はじめに
まずは簡単に自己紹介させてください。
私は大学で工学(化学系)を学び、一般企業で研究員として働いて5年目になります。
今回会社から半年間の育休をもらえたので、育児の合間をぬってプログラミングを勉強することにしました。
はじめるに至った動機ですが、YouTubeで「最近は簡単にプログラミングを学べる」といった動画を多く目にし、
大学時代に少し触ったことがあったのも相まって、思い切って3か月間オンラインスクールに通うことにしました。
本記事の概要
-
どんな人向けの記事か
完全に初心者向けです。今からプログラミングを始めてみようという人に読んでもらいたいです。
どうやってオンラインスクールを選び、何を学んだのかということから書いています。
- **この記事で挑戦したこと** 3か月の受講期間で学んだ技術の中で、面白いなと思ったコードを、自分で題材を決めて動かしてみました。 具体的には、月別の犯罪者数を予測してみました。 はじめはLSTMモデルで予測してみたのですが、精度がいまいちだったため、機械学習を用いて予測してみました。
オンライン学習の振り返り
-
なぜAidemyを選んだのか
オンラインスクールを選ぶにあたり、たくさんの選択肢がありました。
それぞれHPを見に行ったのですが、転職成功率等のビジネスよりの広告が最も少なかったAidemyに決めました。
今回は転職のためのスキルを磨くというよりは、純粋に流行の機会学習やデフィープラーニングってどんなの?
という感情が大きかったので、結果的にこの選択は良かったです。
また、代表の方がホリエモンチャンネルに出演していたり、ヨビノリのたくみ先生が推していたのも大きかったですね。
- **Aidemyで学んだこと** 私はデータ分析コースだったのですが、 Premium Planというものを選択したので、他コースの教材も+αで学ぶことができました。 幅広く勉強できて、大変満足できるものでした。私が学習したことを簡単に書いておきますね。 (1)Numpy、Pandas、Matplotlib、データクレンジング、データハンドリング (2)教師あり学習、教師なし学習 (3)時系列分析、株価予測、kaggleのコンペ(タイタニック号、住宅価格予測) (4)自然言語処理、トピック抽出、感情分析 (5)深層学習画像認識
【本題】犯罪者数の予測
** ●犯罪者数**
さて本題です。 今回は月別の犯罪者数を予測してみることにしました。まずは、LSTMモデルでの予測を行います。
使用するデータはe-Statという政府の統計を管理しているページから引っ張ってきました。
この中の「罪名別被疑事件の処理人員(2007年1月~2018年1月)」の数字を扱います。
※「犯罪認知件数」という言葉の方が一般的かもしれませんが、
犯罪を件数単位ではなく、人数単位でカウントしたかったのでこの統計を選びました。
** ●データの読み込みとindex,columnsの除去**
使用するデータは先頭Sheetの先頭列です。
また、取り出したデータの値はLSTMでの分析に適合させるため、float型に変換して読み込みます。
# データの読み込み
dataframe = pd.read_excel('./blog_data/criminal_prediction.xlsx', sheet_name=0, usecols=[0])
# index,columns除去
dataset = dataframe.values
# float型に変換
dataset = dataset.astype('float32')
** ●トレーニングデータ・テストデータの作成**
前半の2/3をトレーニング用、残りの1/3をテスト用に分ける操作を行います。
トレインデータが89個、テストデータが44個です。
# トレーニングデータにするデータ件数を算出
train_size = int(len(dataset) * 0.67)
# トレーニングデータ、テストデータに分割
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
print(len(dataset), len(train), len(test))
# 出力結果:133 89 44
** ●データのスケーリング**
前処理でスケーリングを行います。
ここでは正規化(MinMaxScaler)を用いて、トレーニングデータを基準としたスケーリングを行いました。
from sklearn.preprocessing import MinMaxScaler
# 最小値が0, 最大値が1となるようにスケーリング方法を定義
scaler = MinMaxScaler(feature_range=(0, 1))
# `train`のデータを基準にスケーリングするようパラメータを定義
scaler_train = scaler.fit(train)
# パラメータを用いて`train`データをスケーリング
train = scaler_train.transform(train)
# パラメータを用いて`test`データをスケーリング
test = scaler_train.transform(test)
** ●入力データ・正解ラベルの作成**
LSTMの予測では、基準となる時点からいくつか前のデータを用いて次の時点のデータの予測を行います。
ここでは入力データと正解ラベルを次の要件で作成しました。
・入力データ:基準点を含め、3か月前の時点までのデータ
・正解ラベル:基準点の次の時点のデータ
import numpy as np
# 入力データ・正解ラベルを作成する関数を定義
# data_X:入力データ。n月分のデータを1セットとする
# data_Y:正解ラベル。Xの翌月を正解とする
def create_dataset(dataset, look_back):
data_X, data_Y = [], []
for i in range(look_back, len(dataset)):
data_X.append(dataset[i-look_back:i, 0])
data_Y.append(dataset[i, 0])
return np.array(data_X), np.array(data_Y)
# 3つ前のデータを1セットとする入力データと正解ラベルを作成
look_back = 3
# 作成した関数`create_dataset`を用いて、入力データ・正解ラベルを作成
train_X, train_Y = create_dataset(train, look_back)
test_X, test_Y = create_dataset(test, look_back)
** ●データの整形**
作成したデータはLSTMで分析できるデータ形式ではないので、入力データの整形を行います。
入力データを行数×変数数×カラム数の3次元の行列に変換し、LSTMで分析できるデータ形式に整形します。
・行数:データの総数
・変数数:1セットのデータに含まれる要素数 = look_back
・カラム数:扱うデータの種別数 = 1(犯罪者数の1種類だけ)
# データの整形
# 3次元のnumpy.ndarrayに変換
train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1)
test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)
** ●LSTMネットワークの構築と訓練**
次に、LSTMネットワークを構築し、用意したデータを用いてモデルの訓練を行います。
from sklearn.metrics import mean_squared_error
import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.callbacks import EarlyStopping
