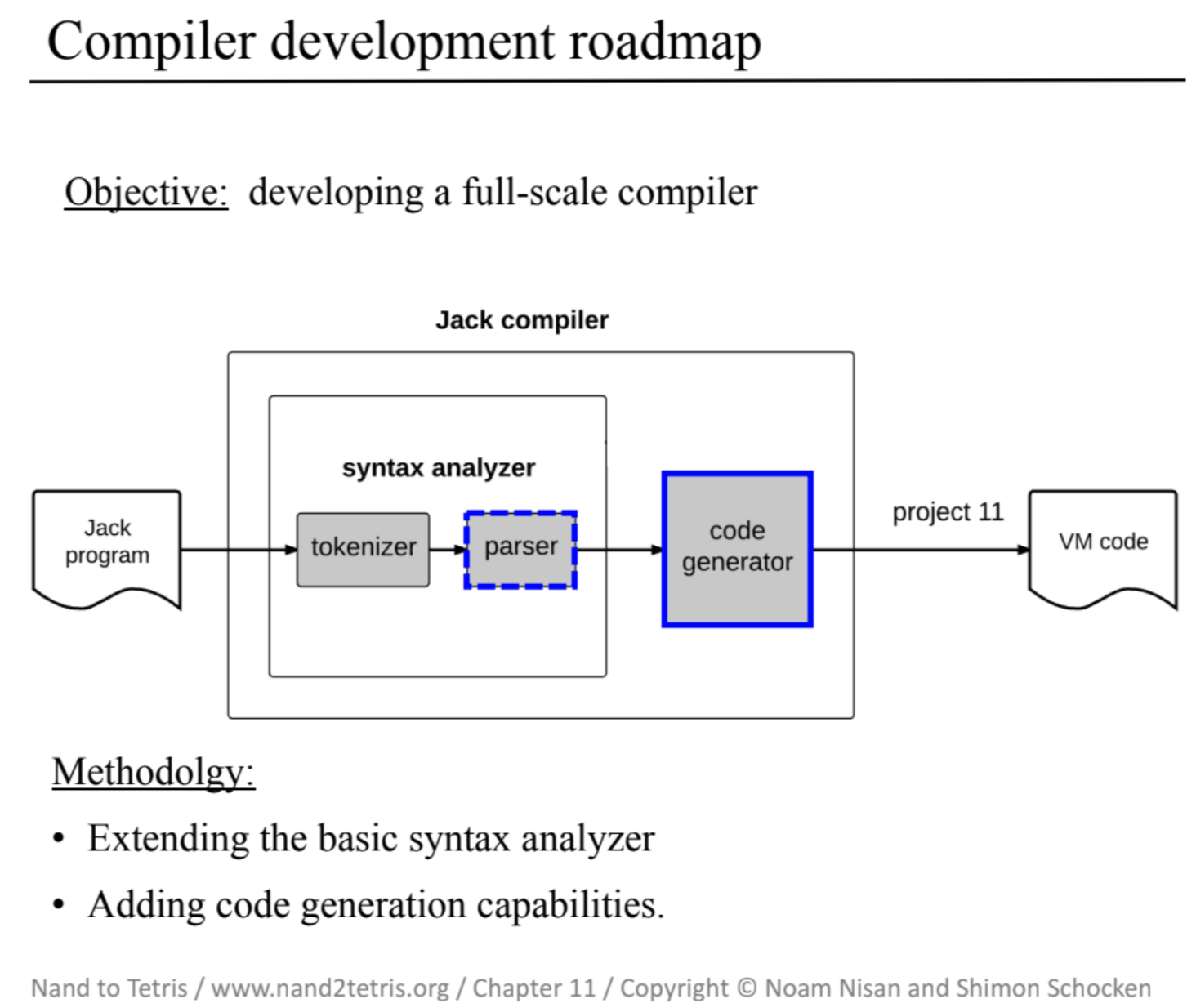
0-1. はじめに
からの続きです!
こちらから読む方へ
少し前にCPUの自作を通して 「コンピュータが命令を実行する仕組み」 を学びました。
それによりハードウェア階層の話はある程度理解できたため、次はもう少しレイヤーが上のソフトウェア階層の話(機械語から高水準言語・オペレーティングシステムに至るまでの抽象化の階段)について学んでみたいなと思い、こちらの「コンピュータシステムの理論と実装」に挑戦することにしました。

コンピュータを理解するための最善の方法はゼロからコンピュータを作ることです。コンピュータの構成要素は、ハードウェア、ソフトウェア、コンパイラ、OSに大別できます。本書では、これらコンピュータの構成要素をひとつずつ組み立てます。具体的には、NANDという電子素子からスタートし、論理ゲート、加算器、CPUを設計します。そして、オペレーティングシステム、コンパイラ、バーチャルマシンなどを実装しコンピュータを完成させて、最後にその上でアプリケーション(テトリスなど)を動作させます。実行環境はJava(Mac、Windows、Linuxで動作)。
※引用元 O'Reilly Books内容紹介
上の内容紹介にもある通り、こちらの本はNANDゲートという単純な電子素子から最終的にはアプリケーション(テトリス)を動作させるまでの過程を追っていくものとなっており、プロジェクト名は一般的に Nand2Tetris(NANDからテトリスへ) と呼ばれています。
(最終的な成果物はテトリスではなく実はピンポンゲームであるのは内緒。)
で、このNand2Tetrisの作成を実際にやってみて、個人的に学ぶことが非常に多かったためメモを残すことにしました。
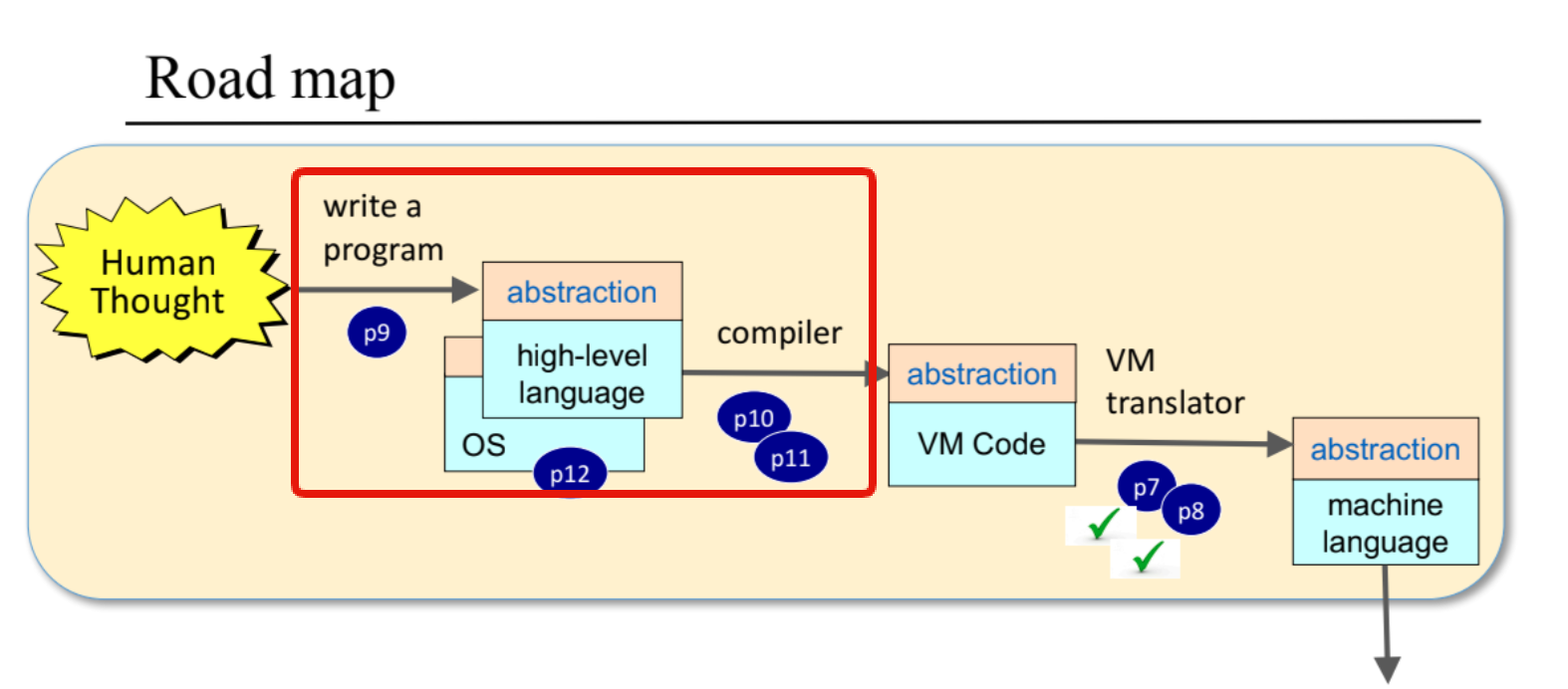
前回は主にハードウェア階層部分までの話をメインに取り上げさせていただいたので、こちらではソフトウェア階層(アセンブラ、VM、コンパイラ、OS)を中心に重要な部分をまとめていきたいと思います。
記事の内容が少しでもみなさんの参考になれば幸いです。
ぜひ最後までご覧ください。
0-2. 対象読者
-
低レイヤに興味がある人
-
コンピュータの内部を理解したい人
-
アセンブラ、コンパイラの仕組みについて知りたい人
目次
| 章 | タイトル | サブタイトル | 備考 |
|---|---|---|---|
| 0-1. | はじめに | ||
| 0-2. | 対象読者 | ||
| 1. | コンパイラ・OSを作り終えた感想 | ||
| 2. | 各章の内容メモ | 9章:高水準言語 | |
| 10章:コンパイラ#1:構文解析 | |||
| 11章:コンパイラ#2:コード生成 | |||
| 12章:オペレーティングシステム | |||
| 3. | おわりに | ||
| 参考文献など |
1. コンパイラ・OSを作り終えた感想
さてまずは恒例の感想から。
コンパイラとOSを作り終えた感想を一言で述べるとするなら
「コンパイラって使うのは簡単だけど、実際作るとめちゃくちゃ難しい...」
です。
はい、何を隠そう私はこのコンパイラの実装で一度挫折しかけました。
というのもですね、このコンパイラの仕組みめちゃくちゃややこしいんですよ。間にVM言語という中間コードを挟んでいるのにも関わらず、ですよ。
コンパイラのやるべきこととして、まず 「構文解析」 と呼ばれるプログラムテキストの構造を理解する作業があります。
この作業がそもそもかなり抽象的で、イメージするのがとても難しく、最初の感覚を掴むまでかなり時間がかかりました。
構文解析を理解するためにはコンピュータサイエンスで重要となる「文脈自由文法」「BNF記法」「構文木」「再帰下降アルゴリズム」...といった前知識が必要不可欠でして、これらを知らないとかなり苦労します。
要は実装云々に入る以前に、非常に大変だということです。
そしてイメージを掴めたら掴めたらでコードに落とし込んでいくわけですが、これも使用言語(私はC言語を使用しました...)や前知識のためか相当苦労しました。
こうして様々な苦難を乗り越えて構文解析器を作り終えたと思ったら、実はまだ「コード生成モジュール」の実装が残っているんですよね。
とまぁこんな感じで、「コンパイラの実装はここまでのスタックマシン、アセンブラ、Hackアーキテクチャの実装と比べると明らかに難易度が高く、その分必要となる知識量も増えたため非常に苦労したよ」ということです。
ただ逆にこれらを作り終えた時の達成感といったらそれはもう半端じゃなかったですね。特に自分で作ったコンパイラを動かせた時の快感はもうたまらないです...
