株式会社バンダイナムコ研究所のlaiです。Nishika株式会社が主催した「ボケ判定AIを作ろう! (ボケてコンペ #1)」コンペに参加しました。本記事で私の取り組みの共有と振り返りをしたいと思います。
概要
本コンペでは、株式会社オモロキ様提供の「ボケ缶データセット」を用い、ボケ画像とボケテキストのみから、そのボケが面白いか・面白くないかを予測するコンペです。「ボケて」では星をつけることで面白いボケに投票できるようになっており、その数をもとに面白さを定義しています。ある時点のボケての星の数を2段階にビニングしたもの(面白いものを1、 面白くないものを0)が本コンペの目的変数となります。
ボケ画像とテキストのペアの例:

結果
リーダーボード & 最終ランキングで1位でした。去年参加しました「小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?」コンペに続いて2回目の入賞となります。


解法
本コンペの難点
本コンペの目的はつまり「AIに笑いを理解させる」ことですが、実は極めてハイコンテクストであることをある程度想像できると思います。例えば以下の画像のボケを理解するには、「画像には何がある」、「テキストは何を表している」だけでなく、「SASUKEは障害物を使った番組である」という暗黙の前提条件も理解しないといけません。

もう一つの難点として、目的変数はバイナリであることから、画像・テキストペアに対して面白い・面白くないの判定は基本「ボケて」サイト上の評価に依存するため、「ボケて」以外のソースから追加の正例データを作成することがかなり難しいです。なお、AWS電笑戦で使用された「ボケ缶データセット」から追加で情報を得ることや、「ボケて」のサイトから直接スクレイピングする行為は運営から禁止されています。一応負例データ(面白くない)ボケなら量産できますが、学習データのラベル分布がほぼ1:1のため、安易な水増しは既存のデータ分布を改変し、予測性能にマイナスな影響を与えるリスクが高いです。
「ボケ」データの特徴
本コンペと類似するコンペがないかを調査したところ、Facebook AI が過去開催したHateful Memes Challengeを紹介する論文を発見しました。詳細な紹介は割愛しますが、そこで得られた最も重要な知見として:
- 画像とテキストの結びつけが面白いことにより成立するボケ (multimodal boke)
- 画像が適当だけどテキスト単体が面白いことにより成立するボケ (unimodal boke)
以上2種類のボケが存在することを気付きました。ちなみに配布されたデータセットでは画像単体で成立するボケがほぼいませんでした。
例として下記左のボケがmultimodal boke、右のボケがunimodal bokeに該当するではないでしょうか。


この知見が解法とどういう関係があるかと言いますと、unimodal bokeはテキストのみ判別できるため、早すぎるマルチモーダル特徴融合は画像情報によるノイズでunimodal bokeを上手く判別できないおそれがあります。実際私の実験では運営のチュートリアルにあるMMBTのmultimodel分類モデルより、BERT系のunimodal分類モデルのスコアの方が高い場合がほとんどです。結果、言語モデルのunimodal分類モデルの予測値と画像特徴量を結合させる方針を採用しました。
評価について、CVとLBの相関が強いだけでなく、TrainセットとTestセットの各特徴量が驚くほど一致しているため基本Trust Local CVの方針を採用しました。
基盤モデルによるボケテキストの判定
先ほどテキスト特徴量の重要性を述べましたが、実は本コンペではテキスト特徴だけで金圏まで行けます。それを実現するため、Finetuningで利用する基盤モデルの選定が重要になります。私が過去投稿した記事「小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~ 3rd place solution & 振り返り」ではHuggingFaceのHosted Inference APIを利用する方法を紹介しましたが、今年の言語処理学会でやっと定量的に評価する論文が発表されました。
論文: JGLUE: 日本語言語理解ベンチマーク
GitHub: https://github.com/yahoojapan/JGLUE
こちらの早稲田大学とヤフー株式会社が発表された論文では日本語における言語理解ベンチマークJGLUEの構築し、それを用いて主流の日本語基盤モデルに対してベンチマークを行いました。論文発表された後で公開されたroberta-large-japaneseの評価結果もGitHubに追加されています。こちらの論文を指針として選定した基盤モデルとunimodalでファインチューニングしたモデルのCVは以下の通りです。
| CV | |
|---|---|
| cl-tohoku/bert-base-japanese-v2 | 0.6438 |
| cl-tohoku/bert-large-japanese | 0.6487 |
| nlp-waseda/roberta-base-japanese | 0.6384 |
| nlp-waseda/roberta-large-japanese | 0.6359 |
| rinna/japanese-roberta-base | 0.6494 |
| nict_bert-base_JapaneseWikipedia_100K | 0.6452 |
JGLUEのGitHubリポジトリ記載の通り、Best CVモデル=早稲田大学が公開したroberta-large-japaneseのシングルモデルのPrivateスコアが約0.630で最終ランキング6位相当の成績になります。ただし注意点として、Large系のモデルの学習が非常に不安定のため、学習率に関するハイパーパラメータを細かく調整する必要があります。学習を安定化させるTipsとして:
- weight decayとwarmup stepsは必ず入れる
- 事前学習モデル部分の重みに対する学習率を下げる(もしくはフリーズ)、相対的に分類ヘッドの学習率を上げる
- 大きなバッチサイズで学習する(特にGPUメモリが限られた場合、Mixoutなどのトリックによりメモリをバッチサイズに回した方が安定しやすい)
ボケ画像特徴量の抽出
画像の特徴量に関して、「画像認識モデル」と「画像-テキスト対照学習モデル」2つのジャンルから基盤モデルの選定を行いました。
前者はKagglerの間で人気のTimmライブラリを利用したベンチマークで上位の以下2つのモデルを利用しました。
- vit-base-patch16-224-in21k
- swin-large-patch4-window12-384-in22k
後者は下記の論文を参照して選定を行いました。こちらの論文はCLIPの埋め込みを考察する論文ですが、特筆すべき点として、下の図で各CLIPモデルのZero-Shot画像分類性能と画像キャプション生成性能のベンチマークを行いました。
論文: The Unreasonable Effectiveness of CLIP Features for Image Captioning: An Experimental Analysis

