0. はじめに
0-0. はじめに
以前、「Rails における内部結合、外部結合まとめ」や「ActiveRecordにおけるGROUP BYの使い方」という記事を書いたのですが、サブクエリに関して、特にサブクエリと結合するときにActiveRecordでどう記述すればいいのか逡巡したときがあったので、備忘録的に記述します。
また、Otemachi.rb#7にて、「いまさらサブクエリ」というタイトルでLTも行ったので、こちらも参考になるかもしれません。
0-1. RubyとRailsとPostgreSQLのバージョン
$ ruby -v
ruby 2.4.1p111 (2017-03-22 revision 58053) [x86_64-darwin16]
$ rails -v
Rails 5.2.0
=> SELECT version();
version
--------------------------------------------------------------------------------------------------------------
PostgreSQL 9.5.3 on x86_64-apple-darwin15.4.0, compiled by Apple LLVM version 7.3.0 (clang-703.0.31), 64-bit
0-2. 今回扱うERD
| ERD | 説明 |
|---|---|
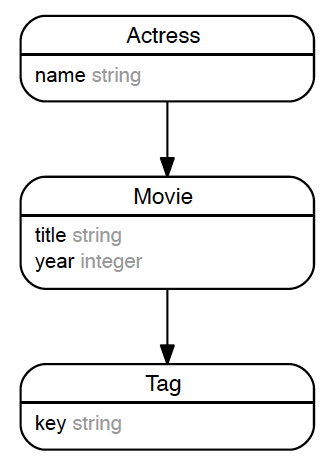 |
女優テーブルがある。 女優テーブルは映画テーブルを持つ。 映画テーブルは、映画に関連するキーワードを入れたタグテーブルを持つ。 |
0-3. モデル
class Actress < ApplicationRecord
has_many :movies
has_many :tags, through: :movies
end
class Movie < ApplicationRecord
has_many :tags
belongs_to :actress
end
class Tag < ApplicationRecord
belongs_to :movie
end
0-4. 今回扱うデータ
SELECT id, name FROM actresses;
id | name
----+------------
1 | 多部未華子
2 | 佐津川愛美
3 | 新垣結衣
4 | 堀北真希
5 | 吉高由里子
6 | 悠城早矢
SELECT id, actress_id, title, year FROM movies;
id | actress_id | title | year
----+------------+---------------------+------
1 | 2 | 蝉しぐれ | 2005
2 | 1 | 夜のピクニック | 2006
3 | 4 | ALWAYS 三丁目の夕日 | 2005
4 | 2 | 忍道-SHINOBIDO- | 2012
5 | 2 | 貞子vs伽椰子 | 2016
6 | 4 | 県庁おもてなし課 | 2013
7 | 5 | 真夏の方程式 | 2013
SELECT id, movie_id, key FROM tags;
id | movie_id | key
----+----------+------------
1 | 1 | 時代劇
2 | 1 | 子役
3 | 3 | 昭和
4 | 5 | ホラー
5 | 7 | ミステリー
6 | 7 | 夏
7 | 6 | 公務員
8 | 6 | 地方活性
9 | 1 | 夏
10 | 4 | 時代劇
1. where句にサブクエリを用いる
タグのある女優だけを取り出したい
(方法1・内部結合)INNER JOINしてDISTINCTをする
Actress.joins(:tags).distinct
=> [#<Actress:0x007f8001839798
id: 2,
name: "佐津川愛美",
created_at: Sun, 26 Mar 2017 12:04:54 JST +09:00,
updated_at: Sun, 26 Mar 2017 12:04:54 JST +09:00>,
#<Actress:0x007f8001831b60
id: 5,
name: "吉高由里子",
created_at: Sun, 26 Mar 2017 12:04:54 JST +09:00,
updated_at: Sun, 26 Mar 2017 12:04:54 JST +09:00>,
#<Actress:0x007f8001831a20
id: 4,
name: "堀北真希",
created_at: Sun, 26 Mar 2017 12:04:54 JST +09:00,
updated_at: Sun, 26 Mar 2017 12:04:54 JST +09:00>]
SELECT
DISTINCT "actresses".*
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
(方法2・サブクエリ)INNER JOINしてactresses.idだけを先に取り出し、INを使う。
- scopeの中で内部結合したり、
DISTINCTは使いたくないというときもあるので、こちらの方法が良い場合もある。 - 副問い合わせになるので、SQL発行は一回で行うことができる。
Actress.where(id: Actress.joins(:tags).select("actresses.id"))
=> [#<Actress:0x007f7fff7d8490
id: 2,
name: "佐津川愛美",
created_at: Sun, 26 Mar 2017 12:04:54 JST +09:00,
updated_at: Sun, 26 Mar 2017 12:04:54 JST +09:00>,
#<Actress:0x007f7fff7d8300
id: 4,
