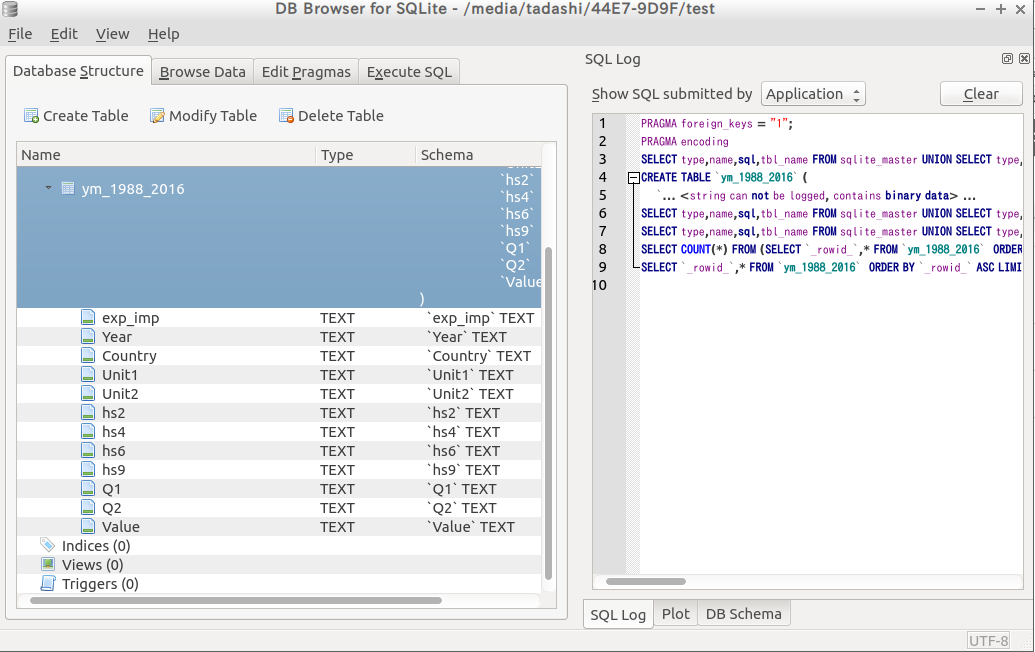
項目の意味は下記です。
"exp_imp" 輸出入のカテゴリ 1:輸出2: 輸入
"Year" 年
"Country" 国(コード)
"Unit1" 単位その1
"Unit2" 単位その2
"hs2" HSコード上2桁
"hs4" HSコード上4桁
"hs6" HSコード上6桁
"hs9" HSコード上9桁
"Q1" Unit1 に対応する数量
"Q2" Unit2 に対応する数量,
"Value" 金額(単位1000円)
作業4 総数を数える
データの総数を数えるのは、データ処理のもっとも基本です。
実行するのは、下記のSQL文です。
select count(*) from year_1988_2016
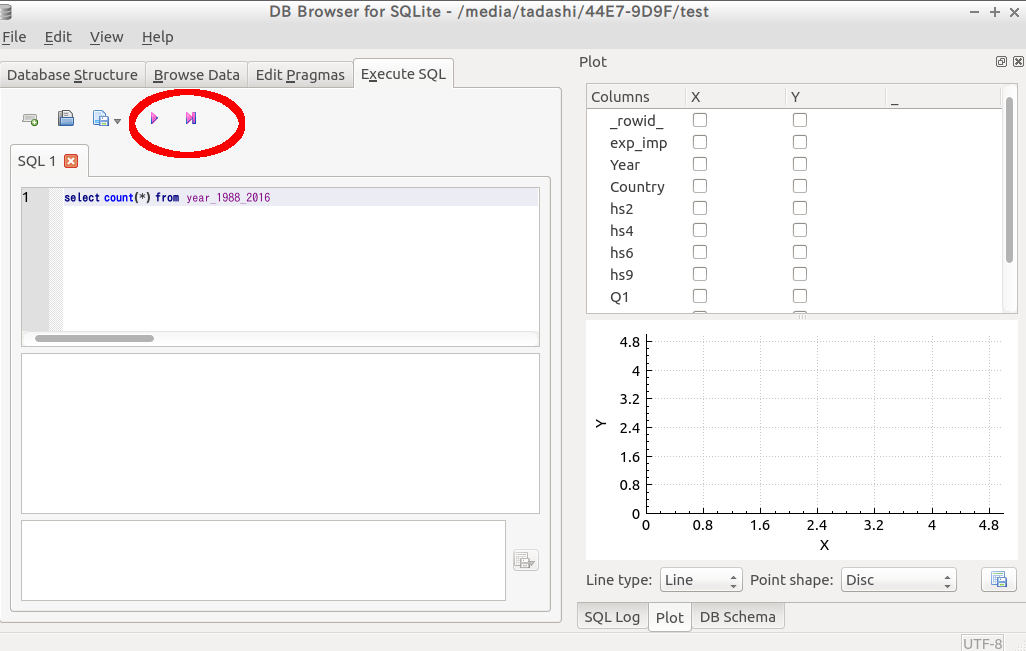
Execute SQL のタブで、SQL文をいれる窓を出して、
実行(→をクリック)します。
結果は、6832185 です。100万行超えていますね。
作業5 作業用新規テーブル作成
1988年から、2016年までのデータは、さすがに大きいので扱いにくいです。2016年だけの作業用テーブルをつくっておきましょう。2016 年の輸出入のデータを抽出して、新しく year_2016 というテーブルをつくります。
create table year_2016 as
select * from year_1988_2016
where Year='2016'
上記のSQL文の意味は、
1行目 year_2016を作成する
2行目 year_1988_2016 から、全部の項目をとってくる(select * )
3行目 2016 のデータに限定
なんとなくわかれば、大丈夫です。
実行すると、year_2016 が作成されます。左のウィンドウの、Database Structure で作成を確認できます。新しいテーブルを作成するのは、このようにとても簡単です。前々処理では、このように新規にテーブルをつくって作業することがしばしばあります。なれておきましょう。
さて、もう一度、上記のSQLを実行すると、すでに、year_2016 は存在するのでつくれませんと、エラーになります。
それでは、year_2016を削除して、もう一度、year_2016をつくってみましょう。Database Structureのタブで、year_2016 を選んで、Delete table すると簡単に削除できます。その後で、SQLを実行してみます。year_2016がまたつくられていますね。新規にテーブルをつくって、不要になったら削除するのは前々処理ではこれからもよく行います。なれておきましょう。SQLデータベースを普段つかっている人は、テーブルをつくってはすぐ削除するのは、心理的に抵抗があるかもしれませんね。
でも、前々処理は、通常のデータベースの使い方とは違います。データ集計して、エクセルで扱いやすくするのが目的です。なれましょう。
なお、year_2016のデータ数は、230583です。エクセルでも扱えないことはない行数になりました。
作業6 保存
取り込んだデータを、sqliteの形式にして一度保存します。
File メニューから、write to change をクリックして、変更を保存します。データベースを閉じて、また、開けてみましょう。先立って作成した、year_2016がでてくるのを確認できます。前々処理では、作業の都合で、テーブルを作成したり、削除したりをよく行います。作業途中のテーブルを保存するのは大切です。なれておきましょう。
作業7 集計
貿易統計のコードをつかって、今、作成したyear_2016で集計をしてみましょう。