2. 各章の内容メモ
では次に、コンパイラとOSの実装にあたる9~12章の内容とその章の課題で実際どのようなものを作ったのか?について簡単にメモしていきます。
【補足】
本書の内容は基本的には書籍でも十分網羅できているのですが、その背景知識などをさらに詳しく知りたい方へ向けて著者らが専用のウェブサイト内に豊富なイラスト付きのスライドを用意してくれています。そのため、もし本書の説明でわからなかったことがあればそちらを参照してみることをおすすめします。
(ただし、資料は全て英語で書かれているのでその点には注意してください。)サポートサイト:Nand2Tetris/Projects
9章:高水準言語
コンパイラの作成に取り掛かる前に、その準備としてまず 今回私たちが用いる高水準言語のJack言語について理解を深めることから始めます。
といってもそこまで身構える必要はありません。
なぜならJack言語はコンパイル作業をシンプルにするためにかなり単純に設計されており、オブジェクト指向言語に触れたことのある人ならすぐに理解することができるからです。
ということで、ここでの説明は省かせていただきます。
(詳しく知りたい方は書籍の説明を参考にしてください(笑))
注意点として書籍の説明を見るだけでなく、実際に例題プログラムをいくつか作ってみるようにしましょう。
本章の目的はJack言語に慣れ親しむことですので、見るだけで終わらせてはいけません。面倒くさがらず、わからなかったら仕様を見て調べて...というのを繰り返し自分の手を動かしてプログラムを実装していくことをおすすめします。
10章:コンパイラ#1:構文解析
さてここからが本題のコンパイラ作成です。
コンパイラの作成は大きく 2段階 に分けて行なっていきます。
まず最初にプログラムの構文を理解し、その意味を明らかにする 「構文解析」 を行い、その次に読み取ったプログラムを実際にスタックマシン用の言語へと変換する 「コード生成」 を行っていきます。
今回は最初の「構文解析」を行うモジュールを作成していきます。
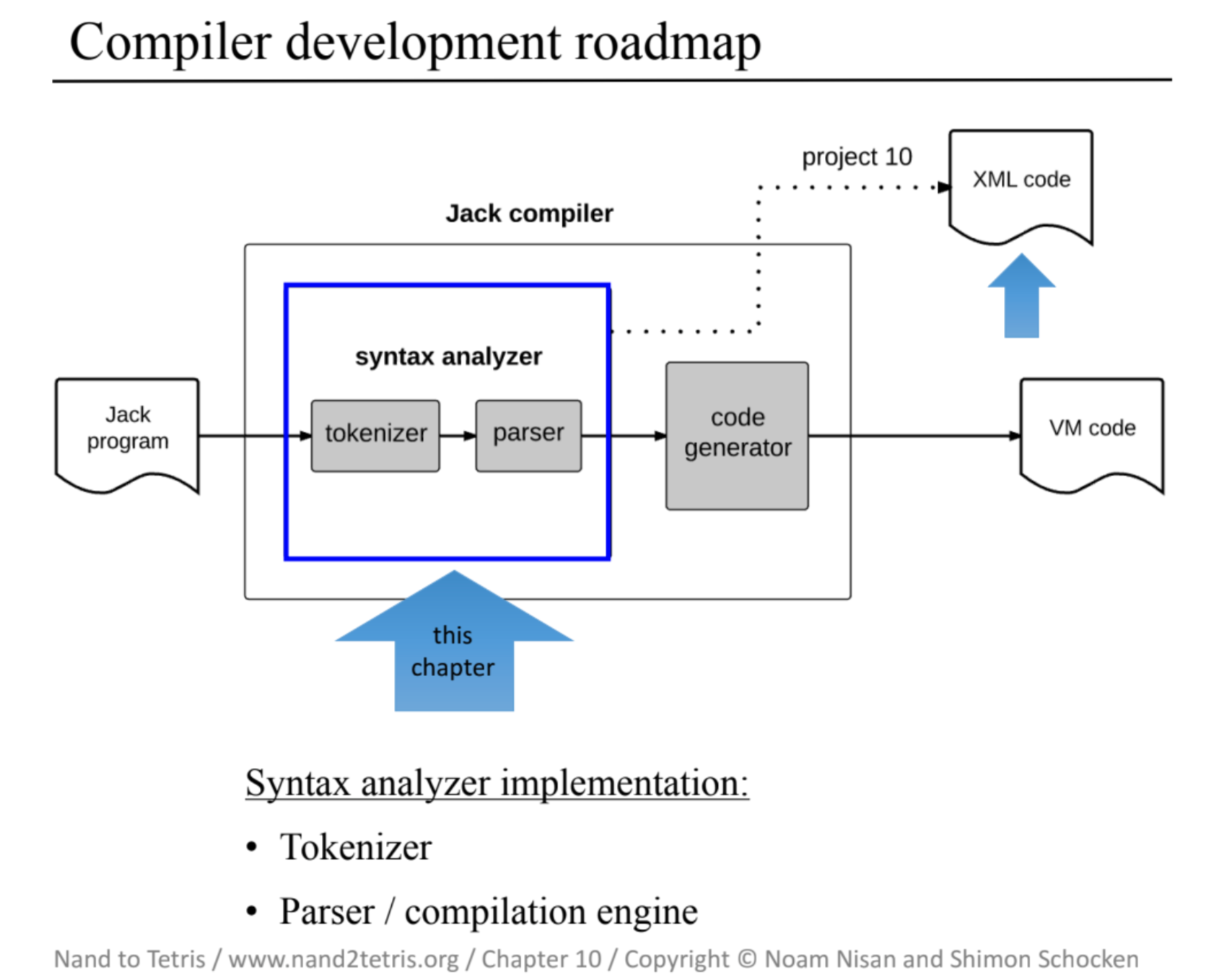
今回から行うコンパイラ実装は非常に難しいです。
なぜなら、コンパイラをゼロから書くには、コンピュータサイエンスにおける重要なトピックを学ぶ必要があるからです。
例えば、「再帰降下アルゴリズム」「字句解析」「文脈自由文法」「構文木」があります。
しかし、大変な分得られるものもかなり大きいです。
というのも、コンパイラのような普段あまり意識しない低レイヤ階層部分を理解することはエンジニアとしての幅を広げることに繋がりますし、さらに言うとコンパイラ作成で必要な知識や作業は他の分野においても応用が可能だからです。
(データベース管理、通信プロトコルなどその応用範囲は様々な分野にまで及びます。)
【補足】
一つ気をつけておいて欲しいのは、本来コンパイラを学ぶ際に扱われる言語理論というのは非常に複雑であるが故に、しっかりと理解するにはそれなりの時間がかかってしまうということです。かくいう筆者もたぶんこの分野については1mmも理解していません。
ただ「Jack言語の実装」という点においては知らなくてもできてしまうんです。これはひとえに
Jack言語を非常にシンプルで簡素なものとして設計しているからに他なりません。例えばJack言語では演算ごとの優先順位を考慮しませんが、これは我々が普段用いているプログラミング言語ではありえないことですよね。(足し算の前に掛け算を行うといった優先順位がない言語なんて見たことがありますか?)
こういった背景があるため、本章でコンパイラについて学んだからといって完全に理解した気分になってはいけません。コンパイラというのはもっともっと深く、そしてとても学び甲斐のある分野だということ忘れないようにしておきましょう。
全体像
さてでは今回作成する「構文解析器」について、まずはその実装の全体像を把握しておきましょう。
こちらも大きく分けて2段階に分けられます。
最初が与えられたソースコードを意味を持つ最小単位の「トークン(字句)」へと変換する 「字句解析」 と呼ばれる作業。次にその一連のトークンを特定の言語の構文ルールへと適合させ、その構文構造を明らかにする 「構文解析」 という作業です。
一つずつ見ていきましょう。
字句解析
まず最初に行うのは 「字句解析」 です。
そもそもこの一連の構文解析で行いたいことは 「プログラムの構造を理解する」 ということです。
では構造を理解するためには一体何が必要でしょうか?
当然我々のような人間ならプログラムを読んでその構造を完全に理解することは可能でしょう。
例えば、「クラスがどこから始まってどこで終わるのか?」「この宣言は何を定義しているのか?」「文は何で構成されているのか?」...など、こういったことは人間は容易に特定可能です。
しかし、「これらの作業を言語化してください」と言われたらどうでしょう。
たぶん皆さん何となくでしか答えられませんよね。
この「皆さんが無意識に何となく行なっている工程」を言語化して、一つずつ解明していこうよ♪というのが構文解析なんです。こう聞くと少しイメージが湧きませんか?
ただ一般的に普段我々が用いる自然言語(英語や日本語など)では曖昧性が存在しているためこういったことはできません。
しかし、今回考えていくJack言語のような形式言語(特定の目的のために意図的に作られたプログラミング言語のような言語)ではこういった構造を正確に定式化することが可能なのです。
特にプログラミング言語の場合2型である 「文脈自由文法」 と呼ばれる生成規則によって記述することができます。
文法とは簡単にいうと、その言語のルールみたいなもの。
例えば英語の命令文の場合、主語は省いて動詞から始めるというルールが定められていますよね。(例)Help me!
こういったものを一般的に文法と呼びます。プログラミング言語も当然言語なのでこういった文法が存在します。
ここまでをまとめましょう。
「与えられたプログラムの構造を理解する」とは、要は「プログラムのテキストとその言語の文法とが正確に適合されていることを確認できたぜ!ヒャッハー!」ということなのです。
で、この際にプログラムのテキストを最小単位にまで細かく分解する必要があり、この分解作業のことを「字句解析」と呼びます。
これも英語で考えたら簡単にわかります。
英語の命令文をめちゃくちゃ簡素な文法で定義すると以下のようになります。
(|は「または(or)」を意味します)【命令文】→【動詞】【目的語】= 命令文とは動詞と目的語が並んだものである
【動詞】→ help|catch = 動詞とは help または catch である
【目的語】→ you|me = 目的語とは you または me である上記の(例)の Help me! が上の文法と一致しているかどうかを調べるには、まずは意味のわかる最小単位(アルファベットではなく単語)にまで分割する必要があるのは当然ですよね。
単語に分割してからこの規則にあっているかどうか照らし合わせていくわけです。
ちなみにこの最小単位にまで切り分けられたものを「トークン」と呼びます。そのため、字句解析のことはトークン化などと呼ばれたりもします。
文法
構文解析に移る前に、文法について軽く触れておきましょう。
先ほども言いましたが、構文解析で行いたいことは「プログラムの構造を理解し、それを意味の単位にグループ化すること」です。例えば
while (count <= 100) {
count++;
//...
