6/5にSolr勉強会 (スライド) で発表したとき、LTRプラグインがあまり知られてない気がしたので、自分が知ってることをテキトーにまとめときます。
(なお、この記事はSolr6.5.1をベースに書いてます)
LTRプラグインとは
LTRは「Learning To Rank」の略で、日本語で言うとランク学習のこと。ランク学習の細かいところはこの辺の資料を読むといい気がします。
LTRプラグインはLucene/Solr Revolution 2015でBloombergの人が発表した内容 (スライド) が元ネタになっており、その後プラグインとしてSolrにパッチが出され、Solr6.4.0から正式にマージされました (SOLR-8542)。
LTRプラグインの目的
LTRプラグインではランク学習に依って調整されたモデルをSolrのランキングで用いることを目的としています。モデルの中身はただの数式なので、SolrのFunctionQueryを用いて表現することが出来なくもないですが、以下のような理由からプラグインとして新規に実装しているんだと思います。
- 機械学習モデルは大きくなりがちで、FunctionQueryだとキツイ
- FunctionQueryではリクエスト毎に計算式が構築される
- LTRプラグインでは事前にモデルをロードして使いまわす
- リクエストパラメタに載せるため通信量が増えるのもネック
- FunctionQueryではリクエスト毎に計算式が構築される
- 単純にFunctionQueryを使うとヒットした全ドキュメントに対して計算が適用される
- モデルを用いたスコア計算はコストが大きいのでレイテンシに跳ねる
- LTRプラグインではヒットしたドキュメントの上位N件 (
default=200) にのみ適用
- LTRプラグインではヒットしたドキュメントの上位N件 (
- 一応ReRankプラグインと組み合わせることもできなくはない
- モデルを用いたスコア計算はコストが大きいのでレイテンシに跳ねる
LTRプラグインの動作
LTRプラグインは前述の通り、ヒットしたドキュメントの上位N件に対してモデルによるスコア計算を適用します。この動作はRnakQueryを用いて実現されています (RankQueryの話は以前書いた記事あたり見てください)。
処理フローを雑に書くと以下のように3つの段階に分かれます (SolrCloudを想定)。
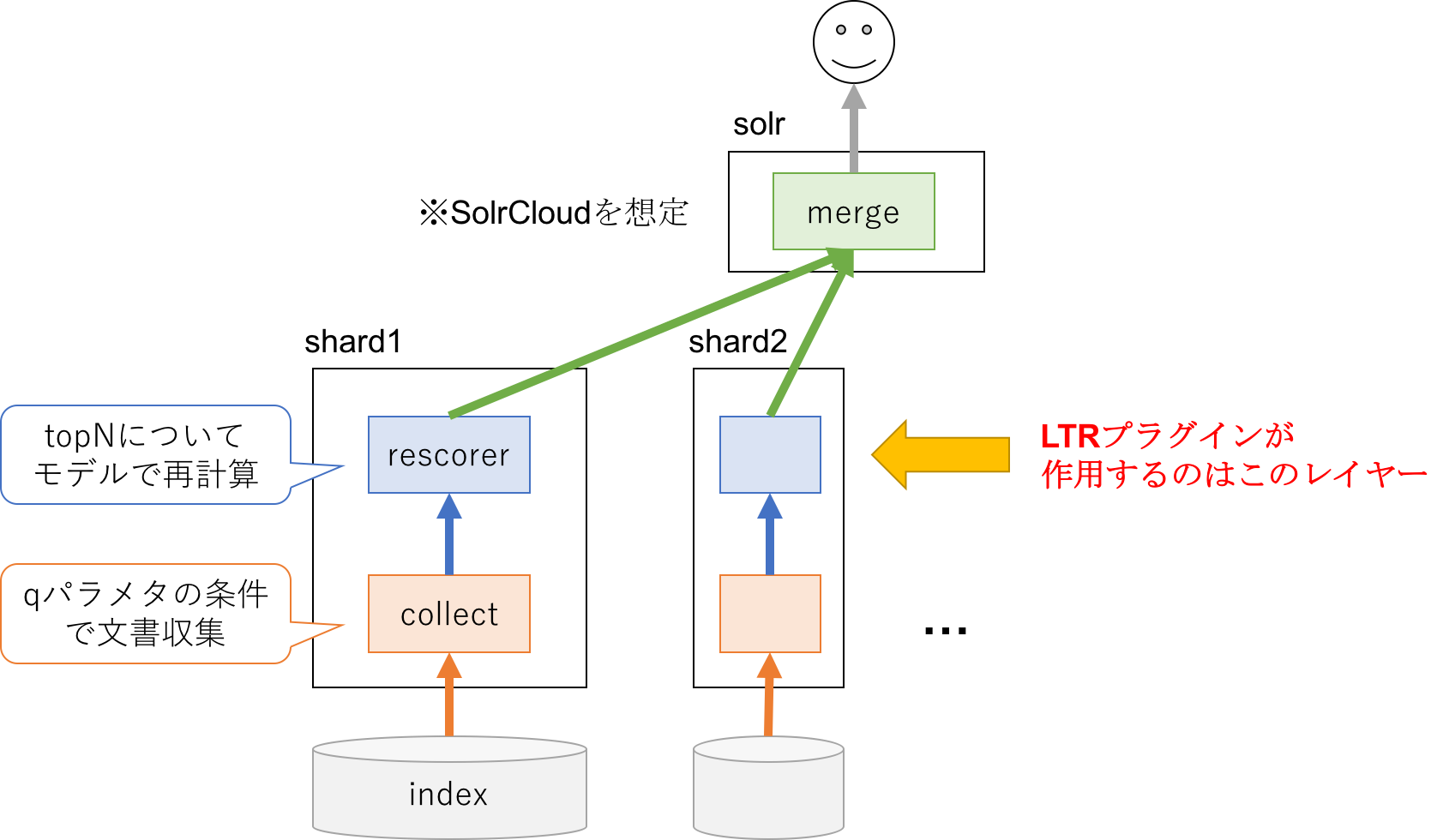
LTRプラグインが作用するのは、上図のrescorerの部分になります。典型的なケースだと以下のような流れ。
-
collectはBM25でスコア計算して各shardでtopNを選択 -
recorerで各shardのtopNにモデルを適用してスコアを再計算 -
mergeにて最終スコアを元にソートしながら全shardからの返却文書をマージ
LTRプラグインの使い方
基本的には公式チュートリアルにある通りなので、ここではポイントをかいつまんで話します。
LTRプラグインを有効にするには
LTRプラグインはcontribパッケージとして提供されおり、対応するjarをsolrに追加する必要です。具体的にはsolrのパッケージに含まれている以下のjarファイルが対応しています。
solr-6.5.1/dist/solr-ltr-6.5.1.jar
実際に使うためにはsolrconfig.xmlに以下の4つの設定が必要になります。
プラグインのjarをロード対象に追加
以下のような感じでjarのパスをsolrのlibraryに追加します (参考)。
