はじめに
こんにちは、レアゾン・ホールディングスでエンジニアをしているYuto Moriです。
Agent Development Kit(以下、ADK)では、手軽にAgentを作成することが可能です。一方で、作成されたAgentが正しい動作をしているのか、適切な回答を出力できているか、などシステム開発と同じくテストや評価が必要です。今回はADKの機能の一つであるEvaluateについて解説します。
主な評価の流れ
- *.evalset.jsonで定義した入力文とその回答過程で使用されたツール、およびAgentの回答結果を記述
- 上記の定義と実際の実行結果を評価
- 評価基準は、ツール利用の一致率と回答結果の類似度(ROUGE)
少しわかりづらいので、実際にAgentを作成しながら見ていきましょう。
Dice agentの作成
今回はダイスを振るエージェントを使用して、正しい振る舞いが可能かどうかを判定します。
ダイスエージェントは公式が提供しているサンプルからお借りします。
Evalsetファイルの作成
想定される入力文とその回答過程で使用されたツール、およびAgentの回答結果を記述します。要するにAgent版のテストコードのようなものです。
手動で書くこともできますが、adk webで作成する方が楽です。
dice agentのEvalsetファイルを作成してみましょう。
adk webを起動します。
adk web
# uvを使用してる場合
uv run adk web
6面ダイスをひとつ振るように指示します。
Roll a 6-sided die.
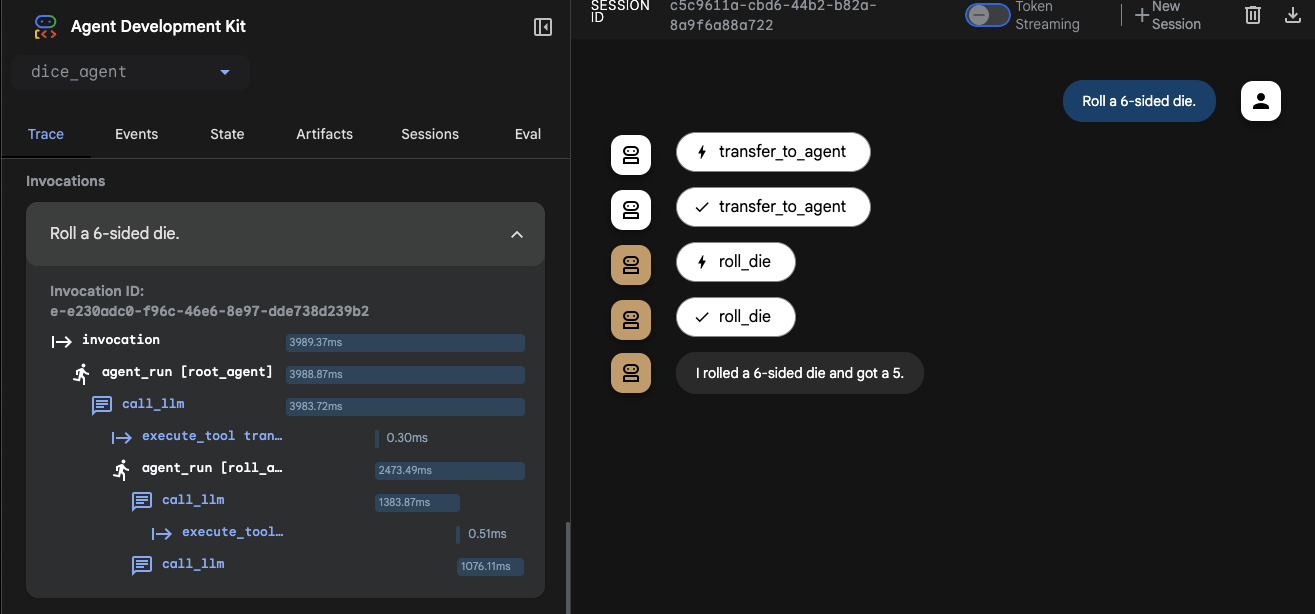
Agentの処理フローは以下の通りです。
-
root_agentがsub agentであるroll_agentにダイスを振るように指示 -
roll_agentがroll_dieツールでダイスを振る - ツールの回答を基に
roll_agentがユーザに回答
1. Evalsetファイルの作成
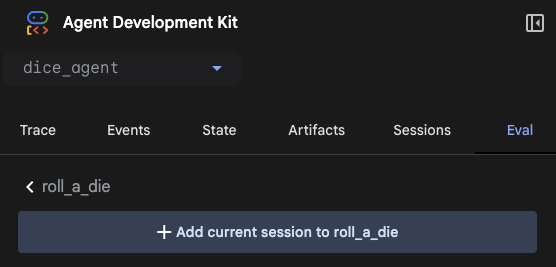
EvalタブにあるCreate Evaluation Setをクリックします。
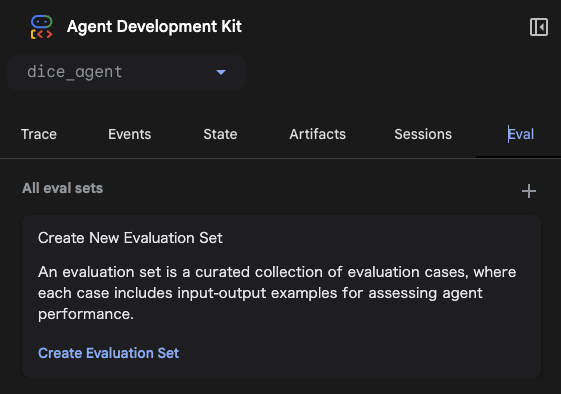
名前は任意です。dice_agent/<任意の名前>_evalset.jsonというファイルが作成されます。例として、roll_a_dieという名前で作成します。
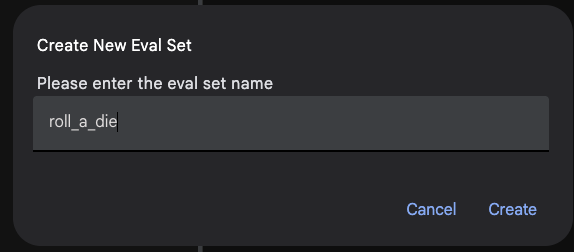
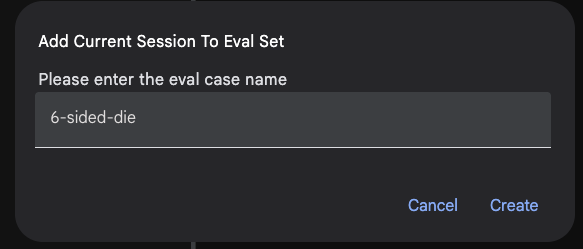
Evalタブに作成されたEval Setをクリックし、+ Add current session to roll_a_dieをクリックすることで、現在のセッション(ユーザの質問からAgentの最終回答まで)を作成したファイルに書き出します。例として、6-sided-dieという名前でcaseを作成します。
これで6面ダイスを振るタスクのEvalsetファイルが作成できました。
