Spark DataFrameはいろいろな形に化ける
DatabricksやPysparkを使っていると必ず扱うことになる、Spark DataFrame。
これはいろいろな形に化けるし、その化けた先から再度Spark DataFrameに戻すこともできたりします。
このいいところは、同じデータに対して、汎用スクリプト言語であるPythonと、データベース言語であるSQLを自由に使い分けられるということ。
Pythonのいいところ、SQLのいいところを両方使えます。Pythonで無理そうな処理にぶち当たったなら変換してSQLを使い、SQLじゃ非効率だと思えばPythonに切り替える、などなど。
ただ、その変換にあたって「これどのコマンド使えばいいんだっけ?」と迷い、そのたびに過去の自分が書いたスクリプトや公式ドキュメントを確認するのがちょっと無駄に感じたので、Spark DataFrameの変換チートシートを作成しました。
これで「Spark DataFrameエコノミー」(勝手に名付けた)を攻略していきましょう!
(もし内容にミスがあったら、ぜひコメントでご意見お願いします!書き直します。)
チートシート
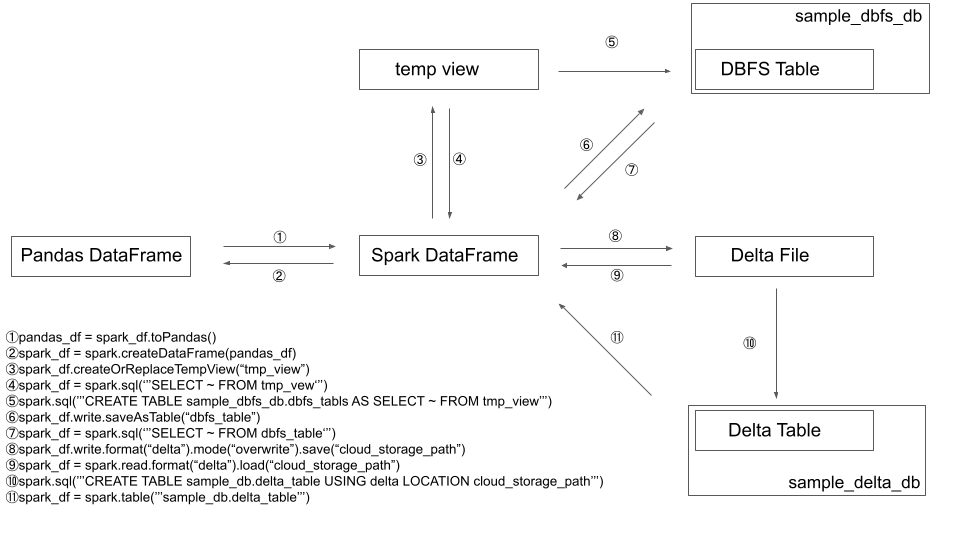
①pandas_df = spark_df.toPandas()
②spark_df = spark.createDataFrame(pandas_df)
③spark_df.createOrReplaceTempView('tmp_view')
④spark_df = spark.sql('''SELECT ~ FROM tmp_vew''')
⑤spark.sql('''CREATE TABLE sample_dbfs_db.dbfs_tabls AS SELECT ~ FROM tmp_view''')
⑥spark_df.write.saveAsTable(“dbfs_table”)
⑦spark_df = spark.sql('''SELECT ~ FROM dbfs_table''')
⑧spark_df.write.format('delta').mode('overwrite').save('cloud_storage_path')
⑨spark_df = spark.read.format('delta').load('cloud_storage_path')
⑩spark.sql('''CREATE TABLE sample_db.delta_table USING delta LOCATION 'cloud_storage_path' ''')
⑪spark_df = spark.table('''sample_db.delta_table''')
中心に位置するSpark DataFrameの変数名は、今回「spark_df」とします。snake_case派なんです…
それぞれ軽く説明
①pandas_df = spark_df.toPandas()
Spark DataFrameをPandas DataFrameに変換する際に使います。
データフレームと言うと「ああPandasね」と言われるくらい、知名度的には断然Pandasが上だと思いますし、そのコマンドに慣れている人も多いのではと思います。そんなときに便利。
ちなみにKoalasやPySpark.Pandasを使うとPysparkのままPandasライクなコマンドを使うことができるので、今後は
②spark_df = spark.createDataFrame(pandas_df)
Pandas DataFrameで処理後、Spark DataFrameに戻すときに使います。
③spark_df.createOrReplaceTempView('tmp_view')
Spark DataFrameをテンポラリビューに変換します。こうすることで、ビューなのでSQLを使って処理をすることができます。
「2つのデータフレームを結合するのに、結合にはSQLのほうが慣れてる…」というときは、結合する両方をこれでtmp_viewに変えるとよいです。
テンポラリ(一時的)なので、Databricksクラスターを終了すると消えてしまう儚いヤツです。
④spark_df = spark.sql('''SELECT ~ FROM tmp_vew''')
テンポラリビューをSpark DataFrameに戻すときに使います。
spark_df = spark.sql('''<SQL文>''')
.sql() のカッコの中にSQL文を書くことで、加工した結果がSpark DataFrameに格納される、みたいなイメージです。
そう、PySparkはそのなかでSQLを書くことができるので、だんだん慣れてくるとビュー化する頻度は減ると思います。
SQLも優しく受け入れる懐深いPyspark!