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-ltr-\d.*\.jar" />
LTRプラグインのqueryParserの登録
以下のような感じでLTRプラグインのQParserPluginのクラスをqueryParserに登録します。このように定義するとSolr内部でLTRQParserPluginのインスタンスが生成され、"ltr"という名前で指定できるようになります。
<queryParser name="ltr" class="org.apache.solr.ltr.search.LTRQParserPlugin"/>
素性ベクトル用のキャッシュの登録
以下のような感じで素性ベクトル (i.e., Feature Vector) 用のキャッシュ定義を追加します。このキャッシュは素性ベクトルの計算結果をレスポンスに乗せるための一時退避場所として利用されます。
<cache name="QUERY_DOC_FV"
class="solr.search.LRUCache"
size="4096"
initialSize="2048"
autowarmCount="4096"
regenerator="solr.search.NoOpRegenerator" />
素性ベクトルダンプ用のtransformerの登録
以下のように素性ベクトルダンプのためのTransformerFactoryの設定を追加します。Transformerはレスポンスの加工で利用されるクラスで、下のように設定するとfl=[feature]とリクエストで指定したときに実行され、レスポンスに素性ベクトルのダンプ情報が追加されます (参考)。
<transformer name="features" class="org.apache.solr.ltr.response.transform.LTRFeatureLoggerTransformerFactory">
<str name="fvCacheName">QUERY_DOC_FV</str>
</transformer>
LTRプラグインの基本的な流れ
LTRプラグインを使う場合、基本的には以下の3つのステップを踏みます。
- 素性定義をプラグインに登録
- モデル定義をプラグインに登録
- 登録したモデルを使って検索
それぞれ以下のような関係図になっています。
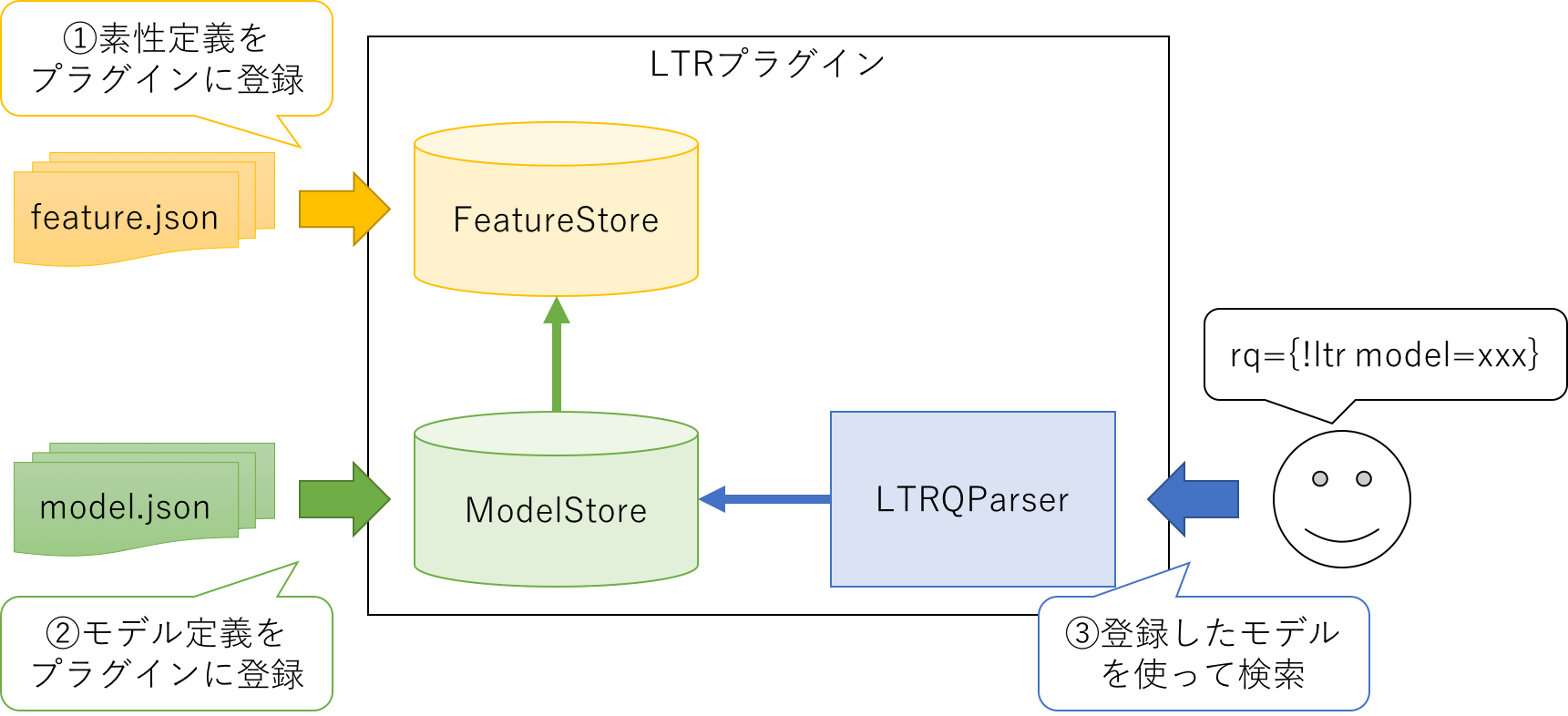
素性定義はモデル計算で参照する素性群の定義のことで、具体的にはフィールド長さとかフィールド値とかが利用されます (詳細は後述します)。モデル定義は素性群をどのように組み合わせて最終的なスコアを計算するか、という部分に対応しています。機械学習でモデルを学習するというのは、このスコア計算の部分を調整することに対応しています。
素性定義をプラグインに登録
素性定義の中身は公式チュートリアルのように以下のようなリストとなっています (中身の詳細は後述)。
[
{
"name" : "documentRecency",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "{!func}recip( ms(NOW,last_modified), 3.16e-11, 1, 1)"
}
},
{
"name" : "isBook",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"fq": [ "{!terms f=cat}book" ]