ファイルには、ユーザの質問や最終回答、回答出力に使用したtoolなどが記載されています。
実際に作成された roll_a_die.evalset.json
{
"eval_set_id": "roll_a_die",
"name": "roll_a_die",
"description": null,
"eval_cases": [
{
"eval_id": "6-sided-die",
"conversation": [
{
"invocation_id": "e-e230adc0-f96c-46e6-8e97-dde738d239b2",
"user_content": {
"parts": [
{
"video_metadata": null,
"thought": null,
"inline_data": null,
"file_data": null,
"thought_signature": null,
"function_call": null,
"code_execution_result": null,
"executable_code": null,
"function_response": null,
"text": "Roll a 6-sided die."
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"video_metadata": null,
"thought": null,
"inline_data": null,
"file_data": null,
"thought_signature": null,
"function_call": null,
"code_execution_result": null,
"executable_code": null,
"function_response": null,
"text": "I rolled a 6-sided die and got a 5."
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [
{
"id": "adk-b7cf0c58-74e4-4f58-be01-f5fafa9e8d78",
"args": {
"agent_name": "roll_agent"
},
"name": "transfer_to_agent"
},
{
"id": "adk-079fd259-fcbe-4474-b034-812e9dfbcf89",
"args": {
"sides": 6
},
"name": "roll_die"
}
],
"tool_responses": [],
"intermediate_responses": []
},
"creation_timestamp": 1757823142.786064
}
],
"session_input": {
"app_name": "dice_agent",
"user_id": "user",
"state": {}
},
"creation_timestamp": 1757823608.789702
}
],
"creation_timestamp": 1757823450.95623