name: "堀北真希",
created_at: Sun, 26 Mar 2017 12:04:54 JST +09:00,
updated_at: Sun, 26 Mar 2017 12:04:54 JST +09:00>,
#<Actress:0x007f7fff7d8198
id: 5,
name: "吉高由里子",
created_at: Sun, 26 Mar 2017 12:04:54 JST +09:00,
updated_at: Sun, 26 Mar 2017 12:04:54 JST +09:00>]
SELECT
"actresses".*
FROM
"actresses"
WHERE
"actresses"."id"
IN (
SELECT
actresses.id
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
INNER JOIN
"tags"
ON
"tags"."movie_id" = "movies"."id"
)
2. joinの中でサブクエリを用いる(サブクエリと内部結合)
Actressに紐づけられている映画が最も新しい順にActressを取り出したい
- 今回用意したデータでは、2005年から2016年までの映画があるが、女優を取り出す時に、登録されている映画が最新のものから順にActressを取り出したい場合のクエリを考える。
- 参考までに今回のデータを最初に示す。
# 今回のデータを表示するためのコード
Movie.all.order(year: :desc).eager_load(:actress).each { |m| puts "#{m.year}\t#{m.title}\t#{m.actress.name}" };nil
2016 貞子vs伽椰子 佐津川愛美
2013 真夏の方程式 吉高由里子
2013 県庁おもてなし課 堀北真希
2012 忍道-SHINOBIDO- 佐津川愛美
2006 夜のピクニック 多部未華子
2005 蝉しぐれ 佐津川愛美
2005 ALWAYS 三丁目の夕日 堀北真希
2013年が吉高由里子と堀北真希がかぶっていて分かりにくいが、2016年の「貞子vs伽椰子」に出演しているのは佐津川愛美なので、佐津川愛美から順に出力されれば良い。
今回以下に4つの方法を示す。
- joins + eager_loadを使う(挙動が不自然)
- find_by_sqlを用いる(返り値の型がArrayなので、使いにくい)
- Arelを用いる(賛否両論あり)
-
joinsの中にSQLを直書きする方法(SQL直書きOK派の人にはおすすめ)
総合的に考えると、一番最後のjoinsの中にSQLを直書きする方法が良さそうである。
joins + eager_loadを使う(挙動が不自然)
Actress.joins(:movies).eager_load(:movies).order('movies.year desc')
# => [#<Actress:0x007f8978525928
id: 2,
name: "佐津川愛美",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>,
#<Actress:0x007f897851d0c0
id: 5,
name: "吉高由里子",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>,
#<Actress:0x007f8972e37968
id: 4,
name: "堀北真希",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>,
#<Actress:0x007f897850fd58
id: 1,
name: "多部未華子",
created_at: Fri, 23 Mar 2018 01:03:30 JST +09:00,
updated_at: Fri, 23 Mar 2018 01:03:30 JST +09:00>]
SELECT
"actresses"."id" AS t0_r0,
"actresses"."name" AS t0_r1,
"actresses"."created_at" AS t0_r2,
"actresses"."updated_at" AS t0_r3,
"movies"."id" AS t1_r0,
"movies"."actress_id" AS t1_r1,
"movies"."title" AS t1_r2,
"movies"."year" AS t1_r3,
"movies"."created_at" AS t1_r4,
"movies"."updated_at" AS t1_r5
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
ORDER BY
movies.year desc
しかし、この挙動はいささか不自然である。なぜなら、内部結合しているにも関わらず、返り値にactressが重複していないからである。SQLの実行結果から考えると、堀北真希の次に佐津川愛美がくるべきである。
また、このクエリの場合、kaminariのgemを使うとうまく動いてくれない。例えば、今回のクエリで、per(4)とすると、
Actress.joins(:movies).eager_load(:movies).order('movies.year desc').page(nil).per(4).count
# => 3
結果が3つだけとなってしまう。これは、kaminariが自動的にクエリを2回に分けて発行してしまっているからである。
一つ目のクエリは
SELECT
DISTINCT movies.year AS alias_0,
"actresses"."id"
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
ORDER BY
movies.year desc
LIMIT 4 OFFSET 0
