はじめに
業務要件で、あるキーワードのGoogle検索結果(検索順位)を毎日取得してモニタリングする必要が生じたため、Custom Search APIを使ってみました。
Googleの公式サイトはこちら
Google Custom Search JSON API
検索結果を取得するまで
以下の流れで説明します。
- APIキーの取得
- Custom Search APIの有効化
- Custom Search Engine(CSE)の取得
- Google API Client Libraries(Python)のインストール
- APIでGoogle検索結果の取得
※ Googleアカウントは既にある前提
※ 1~4は特に順番はありません(どれを先にやってもよいです)
※ 1,4は既に他で実施済みであれば不要
1. APIキーの取得
※既に取得済みであればこの項は不要です。
Google Developer Console または Google Cloud Platform の
APIとサービス > 認証情報
から認証情報(APIキー)を作成します。
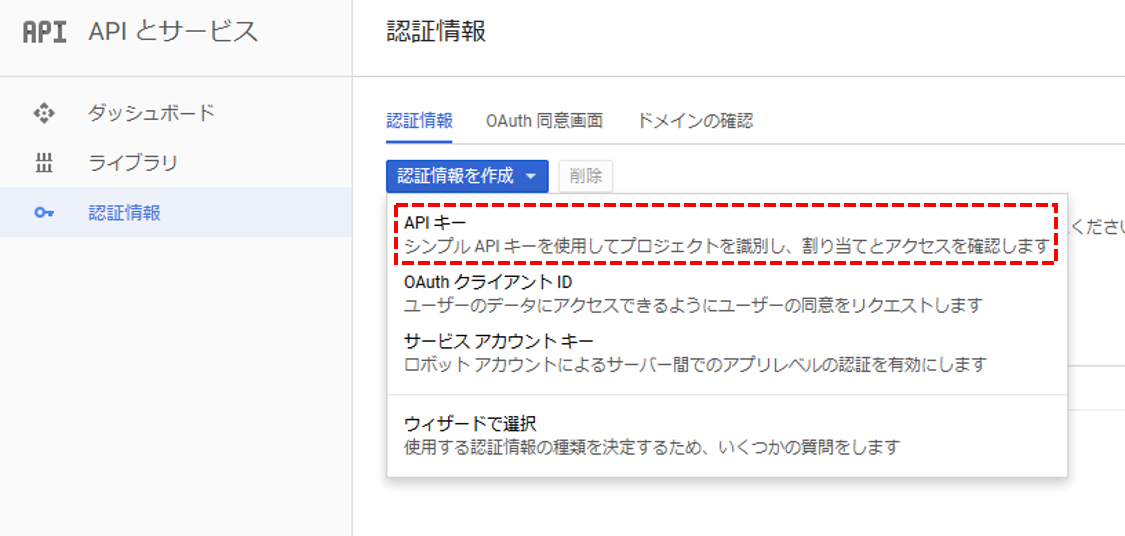
※ 作成したAPIキーをメモしておきます(後で使います)
※ APIキーはデフォルトでは制限がありません。不正使用を防ぐために必要に応じてIPアドレスでの制限や使用できるAPIの種類を制限することなどを検討した方がよいでしょう。
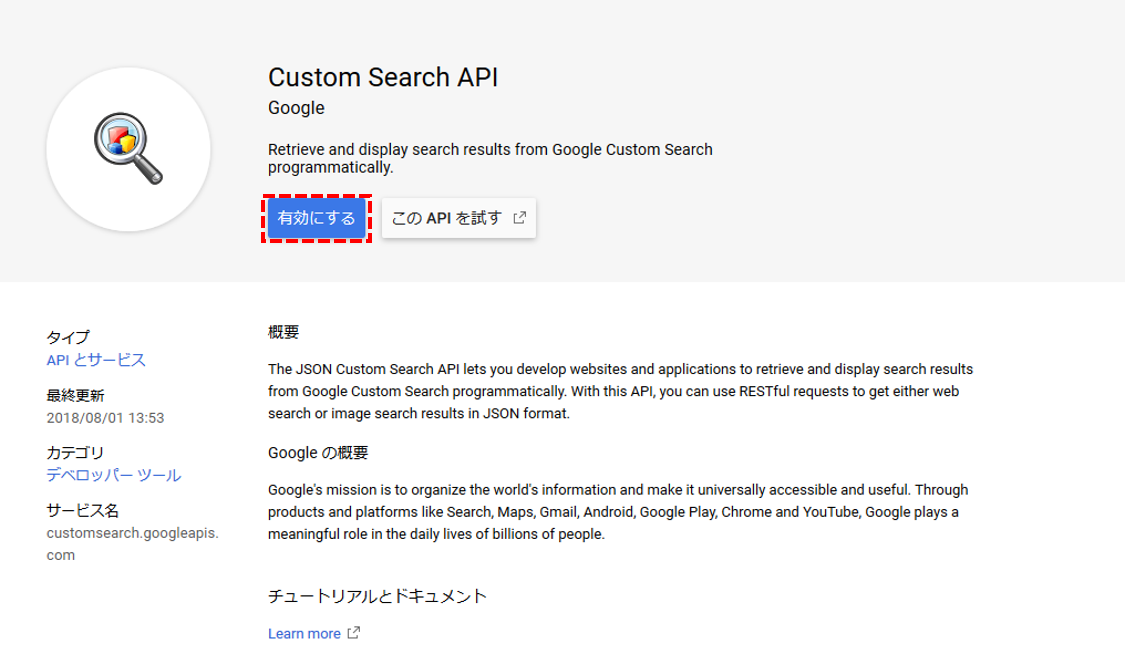
2. Custom Search APIの有効化
Google Developer Console または Google Cloud Platform の
APIとサービス > ライブラリ
からCustom Search APIを有効化します。
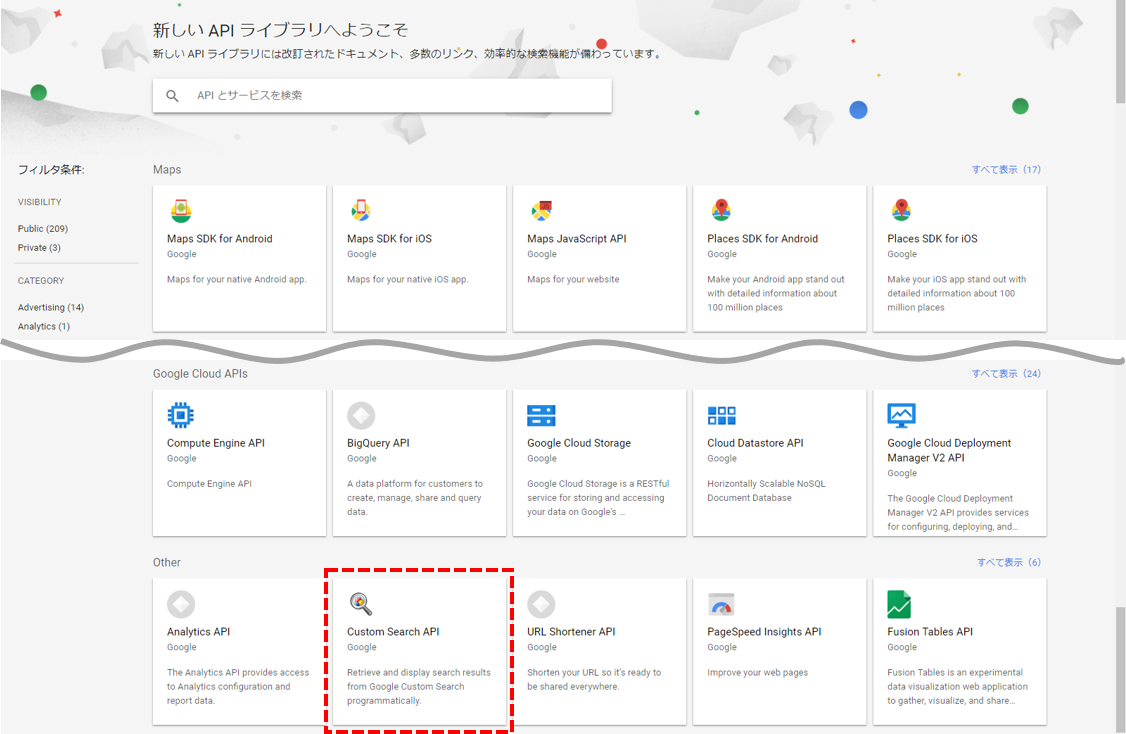
※ Custom Search APIは一番下の Other の中にあります。
※ まだプロジェクトがない場合は、併せてプロジェクトも作成しておきましょう。
3. Custom Search Engine(CSE)の取得
CSEの画面はこちら
Custom Search Engine(CSE)
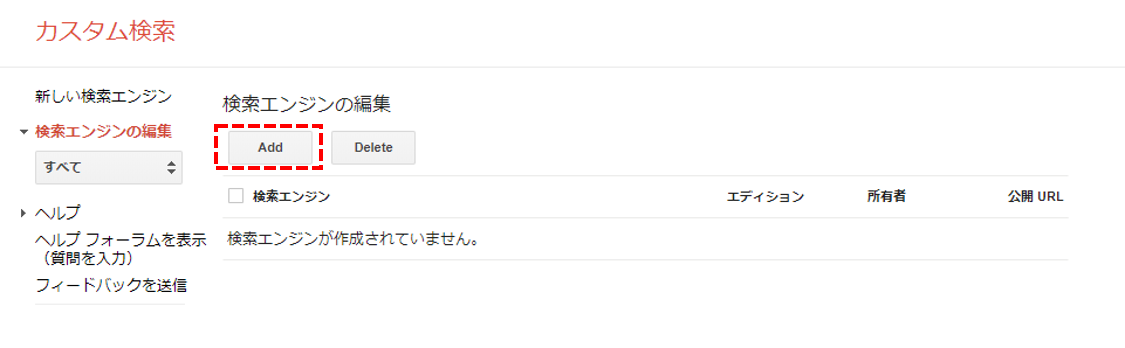
※ 「Add」ボタンから検索エンジンを追加します。
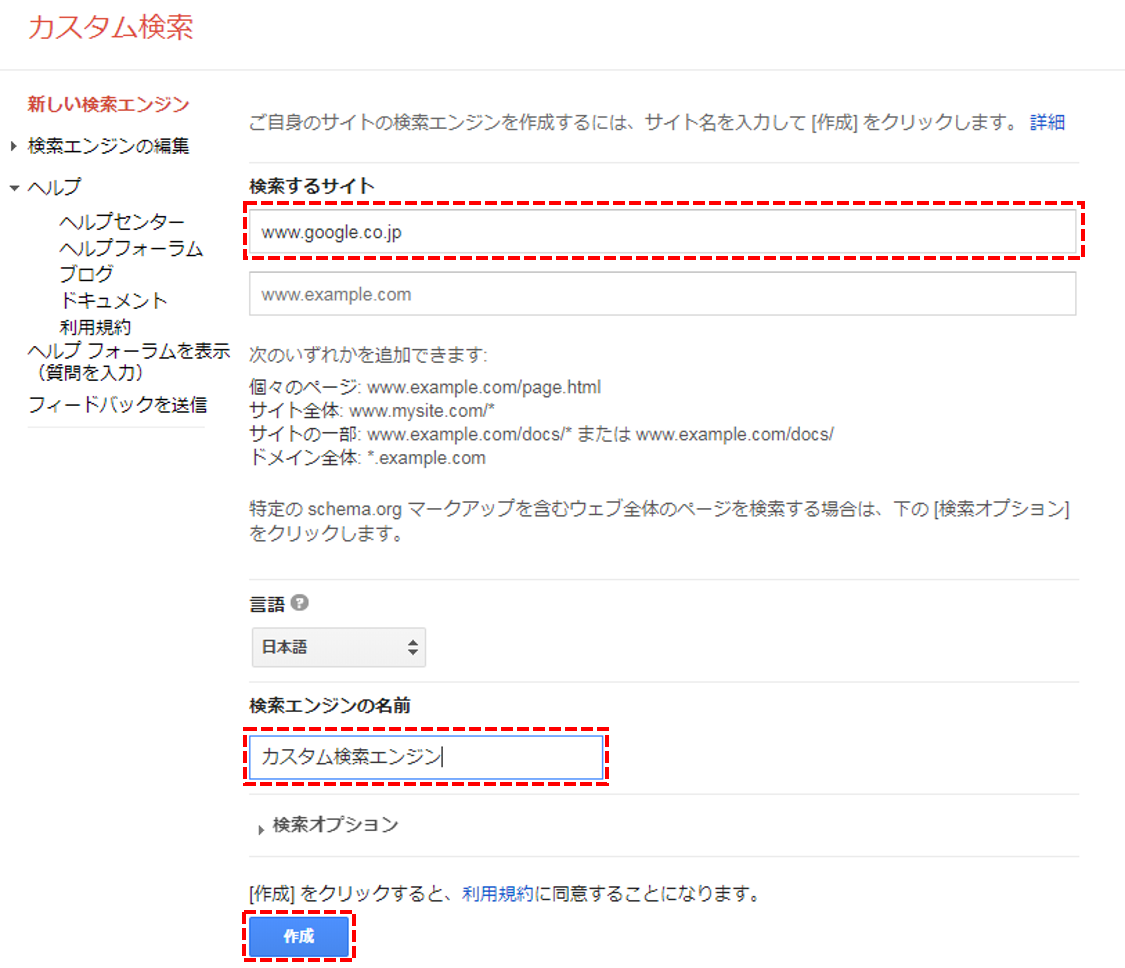
※ 「検索するサイト」に何かサイトを入力して作成します(後で削除するので何でもよいです)
