ファインディ株式会社で機械学習エンジニアをしている真保と申します。
今回は、行列分解の応用手法であるiALSを用いた推薦システムの実装について解説していきます。
現在でも推薦システムの分野では、線形モデルが強力とされていますが、その中でもiALSは原著論文によるとEASEやSLIMなどの推薦システムモデルと比較して、Recallは0.01~0.04上回るというベンチマークも存在しています。iALSは2022年に発表された論文で成果が示されました。
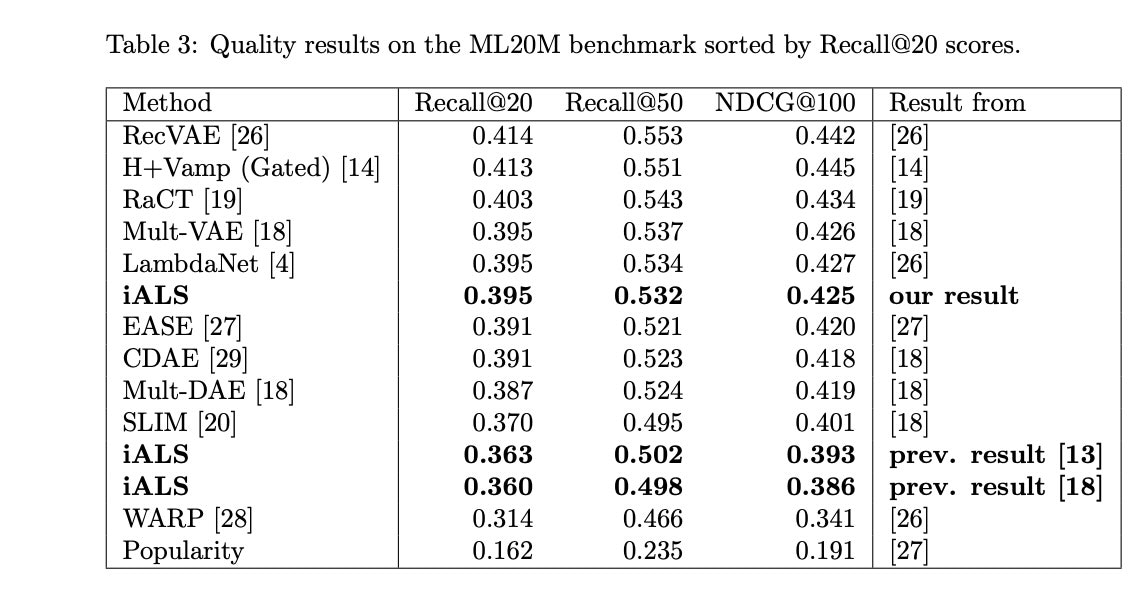
引用:Revisiting the Performance of iALS on Item Recommendation Benchmarks Table3より
既存の推薦システムで使用されるアルゴリズムは数多くありますが、iALSのハイパーパラメータを適切に調整することで、従来の精度を超えることが明らかになっています。
使用するデータセット:MovieLens20m
元論文:https://arxiv.org/abs/2110.14037
コード:https://github.com/google-research/google-research/tree/master/ials
iALS評価の経緯
現在、業務で機械学習システムによる推薦システムの開発に携わっています。そのため、モデル選定から担当しており、様々なモデルを評価して最適なものを実装しようとしています。推薦システムの中でも、解決すべき課題の1つがコールドスタート問題です。これは、新規ユーザー(学習していないデータ)に対して適切な推薦ができないという問題です。
コールドスタート問題は推薦システムにおいて避けて通れない課題ですが、Matrix Factorization(行列分解)系のモデルであるiALSがコールドスタート問題に対処できる可能性があります。そのため、今回は他のモデルと一緒に評価し、実装を検討することにしました。