のようなものを見て、「これはC言語の文法と照らし合わせると文の中でもwhile文を表していて、count<=100は式を表していて...」という風に順に確かめれるということです。
このために必要となるのが「文法」と呼ばれる規則です。
文法をトークンに適合させながら変数宣言、文、式...などのような構造へとグループ化していくのです。
で、ほとんどのプログラミング言語は文脈自由文法と呼ばれる規則によって形式化できます。
文脈自由文法とは、「ある言語の構文要素がより単純な要素からどのように構成されるのか?」 ということを指定したルールの集合体です。
(先ほど記した英語の文章もこの文法に分類される)
本書のJack言語の場合、以下のように文法は表されます。(一部のみ)
statement: whileStatement
| ifStatement
| letStatement
statements: statement*
ifStatement: 'if' '(' expression ')'
'{' statements '}'
whileStatement: 'while' '(' expression ')'
'{' statements '}'
letStatement: 'let' varName '=' expression ';'
expression: term (op term)?
term: varName|constant
varName: アルファベット、数字、_の文字列。ただし数字から始まる文字列は除く
constant: 10進数
op: '+'|'-'|'='|'>'|'<'
ちなみに、上のクォート付きで囲まれた文字は 「終端記号(トークン)」 と呼ばれ、これ以上は展開できない記号を表しています。
逆にそれ以外のものは 「非終端記号」 と呼ばれ、文脈自由文法では何かしらの生成規則の左辺に必ずひとつ付きます。
また上の例からもわかる通り、文法は一般的に再帰構造をしています。
これは意外と重要で、これにより例えばセミコロンで分離された長い文でもこのようなシンプルな文法で適合させることができるようになっています。
【補足】
プログラミング言語の文法を定義する表記方法は、この文脈自由文法以外にも「BNF(Backus-Naur Form)記法」が用いられます。
基本情報技術者試験などを受けた人にはお馴染みの記法ですね。(↓こういうやーつ。)<数字>::= 0|1|2|3|4|5|6|7|8|9
<英字>::= A|B|C|D|E|F
<英数字>::=<英字>|<数字>|_
<変数名>::=<英字>|<変数名><英数字>
構文解析
さてでは本題の構文解析について少し触れていきましょう。
上にもある通り、文法は階層的な構造をとっています。
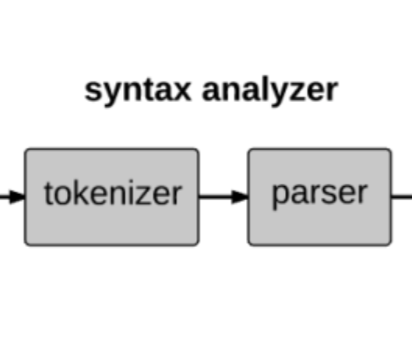
それ故この構文解析によって得られる出力のデータ構造は一般的に木構造で表すことになっています。
木構造とは、データ構造の一つで、一つの要素(ノード)が複数の子要素を持ち、子要素が複数の孫要素を持ち、という具合に階層が深くなるほど枝分かれしていく構造のこと。
例えば、先ほどのJack言語の文の場合、構文解析を行うと以下のような木構造で表すことができます。
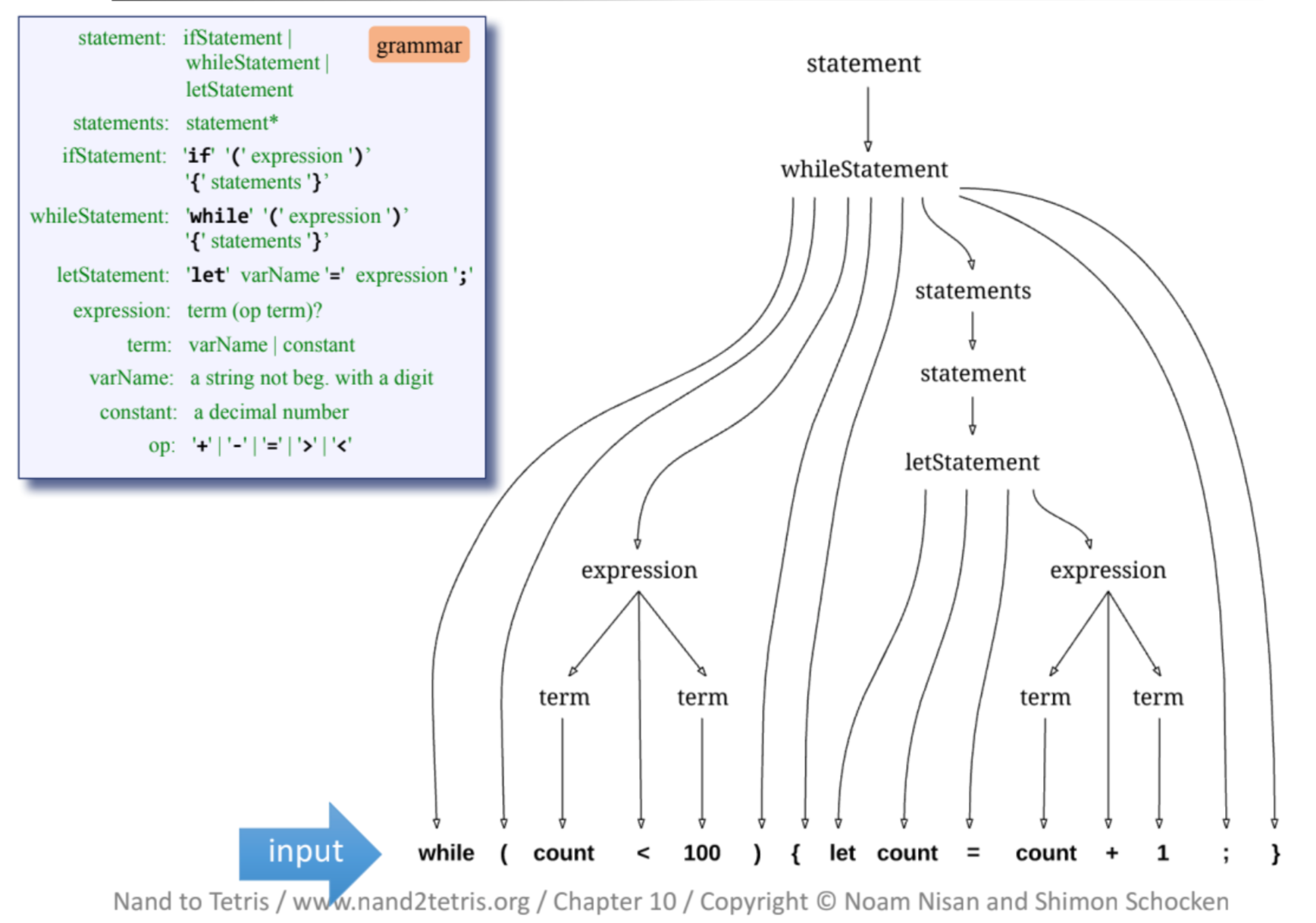
この構文解析によって得られる木構造は一般的に構文木と呼ばれたりもします。(厳密にいうと違いますが...)
今回の実装では、最終的にこの構文木をテキストとして表現したXMLファイルを出力することとします。

再帰下降構文解析
このように文法が与えられれば、それをどんどん展開していくことでこの生成規則に沿った正しい任意のプログラムを機械的に書くことが可能になります。
ただ今回我々が行いたいことは、むしろこういったことの逆の行為です。
我々は外部から文字列として何らかのテキストが与えられると、展開するとその入力文字列になる展開手順、すなわち入力と同じ文字列になるであろう構文木の構造が知りたいのです。
(ノリとしては因数分解みたいなイメージ。)
実はある種の文法に関しては、 入力としてある一連のトークン列と文法が与えられれば、その文法から生成される文にマッチする構文木を求めるコードを機械的に書くことが可能です。
「再帰下降構文解析」 とはそういったテクニックのうちのひとつです。
この再帰下降構文解析では、一般的に非終端記号を生み出すひとつの生成規則をそのままひとつの関数にマップしていきます。
そしてこの関数に沿って、また別の非終端記号を解析する関数を呼んで...というのを繰り返していき、最終的に終端記号が返されるまで繰り返していきます。
statement: whileStatement
| ifStatement
| letStatement
statements: statement*
ifStatement: 'if' '(' expression ')'
'{' statements '}'
whileStatement: 'while' '(' expression ')'
'{' statements '}'
letStatement: 'let' varName '=' expression ';'
expression: term (op term)?
term: varName|constant
varName: アルファベット、数字、_の文字列。ただし数字から始まる文字列は除く
constant: 10進数
op: '+'|'-'|'='|'>'|'<'
例えば、上記のJack言語の例で考えてみましょう。
このJack言語の文法の場合、10個の非終端記号を生み出す規則が存在しているため、 パーサにはまず10個の関数を用意します。
具体的にはparseStatement( )、parseStatements( )、parseIfStatment( )、parseWhileStatement...などです。
そして、今回の例だとプログラムはstatementから始めると決まっているので(実際のパーサもこんな感じで全体の読み込みをどの規則から始めるか決められている)parseStatementを呼んで入力トークンの読み込みを開始します。
まず最初のトークンが while であるため、 parseWhileStatement() を呼び出します。
対応する規則によれば、この関数は終端記号である「while」を読み、それから「(」を読みます。
次に、非終端要素である expression をパースするために parseExpression() を呼び出します。
そのparseExpression()は term をパースするために parseTerm を呼び、さらにparseTermは parseVarName もしくは parseConstant を呼びます。ここではcountというトークンからparseVarNameを呼びます。
そして...(以下略)
とまぁこんな感じで、 終端記号が読み込まれる場所まで再帰的に続けられるわけです。
【補足:LL(1)文法】
先ほどのパーサでは、非終端記号を解析する際に、入力の最初のトークンだけを読み取って関数を決定していました。
具体的にはparseStatementを呼び最初のトークンが「while」であったため、そこからこの文はwhile文であると確定させてparseWhileを呼び出しました。
このように非終端記号の種類を決めるにあたっていくつかの選択肢があった場合、トークンをひとつだけ先読みしてそのトークンの種類を決定づけることができる性質をLL(1)と呼びます。この性質を満たす文法は、
再帰下降構文解析によって簡単に扱うことができます。一方、最初のトークンだけから要素の種類を決定できない場合、 次のトークンをさらに先読みすることで種類を確定させることが往々にしてあります。 その場合はより多くのトークンを読むため、パーサーは非常に複雑になります。
今回作成するJack言語の文法では、そのほとんどがLL(1)であるため、再帰下降を行うパーサによって非常に簡単に扱うことができます。(例外として式のみ先読みが必要)
実装
では具体的な実装案に入っていきましょう。
