YOLOv5がリリースされたとのことなので試してみました。
https://github.com/ultralytics/yolov5/
目次
1. 使用データと目的
以下のサイトから物体検出用の画像を拾ってきました。
https://public.roboflow.ai/object-detection/
色んなデータがありますが、コロナの時期なのでマスク有り無しのデータを選択してみました。
目的は図のようにマスクをしている人・していない人の物体検出を行うことです。

2. 実装例
2-1. データ準備
まずデータをダウンロードします。
以下のURLにアクセスします。
https://public.roboflow.ai/object-detection/
Mask Wearing Datasetをクリックします。
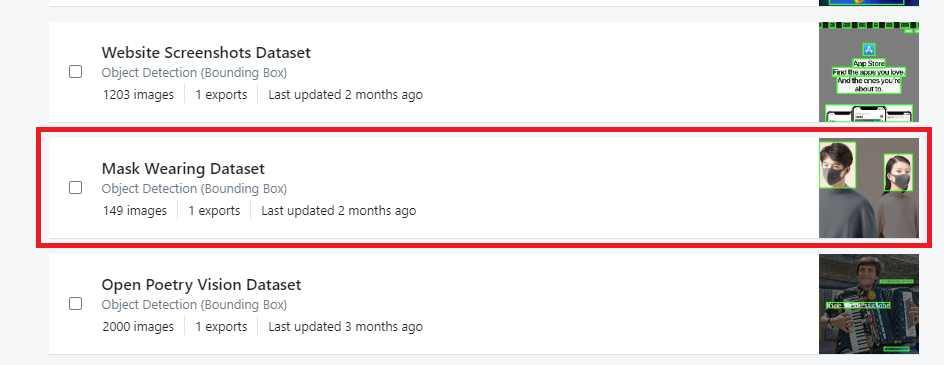
416x416-black-paddingをクリックします。
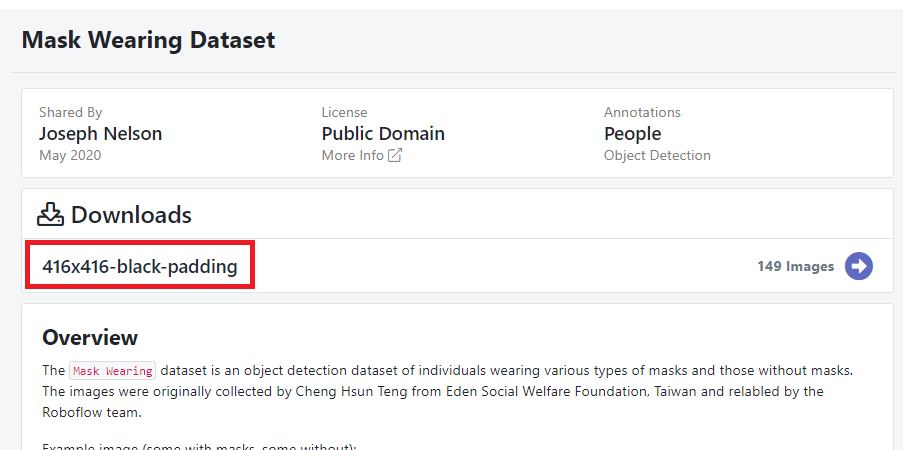
右上のダウンロードをクリックし、YOLOv5 Pytorchを選択、Continueをクリックしてダウンロードします。
※認証が必要だったかもしれません。忘れました。
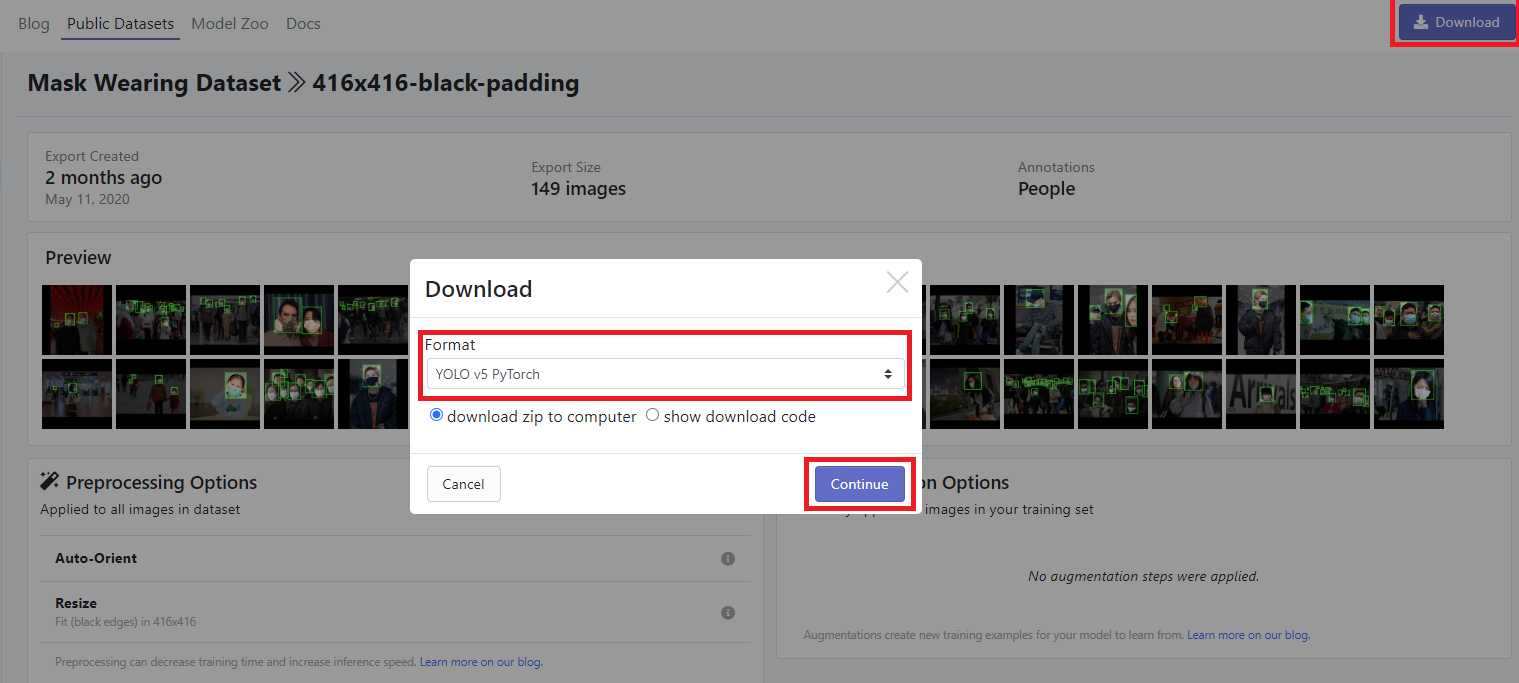
YOLOv5 Pytorchですぐ動かせる形式でダウンロードしてくれます。
2-2. COCOデータのpretrainedモデルのダウンロード
以下から一式ダウンロードしてください。
https://drive.google.com/drive/folders/1Drs_Aiu7xx6S-ix95f9kNsA6ueKRpN2J
COCOデータセットについては以下を参照してください。
COCOデータセット
2-3. コードのダウンロード
下記GitHubからYOLOv5.ipynbをダウンロードしてください。
https://github.com/yuomori0127/YOLOv5_mask_wearing_data
GoogleColabでコードを見てみたい方はコチラ
2-4. 環境準備
環境はGoogleColabを使用しました。
使用方法は以下の記事をご覧ください。サーバ代は無料です。
Google Colabの使い方まとめ
GooleDriveの任意のフォルダに以下3つを入れてください。
・2-1. でダウンロードしたデータ
・2-2. でダウンロードしたpretrainedモデル
・2-3. でダウンロードしたYOLOv5.ipynb
2-5. コード実行
GooleDriveからYOLOv5.ipynbをGoogleColabで開いてください。
※初回はインストールが必要だった気がします。
まずはGPUのリセマラが必要です。
一番上の!nvidia-smi を実行(Shift + Enter)し、Tesla P100が出るまでリセマラしてください。
