0-1. はじめに
少し前にCPUの自作を通して 「コンピュータが命令を実行する仕組み」 を学びました。
それによりハードウェア階層の話はある程度理解できたため、次はもう少しレイヤーが上のソフトウェア階層の話(機械語から高水準言語・オペレーティングシステムに至るまでの抽象化の階段)について学んでみたいなと思い、こちらの「コンピュータシステムの理論と実装」に挑戦することにしました。

コンピュータを理解するための最善の方法はゼロからコンピュータを作ることです。コンピュータの構成要素は、ハードウェア、ソフトウェア、コンパイラ、OSに大別できます。本書では、これらコンピュータの構成要素をひとつずつ組み立てます。具体的には、NANDという電子素子からスタートし、論理ゲート、加算器、CPUを設計します。そして、オペレーティングシステム、コンパイラ、バーチャルマシンなどを実装しコンピュータを完成させて、最後にその上でアプリケーション(テトリスなど)を動作させます。実行環境はJava(Mac、Windows、Linuxで動作)。
※引用元 O'Reilly Books内容紹介
上の内容紹介にもある通り、こちらの本はNANDゲートという単純な電子素子から最終的にはアプリケーション(テトリス)を動作させるまでの過程を追っていくものとなっており、プロジェクト名は一般的に Nand2Tetris(NANDからテトリスへ) と呼ばれています。
(最終的な成果物はテトリスではなく実はピンポンゲームであるのは内緒。)
で、最初の方は思いっきりハードウェア層の話がメインで、以前の「CPUを1から作ってみた話」の復習になってしまったのであっさりと終わってしまいました。
とはいっても、さすがにそこで作成したTD4(とりあえず動作する4 bit CPU)よりは複雑な仕様となっており、意外と面白くて学ぶことが多かったので、簡単にメモに残しておくことにしました。
(本題のソフトウェア階層の話はまた別で記事を出す予定です。)
記事の内容が少しでもみなさんの参考になれば幸いです。
ぜひ最後までご覧ください。
0-2. 対象読者
-
低レイヤに興味がある人
-
コンピュータの内部を理解したい人
目次
| 章 | タイトル | 備考 |
|---|---|---|
| 0-1. | はじめに | |
| 0-2 | 対象読者 | |
| 1. | Nand2Tetrisについて | Nand2Tetrisについて簡単に説明しています |
| 2. | ハードウェア部分を終えた感想 | ハードウェア部分を作り終えた感想について話しています |
| 3. | TD4とHackの違い | TD4と呼ばれるCPUと今回作成したCPUとのスペックの違いを説明しています |
| 4. | 各章の内容メモ | 「コンピュータシステムの理論と実装」の各章の内容を簡単にまとめています。 本記事のメイン部分です。 |
| 参考文献など |
1. Nand2Tetrisについて
まず本書で作っていくNand2Tetrisの全体像や本書の構成について、先ほども少し触れましたが簡単に説明しておきます。
本書の大まかな流れは、以下のようなものになっています。
| 作業内容 | 章 | 詳細 | |
|---|---|---|---|
| 1 | コンピュータアーキテクチャの作成 | 1 ~ 5 章 | プール代数→基本論理ゲート→順序回路・組み合わせ回路→メモリ・CPU の流れで最終的にはコンピュータを作成 |
| 2 | コンパイラの作成 | 6 ~ 11 章 | アセンブラ→VM(バーチャルマシン)→コンパイラ の流れで最終的にコンパイラを作成 |
| 3 | 簡易OSの作成 | 12 章 | シンプルなOSを作成 |
この流れで基本的には進めていきます。
まず前半の1~5章ではハードウェア部分を作成していきます。
ここでは本書独自のHackアーキテクチャと呼ばれるアーキテクチャに沿ったハードウェアプラットフォームを作っていきます。
具体的には、HDL(ハードウェア記述言語)を用いてハードウェア回路を作成していき、本書のシミュレータで実際に動くかどうかテストするという流れで行なっていきます。
後半の6~12章では主にソフトウェア部分を作成していくのですが、大まかにはコンパイラとOSの作成に分かれています。
6~11章ではコンパイラを作成していきます。
コンパイラはアセンブラ→VMというように順にステップを踏んで作成していくことになっており、ここでは自分で好きなプログラミング言語を選択して作っていくことになります。
12章ではOSの作成を行なっていきます。
ここは本書で実際に作成するJack言語というJavaに似た特徴を持つ言語を用いて簡単なOSを作成していきます。
ただし、OSといってもプロセス管理やファイル管理などのような高度なことはしません。簡単なライブラリみたいなものを作成していきます。
さて、そんな本書の最大の特徴は 「各章の終わりごとに課題が用意されている」 という点です。
(課題というよりはプロジェクトと呼ぶ方が正しいかも)