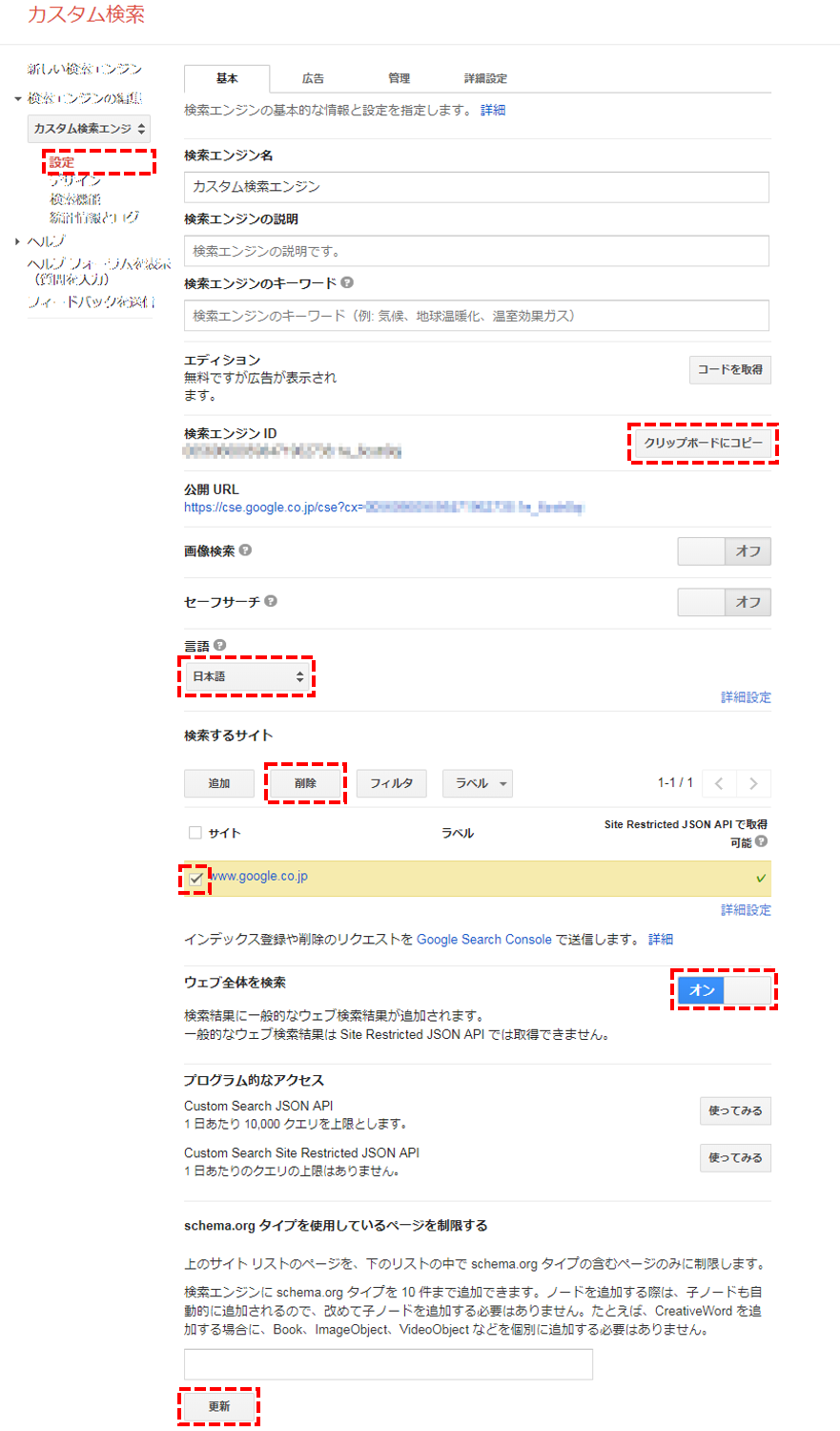
※ 作成した検索エンジンの設定を編集します。
※ ここでのポイントは下記
・この画面で「検索エンジンID」が表示されているのでメモしておきます(後で使います)
・「言語」は日本語を選択します。
・「検索するサイト」に表示されている先ほど入力したサイト(例ではwww.google.co.jp)は削除します。
・「ウェブ全体を検索」をオンにします。
4. Google API Client Libraries(Python)のインストール
※既にインストール済みであればこの項は不要です。
今回はGoogleが提供しているAPIクライアントライブラリ(Python)を使って取得してみます。
こちらを参考にインストールしておきます。
Google API Client Libraries > Python
具体的には下記コマンドで入ります(pip)
$ pip install --upgrade google-api-python-client
5. APIでGoogle検索結果の取得
以下がサンプルコードです(Python3)
GOOGLE_API_KEY に、1.で取得したAPIキーを設定します。
CUSTOM_SEARCH_ENGINE_ID に、3.で取得した検索エンジンIDを設定します。
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import datetime
import json
from time import sleep
from googleapiclient.discovery import build
GOOGLE_API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
CUSTOM_SEARCH_ENGINE_ID = "000000000000000000000:xxxxxxxxxxx"
DATA_DIR = 'data'
def makeDir(path):
if not os.path.isdir(path):
os.mkdir(path)
def getSearchResponse(keyword):
today = datetime.datetime.today().strftime("%Y%m%d")
timestamp = datetime.datetime.today().strftime("%Y/%m/%d %H:%M:%S")
