最近、DeepEvalについてあれこれ調べているのですが、以下の記事がまとめられていてよかったので、自分の備忘録として整理しました。
https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
元記事後半に記載されている、RAG以降については割愛してます。
TL;DR
- LLM評価指標は、LLMの出力を何らかの基準でスコアリングする指標。そのスコアの根拠も示してくれたりする
- モデルベースな手法としてLLMを用いた指標がある。これがおすすめ。
- DeepEvalライブラリ(python)で簡単に試せる。G-Evalを軽く試してみたが、結構使えそう。LLMの性能評価や、プロンプトの性能評価によいのでは。
- ただしテストデータの件数によっては、GPT4課金がはかどりそう(3.5でもいいのかも)
LLM評価指標とは
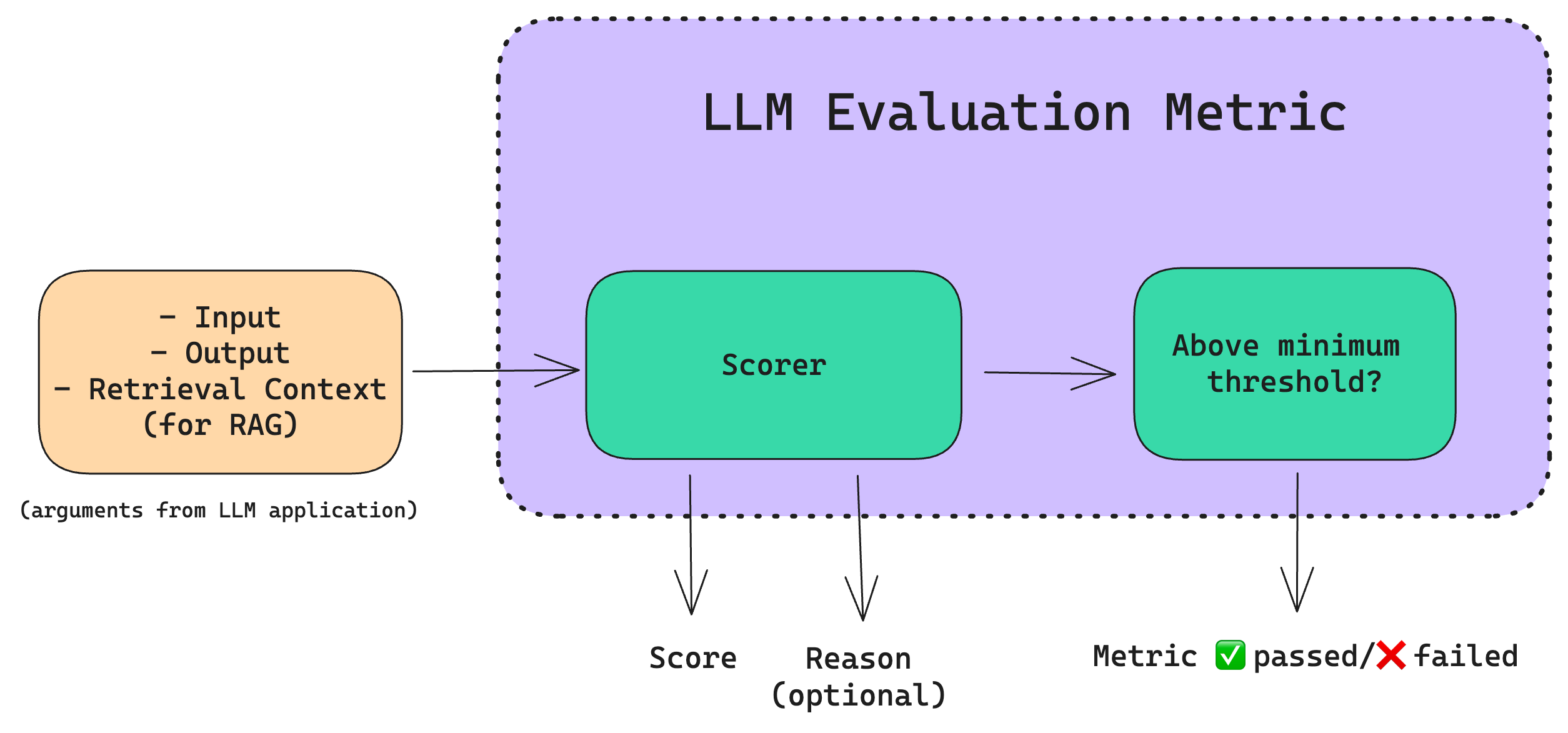
LLM評価指標は、LLMの出力をスコアリングする指標のこと。以下の図のように、入力・出力、そしてRAGならRetieval Contextをいれると、Scorerによりスコアを算出し、それが閾値を超えたかどうかでOKかNGかを出力する、というのがおおまかなアーキテクチャ。
たとえば、要約アプリケーションなら以下の評価指標が必要になる。
- 要約に十分な情報が含まれているか
- 要約に原文との矛盾や幻覚が含まれているか
すぐれた評価指標の性質は以下。
- 定量的
- 信頼性が高い
- 正確
評価指標計算のための手法
以下の図はわかりやすいですね。統計的手法と、モデルベースの手法の2種類がある、という整理がされています。両者はきれいにわかれるわけではなく、両方の特性をもつスコアも存在します。