大体5回以内で引けます。
リセットは以下からできます。
ランタイム->すべての処理を実行を実施すると全て実行してくれますが、
おそらくフォルダ名や階層が合わないです。
コードも短いですしそんなに大変ではないはずですので、なんとか合わせてください。すみません。
2-6. コード説明
短いので、一つ一つコードを説明します。
GPUを確認しています。
!nvidia-smi
インポート。
from IPython.display import Image, clear_output # to display images
GoogleDriveをマウントしています。
from google.colab import drive
drive.mount('/content/drive')
ディレクトリ移動
import os
os.chdir("./drive/My Drive/YOLOv5/")
リソースを確認しています。
主にRAMを確認するためですが、今回はデータも少ないですし100epochなのであまり気にしなくて良いです。
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install gputil
!pip install psutil
!pip install humanize
import psutil
import humanize
import os
import GPUtil as GPU
GPUs = GPU.getGPUs()
# XXX: only one GPU on Colab and isn’t guaranteed
gpu = GPUs[0]
def printm():
process = psutil.Process(os.getpid())
print("Gen RAM Free: " + humanize.naturalsize( psutil.virtual_memory().available ), " | Proc size: " + humanize.naturalsize( process.memory_info().rss))
print("GPU RAM Free: {0:.0f}MB | Used: {1:.0f}MB | Util {2:3.0f}% | Total {3:.0f}MB".format(gpu.memoryFree, gpu.memoryUsed, gpu.memoryUtil*100, gpu.memoryTotal))
printm()
yolov5をcloneしています。
!git clone https://github.com/ultralytics/yolov5
実行に必要なパッケージをインストールしています。
!pip install -r yolov5/requirements.txt