makeDir(DATA_DIR)
service = build("customsearch", "v1", developerKey=GOOGLE_API_KEY)
page_limit = 10
start_index = 1
response = []
for n_page in range(0, page_limit):
try:
sleep(1)
response.append(service.cse().list(
q=keyword,
cx=CUSTOM_SEARCH_ENGINE_ID,
lr='lang_ja',
num=10,
start=start_index
).execute())
start_index = response[n_page].get("queries").get("nextPage")[0].get("startIndex")
except Exception as e:
print(e)
break
# レスポンスをjson形式で保存
save_response_dir = os.path.join(DATA_DIR, 'response')
makeDir(save_response_dir)
out = {'snapshot_ymd': today, 'snapshot_timestamp': timestamp, 'response': []}
out['response'] = response
jsonstr = json.dumps(out, ensure_ascii=False)
with open(os.path.join(save_response_dir, 'response_' + today + '.json'), mode='w') as response_file:
response_file.write(jsonstr)
if __name__ == '__main__':
target_keyword = 'ダイエット'
getSearchResponse(target_keyword)
※ ここでは「ダイエット」というキーワードでGoogle検索結果を取得しています。
※ 毎日取得することを想定しているため、APIのレスポンスは data/response/response_yyyymmdd.json にファイルとして保存しています。
細かいAPIパラメータの仕様はこちらを参照
Google Custom Search JSON API(リファレンス)
後述しますが、APIアクセスの回数制限が(特に無料枠では)非常に厳しいため、いったん生のAPIレスポンスを保存しておき、後で加工処理することにします。