ALSモデルについて
iALSを理解するためには、ベースとなるALS(Alternating Least Squares)についても理解する必要があります。
ALSは、行列分解を使用してアイテムとユーザーの特徴を抽出し、推薦を行います。
以下の図のように、ユーザーとアイテムの評価行列を2つの低次元の長方形行列の積に分解することで、ALSは機能します。
MF系のアルゴリズムは、特徴抽出から推薦を見つける手法であり、具体的にはアイテムとユーザーの間の評価行列を近似することを目指します。
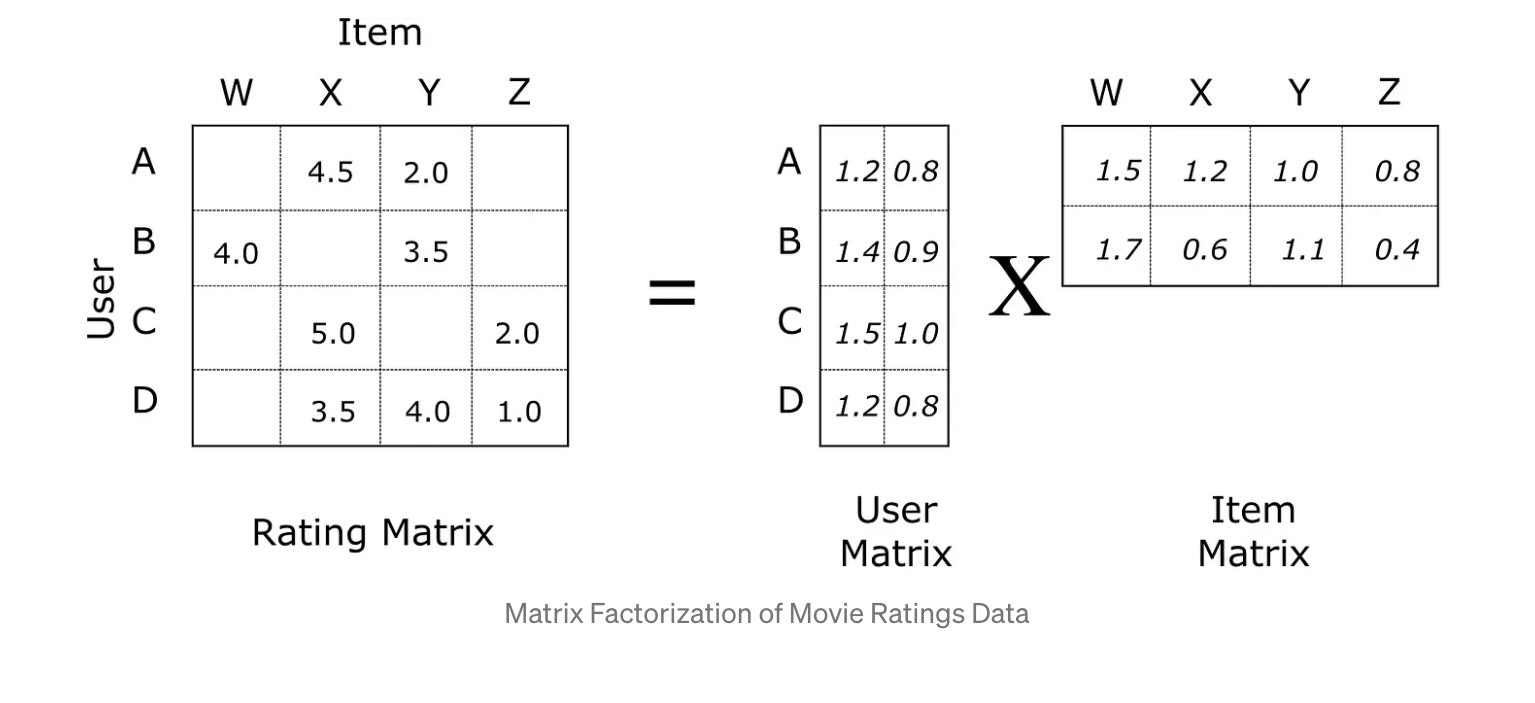
評価行列は、ユーザーがアイテムに与えた評価やフィードバックなどで、評価とはMovieLensで言うところのreviewなどです。
ALSは、評価行列を低次元の特徴空間に分解することで、ユーザーとアイテムの特徴を学習します。
この分解を交互に行いながら、評価行列と近似行列の差を最小化するように学習を進めます。
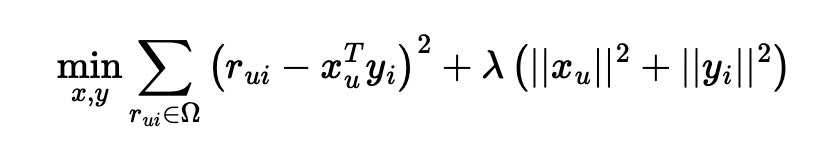
ALSは以下の手順で動作します:
- 1.ユーザーとアイテムの特徴ベクトルを初期化
- 2.ユーザーの特徴ベクトルを固定し、アイテムの特徴ベクトルを最適化
- 3.アイテムの特徴ベクトルを固定し、ユーザーの特徴ベクトルを最適化
- 4.上記のステップを繰り返し、評価行列と近似行列の差が最小となるように特徴ベクトルを調整
ALSは、行列の特異値分解と同様に次元削減を行うため、疎な評価行列を補完し、欠損値を予測することができるという特徴もあります。このようにして得られた近似行列を使用して、ALSはユーザーに対してアイテムの推薦を行います。
詳しくはimplicitのドキュメントが役立ちます。
https://github.com/benfred/implicit
iALSモデルとは?