apexをインストールしています。学習が早くなります。
!git clone https://github.com/NVIDIA/apex
!pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./apex
tensorboardの準備。
# Start tensorboard
%load_ext tensorboard
%tensorboard --logdir runs
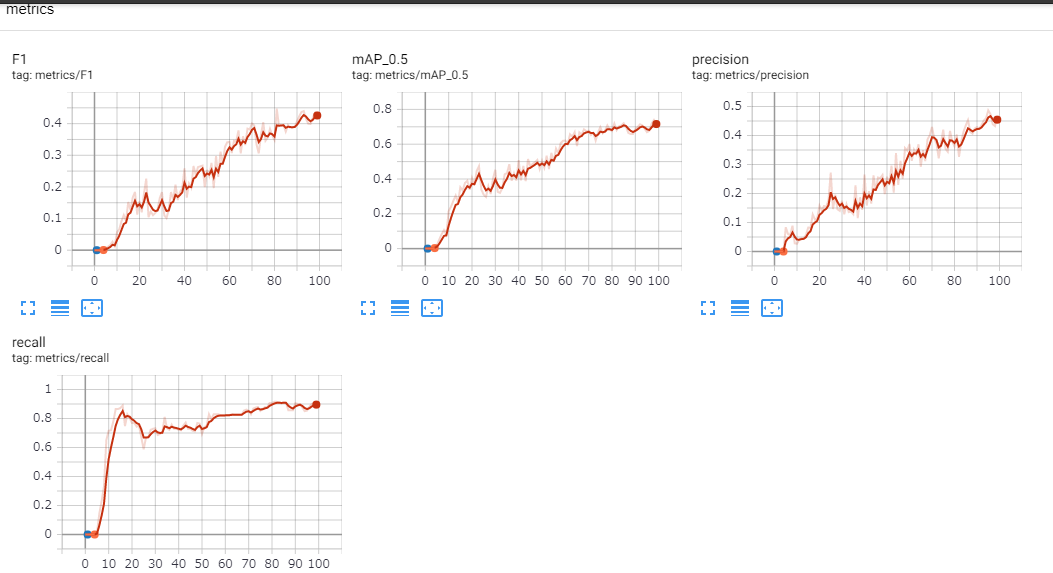
ちなみに、100epoch学習後はこんな感じでした。
100だと全然足りてないですね。(lossの画像取り忘れました。。)
学習します。引数についてはtrain.pyを見れば書いてあるのですが、ここでも簡単に説明します。
#--img:画像サイズ
#--batch:バッチサイズ
#--epochs:エポック数。
#--data:データ定義ファイル。データダウンロード時に自動的に作成されています。シンプルなので是非中身を見てみてください。
#--cfg:モデルの構成ファイル。
#--name:モデルファイル名。学習後のモデルで最も精度の高いものはbest_mask_wearing.ptという名前で保存されます。
#--weights:ファインチューニング元のモデル。今回はCOCOのpretrainedモデルを指定していますが、自分で学習したモデルも指定できます。
!python yolov5/train.py --img 416 --batch 16 --epochs 100 --data data/data.yaml --cfg yolov5/models/yolov5x.yaml --name mask_wearing --weights yolov5_models/yolov5x.pt
推論させています。
見栄えする良い感じの画像がテストデータになかったので、今回は学習データを推論させています。
!python yolov5/detect.py --weights weights/best_mask_wearing.pt --img 416 --conf 0.4 --source data/train/images/
Image(filename='/content/drive/My Drive/YOLOv5/inference/output/0_10725_jpg.rf.99ff78c82dadd6d49408164489cb6582.jpg', width=600)

3. 最後に
YOLOv5かなり使いやすかったです。
データを指定してtrain.py実行するだけで学習できてしまいます。
メジャーなData Augmentationは半自動で実施でき、パラメータも結構調整してあります。
もしかしたらkaggleのようなデータ分析者の腕の見せ所はどんどんなくなっていくのかもしれません。