}
},
{
"name" : "originalScore",
"class" : "org.apache.solr.ltr.feature.OriginalScoreFeature",
"params" : {}
}
]
素性定義のアップロードは以下のような感じでPUTリクエストで行います。
curl -XPUT 'http://localhost:8983/solr/techproducts/schema/feature-store' --data-binary "@/path/myFeatures.json" -H 'Content-type:application/json'
なお、リクエスト先のURLは以下のような構成で、自分のコレクション名に応じて変更が必要になります。
http://${HOST}:${PORT}/solr/${COLLECTION}/schema/feature-store
登録内容の確認は以下のようなURLを叩けばわかります。なお、_DEFAULT_は後述のstoreで指定されたグループ名に対応しています。
http://localhost:8983/solr/techproducts/schema/feature-store/_DEFAULT_
ちなみに、これら一連の処理はあくまでリクエストを行ったノードにだけ実行されるため、SolrCloudのような環境ではcoreのreloadを行ってzookeeperから最新設定を取得させる必要があるかと思います。
モデル定義をプラグインに登録
こちらも素性定義と同じようにjsonファイルで記述します。公式チュートリアルの例だと以下のような感じ (詳細は後述)。
{
"class" : "org.apache.solr.ltr.model.LinearModel",
"name" : "myModel",
"features" : [
{ "name" : "documentRecency" },
{ "name" : "isBook" },
{ "name" : "originalScore" }
],
"params" : {
"weights" : {
"documentRecency" : 1.0,
"isBook" : 0.1,
"originalScore" : 0.5
}
}
}
アップロード方法も素性定義と同じ。ただし、アップロード先のパスがfeature-storeからmodel-storeに変わります。
curl -XPUT 'http://localhost:8983/solr/techproducts/schema/model-store' --data-binary "@/path/myModel.json" -H 'Content-type:application/json'
登録内容の確認は以下のようなURLを叩けばわかります。
http://localhost:8983/solr/techproducts/schema/model-store
ちなみに、modelの方もSolrCloudのような環境ではcoreのreloadを行ってzookeeperから最新設定を取得させる必要があるかと思います。
登録したモデルを使って検索
LTRプラグインは前述のようにRankQueryとして実装されているため、rqパラメタを使ってプラグインを指定します。具体的には以下のようにrq={!ltr ...}と指定します。
rq={!ltr model=myModel}
