0-1. はじめに
からの続きです!
こちらから読む方へ
少し前にCPUの自作を通して 「コンピュータが命令を実行する仕組み」 を学びました。
それによりハードウェア階層の話はある程度理解できたため、次はもう少しレイヤーが上のソフトウェア階層の話(機械語から高水準言語・オペレーティングシステムに至るまでの抽象化の階段)について学んでみたいなと思い、こちらの「コンピュータシステムの理論と実装」に挑戦することにしました。

コンピュータを理解するための最善の方法はゼロからコンピュータを作ることです。コンピュータの構成要素は、ハードウェア、ソフトウェア、コンパイラ、OSに大別できます。本書では、これらコンピュータの構成要素をひとつずつ組み立てます。具体的には、NANDという電子素子からスタートし、論理ゲート、加算器、CPUを設計します。そして、オペレーティングシステム、コンパイラ、バーチャルマシンなどを実装しコンピュータを完成させて、最後にその上でアプリケーション(テトリスなど)を動作させます。実行環境はJava(Mac、Windows、Linuxで動作)。
※引用元 O'Reilly Books内容紹介
上の内容紹介にもある通り、こちらの本はNANDゲートという単純な電子素子から最終的にはアプリケーション(テトリス)を動作させるまでの過程を追っていくものとなっており、プロジェクト名は一般的に Nand2Tetris(NANDからテトリスへ) と呼ばれています。
(最終的な成果物はテトリスではなく実はピンポンゲームであるのは内緒。)
で、このNand2Tetrisの作成を実際にやってみて、個人的に学ぶことが非常に多かったためメモを残すことにしました。
前回は主にハードウェア階層部分までの話をメインに取り上げさせていただいたので、こちらではソフトウェア階層(アセンブラ、VM、コンパイラ、OS)を中心に重要な部分をまとめていきたいと思います。
記事の内容が少しでもみなさんの参考になれば幸いです。
ぜひ最後までご覧ください。
0-2. 対象読者
-
低レイヤに興味がある人
-
コンピュータの内部を理解したい人
-
アセンブラ、コンパイラの仕組みについて知りたい人
目次
| 章 | タイトル | サブタイトル | 備考 |
|---|---|---|---|
| 0-1. | はじめに | ||
| 0-2. | 対象読者 | ||
| 1. | アセンブラ・スタックマシンを作り終えた感想 | ||
| 2. | 各章の内容メモ | 6章:アセンブラ | アセンブラ実装に関する内容をまとめています |
| 7章:バーチャルマシン#1:スタック操作 | スタックマシンの基本的な操作であるスタック操作に関する内容をまとめています | ||
| 8章:バーチャルマシン#2:プログラム制御 | スタックマシンの応用的な操作である「プログラムフロー」と「関数呼び出し」に関する内容をまとめています。 本章がメイン部分です。 |
||
| 参考文献など |
1. アセンブラ・スタックマシンを作り終えた感想
本題に入る前に、アセンブラとスタックマシンを作り終えた感想をさらっと述べていきます。
そうですね、作り終えてから思ったことは
「スタックマシンってすげー」
です(めちゃくちゃシンプル。)
まずアセンブラはやってることが非常に単純なため、あまり面白味はありませんでした。
というのもアセンブリ言語と機械語は基本的に一対一対応なので、対応する機械語に変換するプログラムを書けばいいだけだからです。(唯一面倒くさいのはシンボル機能くらい)
一方、スタックマシンの機能は非常に多彩です。
これは「関数呼び出し」や「条件付き分岐命令」のような複雑な命令を行えて、さらにそれらを組み合わせることで様々なプログラムが実行可能になります。
それゆえ必然的に実装の方も難しくなってきます。
ただ面白いのが、この複雑そうに見えるスタックマシンを成立させているのは実は非常にシンプルなロジックだということです。
この点が実装を進める中で肌感覚として実感できてくるよう設計されているため、スタックマシンの実装はめちゃくちゃ面白かったです。
また同時にそんなロジックを考えついた人に対してリスペクトの気持ちがかなり強まりました。
スタックマシンを作り終えると、本書の一節にもある
「コンピュータサイエンスの分野において『シンプルさと優美さを兼ね備えたものは表現力も豊かである』というのが常である」
という言葉がかなり響くことになるでしょう。
2. 各章の内容メモ
では、次にアセンブラとスタックマシンの実装にあたる6~8章の内容とその章の課題で実際どのようなものを作ったのか?について簡単にメモしていきます。
【補足】
本書の内容は基本的には書籍でも十分網羅できているのですが、その背景知識などをさらに詳しく知りたい方へ向けて著者らが専用のウェブサイト内に豊富なイラスト付きのスライドを用意してくれています。
そのため、もし本書の説明でわからなかったことがあればそちらを参照してみることをおすすめします。
(ただし、資料は全て英語で書かれているのでその点には注意してください。)
サポートサイト:Nand2Tetris/Projects
6章:アセンブラ
まず最初に作成するのが 「アセンブラ」 です。
(ちなみにアセンブラとはアセンブリ言語で書かれたプログラムを機械語に変換するプログラムのことです。)
アセンブリ言語は機械語と一対一対応であるため、構文解析という構文解析はほぼする必要はなく、基本的には決められた記号を対応するバイナリへと変換するプログラムを書いていけばいいだけとなっています。
しかし、このアセンブラの作成で少し厄介なのが 「シンボル機能」 です。