;
であり、映画の公開年で降順に並べ替えたactresses.idを四つ取得している。
このクエリの結果は
alias_0 | id
---------+----
2016 | 2
2013 | 5
2013 | 4
2012 | 2
となる。ポイントは、id=2が2回登場しているということである。この結果を2つ目のクエリのIN句に渡している。
SELECT
COUNT(DISTINCT "actresses"."id")
FROM
"actresses"
INNER JOIN
"movies"
ON
"movies"."actress_id" = "actresses"."id"
WHERE
"actresses"."id" IN (2, 5, 4, 2)
IN句の中に重複があるので結果は3つとなってしまい、kaminariのpaginationが正しく動作しない。
find_by_sqlを用いる(返り値の型がArrayなので、使いにくい)
ここで、原点に戻ってSQLで考える。SQLで書くならば例えば次のようになる。
SELECT "actresses".*, MAX("movies"."year") as max_year
FROM actresses, movies
WHERE
"actresses"."id" = "movies"."actress_id"
GROUP BY
"actresses"."id",
"movies"."actress_id"
ORDER BY
max_year DESC
;
あるいは、FROM句に複数テーブルを記述するSQLはActiveRecordでは発行しにくい(できない?)ので、素直にINNER JOINを用いて次のように書く。
SELECT actresses.*
FROM actresses
INNER JOIN (
SELECT
"movies"."actress_id" as actress_id,
MAX(year) as max_year
FROM
"movies"
GROUP BY
"movies"."actress_id"
) movies_max_year
ON actresses.id = movies_max_year.actress_id
ORDER BY max_year DESC
;
このSQLをActiveRecordから発行したい。
単純に思いつくのは、find_by_sqlを使う方法。
Actress.find_by_sql(%|
SELECT "actresses".*
FROM actresses
INNER JOIN (
SELECT
"movies"."actress_id" as actress_id,
MAX(year) as max_year
FROM
"movies"
GROUP BY
"movies"."actress_id"
) movies_max_year
ON "actresses"."id" = "movies_max_year"."actress_id"
ORDER BY max_year DESC
|)
しかし、find_by_sqlでは返り値の型がArrayになってしまう。やはり使い勝手の良さを考えるとActress::ActiveRecord_Relationで返ってきて欲しい。
Arelを用いる(賛否両論あり)
Arelを用いれば、Actress::ActiveRecord_Relationで返ってこさせることができる。
Arelは内部APIなのでバージョンが異なると仕様が異なるかもしれないので、ご利用の際はきちんとテストを書くことをおすすめ
actress_at = Actress.arel_table
movie_at = Movie.arel_table
movies_max_year = movie_at.project(
Arel.sql(%|
"movies"."actress_id" as actress_id,
MAX(year) as max_year
|)
).group("movies.actress_id").as("movies_max_year")
join_conds = actress_at.join(
movies_max_year,
Arel::Nodes::InnerJoin
).on(
movies_max_year[:actress_id].eq(actress_at[:id])
).join_sources
Actress.joins(join_conds).order('movies_max_year.max_year DESC')
型を確認してみると、無事Actress::ActiveRecord_Relationにっているのがわかる。
Actress.joins(join_conds).order('movies_max_year.max_year DESC').class
# => Actress::ActiveRecord_Relation
ここまでくれば、無事kaminariを用いることができる。
joinsの中にSQLを直書きする方法(SQL直書きOK派の人にはおすすめ)
世の中には、Railsを使っていてSQLを直書きするなんてという人と、Arel使うぐらいならSQL直書きするという人がいるらしい。
最近は、こちらの記事の影響からか、Arel使わない勢の方が優勢かもしれない。
ポイントは、joinsを用いていればデフォルトで内部結合になるが、サブクエリを用いるがゆえに、内部結合でもSQLを直書きしている点。
Actress.joins(%|
INNER JOIN (
SELECT
"movies"."actress_id" AS actress_id,
MAX(year) AS max_year
FROM
"movies"
GROUP BY
"movies"."actress_id"
) AS movies_max_year
ON actresses.id = movies_max_year.actress_id
|).order("max_year desc, actresses.id asc")