# LSTMモデルを作成
model = Sequential()
model.add(LSTM(64, input_shape=(look_back, 1), return_sequences=True))
model.add(LSTM(32))
model.add(Dense(1))
# モデルをコンパイル
model.compile(loss='mean_squared_error', optimizer='adam')
# 訓練
model.fit(train_X, train_Y, epochs=50, batch_size=1, verbose=1)
** ●データの予測・評価**
モデルの構築と訓練が終了したので、データの予測と評価を行います。
出力されたデータの予測結果を正しく評価するには、スケーリングしたデータを元に戻す必要があります。
元に戻すには、transform()メソッドの逆変換を行う、inverse_transform()メソッドを用います。
データが少ないせいか、誤差が大きくなっていますね。
import math
# 予測データを作成
train_predict = model.predict(train_X)
test_predict = model.predict(test_X)
# スケールしたデータを元に戻す
train_predict = scaler_train.inverse_transform(train_predict)
train_Y = scaler_train.inverse_transform([train_Y])
test_predict = scaler_train.inverse_transform(test_predict)
test_Y = scaler_train.inverse_transform([test_Y])
# 予測精度の計算
train_score = math.sqrt(mean_squared_error(train_Y[0], train_predict[:, 0]))
print('Train Score: %.2f RMSE' % (train_score))
# 出力結果:Train Score: 13596.52 RMSE
test_score = math.sqrt(mean_squared_error(test_Y[0], test_predict[:, 0]))
print('Test Score: %.2f RMSE' % (test_score))
# 出力結果:Test Score: 14855.30 RMSE
** ●予測結果の可視化**
次の3つを1つのグラフにプロットします。
・読み込んだままのデータ(dataset)
・トレーニングデータから予測した値(train_predict)
・テストデータから予測した値(test_predict)
import matplotlib.pyplot as plt
# プロットのためのデータ整形
train_predict_plot = np.empty_like(dataset)
train_predict_plot[:, :] = np.nan
train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict
test_predict_plot = np.empty_like(dataset)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict
# データのプロット
plt.title("monthly-suspected-criminals-in-ten-years")
plt.xlabel("time(month)")
plt.ylabel("Persons")
# 読み込んだままのデータをプロット
plt.plot(dataset, label='dataset')
# トレーニングデータから予測した値をプロット
plt.plot(train_predict_plot, label='train_predict')
# テストデータから予測した値をプロット
plt.plot(test_predict_plot, label='test_predict')
plt.legend(loc='lower left')
plt.show()
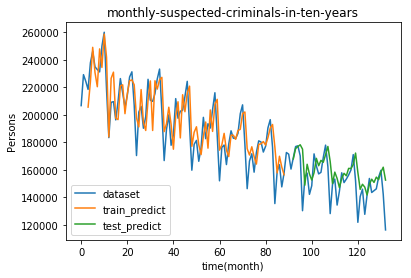
X軸の0のところが2007年1月です。意外にも犯罪者数は減少していますね。
テストデータの部分を拡大してみます。
import matplotlib.pyplot as plt
import numpy as np
# プロットのためのデータ整形
train_predict_plot = np.empty_like(dataset)
train_predict_plot[:, :] = np.nan
train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict
test_predict_plot = np.empty_like(dataset)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict
# データのプロット
plt.title("monthly-suspected-criminals-in-ten-years")
plt.xlabel("time(month)")
plt.ylabel("Persons")
# 範囲設定
plt.xlim(89,140)
plt.ylim(110000,200000)
# 読み込んだままのデータをプロット
plt.plot(dataset, label='dataset')
# トレーニングデータから予測した値をプロット
plt.plot(train_predict_plot, label='train_predict')
# テストデータから予測した値をプロット
plt.plot(test_predict_plot, label='test_predict')
plt.legend(loc='upper right')
plt.show()
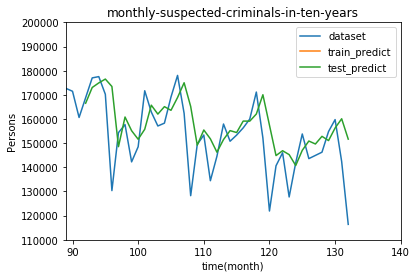
うーん、やはりデータが少ないせいか、ところどころ誤差が目立ちますね。
機械学習で予測してみた
少し不完全燃焼な気分だったので、視点を変えてもう少し工夫してみました。
何か犯罪者数とは全く異なる説明変数で、犯罪者数を予測できないかと考え、次のようなデータを用意しました。

これらを使って以下のように重回帰分析を行いました。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# データの読み込み、日付の削除
df = pd.read_excel('./blog_data/criminal_prediction.xlsx', sheet_name=0)
df = df.drop(df.columns[0], axis=1)
X = df.drop('被疑事件の受理人員', axis=1)
y = df['被疑事件の受理人員']
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 訓練、評価
model = LinearRegression()
model.fit(X_train, y_train)
R2 = model.score(X_test, y_test)
print("{:.5f}".format(R2))
# 出力結果:0.79810
まずまずの結果ですね。とりあえず満足です。
おわりに
受講期間は終わってしまいましたが、これからも時間を見つけて少しずつ勉強していこうと思います。
卒業までに実際にコードを実行しながら、幅広く触れることができて良かったです。