0. はじめに
0-0. はじめに
以前、「Rails における内部結合、外部結合まとめ」という記事を書いたのですが、GROUP BYに関しては触れなかったなと思い、実務で割と使用していて毎回少しずつ悩むので、自分の備忘録の意味も込めて記載します。
0-1. RubyとRailsとPostgreSQLのバージョン
$ ruby -v
ruby 2.4.1p111 (2017-03-22 revision 58053) [x86_64-darwin16]
$ rails -v
Rails 5.1.2
=> SELECT version();
version
--------------------------------------------------------------------------------------------------------------
PostgreSQL 9.5.3 on x86_64-apple-darwin15.4.0, compiled by Apple LLVM version 7.3.0 (clang-703.0.31), 64-bit
0-2. 今回扱うERD
| ERD | 説明 |
|---|---|
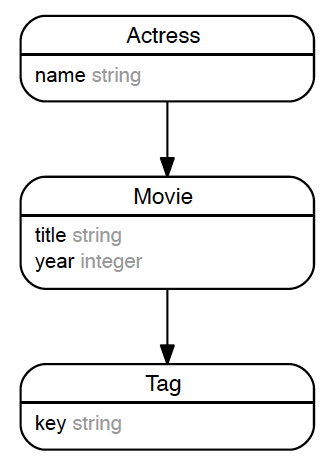 |
女優テーブルがある。 女優テーブルは映画テーブルを持つ。 映画テーブルは、映画に関連するキーワードを入れたタグテーブルを持つ。 |
0-3. モデル
Actress
class Actress < ApplicationRecord
has_many :movies
has_many :tags, through: :movies
end
Movie
class Movie < ApplicationRecord
has_many :tags
belongs_to :actress
end
Tag
class Tag < ApplicationRecord
belongs_to :movie
end
0-4. 今回扱うデータ
actress
SELECT id, name FROM actresses;
id | name
----+------------
1 | 多部未華子
2 | 佐津川愛美
3 | 新垣結衣
4 | 堀北真希
5 | 吉高由里子
6 | 悠城早矢
movies
SELECT id, actress_id, title, year FROM movies;
id | actress_id | title | year
----+------------+---------------------+------
1 | 2 | 蝉しぐれ | 2005
2 | 1 | 夜のピクニック | 2006
3 | 4 | ALWAYS 三丁目の夕日 | 2005
4 | 2 | 忍道-SHINOBIDO- | 2012
5 | 2 | 貞子vs伽椰子 | 2016
6 | 4 | 県庁おもてなし課 | 2013
7 | 5 | 真夏の方程式 | 2013
tags
SELECT id, movie_id, key FROM tags;
id | movie_id | key
----+----------+------------
1 | 1 | 時代劇
2 | 1 | 子役
3 | 3 | 昭和
4 | 5 | ホラー
5 | 7 | ミステリー
6 | 7 | 夏
7 | 6 | 公務員
8 | 6 | 地方活性
9 | 1 | 夏
10 | 4 | 時代劇
# 前回のレコードにid: 10のレコードが追加されています。
1. テーブルが1つの場合
1-1. 各女優の映画数を知りたい(idで表示)
Movie.group(:actress_id).count
=> {4=>2, 1=>1, 5=>1, 2=>3}
SELECT
COUNT(*) AS count_all,
"movies"."actress_id" AS movies_actress_id
FROM
"movies"
GROUP BY
"movies"."actress_id"
これだとacctress_idで出てくるので、分かりにくい。そこで、acctressesテーブルを結合して表示させる。
2. テーブルが2つに跨ぐ場合
2-1. 各女優の映画数を知りたい(名前で表示)(JOINする方法)
Movie.joins(:actress).group("actresses.name").count
=> {"多部未華子"=>1, "佐津川愛美"=>3, "堀北真希"=>2, "吉高由里子"=>1}
SELECT
COUNT(*) AS count_all,
actresses.name AS actresses_name
FROM
"movies"
INNER JOIN
"actresses"
ON
"actresses"."id" = "movies"."actress_id"
GROUP BY
actresses.name
2-2. 各女優の映画数を知りたい(名前で表示)(JOINしない方法)
- 名前の表示の必要がなければ、moviesテーブルのactress_idで
GROUP BYすればいいので、前述のようにMovie.group(:actress_id).countとすればよい。ここでactress_idがとれるので、それを事前読み込みするという方法もある。 - n+1を考慮しない場合
Movie.group(:actress_id).select("actress_id, count(movies.id) as movie_count").map { |m| [m.actress.name, m.movie_count] }.to_h
# =>
Movie Load (0.5ms) SELECT actress_id, count(movies.id) as movie_count FROM "movies" GROUP BY "movies"."actress_id"
Actress Load (0.4ms) SELECT "actresses".* FROM "actresses" WHERE "actresses"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]]
Actress Load (0.4ms) SELECT "actresses".* FROM "actresses" WHERE "actresses"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]]
Actress Load (0.4ms) SELECT "actresses".* FROM "actresses" WHERE "actresses"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]]
Actress Load (0.4ms) SELECT "actresses".* FROM "actresses" WHERE "actresses"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]]