これがなかなかに手強く、ちゃんと本書の内容を理解していないと解けない仕組みになっているため、「課題に取り組んでわからないところがあったら読み返す」ということを繰り返していくうちに理解がかなり深まります。
また、この課題を取り組むにあたっては補助教材やエミュレータが用意されているため、それらを活用しながら進めていくことが可能です。
本書で使用するツールやその使い方などはこちらに全て載っています。
Nand2tetris Software Suite
具体的には、実際に作成した回路をシミュレートできる 「ハードウェアシミュレータ」、Hackマシンの動きを実際にシミュレーションできる 「CPUエミュレータ」、Hackアーキテクチャに沿って記述されたアセンブリ言語を機械語へ変換する 「アセンブラ」、バーチャルマシンの動きをシミュレーションした 「VMエミュレータ」 の4つが存在していて、最終的に作りたいものの動きを視覚的に把握できるのでめちゃめちゃ便利でした。
(以下に実際のエミュレータの様子を載せておきます。)
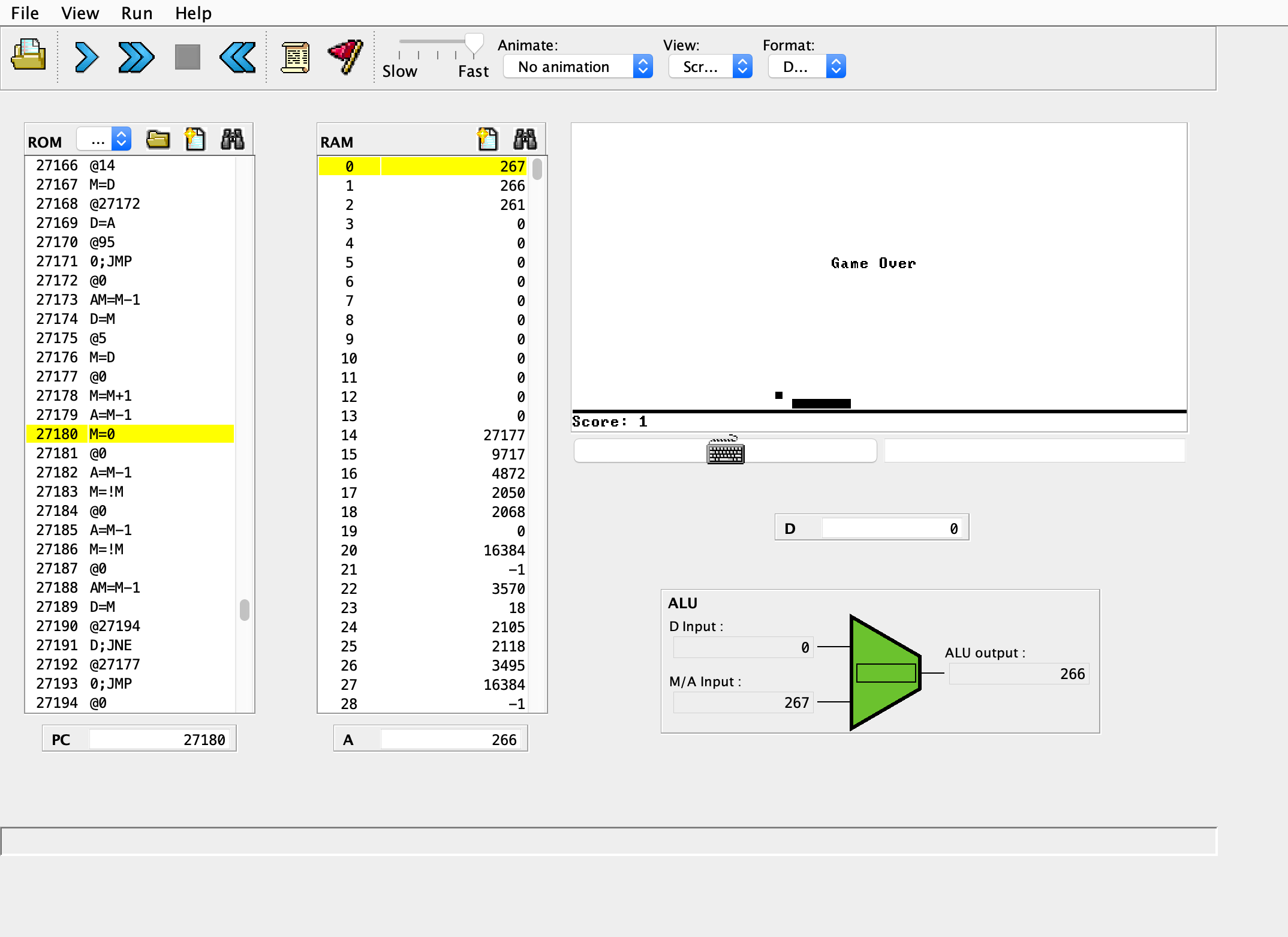
またエミュレータだけでなく、「課題の実装がちゃんとできているのか?」を確認できるテストも大量に用意されており、このテストがパスすることを目標に課題を進めていけば良いので基本的には迷わずに進めることができます。
そんな本書ですが、今回は主にハードウェア階層の話、つまり 「Hackアーキテクチャの作成」 までをメインとして色々と説明していきたいと思います。
2. ハードウェア部分を終えた感想
ということで、本題のハードウェア階層の話に入っていきたいところですが...
いきなりお堅い話になるのもアレなんで、まずは肩慣らし程度にハードウェア部分のHackマシンを完成させた感想を軽く話していきたいと思います。
(さっさと本題を読みたい人はこの章は読まなくていいですw)
一言で表すなら
「とにかく楽しく面白かった。。」
これに尽きます。
要は低レイヤの知識を学びたい人にとってはまさに「うってつけ」だったということです。
ぶっちゃけ以前取り組んだ「CPUの自作」(詳しくはこちらの記事をどうぞ)も相当面白かったのですが、こちらはそれをはるかに凌駕した面白さでした。
先ほども紹介しましたが、本書は電子素子からボトムアップ方式でコンピュータを作成していくという流れになっているため、通常はバラバラに点在しているはずの知識を一貫的に理解できるというのが最大の特徴となっています。
で、その点在している知識が繋がった時の感覚がもう最高に気持ちいんですよね...(変な意味はありません)
「前章でやったことがそうやって生かされるのか!!」
みたいな驚きがめちゃめちゃ多かったです...
(壮大な伏線が回収される感覚、あれに近いですね。)
しかも、本書は「ただ解説を読んでいく」のではなく、 「手を動かしながら実際の挙動を目と手で確認する」 ということに重点が置かれているため、理解がより一層しやすくなっているのが素晴らしいです。
つまり、インプットだけでなく適度な頻度で学んだ知識をアウトプットする場が用意されているため、サクサク読み進めることができるんです!!
また、本書では独自のHDLや言語が登場しますが、これらもなるべく読者が理解しやすいような設計が施されているため、低レイヤ概念の理解以外に余計な気を使わなくて済みますし、膨大なテストケースやシミュレーターまで付属として付いてき、通常のプロジェクトなら1から準備すべき部分がごっそり省かれているため、実装のみに集中することができるようになっています。
...このように、本書の感想を挙げだすとキリがないのですが、要するにそれだけ本書の構成は練られたものになっていて、低レイヤの知識を一気通貫で学びたい人にとってはまさに"最強"の教材といっても過言ではないかと個人的には思います。
3. TD4とHackの違い
さて本書の「Hackアーキテクチャに沿ってコンピュータを作成していく」という作業は、以前取り組んだ「CPUの創りかた」という本とやっていることは基本的には同じなのですが、そちらで作成したTD4よりはアーキテクチャの仕様が少々複雑になってい ます
下に具体的な仕様の比較を載せておきます。
| 名前 | TD4 | Hack |
|---|---|---|
| 命令長 | 8 bit = オペコード 4bit + Im 4bit ※ Im = イミディエイトデータ (命令に組み込まれたデータという意味) |
16 bit |
| 命令の種類 | 12種類 |
A命令とC命令の2種類に分かれている。 ただしC命令では28種類の関数を実行可能・ジャンプ命令は7種類を実行可能...など中身は非常に多彩。 |
| アドレス空間 | 4 bit | 15 bit |
| メモリのワード | 8 bit(つまり16バイトROM) | 16 bit (つまり64Kバイトサイズ) |
| メモリの種類 | ROM | 命令メモリとデータメモリの2種類が存在。 命令メモリはROMでデータメモリはRAM。どちらもサイズは64Kバイト。 |
| 汎用レジスタ | 4 bit × 2(AレジスタとBレジスタ) | 16 bit × 2(AレジスタとDレジスタ) |
| プログラムカウンタ | 4 bit | 15 bit |
| フラグレジスタ | 1 bit | なし |
| I/O | 入出力ともに4 bit ※入力はDIPスイッチ・出力はLED |
入出力ともに16 bit ※入力はキーボード・出力はスクリーン(本書のシミュレータで擬似的に再現してある) |
こちらを見ても分かる通り、かなりスペックに差があります。
そのため、実際に作成していく際にはTD4との違いを把握しながら進めていくと色々と学ぶことが多かったです。
その中でも特に違いを感じたのが次の2つになります。
3-1. メモリ
まずは「メモリ」です。
「メモリ」といってもいくつか違いがあるのですが、第一にメモリの材料が違っていました。
具体的には、TD4ではメモリはDIPスイッチを用いた自作だったのが、HackのメモリではD-FF(Dフリップフロップ)を大量に並べたユニットとなっていました。
【補足】
実際に私がTD4を作成した際はメモリ部分はArduinoで代用したのですが、機能としてはDIPスイッチを並べたものと全く同じですので、ここではDIPスイッチと記述させていただきました。
これによりメモリ以外の部分でも色々な違いが出てき、例えばTD4ではデータメモリに値を書き込むことは基本的にはプログラムの動作中には不可能でしたが、Hackではそのような制限はなく自由に値を書き込めるようになりました。
またこれに付随して、Hackではメモリを命令メモリとデータメモリの2種類に分けるような設計になりました。
このおかげで、データメモリに値を書き込んだり、逆に値をデータメモリから読み出すような命令が実行可能になりました。
あとはアドレス空間やメモリのワード(単位)がHackの方が規模が大きくなっており、プログラムで実行可能なことがかなり多くなりました。
3-2. ALUの機能
次にALUの機能がかなり違っていましたね。
ここでALUとは算術論理演算器(Arithmetic Logical Unit)の略で、CPUの中心的役割を担うものです。
そのALUが、TD4では基本的に加算しか行わない超シンプルな仕組みになっていたのですが、Hackでは算術演算(足し算・引き算)と論理演算を含む合計18種類の関数が実行可能でした。
このため、HackではALUへの制御信号が必要になってき、TD4がいかに単純な仕組みで動いていたのかを痛感させられました。
【補足】
とはいってもHackアーキテクチャはこの辺りがうまくいくよう設計されており、機械語のある特定部分をそのままALUへの制御信号とすればうまく計算できるようになっています。
以下の表はALUへの6つの制御信号とそれによって実行される関数式をまとめたものです。
| zx | nx | zy | ny | f | no | f(x, y) = |
|---|---|---|---|---|---|---|
| if zx then x = 0 | if nx then x = ! x | if zy then y = 0 | if ny then y = ! y | if f then out = x + y else out = x & y |
if no then out = ! out | out |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 0 | 1 | 0 | -1 |
| 0 | 0 | 1 | 1 | 0 | 0 | x |
| 1 | 1 | 0 | 0 | 0 | 0 | y |
| 0 | 0 | 1 | 1 | 0 | 1 | ! x |
| 1 | 1 | 0 | 0 | 0 | 1 | ! y |
| 0 | 0 | 1 | 1 | 1 | 1 | -x |
| 1 | 1 | 0 | 0 | 1 | 1 | -y |
| 0 | 1 | 1 | 1 | 1 | 1 | x + 1 |
| 1 | 1 | 0 | 1 | 1 | 1 | y + 1 |
| 0 | 0 | 1 | 1 | 1 | 0 | x - 1 |
| 1 | 1 | 0 | 0 | 1 | 0 | y - 1 |
| 0 | 0 | 0 | 0 | 1 | 0 | x + y |
| 0 | 1 | 0 | 0 | 1 | 1 | x - y |
| 0 | 0 | 0 | 1 | 1 | 1 | y - x |
| 0 | 0 | 0 | 0 | 0 | 0 | x & y |
| 0 | 1 | 0 | 1 | 0 | 1 | x | y |
これだけでもなんとなく面倒くさそうなのがわかるかと思います。
またこのように複数の関数が実行できると自然と使用できる命令セットは増えることになるため、それを制御するためのデコーダ部分の仕組みはかなり複雑になりました。
正直このデコーダ部分の設計がハードウェア階層の部分の1番難しかったです。(ただその分、うまくいったときの快感は半端ないです(笑))
4. 各章の内容メモ
では、次に1~5章の内容やその章の課題で実際どのようなものを作ったのか?について簡単にメモしていきます。
これからNand2Tetrisに取り組まれる方などはぜひ参考にしてください。
本書の内容は基本的には書籍でも十分網羅できているのですが、その背景知識などをさらに詳しく知りたい方へ向けて著者らが専用のウェブサイトを用意してくれており、そこにスライドなどがアップされています。
なので、もし本書の説明でわからなかったことがあればそちらを参照するのをおすすめします。
(ただし、資料は全て英語で書かれているのでその点には注意してください。)サポートサイト:Nand2Tetris/Projects
0章:イントロダクション
まずはイントロ部分。
このイントロ部分、ただのイントロ部分と思って侮るなかれ。
ここでは 「エンジニアリングにおいて抽象化とはなんぞや?」 って話をメインに、本書を進めていく上で知っておくべき重要なことが実は記述されています。
簡単にテーマである「抽象化」について説明しておくと
-
抽象化=機能部分(この要素が何をするのか?=What)のみを考え、その詳細である実装部分(この要素がどのようにその機能を実行するのか?=How)は無視するということ
-
抽象化により複雑さを内包するものを独立な構成要素(=モジュール)へと分割することが可能で、このモジュール単位で処理していくことで複雑性に対抗できる
-
抽象化により作成された独立モジュールは他のモジュールに対し相互に関係性を持っており、それらの関係性を持つモジュール同士を組み立てていくことで最終的なシステムは形成される
-
そうして繰り返される抽象化は基本的にレイヤ構造をとることが多く、一般的には下の階層を構成要素としてモジュールは生成される(レイヤが重なっていくほどに、システムの能力も増す。)