シンボル機能とは 「アセンブリ言語においてシンボルを用いることでメモリアドレスを参照することができる」 機能のことで、これによりアセンブラは単純なテキスト処理のプログラムから少々複雑なプログラムへと変化します。
(例えば以下の i )
@i
M=1 //M[16] = 1 (M=memory)
@sum
M=0 //M[17] = 0
とはいっても後述のコンパイラやVMと比べるとかなりやさしい方で、シンボルテーブルをうまく活用すれば簡単にシンボル機能込みのアセンブラは作成できます。
アセンブラ実装にあたっては
- Parserモジュール(入力されたアセンブリプログラムを基本要素へと分解するモジュール)
- Codeモジュール(アセンブリコードのニーモニック全てを機械語へ変換するモジュール)
- SymbolTableモジュール(シンボルとアドレスの対応関係を記憶したリストに関連するモジュール)
の3つのモジュールをベースにし、最初にまずシンボルフリーなアセンブラを作成してからシンボル込みのアセンブラを作成しました。
(こちらは全て書籍通り。)
「シンボルフリーなアセンブラ」に関しては、
- A命令が数値であること
- ラベル宣言は用いない
の2つを前提に考えていくため割と簡単でした。
以下に主な実装の流れを記しておきます。(赤字が書籍に記されている各モジュールのAPIにあたる)
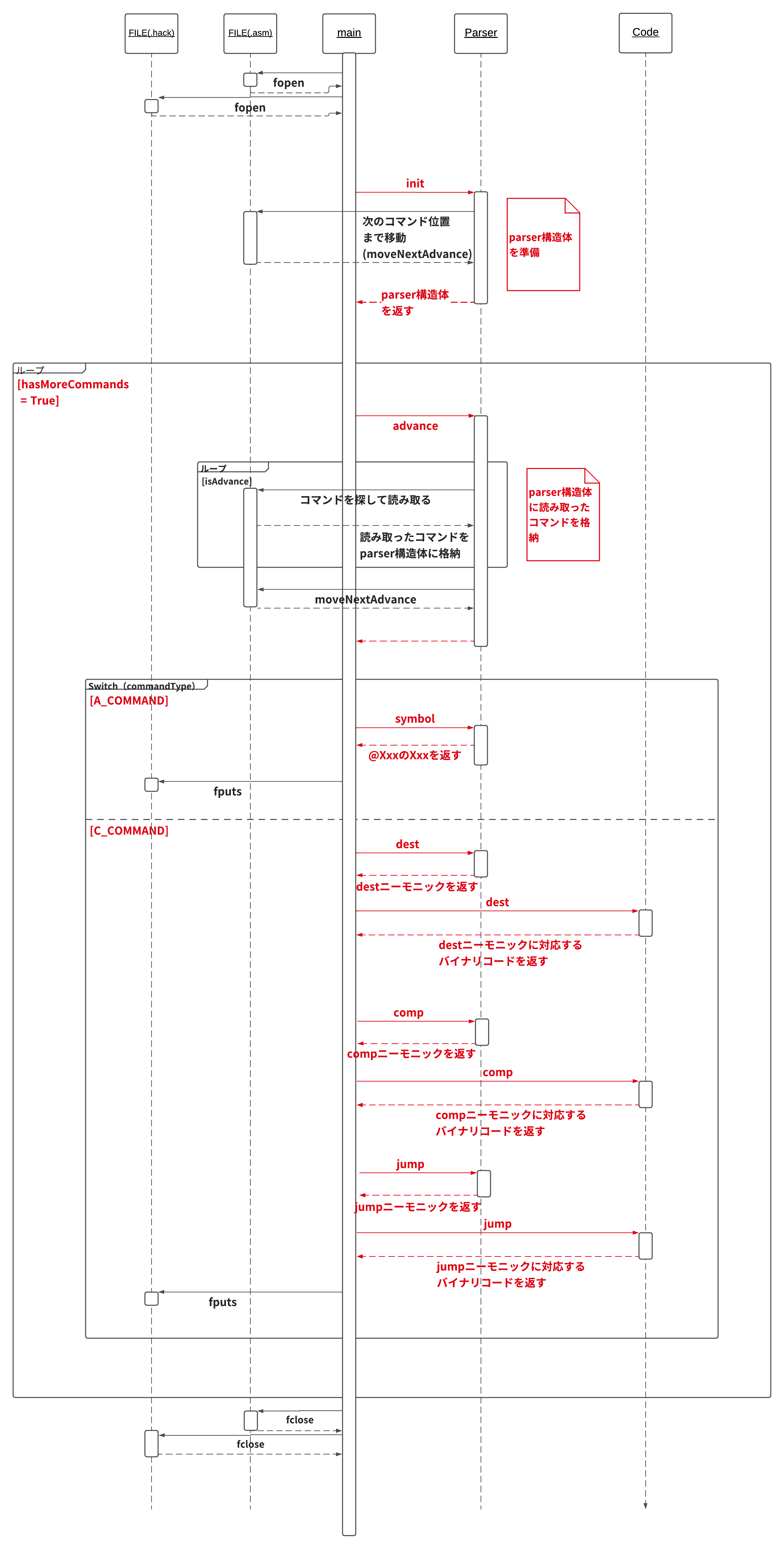
「シンボル込みのアセンブラ」に関しては、テキストにもある通り2パスのアセンブラを用いて実装していきました。
具体的には アセンブル作業に移る前に、コードの最初から最後まで読んでいき、ラベル宣言部分のシンボルテーブルを作成するという工程を挟みました。

コードはこちらにありますので、よければ参考にしてください。
7章:バーチャルマシン#1:スタック操作
ここから本格的なコンパイラの作成に入っていくのですが、いきなりJack言語(今回の実装で用いられる高水準言語のこと)のコンパイラを作るのは相当難易度が高いため、ここでは2段階に分けて実装していきます。
ちなみにJack言語の仕様に関しては9章で確認することになっています。
これは現在使用されているJavaのようなモダンな言語においても取り入れられているアイデアで、具体的には
- 高水準プログラムを中間コードに変換:10〜11章
- 中間コードを機械語(アセンブリ言語)へと変換:7〜8章
の2段階による変換処理を行なっていきます。
今回は後者の 「中間コードを機械語へと変換」 の過程について考えていくことにします。

バーチャルマシン(VM)
本題に入る前にいくつか説明することがあります。
まずは「バーチャルマシン」について。
バーチャルマシンとは簡単にいうと、「仮想的に設計されたコンピュータ」のことを指し、中間コードを実行するためだけに使用されるものです。
これは実際に存在しているわけではないのですが、コンピュータ上で実現可能なものとなっており本章と次章の目標としては1~6章で作成したマシン上にこのVMの実装を行うこととなっています。
つまり、今回の場合だとVMプログラム(=中間コード)をHackプラットフォーム用の機械語に変換する変換器を作っていきます。
【余談:VMを利用することにより得られる恩恵】
ここではVMを利用することに得られる恩恵について少し考えていきましょう。まず最大の恩恵としては 「コードの移植性」 が挙げられます。
どういうことか?というと、もし仮にVMプログラムを今利用しているのとは別のプラットフォーム(ハードウェア)で利用したい場合、VM実装をそのプラットフォーム用に置き換えるだけで済むということです。
つまり、元のソースプログラムをそのまま別のプラットフォーム上でも使用できるということです。
これはVM実装の手間が比較的容易であるために可能なことで、これだけでVMを利用する価値は十分あり、実際にこのようなコンピュータで別のコンピュータをエミュレートするというアイデアは現在とても重要なものとなっています。
他にもVMの改良するだけで一連のコンパイルのパフォーマンスを改善させることが可能という利点もありますし、同じVMのバックエンドを利用している言語同士なら相互利用することも可能になります。
スタックマシン
このVM実装案として最も代表的なのが 「スタックマシン」 と呼ばれるモデルです。
これはスタックと呼ばれるデータ構造にオペランドと命令結果を格納していくものですが、基本的にはどのような算術命令や論理命令であってもこのモデルで実装することが可能です。
(スタックについての詳しい説明はテキストに載っていますので、そちらを参考にしてください。)
今回扱うVMも基本的にはこのスタックマシンに沿って実装していくことになります。
VM言語
前述のVMは「言語」を持ちます。VM言語は基本的に以下のフォーマットのコマンドが行ごとに並べられる形をとります。
- command(例:add)
- command arg(例:goto LOOP)
- command arg1 arg2(例:push local2)
具体的には今回は以下の4種類のコマンドを使用します。
- 算術コマンド:スタック上で算術演算と論理演算を行う
- メモリアクセスコマンド:スタックとバーチャルメモリ領域の間でデータ転送を行う
- プログラムフローコマンド:条件付き分岐処理または無条件の分岐処理を行う
- 関数呼び出しコマンド:関数呼び出しとそれらからのリターンを行う
本章では「算術」と「メモリアクセス」のためのコマンドのみを実装したベーシックな変換器を作成していきます。
