概要
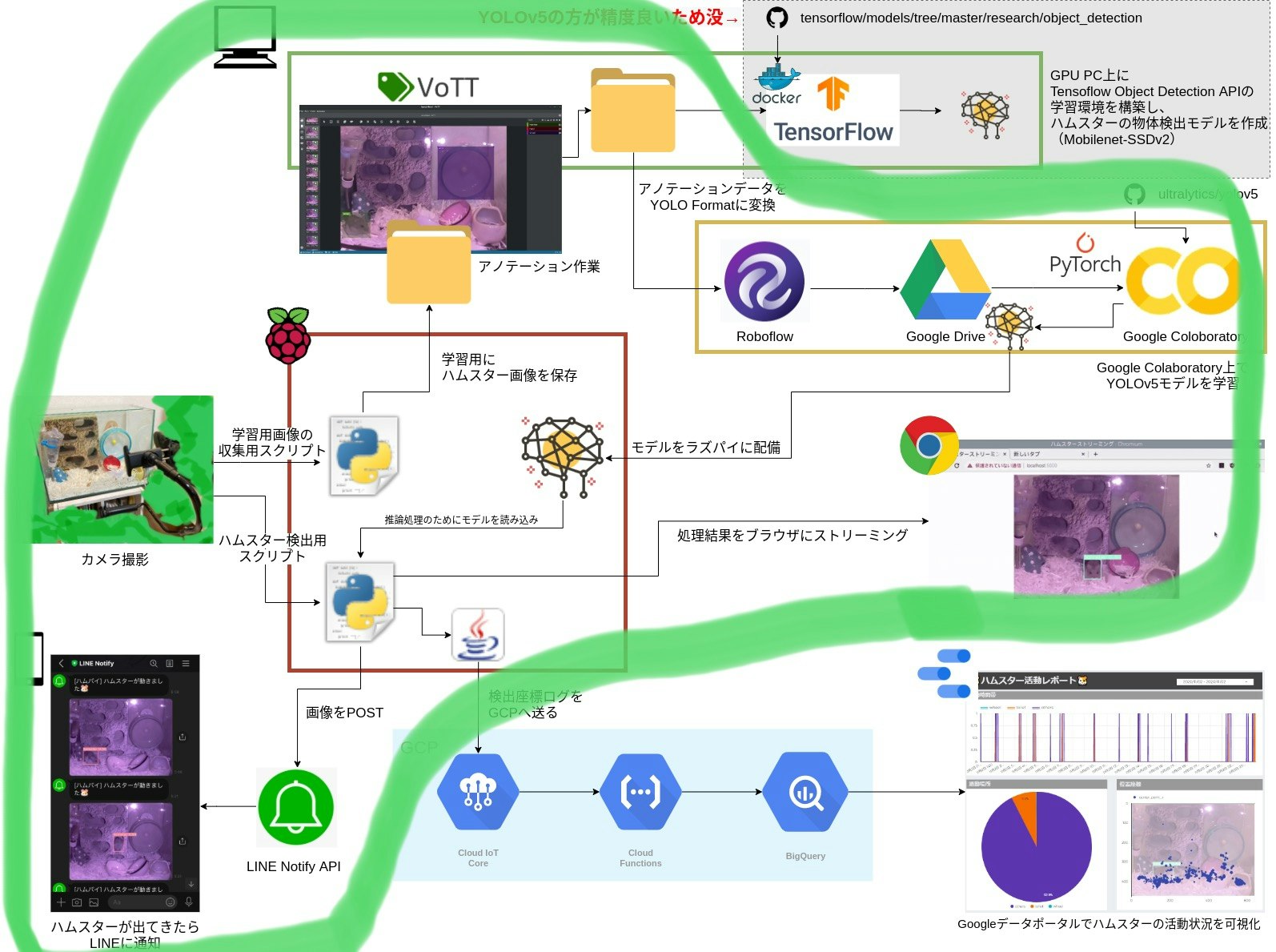
今回はラズパイやディープラーニングを用いてハムスターの行動を監視するシステムを作ってみた【概要】で紹介したハムスター監視システム(ハムパイ)の実装編となります。
- Python(Flask)+ OpenCVを使ったストリーミング処理
- 物体検出アルゴリズムYOLOv5モデルの学習および実装
が主となります。雑ですが、↓の緑枠の部分です。
前提知識
- Pythonの基礎
- OpenCVの基礎
- Linuxの基本操作(特にパッケージのインストール周り)
- gitの基礎的なコマンド(cloneしてきたり、特定のコミットに戻したり、等)
- 機械学習及びディープラーニングの基礎知識
※ 今回はディープラーニングそのものの難しいチューニングは行っていないので、「データを準備してモデルを学習させる流れ」を抑えておけばOKくらいのレベル感だと思います。
ラズパイのセットアップ
カメラモジュールをラズパイにくっつけ、OpenCV4やらPythonやら必要なものをインストールします。
※ 後日追記します。
ストリーミング&LINE通知処理の仕組み
完成版のコード(stream_yolov5.py)をかいつまんで処理の流れを整理します。
フレームを読み込み、処理をかけ、ストリーミングする
# 毎フレームに対して行う処理
while True:
frame = camera.get_frame() # フレームをカメラモジュールから取得
# 略
# ストリーミングに向けた型変換
frame_encode = cv2.imencode('.jpg',frame)[1]
string_frame_data = frame_encode.tostring()
yield (b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n' + string_frame_data + b'\r\n\r\n')
OpenCVチュートリアルに詳しいですが、Python上でOpenCVを用いて動画を処理する際は、パラパラ漫画のように一枚一枚の画像(フレーム)を拾ってきて、その一枚一枚に対して処理を行っています。上記コードの書き方はそのためのおまじないのようなものです。
「# 略」の部分では、各フレームに対して「物体検出」「LINE通知」の処理を行うか否かの判定が行われています。
以下にてそれらの処理を簡単に紹介します。
物体検出ディープラーニングモデルの推論処理を実行
# フレームから物体検出した推論結果を受け取る。
bboxes = detect_bboxes(frame)
受け取ったフレームの画像を入力として、detect_bboxesにてYOLOv5モデルの推論処理を走らせ、その結果をbboxes変数にて受け取っています。
detect_bboxesはYOLOv5のdetect.pyを参考に実装しました。
ここの出力の一例です(bboxesをprintしたもの)
[[ 127 332 233 446 0.90786 0]]
# [検出枠の左上x座標, 左上y座標, 右下x座標, 右下y座標, 信頼度, クラス番号]
検出枠の4点座標、信頼度(物体検出モデルがどのくらい自信を持って予測したかの0~1スコア)、識別クラス番号(今回はハムスター=0)がそれぞれ得られます。もしここで何も検出されていなければ空っぽのリストが返ってきます。
このようにして、ハムスターがいるかいないか、映っていた場合どこにいるか、の推論結果が手に入りました。
あとは、ハムスター(class=0)の座標値をもとに、検出枠をフレームに描画します。YOLOv5のplot_one_box関数を利用。
# 物体の枠をストリーミングに描画
label = '%s %.2f' % (names[int(bbox[5])], bbox[4]) # class_number, confidence
plot_one_box(bbox[:5], frame, label=label, color=colors[int(bbox[4])])
描画結果↓

判定を通過したフレームをLINEのAPIにPOST
物体検出モデルによる推論処理を行い、結果を描画することまで出来ました。
次はLINE Notifyを用いてこの画像をLINEに通知する機能を実装してみたいと思います。
LINE Notifyの初期設定、使い方等については以下の記事が詳しく、参考にさせていただきました。
PythonでLINEにメッセージを送る
まずは、LINE Notifyに画像をPOSTするために必要な情報を定義します。
アクセストークンは環境変数として設定し、os.environで拾ってきています。
# LINE Notifyとの連携に関する情報
LINE_API_URL = 'https://notify-api.line.me/api/notify'
LINE_API_TOKEN = os.environ['LINE_API_TOKEN']
MESSAGE = 'ハムスターが動きました🐹'
そして、リクエストヘッダ、ボディを組み立て、POSTする処理を関数にまとめ、
# LINE Notify APIを用いて、ローカルに保存されている画像のパスを参照し投稿する
def post_image_to_line_notify(line_token, message, image_path, line_api_url):
line_header = {'Authorization': 'Bearer ' + line_token}
line_post_data = {'message': message}
line_image_file = {'imageFile': open(image_path, 'rb')}
