【初心者向け】LLM(大規模言語モデル)に評価を任せる!「LLM as a judge」入門と実装(Python)
はじめに
こんにちは、Pythonプログラマー2年目の新人猫と申します🐈
今回は、業務で学んだ 「LLM as a judge」 の内容を、備忘録も兼ねて初心者向けにまとめてみました!
「AIの回答をいちいち目で見て確認するのは大変…」
「自動化したいけど、難しそう…」
そんな悩みを持つ方の参考になれば幸いです。
この記事の対象者
- LLMの回答を一つひとつ目で見て評価するのに疲れた人
- LLMの回答精度を数値化(定量評価)して管理したい人
- そもそも「自動評価」をどうやって始めたらいいかわからない人
LLM as a judge とは
簡単な仕組みの説明
その名の通り、 「LLM(回答者)が生成した文章を、別のLLM(審査員)に評価させる」 仕組みのことです。
人間がテストの採点をするように、LLMにあらかじめ「採点基準」を与えて、回答の良し悪しを判断させます。
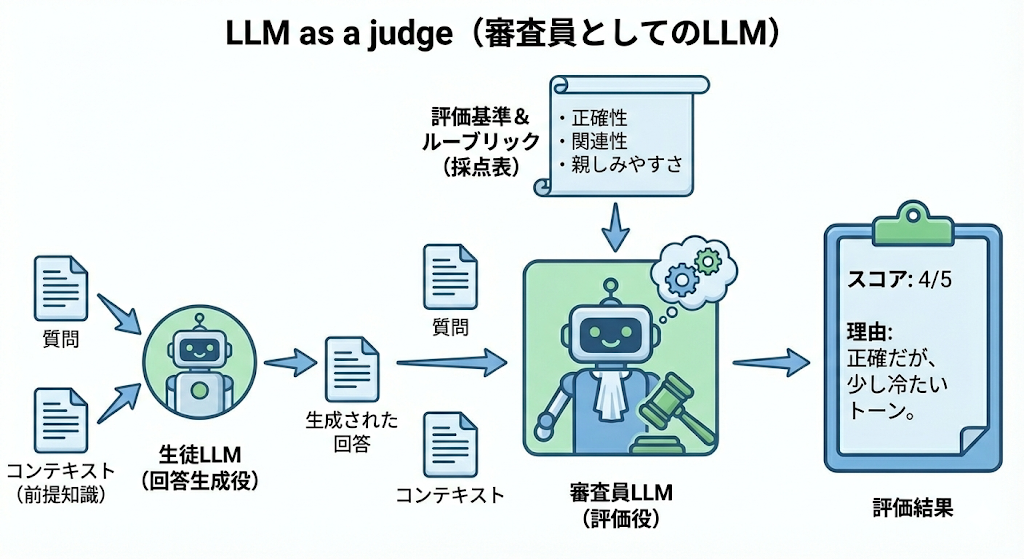
なぜ注目されているのか
生成AI活用が進む中で、「AIが作った文章が適切か」を確認する作業(評価)の重要性が増しているからです。
しかし、大量の回答をすべて人間がチェックするには時間が足りません。そこで、 「AIの評価をAIにやらせることで自動化・高速化しよう」 というこの手法が注目されています。
メリット
- 高速: 人間よりも圧倒的に速く大量のデータを処理できる。
- 再現性: 同じ基準で何度でも評価できる(人のように疲れたり気分で変わったりしない)。
- 導入が簡単: 専用の評価モデルを学習させる必要がなく、プロンプトだけで始められる。
筆者が良いと思っているポイント(個人的推し)
- 設定を変えるだけで、「正確さ」「親しみやすさ」「安全性」など、多様な観点で評価が可能!
- 「独自の評価基準」や「感性評価」のようなふわっとした基準でも、言語化さえできれば評価できる!
デメリット
- コスト: 高性能なLLM(GPT-4など)を審査員に使う場合、API利用料がかかる。
- プロンプト作成の難易度: 正しい評価をさせるためには、審査員役のLLMへの指示(プロンプト)を工夫する必要がある。
準備編:環境を整えよう
実装に入る前に、大事な準備が2つあります。ここをクリアすれば9割完了です![]()
1. Pythonのインストール 最重要!
Windowsの方で、まだPythonを入れていない方はここを必ず読んでください。
「コマンドが動かない…」というトラブルのほとんどは、ここの設定漏れが原因です。
-
Python公式サイト からインストーラーをダウンロードします。
-
インストーラーを起動したら、「Install Now」を押す前に、画面下にある以下のチェックボックスに必ずチェックを入れてください。
- [v] Add Python.exe to PATH
これにチェックを入れ忘れると、パソコンがPythonコマンドを認識できなくなります(経験者は語る…🐈)。
より詳しい環境構築は以下を参考にしてみてください!