貿易統計コードは、テーブルのhs2,hs4,hs6,hs9 の部分です。輸出品目表(HSコード)と呼ばれるもので、一番詳細なのは、9桁のコードです。項目では、hs9です。hs2,hs4,hs6は、上2桁、4桁、6桁です。大分類、中分類、小分類のようになっています。分類の階層構造は、マーケティングのときもよくあります。扱いになれておきましょう。
HS2桁から集計
まず、大分類のhs2で集計してみましょう。
2016 の輸出額を、hs2 ごとに、集計して、大きい順から、
5つだすには、次のSQLを実行します。
select hs2,sum(Value) as Value from year_2016
where exp_imp=’1’
group by hs2
order by Value desc
limit 5
結果は、コードだけでわかりにくいですね。なお、Value(金額) は、1000円単位です。
| hs2 | value | |
|---|---|---|
| 0 | 87 | 15399944042 |
| 1 | 84 | 13462984260 |
| 2 | 85 | 10658444794 |
| 3 | 00 | 4149835965 |
| 4 | 90 | 3893886396 |
hs2 87 は、自動車関連です。輸出品目表(HSコード) では、87類で、「鉄道用及び軌道用以外の車両並びにその部分品及び附属品」とわかりにくい説明がついていますが、自動車関連です。年間おおよそ15兆円です。2016年の輸出金額は、約70兆円なので、自動車関連は、かなりな額であることがわかります。誰もがしっていることですが、自動車産業は、日本の大切な産業です。
SQL文を少し詳しくみてみましょう。個別のSQLをもう少し詳しく説明します。
一行目
select hs2,sum(Value) as Value from year_2016
select は、英語で、選ぶという意味です。テーブル year_2016 から、 hs2 (HS2桁コード)と、Value(金額)の合計sum(Value)を選ぶという意味です。
2行目
where exp_imp='1'
輸出のみを選ぶ指定です。
条件節と言われる部分です。exp_imp = ‘1’ で輸出のみに限定しています。’1’ になっているのは、exp_imp が、数字ではなく文字型として定義されているからです。テーブルの項目が、文字列なのか、整数なのかは、実際にSQLを書くときには、実はかなり問題になります。今回、CSVから取り込むときには、項目のデータタイプ(文字列か、整数か、数値型かなど)は意識していませんが、今後、必要に応じて、項目のデータ型の定義を変える作業をおこなっていきます。今は、いい加減に使います。 現状では、Value(金額)もテキストになっているので、場合によっては、支障がでます。
3行目
group by hs2
HS2桁コードの項目 hs2 でグループにしています。これで、HS2桁コードで集計できるようになります。上記のように、select の中に、sum(Value) と書いておくと、このグループの指定にしたがって、Value がHS2桁コードごとに集計されます。
4行目
order by Value desc
金額(Value)の降順(desc)で並べかえ(order)します。降順なので、金額の大きい方から並びます。
なお、金額(Value)は、文字列として取り込まれているのですが、並べ替えでは、数字のデータとしてsqlite では扱われているようです。
5行目
limit 5
結果を5行に限定しています。
できたでしょうか? 簡単でしたか? なれるために、演習です。やってみましょう。
- hs2 でなく、hs4 で集計
- 輸出でなく輸入を集計