res = requests.post(line_api_url, data=line_post_data,
headers=line_header, files=line_image_file)
print(res.text)
フレームにハムスターが検出されていて、かつ、最後のLINE通知からWAIT_SECOND秒以上経っている場合、POSTを実行します。今は最短10分おきにLINE通知するように設定しています。
# 最後の投稿からWAIT_SECOND以上経っている場合、LINEへ物体検出時のフレーム画像を投稿
now = datetime.now()
if ((now - last_post_time).total_seconds() > WAIT_SECOND):
# まずLINEへ投稿するフレームをローカルに保存
image_path = 'img/{}.jpg'.format(now.strftime('%Y%m%d%H%M%S'))
cv2.imwrite(image_path, frame)
# LINEへ投稿
post_image_to_line_notify(LINE_API_TOKEN, MESSAGE, image_path, LINE_API_URL)
last_post_time = now
検出ログをGCP(BigQuery)に格納
さらに、検出座標をログとしてGCPのIoT Coreへ送り、その活動履歴をBIツール(ダッシュボード)で可視化、というのも行っていますが、ここの詳細は別記事として投稿予定です。
以上が、システム全体の処理となります。
コード全体はこちら
from flask import Flask, render_template, Response
from flask_sslify import SSLify
import cv2
from datetime import datetime
import threading
import requests
import time
import ssl
import numpy as np
import os
from video_streamer import VideoStreamer
# for yolov5 import
import sys
sys.path.append("/home/pi/yolov5")
import torch
from utils.datasets import *
from utils.utils import *
# model settings
device = 'cpu'
weights = 'models/best.pt' # self trained model
model = torch.load(weights, map_location=device)['model'].float()
# Get names and colors
names = model.names if hasattr(model, 'names') else model.modules.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
camera = VideoStreamer()
# Flask settings
app = Flask(__name__)
context = ssl.SSLContext(ssl.PROTOCOL_TLSv1_2)
context.load_cert_chain('/home/pi/cert.crt', '/home/pi/server_secret.key')
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, 32), np.mod(dh, 32) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
# LINE Notify APIを用いて、ローカルに保存されている画像のパスを参照し投稿する
def post_image_to_line_notify(line_token, message, image_path, line_api_url):
line_header = {'Authorization': 'Bearer ' + line_token}
line_post_data = {'message': message}
line_image_file = {'imageFile': open(image_path, 'rb')}
res = requests.post(line_api_url, data=line_post_data,
headers=line_header, files=line_image_file)
print(res.text)
def detect_bboxes(frame):
img = cv2.cvtColor(np.array(frame), cv2.COLOR_RGB2BGR)
img = letterbox(img, new_shape=320)[0]
img = np.transpose(img, (2,0,1))
img = torch.from_numpy(img).to(device)
img = img.float()
img /= 255.0 # 0 - 255 to 0.0 - 1.0
img = img.unsqueeze(0)
# Inference
pred = model(img, augment=False)[0]
# Apply NMS
# detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
pred = non_max_suppression(pred, 0.4, 0.5, classes=None, agnostic=True)
dets = pred[0]