LTRプラグインではlocalParamsとして以下のようなパラメタが設定できます。
| key | required | default | desc |
|---|---|---|---|
| model | o | - | リランキングで使うモデルを指定 |
| reRankDocs | 200 | リランキング対象となるドキュメント数 | |
| efi.XXX | - | クエリ素性の指定、素性の値を動的に変えるときに使う |
素性とモデルの定義
LTRプラグインでは素性とモデルが肝となるので、ここではそこを深掘りしてみます。
素性定義
素性は前述の通りjsonファイルにlistで列挙することで定義します (単体素性ならmapも可)。素性一つ一つの定義は以下のようなmapとして定義されます。
{
"store": "myFeatureStore",
"name" : "documentRecency",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "{!func}recip( ms(NOW,last_modified), 3.16e-11, 1, 1)"
}
},
それぞれ以下のような意味があります。
| key | required | default | desc |
|---|---|---|---|
| store | _DEFAULT_ |
素性の所属グループ名、参照操作や素性ダンプとか指定する | |
| name | o | - | 素性の名称、モデルからの参照で使う |
| class | o | - | 素性のクラス、クラス毎に取得できる素性が異なる |
| params | - | 素性のパラメタ、コンストラクタの引数みたいなもの |
現在の実装では5つの素性が利用できます (すべてorg.apache.solr.ltr.featureパッケージのクラス)。
FieldValueFeature
フィールドの値を参照するための素性で、以下のような感じで定義します。この例ではhitsというフィールドの値を参照しています。
{
"name": "rawHits",
"class": "org.apache.solr.ltr.feature.FieldValueFeature",
"params": {
"field": "hits"
}
}
FieldValueFeatureを使う場合は、計算で利用する都合で数値型のフィールドを指定することになるかと思います。
FieldLengthFeature
フィールドの長さ (トークン数) を参照するための素性で、以下のような感じで定義します。この例ではtitleというフィールドの長さを参照しています。
{
"name": "titleLength",
"class": "org.apache.solr.ltr.feature.FieldLengthFeature",
"params": {
"field": "title"
}
}
ここで指定するフィールドはtext_jaのようなトークナイズ対象のフィールドになるかと思います。なお、Solrは内部でフィールド長を1byte (i.e., 0-255) の範囲に圧縮して保持するため、大雑把な値が返ってくる点に注意 (使う上ではあんまり影響ないと思うけど)。
SolrFeature
Solrのクエリ自体を利用する素性で、以下のような感じで定義します。この例では、isBookの方はリランク対象の文書のcategoryフィールドにbookが含まれるかの判定を、documentRecencyの方はpublic_dateフィールドをシグモイド関数に通して文書の新しさを0-1で表現するみたいなことをしています。
