この記事は Solr Advent Calendar 2016 の 25日目です。
今回はSolrのRankQueryについてテキトーに話します。
(なお、この記事の時点でのSolrのバージョンは6.3.0です)
Solrとランキング
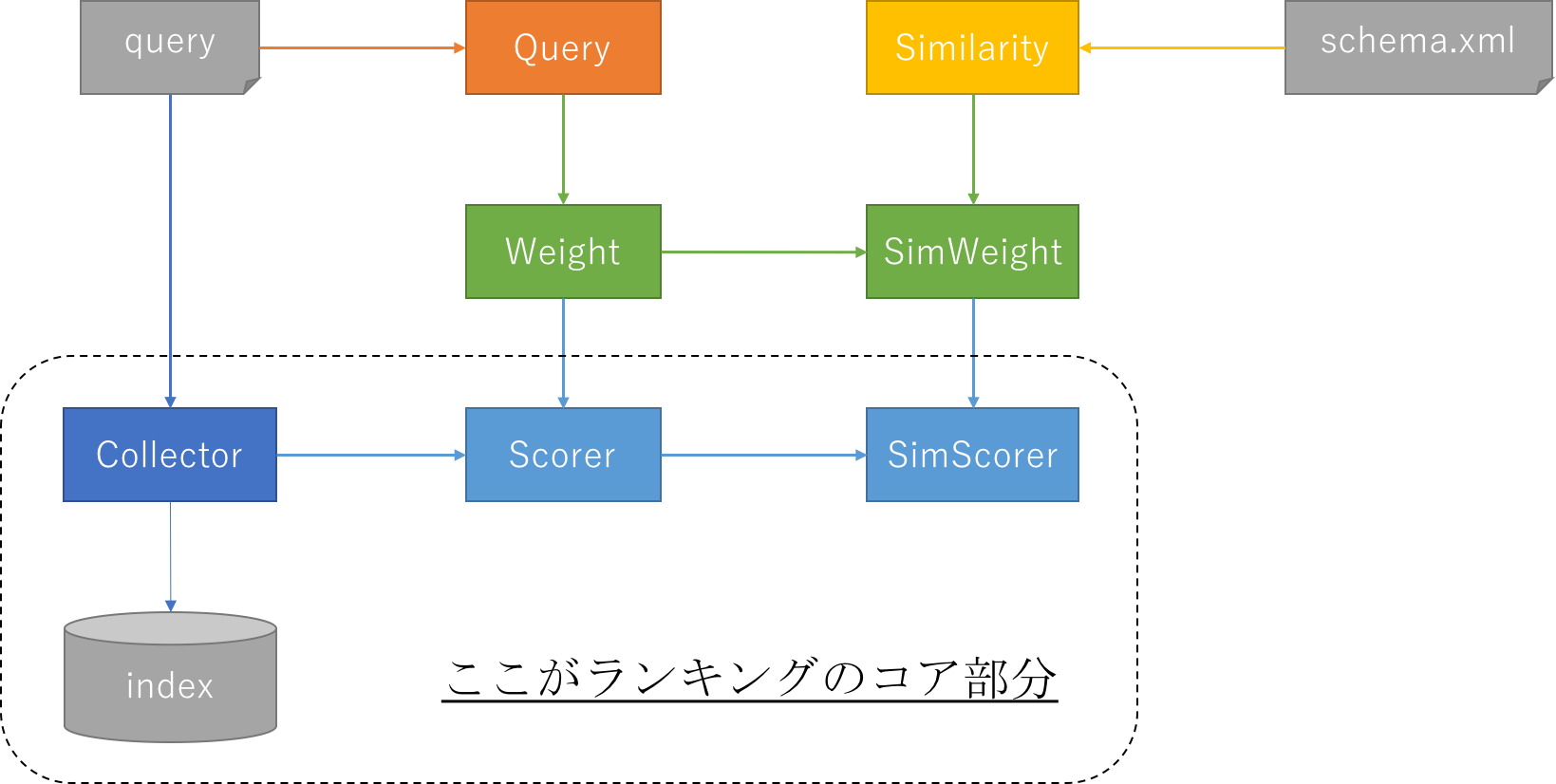
Solrのランキングでは大きく分けて以下の3つのコンポーネントが関係します。
-
Query/Weight/Scorer- 検索クエリから
QueryParserを介して生成される部分 -
Query=>Weight=>Scorerの順番で生成 - 先に行くほど担当範囲が狭くなり、
Scorerでは単一のセグメント (LeafReaderContext)
- 検索クエリから
-
Similarity/SimWeight/SimScorer -
Collector- 検索でヒットした文書セットから最終候補を選別する部分
- 前述の
Scorerでヒットした文書のスコア計算をしていき、そのスコアに応じて文書セットの優先度キューを更新 - sort条件に依ってインスタンスが切り替わり、scoreのみのソートなら
TopScoreDocCollectorが、fieldも加味するソートならTopFieldCollectorが生成
ランキングは実際に文書に触る箇所で行われるため、上記だとセグメントレベルの粒度で動作するScorer、SimScorer、Collectorがランキングのコア部分になります。
ランキングの例: TopScoreDocCollector
単純な検索の場合、スコア計算の起点はDefaultBulkScorerになります。DefaultBulkScorerでは以下のようにコンストラクタの中でScorerからDocIdSetIteratorとTwoPhaseIteratorを取得します。
DocIdSetIteratorとTwoPhaseIteratorは実際にクエリとのマッチしたドキュメントを返すイテレータで、前者が単純なIDの走査に、後者がより複雑なマッチ条件の判定に対応しています (だったはず)。これらの実装は対応するScorerによって違い、例えばフレーズ検索に対応するExactPhraseScorerなら対象の単語列が隣接して出現するかの判定が実装されています。
DefaultBulkScorerではこのイテレータを使ってヒットしたドキュメントを走査していき、得られたdocIDをCollectorに引き渡していきます。
TopScoreDocCollector (正確にはSimpleTopScoreDocCollector) のcollectメソッドは以下のようになります。
処理中で参照されているpqが優先度キューのことで、pqTop (優先度キューの末尾) とスコア比較をして、スコアが高い場合はドキュメントを入れ替えて優先度キューを更新という流れを繰り返していきます。なお、このスコア計算の部分に前述のSimScorerが利用されるという感じです。