(「プログラムフロー」と「関数呼び出し」は次章で実装します。)
なお算術コマンドに関しては以下の9つのコマンドが存在しています。
| コマンド | 戻り値 | 備考 |
|---|---|---|
| add | x + y | 整数の加算(2の補数) |
| sub | x - y | 整数の減算(2の補数) |
| neg | -y | 符号反転(2の補数) |
| eq | x = yであればtrue、それ以外はfalse | 等しい |
| gt | x > yであればtrue、それ以外はfalse | 〜より大きい |
| lt | x < yであればtrue、それ以外はfalse | 〜より小さい |
| and | x And y | ビット単位 |
| or | x Or y | ビット単位 |
| not | Not y | ビット単位 |
またメモリアクセスコマンドに関しては基本的に「pop」と「push」を用いて表します。
具体的には以下の2パターンのコマンドによってメモリアクセスは行われます。
(segmentは次に示す仮想セグメントの先頭アドレスのこと。)
- push segment index(segment[index]をスタックの上にプッシュする)
- pop segment index(スタックの一番上のデータをポップし、それをsegment[index]に格納する)
注意点としては、スタックとヒープに関しては直接操作されることはなく、VMコマンドを実行した結果として背後で更新されるようになっているため扱うコマンドが存在しません。
具体的な実装
ここから具体的な作業に入っていくのですが、まず今回の実装に関しては大きく2つのタスクがあります。
ひとつ目が、VM用に用意された仮想メモリセグメントなどを対象のHackマシンのデータメモリに対応させるという作業です。
具体的にはVMは以下の8つの仮想メモリセグメントと明示されないスタック(とヒープ)を持っており、これらをその次に示すHackデータメモリ上でエミュレートしていきます。
| セグメント | 目的 |
|---|---|
| argument | 関数の引数を格納する |
| local | 関数のローカル変数を格納する |
| static | スタティック変数を格納する。これは同じファイル内の全ての関数で共有される |
| constant | 定数値を持つ疑似セグメント |
| ・this ・that |
汎用セグメント。異なるヒープ領域に対応するように作られている |
| pointer | thisとthatセグメントのベースアドレスを持つ2つの要素からなるセグメント |
| temp | 固定された8つの要素からなるセグメント。一時的な変数を格納するために用いられる |
| RAMアドレス | 使用法 |
|---|---|
| 0-15 | 16個の仮想レジスタ。VM実装の可読性を高めるために導入。pointerとtempはここに直接マッピングされている |
| 16-255 | (同一ファイル内の全てのVM関数における)スタティック変数 |
| 256-2047 | スタック |
| 2048-16383 | ヒープ(オブジェクトと配列を格納) |
| 16384-24575 | メモリマップドI/O |
| 24576-32767 | 使用しない |
エミュレートの仕方ですが、上にもある通り、実はRAMアドレスの0から4番目までがシンボルのSP、LCL、ARG、THIS、THATを用いて参照できるようになっています。これらは各セグメントのベースアドレスをわかりやすくする役割を果たしていて、これを用いることで比較的簡単にRAM上で仮想セグメントを実装できるようになっています。
例えば、以下のようなメモリアクセスコマンドの場合を考えてみましょう。
push argument 0
この場合、シンボルを用いれば
@0
D = A
@ARG
D = M + D
@R13
M = D
A = M
D = M
@SP
A = M
M = D
@SP
M = M + 1
こんな感じで表すことができます。
argumentセグメントはARGを用いることで簡単に参照できるんです。
ただひとつ厄介なのがStaticセグメントです。
これだけ少し表し方が特殊で、例えば
push static 0
みたいなコマンドがきた場合、以下のように変換します。(XXX.vmファイルと仮定)
@Xxx.0
D = M
@SP
A = M
M = D
@SP
M = M + 1
これは何をしているのか?というと、要は
与えられたプログラムからstaticセグメントの最初の値がわかる = Xxxファイルの最初の変数シンボル = Xxx.0
と解釈しているわけです。
要は、与えらればVMプログラムが何番目に出てきたスタティック変数なのか?ということを指し示してくれているわけです。
このため、一番最初に出てきた変数シンボルとして解釈し、Xxx.0として記憶し、そのメモリアドレスはスタティックセグメントに割り当てられるわけです。
少しトリッキーですが、一応ちゃんと実装できていますね。
ふたつ目の作業が、各VMコマンドを一連の機械語命令に変換するという作業です。
具体的にはpushやpop、addなどのVMコマンドをアセンブリ命令に変換していくという作業が必要になってきます。
このコマンド変換は少し頭を使いますが、基本的にそこまで苦労はしないでしょう。謎解き要素が強くてなかなかに楽しいですよ♪
さてこれらの実装方法やマッピングに関してはテキストの「実装」の節に詳しく載っていますのでそちらを参考にしていただくとして...