{ "name": "isBook",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params":{ "fq": ["{!terms f=category}book"] }
},
{
"name": "documentRecency",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {
"q": "{!func}recip( ms(NOW,publish_date), 3.16e-11, 1, 1)"
}
}
上の例を見ると分かるように、SolrFeatureではSolrのクエリ自体をパラメタとして渡します。内部ではこのパラメタからローカルリクエストを生成して、通常の検索のように処理をしてクエリに対応するスコアを計算することで素性値を取得しています。なお、通常の検索のような動作をするので、fqを指定すればリランキング対象の文書をフィルタすることができるというカラクリです。
なお、内部リクエストの生成は検索するタイミングで行われるため、非常に長いFunctionQueryとかを指定すると毎回パース処理が走る点には注意が必要かも。
ValueFeature
固定値を定義するための素性で、以下のような感じで定義します。この例ではクエリのパラメタ (efi.userFromMobile=xxx) で指定された値を参照しています。
{
"name" : "userFromMobile",
"class" : "org.apache.solr.ltr.feature.ValueFeature",
"params" : { "value" : "${userFromMobile}", "required":true }
}
この素性は固定値を扱うというよりは、上記の例のようにクエリ指定のパラメタを参照することが典型的なユースケースのように見えます。なお、efi.XXXで指定したクエリパラメタは他の素性でも${XXX}というフォーマットで参照できます。
OriginalScoreFeature
オリジナルクエリでのスコアを参照する素性で、以下のような感じで定義します。この例ではcollectの段階で計算された元スコアがそのまま参照しています。
{
"name": "originalScore",
"class": "org.apache.solr.ltr.feature.OriginalScoreFeature",
"params": { }
}
この素性は他と少し異なりparamsの指定がなく、基本的に上記例以外にはパターンがないかと思います。デフォルトでは元スコアはBM25が利用されるため、その場合は検索クエリに対するBM25のスコアが返る感じになります。
モデル定義
モデルも素性と同じようにjsonファイルで記述します。中身は以下のような感じのmap。
{
"class" : "org.apache.solr.ltr.model.LinearModel",
"name" : "myModel",
"features" : [
{ "name" : "documentRecency" },
{ "name" : "isBook" },
{ "name" : "originalScore" }
],
"params" : {
"weights" : {
"documentRecency" : 1.0,
"isBook" : 0.1,