RankQuery
先程までの話では、Solrのスコア計算はSimilarityで最終的に行われるため、独自のSimilarityを実装すればランキングの挙動を簡単に変更できることがわかります。一方で、この方式だと以下のような事ができない問題があります。
-
SimilarityのAPIに従った実装しか出来ないため、より複雑なこと (例えば実行時にfield値を参照するとか) がやりずらい -
Collectorではマッチした全ての文書に対してスコア計算を行うため、計算コストが大きい複雑なロジックを入れづらい
これらの問題を解決する仕組みとして、SolrではRankQueryが用意されています。
RankQueryの仕組み
RankQueryはざっくり言うと「元の検索クエリをラッピングして動作を変える」ことができる仕組みになります。前述の通り、検索クエリはQueryParserによってQueryというクラスに変換しますが、RankQueryが指定されている場合、以下のように実際の検索コマンドを生成するときにQueryがRankQueryでラッピングされます。
この結果、本来Queryが呼ばれるはずだった処理がRankQueryに委譲され、RankQueryで好き勝手改変することができるようになります。例えば、QueryからWeightを生成する箇所 (createWeight) もRankQueryを経由するため、独自のスコアリングロジックを実装したScorerを生成するWeightに差し替えることができるわけです。
RankQueryの実装を見てみると、以下のように3つのAPIが定義されていることがわかります。
TopDocsCollector getTopDocsCollector(int len, QueryCommand cmd, IndexSearcher searcher)MergeStrategy getMergeStrategy()RankQuery wrap(Query mainQuery)
このうちwrapは前述のラッピングのタイミングで呼び出されるものです。この中でランキングで重要なのはgetTopDocsCollectorです (getMergeStratedyは分散計算で検索結果をマージするときの挙動を変えるだった気がする)。getTopDocsCollectorでは独自のCollector (i.e., TopDocsCollector) を返すことができ、ランキング時のスコアリングの挙動を変更することが可能となります (具体的にはここで差し替わる)。