今回の実装では以下の3つのモジュールを作成します。
| モジュール名 | 動作内容 |
|---|---|
| JackAnalyzer | セットアップや他モジュールの呼び出しを行う。下2つのモジュールをコンパイラした結果物。 |
| JackTokenizer | トークナイザ。字句解析を行う |
| CompilationEngine | 再帰下降構文解析によるトップダウン式の解析器 |
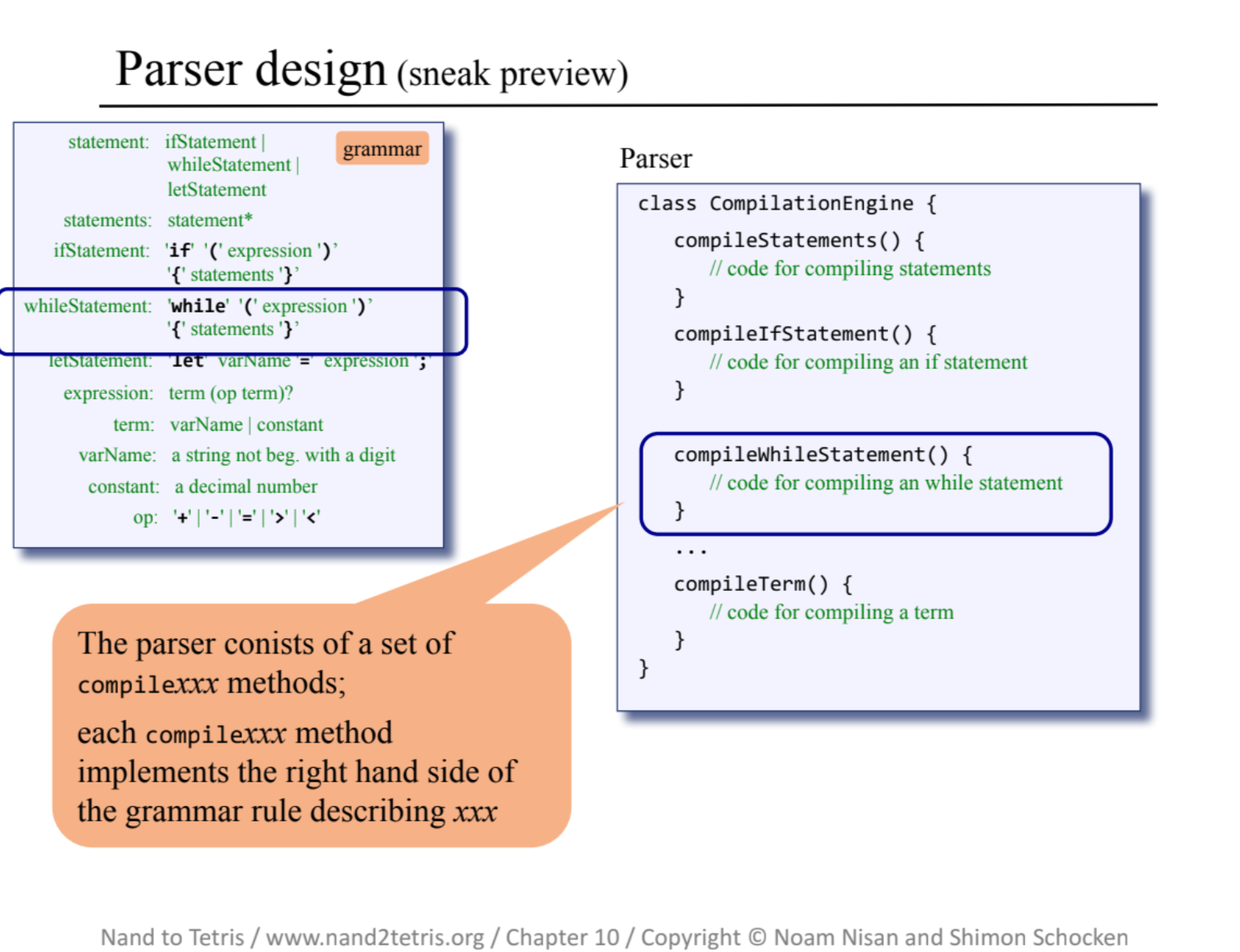
まず最初に字句解析を行う JackTokenizerモジュール を作成し、次段階として CompilationEngine を搭載したパーサを作成していきます。
CompilationEngineの作成は、 式以外の要素を扱うものとそうでないものとで分けて実装していきます。
式を含むと先読みが必要になり複雑なプログラムになってしまうため、ここでは分けて実装することをおすすめします。
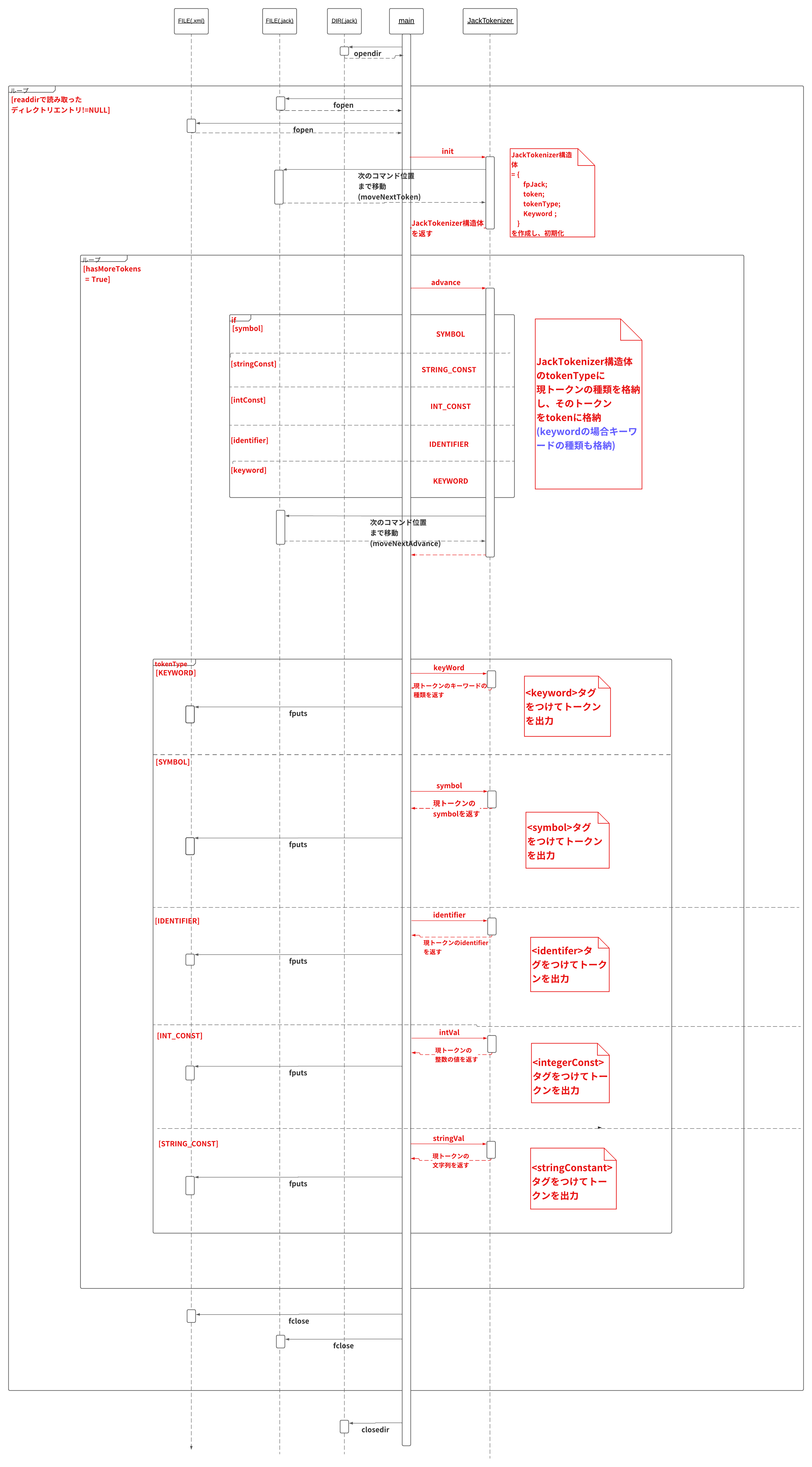
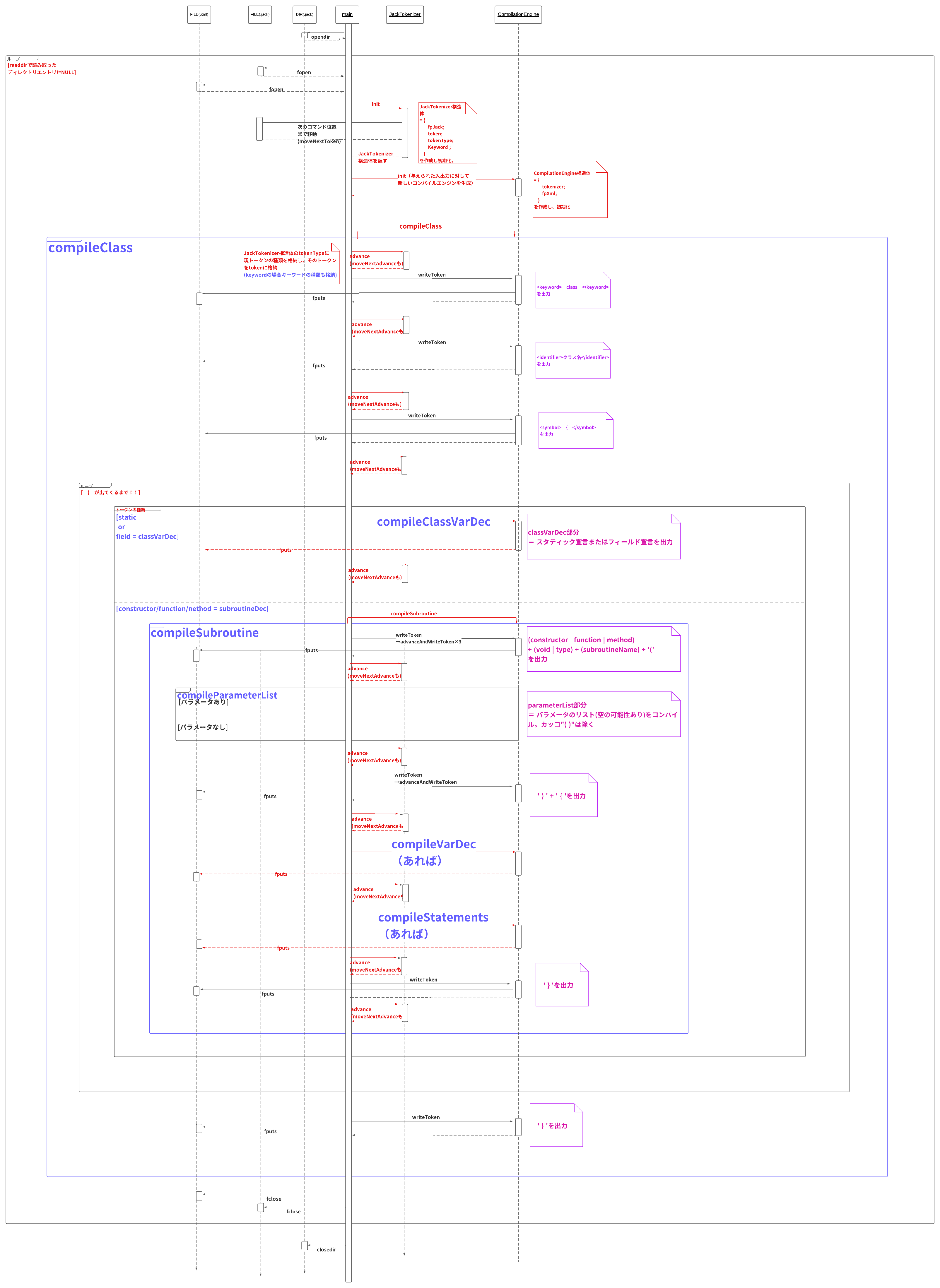
以下にそれぞれのモジュールを搭載したパーサプログラムのシーケンス図を載せておきます。
注意点として、 CompilationEngineモジュールの関数を呼び出す際は、必ずJackTokenizer構造体にトークンを格納した状態で行いましょう。
関数を呼び出してからトークンを格納しないことを前提にプログラムを作成していますので、もし参考にされる方がいましたらその点はご注意ください。
①JackTokenizer
②CompilationEngine
長いので、compileStatements以下は含めていません。
11章:コンパイラ#2:コード生成
この章では前章で作成した構文解析器を 完全版のコンパイラ へと拡張します。
前章までで構文解析器によって高水準言語を「理解」することができました。
完全版のコンパイラではその「理解」された高水準言語を、同等の意味を持つ一連のVM命令へと再構成します。いわゆる「コード生成」を行うモジュールを作成していきます。
さて高水準言語とVM言語の対応関係について、今回は「データ変換」と「コマンド変換」の観点で見ていきたいと思います。
こうしたのは基本的に高水準言語で書かれたプログラムというのは、データを操作する一連の命令で構成されているためです。操作したいデータをプラットフォーム用に変換して、コマンドで操作するといった感じ。
データ変換
まずはデータ変換。
これは要は、プログラム中で宣言される様々な型( int、booleanなど)や属性( field、var、引数、パラメータ引数、スタティック変数など)の変数をVMの仮想メモリセグメント上でどのように対応づけるか? ということである。
これだけ聞くと難しそうに見えますが、実はあまり難しくはありません。
というのも、このデータ変換は何も 「メモリ上にそのまま対応づける」 という意味ではないからです。
上でも述べましたが、あくまで対応づけるのは "VMの仮想メモリセグメント上" なんです。別に具体的なアドレスに割り当てる必要なんて一切ありません。
(そういった作業を我々はすでにVM変換器の開発で行いましたよね(笑) 忘れてしまった人は8章の辺りを読み返せばすぐに思い出すはずです。)
例えば、ローカル変数。つまり以下のような関数内だけで定義される変数を考えてみよう
function void main(){
var Array a;
var int length;
var int i, sum;
// 以下略
}
このローカル変数は、単純に仮想localセグメントを用いて割り当てればいいだけです。具体的に何かを操作する必要なんてなく、ただ以下のようにfunctionコマンドを定義すればいいだけなのです。
function Main.main 4
// 以下略
こうすればfunctionコマンドによって自動的に4つのローカル変数領域が0に初期化された状態で確保されます。
シンボルテーブル
とまぁこんなふうにメモリの割り当てやアクセスは全部低レイヤ側が引き受けてくれるということなんです。
VM作っておいてよかったですね本当に。
ただ少々厄介なのが、高水準言語には 「スコープ」 という概念が存在することです。
これは 変数の有効範囲 を示したものなのですが、これによって低レイヤでは以下のような属性が書かれていない変数や同じ名前の変数が入り込む場合にも対処しなければいけません。
class Square {
field int x,y;
field int size;
constructor Square new(int Ax, int Ay, int Asize){
var int length, size;
var boolean status;
let x = Ax;
let y = Ay;
let size = Asize;
// 以下略
}
// 以下略
}
このプログラム中に出てくる「 x 」「 y 」「 size 」が一体どんな属性でどんな型の変数なのか?はこの文を見ただけではわかりません。
さらに言えば、それぞれのローカル変数がセグメント内のどこに割り当てられるのか?といったこともメモしておかないと後で使用できませんよね。
こういったことを解決するために用いられるのが 「シンボルテーブル」 と呼ばれるものです。
プログラム中で新しい識別子に出くわすたび(例えば変数宣言など)、コンパイラはその情報をシンボルテーブルに追加していきます。そして他の場所で識別子に出くわすたびコンパイラはシンボルテーブルでその識別子を探し、必要な情報を得ていきます。
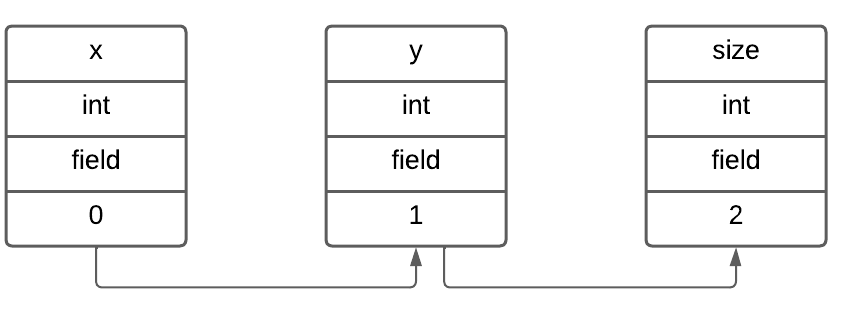
先ほどのSquare.jackファイルならまずフィールド変数のx, y, sizeに遭遇するのでこれらを記録します。次にコンストラクタに入ると引数のAxや Ay、size とローカル変数lengthとstatusに出くわすのでこれも記録します。
| 名前 | 型 | 属性 | 番号 |
|---|---|---|---|
| x | int | field | 0 |
| y | int | field | 1 |
| size | int | field | 2 |
| Ax | int | argument | 0 |
| Ay | int | argument | 1 |
| Asize | int | argument | 2 |
| length | int | local | 0 |
| size | int | local | 1 |
| status | boolean | local | 2 |
そして、記録した変数に出くわすと今度はその情報をシンボルテーブルから引っ張り出してきます。
先ほどの例なら、let文の x や Ax などに遭遇すると 「xは最初のfield変数でint型なんだな」 みたいな情報を得て、それを用いてアクセスします。
先ほどのコードのlet文の部分のみVM言語に変換すると以下のようになります。
(ちなみにthisセグメントはヒープの中にあるオブジェクトを格納するための専用領域。フィールド変数はここに割り当てられる。)
push argument 0
pop this 0
push argument 1
pop this 1
しかしこのシンボルテーブルですが、肝心のスコープの情報に関しては不十分です。
事実、上のテーブルにはクラス用のスコープと関数用のスコープがごちゃ混ぜになっています。(それ故sizeがどちらのものなのか識別できない。)
そこでスコープを記録するために、「リスト」 を用います。
具体的にはひとつのリストをクラス用のスコープ、もうひとつを関数用のスコープのために準備し、それぞれの範囲で新しい識別子に遭遇するたびにリストの要素を増やしていく...といった操作を行います。
先ほどの例の場合だと以下のように改良されます。(上がクラス用スコープ、下が関数用スコープ)
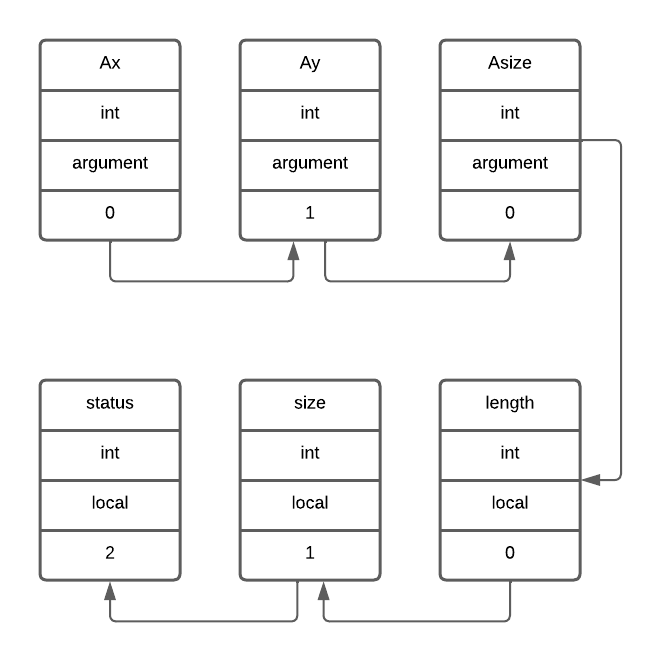