=> {"吉高由里子"=>1, "堀北真希"=>2, "佐津川愛美"=>3, "多部未華子"=>1}
- n+1を考慮する場合
- preloadやincludesを利用する。
Movie.group(:actress_id).select("actress_id, count(movies.id) as movie_count").preload(:actress).map { |m| [m.actress.name, m.movie_count] }.to_h
=> {"吉高由里子"=>1, "堀北真希"=>2, "佐津川愛美"=>3, "多部未華子"=>1}
Movie.group(:actress_id).select("actress_id, count(movies.id) as movie_count").includes(:actress).map { |m| [m.actress.name, m.movie_count] }.to_h
# =>
Movie Load (0.5ms) SELECT actress_id, count(movies.id) as movie_count FROM "movies" GROUP BY "movies"."actress_id"
Actress Load (0.4ms) SELECT "actresses".* FROM "actresses" WHERE "actresses"."id" IN (5, 4, 2, 1)
=> {"吉高由里子"=>1, "堀北真希"=>2, "佐津川愛美"=>3, "多部未華子"=>1}
- ここで、preloadではなくeager_loadをつかうと外部結合をしてしまい、エラーになる。(PostgreSQLで検証。他は不明)
- 挙動をいちいち覚えておけないので、
GROUP BYしてダメならpreloadやincludesを用いると覚えておけば良さそう。
- 挙動をいちいち覚えておけないので、
Movie.group(:actress_id).select("actress_id, count(movies.id) as movie_count").eager_load(:actress).map { |m| [m.actress.name, m.movie_count] }.to_h
# =>
ActiveRecord::StatementInvalid: PG::GroupingError: ERROR: column "movies.id" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: ...LECT actress_id, count(movies.id) as movie_count, "movies"."...
2-3. 数が多い順に並び替える
2-3-1. 返り値がHashで良い場合
- 発行されたSQLを見るとわかるが、Railsが
COUNT(*)にcount_allという名前をつけているのでこれでORDER BYする。
Movie.joins(:actress).group("actresses.name").order("count_all DESC").count
=> {"佐津川愛美"=>3, "堀北真希"=>2, "多部未華子"=>1, "吉高由里子"=>1}
SELECT
COUNT(*) AS count_all,
actresses.name AS actresses_name
FROM
"movies"
INNER JOIN
"actresses"
ON
"actresses"."id" = "movies"."actress_id"
GROUP BY
actresses.name
ORDER BY
count_all DESC
Movie.group(:actress_id).select("actress_id, count(movies.id) as movie_count").order("movie_count desc").preload(:actress).map { |m| [m.actress.name, m.movie_count] }.to_h
# =>
Movie Load (0.5ms) SELECT actress_id, count(movies.id) as movie_count FROM "movies" GROUP BY "movies"."actress_id" ORDER BY movie_count desc
Actress Load (0.4ms) SELECT "actresses".* FROM "actresses" WHERE "actresses"."id" IN (2, 4, 5, 1)
=> {"佐津川愛美"=>3, "堀北真希"=>2, "吉高由里子"=>1, "多部未華子"=>1}
2-3-2. 返り値をActiveRecord_Relationにしたい場合
- moviesでjoinして、
count(actresses.id) descなどをorderに指定する。 - Rails6.0からは、orderの中にSQLを直書きしてはいけないので、
Arel.sqlで囲む。
Actress.joins(:movies).group('actresses.id').order(Arel.sql('count(actresses.id) desc'))
# => [#<Actress:0x007f89619a7878
id: 2,
name: "佐津川愛美",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>,
#<Actress:0x007f89619a7738
id: 4,
name: "堀北真希",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>,
#<Actress:0x007f89619a75a8
id: 5,
name: "吉高由里子",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>,
#<Actress:0x007f89619a7468
id: 1,
name: "多部未華子",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>]
SQL
SELECT
"actresses".*
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
GROUP BY
actresses.id
ORDER BY
count(actresses.id) desc
3. テーブルが3つに跨ぐ場合
3-1. 各女優のタグ数を知りたい
- 二つ先のテーブルなので、moviesを経由して結合する。
Actress.joins(movies: :tags).group("actresses.name").count
=> {"佐津川愛美"=>5, "堀北真希"=>3, "吉高由里子"=>2}
SQL
SELECT