どの言語でも処理できるよう、json形式で保存しておきます。
下記のようなデータが保存されます。
{
"snapshot_ymd": "20181002",
"snapshot_timestamp": "2018/10/02 12:57:30",
"response": [
{
"url": {
"type": "application/json",
"template": "https://www.googleapis.com/customsearch/v1?q={searchTerms}&num={count?}&start={startIndex?}&lr={language?}&safe={safe?}&cx={cx?}&sort={sort?}&filter={filter?}&gl={gl?}&cr={cr?}&googlehost={googleHost?}&c2coff={disableCnTwTranslation?}&hq={hq?}&hl={hl?}&siteSearch={siteSearch?}&siteSearchFilter={siteSearchFilter?}&exactTerms={exactTerms?}&excludeTerms={excludeTerms?}&linkSite={linkSite?}&orTerms={orTerms?}&relatedSite={relatedSite?}&dateRestrict={dateRestrict?}&lowRange={lowRange?}&highRange={highRange?}&searchType={searchType}&fileType={fileType?}&rights={rights?}&imgSize={imgSize?}&imgType={imgType?}&imgColorType={imgColorType?}&imgDominantColor={imgDominantColor?}&alt=json"
},
"searchInformation": {
"searchTime": 0.519702,
"formattedTotalResults": "33,900,000",
"totalResults": "33900000",
"formattedSearchTime": "0.52"
},
"items": [
{
"pagemap": {
"metatags": [
{
"referrer": "origin"
}
]
},