基本的にスコープの包含関係は「関数用⊂クラス用」となってるので、関数用スコープから探して該当識別子が存在しなければクラス用スコープから探すといった具合に探索していきます。
つまり先ほどのsizeは先に関数用スコープから探し出して見つかるので、属性はargumentだと識別できるわけです。
配列操作
Jack特有のデータ構造として 「配列」「オブジェクト」 が存在します。
これらはVMには存在しないため、VM言語にコンパイルする際はこれらを当然VM用に変換する必要があります。
まずは「配列」から見ていきましょう。
基本的に配列というのは連続したメモリ領域に格納され、その配列名はポインタ(その配列が格納されたRAMのベースアドレス)として扱われます。
C言語やってる方にとってはお馴染みですね。
そしてJavaをやっている方なんかにお馴染みかもしれませんが、一般的にこの配列は宣言時にはポインタひとつ分のメモリ領域しか割り当てらません。実際の配列領域は実行時にそれが生成された時に割り当てられるようになっています。
今回のJack言語もこれらを前提に配列を用いています。
つまり、配列宣言時にはその配列名のポインタのみを用意し、実際に生成された時にOSによってメモリ領域が確保されるということです。
実際のこのメモリ領域の確保にはArrayクラスのコンストラクタを用います。
この関数はメモリサイズを指定することで、ヒープからその指定サイズのメモリブロックを探し出し確保し、そのベースアドレスを返すようになっています。
以下に例を載せておきます。
// var Array bar;
// let bar = Array.new(8);
push constant 8
call Array.new 1 // これが実行されて初めて配列は実体を得る
pop local 0
では、次にこの配列を操作する場合について考えていきましょう。
例えば先ほどのbarに「bar[k] = 19」という文を追加した場合、どのように変換されるでしょうか?
まずbarというのは配列のベースアドレスを指すのでこの文はC言語に置き換えると、要は「*(bar+k) = 19」という文になります。
C言語では*(address)でaddressが指すメモリにアクセスできます。
これを参考にVM言語に変換すると以下のようになります。
// var Array bar;
// let bar = Array.new(8);
push constant 8
call Array.new 1
pop local 0
// let bar[k] = 19;
// (bar + k)の計算
push local 0
push constant k
add
pop temp 2 // temp[2]は配列ポインタを一時的に格納するために使用
// *(bar + k) = 19
push constant 19
push temp 2
pop pointer 1 // thatセグメントのベースアドレスを指定
pop that 0 // 配列はヒープ領域の中のthatセグメントに格納される
オブジェクト操作(データ)
次にオブジェクト操作について見ていきましょう。
オブジェクトも基本的に配列と似たような考え方をします。
ただ唯一違うのは、オブジェクトはデータだけでなく、データを操作する「メソッド」もカプセル化されているという点です。
データとメソッドは各オブジェクトごとにカプセル化されているため同じように思えますが、コンパイラによって全く別物として扱われます。
まずはデータから見ていきましょう。
データに関しては、先ほど見た配列とほとんど同じです。クラス型の変数が宣言された時にそのオブジェクト名のポインタのメモリ領域のみ割り当てられ、実際にそのクラスのコンストラクタが呼ばれた段階で中身のメモリ割り当てが行われます。
例えば、以下のようなコードを考えていきましょう。(シンボルテーブルと同じサンプルプログラム)
class Square {
field int x, y;
field int size;
constructor Square new(int Ax, int Ay, int size){
var int length;
var boolean status;
let x = Ax;
let y = Ay;
let size = size;
// 以下略
}
// 以下略
}
これがコンパイルされると、まずコンパイラはそのクラスのフィールドの数と属性を調べて、RAM上でSquare型のインスタンスを生成するのに必要なメモリ領域の大きさを計算します。
今回の場合、int型のフィールド変数が3つあるので3番地分が必要なメモリ領域の大きさになります。
そして次にこのメモリを実際にヒープ領域から探し出し、確保するコードを生成します。
配列の場合ここでArray.new(int size)が用いられましたが、オブジェクトの場合はMemory.alloc(int size)を用います。
次にthisセグメントのベースアドレスを確保したメモリ領域の先頭アドレスに変更します。
具体的にはpointer[ 0 ]にベースアドレスを格納します。
これらをまとめると以下のようなコードに変換されます。
/* class Square {
field int x, y;
field int size;
constructor Square new(int Ax, int Ay, int size){
// 以下略
}
// 以下略
} */
// コンストラクタ実行開始時
function Square.new 2
push constant 3
call Memry.alloc 1 // 戻り値として確保したメモリ領域の先頭アドレスがワーキングスタックの一番上にpushされる
pop pointer 0 // thisセグメントのベースアドレスを変更する
では次にこのオブジェクトを操作して、カプセル化されたデータにアクセスして見ましょう。
これも配列と考え方は同じで、ベースアドレスからの相対的なインデックスを用いることでアクセス可能です。
/* class Square {
field int x, y;
field int size;
constructor Square new(int Ax, int Ay, int size){
var int length;
var boolean status;
let x = Ax;
let y = Ay;
let size = size;
// 以下略
}
// 以下略
} */
// オブジェクト生成後のコンストラクタの流れ
...
push argument 0
pop this 0
push argument 1
pop this 1
push argument 2
pop this 2
要は「 let x = Ax; 」という文の場合、xはthisオブジェクトの0番目のフィールドで、Axはコンストラクタの最初の引数であることをシンボルテーブルから確認できる ので、C言語風に書くと
「*( this + 0 ) = *( argument 1 )」
となることがわかります。
オブジェクト操作(メソッド)
さてでは最後に「メソッド」について見ていきましょう。
例えば以下のようなコードを考えてみましょう。
class Main {
function void main() {
var SquareGame game;
let game = SquareGame.new();
do game.run();
do game.dispose();
return;
}
}
...
// (別のファイル内)
class SquareGame {
field Square square;
field int direction;
constructor SquareGame new() {
let square = Square.new(0, 0, 30);
let direction = 0;
return this;
}
method void run() {
// 略
}
// 以下略
}
main関数内の2行目までは今までやったことなので特に問題はないでしょう。問題は3.4行目です。
コンパイラはメソッド呼び出しをどのように処理するのでしょうか?