この図を従って、2つの指標において性能が最も良い2つのモデルを採用しました。
- CLIP-ViT-L/14
- CLIP-ViT-RN50x16
その他、rinna社が公開した日本語CLOOBモデルも利用しました。英語と日本語、2つの異なる言語のCLIPモデルを同時に利用することになりましたが、「異なる言語の埋め込みに実は潜在的なマッピング関係が存在し、言語が違うけど画像の意味さえ表現できれば関係ない」という仮説のもとに検証したところ、日・英のCLIP特徴量両方ともCVを大きく向上させました。
上記の各モデルのLastHiddenStateで出力された特徴量の次元数が異なるため、PCAを用いて全部128次元に変換しておきました。
マルチモーダル特徴量の融合
言語モデルの出力と画像モデルの特徴量をconcatし、ピアソン相関係数の上位の300件の特徴量を最終候補として選出しました。特徴量を融合する手法として、今年の言語処理学会で私が発表した以下論文の手法を採用しました。
論文: RINA:マルチモーダル情報を利用したキャラクターの感情推定
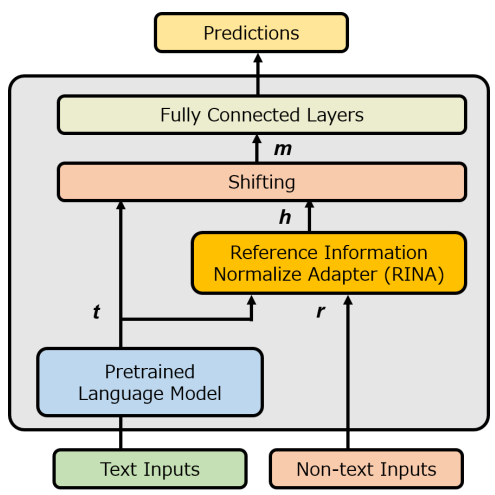
論文では感情分類タスクをフォーカスしていましたが、この手法の本質は「非テキスト情報の特徴量を用いてテキスト情報を補正する」ため、本コンペとの相性が非常に良かったです。Facebook Hateful Memes Challenge で提案されたLate FusionをLightGBMで試していましたが、CVではRINAの方が若干良い結果が得られました。
おわりに
今回は1位をいただきましたが、自分のベストモデルでも予測正解率が6~7割に留まる結果になりましたので、正直まだまだポテンシャルを感じています。コンペ終了した後にもコンペのホームページからデータセットをダウンロードできますので、外部データなどコンペの制約が解禁された条件において、AIがどこまで「ボケ」を理解できるか、ぜひ一度チャレンジしてみてください。あらためてコンペを開催してくださった皆様 & コンペに参加してくださった皆様ありがとうございました。