わかったようなわからないような感じですね。
超ざっくりまとめると、「困難は分割せよ」という原則にしたがって徹底的にシンプルなものへと切り分けて作業を進めていくというイメージを持っていただけるとわかりやすいかと思います。
Nand2Tetrisのプロジェクトに置き換えると 「モダンなコンピュータ作成」という抽象化されたプロジェクトを、独立した各モジュールへと分割し、ボトムアップ方式にそれらを実装し、積み上げていくという作業を行なっていくということになります。
1章:プール論理
この章は、基本的な論理ゲート(論理回路)をNandゲートから実際に作っていくことがメインとなっています。
具体的にはNot、And、Or、Xorなどの基本論理ゲートからマルチプレクサ(セレクタ)や多ビット.多入力の基本論理ゲートを本書独自のHDL(ハードウェア記述言語)を用いながら作成していきます。
まぁ本書の内容をちゃんと読んでいけば自然と理解できるようになっているので、ここに関してはそこまで難しくないです。
HDLや実際に作成した回路をテストするために用いるシミュレータの使い方に関しても巻末の付録に詳しい説明があり、そちらを読んで適当にサンプル回路を記述すれば大体コツは掴めると思います。
(以下イメージしやすいように簡単な操作例を載せておきます。)
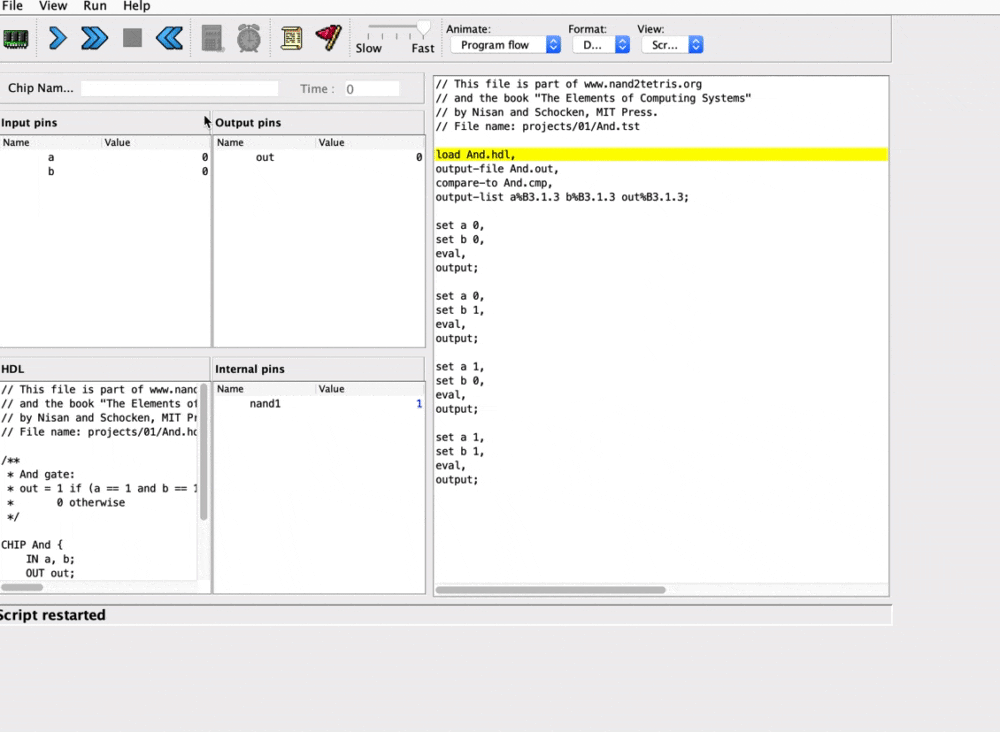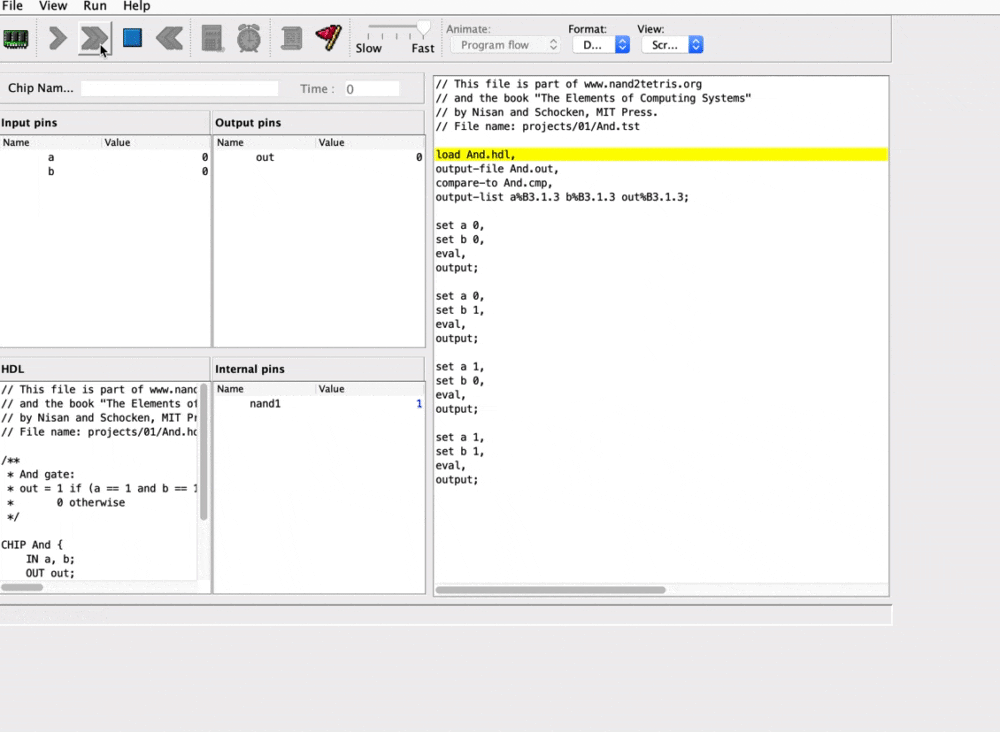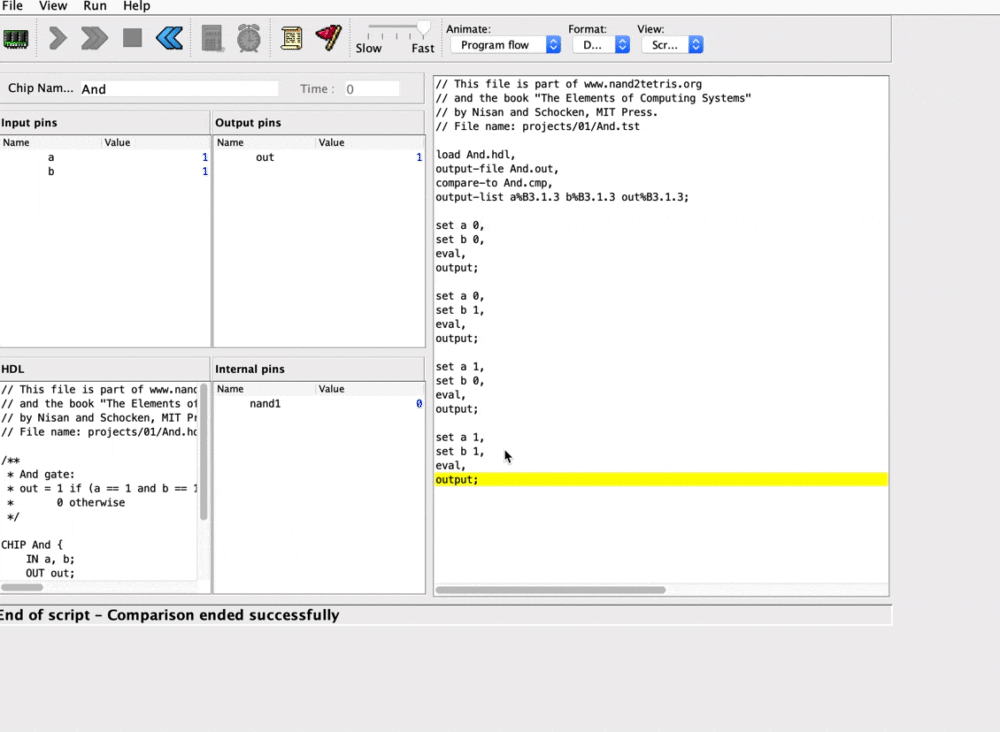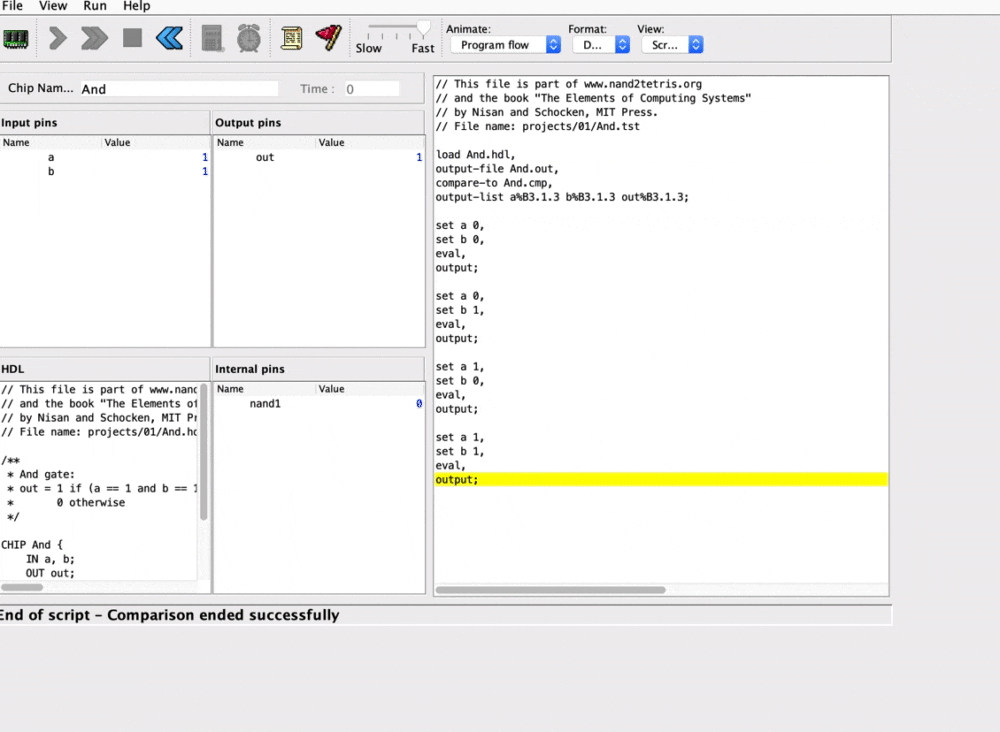
そんな本章の内容で個人的に一番印象に残ったことは、抽象化の最初のステップが論理ゲートであるということに言及していた点です。
抽象化を積み上げていくことでコンピュータは作り上げられるという話は先ほどもしましたが、その抽象化の出発点が(厳密には違いますが...)論理ゲートであるというのはあまり意識したことがなかったので少し新鮮でした。
もう少し具体的に話すと、スイッチング素子としてコンピュータサイエンスの世界では一般的にはトランジスタが使用されますが、実はこのスイッチング技術にどんなものが使われているのか?という点に関してはコンピュータの世界に生きる人にとってはそんなに重要な話ではないんですよね。
2値データの表現と伝達を可能にする技術が電気以外にあればそれでいいのです。
もちろん最適化を考える上ではトランジスタの製造コストや処理速度などを具体的に考慮する必要がありますが、基本的にそれらは物理の領域に生きる人たちが考える話で、 コンピュータ側の人間はプール代数と論理ゲートの抽象化された世界に集中して、ソフトウェアの設計や抽象化について考えるのが一般的なのです。