まず押さえておかなければいけないのが、データはインスタンスごとに別のコピーが存在する一方で、メソッドは対象のコードレベルに変換されたコピーがただひとつしか存在しないということです。
どういうことか?というと、例えば上記の例の場合SquareGameクラスのインスタンスgameが生成されますが、このインスタンス自身にはrunメソッドなどは含まれないということです。
(↓こんなイメージです...)
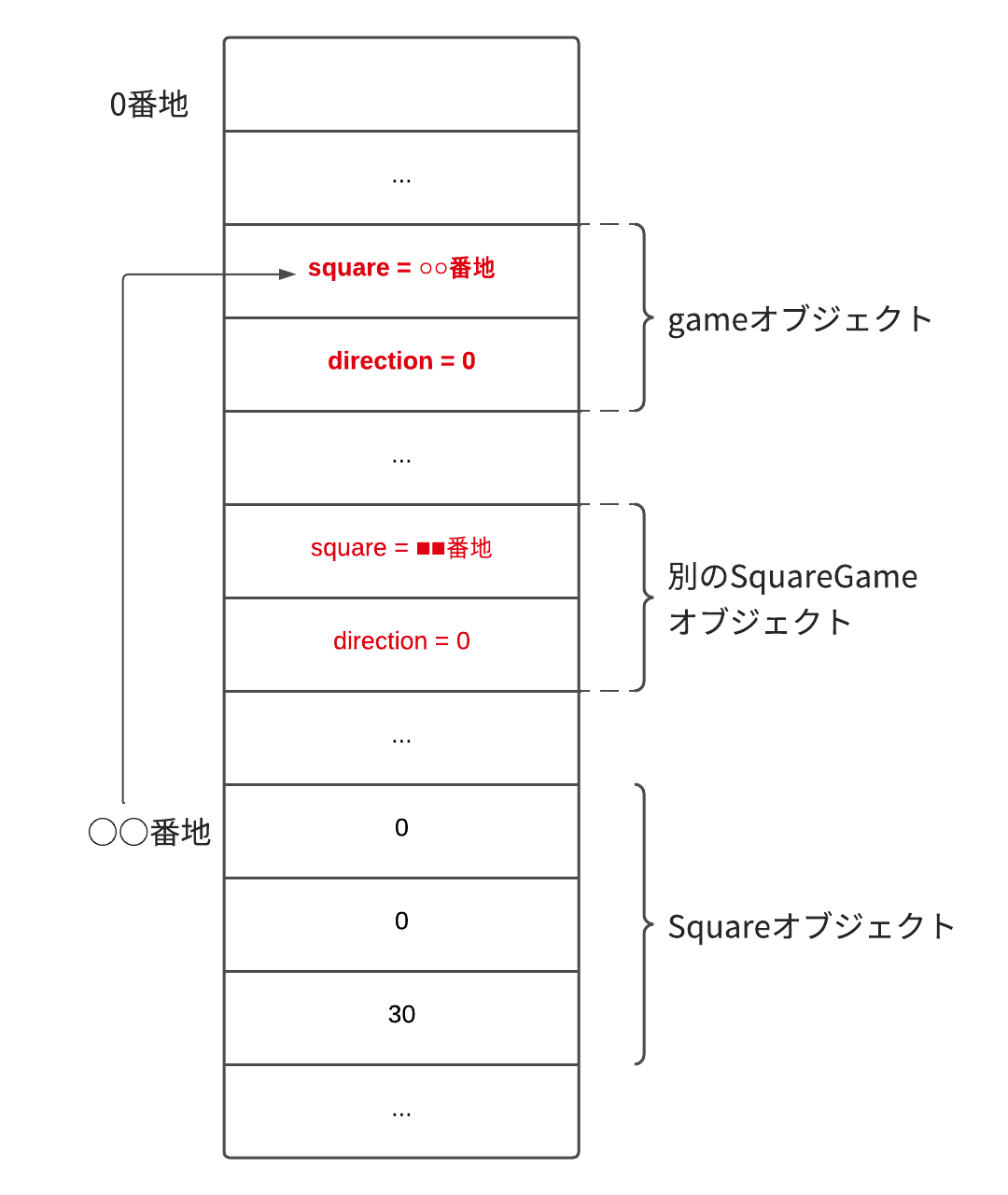
一方、このメソッドは上記にもある通り同じクラスから生成されたオブジェクト全てに適用できるという矛盾を孕んでいます。
つまり、まるでひとつだけしか存在しないメソッド(run)を対象オブジェクト(SquareGame game)に対して適用しているかのように見せかけれるわけです。
これでははあたかもオブジェクト自身がそのメソッドを格納しているかのように見えてしまいますね
では一体どのようなトリックを用いてこれを実現させているのでしょうか?
そのカラクリが、操作するオブジェクトのベースアドレスをメソッドの「隠れ引数」として渡すということです。
例えば、先ほどの例だとmain関数内の3行目「 do game.run() 」は隠れ引数としてgameオブジェクトのベースアドレスをrunメソッドに渡しているということになります
/* class Main {
function void main() {
var SquareGame game;
let game = SquareGame.new();
do game.run();
do game.dispose();
return;
}
} */
// main関数の流れ
function Main.main 1
call SquareGame.new 0
pop local 0
push local 0 // 隠れ引数としてオブジェクトのベースアドレスを渡す
call SquareGame.run 1 // 隠れ引数の分、引数を増やしている
pop temp 0
push local 0
call SquareGame.dispose 1
pop temp 0
push constant 0
return
こうすることで、低レイヤでは別オブジェクトに対して同じメソッドを適用できるしているにも関わらず、高水準言語の視点で見れば各々のオブジェクトが自身のコードをカプセル化しているように見せれるわけです。
お見事!
コマンド変換
最後にコマンド変換の中で「式の評価」について簡単に触れておきます。
例えば、「 1 + ( 2 * 3 ) 」のようなJack言語の式を評価するためにはどのようなコードを生成すれば良いでしょうか?
これは意外と簡単で結論から言うと、構文木の構造に従って再帰的に後行順探索すれば良いだけで済みます。
順を追って説明していきます。
まず数式をスタックマシン上で評価するためには、その数式を 「逆ポーランド記法」 で表現する必要があります。
「逆ポーランド記法」とは項の後ろに演算子記号を記述する方式で、先ほどの例の式だと「 1 2 3 * + 」となります。
こうすればこの表記順に値をpushし、演算を行うだけで式を計算することができます。
// 1 + ( 2 * 3 ) = 1 2 3 * +
push 1
push 2
push 3
call Math.multiply 2 // 掛け算
add
つまり、式を逆ポーランド記法で表せればスタックマシン上で簡単に計算できるということです。
では前章の構文解析器で得られた構文木をどのように変換すれば逆ポーランド記法の数式が得られるのでしょうか?
この作業は非常に単純で、構文木を再帰的に後行順探索すればいいだけです。
具体的には以下のように構文木を探索していきます。
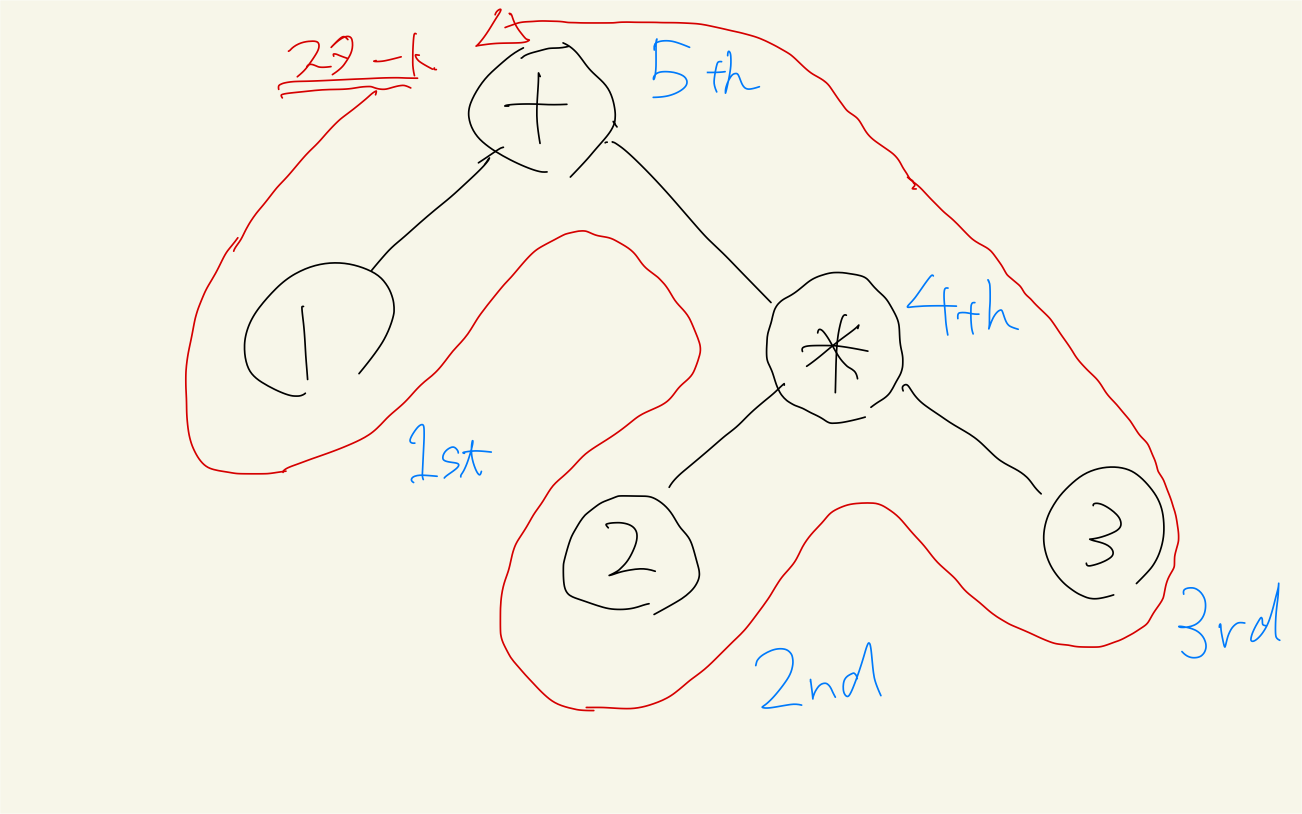
このように構文木を後行順探索するアルゴリズムに関しては、こちらの記事に載っていますので詳細を知りたい方はぜひ参照してください。
この後行順探索アルゴリズムを元に、プログラムを作成していきます。
実装
次に具体的な実装法について軽く触れておきます。
今回は主に以下の5つのモジュールを作成していきます。
| モジュール名 | 動作内容 |
|---|---|
| JackCompiler | セットアップや他モジュールの呼び出しを行うモジュール。下4つのモジュールをコンパイルした結果物 |
| JackTokenizer | トークナイザ。前章と同じ |
| SymbolTable | シンボルテーブル |
| VMWriter | VMコードを生成するための出力モジュール |
| CompilationEngine | 再帰によるトップダウン式の解析器 |
いきなり全てを作成するのは難しいので順を追って実装していきましょう。
まず第一段階としてシンボルテーブルを作成するSymbolTableモジュールを実装していきます。
ここでは前章の構文解析器にシンボルテーブル機能を追加したものを最終的に作ります。
シンボルテーブルが正しく機能しているかどうかをチェックするため、XMLの出力の一部に
- 識別子のカテゴリ(var, argument, static, field, class, subroutine)
- 識別子が定義済みかどうか
などの情報を追加すると良いでしょう。
面倒だったので私はしていません!(笑)
第二段階ではコード生成モジュールの作成を行いましょう。
書籍の仕様を確認しながら上記に記した5つのモジュールの実装を行なっていきます。
またここでは段階的にテストを行えるように6つのテストプログラムが用意されていますので、このプログラムを順番通りにクリアしていくことを目標に実装を行なっていくと良いでしょう。
特に「一気に全ての機能を搭載したコンパイラを作るのはハードルが高すぎる(汗)」という自分みたいな人はこちらのテストプログラムを活用することを強く推奨します。
注意点
では最後に実装段階で私がつまずいたところであったり、「ここの実装は注意した方が良い」と思った箇所について簡単に箇条書きでメモしていきます。
個人的には「関数呼び出し」と「関数の実体」の部分のコードを変換するのが苦労しました(泣)
もし実装で詰まった人がいましたら、ぜひ参考にしてください。
※注意点
- サブルーチンとクラスの名前は subrotineCall で見分ける必要があるが、トークンを先読みすることにより見分ける事ができる。よってサブルーチンとクラスの名前はシンボルテーブルに記録する必要なし。
- parameterListとexpressionListの違い = parameterListはシンボルテーブルに記録するだけ。expressionListは具体的な式の評価をしてワーキングスタックにpushする
- subroutineCallの先読みで 「.」 がきて、変数属性があればvarNameと確定。なければclassName。
- classNameはそのまま関数呼び出し。
- varNameならそのオブジェクトのベースアドレスをpush(メソッド呼び出しだから)→オブジェクトのクラスをハッシュテーブルで調べて関数呼び出し。
- subroutineのみなら現在のthisセグメントのベースアドレスをpushし、格納してあるclassNameを利用し関数呼び出し
- 4~6のsubroutineCallの違いは めちゃくちゃ重要
- Jackのメソットまたはコンストラクタに対応するVM関数の中では、そのオブジェクトのフィールドへアクセスできるようにするためthisセグメントが現在のオブジェクトを指すように設定する必要がある。
- ただfunctionの場合はクラス全体に属して特定のオブジェクトに属しないのでこの操作は必要ない
- コンストラクタとメソッドのVM関数内の違い = constructorは 自身でオブジェクトのアドレスをMemory.allocで設定し、thisセグメントのベースアドレスに設定。 methodは引数で渡されてくるのでそれをthisセグメントのベースアドレスに設定
- メソッドをVM関数へコンパイルする場合(method void ~ みたいな形のやつ)、thisセグメントのベースを正しく設定するVMコードを入れる必要がある。この場合、少し特殊で あらかじめその関数のシンボルテーブルリストにthisを属性=argument、index=0にして登録しておく。
- そしてthisのベースアドレスを設定。こうする事で、thisは引数で渡されたオブジェクトのベースアドレスとして登録され、いつでもシンボルテーブルリストから呼び出せる。また引数が+1されることにもしっかり対応。
- 文字列作成 = String.new(文字の長さ) → String.appendChar(文字コード)×文字数分
【補足】
少し補足として、このJackコンパイラの開発は通常のコンパイラ開発と比べるとかなり難易度が低く設定されていることに触れておきましょう。これはJack言語を比較的単純な言語として設計しであるからに他なりません。
例えば、Jack言語は型付き言語の形をとってはいますが、実情はそれとはかけ離れています。
(こういうのを弱い型付け言語と言うらしい。)