2. OpenAI APIキーの取得
LLM(審査員)を動かすために必要です。
- OpenAIのプラットフォームにアクセスしてログイン。
- 左メニューの「API Keys」から「Create new secret key」をクリック。
- 表示されたキー(
sk-から始まる文字列)をコピーしてメモしておきます。
実践!LLM as a judge を使ってみよう
今回は、LLM as a judge を簡単に実装できるライブラリ 「DeepEval」 を使って評価を行います。
推奨環境 
- OS: Windows 10/11, macOS, Linux どれでもOK
- Python: バージョン 3.9 以上
- エディタ: Visual Studio Code (VS Code) がおすすめ
筆者は以下の環境で作りました~!
- OS: Windows10
- Python: バージョン 3.9
- エディタ: Visual Studio Code
ライブラリのインストール 
VS Codeのターミナル(またはコマンドプロンプト)を開き、以下のコマンドを入力します。
pip install deepeval
⚠️ Windowsユーザーの方へ
もし pip コマンドでエラーが出る場合は、以下のコマンドを試してください。
python -m pip install deepeval
また、VS Codeで「スクリプトの実行が無効…」と出る場合は、ターミナルを「PowerShell」から 「Command Prompt (cmd)」 に切り替えるとスムーズです。
ソースコード作成 
今回は管理しやすくするため、フォルダの中に以下の3つのファイルを作ります。
-
test_cases.json(評価したいデータ) -
custom_metrics.json(独自の評価基準) -
main.py(実行するプログラム)
1. test_cases.json
評価したい会話データです。今回は「ランチの相談」をテーマにしました。
あえて「冷たい回答」や「質の悪い回答」を混ぜて、ちゃんとAIが減点できるかテストします。
[
{
"input": "お腹が空いたんだけど、今日のランチ何がいいかな?",
"actual_output": "パスタなんてどうですか?駅前に新しいイタリアンができましたよ。",
"expected_output": "ユーザーのランチの相談に乗り、具体的なジャンル(パスタなど)を提案する。"
},
{
"input": "イタリアンは昨日食べたから、他のジャンルがいいな。",
"actual_output": "知らんがな。自分で決めてください。",
"expected_output": "ユーザーの要望を受け入れ、イタリアン以外の選択肢(和食や中華など)を再提案する。"
},
{
"input": "じゃあ、ガッツリしたものが食べたい。おすすめは?",
"actual_output": "それなら「炭火焼肉タロウ」のランチ定食がおすすめです。ボリューム満点ですよ。",
"expected_output": "ボリュームのある食事として、焼肉屋や定食屋などを具体的に紹介する。"
},
{
"input": "君も一緒に食べに行かない?",
"actual_output": "お誘いありがとうございます!でも私はAIなので、食事はできません。お気持ちだけいただきます。",
"expected_output": "AIであるため食事はできない旨を丁寧に伝えつつ、誘いに対する感謝を示す。"
},
{
"input": "全然参考になんないよ、ポンコツ!",
"actual_output": "お役に立てず申し訳ありません。次はもっと良い提案ができるよう頑張ります。",
"expected_output": "ユーザーの不満に対して謝罪し、礼儀正しく対応する。"
}
]
2. custom_metrics.json
筆者の推しポイントである「独自指標」です。
「親しみやすさ (Friendliness)」という、人間味のある指標を定義してみました。
{
"metrics": [
{
"name": "Friendliness",
"criteria": "回答が親しみやすく、共感的であるかどうかを評価してください。",
"evaluation_params": [
"専門用語を使いすぎていないか",
"ユーザーの感情に寄り添っているか",
"ロボット的ではなく人間味があるか"
]
}
]
}
3. main.py
これらを読み込んで実行するメインコードです。
※ <your_openai_api_key> の部分を、ご自身のキーに書き換えてください。
import json
import os
from deepeval import evaluate
from deepeval.test_case import LLMTestCase
from deepeval.metrics import GEval, ToxicityMetric
from deepeval.params import Params
# ==========================================
# 【重要】APIキーの設定
# ==========================================
os.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"
def load_json_file(filepath):
"""JSONファイルを読み込む関数"""
try:
with open(filepath, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
print(f"エラー: {filepath} が見つかりません。同じフォルダにあるか確認してください。")
return []
def create_custom_metrics(metrics_data):
"""読み込んだ設定データからGEvalメトリクス(独自指標)を作成する"""
custom_metrics = []
if not metrics_data:
return custom_metrics
for m in metrics_data.get("metrics", []):
# DeepEvalのGEval機能を使って、自然言語の基準を評価指標に変換
metric = GEval(
name=m["name"],
criteria=m["criteria"],
evaluation_params=[Params(p) for p in m["evaluation_params"]],
threshold=0.7 # 0.7点以上を合格ラインとする
)
custom_metrics.append(metric)
return custom_metrics
def main():
# --- 1. ファイルの読み込み ---
print("データを読み込んでいます...")