すなわち、コンピュータサイエンスと物理学の分かれ目となるのが論理ゲートの部分で、本書ではそれをNandゲートと定めているわけです。
そういった意味で壮大なコンピュータサイエンスの冒険の始まりがこの章であると実感し、少しワクワクしました。
2章:プール算術
この章では、1章で作成した論理ゲートを用いて、半加算器・全加算器・加算器・インクリメンタ・ALU(算術論理演算器)を作るという流れになっています。
コンピュータで行われる算術演算と論理演算は全てこのALU回路によって行われているので、この章はめちゃめちゃ重要です。また当然ですが、このALUのスペック次第でコンピュータが提供できる命令の種類も変化してきます。
ちなみに、TD4では4 bit 全加算器をそのままALUとして使用しましたので加算命令しか行えない超低スペックなCPUとなっていました(笑)
この辺も比較対象として比べてみると、面白かったです。
ただTD4はその分動作が非常に単純化されているため、コンピュータが本質的に何をやっているのか?が理解しやすかったです。
で、この章も前回と同様にHDLを用いて回路を作成していくわけですが、最後のALUの実装が案の定難しかったです。
作成するALUは先ほど述べた通り、6つの制御信号を用いて18種類の関数を出力する仕様となっています。
-
入力
- x[16], y[16]・・・ふたつの16ビットデータ入力
- zx・・・入力xをゼロにする
- nx・・・入力xを反転する
- zy・・・入力yをゼロにする
- ny・・・入力yを反転する
- f・・・関数コード:1は「加算」、0は「And演算」に対応する
- no・・・出力outを反転する
-
出力
- out[16]・・・16ビットの出力
- zr・・・out = 0 の場合にのみTrue
- ng・・・out < 0 の場合にのみTrue
-
関数
- if zx then x = 0・・・16ビットの定数ゼロ
- if nx then x = !x・・・ビット単位の反転
- if zy then y = 0・・・16ビットの定数ゼロ
- if ny then y = !y・・・ビット単位の反転
- if f then out = x + y・・・2の補数による加算
- else out = x & y・・・ビット単位のAnd演算
- if no then out = !out・・・ビット単位の反転
- if out = 0 then zr = 1 else zr = 0・・・16ビットの等号比較
- if out < 0 then ng = 1 else ng = 0・・・16ビットの負判定