そのため代入や演算操作において型の一致は厳密には要求されず、弱い型付けの例1(ポインタに直接数値を代入)var Array a; let a = 5000;なんてことも可能です。これは参照変数(ポインタ)へ直接数値を代入しています。
C言語のような強い型付け言語では普通の数値とメモリ番地は根本的に違うと言う考え方で設計されているためこういうのはエラーは出ないまでも警告(warning)が出たりしますね。他にも文字と数字は必要に応じてユニコードの仕様に基づいて自動で変換されたり、さらにオブジェクト変数はArray変数に相互に変換が可能だったりします。
弱い型付けの例2(文字と数字の変換)var char c; var String s; let c = 33; // 'A' // 下のコードでも同じ結果になる let s = "A"; let c = s.chartAt(0);弱い型付けの例3(オブジェクト変数⇔Array変数)// Complexというクラスがあり、そのクラスには re と im という二つのフィールドがあるとする var Complex c; var Array a; let a = Array.new(2); let a[0] = 7; let a[1] = 8; let c = a; // c == Complex(7, 8)また、他にJack言語が簡単に設計されている例としては、
・doやletなどのキーワードを用いて文を簡単に見分けられるようにしている
・1行の文でも波カッコを用いる必要がある
・演算子の優先順位(掛け算の方が優先されるなど)を考慮しない
・クラスの継承をサポートしていないといったことが挙げられます。
12章:オペレーティングシステム
さて最後はオペレーティングシステム、つまりOSを作成していきます。
ここでは主にハードウェアの込み入った詳細をソフトウェアにカプセル化していき、自由自在にコード中のどこからでも使えるようにしていきます。
具体的には OSをJackクラスの集合体としてパッケージして、それぞれがJackのサブルーチン呼び出しを通してサービスを提供できるようなものを実装していきます。
(いわばOSという名の標準ライブラリみたいなものを作っていくわけです。)
ただ今回作成するOSは コンパイラ同様かなり簡易化されたものになっています。
例えば、一般的なOSに備えられているGUI機能やマルチタスク、シェル、さらにはプロテクトモードや通信機能といったものは一切ありません。(正直OSといったらこっちが本丸ですらある)
まぁこれらの機能を備えたOSを作ろうとするとそれなりの労力と時間がかかりますからね。OSをちゃんと自作したい人は「30日でできる! OS自作入門」とかがおすすめなので、そちらをどうぞ。
とはいうものの、やはりそれなりに大切な機能を備えているのも事実でして、本章ではその辺りを中心に説明していきたいと思います。
そもそも論
本題に入る前に毎度の如く 「そもそも論」 的な部分に少し触れておきたいと思います。
OSとは"そもそも"どんな役割を果たすものなのでしょうか?
例えば「Hello World」のようなテキストをコンピュータ上のスクリーンに表示させることを考えてみましょう。
Hackマシンの仕様によればスクリーンはアドレス16384(0x4000)から始まる8KのRAMにマッピングされているため、この中の適切な位置にビットを書き込むコードを書いていけば良さそうです。
具体的に機械語でコードを書いてみると
@××× // 表示位置
D = A
@SCREEN
D = M + D // 表示させたい位置を設定
A = D
M = -1 // 例として表示させたい位置を黒に塗りつぶす
...
みたいなコードを延々と書いていく必要があります。
これはここまでHackマシンの作成を行なってきた人にとっては尚更厄介な作業であることがわかるでしょう。だっていちいちメモリ位置を求めて1ビットずつ適切に書き込んでいく必要があるんですよ。面倒くさすぎます。
高水準言語を用いるエンジニアにとってはこれよりももっと簡単な方法が求められるのも当然です。
そこで颯爽と登場するのがOSです。
Jackの場合、
do Output.printString("Hello World");
というOSのコマンドを使うだけでこの操作を実行できるようになっています。さっきまでの苦労が嘘のようです。
このように本章では ハードウェアとソフトウェアシステムのギャップを埋めるものとしてOSを解釈し、また次の2つのことを目標に作成していきます。
(なおOSはJack言語で書いていくものとします。)
- ハードウェアに特化したサービスをカプセル化し、ソフトウェアから使いやすいサービスを提供すること
- 高水準言語を、様々なファンクションと抽象データ型で拡張すること
【補足】
実際「OSとは何なのか?」という質問にはたくさんの答えがあり、一概に定義することはできません。
そのため今回作成するOSはある人にとっては「これは正真正銘OSそのものだ!」と言えるでしょうし、またある人にとっては「こんなのはOSじゃない!」と言えるでしょう。(たぶん大半は後者)ただ理解して欲しいのは、今回の一連の作業の目的は 「ハードウェア階層からソフトウェア階層まで一気通貫でコンピュータを作成することにより、コンピュータの動作原理の全体像を理解する」 ということであり、OSを自作することではないということです。
そのため少々大雑把に見えるものを作ろうが「OSを作ることで得られる恩恵」や「OSを作成する目的」を肌感覚として多少なりとも感じれればそれで万々歳なんです。誰がみてもOSと呼べるような代物を作る必要なんて一切ないんです。
つまりほぼ標準ライブラリと言えるであろうJack OSもちゃんと作る意味はあるということです...(だからあんま悪く言わないであげてね♪)
数学的操作
まずは高水準言語の拡張として、様々な数学的操作をサポートしていきましょう。
ここでOSを作る際に 「処理時間に気を遣う」 必要があることに触れておきます。
なぜ処理時間に気を付ける必要があるのかというと、OSがチンタラチンタラ実行してたらせっかく使っているのに余り意味がありませんし、またコンピュータは数字を2進数で処理していくため大きい桁の数字の計算では時間がかかるということも挙げられます。。
一般的にOSでは処理時間がnビットの数字の "値" に比例するアルゴリズムは歓迎されません。
これはその値はnの指数関数的に増えていくため(2^n)、桁数が大きければ大きいほどより処理時間がかかるようになっていくからです。
そのため本書では "値" そのものではなく、ビット数 "n" に比例した処理時間となるようコードを書いていきます。
【補足:Big-O記法】
処理時間をわかりやすく表記するために用いられるのが、Big O-記法と呼ばれるものです。
これはO (n)のような形で表され、この場合だと「nに比例した処理時間がかかるよー」というような意味になります。
ちなみに数学的操作はMathクラスにパッケージ化されています。
他にもOSには以下のような7つのクラスが存在します。これらの各クラスの関数を作っていくわけですね。
| クラス名 | 動作内容 |
|---|---|
| String | String型と文字列に関する関数を提供する |
| Array | Array型と配列に関する関数を提供する |
| Output | スクリーンへのテキスト入力 |
| Screen | スクリーンへのグラフィックによる出力を扱う |
| Keyboard | キーボードからのユーザー入力を扱う |
| Memory | メモリ操作を扱う |
| Sys | プログラムの実行に関連するサービスを提供する |
さてではまず例として乗算についてみていきましょうか。
これは我々が普段行っている筆算と同じ方法を用いることで、O( n )の加算演算となります。
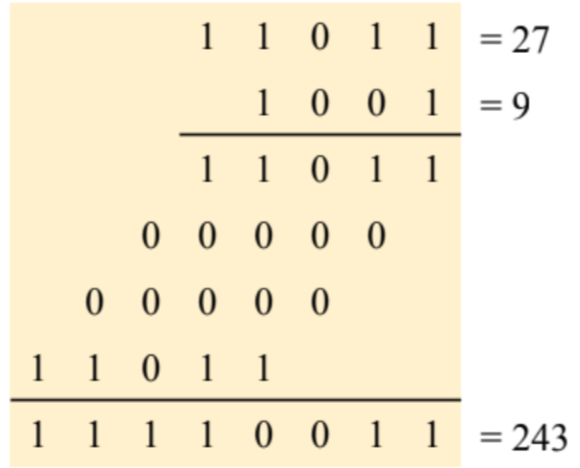
これをコードに落とし込めば良いわけですね。
他にも除算や平方根もありますが、これらはテキストに詳しく書かれていますのでそちらを参照してください。
メモリ管理
OSの代表的なメモリ管理術として 「動的メモリ割り当て」 と呼ばれる方法があります。
これは
「配列やオブジェクトは宣言時にはあえてポインタひとつ分のメモリスペースだけを割り当て、実際のメモリはプログラム実行時に割り当てる」
といった際に用いられる方法です。そしてこの配列やオブジェクトは必要なくなった時にその領域が再利用されるようになっています。
Javaのようなオブジェクト指向言語では、このいらなくなったメモリを自動的に破棄する仕組みが備わっていて、これを「ガーベージコレクション」と言います。
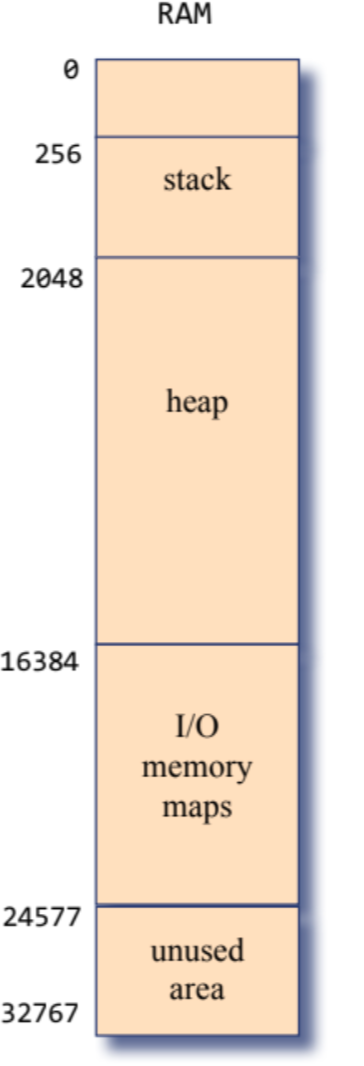
この動的に割り当てが行われるRAMセグメントは主に「ヒープ領域」と呼ばれていて、このヒープの管理を行うのがOSというわけです。
そしてOS は伝統的にalloc()とdeAlloc()という2つの関数を用いてヒープを管理します。(以下はJackメモリのメモリマップ)
さて、ではこのメモリ割り当てと破棄はどのようなアルゴリズムで行ったら良いのでしょうか?