}
2. Custom Metricsで評価を実行
作成したCaseにチェックを入れて、Run Evaluationで実行します。
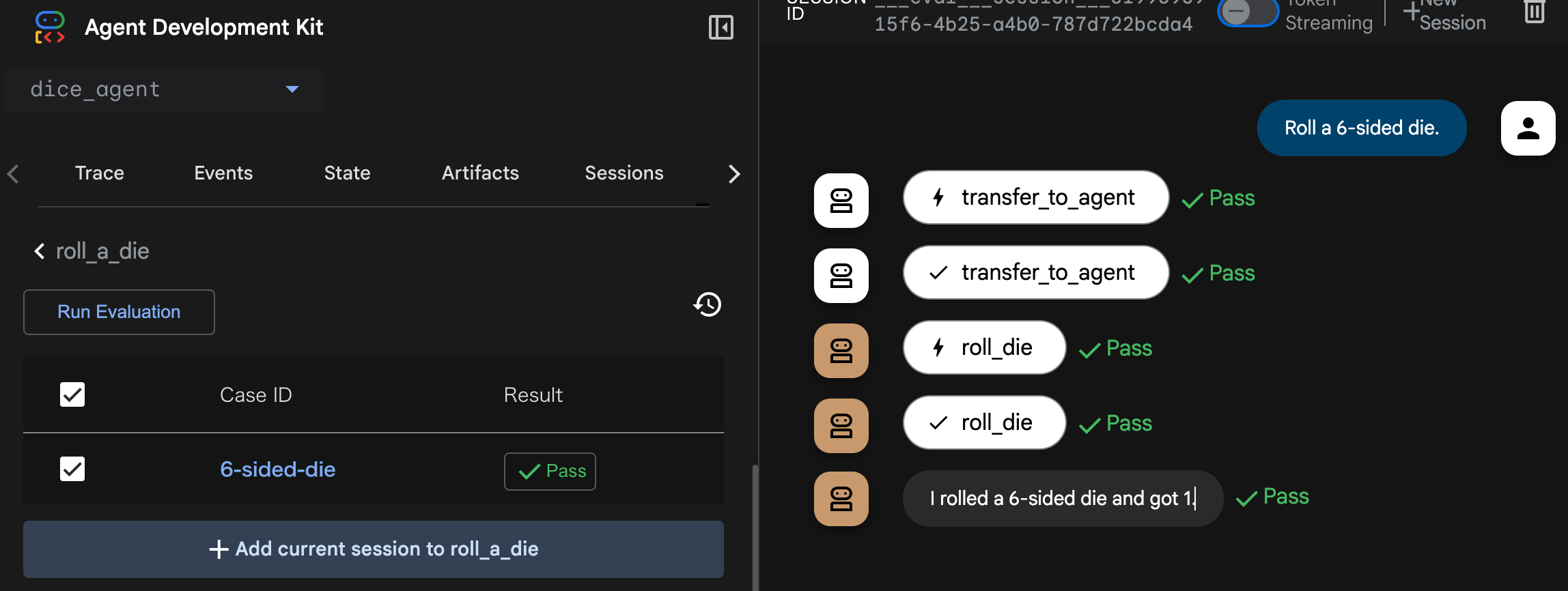
Result欄でテストにPassしたかどうかがわかります。
評価軸は以下の2種類です。
-
Tool trajectory avg score: Evaluationを実行した時のエージェントの実際のツール履歴が定義されたツール利用履歴を比較します。一致するツール利用には1点、一致しないステップには0点を与えて、平均点を最終スコアとして判断します。 -
Response match score: Eval Setに定義された最終出力とEvaluationで実行された結果の類似度をスコアとして出力します。類似度にはROUGEを採用しています。
Custom Metricsはrouge-scoreライブラリのROUGE-1を採用しています。ROUGE-1では生成文と正解文の間で共通して出現する単語の数のF1値で算出しています。一方で、以下のような短所があります。
-
単語の順序を無視する: 「AがBを叩いた」と「BがAを叩いた」は、ROUGE-1では同じ単語の組み合わせとして評価されるため、文の意味の違いを捉えることができません。
-
同義語を考慮しない: 「生徒」と「学生」のように意味が同じでも、異なる単語として扱われます。
現時点では別の評価基準を追加することは不可能です。個人的には出力フォーマットなどのテストや出力結果の妥当性をLLMが評価するLLM as a judgeなどがあればより便利に使えそうだなと感じました。
adk evalで評価
上記の評価はCLI上でも実行可能です。CIなどの自動化に含めるときに便利そうです。
adk eval dice_agent dice_agent/roll_a_die.evalset.json
# adk eval <Agentのフォルダ名> <Evalsetのファイル>
終わりに
今回はADKの機能であるEvaluateについて解説しました。
AIエージェントは画期的な技術ですが、その挙動が常に期待通りとは限りません。だからこそ、開発プロセスにおいて「正しいガードレール」、すなわち継続的なテストと評価が不可欠です。
ADKのEvaluate機能は、エージェントの動作の正確性や応答の妥当性を自動でチェックするための強力なツールです。
本記事が、皆様の堅牢で信頼性の高いAIエージェント開発の一助となれば幸いです。
▼新卒エンジニア研修のご紹介
レアゾン・ホールディングスでは、2025年新卒エンジニア研修にて「個のスキル」と「チーム開発力」の両立を重視した育成に取り組んでいます。 実際の研修の様子や、若手エンジニアの成長ストーリーは以下の記事で詳しくご紹介していますので、ぜひご覧ください!
▼採用情報
レアゾン・ホールディングスは、「世界一の企業へ」というビジョンを掲げ、「新しい"当たり前"を作り続ける」というミッションを推進しています。 現在、エンジニア採用を積極的に行っておりますので、ご興味をお持ちいただけましたら、ぜひ下記リンクからご応募ください。