"originalScore" : 0.5
}
}
}
それぞれのパラメタの意味は以下の通り。
| name | required | default | desc |
|---|---|---|---|
| class | o | - | モデルのクラス |
| name | o | - | モデルの名前、検索時に指定する |
| features | o | - | モデルで利用する素性のリスト |
| params | - | モデルのパラメタ、クラス毎にフォーマットが異なる |
現在の実装では2つのモデルが利用できます (すべてorg.apache.solr.ltr.modelパッケージのクラス)。
LinearModel
線形モデルに対応した実装クラス。線形モデルとは、各素性に対して重みを設定し、素性値と重みの積を足し合わせてスコア計算するモデルのことです。数式にすると以下のような感じになります。
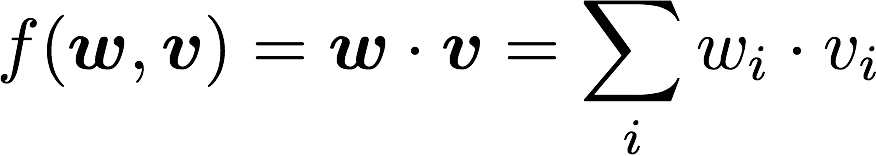
LTRプラグインでは以下のような感じで定義します。
{
"class" : "org.apache.solr.ltr.model.LinearModel",
"name" : "myModelName",
"features" : [
{ "name" : "userTextTitleMatch" },
{ "name" : "originalScore" },
{ "name" : "isBook" }
],
"params" : {
"weights" : {
"userTextTitleMatch" : 1.0,
"originalScore" : 0.5,
"isBook" : 0.1
}
}
}
paramsにあるweightsが数式のwに対応していて、各素性の重みを指定しています。モデル内部ではこの重みを使って先程の数式を計算する感じになります。
なお、線形モデルの場合、素性の値の正規化が重要になります。これはフィールドの特性によって取りうる値の範囲が大きく違うためで、線形モデルを有効に使うならこの値の範囲を一定 (例えば0〜1) に統一した方が精度がよくなります。LTRプラグインではこの正規化のためにNormalizerというクラスが用意されていて、モデルのfeaturesの中で以下のような感じで指定ができます。
"features" : [
{ "name" : "hits",
"norm" : {
"class" : "org.apache.solr.ltr.norm.MinMaxNormalizer",
"params" : { "min":"0", "max":"100000" }
}
},
...
],
LTRプラグインではNormalizerは2つ用意されています (パラメタは公式ドキュメント参照)。なお、指定が無い場合は値をそのまま使うダミーのNormalizer (IdentityNormalizer) が内部的に利用されます。
-
MinMaxNormalizer- 指定された最大値、最小値を元に次のように正規化
norm_val = (val - min) / (max - min)
- 指定された最大値、最小値を元に次のように正規化
-
StandardNormalizer- 指定された平均、標準偏差を元に次のように正規化
norm_val = (val - avg) / std
- 指定された平均、標準偏差を元に次のように正規化
MultipleAdditiveTreesModel