ここからは今回の実装の大まかれな流れについてのみ触れておきたいと思います
まずアセンブラと同様に 2段階に分けて実装していきます。
最初のバージョンとして、スタック算術コマンドと「push constant」コマンドに対応できるように実装します。
(この段階では、仮想メモリセグメントを対応づけする必要はありません。)
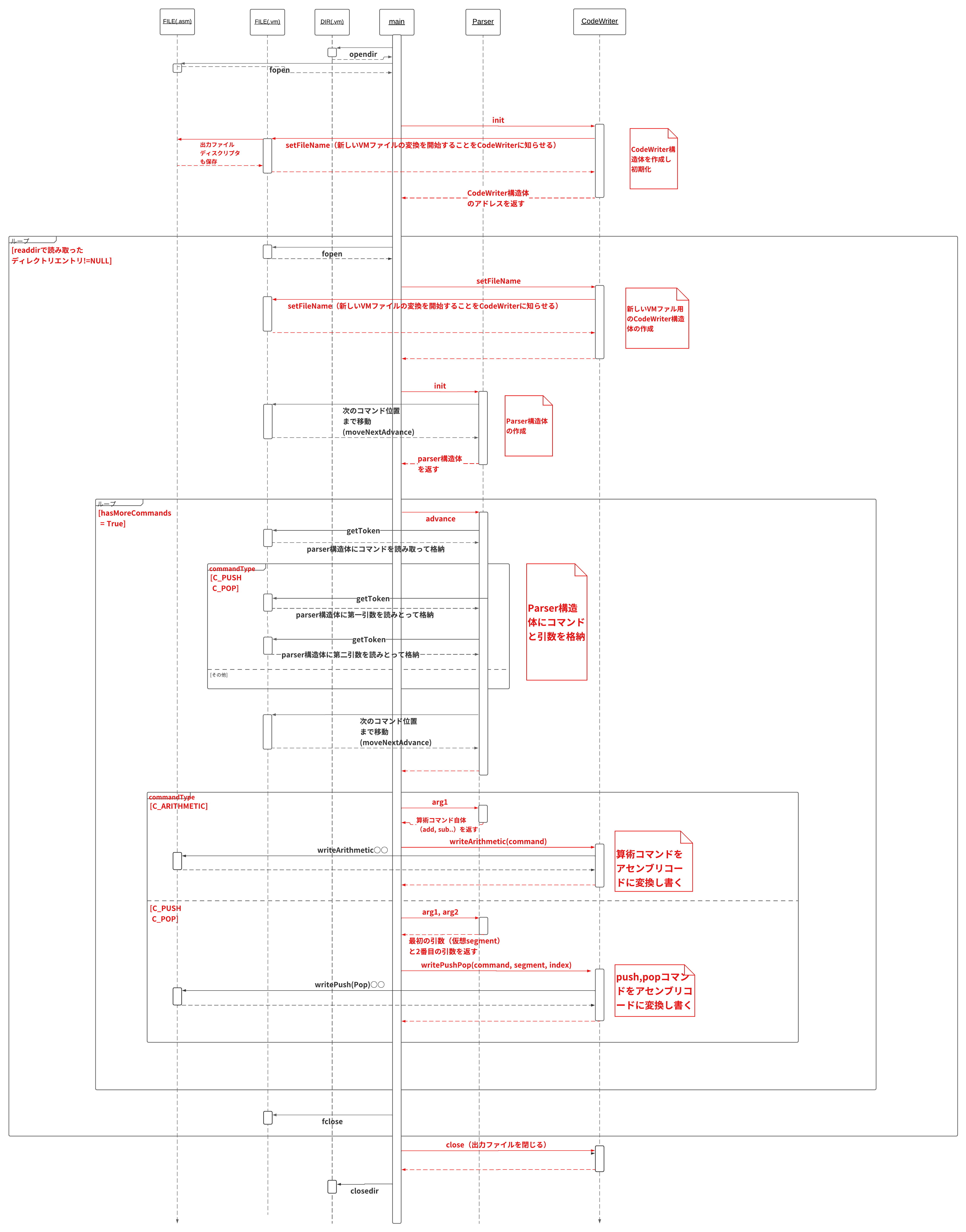
次に、メモリアクセスコマンドを実装し、仮想メモリセグメントに対応できるように実装していきます。
(この段階でようやくメモリアクセスコマンドと仮想メモリセグメントに対応づけしていきます。)
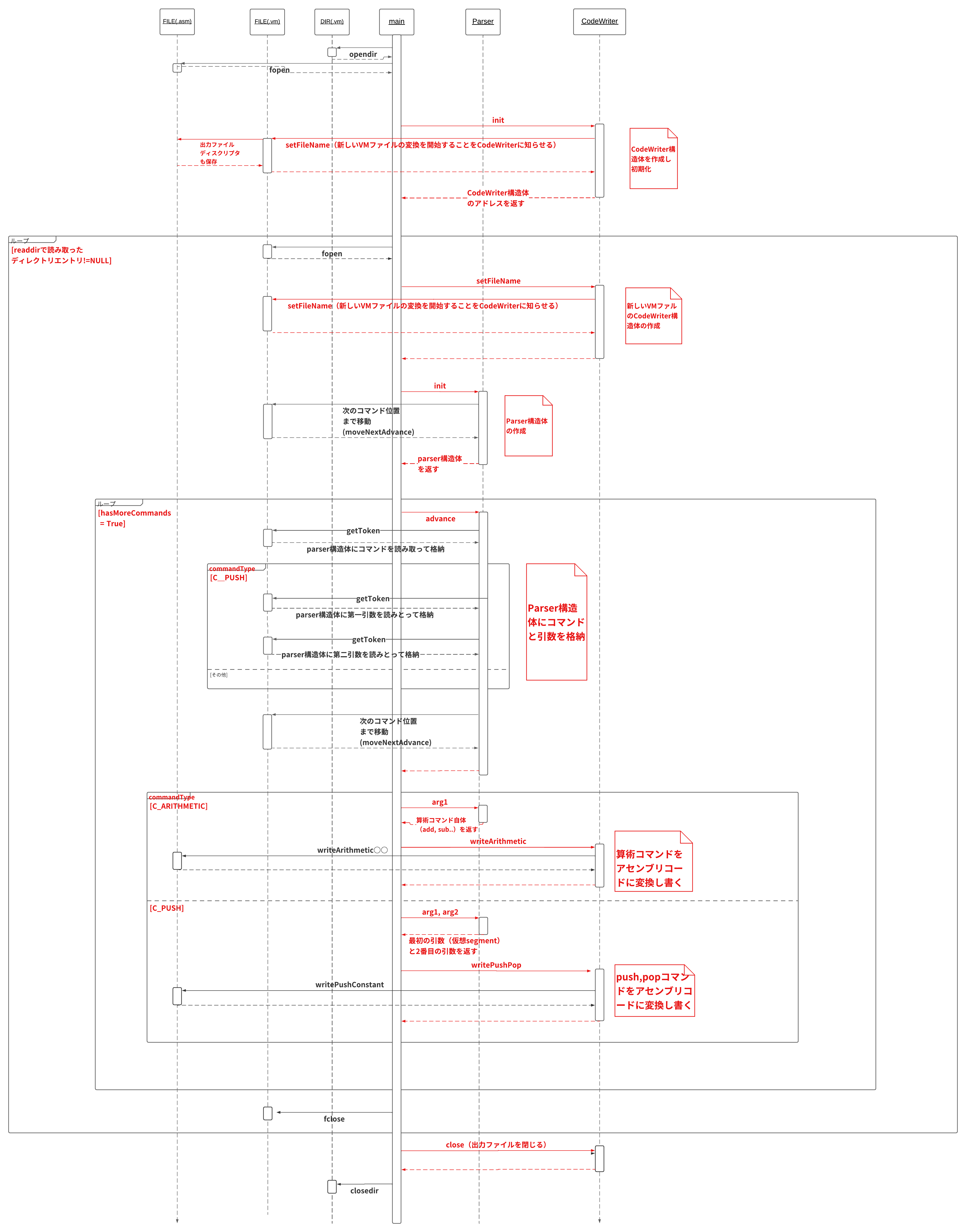
設計案としては、
- Parserモジュール(VMコマンドを読み、パースして各要素に分解していく)
- CodeWriterモジュール(VMコマンドをアセンブリコードに変換する)
というふたつのモジュールをベースに作成していきます。
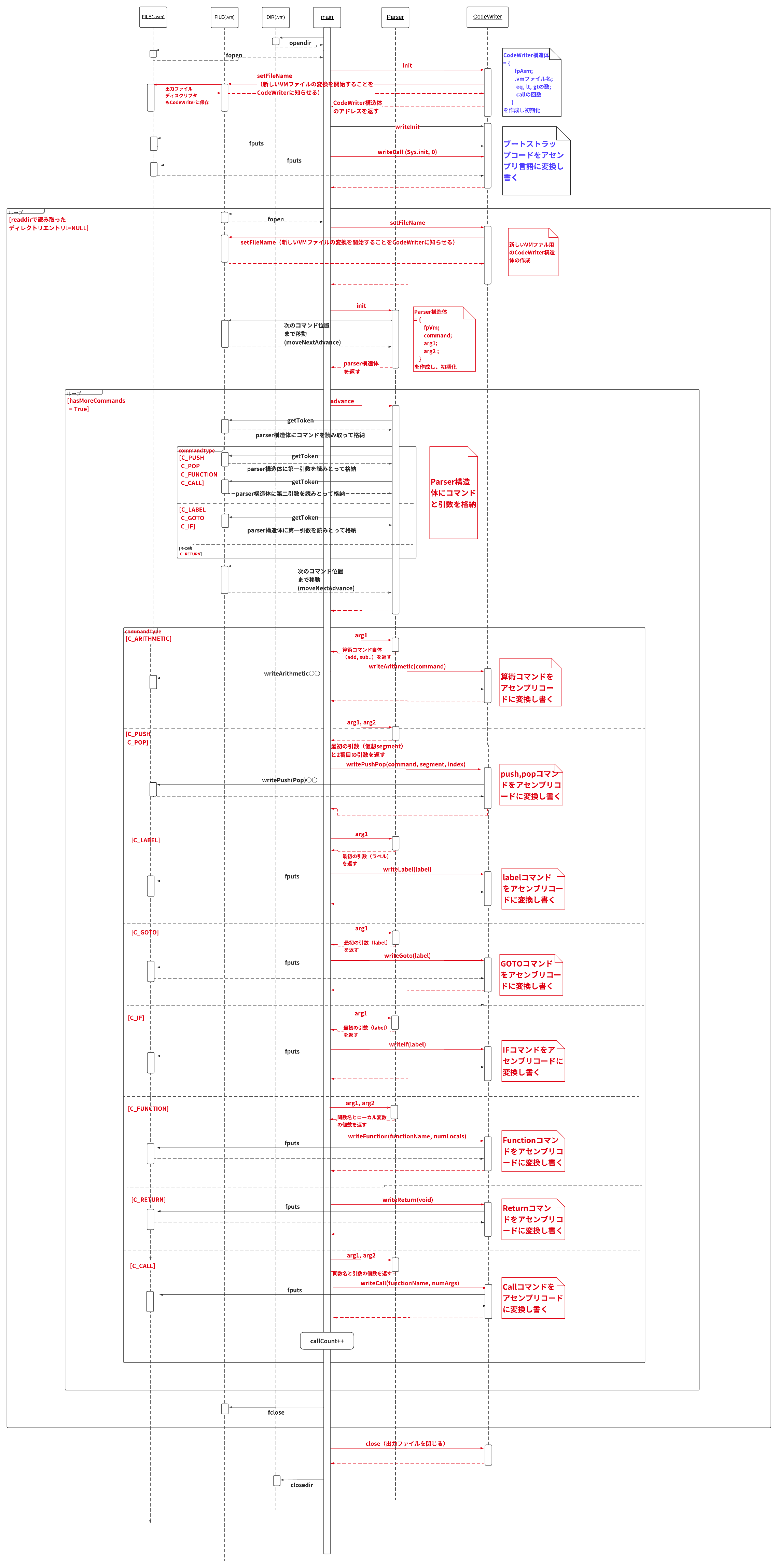
(以下の図はディレクトリを入力として読み込んだ時のシーケンス図。ファイルの場合もこれとほぼ同じ。)
①スタック算術とpush constantだけに対応したもの
②メモリアクセスコマンドにも対応したもの
8章:バーチャルマシン#2:プログラム制御
この章では、前章で作成したVM変換器を拡張し、完全版のVM変換器を作成していきます。