これだけ複雑だといきなり全てまとめて考えるのは難しいので、場合分けをして考えていくことをおすすめします。
具体的には
- zx(zy)とnx(ny)を入力として受け取った際に入力値がどのように変化するのか?
- fとnoからoutがどのように出力されるのか?
- outからzrとngがどのように出力されるのか?
これら3つに分けて考えるとわかりやすいかと思います。回路図は以下のような感じです。(zrとngは省略。回路内を伝わるデータは全て16ビット。)

コードはこちらにありますので、よければ参考にしてください。
nand2tetris/projects/02/ALU.hdl
ただし、これが絶対的に正解というわけではなく、テストさえ通れば基本的にどんな設計でも良いかと思います。(最適化は本書では一切考えないので...)
3章:順序回路
この章では順序回路について考えていきます。
そもそも論理回路というのは、入力値の組み合わせ次第で出力が決定される 「組み合わせ論理回路」 と、入力値の組み合わせだけでなく過去の履歴(記憶)にも依存して出力が決定される 「順序回路」 の2種類に分けることができます。
1.2章で考えてきた回路は組み合わせ回路で、その瞬間の入力値のみに依存して出力が変わります。
そのため、「値の保存」といったことに関しては全く考える必要がなかったわけです。
しかし、当然コンピュータというのは値を計算するだけではなく、その値を保存し呼び出すことができなければいけません。
そのため、時間が経過してもデータを記憶することが可能な記憶素子を備える必要があり、その記憶素子を順序回路を用いて構築していくのが本章の大まかな流れになります。
具体的にはD-フリップフロップ(以下ではD-FFと略します。)と呼ばれる回路をビルディングブロックとして用いてレジスタやメモリ、そしてカウンタを前章と同じように作成していきます。
【補足】
さてここで論理回路における「時間」という概念について考えてみましょう。先ほど各瞬間の入力値の組み合わせによって出力値が変化するのが組み合わせ回路、過去の値に依存する可能性があるため時間経過を考慮する必要がある回路が順序回路だと述べました。
では、順序回路は具体的にどのように時間経過を表現しているのでしょうか?
一般的に順序回路において時間経過は、絶え間なく2つのフェーズを行き来する信号を送信するクロックによって表されます。仮にこの2つのフェーズをlow/highだとすると、lowの始まりからhighの終わりまでに経過した時間を「クロックの1周期」として、現在の時間が何周期目か?といった具合に表します。こうすることで、例えば1ビットレジスタなら以下のような回路で表すことができます。
組み合わせ回路のように考えるとこの回路は明らかにおかしいです。なぜなら出力値は入力値のみに依存するはずが、出力値にも依存してしまうという意味のわからない状況が生まれてしまうからです。
しかし、この回路に時間という概念を追加するとどのようになるでしょう?すると、この回路は以下のような関数式を表していることがわかります。
- if load( t - 1 ) then out( t ) = in( t - 1 )
else out( t ) = out( t - 1 )つまり、この回路は1周期前の入力値または出力値を出力するのです。
このように順序回路では「時間」という概念を導入することにより、「値の保存」といった非常に高度な機能を付与することができるのです。そしてその中心を担っているのがDフリップフロップなのです。
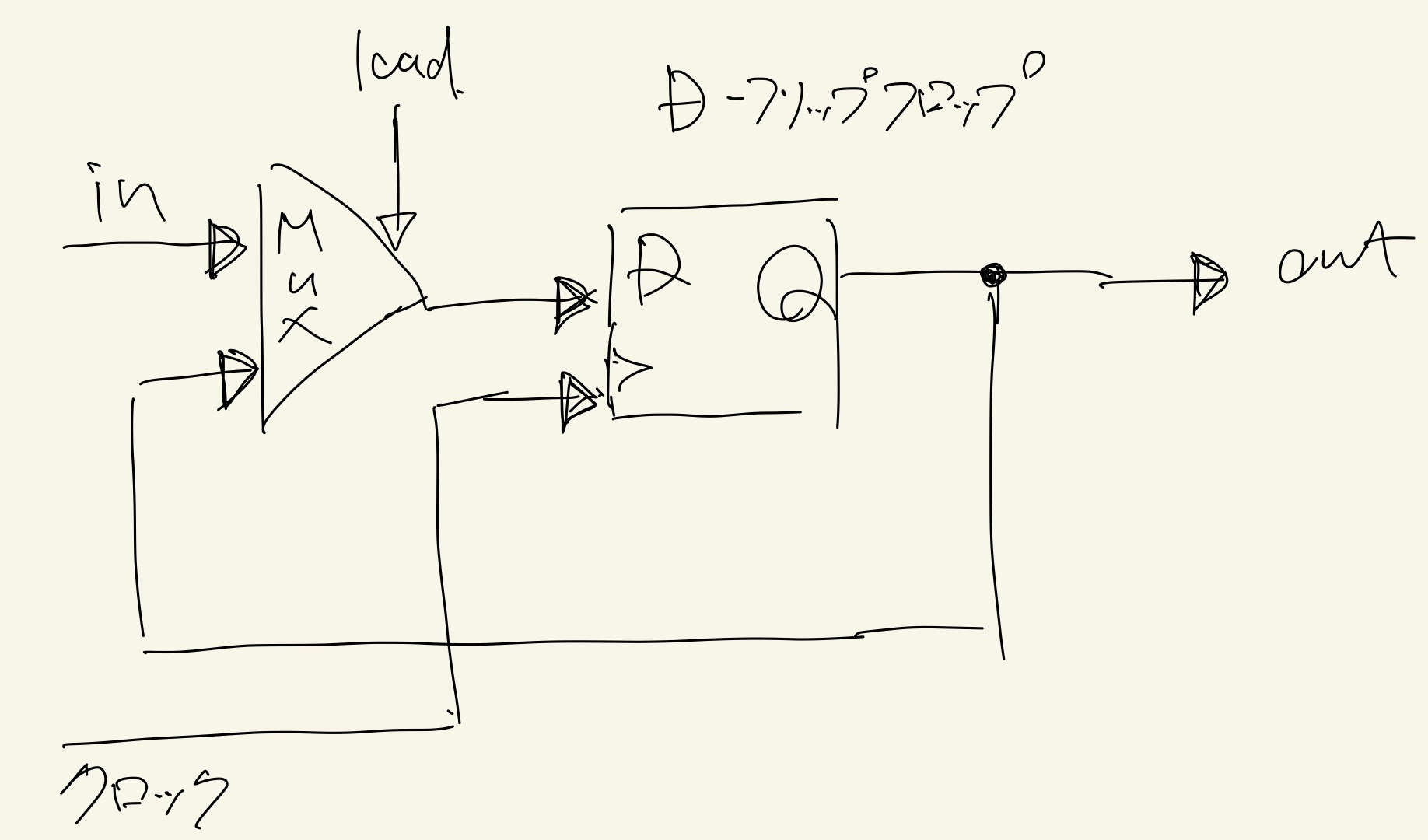
D-FF(Dフリップフロップ)
このビルディングブロックとして扱うD-FFはは簡単にいうと1ビットのデータを保存する役割を持つ順序回路で、具体的には以下のような回路になっています。