COUNT(*) AS count_all,
actresses.name AS actresses_name
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
GROUP BY
actresses.name
- 今回の場合、以下のようにActressモデルに
throughオプションをつけているのでmoviesを明示しなくても動く。
actress.rb
has_many :tags, through: :movies
Actress.joins(:tags).group("actresses.name").count
=> {"佐津川愛美"=>5, "堀北真希"=>3, "吉高由里子"=>2}
3-2. 各女優の各タグごとの数を知りたい
- 例えば、佐津川愛美には「ホラー」「夏」「子役」「時代劇」というタグがつけられているが、それぞれ何個あるかを知りたいという場合。
-
actresses.nameでGROUP BYしてからtags.keyでGROUP BYを行えば良い。(軸をactresses.name)
Actress.joins(:tags).group("actresses.name").group("tags.key").count
=> {["堀北真希", "地方活性"]=>1,
["佐津川愛美", "子役"]=>1,
["佐津川愛美", "夏"]=>1,
["佐津川愛美", "ホラー"]=>1,
["吉高由里子", "ミステリー"]=>1,
["堀北真希", "昭和"]=>1,
["堀北真希", "公務員"]=>1,
["佐津川愛美", "時代劇"]=>2,
["吉高由里子", "夏"]=>1}
SELECT
COUNT(*) AS count_all,
actresses.name AS actresses_name,
tags.key AS tags_key
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
GROUP BY
actresses.name, tags.key
- 返り値を見ると、同じ女優でもまとまっていなくて見にくいので
ORDER BY句をつけておくと良い。
Actress.joins(:tags).group("actresses.name").group("tags.key").order("actresses.name").count
=> {["堀北真希", "昭和"]=>1,
["堀北真希", "公務員"]=>1,
["堀北真希", "地方活性"]=>1,
["佐津川愛美", "夏"]=>1,
["佐津川愛美", "子役"]=>1,
["佐津川愛美", "ホラー"]=>1,
["佐津川愛美", "時代劇"]=>2,
["吉高由里子", "夏"]=>1,
["吉高由里子", "ミステリー"]=>1}
SELECT
COUNT(*) AS count_all,
actresses.name AS actresses_name,
tags.key AS tags_key
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
GROUP BY
actresses.name, tags.key
ORDER BY
actresses.name
- 各女優の中で、タグの数が多い順で並び替えたい場合
Actress.joins(:tags).group("actresses.name").group("tags.key").order("actresses.name, count_all DESC").count
=> {["堀北真希", "地方活性"]=>1,
["堀北真希", "昭和"]=>1,
["堀北真希", "公務員"]=>1,
["佐津川愛美", "時代劇"]=>2,
["佐津川愛美", "ホラー"]=>1,
["佐津川愛美", "夏"]=>1,
["佐津川愛美", "子役"]=>1,
["吉高由里子", "夏"]=>1,
["吉高由里子", "ミステリー"]=>1}
タグ数の多い女優から順に表示させたい場合
- 佐津川愛美のタグ数が5、堀北真希が3、吉高由里子が2なので、この順に表示させたい。
- 何かいい方法がないかと考えたが、思いつかなかったので、あらかじめタグ数で
ORDER BYしてから行うという方法をとってみた。 - SQLで一発で書く方法教えてください。
- 何かいい方法がないかと考えたが、思いつかなかったので、あらかじめタグ数で
# Lambdaにしたのは、遅延評価したかったため。実用的には変数に格納してしまえば良い。
ordered_actress_ids = -> {
Actress.joins(:tags).group("actresses.id").order("count_all DESC").count.keys.map.with_index { |id, i| "WHEN #{id} THEN #{i} " }.join.strip
}
Actress.joins(:tags).group("actresses.id, actresses.name").group("tags.key").order("CASE actresses.id #{ordered_actress_ids.call} END").order("actresses.name, count_all DESC").count
=> {["佐津川愛美", "時代劇"]=>2,
["佐津川愛美", "ホラー"]=>1,
["佐津川愛美", "夏"]=>1,
["佐津川愛美", "子役"]=>1,
["堀北真希", "公務員"]=>1,
["堀北真希", "地方活性"]=>1,
["堀北真希", "昭和"]=>1,
["吉高由里子", "夏"]=>1,
["吉高由里子", "ミステリー"]=>1}
SELECT
COUNT(*) AS count_all,
actresses.id AS actresses_id
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
GROUP BY
actresses.id
ORDER BY
count_all DESC
SELECT
COUNT(*) AS count_all,
actresses.id,
actresses.name AS actresses_id_actresses_name,
tags.key AS tags_key
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
GROUP BY
actresses.id, actresses.name, tags.key
ORDER BY CASE
actresses.id WHEN 2 THEN 0 WHEN 4 THEN 1 WHEN 5 THEN 2 END
, actresses.name, count_all DESC
その他(GROUP BYとは関係ないものも含む)
サブクエリ関係は、ActiveRecordでサブクエリ(副問い合わせ)と内部結合に移動。