アンサンブル木モデルに対応した実装クラス。アンサンブル木モデルとは、複数の回帰木 (決定木) を組み合わせてスコア計算するモデルで、線形モデルの素性の部分が回帰木になった雰囲気。
LTRプラグインでは以下のような感じで定義します。
{
"class" : "org.apache.solr.ltr.model.MultipleAdditiveTreesModel",
"name" : "multipleadditivetreesmodel",
"features":[
{ "name" : "userTextTitleMatch"},
{ "name" : "originalScore"}
],
"params" : {
"trees" : [
{
"weight" : 1,
"root": {
"feature" : "userTextTitleMatch",
"threshold" : 0.5,
"left" : {
"value" : -100
},
"right" : {
"feature" : "originalScore",
"threshold" : 10.0,
"left" : {
"value" : 50
},
"right" : {
"value" : 75
}
}
}
},
{
"weight" : 2,
"root" : {
"value" : -10
}
}
]
}
}
paramsのtreesが回帰木のリストになっていて、要素の各mapが一つの回帰木に対応しています。例えば上のモデルを図にすると以下のような雰囲気になります。
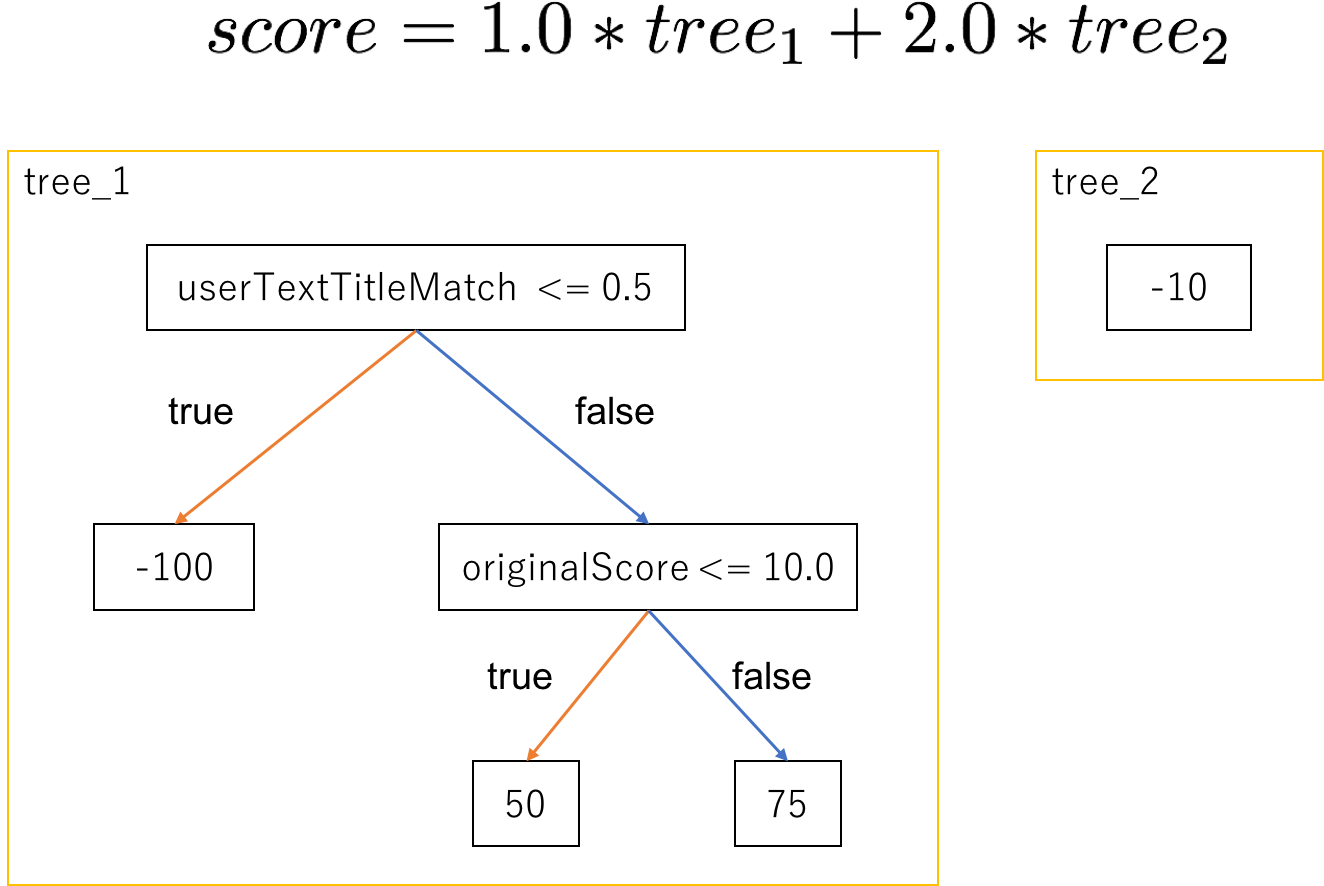
なお、LTRプラグインでは回帰木の条件分岐はfeature <= thresholdで固定なので、モデルを記述するときは注意してください。
独自の素性やモデルを作りたいとき
LTRプラグインの素性やモデルは共通の親クラスをもつ構成となっているため、それを継承した独自クラスを実装すれば機能拡張が簡単に出来ます。具体的には、
- 独自素性を作りたい => Featureの継承クラスを作る
- 独自モデルを作りたい => LTRScoringModelの継承クラスを作る
のような感じになります。
LTRプラグインと機械学習
ここまでLTRプラグインの概要をざっくり説明しましたが、そもそもLTRプラグインを使う前提条件としてモデルがすでに手元にあることを想定していました。一方で、現実にはそもそもモデルが手元にないというケースがほとんどで、LTRプラグインを使う前の前準備が色々と必要になると思います。ここでは個人的に思う前準備で必要そうなことを考えてみます。
学習データの収集
モデルを作るためには機械学習で用いるデータの収集が必要不可欠です。学習データには最低限、対応する素性値のリストと良し悪しのラベルの2つが必要となります。
LTRプラグインでの運用を想定した場合、素性値はLTRプラグインで取得できるものにする必要があります。
幸い、LTRプラグインでは検索レスポンスに素性リストを付与する機能としてLTRFeatureLoggerTransformerFactory が実装されているため、それを使うことでモデルのfeaturesで指定されている素性の実際の値を収集することができます (ドキュメント)。
具体的には以下のようなサイクルを回してモデルを学習していくんじゃないかと思っています。
- モデルで利用する素性を選択
- 選択した素性をLTRプラグイン登録
- 登録した素性をダンプしながらしばらく検索を回してログを収集
- 得られた検索ログを元に新しいモデルを学習