この回路は、クロック信号(回路図でいうところのC)が0から1に変わる瞬間にのみ値を保存するもので、Dラッチと呼ばれる回路を2つつなげることで完成します。
(ちなみに2つつなげたものは「マスター・スレーブ」とそれぞれ呼びます。)
...
「え?ということはビルディングブロックとして扱う必要なくね?」
と思ったあなた、なかなか鋭いです。
そう、D-FFは上の図のように組み合わせ回路を用いて構築していくことが可能なのです。
しかし、本書ではあえてそのようにD-FFを1から作成するということはしません。
というのも、この回路を作成するには組み合わせ回路におけるフィードバックがもたらす問題やクロック周期を実装する方法などについて理解する必要があり、少々ハードルが高くなってしまう恐れがあるからです。
そのため、本書ではこの複雑さを抽象化してD-FFを"原子"回路として扱うことでこのような様々な問題を見て見ぬフリをするわけです。
よってこれからD-FFと言われたら基本的にはこちらのような記号を用いて使用していくことになります。

カウンタ
この章も先ほどと同様に基本的にテキストを読んでいけばだいたいの課題を実装できるようになっているのですが、少々厄介なのがカウンタ。
このカウンタは他の記憶装置とは少々毛色の違うもので、次に実行すべき命令コードのアドレスを指定するために用いられます。
基本的には各クロック周期で1ずつ加算していくのですが、例えばジャンプ命令などを実行する場合にはカウンタに直接、値を設定できるようになっています。
さらにプログラムの実行をいつでも再実行できるように、カウンタの値を0にする機能も備えています。
まとめると以下のようなインターフェースを持つ回路となっています。
-
入力
- in[16]
- inc
- load
- reset
-
出力
- out[16]
-
関数
- if reset ( t - 1 ) then out ( t ) = 0
else if load ( t - 1 ) then out ( t ) = in ( t - 1 )
else if inc ( t - 1 ) then out ( t ) = out ( t - 1 ) + 1
else out ( t ) = out ( t - 1 )
- if reset ( t - 1 ) then out ( t ) = 0

回路としては基本的には前回結果に依存するのでレジスタ使うのですが、ポイントは入力部のフィードバック部分を少し工夫する必要があるということです。
具体的には、
- out ( t - 1 )
- out ( t - 1 ) + 1
- 0
- in
の4つの中から入力を自由に選べるようにします。
この選択にはやり方が色々とあるのですが、今回はマルチプレクサを3つ利用することにしました。
回路図は以下のようになります。

コードはこちらにありますので、よければ参考にしてください。
nand2tetris/projects/03/a/PC.hdl
4章:機械語
この章では、次章で作成するHackプラットフォームの命令セットを具体的に見ていきます。
これにはHackマシンを通常コンピュータを用いる時と同じような抽象的目線で見ていくことにより「Hackがどういった操作が可能なのか?」といったことを知るという目的があります。
つまり、この章を通してHackマシンへの理解を深め、次章で見ていくHackアーキテクチャの設計思想を理解していくことになります。
そのため、今までのような構造的視点でコンピュータを見ていく必要はなく、また同時にHDLを用いた回路設計も本章では必要ありません。
ハードウェア部分は私たちがよく見るようなプロセッサ、メモリ、レジスタの3つにシンプルに抽象化して考えればいいのです。

その代わりに、機械語への理解を深めるために指定されたサンプルプログラムをHackアセンブリ言語で記述していくということを行います。
この実装課題については特に難しい部分はないので説明する必要はおそらくないでしょう。(唯一苦労するとすればFill.asmでしょうか。)
さてそんな本章で個人的に最も印象に残ったのは 「機械語がコンピュータ全体における最も重要なインターフェースである」 という一節です。
これは1章の「抽象化のスタート地点=論理ゲート」とも重なるところが若干ありますが、ざっくり言うと 「機械語の存在がソフトウェア階層とハードウェア階層を繋ぐ」 ということです。
一般的にコンピュータのハードウェアというのは機械語を読んで実行できるように設計されるわけですが(命令デコーダなどがその最たる例)、同時にこの機械語によってエンジニアの抽象的思考(これは高水準言語のような記号命令で表される)は物理的操作に変換されるわけです。(どんな高水準言語も結局は機械語に翻訳され実行される。そもそも高水準言語はできるだけ機械語を便利にしたもの。)
要は、機械語はエンジニアの思考を表現するためのツールとして使われると同時に、ハードウェアの設計においても重要な役割を担っているということになるため、コンピュータ全体で見た場合に最も重要なインターフェースになるわけです。

機械語の存在というのは普段あまり意識しないので、この部分は個人的には結構目から鱗でした...
5章:コンピュータアーキテクチャ
ハードウェア階層ラストは1~3章で作成したパーツを用いたHackマシンの作成です。
まぁハードウェア部分の集大成的な立ち位置にあたるので結構難しいです。
以下この章で個人的に重要だと思った部分について簡単にまとめていきます。
プログラム内蔵方式
基本的に私たちが普段用いているコンピュータが様々なアプリケーションを柔軟に実行できるのは、そのアプリケーションプログラムのコードをまるでデータであるかのようにメモリ上で操作しているからです。
つまり、プログラムのコードはコンピュータのメモリに格納され、操作することができるのです。
これは今では結構当たり前のこととして知られていますが、当時としては画期的なアイデアで、今でもコンピュータサイエンスの分野で最も偉大な発明とされています。
このようにプログラムがメモリに内蔵されて、実行されていく方式をプログラム内蔵方式と言います。
これにより 「柔軟に」(ソフトウェアの語源) いろんな操作を実行することが可能になります。
ノイマン型アーキテクチャ
プログラム内蔵方式にしたがって今まで様々なコンピュータモデルが考案されてきました。
その中でも特に重要なモデルとしてノイマン型コンピュータと呼ばれるものがあります。
このノイマン型コンピュータは現在最も一般的に用いられているアーキテクチャで、中央演算装置(Central Processing Unit, CPU)を中心に、メモリデバイスを操作して、入力デバイスからデータを受け取り、出力デバイスへデータを送信するという動作を行います。

本章で作成するHackマシンもこのアーキテクチャに沿って開発していきます。
(細かい部分は機械語の仕様にしたがって設計されていきます。)
各ユニットに関しての詳しい説明はテキストにわかりやすくまとまっていますのでそちらを参照してください。
Hackハードウェアの仕様と実装例
Hackは16ビットのノイマン型コンピュータで、CPUがひとつ、メモリモジュールが2つ(データメモリと命令メモリ) 、メモリマップドI/Oが2つ(スクリーンとキーボード)から構成されます。