if dets is not None:
# Rescale boxes from image_size to frame_size
dets[:, :4] = scale_coords(img.shape[2:], dets[:, :4], frame.shape).round()
dets = dets.detach().numpy()
return dets
@app.route('/')
def index():
return render_template('index.html')
# ストリーミングしつつ、物体検出したらLINEへ通知
def generate(camera):
WAIT_SECOND = 600
# LINE Notifyとの連携に関する情報
LINE_API_URL = 'https://notify-api.line.me/api/notify'
LINE_API_TOKEN = os.environ['LINE_API_TOKEN']
MESSAGE = 'ハムスターが動きました🐹'
CONFIDENCE = .7
last_post_time = datetime(2000, 1, 1) # このタイミングで適当な日付で初期化
# 毎フレームに対して行う処理
while True:
frame = camera.get_frame() # フレームをカメラモジュールから取得
# フレームから物体検出した推論結果を受け取る。
bboxes = detect_bboxes(frame)
print(bboxes)
if bboxes is not None:
highest_score = CONFIDENCE
bbox = None
# select highest scored box
if np.all(bboxes[:, 5]!=1): # no hand
for b in bboxes:
if (b[5] == 0) & (b[4] > highest_score):
bbox = b
highest_score = b[4]
if bbox is not None:
# 物体の枠をストリーミングに描画
label = '%s %.2f' % (names[int(bbox[5])], bbox[4]) # class_number, confidence
plot_one_box(bbox[:5], frame, label=label, color=colors[int(bbox[4])])
# 最後の投稿からWAIT_SECOND以上経っている場合、LINEへ物体検出時のフレーム画像を投稿
now = datetime.now()
if ((now - last_post_time).total_seconds() > WAIT_SECOND):
# まずLINEへ投稿するフレームをローカルに保存
image_path = 'img/{}.jpg'.format(now.strftime('%Y%m%d%H%M%S'))
cv2.imwrite(image_path, frame)
# LINEへ投稿
post_image_to_line_notify(LINE_API_TOKEN, MESSAGE, image_path, LINE_API_URL)
last_post_time = now
# GCPのIoT Coreへログを送信
# TODO:Add conf, class_number
frame_height, frame_width = frame.shape[:2]
start_x = bbox[0]
start_y = bbox[1]
end_x = bbox[2]
end_y = bbox[3]
cmd = 'cd /home/pi/iotcore/; java -jar raspi-comfort-sensor-iotcore-1.0.jar '
opt = '--start_x {} --start_y {} --end_x {} --end_y {} --frame_height {} --frame_width {}' \
.format(start_x, start_y, end_x, end_y, frame_height, frame_width)
os.system(cmd + opt)
# ストリーミングに向けた型変換
frame_encode = cv2.imencode('.jpg',frame)[1]
string_frame_data = frame_encode.tostring()
yield (b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n' + string_frame_data + b'\r\n\r\n')
@app.route('/video_feed')
def video_feed():
return Response(generate(camera), # generate関数からframeをストリーム
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, ssl_context=context, threaded=True, debug=False)
「ハムスターの動きを捉える」試行錯誤の経緯
物体検出モデル開発の詳細に入る前に、ちょっとだけ経緯を..
1. OpenCVを用いた動体検知システムの作成
元々はディープラーニングを使おうとしたのではなく、この記事を参考にし、OpenCVのシンプルな画像処理による動体検知システムとして作っていました。コードはこちら。
動体検出&LINE通知の仕組みとして実装は出来たものの、これだとハムスター以外の動き(カメラ自体の揺れ、世話をするために水槽に手を入れる等)に対しても検知が働いてしまい不便..