⑤spark.sql(’’’CREATE TABLE sample_dbfs_db.dbfs_tabls AS SELECT ~ FROM tmp_view’’’)
テンポラリビューを"テーブルとして"DBFSに登録するコマンドです。
個人的にあんまり使わないです。
⑥spark_df.write.saveAsTable(“dbfs_table”)
Spark DataFrameを"テーブルとして"DBFSに登録するコマンドです。ここで作成されるテーブルはマネージドテーブルとも呼ぶらしいです(Databricks側がファイルの置き先を決める)。
こうすると、任意のDatabricks上のデータベース上に登録はされるのですが、アクセス制限のないDBFS上(ワークスペースのユーザなら誰でも参照できる)にテーブルの実態であるDeltaのファイルが保存されるので、データガバナンスができないというデメリットがあります。
このあと紹介する⑧を理解すれば、ほとんど使わなくなるコマンドかと思います。
⑦spark_df = spark.sql(‘’’SELECT ~ FROM dbfs_table‘’’)
コレもビューからDataFrameに戻すのと同じく、DBFSテーブルをSQLで加工処理した結果をSpark DataFrameとして扱うコマンドです。
⑧spark_df.write.format(“delta”).mode(“overwrite”).save(“cloud_storage_path”)
最も使うコマンドだと思います。これだけ覚えて帰ってください(笑)
僕はコレを理解できずに、結構長い間苦しみました…
pythonは()でくくることで、改行する際のバックスラッシュが不要になります。僕はこの書き方が好き
(
spark_df
.write
.format('delta')
.mode('overwrite')
.save('<cloud_storage_path>')
)
まず、DeltaLakeで扱う「Deltaテーブル」というのは、クラウドストレージ上にある「Parquetファイル+ログ・バージョン各種情報を付けたファイル」、つまり実態がファイルなんです。
その後、「このファイルは『〜』っていうテーブル名として扱うよ」と、このあと⑩で紹介するコマンドでテーブル名を名付けることで、テーブルとして扱うことができるという仕組みです。
流れとしては
Spark DataFrame
→(⑧)→クラウドストレージのファイルが出来上がる
→(⑩)→任意の名前を名付け、Deltaテーブルとして扱う(SQLが使える、RedashやTableauなどBIツールで使える)
なんですね。
ちなみに⑧は (変数名)=(処理)といったよく見る構文ではなく、Spark DataFrameに対して一方的にコマンドをくっつけている構文なので、最初は慣れませんでした…
上ではmodeにoverwrite(実行するごとに上書きする)を選択しましたが、このほかにもappendやcompleteなどいろいろなモードがあるので、よければ調べてみてください。
⑨spark_df = spark.read.format('delta').load('cloud_storage_path')
⑧のようなコマンドでクラウドストレージ上に作成したdeltaファイルをread(読み込み)し、Spark DataFrameとして扱います。
やはりDeltaLakeの世界でもキホンは読み、書き、そろばん(?)なんですね。
⑩spark.sql('''CREATE TABLE sample_db.delta_table USING delta LOCATION 'cloud_storage_path' ''')
さきほど紹介したように、⑧で作成したクラウドストレージ上のdeltaファイルを、deltaテーブルとして名付けます。
親になる前に名付けを体験することが出来ます。
spark.sql('''
CREATE TABLE <テーブルを保存するデータベース名>.<任意のテーブル名>
USING delta
LOCATION '<S3とかGCSとかのパス名 ここにあるファイルを元にテーブルを作る>'
''')
(<>はいらないので書かないでください)
自分でクラウドストレージのどこに置くかを決めるので、アンマネージドテーブルとも呼ぶそうな。
⑪spark_df = spark.table('''sample_db.delta_table''')
これは僕も最近知りました!
deltaテーブルを.table('''<データベース名.テーブル名>''')で読みこみ、Spark DataFrameとして扱うことができるのです。
一度Deltaテーブルにしたものを別NotebookでSpark DataFrameとして扱いたい…というとき、Deltaファイルをreadする⑨の方法とは別にこんなやり方もあるよ、的に認識しています!
また、これは一方通行で、Spark DataFrameを直接アンマネージドテーブルにすることはできないようです。