簡単にHackのプログラム実行過程をまとめておくと、まずHackは命令メモリに存在するプログラムを実行します。
命令メモリは読み込み専用であり、実行したいプログラムを予めロードする必要があります。これは本書の付属としてついてくるハードウェアシミュレータでできるようになっています。
次にHackのCPUですが、これは図にもある通りALUと3つのレジスタから構成されています。
3つのレジスタは
- データレジスタ(D)
- アドレスレジスタ(A)
- プログラムカウンタ(PC)
と呼ばれています。
DレジスタとAレジスタは16ビットの汎用的なレジスタであり、例えば A = D - 1 や D = D | A のような算術計算や論理演算において使用されます。
(実行できる計算の種類については機械語の仕様に従います。)
このうちDレジスタはデータ保持のためだけに用いられますが、Aレジスタの内容は実行命令に応じて次の3つの異なる意味として解釈されます。
- データ値
- RAMアドレス
- ROMアドレス(ジャンプ命令のとき...)
次にPC(プログラムカウンタ)は命令メモリのアドレス入力に接続されるように配線されており、これにより命令メモリ中でPCが指す場所のデータ値が出力されます。
(この値は現在命令と呼ばれる。)
Hack機械語に関してはA命令とC命令という2種類の16ビット命令をベースにしています。
A命令は 「0vvvvvvvvvvvvvvv」 というフォーマットに従い(vは0または1を示す)、C命令は 「111accccccdddjjj」 というフォーマットに従います。
A命令を実行すると、コンピュータは15ビットのvvv...vという値をAレジスタに設定します。
C命令を実行すると、aビットとcビットによりALUで行うべき関数を決定し、dビットによりALUの出力を格納する場所を指定します。
またjビットにより移動条件を指定できます。
つまり、まとめると各クロックサイクル中におけるHack全体の操作は次の2つの操作からなることになります。
-
実行- 現在命令を構成するビットはデコードされ、制御信号としてコンピュータの様々な回路へ送られる。
- A命令であれば、命令に埋め込まれた15ビットの定数値がAレジスタに設定される
- C命令であれば、a、c、d、jビットは制御ビットとして扱われ、ALUとレジスタに命令を実行させる
-
フェッチ- 次にどの命令をフェッチするかということは「現在命令のジャンプビット(jビット)」と「ALUの出力」によって決まる
- この2つの要素からジャンプを実行すべきかどうかが決定される
- もしジャンプを行う場合はPCにAレジスタの値を設定する
- それ以外はPCの値は1だけインクリメントされる
- 次のクロック周期において、プログラムカウンタの指す命令が命令メモリの出力から送信される
- このサイクルが連続して続いていく
最後にメモリアクセスについてですが、前回の機械語の章で機械語を触った人ならわかるかと思いますが、Hackではメモリアクセスを伴う操作は2つの命令を必要とします。
ひとつはA命令で、もうひとつはそれに続くC命令です。
まずA命令でAレジスタにアドレスを設定し、C命令でこのアドレスに対して何らかの操作を行います。(読み書き命令、または命令メモリへの移動命令など)
例えば、
@ 10
M = M + 1
という命令なら、メモリアドレスが10のデータをインクリメントし、再び保存します。
さてここまででHackマシンの命令実行過程を見てきたので、次はHackマシンの構成要素の仕様とその実装例について見ていきましょう。
①CPU
まず最初はCPU。
CPUの仕様は以下のようになっています。
-
入力
- inM[16]・・・M入力値(これはデータメモリの値)
- instruction[16]・・・現在命令
- reset・・・reset信号。具体的にはreset=1なら再実行し、reset=0ならそのまま続行。
-
出力
- outM[16]・・・M出力値
- writeM・・・データメモリへ書き込みを行うかどうか
- addressM[16]・・・データメモリ中のMのアドレス
- pc[15]・・・次の命令のアドレス
-
関数
- inMは前回クロックサイクル時のAレジスタの値をアドレスとするデータメモリアドレスの値
- Mに値を書き込む必要がある場合は writeM = 1 となり、outMの値をaddressMに書き込む
- writeM = 0 の場合は、outMの値はいかなる値を取る可能性がある
- reset = 1 の場合は、CPUは命令メモリのアドレスが0の場所に移動する
- reset = 0 の場合は、現在命令の実行結果にしたがって移動先のアドレスが決まる
イメージとしては以下のような感じです。

次に 具体的な実装案についてですが、正直CPUの実装がハードウェア階層部分では1番難しいです。
ゲートの個数もかなり多くなりますし、何よりデコーダ部分の設計にはかなり骨が折れます。
以下に私が作成したゲート構成図とコードを載せておきます。
(なお太線はデータパスとアドレスパスを指し、太枠で囲ったパーツが実行部になります。)

nand2tetris/projects/05/CPU.hdl
これだけ見てもかなりややこしいことがわかるでしょう。
一応テキストに実装案が書かれていますので、そちらをベースに考えていけばできなくはないのですが、1番難しいデコーダ部分の設計に関してはほとんど示されていないため、CPUの設計を初めてする方の場合はかなり戸惑うと思います。
なのでデコーダ部分の設計の大雑把な考え方について以下に簡単に示しておくことにします。
まずデコーダとは簡単にいうと、
「機械語命令」を「実行部への指示」へと変換する回路
のことを指します。
これだけだとわかりにくいので、少し具体例を出して考えていきましょう。
例えば、いま「1111110111001000」という命令を実行するとしましょう。
先ほども説明しましたが、この命令自体はプログラムカウンタの指す値を命令メモリに出力し、それによって命令メモリが指示されたアドレスに格納された命令を返すことによって得られます。
ここまでがいわゆる 「命令フェッチ」 と呼ばれる動作にあたります。
今回だとこれにより1111110111001000という 16ビット命令が得られます。
そしてこの機械語命令により実行部(図で太枠で囲った部分)が動作するわけですが、一般的にHack機械語は
i xx a cccccc ddd jjj
という領域へ分けて考えることができ、
- iビットが命令の種類を表す。0ならA命令、1ならC命令
- C命令の場合、aとcビットはcomp領域として解釈され、ALUで行う関数を決定(aビットによりALUにAレジスタの値を代入するか、データメモリ入力の値を代入するか決定される)
- dビットはdest領域として解釈され、ALUの出力先を決定
- jビットはjump領域として解釈され、移動条件を指定
- A命令の場合は、iビットを除いた15ビットは定数値として解釈
というような意味が与えられています。
今回の命令だと
1 11 1 110111 001 000
という領域へ分けることができ、
- i = 1
- a = 1
- comp = 110111
- dest = 001
- jump = 000
となることがわかります。
これにより、まずはC命令の M = M + 1 を実行することがわかりますね。
ではこの命令を実行するため、実行部がどのような動作をするのか?ということを考えていきましょう。
上のゲート構成図だと少し見にくいと思いますので、ここから各実行部だけを抜き出した以下の図を参考にして進めていくことにします。
(入力のcという記号は制御ビットを意味しています。これらのビットは現在命令から抜き出され、様々な回路へ送られ、その回路の振る舞いを制御します。)

実行部が行う動作としては
- ①のマルチプレクサのselect信号によりA命令かC命令のどちらを実行するのか決める。
- ②のマルチプレクサのselect信号によりALUが「Aレジスタ」か「メモリ入力」のどちらを操作するかが決定される
- Aレジスタのload信号により値を書き込むかどうか決める
- Dレジスタのload信号により値を書き込むかどうか決める
- writeMによりメモリアドレスaddressMに値を書き込むかどうか決める
- ALUの制御信号6つによりどの関数を実行するのか決める
- PCのload信号、inc信号、reset信号により次の命令アドレスを決める
というようなパターンがあり、これらをコントロールする必要があります。
つまり、指示しなくてはいけないのは以下の14 bitであることがわかります。
- select①
- select②
- loadA
- loadD
- writeM
- ALUの制御信号6 bit
- PCのload、inc、reset信号
今回だとC命令かつALUはメモリ入力(M)を操作するので、select①には1、select②には1が入りそうです
さらにloadAとloadDはどちらも0、writeMは1になりそうですね。
またALUにはcomp領域のビットがそのまま入ります。
ラストはPCですが、ここはジャンプ命令も起こらないので普段通りインクリメントするとわかり、
- load = reset = 0
- inc = 1
になることがわかります。
注意点としては今回はj領域が0だったためジャンプ命令が起こらないことが簡単にわかりましたが、j領域が0でない場合はALUのステータスビット(zrとng)を見て命令を実行するのかどうかを決める必要があるということです。
例えば、jjj = 100 だった場合、機械語としてはJLT命令を指すわけですが、このJLT命令を実行できるのは ng = 1(ALUの出力値が負)の場合に限ります。
つまり、PCのload信号とinc信号は
- 現在命令のjビット:このビットにより移動条件が指定
- ALUのステータスビット:条件を満たしたかどうかを示す
の2種類の制御ビットが関与することになるわけです。
このように「機械語 + ALUのステータスビット」から「13 bitの制御信号」を作り出す作業を自動的に行わせるようにしたもの、それが「デコーダ」となるわけです。