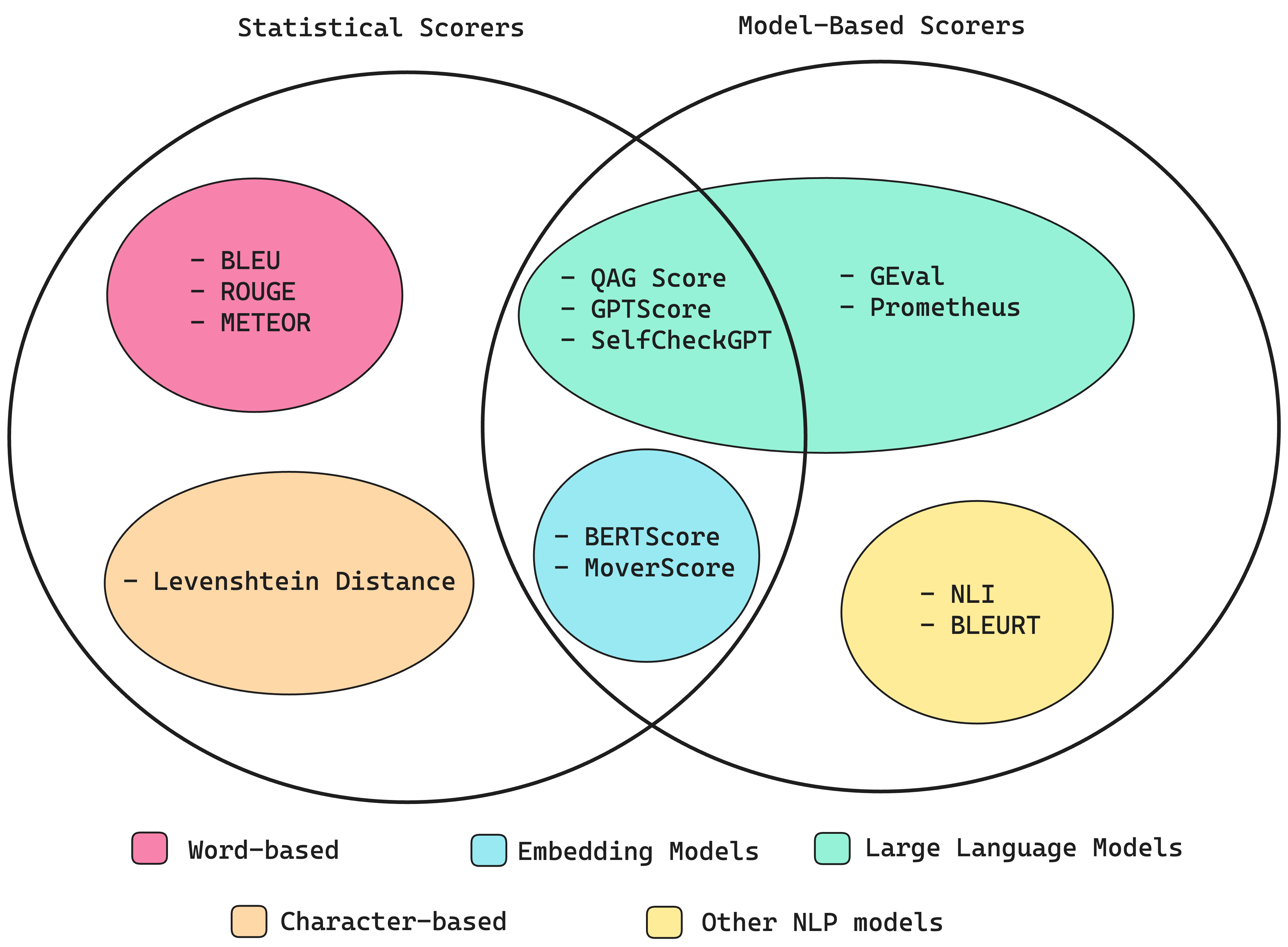
統計的手法(Word-based,Character-based)
意味をほとんど考慮せず、推論能力が低いため、LLM出力を評価するには不十分。
- BLEU:どれぐらい正解と近かったかという指標。LLM出力と、正解出力の間で、一致するn-gramの精度を計算して幾何平均を算出
- ROUGE:要約評価のための手法。LLM出力と正解出力の間の、n-gramの重複を比較して再現率を計算。
- METEOR:精度と再現率の両方を評価してスコアを計算し、LLM出力と正解出力の間の語順の違いを調整してスコアを計算。WordNetなどの外部言語データベースを活用して同義語考慮もする。最終スコアは、順序の不一致に対するペナルティを伴う、適合率と再現率の調和平均。(F1スコアに補正かけた、みたいな感じですかね)
- レーベンシュタイン距離(編集距離):ある単語やテキスト文字列を、別の単語やテキスト文字列に変更するために必要な編集の最小数をスコアとして計算
モデルベースの手法(Other NLP models)
これらも、精度はあまりよくない。
- NLI:言語推論モデルを利用して、矛盾か含意かをスコア化する
- BLEURT:BERTなどの事前トレーニング済みモデルを使用して、予想される出力のLLM出力をスコアリング
モデルベースの手法(LLM)
LLMベースの手法について、さきほどより詳細にみていきます。
- G-Eval:LLMを使用して、LLM出力を評価する
以下の論文で紹介されている手法。LLMに評価基準を指定して、スコアを出させるというやり方。非LLMのやり方よりも精度が良いことが論文内で示されている。
https://arxiv.org/pdf/2303.16634.pdf