具体的には 「プログラムフロー」と「関数呼び出し」のコマンドに対応した機能を追加していきます。
ここは結構重要な章になっていて、私たちが一般的に用いる高水準言語が「高水準」たる所以である関数機能が、実はスタックを用いることで非常にシンプルに実装されていることを目で見て確認できるようになっています。
特に抽象化を進めていくことに大きな意味があるコンピュータサイエンスにとってはこの「関数」機能はめちゃくちゃ重要で、これにより基本的な命令セットしかない言語を
- より自由に複雑な命令を実行可能
- より使いやすい
そんな高水準な言語へと進化させることが可能になるのです。そういう意味で関数機能の実装はコンピュータを理解するには避けては通れません。
では、ここからは「プログラムフロー」や「関数呼び出し」機能の仕様とそれらの実装法について簡単に説明していきます。
(今回の実装も一気に行うと難しいので、 それぞれのコマンドの実装ごとに分けて行なっていきます。)
プログラムフロー
一般的にプログラムの流れを変えるコマンドをプログラムフローコマンドと呼び、今回作成していくのは主に 「条件付きプログラムフローコマンド」 になります。
これは与えられたプール条件式(trueかfalseを返す式)が
- trueの場合別の場所に移動し、実行する
- falseの場合そのままの流れで実行する
というコマンドなのですが、、
VM言語においてそのようなプール条件を導入するにはどうしたらいいのでしょうか?