先程のランキングのところでCollectorがスコアリングとドキュメントのランキングを行うと説明しましたが、実際に利用されるCollectorのベース実装であるTopDocsCollectorにはTopDocs topDocs(int start, int howMany)という初めのランキング後の優先度キューから上位n件を取得するためのメソッドが存在します。getTopDocsCollectorで独自のCollectorを用意できるようになったお陰で、このTopDocsの処理を上書きできます。
ところで、なぜTopDocsの変更がポイントとなるのでしょうか。TopDocsはモダンな検索エンジンで実装されているtwo-phase rankingを実現する上で、two-phase目の高精度高コストなリランキングに相当する箇所になります。TopDocsでは事前に収集して足切りされたドキュメントセットがリランクの対象となるため、スコア計算する対象が絞り込まれ、より複雑な計算ロジックも適用できるようになるわけです。
RankQueryの例: ReRankQuery
RankQueryの実際の例としてReRankQueryを見てみます。
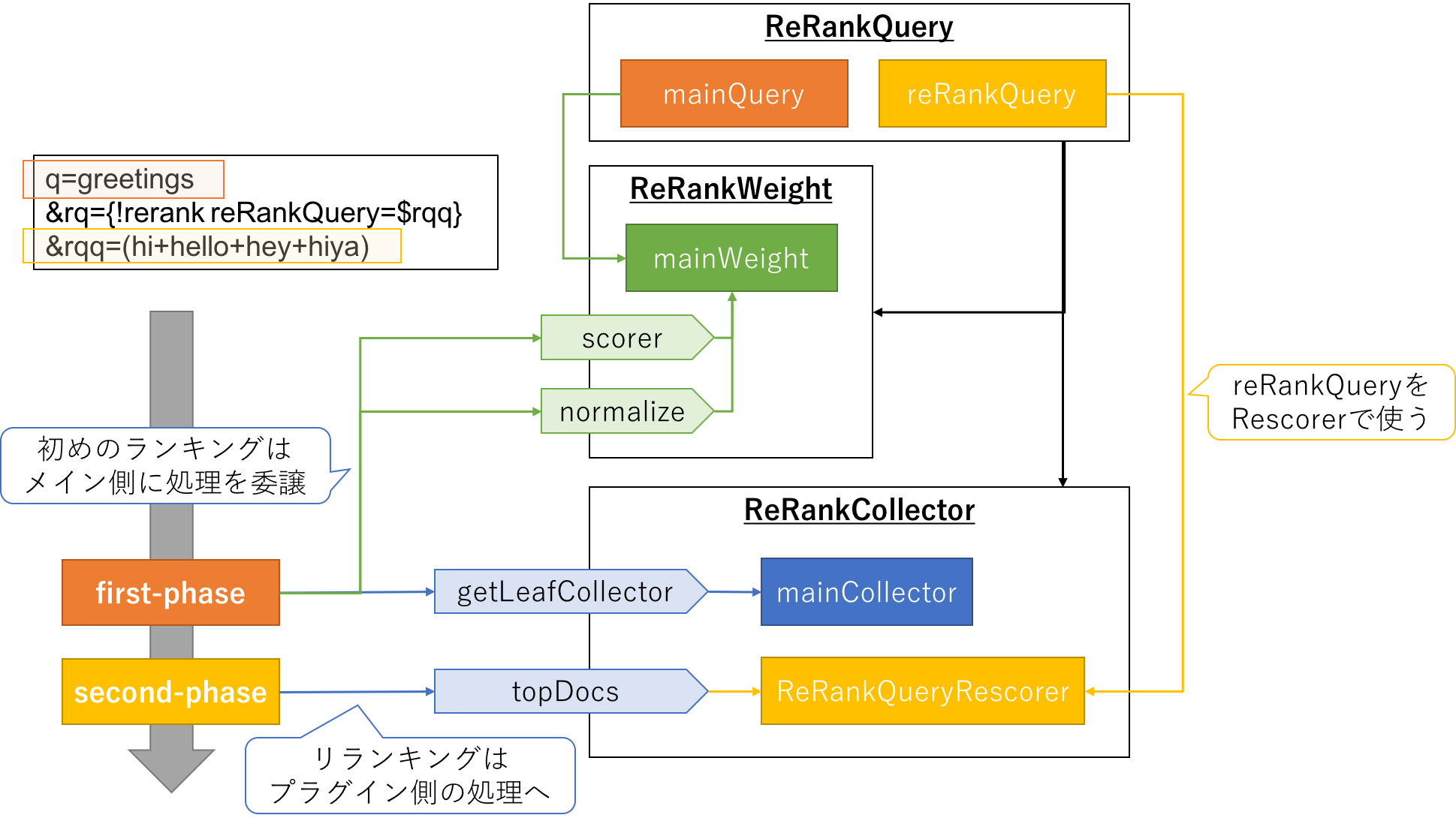
ReRankQueryは以下のように使うプラグインの一つ (ReRankQParserPlugin) で、reRankQueryで指定されたクエリでドキュメントを再評価し、スコアに補正をかけるものになります。
q=greetings&rq={!rerank reRankQuery=$rqq reRankDocs=1000 reRankWeight=3}&rqq=(hi+hello+hey+hiya)
実際の実装は以下のようになっています (6.3.0から主要な処理がAbstractReRankQueryに集約されたみたい)。
ReRankQueryではTopDocsCollectorをReRankCollectorに差し替えることでリランキングを実現しています。ReRankCollectorでは元のCollector (mainCollector) をラッピングしていて、基本的なAPIは処理をmainCollector側に委譲しつつ、topDocsを書き換えるような実装となっています。
TopDocsの実装において、リランクのコア処理はこの部分になります。ここでは、初めのランキング後のドキュメントセットを以下のReRankQueryRescorerに渡すことでリランキングを行っています。
リランキングのコア処理は親クラスのQueryRescorer側のrescoreメソッドに実装されています。処理の流れをざっくりまとめると以下のようになります。
- リランク対象のドキュメントをdocID順にソート (セグメント順にするため)
- 検索時に指定されたreRankQuery対応する
QueryからWeightを生成 - リランク対象のドキュメントに対して以下を繰り返し
- ドキュメントのdocIDに対応するセグメント (