"formattedUrl": "https://ja.wikipedia.org/wiki/ダイエット",
"cacheId": "R2Q86BMq68cJ",
"title": "ダイエット - Wikipedia",
"htmlSnippet": "<b>ダイエット</b>(diet)とは、規定食という意味である。 人や動物や共同体が習慣的に摂る食品<br>\nのこと。 食事療法: 健康のため、美容のため、肥満の防止(や解消)のため、食事を制限<br>\nすること。 <b>ダイエット</b>は体重を目安にするが、 健康体重、標準体重、理想体重、目標 ...",
"link": "https://ja.wikipedia.org/wiki/%E3%83%80%E3%82%A4%E3%82%A8%E3%83%83%E3%83%88",
"displayLink": "ja.wikipedia.org",
"htmlTitle": "<b>ダイエット</b> - Wikipedia",
"kind": "customsearch#result",
"snippet": "ダイエット(diet)とは、規定食という意味である。 人や動物や共同体が習慣的に摂る食品\nのこと。 食事療法: 健康のため、美容のため、肥満の防止(や解消)のため、食事を制限\nすること。 ダイエットは体重を目安にするが、 健康体重、標準体重、理想体重、目標 ...",
"htmlFormattedUrl": "https://ja.wikipedia.org/wiki/<b>ダイエット</b>"
},
6. (おまけ)検索レスポンスの加工整形処理
例えば下記のような処理で、検索レスポンスから加工整形処理を行います。
(例では、displayLink、title、link、snippetを抜き出してdata/results/results_yyyymmdd.tsvとしてファイル保存しています)
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import datetime
import json
import pandas as pd
DATA_DIR = 'data'
def makeDir(path):
if not os.path.isdir(path):
os.mkdir(path)
def makeSearchResults():
today = datetime.datetime.today().strftime("%Y%m%d")