今回はスタックマシンベースで実装を行なっていくため、シンプルに考えれば「スタックの最上位にある値を条件」として考えればうまく行きそうです。
具体的には
- スタックの最上位がtrue(-1)なら別の場所へ移動
- スタックの最上位がfalse(0)ならそのままの流れを維持
というものになります。
幸いにも前章でそのような算術コマンドとしてeqやgt、ltを作成していますので、今回はこれを利用していくことにします。
さて具体的に実装していくコマンドとしては
- label xxx
- goto xxx
- if-goto xxx
の3つのフローコマンドです。(xxxはラベル)
これらの実装は比較的簡単です。
なぜならHackアセンブリ言語は当然のようにこういったフローコマンド(JEQ、JLT、JGTなど)を備えているので、基本的にはこれに沿って実装していくだけで良いからです。
以下にフローコマンドに対応したVM変換器のシーケンス図を載せておきます。
注意点としては、ここで用いられるラベルは定義された関数内でしか有効ではないということです。そのためラベルの表し方は"f$b"(fというVM関数に定義されたbというラベルコマンド)となることに注意しましょう。
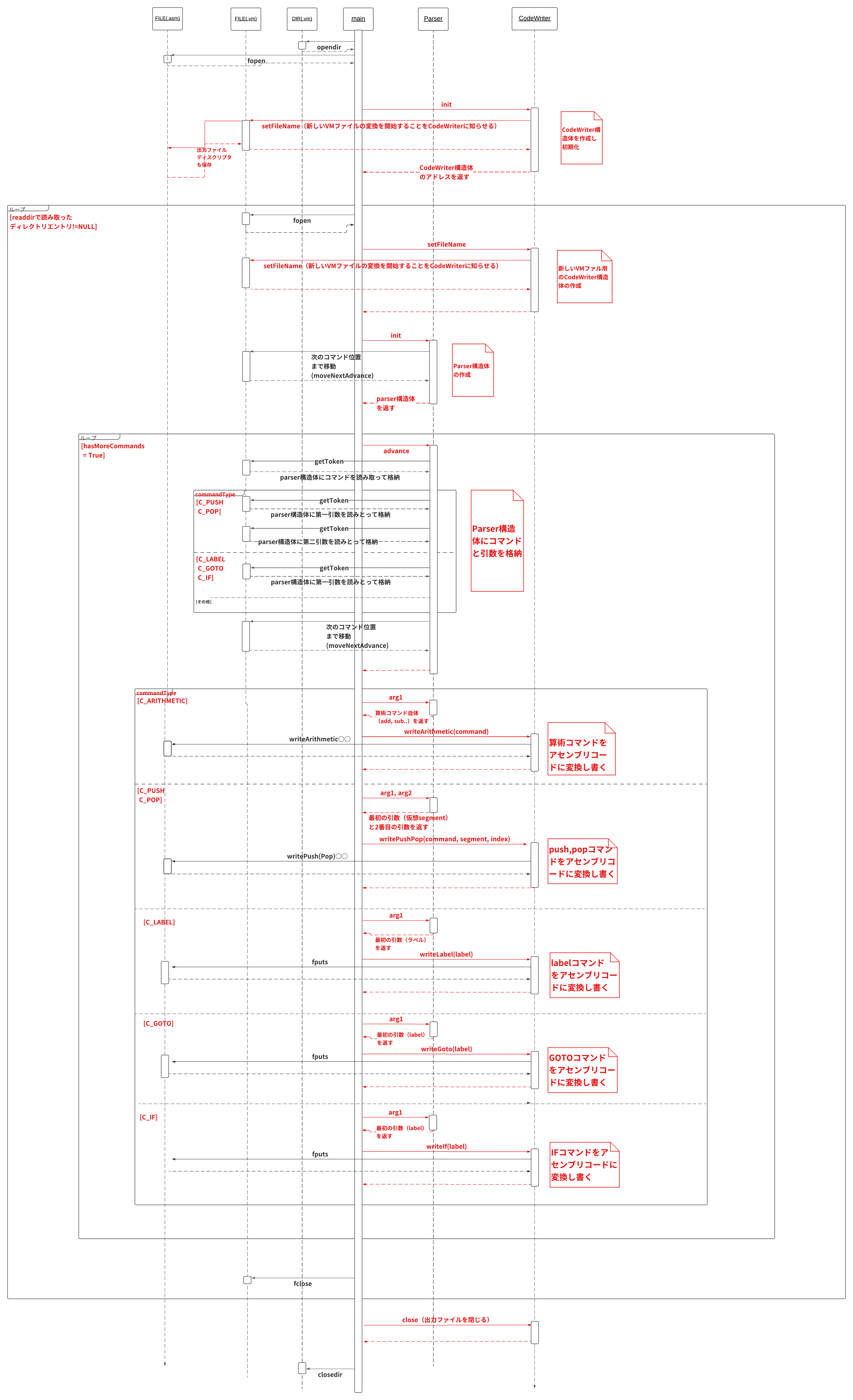
関数呼び出し
前置き(かなり長い...)
先ほどよりも難しいのがこちらの関数機能の実装。
実装案に入る前に、少し具体例を交えながら今回作成するスタックベースの関数呼び出しを低レイヤがどのように実現させているのかを考えてみましょう。
まずは以下の前章で作成した基本的なコマンドと関数をご覧ください。
// x+2 // x^3 // 累乗(power)関数
push x push x // 第一引数が第二引数だけ累乗される。power(2, 3)は2の3乗。
push 2 push 3 function power
add call power // コードは省略
... ... push result
return
ここからも分かる通り、両者ともに
- 引数を設定する必要がある
- 引数をスタックから取り出して計算を実行
- 命令結果をスタックの最上位に格納し、値を返す
という手順を辿るため、見た目は完全に一緒です。唯一の違いはcallを用いるか否かくらいです。
この「見た目が完全に一緒」というのは見てるだけだとあまり恩恵を感じられないですが、実際に開発を行う人にとってはとても重要です。
というのも、以下のようにいろんな関数を組み合わせて複雑な処理を行うことを可能にしますし、さらにコードを読む人にとってはプログラムの手順が統一されているため非常に読みやすくなります。
// (x^3 + 2) ^ y push x push 3 call power push 2 add push y call power
ただしこのように見た目が似ている一方で、実装法は実はかなり異なります。
まず上のpowerのような関数は、一時記憶に置かれる 「ローカル変数」 というのものが存在します。
これは関数が実行されている間に限ってメモリに保持されるという特徴を持つ変数で、具体的には関数実行開始地点からreturnが実行されるまでの間、保持されます。
(他にも関数で用いられる変数としてはパラーメタ変数なども存在します)
こういった関数内特有の変数についてそれらが単体ならまだ実装しやすいのですが、 一般的には関数はネスト化された構造(入れ子構造)を取っているためこうした変数のためのメモリ領域をいくつも確保する必要があります。
これは少し考えればわかりますが、そのまま実装しようとするとかなり大変ですよね。
では関数実行のためのこういった複雑なメモリ管理はどのように行われているのでしょうか?