iALS(Implicit Alternating Least Squares)は、ALSの応用的な位置付けのモデルです。
ユーザーの行動履歴などの暗黙的なフィードバック情報を利用して、推薦を行います。
通常のALSは、ユーザーがアイテムに対して明示的な評価を与える場合に適用されますが、
iALSはユーザーの行動履歴などの暗黙的なフィードバック(例:クリック、閲覧、購入履歴など)を扱います。
暗黙的・明示的と言うとわかりにくいですが、
明示的=意識下の行動、暗黙的=無意識下の行動とするとわかりやすいと思います。
暗黙的なフィードバックでは、ユーザーが関心を持っているアイテムは明示的に評価されない場合がありますが、ユーザーの行動からその関心度を推定することができます。
実際に計測されたデータは無意識下の行動、つまり、暗黙的なフィードバックであることも多々ありますので、実践的なモデルとも言えるかもしれません。
ALSとの違いは、評価行列ではなく、ユーザーとアイテムの関連性を示す行列を作成します。
行列には、ユーザーのアイテムへの行動回数や重み付けなどの情報も含まれることがあります。
iALSは、以下の手順で動作します:
- ユーザーとアイテムの特徴ベクトルを初期化
- ユーザーの特徴ベクトルを固定し、アイテムの特徴ベクトルを最適化(この際、ユーザーがアイテムに対して行った暗黙的なフィードバックの重みを考慮)
- アイテムの特徴ベクトルを固定し、ユーザーの特徴ベクトルを最適化同様に、ユーザーの行動パターンの重みを考慮します。
- 上記のステップを繰り返し、関連性行列と近似行列の差が最小となるように特徴ベクトルを調整します。
暗黙的なフィードバックを取り扱うため、ユーザーの関心や嗜好を推測し、パーソナライズされた推薦を提供することができます。
下記は論文内のモデル定義です。
class IALS(Recommender):
"""iALS solver."""
def __init__(self, num_users, num_items, embedding_dim, reg,
unobserved_weight, stddev):
self.embedding_dim = embedding_dim
self.reg = reg
self.unobserved_weight = unobserved_weight
self.user_embedding = np.random.normal(
0, stddev, (num_users, embedding_dim))
self.item_embedding = np.random.normal(
0, stddev, (num_items, embedding_dim))
self._update_user_gramian()
self._update_item_gramian()
def _update_user_gramian(self):
self.user_gramian = np.matmul(self.user_embedding.T, self.user_embedding)
def _update_item_gramian(self):
self.item_gramian = np.matmul(self.item_embedding.T, self.item_embedding)
def score(self, user_history):
user_emb = project(
user_history, self.item_embedding, self.item_gramian, self.reg,
self.unobserved_weight)
result = np.dot(user_emb, self.item_embedding.T)
return result
def train(self, ds):
"""Runs one iteration of the IALS algorithm.
Args:
ds: a DataSet object.