やはりハムスターをピンポイントで見分ける仕組みが欲しいため、ディープラーニングモデルを埋め込むことを決意。
2. TensorFlow Object Detection APIを用いたディープラーニングによる物体検出の導入
まずは気軽にディープラーニングモデルを作成出来て、ラズパイへの実装例もあるObject Detection APIを利用し、軽量アルゴリズムのMobileNet-SSDv2によるハムスター検出モデルを作成、無事実装完了。そのコードはこちら
(機会あればここの取り組み詳細も記事にしたいです..)
3. 誤検出の問題
ところが、いざ運用してみると、



このように、誤検出がちらほら(confidenceの閾値を0.9とか高く設定してもこうなる..)
画面にハムスターが映っている間は体感的にすごく良い性能を示してくれてたんですが、ハムスターが居ないときには手やら何やらを誤認識してしまうという減少に悩まされることに..このままじゃ、動体検知から物体検出に変えたメリットも薄い..
以下のissueのように、似た症状に悩まされる人は多い模様。
Trained model detects other objects
いろいろググって、
- Hard Negative Miningのハイパーパラメータを変える。
- 「背景」となる画像(ハムスターが映っていない画像、全く関係のない画像)を学習用データセットに追加する。
- Fine tuningを辞め、スクラッチで学習させる。
- 誤認識の原因となりそうな紛らわしいアノテーションデータを教師データから省く。
などいろいろ試行錯誤してみたものの結果は芳しくなく、これ以上のチューニングを断念。
次の手として、最近出たSoTAかつ軽量の物体検出アルゴリズム、YOLOv5でのモデル作成を試してみました。
YOLOv5
One stage系の物体検出アルゴリズムであるYOLOシリーズの最新版です(これを後継と言ってよいのかどうか議論もあるようですが、本記事では割愛)
高い精度と推論速度を両立したアルゴリズムとして注目されています。YOLOv4の例にはなりますが、Mosaic augmentation等、学習時のデータ拡張手法の工夫が一つのポイントとなっているようです。
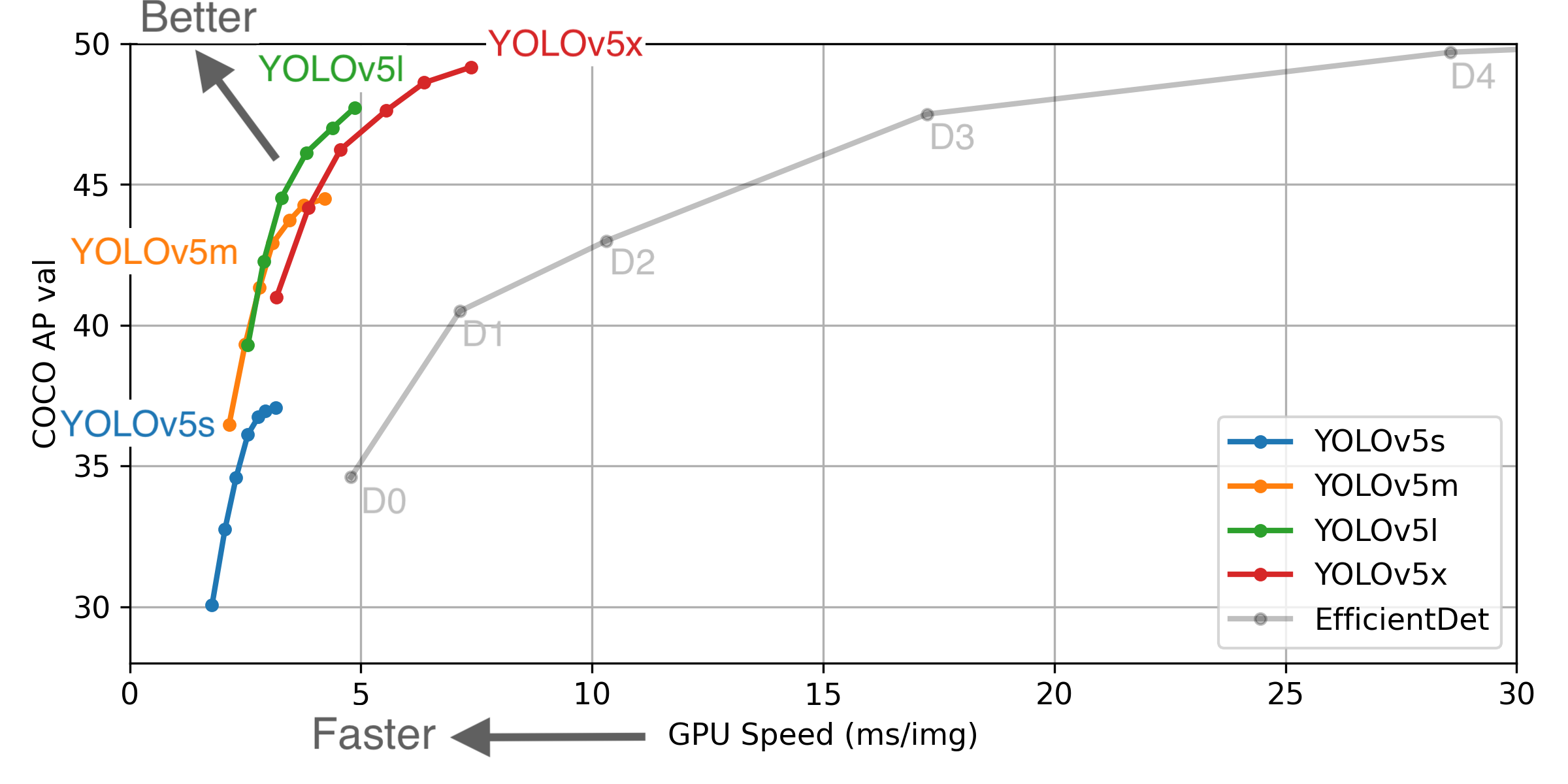
精度と速度のトレードオフを考慮し、x,l,m,sの4つのネットワークが提供されていますが、今回は非力なラズパイで動かすため、一番軽いYOLOv5sを利用します。
ラズパイの環境構築
まずはラズパイにPyTorch一式をインストールし、GitHubよりYOLOv5のソースをcloneしてきます。
ここはラズパイで物体認識シリーズ YOLO v5のセットアップ、の記事を参考にさせていただきました。