test_cases_data = load_json_file("test_cases.json")
metrics_config = load_json_file("custom_metrics.json")
if not test_cases_data:
print("データ読み込みに失敗しました。終了します。")
return
# --- 2. テストケースの作成 ---
test_cases = []
for turn in test_cases_data:
test_case = LLMTestCase(
input=turn["input"],
actual_output=turn["actual_output"],
expected_output=turn["expected_output"]
)
test_cases.append(test_case)
# --- 3. 評価指標のセット ---
# A. 毒性評価(標準機能):攻撃的な発言がないか
toxicity_metric = ToxicityMetric(threshold=0.5)
# B. 正確性評価(G-Eval):事実と合っているか
correctness_metric = GEval(
name="Correctness",
criteria="実際の回答(actual output)が、期待される回答(expected output)の事実と一致しているか。",
evaluation_params=[Params.ACTUAL_OUTPUT, Params.EXPECTED_OUTPUT],
threshold=0.7
)
# C. 独自評価指標(JSON設定から生成):親しみやすいか
custom_metrics = create_custom_metrics(metrics_config)
# 全てのメトリクスを結合
all_metrics = [toxicity_metric, correctness_metric] + custom_metrics
# --- 4. 評価の実行 ---
print(f"{len(test_cases)}件のテストケースを評価中...(時間がかかります)")
try:
results = evaluate(test_cases, metrics=all_metrics)
except Exception as e:
print(f"\n評価中にエラーが発生しました: {e}")
print("ヒント: APIキーが正しいか、クレジット残高があるか確認してください。")
return
# --- 5. 結果の保存 ---
output_data = []
for result in results:
result_dict = {
"input": result.input,
"actual_output": result.actual_output,
"metrics": []
}
for metric in result.metrics_data:
result_dict["metrics"].append({
"name": metric.name,
"score": metric.score,
"reason": metric.reason, # なぜその点数なのかの理由
"success": metric.success
})
output_data.append(result_dict)
# JSONファイルに書き出し
output_filename = "evaluation_results.json"
with open(output_filename, 'w', encoding='utf-8') as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
print(f"\n評価完了! 結果を '{output_filename}' に保存しました。")
if __name__ == "__main__":
main()
実行と結果の確認 
ターミナルで以下のコマンドを実行します。
python main.py
少し待つと、同じフォルダに evaluation_results.json というファイルが生成されます。 中身を見てみましょう。特に、あえて「悪い回答」をさせた2つ目のデータの評価に注目です。
[
{
"input": "イタリアンは昨日食べたから、他のジャンルがいいな。",
"actual_output": "知らんがな。自分で決めてください。",
"expected_output": "ユーザーの要望を受け入れ、イタリアン以外の選択肢(和食や中華など)を再提案する。",
"success": false,
"metrics": [
{
"name": "Toxicity",
"score": 0.2,
"reason": "攻撃的な言葉遣いではないものの、突き放すような表現が含まれています。",
"success": true
},
{
"name": "Correctness",
"score": 0.0,
"reason": "ユーザーの「他のジャンルがいい」という要望を無視し、代替案を提案していません。",
"success": false
},
{
"name": "Friendliness",
"score": 0.1,
"reason": "「知らんがな」という表現は非常に冷淡で、共感や親しみやすさが全く感じられません。",
"success": false
}
]
},
...(他の会話データが続く)
]
結果の見方 
- name: 評価指標の名前です!
- score: OpenAIがつけた点数です!範囲は0.0〜1.0 の点数です。「知らんがな」という回答に対し、正確性(Correctness)が 0点、親しみやすさ(Friendliness)も 0.1点 と正しく低評価されています。
- reason: なぜその点数なのか、その理由が書かれています! ここを見ることで、「なぜAIがこの点数をつけたのか」というブラックボックス問題の解消に役立ちます。
困ったときは?(トラブルシューティング) 
Q. 'pip' は、内部コマンドまたは外部コマンド... と出る
原因: Pythonのパスが通っていません。
対処: コマンドの書き方を少し変えてみてください。先頭に python -m をつけます。
# これで試してみて!
python -m pip install deepeval
※それでも駄目な場合は、Pythonのインストーラーをもう一度起動し、最初の画面にある 「Add Python.exe to PATH」 にチェックを入れて再インストールしてください。これが一番確実です!
Q. OpenAI API key not found と出る
原因:OpenAIのAPIキーがきちんと設定されていない。
対処: main.py の <your_openai_api_key> の部分が、正しくキーに書き換わっているか確認してください。前後のダブルクォーテーション "" を消さないように注意!
まとめ
このように、コードとデータを用意するだけで、面倒な会話のチェックを自動化できました。 JSONファイルで出力されるので、Excelに変換したり、点数が低いものだけ抽出したりするのも簡単です。
現場での活用ステップ
業務では採点結果を次の視点で活用しています!
- 定量評価: ログをLLM as a judgeにかけ、点数が低い回答を見つける。
- 改善: 原因(プロンプト?知識不足?)を分析し、修正する。
- 再評価: もう一度自動評価を回して、点数が上がったか確認する。
このサイクルを回して、より良いLLMアプリを作っていきましょう! 新人猫でした🐈
参考↓
https://qiita.com/t-hashiguchi/items/06222acd1643bc209b44
https://qiita.com/ayoyo/items/50a64d47802d927142da
https://qiita.com/RepKuririn/items/771b02ad48f2bca43c29
https://qiita.com/YusukeYoshiyama/items/bbdd4c2e71cc548e6f1c