"Envision: Benchmarking Unified Understanding & Generation for Causal World Process Insights"
(因果的世界プロセスの洞察に向けた統一的理解と生成のベンチマーク)
という論文を紹介します。
日本語訳がやや難しくなりましたが、要するに、
生成 AI は様々な状況の画像を創り出すことは可能であるが、その原因と結果は区別できない曖昧さがある。
ということです。
例えば、雨が降る→地面が濡れる→水たまりができる→蒸発する、のような動的な過程の性質を捉えていない、という主張です。
「動画はつくれるのだからそんなはずないだろう」と思うかもしれませんがこのような主張をする根拠があります。
2025年12月2日公開 Shanghai Artificial Intelligence Laboratory
記事内の画像はすべて論文内のものです
なぜ因果を捉えていないのか?
この論文の対象になっているのは T2I( Text-To-Image )モデル、T2V( Text-To-Video )モデル の技術です。特に T2I が対象で、そのスペクトラムとして T2V を取り上げています。
問題として取り上げているのは、現実世界の出来事が展開する動的プロセスを制御・理解する能力を欠いているということです。
その理由は、本質的に静止画像は時間的な方向性を持たず、ある状態がどのように生じ、どのような結果として現れたのかを区別できないためです。
では、生成された動画はなぜ自然に見えるのか?
2つの主張があります。
1. 視覚的相関を学んでいるから
見た目の連続性や画素の局所的な遷移が得意なだけ
2. 時間的一貫性と因果的一貫性を区別できるから
フリッカーが少なく、動きが自然であるのは時間的一貫性 (spatiotemporal continuity) を満たしているだけでなぜその変化が起きたのかが説明できるかは説明していない
結局は「因果と相関は違う」という統計の教科書的な話という理解です。
Envision:因果的なイベント進行を評価する
この研究のビジョンは生成モデルは世界知識を真に内在化し、それを制御できる能力を備えるべきであるというものです。
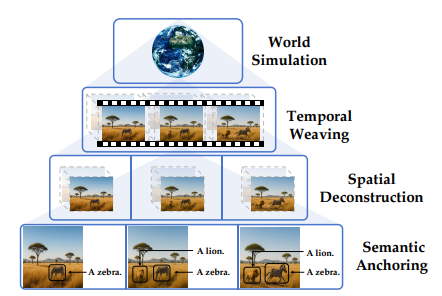
そこで、因果を理解しているかを区別するための方法として、Envision と命名されたベンチマークを提案しています。
“Envision is a comprehensive benchmark centered on multi-image generation that compels models to generate the event process image by image.”
Envision は、モデルにイベントの進行を画像ごとに生成させることを強制する、複数画像生成を中心とした包括的ベンチマークである。
モデルに対して静的なパターンマッチングではなく、イベントの進行が破綻していないかを評価することで因果を理解しているかの結論を出すというわけです。