- 新しいモデルでLTRプラグインのモデルを更新
- 3.に戻る
初めの素性の選択は難しい作業ですが、実際に有効な素性は機械学習の過程で選別すればいいので、初めはパフォーマンスが許す限りたくさんの素性を選んでおくといいと思います。一番簡単なのは、とりあえず思いつく素性定義をstore指定をしないで全て_DEFAULT_に登録して、素性ダンプのstoreに_DEFAULT_を指定して全てダンプするとかかと。
3.では前述のラベルの付与も必要となります。すでに稼働中のサービスならばユーザのクリックのようなフィードバックが得られるはずなので、クリックありを正例、クリックなしを負例とするのがいいかと。それ以外では、人的リソースがあるなら人手でラベル付けをするという方法もあります。それぞれ以下のようなメリット・デメリットがあります。
- ユーザのクリックなどのフィードバックを使う
- good: トラフィック分のデータが集まるので、大量の学習データが得られる
- bad: ユーザの嗜好に左右されるためラベルのノイズが大きい
- 人手でラベル付けを行う
- good: 知識ある人がラベル付けを行うのでラベルの精度が高い
- bad: 大量のデータを用意するのが大変
モデルの学習に必要なデータ量はモデルのサイズに依存するので、その辺との兼ね合いで決める感じになるのかなぁ、と思います。
モデルの選択
LTRプラグインでは前述の通り線形モデルとアンサンブル木モデルの2つが選択出来ますが、どちらを用いるのがいいか、という議論がでてきます。
個人的な意見としては特に理由がなければアンサンブル木をお勧めします。理由は以下の通りです。
- 回帰木では各素性の評価を分岐判定で別々に行うため、線形モデルで述べた正規化をあまり気にしなくてもちゃんと動く
- 回帰木では線形モデルでは判定できない非線形な関連を処理することができ、表現力が高い
- web検索とかだとアンサンブル木モデルの方がナウい (ex. Ranking Relevance in Yahoo Search)
モデルの学習
モデルの学習ですが、世の中には様々な学習ライブラリが存在するため、特にこだわりがなければそれらを用いてモデルを学習すればいいかと思います。例えば線形モデルならばLinearModeのJavadocにも書かれているLIBLINEARや、アンサンブル木モデルならKaggleでよく見かけるXGBoostあたりを使えばとりあえずはなんとかなると思います。
まとめ
この記事ではSolr6.4から追加されたLTRプラグインについて紹介しました。
機械学習はなかなかとっつきにくいかもしれないですが、検索モデルとして利用した場合、精度面でのリターンは非常に大きいです。LTRプラグインの登場は、Solrでこのような機械学習モデルを使う敷居を大きく下げたんじゃないかと個人的に感じています。もし検索ログなどデータが入手し易い環境にあるならば、精度改善に大きく寄与できる可能性があるので、機械学習モデルの導入にチャレンジしてみると楽しいかもしれないです。
ただし、機械学習は必ずしも魔法のツールでは無いということは注意してください。サービスの規模や内容によっては足回りの軽いFunctionQueryとかで済ました方が運用コストとかを総合的に判断していいというケースは多々あると思います。機械学習を導入しようとしてサービスが火を吹いたら本末転倒なので、ある程度の知識がある人を交えて導入可否をしっかり検討することが重要になります。
最後に、この記事が今後LTRプラグイン導入を検討している人の助けに少しでもなれば幸いです。