お察しの方は多いかもですが答えはまたも 「スタック」 になるわけです。
スタックごときのデータ構造が一体どうしてこのような複雑なメモリ管理を可能にしているのか?と思うでしょう。
これ実は結構単純で、要は関数の 「call-returnロジック」 が持つ階層的な性質ゆえなのです。
どういうことか分からないでしょうから説明していきます。
まず関数というのは以下のように「呼び出しチェーン」(呼び出しの鎖)を任意の深さまで再帰的に繰り返すことができます。
(こういった階層構造を先ほども出てきましたが、ネスト構造と呼びます。)
subroutine a: start a
call b start b
call c start c
... start d
①
subroutine b: end d
call c end c
call d start d
... ②
subroutine c: end d
call d end b
... start c
③
subroutine d: start d
... end d
end c
end a
ただこれってある瞬間(例えば①)だけ切り取ってみると、実はそのチェーンの最後尾(関数d)をただ実行しているだけであり、他のチェーン(関数aやbやc)はその処理が終わるのを待っているんです。
これどこかで見たことがありませんか?
そうです。
この仕組み、スタックのデータ構造である 「後入れ先出し(LIFO)」 と全く同じなんです。
(後に実行された関数から順に処理されていくというイメージ)
要は
○○○という関数が×××という関数を呼び出した場合、○○○の環境(フレーム)をスタックにプッシュ(保存)し、×××の実行に切り替えが可能になるということなのです。
同様に×××からリターンされるときに○○○の環境(フレーム)をスタックからポップ(復帰)することで、○○○の実行をまるで何も起こっていないかのように再開させることができるのです。
はい、これだけだとたぶんわかりづらいですよね。
ということで、先ほどのコードの①②③時点での処理モデルを簡単に以下に示します。
これを見れば先ほど説明したようなスタックの挙動がはっきりとわかることでしょう。
(関数の実行が完了するごとにスタックが短くなっていき、新たな関数が実行されるごとにスタックが長くなっていく)
①
②
③
ここで 「フレーム」 という言葉が出てきました。
これは関数のローカル変数、引数、ワーキングスタックやその他のメモリセグメントを意味しています。つまり、関数実行のために必要なメモリ領域のことです。
またこうしたフレームの集合体を 「グローバルスタック」 と呼び、現在の関数とそのリターンを待つ他の全ての関数のためのフレームを含むメモリ領域を指します。
(ちなみにこのグローバルスタックの一番上に置かれるデータが現在の関数のワーキングスタックとなリます。pushやpopで値をやり取りするための領域ですね。)
前章ではスタックという言葉はpop、push、addなどの命令をただサポートするだけのいわゆるワーキングスタックを意味していましたが、関数呼び出しを実装する本章以降はグローバルスタックを表すことになりますので注意してください。なおVMで使用するメモリは
このグローバルスタックに保持される形で実装され、上図で見たように関数が呼ばれるごとに新しいフレームが追加されていくという流れに沿っていきます。
ここまでを一旦まとめると以下のようになります。
「call命令が実行されると、低レイヤ側では呼び出し側のフレームをスタック上に格納する操作と、呼び出された側のローカル変数のためのメモリ領域を確保する操作を行い、目的の関数へと実行を移す」
では次に関数の実行が終わった後はどうなるのでしょう?
一般的にはreturn命令を用いて呼び出した側へ戻るとされています。
このreturn命令は少しトリッキーな処理を行います。というのもreturn命令には 「戻り先のアドレス」 が指定されていないのです。
これは関数がどのような場所からでも呼び出せることを考えれば理解できると思います。
自由に呼び出せる代わりに戻るべきアドレスをコード中に指定することは実質不可能になってしまうのです。
じゃあどのように呼び出し側へと戻るのでしょう?ここでもスタックが利用されます。
つまり、戻るべきリターンアドレスを関数を呼び出した直後にスタックにプッシュし、その関数を実行します。
そしてその後、return命令に遭遇した際にスタックからリターンアドレスをpopし、そこへジャンプするのです。
要は呼び出された側のフレームにリターンアドレスを置き、関数を実行しているのです。
なおこれらの操作は当然ですが低レイヤが担当しているため、プログラムを書いている人たちはあまり意識することがありません。私たちが普段コードを書いている裏ではコンパイラがこんなにも色々なことを行なっているというわけです。コンパイラに感謝しましょうね。
仕様と実装
では前置きで説明したことを踏まえつつ、関数呼び出しコマンドとそれに関連するコマンドの仕様を見ていきましょう。
当然前章と同じように、
①各VMコマンドをアセンブリ言語に変換
②仮想メモリセグメントやスタック用に用意された専用のプライベート環境をHackマシンのデータメモリに対応づける
という2つのタスクを行なっていく必要があります。
まず最初に①について、VM言語は次の3つの関数に関するコマンドを持ちます