今回は、利用可能なメモリセグメントを 「連結リスト」 を用いることで管理していきます。
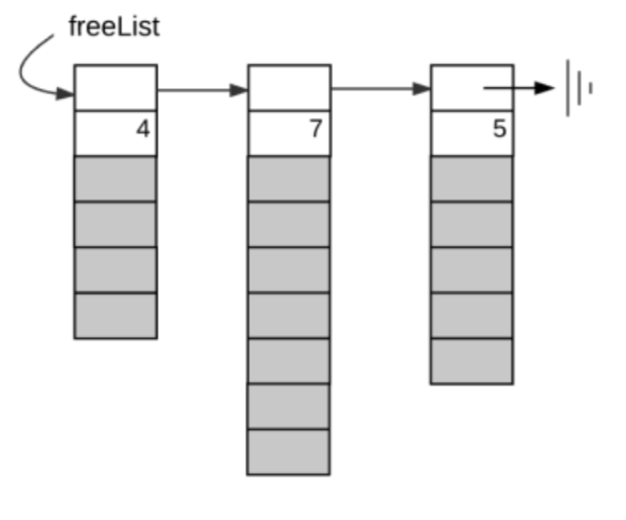
詳しくはテキストを参照して欲しいのですが、簡単にいうとfreeListと呼ぶリストを作成し、セグメントの長さと次のセグメントへのポインタを格納します。そして、あるサイズのメモリブロックの割り当て命令が行われた場合、freeListから適したセグメントを見つけその先頭アドレスを返すといったイメージです。
このコードを作成する際にひとつ注意点として押さえておかなければいけないのは、「フラグメンテーション(断片化)」 に対処する必要があるということです。
どういうことか?というと、上のメモリ割り当てを繰り返し行なっていくと、利用可能メモリ領域が細切れ(フラグメンテーション)になってしまうことが出てます。そんな時にもし次のメモリ割り当て命令が来たら、割り当てれる領域が存在しないという事態になってしまう恐れがあるのです。
こうしたフラグメンテーションに対処するため、OSは 「デフラグ」 と呼ばれる操作を行う必要があります。
これは細切れになったメモリ領域で、つなげれる部分があったら物理的に連続したメモリ領域へ結合することでフラグメンテーションを回避するというもので、今回のJackOSでもこの操作に該当するコードを書く必要があります。(なおこの操作はメモリ破棄時に同時に行います。)
文字出力
次に文字出力について簡単に触れておきましょう。
今回の実装ではスクリーンの実装は 「グラフィック出力(Screenクラス)」と「文字出力(Outputクラス)」 に分けて行いますが、グラフィック出力についてはテキストに詳しいアルゴリズムが載っていますのでそちらを参照してもらえば割と簡単に実装できると思います。
(「グラフィック出力」とは直線や円のような図を描いていくことです。)
問題は文字出力の方です。
これが若干ややこしいので軽く触れておきます。
まず文字出力の際に考えておかなければいけないのが、「物理的なピクセル指向のスクリーンを文字指向のピクセルに変換する」 ということです。
どういうことか?というとHackコンピュータは横512ピクセル、縦256ピクセルの大きさのスクリーンに接続されているのですが、このピクセル単位のスクリーンだと文字を表すのに不都合だということです。もし1ピクセル単位で書いていったら行や列の概念が消えてしまい、テキストを書き込んだら非常にわかりにくくなるでしょう。
そのため、今回は以下のように1文字あたり「横8ピクセル、縦11ピクセルのグリッド」を割り当てて考えることにします。
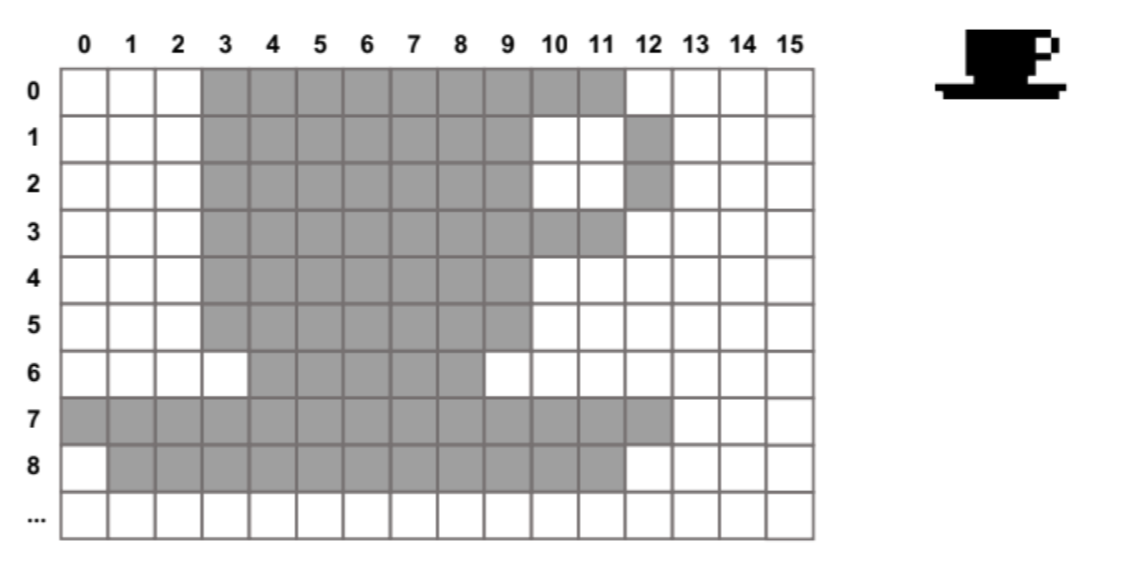
こうすることで、1ピクセル単位で考えるよりもかなり処理しやすくなるはずです。
そして文字を実際に表す際は形の良いフォントをデザインし、文字ごとにそのデータを「座標と色」で記憶しておきます。 (ちなみにこのような形式をビットマップ形式と呼ぶそうです)
例えば、上のコーヒーカップなら黒を1、白を0とすると各行ごとに
0001111111110000
0001111111001000
0001111111001000
0001111111110000
0001111111000000
0001111111000000
0000111110000000
1111111111111000
0111111111110000
と表すことができます。
実際の実装ではこのビットマップデータが様々な文字や記号の分だけ与えられているので、うまく活用していきましょう。
Sysクラス
あとひとつ触れておかなければいけないのが、「Sysクラス」 についてです。
これは主にプログラムの実行に関する操作をパッケージ化したクラスなのですが、挙動がいまいちわかりにくいです。
まずSys.init()という関数について。
ここで以前VM変換器を作成した際に少し触れた 「ブートストラップコード」 というものを思い出して欲しいです。
VM変換器はコード変換を行う前に、まず最初にこのブートストラップコードを生成しました。
このコードは、スタックポインタを初期値に設定し、さらに自動的にこのSys.initを呼び出すようになっています。
ではSys.initは一体何をしているのでしょうか?
まずJack言語をコンパイルしていく過程で得られるVMプログラムの実態は「関数の集合体」であり、連鎖的に関数を呼び出し続けていくことでプログラムが実行されるような仕組みになっています。
実際私たちがテストプログラムとして実行してきたVMプログラムもそーいえば関数を呼び出し続けていたような気がしませんか??(ってかそうです。)
でその連鎖を辿っていくと、終点となる関数(VM関数だとMain.main。Jack言語だとMainクラスのmainファンクション)は一体どこから呼ばれるのか?という問題が当然ながら発生するわけです。
それを解決しているのがSys.init関数(Jack言語だとSysクラスのinitファンクション)なのです。
つまりSys.initは連鎖の起点となるMain.mainを呼び出しているというわけです。
そしてこのように多段階的に関数が実行される流れを、ブーツの「つまみ皮」に見立てて「ブートストラップ方式」と呼んでいて、一番最初のセットアップを行うコードをブートストラップコードというんでしたね。
さらにSys.initのやるべきことはこれだけに留まらず、実は他のOSのクラスの初期化も行なっています。
例えば先ほどのテキスト表示を行うOutputクラスの場合、テキストの表示位置を定めるcursor_xとcursor_y変数やアルファベットや記号を表すために用いられるビットマップデータが内部には存在しています。
これらは当然ですが、プログラム起動時には必ず初期化しておかなければいけません。
カーソルなら初期位置を(0, 0)とし、ビットマップデータならいつでもアクセスできるようcharMapsと呼ばれるArrayクラスの変数と紐づけておく必要があります。
こういった各クラスレベルの初期化はXxx.initファンクションとして行うことが定められており、Sys.initはこれらのファンクションを全て呼び出す必要があるわけです。
つまり、Sys.initの動作をまとめると
「ブートストラップコード→Sys.initが呼び出される→各クラスのinitファンクションを全て呼び出す→Mainクラスのmainファンクションを呼び出す→Sys.halt」
となるわけです。
Sysクラスにはもうひとつややこしい関数として Sys.wait() と呼ばれる関数があります。
これは引数で指定されたミリ時間だけ待機する関数ですが、ループ関数を用いて実装します。しかしループ関数というのはCPUが違えば一回あたりの実行速度が変わってきてしまうので、
各々のCPU速度に応じて必要なループ回数を計測する必要があります。この作業があるため、Sys.initの実装は若干面倒です。
3. おわりに
はい、長かった長かったHackマシンの作成もようやくこれにて終了です。
作業内容が非常に多いためまとめるのも一苦労でした。ただ難しい分、得られるものもかなり多いです。
自分も何度か途中で挫折しかけましたけど(特にコンパイラの実装あたりで)、先人たちが残してくれたブログ記事やコードを参考になんとか乗り切ってこれました。
この記事も過去の自分のように途中で挫折しかかっている人に届くと嬉しいです。
最後までご覧いただき、本当にありがとうございました。
次はOS自作あたりのまとめ記事もあげる(こちらもかなりヘビー...)予定ですので、そちらもぜひ見ていただけると幸いです。
参考文献など
書籍
言わずもがな。
本を読み進める上で参考にさせていただいた記事など
-
「コンピュータシステムの理論と実装の10章のコンパイラ#1:構文解析を実装しました」
こちらの記事は、コンパイラのコードを書く方針がわかない時などに主に参考にさせていただきました。 -
Nand2tetris サポートサイト
こちらのサイトには、各章ごとにスライド付きの解説が載っていて、文字だけだとイメージが掴みにくい分野に関しては結構参考にさせていただきました。
イラストが豊富なので、正直本よりもわかりやすい気がします。
あえて難点を挙げるなら英語で書かれているという点ですが、ある程度英語ができる方なら割と読めると思います。