LeafReaderContext) を取得 - セグメントに対応するリランク用の
Scorerを生成 -
Scorerを用いてドキュメントのリランクスコアを計算 - 得られたスコアを元のスコアに検索時に指定されたreRankWeightで重み付けして加算
- ドキュメントのdocIDに対応するセグメント (
- 最終的なスコア順にドキュメントセットを再ソートして結果を返却
ReRankQueryの処理の流れをざっくりまとめると以下のような感じになります。
Bloombergのltr-plugin
Solr6.4からBloombergのltr-pluginが取り込まれるそうです (Solr6.4 Features)。ltr-pluginはLucene/Solr Revolution 2015でBloombergの技術者が発表していた機能のことで、詳細は発表スライドにまとめられています。
- ltr-plugin (マージされたらmaster側見てください)
ltr-pluginのltrは"Learning To Rank"の略で、機械学習を用いてドキュメントのスコアを計算するモデルを学習することを意味しています。ltr-pluginではこのような機械学習モデルを使うために、以下のような機能を提供しています。
- モデルで利用する素性 (特徴、
Feature) の展開 - 線形モデルや回帰木モデルを用いたリランキング
ltr-pluginによって、前述のReRankQueryに比べ、より複雑かつ高精度なモデルをリランキングに使うことが可能となるため、ランキングの精度向上が見込めるわけです。線形モデルや回帰木モデルの学習には、例えばliblinearやxgboostといった機械学習ライブラリが使えるかと思います (教師データは別途準備が必要ですが)。
ltr-pluginもここまで話してきたRankQueryを利用して実装されています。複雑なモデルを扱うために内部で利用されるスコア計算はかなり作り込まれた実装となっていますが、表面上の大雑把な流れはReRankQueryと大きくは変わりません。
まとめ
この記事ではSolrのランキングとそのカスタマイズで利用されるRankQueryについて紹介しました。
ランキングの精度は検索結果へのユーザの印象に直結するので、特にドキュメント数が多くて絞込が難しい環境では重要になるかと思います。今までのSolrは正直ランキング周りが貧弱な印象でしたが、Solr6.4からltr-pluginが導入されるとのことなので、ランキング問題が解消されてこのあたりの話題がコミュニティでも賑わってくるのかなぁ、と期待します。
一方で、「もっとヤングでナウい俺様ランキングをSolrで使いたい!」という稀有な人はRankQueryを使って機能を実装することになるかと思います。そんな時にこの記事の内容が少しは役に立てば幸いです。