- function f n (n個のローカル変数を持つfという名前の関数を定義する)
- call f m (fという関数を呼ぶ。ここで、m個の引数は、呼び出し側によってスタックにプッシュ済みであるとする)
- return (呼び出し元へリターンする)
注意点としては、高水準言語では別々のファイルにあったとしてもVMのレベルでは全てのファイルの全ての関数は互いに見ることができて、関数名を用いてお互いに呼び出すことができます。
つまり関数名のスコープはVMレベルではグローバルであるということです。
これは意外と盲点ですので、押さえておきましょう。(まぁ実装していけば「そりゃそうなるよね」となります。)
そして、関数呼び出しコマンドを実行した際に裏側で行われるグローバルスタックの操作について(②)は 以下のように2つの視点に分けて考えていきます。
-
関数を呼び出す側の視点
- 関数を呼び出す前に、必要な個数分の引数をスタックにプッシュ
- 次にcallコマンドを用いて関数を呼び出す
- 呼び出した関数がリターンされた後は、呼び出し側がプッシュした引数はスタックから取り除かれ、戻り値がスタックの最上位に格納された状態になる
- 呼び出した関数がリターンされた後は、呼び出し側のメモリセグメントであるargument、local、static、this、that、pointerは関数を呼ぶ前と同じである。tempセグメントについては未定義。
-
関数が呼び出される側の視点
- 呼び出された関数の実行が開始すると、そのargumentセグメントが呼び出し側から渡された実際の引数の値に初期化される。
- またlocal変数のセグメントが割り当てられ、0に初期化される。
- 呼び出された側から見えるstaticセグメントは、そのVMファイルのstaticセグメントに属する。
- 呼び出された側から見えるワーキングスタックは空である。this、that、pointer、tempセグメントは最初は未定義である
- リターンされる前に呼び出された関数はスタック上に値をプッシュしなければならない
これらを元にコードに落とし込んでいきます。
(詳しい仕様については書籍の方にまとめてありますので、そちらを参考にしてください。)
最後にひとつ注意点として VMプログラムを実行する際の初期化 について少し触れておきます。
VMプログラムの実行が開始されると、まずはじめに
- Sys.initと呼ばれる引数が存在しない関数を実行
- VMスタックはRAM[256]から先へ対応づけする
という規則に従うことが決まっています。
この初期化を行うため、ROM[0]にはそれに対応するプログラムを格納する必要があり、それを一般的に「ブートストラップコード」と呼びます。
【補足】
ブートストラップとは一般的にブーツについている「つまみ皮」を意味していて、つまみ皮(Sys.init)を引っ張ることでブーツ(メインプログラム)を多段階的に履けることからこのような名前がつけられました。OSの起動の際にも出てきますね。(BIOS→IPL→OS読み込み...という多段階的にOSを起動させる)
具体的には、
SP=256 // スタックポインタを0x0100に初期化
call Sys.init // (変換されたコードの)Sys.initを実行する
というコードを実行します。
このSys.initはメインプログラムのメイン関数を呼び出します。
そしてそれがまた別の関数を呼び出していき、さらにその関数が別の関数を呼び出していくという風にしてプログラムが実行されます。
これはVMプログラムの実態が「関数の集合体」であることが理由です。まぁそういう風にわざと設計しているんでしょう。
なお次章以降で作成するJack言語では、このブートストラップによってMainという名前のクラスに含まれるmainというメソッドが自動で実行されます。
本章の実装課題は、このブートストラップコードの有無で一部分かれているところがあります。
以下に関数呼び出しを実装したVM変換器のシーケンス図を載せておきます。(ブートストラップあるversionとなしversion)
①ブートストラップなし(callコマンドもなし)
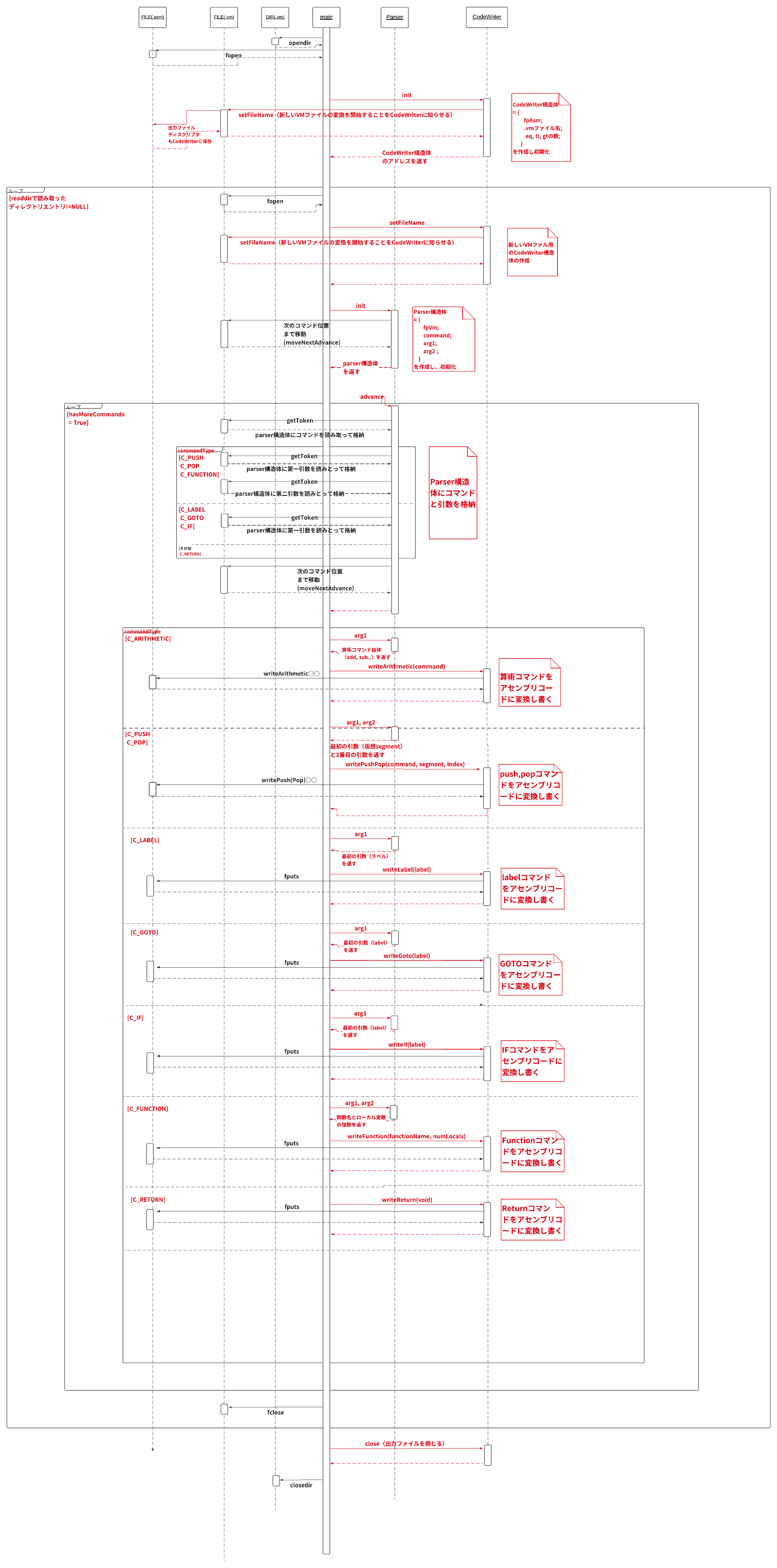
②ブートストラップあり(callコマンドもあり)
-1. つづく
ということで、アセンブラとスタックマシンに関する話でした。
全体を通してみると、やっぱりスタックマシンの実装がかなり重かったなという印象でした。
特に8章の関数呼び出しに関しては実装がかなり大変だと思います。
ただこの次のコンパイラ作成は実はこの比じゃないくらいの大変さなんですよね...先が思いやられます。。
次:「CPUからOSまで自作してみた話(コンパイラ・OS編)」
参考文献など
書籍
言わずもがな。
本を読み進める上で参考にさせていただいた記事など
-
「コンピュータシステムの理論と実装の7章と8章のバーチャルマシンを実装しました」
こちらの記事は、コードを書く際の方針がわかない時などに主に参考にさせていただきました。 -
Nand2tetris サポートサイト
こちらのサイトには、各章ごとにスライド付きの解説が載っていて、文字だけだとイメージが掴みにくい分野に関しては結構参考にさせていただきました。
イラストが豊富なので、正直本よりもわかりやすい気がします。
あえて難点を挙げるなら英語で書かれているという点ですが、ある程度英語ができる方なら割と読めると思います。