ポイントは、arm系のラズパイには普通に「pip install torch」をしても上手くインストールできないため、ソースからPyTorchをビルドする、もしくはラズパイ4用に提供されているwheelをダウンロードしpipインストールする、です。私は後者のwheel経由でインストールし、少し古いPyTorch1.5.0およびTorchVision0.6.0をインストールしました。
ところがなんと、最新のYOLOv5ソース(2020/11/10時点)がこのバージョンに対応していなかったようで、エラーが出てしまう..
使えなければ元も子もないので、今回はやむを得ずバージョンダウンする道を選びました。
試行錯誤の過程をきちんと記録できておらず申し訳ないですが、このコミットまで戻すと、バージョン関連のエラーが解消され使えるようになりました。以下の流れで出来たと思います。
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
git reset --hard 24dd150
これで最新のYOLOv5のアップデートやfixには対応できなくなってしまうのですが、致し方なしということで..
学習用の画像の収集
物体検出モデルを作るためには、認識したい対象が映っている画像をたくさん用意し、それらを座標情報とともに"学習"させる必要があります。
ここでは、既に作成してあるOpenCVの動体検知スクリプトを流用し、ハムスターが写っている画像計500枚を撮り溜めました。このうち400枚を学習用に、100枚を検証用の画像データセットとして使用します。
教師データセットの作成
アノテーション作業
画像が集まったら、ハムスターが画像内のどの位置(座標)にいるかをデータ化する、アノテーション作業を行います。
専用のツールを用いて、GUI上でマウスでドラッグしながら、以下のように画像の中の対象物の位置を囲って枠をつける、というイメージです。今回はアノテーションツールにVOTTを採用しました。
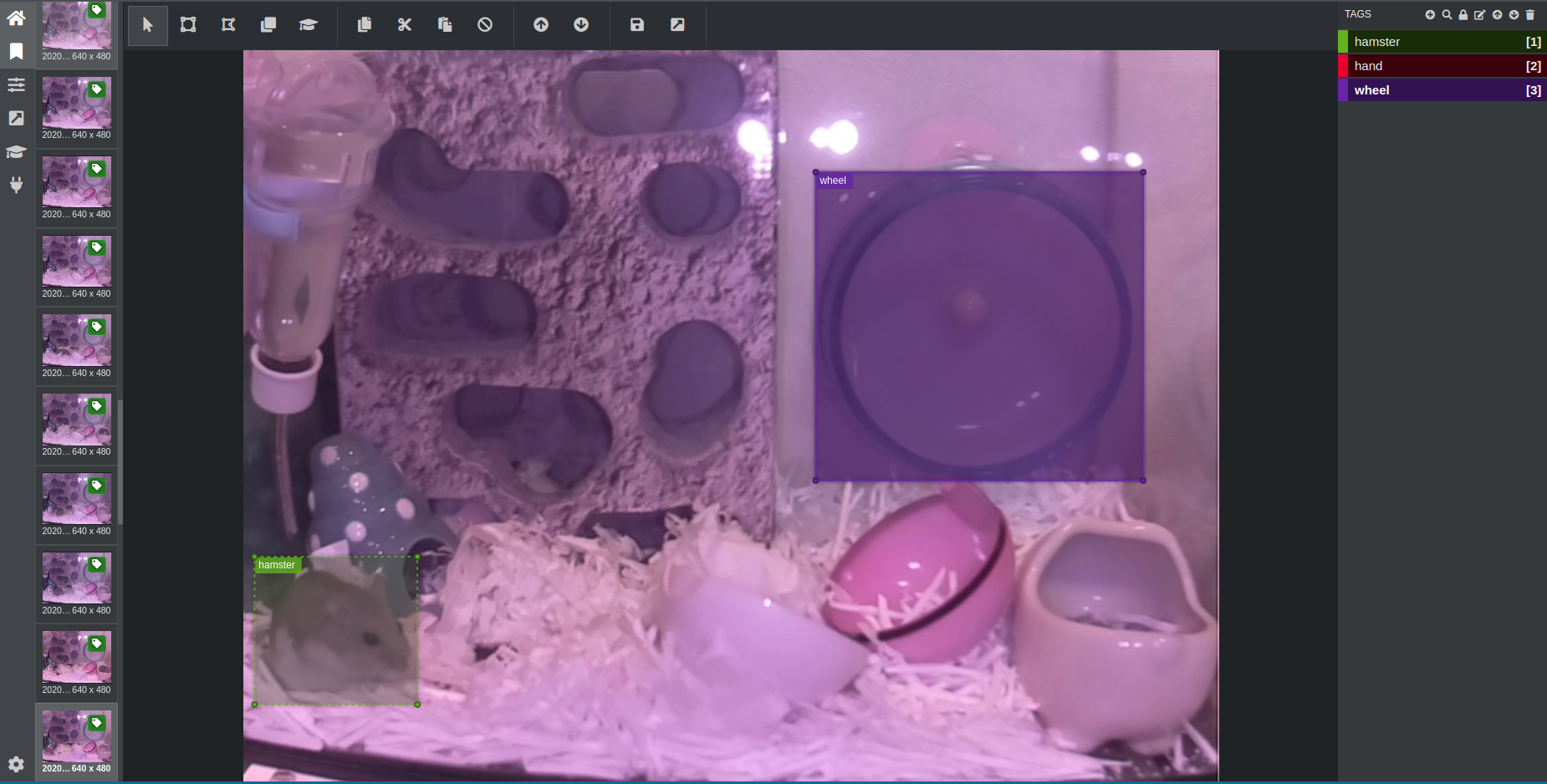
※ 回し車にもアノテーションしている理由は後述します。
アノテーション作業が終わったら、各画像に対する座標データを任意のフォーマットで書き出すことになります。
今回は、VOTT-JSON形式で出力しています。
YOLO Formatへの変換
YOLOv5でモデル学習するためには、YOLO Formatのデータセットが必要となります。
しかし、VOTTでは直接YOLO Formatを出力形式として指定できないため、いったんVOTT-JSON形式で出力したアノテーションデータを、画像と共にRoboflowで変換し作成しました。この変換作業は以下の記事が非常に参考になりました。
アノテーションツール VoTT を使って YOLOv5 の学習データセットを作る
ここまでで、学習に必要なデータセットを準備することが出来ました。
Google Colaboratoryのセットアップ