"""
# Solve for the user embeddings
self._solve(ds.user_batches, is_user=True)
self._update_user_gramian()
# Solve for the item embeddings
self._solve(ds.item_batches, is_user=False)
self._update_item_gramian()
def _solve(self, batches, is_user):
"""Solves one side of the matrix."""
if is_user:
embedding = self.user_embedding
args = (self.item_embedding, self.item_gramian, self.reg,
self.unobserved_weight)
else:
embedding = self.item_embedding
args = (self.user_embedding, self.user_gramian, self.reg,
self.unobserved_weight)
results = map_parallel(solve, batches, *args)
for r in results:
for user, emb in r.items():
embedding[user, :] = emb
iALSのハイパーパラメータ
今回の論文では、重要な役割を果たすiALSのハイパーパラメータについて説明します。
実際には、iALSの改善はこのパラメータを調整して精度を向上させることに関わります。
そのため、論文の内容を完璧に把握する必要はありませんが、ハイパーパラメータを調整して従来の精度を上回ることを理解しておくことが重要です。
パラメータはコード内でモデルによって定義されているため、使用する際には問題ありませんが、理解のためにパラメータの概要を説明します。

引用:Revisiting the Performance of iALS on Item Recommendation Benchmarks Table1より
論文では、以下の5つのパラメータがチューニングすべきと述べられています。下記パラメータはコード内の変数名で記載されています。
- embedding_dim (埋め込み次元数)
- reg(正則化)
- unobserved_weight(未観測の重み)
- num_iterations (イテレーション数)
- stddev(埋め込みのノルム調整用標準偏差)
embedding_dim(埋め込み次元数)
一番性能に影響すると言われているのは、埋め込み次元数です。 これはデータを埋め込みベクトルに変換する際の次元数を指します。論文でも解説されていますが、次元数が小さすぎると精度が低下しやすいとされています。
そのため、通常、iALSでも次元数の設定には注意が必要です。ただし、次元数の調整には正則化も関与することも明記されています。Movielens 20Mデータセットでは、2000次元の埋め込みが最良の結果となっているようです。
これを聞くと、次元数が非常に大きく設定されている印象を受けるかもしれませんが、実際に他の行列分解モデルでも次元数を大きめに設定すると精度が改善する傾向があるようです。論文では、おすすめの調整方法として、まず中程度の埋め込み次元(例えばd = 128)を使用しておおまかな見積もりを得た後、他のハイパーパラメータの調整においてより大きな埋め込み次元を使って詳細な探索を行うことが良いとされています。
reg[regulation] (正則化)
正則化のパラメータがありますが、L2ノルムを使用した正則化です。これは過学習を防ぐためのペナルティであり、他のモデルでも一般的に使用されています。そのため、詳細な説明は必要ないと思います。論文では、Frequency scaled Regularization(vで表記)を1に設定することでより良い評価が得られたと報告されていますが、データによって調整が必要な場合もあります。
unobserved_weight (未観測の重み)
本論文で一番難解な部分です。このパラメータはあまり一般的には聞かないものであるので、おおまかに理解して使用することにしました。 未観測の重みと正則化はiALSにとって重要なパラメータであり、非常に注意深く扱う必要があるようです。 これらのパラメータは、平方損失(LS)、ロジスティック損失(LI)、および正則化(R)の3つの損失要素のバランスを制御しています。未観測の重みと正則化は一緒に調整する必要があるようです。
論文には次のようにあります。
'LSとLIの観測された誤差値は桁数の差が数段あってはなりません。
また、大きな埋め込み次元の場合、一定の正則化が必要です。そのため、R、LS、およびLIの値は同じ桁数のオーダーを持つべきです。未観測重みの設定では、行列の疎さの程度を考慮する必要があります。通常、未観測重みは1.0より小さくなります。行列がより疎な場合、指数グリッド(例:α0 ∈ {1, 0.3, 0.1, 0.03, 0.01, 0.003})で未観測重みを始めることが推奨されます。正則化に関しては、出発点として λ∗ ∈ {0.1, 0.03, 0.01, 0.003, 0.001, 0.0003} が良いです。'
基本的には上記に従って調整を進めました。なかなかに説明が難しいので、構造を詳しく知りたい方は、論文で定義されている学習モデルのクラスを参考にしてください。
num_iterations (イテレーション数)
イテレーション数は、他のモデルと同様に、モデルの学習を繰り返す回数を指します。 大きな値を設定しても精度に大きな変化は見られませんが、実行時間に影響が出るため、調整が必要です。論文では、最初に16回から始めて徐々に増やしていくことが良いと述べられています。
したがって、精度と時間を考慮しながら、値を大きくしたり小さくしたりして調整しています。
stddev (埋め込みベクトルのスケーリング用標準偏差)
埋め込みベクトルをスケーリングするための標準偏差も設定します。ただし、このパラメータは他のものに比べて感度は低いようです。
ある程度大まかな調整でも良さそうです。
ただし、上記5つのパラメータをALSを構築できるライブラリで上記のパラメータは調整できません。 pysparkやimplicitというiALSモデルをトレーニングすることは可能ですが、実際に論文と同じようなパラメータの調整はできない仕様になっています。
実装に関しては、論文のコードを使用してください。
https://github.com/google-research/google-research/blob/master/ials/ncf_benchmarks/ials.py
データの作成方法
論文の内容を実装する際には、Readmeを参考にすることを推奨します。 ただし、その方法では既存のデータをダウンロードしてから評価を行うため、そのデータに合わせてDatasetも定義されています。 自分のデータで論文の内容を実行する場合は、手間はかかりますがデータを加工する必要があります。class DataSet:
"""A class holding the train and test data."""