response_filename = os.path.join(DATA_DIR, 'response', 'response_' + today + '.json')
response_file = open(response_filename, 'r')
response_json = response_file.read()
response_tmp = json.loads(response_json)
ymd = response_tmp['snapshot_ymd']
response = response_tmp['response']
results = []
cnt = 0
for one_res in range(len(response)):
if 'items' in response[one_res] and len(response[one_res]['items']) > 0:
for i in range(len(response[one_res]['items'])):
cnt += 1
display_link = response[one_res]['items'][i]['displayLink']
title = response[one_res]['items'][i]['title']
link = response[one_res]['items'][i]['link']
snippet = response[one_res]['items'][i]['snippet'].replace('\n', '')
results.append({'ymd': ymd, 'no': cnt, 'display_link': display_link, 'title': title, 'link': link, 'snippet': snippet})
save_results_dir = os.path.join(DATA_DIR, 'results')
makeDir(save_results_dir)
df_results = pd.DataFrame(results)
df_results.to_csv(os.path.join(save_results_dir, 'results_' + ymd + '.tsv'), sep='\t', index=False, columns=['ymd', 'no', 'display_link', 'title', 'link', 'snippet'])
if __name__ == '__main__':
makeSearchResults()
下記のようなデータが保存されます。
ymd no display_link title link snippet
20181002 1 ja.wikipedia.org ダイエット - Wikipedia https://ja.wikipedia.org/wiki/%E3%83%80%E3%82%A4%E3%82%A8%E3%83%83%E3%83%88 ダイエット(diet)とは、規定食という意味である。 人や動物や共同体が習慣的に摂る食品のこと。 食事療法: 健康のため、美容のため、肥満の防止(や解消)のため、食事を制限すること。 ダイエットは体重を目安にするが、 健康体重、標準体重、理想体重、目標 ...
20181002 2 cancam.jp ダイエット成功の秘訣は「食事」にあり!やせる食生活のルール https://cancam.jp/archives/285227 2017年5月5日 ... ダイエットを成功に導く鍵を握っているのは、毎日の食事。 ダイエット時に摂るべき食材、食事のタイミングなど、太らない食生活にはいくつかルールがあるんです。そんなやせるためのダイエット法をまとめてみました。これを参考にぜひダイエット ...
20181002 3 youpouch.com 【ダイエット】ほとんどお金かけずに8キロ落としたよ! 極意は「飽きっぽさ ... https://youpouch.com/2017/01/05/402580/ 2017年1月5日 ... 今までも何度かダイエットに挑戦してきましたが、全て挫折。ことごとく挫折。見事に何もかも挫折。その原因はただひとつ、私が飽きっぽい性格だから。何であれ1カ月で飽きてしまい、ジムの会員とかヨガの会員とかを色々無駄にしてきました。
20181002 4 dietplus.jp 【ダイエット診断】 あなたの“痩せない理由”がすぐわかる! ダイエットプラス https://dietplus.jp/shindan/entry.html 5000人のダイエット指導実績に基づいたダイエットプラスだけの「ダイエット診断」。「痩せない理由」とその改善ポイントがわかります。
20181002 5 blogger.ameba.jp ダイエット記録ジャンルトップ | Ameba公式ジャンル https://blogger.ameba.jp/genres/diet 公式ジャンル「ダイエット記録」のページです。糖質制限や炭水化物抜きダイエット、置き換えダイエットなど食事制限ダイエットに挑戦している人や、縄跳びダイエットやダイエット器具を使った運動ダイエットに挑戦中の人のブログが集まっています。お腹や下半身 ...