学習環境にはGoogle Colaboratoryを使用しました。
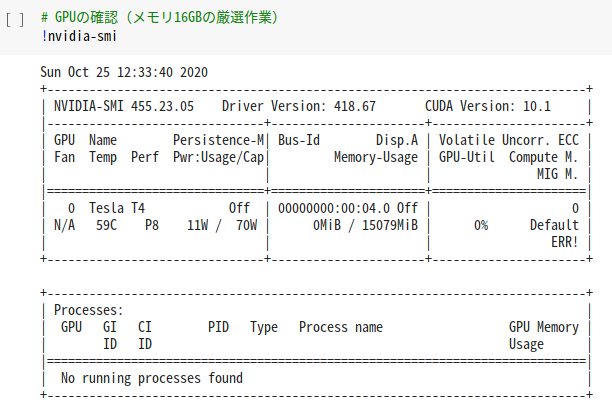
※ Object Detection APIの施行時は自前のGPU PC(RTX2070 SUPER 12GB)を使っていましたが、Colaboratoryではより多くのGPUメモリ(16GB)のランタイムが使える=batch sizeを稼げるし、何より手軽ということで採用にいたりました。
細かな流れに関しては【YOLOv5】マスクしてる人・してない人を物体検出の記事にてとてもわかりやすくまとめていただいておりますが、ここでも簡単におさらいします。
最初に、GPUランタイムを厳選します。約16GBのGPUメモリが出てくるまで粘ります。
まずはGoogle Driveをマウントします。
# Googleドライブをマウント
from google.colab import drive
drive.mount('/content/drive')
cd /content/drive/My Drive
次に、GitHubからYOLOv5のコード一式をcloneします。
一度cloneすればマウントしたGoogle Driveに保存されるので、2回目以降は不要な作業です。
# YOLOv5のclone(初回のみ)
!git clone https://github.com/ultralytics/yolov5
yolov5のディレクトリに移動し、ラズパイ環境にて下げたバージョンと合わせます。
これをやらないと、せっかくモデルが学習できてもラズパイで動いてくれません。
cd yolov5
!git reset --hard 24dd150
あとは、必要なものをpip経由でインストールします。
これはランタイムを再起動した場合、毎回必要となります。
# 必要なライブラリのインストール(ランタイム再起動ごとに毎回)
!pip install -U -r requirements.txt
学習
いよいよ、ディープラーニングでハムスター検出モデルを学習させます。
YOLOv5のスクリプトが素晴らしく使いやすく出来ているおかげで、ここはデータを指定してコマンドを打つだけです。
特にひねったチューニングはやっておりません。
# YOLOv5s
!python train.py --img 640 --batch 32 --epochs 200 --data ../hamster_datasets/data.yaml --cfg ../hamster_datasets/hampi_yolov5s.yaml --weights ''
バッチサイズ32、200エポックで、スクラッチで学習を回しています。
※ GPUメモリ15GBでなく、16GBのランタイムもあった気がするので、それ使えばバッチサイズ64で出来たかも..