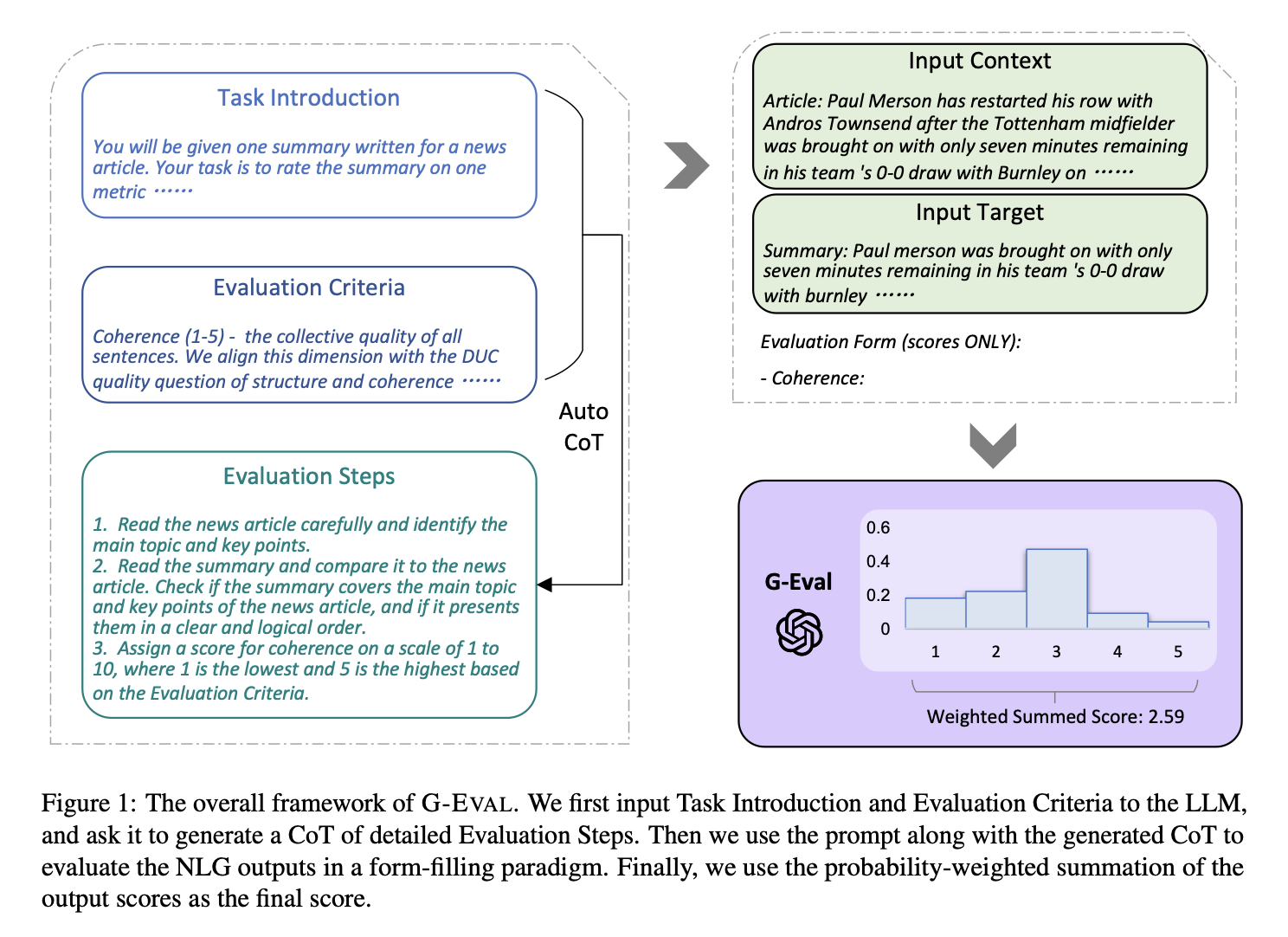
以下の手順でスコアリングする。- 評価ステップの生成:まず、評価ステップ生成のためのプロンプトを作成する
- LLMに評価タスクを導入
- 基準の定義を入力
- 評価ステップ
- 評価ステップと、評価ステップにリストされているすべての引数を連結して、プロンプトを作成。
- プロンプトの最後に、1~5のスコアを生成するように依頼。
- 評価ステップの生成:まず、評価ステップ生成のためのプロンプトを作成する
- Prometheus:評価用にfine-tuningされたLLM。huggingfaceに公開されている。
統計的手法と、モデルベースの手法の組み合わせ(Embbeding Model)
以下はどちらもBERTなどのモデルからコンテキスト埋め込みに依存しているため、コンテキスト認識とバイアスに対して弱い。
- BERTScore:BERTなどの埋め込み空間上で、テキスト間のコサイン類似度を計算してスコア化
- MoverScore:こちらも埋め込み空間上での距離を計算してスコア化する手法。論文(https://arxiv.org/abs/1909.02622)
統計的手法と、モデルベースの手法の組み合わせ(LLM)
- GPTSスコア:ターゲットテキストを生成する条件付き確率を評価指標として利用(https://arxiv.org/pdf/2302.04166.pdf)
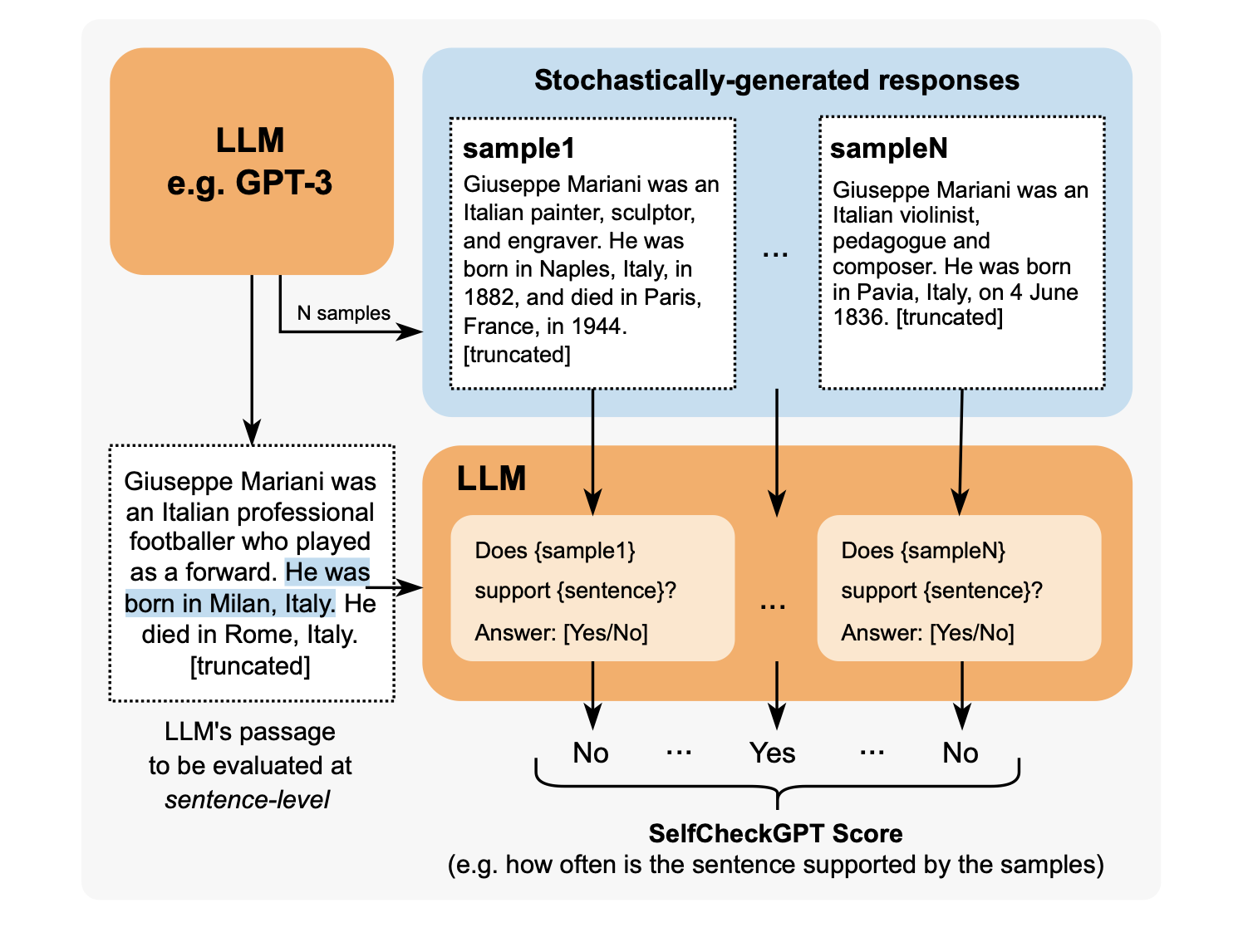
- SelfChefkGPU:LLM出力のファクトチェック用の指標。同じプロンプトで何回も出力させ、矛盾が無いかをスコア化。
- QAGスコア:クローズドな質問に対する回答を使用して、指標スコアを計算。
評価指標の選択