無料枠と回数のリセットタイミング
上でAPIを利用してデータが取得できることは確認できました。
実際運用にするにあたって、気になるのはお金の話です。
無料枠は非常に少ない
残念なお話ですが、Custom Search APIの無料枠は非常に少ないです...
こちらに書かれていますが
Google Custom Search JSON API(pricing)
1日100クエリーまでが無料で、それ以降は1000クエリーにつき5ドルとなっているようです(課金したとしても、MAX1万クエリー/日まで)
このAPIでは1回のリクエストにつき10件までしか取得できないため、100位まで取得するために10リクエスト使っています(ちなみに100位より下位をこのAPIで取得することはできませんが、仕様のようです)
ということは、毎日取得が前提だと、無料枠ではMAX10キーワードしか設定できないことになります。
それ以上にキーワードを設定したい場合は課金前提ということで。。。
回数のリセットタイミング
非常に少ない無料枠なので、開発中に気になるのはリセットタイミングです。
日本時間とは異なるタイミングでリセットされるため、注意が必要です。
Google Developer Console または Google Cloud Platform の
IAMと管理 > 割り当て
から Custom Search API(Queries per day)を選択すると確認できますが、
「毎日の割り当ては、太平洋時間(PT)の午前 0 時にリセットされます。」
となっています。
太平洋時間、つまりアメリカ西海岸地域の標準時ですね。
日本時間との差は17時間なので、日本時間の17時がリセットタイミングになります。
と理解したわけですが、実際はなぜか日本時間の16時にリセットされている??
原因はサマータイムでした(サマータイムほんとやめて欲しい...)
2018年のサマータイムは3月11日(日)に始まり、11月4日(日)に終了するようです。
ということで上記期間中は日本時間の16時がリセットタイミングになります。
その他、気になったところ
その他、検証中に気になったことをつらつらと書き留めています。
APIで取得した結果と普通にWebで検索した結果が微妙に違う
違うことはこちらのサポートにも書いてあるのですが
カスタム検索とは - カスタム検索 ヘルプ
いまいち挙動が不明です...
体感としては、APIの方が若干少ないように思います(Web検索と比べるとちょくちょく歯抜けがある)
APIで取得した件数(totalResults)と普通にWebで検索した際に表示されている件数が違う
例えば「ダイエット」で検索した場合
APIだとtotalResultsは「33,900,000」ですが
Webで検索すると「約 344,000,000 件」と表示され約10倍もの開きがあります。
これはなぜなんだろう...
APIではリスティング広告が取れない
APIでは自然検索の結果しか取得することができません。
Custom Search Site Restricted JSON APIとは?
こちらの価格説明に
Google Custom Search JSON API(pricing)
「1日あたり10,000件以上のクエリが必要で、カスタム検索エンジンが10個以下のサイトを検索する場合は、毎日のクエリ制限がない Custom Search Site Restricted JSON API に興味があるかもしれません」(Google翻訳)
とあったので気になって調べてみましたが、こちらに書いてある通り
Custom Search Site Restricted JSON API
「ウェブ全体を検索」をオフしないと使えない(本来のカスタム検索用途)ので、今回は該当しないようでした。
参考にしたサイト
・google custom search engine(CSE)を使って、検索結果をjsonで取得する
・Googleの画像検索APIを使って画像を大量に収集する
・Google Custom Search API(カスタムサーチAPI)を使ってプログラムで検索結果を取得する
・Google Custom Search API を使ってみる
おわりに
本記事ではAPIを使って取得していますが、実際は並行してスクレイピングでの取得にもトライしていました。
ただ、そちらは常識的なお作法を守っても、一定回数で503エラーとなってIPが使えなくなり、、、
なかなか手ごわいGoogle先生![]()