Mosaic Augmentationしながら学習する様子が吐き出されています。
モデルの性能評価
学習が終わったら、性能を評価してみます。
ログと共に、以下のような要約図も出力されるので便利です。
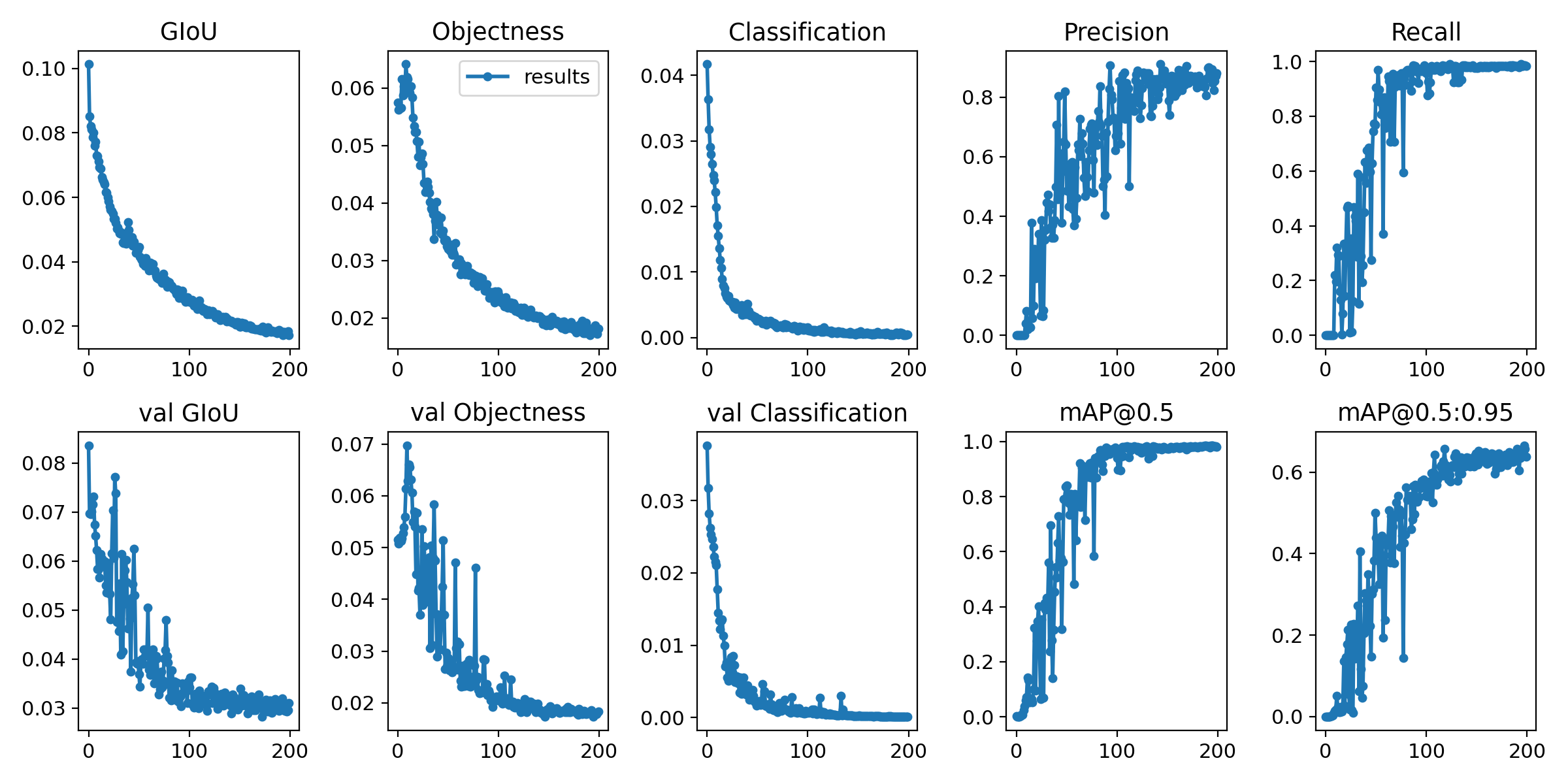
test.pyのスクリプトにて、Recall、Precision、mAP等の物体検出モデルとしての精度指標を確認できます。
最も検証データに対するmAPが良かった重み(best.pt)、で評価すると、mAP@0.5で0.926となりました。
データ数がそこまで多くなく、特別なチューニングをしていないことを考えると、数値だけで見るとそこそこ良いのかなと思います。

ストリーミング&LINE通知システムへのモデルの配備
あとは、出来上がったbestの重みのモデルをラズパイに配備します。
あとは、ストリーミング&LINE通知スクリプトでこのモデルを読み込み、推論処理が走らせられるようにします。
# model settings
device = 'cpu'
weights = 'models/best.pt' # self trained model
model = torch.load(weights, map_location=device)['model'].float()
運用面での工夫
システム、およびディープラーニング実装としては以上なのですが、最後に工夫したポイントを2つ紹介します。
誤検出問題への対処
今回、「ハムスター」以外にも、「飼い主の手」「回し車」の3つをアノテーションしたデータを学習させています。目的は「誤検出の低減」です。

元々はハムスターのみを学習させたモデルを作っていたのですが、[経緯](# 「ハムスターの動きを捉える」試行錯誤の経緯)のところと同じ誤検出問題に悩まされることに..