マルチイメージフレームワーク(Multi-Image Framework)
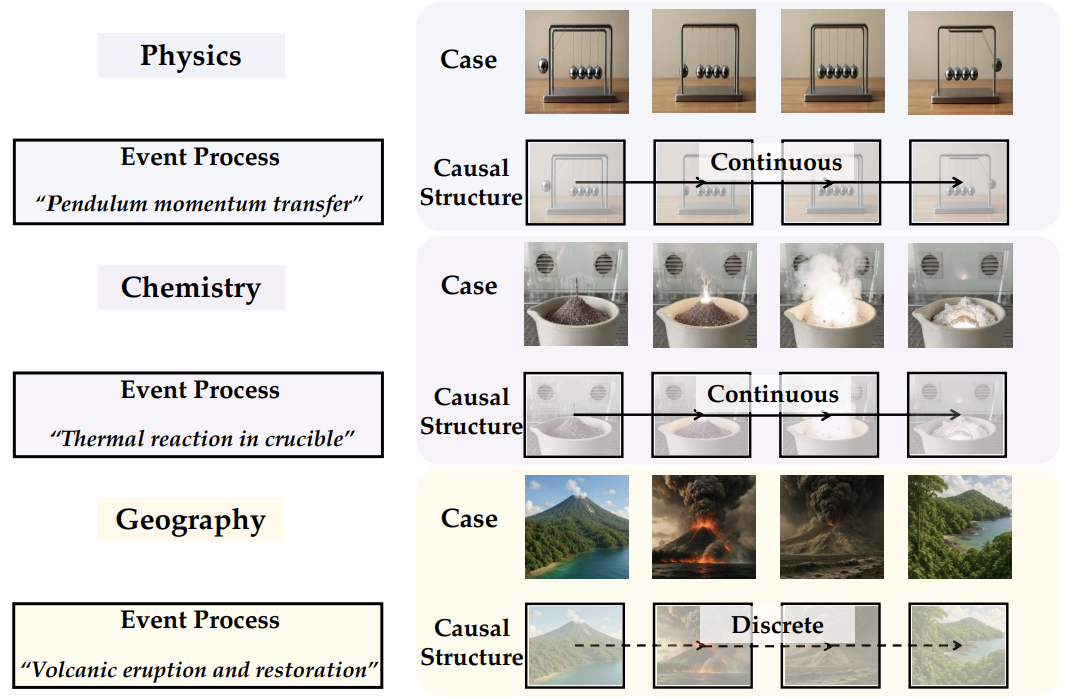
連続的・離散的いずれのイベント表現にも適応可能なフレームワーク。
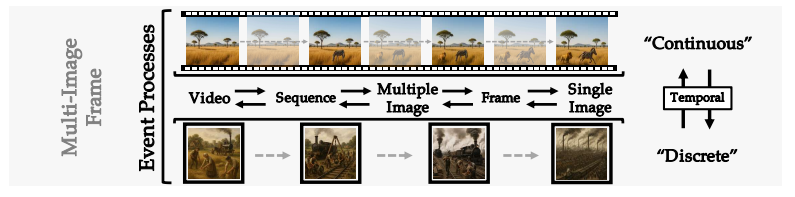
連続的な時間変化では、モデルは、保存則に従い物理的に一貫した滑らかな遷移を生成することが求められます。一方で、離散的な文脈においては、時間解像度に飛躍が生じたとしても、論理的な進行を維持しなければならないです。この双方を扱うモデル能力を厳密に評価するというものです。
双方向検証(Bidirectional Verification)
T2I モデルに対して 理解(understanding)と生成(generation)の相互作用を厳密に検証する双方的な評価。
- 順方向(Understanding → Generation) では、モデルが内在化した世界知識および因果推論能力が体系的に検証される
- 逆方向(Generation → Understanding) では、生成行為そのものが理解を深化させる分析的なメカニズムとして機能する
世界知識データセット群
Envision は、自然科学と人文学史の2つの主要ドメインを基盤として構築されており、現実世界の出来事を中心に、学術教科書およびオンライン資料から厳選された情報を用いています。物理、地理など対象とする分野は合計6分野。
生成の概要
こちらは失敗例です。

正しくない状態になっている、物理的に成立しない、曖昧、など。
こちらが上手く説明できている例です。
- Continuous: 連続的
- Discrete:離散的

因果を理解していないからはちゃめちゃな動画になる?
たしかに生成 AI は因果を理解しているとは思えない動画をつくるのは得意だと感じます。
モデルに関しては、特定の分野だけスコアが悪いということはなく、GPT など規模の大きいモデルのスコアは高いです。
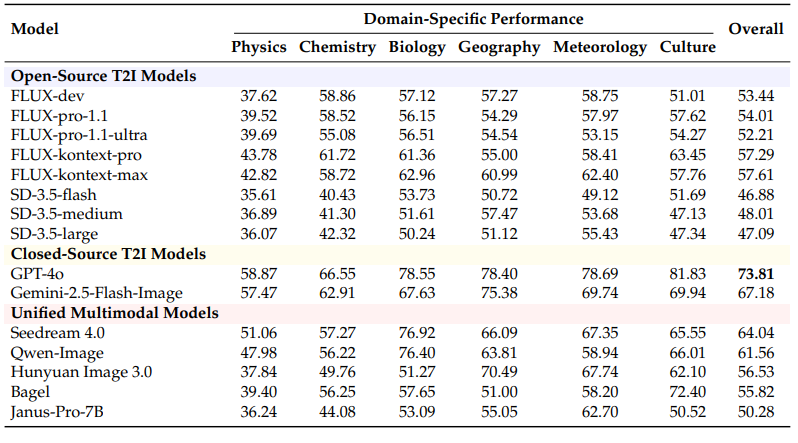
このチームが目指す「世界をシミュレーション可能なモデルの構築」は、やはり巨大なデータセットを持つ会社が最も有利だと言えそうです。