def __init__(self, train_by_user, train_by_item, test, num_batches):
"""Creates a DataSet and batches it.
Args:
train_by_user: list of (user, items)
train_by_item: list of (item, users)
test: list of (user, history_items, target_items)
num_batches: partitions each set using this many batches.
"""
self.train_by_user = train_by_user
self.train_by_item = train_by_item
self.test = test
self.num_users = len(train_by_user)
self.num_items = len(train_by_item)
self.user_batches = self._batch(train_by_user, num_batches)
self.item_batches = self._batch(train_by_item, num_batches)
self.test_batches = self._batch(test, num_batches)
def _batch(self, xs, num_batches):
batches = [[] for _ in range(num_batches)]
for i, x in enumerate(xs):
batches[i % num_batches].append(x)
return batches
手元のCSVなどのデータフレームを使用する場合、上記の定義に合わせてデータを作成しました。
データのイメージは、ユーザーとアイテムがそれぞれ推薦されたものに対応しているため、リスト形式のデータを作成します。
item_data = [[user_id1,[item_id1,item_id2,item_id3],
[user_id2,[item_id3],...]
item_data = [[item_id4,[user_id1,user_id2,user_id3],
[item_id6,[user_id4,user_id5],...]
実装と他のモデルとの評価比較
実際にデータを使用して、iALSを評価し、他のモデルの結果と比較します。 業務では自社データを扱っていますが、ここでは評価のためにMovielens20Mデータを使用します。 評価はALS、iALS、NNの3つのモデルで行い、評価指標はndcgスコアを使用します。ALSはpythonライブラリのimplicitで実装、iALSは論文のモデルで実装、NN系はPytorchで実装しています。
implicitというので、暗黙的フィードバックは与えられるようですが、基本的にALSで少しパラメータがいじれるという感じでした。
どのモデルもパラメータ探索を行っていますが、NNやiALSは計算時間の制約から大まかに調整しています。
継続的な調整により、さらなる精度向上が期待できるかもしれません。
| ndcg | ndcg@10 | ndcg@30 | |
|---|---|---|---|
| ALS | 0.162 | 0.131 | 0.106 |
| iALS | 0.268 | 0.211 | 0.164 |
| NN | 0.265 | 0.231 | 0.155 |
論文よりも精度は出てませんが、確かにALSよりもiALSの方が良い結果になりました。
論文実装の所感
iALS論文は国内でも紹介されておりに、推薦システムは「今だに線形モデルが有用である」という意見は多々あります。
paper with codeを見ても、Deep系は流石に多くなりますが、意外に線形モデルのパフォーマンスも上位に来てたりします。データの種類によっては良いということでしょう。
しかし、業務で使用するためのモデルとして実装を試みましたが、パラメータチューニングも感度が高いものをいじると、精度も定まらないという難しさを感じました。
論文からの実装なので、プロダクトに組み込む工数を考えると、検討するモデルの1つという位置付けになりそうです。(特に埋め込み次元数を増やすと、結構計算に時間がかかります。)
「コールドスタート問題を対処できるか?」という点については、確かにユーザーやアイテム単体ではなく、特徴ベクトルで学習するという特徴があるので、理論としては正しいと思います。
しかし、試してみるとモデルの精度、説明性や使いやすさを考えると、回帰の方が良さそうという感じでもありました。
ただし、線形モデルがまだ強力でかつ使いやすいというのは事実としてあるので、
今後も面白そうな線形モデルがあったら評価していきたいと思います。