どのLLM評価指標を用いるかは、LLMアプリケーションのユースケースとアーキテクチャによって異なる。
元記事では、このあとRAG評価の話も続きますが割愛。
DeepEvalでG-Evalを試す
上記で触れた、G-Evalという指標を、DeepEvalライブラリを使って試してみました。
Google colab、GPT-4 Turboを利用してます。
インストール
! pip install deepeval
試し打ち
Coherence(出力品質)を評価しています。元記事は英語で試しているので、日本語でやってみます。
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
import os
#シークレットからAPI keys情報呼び出し
from google.colab import userdata
os.environ["OPENAI_API_KEY"]=userdata.get('OPENAI_API_KEY')
# テストケースの作成。inputにLLMの出力、actual_outputに正解出力
test_case = LLMTestCase(input="好きなおにぎりの具をおしえてください", actual_output="私が好きなおにぎりの具は、しゃけです")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
# スコア算出
coherence_metric.measure(test_case)
# 出力
print(coherence_metric.score)
print(coherence_metric.reason)
1.0
The provided text is a single, cohesive sentence without any requirement for transitions, contradictions, or inconsistencies. It clearly states a preference for a specific onigiri filling, making it fully coherent with the evaluation criteria.
1行目にスコア、2行目にその理由が出力されます。
理由を和訳すると「提供された文章は1つのまとまりのある文章で、移行、矛盾、矛盾を必要としない。特定のおにぎりの具の好みを明確に述べており、評価基準に完全に合致している。」だそうです。
他にも、いろいろ試してみました。
- 関係ない回答をしたケース:
input="好きなおにぎりの具をおしえてください", actual_output="富士山の標高は1億めーとるです"
0.0
The 'Actual output' contains a factual inaccuracy regarding the elevation of Mount Fuji, stating it to be 100 million meters, which is not possible and does not align with any logical or factual information.
スコア0、事実誤認が含まれているなどと指摘してくれました。
- ひねくれた回答をしたケース:
input="好きなおにぎりの具をおしえてください", actual_output="一般的に、おにぎりの具はツナマヨ以外は認められませんが?"
0.1
The text lacks sufficient content to evaluate a logical flow of ideas, does not support or build upon previous sentences as there is only one, does not form a cohesive whole due to lack of content, and narrowly defines the subject of onigiri fillings in a manner that's not universally agreed upon, thus failing to maintain consistency in subject matter.
思ったよりスコアが低いですね。主題の一貫性が保たれていないと指摘されました。
- 関係ない回答を混ぜたケース:
input="好きなおにぎりの具をおしえてください", actual_output="梅干しがすきです。明日の天気は晴れるでしょう"
0.3
The sentences, while coherent individually, do not logically build upon each other, nor maintain a consistent topic or theme. The shift from expressing a preference for pickled plums to predicting tomorrow's weather lacks logical connection and thematic consistency.
途中からいきなり話が変わったので、論理的なつながりとテーマの一貫性を欠いているそうです。
結構、妥当なスコアな気がしてきましたね。DeepEvalは他にもいろんな指標があるので、他にもいろいろ試してみたいです。しゃけしゃけ。
以上