世話のために水槽に手を入れガサガサしているときに一瞬、物体検出モデル的にハムスターっぽいと解釈できてしまう模様が生まれているようです。
最近、AI自動追尾カメラが、サッカーの試合で線審のハゲ頭とボールを誤認識で、サポーターがっかりという記事が出てたのですが、商用で運用されているものですら間違いは起こりうる..
その間違いを減らすために、「覚えさせる物体を増やす」ことで、モデルがそれらを見分けられるように誘導しました。これで、上の写真のような「回し車を誤判定する」のは無くなりました。
誤判定をさらに減らすために、検出後の後処理として「"手"が映っている場合は処理を働かせないようにする」判定をストリーミングのスクリプトに加えています。
以下が当該部分のコードです。
リファクタリング出来ておらず見づらいですが、クラス番号が1である手が検出されていないときだけ(bboxes[:, 5]!=1)、ハムスターに枠をつけたりLINE通知したりする処理に続くようにしています。
if bboxes is not None:
highest_score = CONFIDENCE
bbox = None
# select highest scored box
if np.all(bboxes[:, 5]!=1): # no hand
for b in bboxes:
if (b[5] == 0) & (b[4] > highest_score):
bbox = b
highest_score = b[4]
これにより、手をガサガサしたせいで一瞬ハムスターっぽい模様が生まれる現象を強引に封印しました。
荒療治ですが、もともとハムスターの自然な行動を検出したいという目的を考えれば、手が写っている=世話をしているイレギュラーな条件、とみなしと除外するのは不自然ではないと自己納得しました。
もうちょっと教師画像を工夫したり、ちゃんとしたモデルチューニングしたり等の余地はあったかもしれないですが、今回はこれでしのぎました。
おかげさまで、完全にゼロとまでは行きませんが、相当誤検出を減らすことが出来ました。
処理が重すぎる
YOLOv5に画像を読み込ませる際、デフォルト設定だと入力画像は640×640に圧縮されるのですが、ラズパイのスペックだと、たとえ640のサイズでもフレームごとに推論処理をかけるのはかなりきつい印象でした。先例でも同じ悩みにぶち当たっているようです。
そこで、入力画像をデフォルトの半分の320にリサイズしたうえで推論させるように変更すると、カクカクではあるもののとりあえず本システムの要件を満たせそうなレベルに改善できました。
(時間あったら比較動画を追記したいと思います。)
モデルの学習はデフォルトの640×640リサイズで行なっているため、さらに荒い画像を推論時に流すことで精度が大きく落ちたら嫌だと思っていたのですが、気になるほどではなかったのでこのまま採用を決めました(主観的な物言いですみません..)
def detect_bboxes(frame):
img = cv2.cvtColor(np.array(frame), cv2.COLOR_RGB2BGR)
img = letterbox(img, new_shape=320)[0] # 画像を320×320にリサイズ
img = np.transpose(img, (2,0,1))
img = torch.from_numpy(img).to(device)
img = img.float()
img /= 255.0 # 0 - 255 to 0.0 - 1.0
img = img.unsqueeze(0)
# Inference
pred = model(img, augment=False)[0]
# Apply NMS
# detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
pred = non_max_suppression(pred, 0.4, 0.5, classes=None, agnostic=True)
dets = pred[0]
if dets is not None:
# Rescale boxes from image_size to frame_size
dets[:, :4] = scale_coords(img.shape[2:], dets[:, :4], frame.shape).round()
dets = dets.detach().numpy()
return dets
感想
今回はラズパイの環境構築、データセットの変換あたりが主な試行錯誤ポイントで、ディープラーニングそのものはただデータを流し込んで学習させただけに近しく大したことはしていないのですが、逆にいえば、お膳立ての仕方を学べばかなり簡単に"AI"が作れることを実感できました。
また、ハードや"AI"の機能制約にぶち当たったときに、要件を満たすためにその外側のシステムで工夫する、という試行錯誤もちょっと体験できて良かったです。
おまけ

かわいい。