【補足】
デコーダは命令を具体的な作業へと噛み砕いて実行部へ指示を送るだけで、実作業はほぼしていないので「中間管理職」といったイメージを持つとわかりやすいかと思います。
実行部への根回しを素早く的確に行う、ザ裏方みたいな感じですかね。
で、このデコーダの設計に関してですが、基本的には上の例で示した通りに各命令ごとに必要な指示を書き出し、そのために必要となるであろう回路を考えていくという作業を繰り返していくだけになります。
これはパズルを解いていくような感覚に近く、コツをつかめば割とスムーズに進むかと思います。
個人的にはPCへの制御信号が結構難しかったですが、シミュレータなどをうまく活用すれば何なく突破できるはずです。
②メモリ
次にメモリです。
命令メモリに関しては、あらかじめ用意されているので考えなくて大丈夫です。
問題なのはデータメモリです。
基本的には3章で作成したものと同じインターフェースを持ちますが、メモリマップドI/Oによりスクリーンとキーボード専用のメモリマップが確保されているため少々ややこしいです。
メモリ全体の仕様に関しては以下のようになっています。
-
入力
- in[16]・・・何を書き込むか?
- load・・・書き込み有効ビット
- address[15]・・・どこに書き込むか
-
出力
- out[16]・・・与えられたアドレスにおけるメモリの値
-
関数
- out ( t ) = Memory [ address ( t ) ] ( t )
- if load ( t - 1 ) = 1 then Memory [ address ( t - 1 ) ] ( t ) = in ( t - 1)
-
メモリマップ
| サイズ | アドレス範囲 | |
|---|---|---|
| RAM | 16K | 0〜16383(0x0000〜0x3FFF) |
| Screen | 8K | 16384〜24575(0x4000〜0x5FFF) |
| Keyboard + 無効 | 8K | Keyboard = 24576(0x6000) 無効 = 24577〜(0x6001〜) |

実際の構成図としては以下のようになりました。
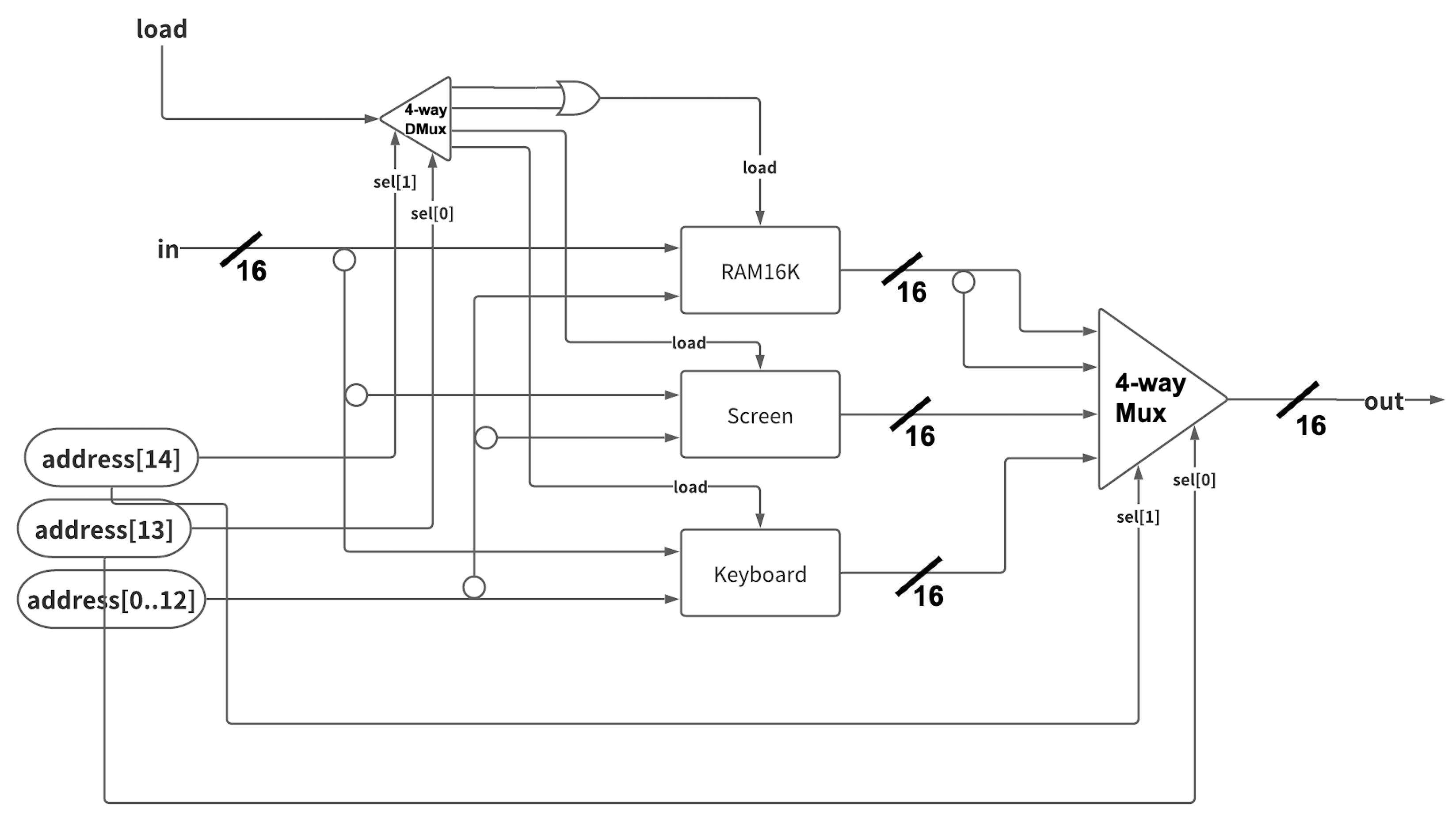
ミソとしては、4-wayDMuxの出力信号の2つにORゲートを用いることでRAM16Kのload信号としているところです。
こうすることで、0b00xx...xだけでなく0b01xx...xというアドレスにもRAM16Kが対応するようになります。
他は3章で作成したRAMnと同じ要領でできます。
一応下にコードを載せておきますので、よければ参考にしてください。
nand2tetris/projects/05/Memory.hdl
③コンピュータ
コンピュータに関しては、①と②を組み合わせればほぼできます。
こちらもテキストに実装案が載っていますので、そちらの通りにすれば特に問題はないでしょう。
-1. つづく
ということで、ここまでがハードウェア階層に関する話でした。
1番の山場はやはり5章のCPUですね。
ここを実装することができれば、Hackマシンはほぼできたも同然です。
次はソフトウェア階層がメインの「CPUからOSまで自作してみた話(アセンブラ/スタックマシン編)」に続く予定ですので、興味ある方はぜひご覧ください。
参考文献など
書籍
ハードウェア階層部分についてはこちらの本とかなり相性が良いので、ぜひ参考にすることをおすすめします。
レベル感としてはこちらの方が初心者向けに書かれているため易しいです。
言わずもがな神本。
本を読み進める上で参考にさせていただいた記事など
ざっくりと本書の内容がまとまっていて、実際にやって見て苦労した点なども書かれているのでかなり参考になりました。
(コードの方も参考にさせていただきました。)
こちらの方の記事はCPU自作の際にもお世話になりましたので、本当に感謝してもしきれません🙇♂️🙇♂️
こちらのサイトには、各章ごとにスライド付きの解説が載っていて、文字だけだとイメージが掴みにくい分野に関しては結構参考にさせていただきました。
イラストが豊富なので、正直本よりもわかりやすい気がします。
あえて難点を挙げるなら英語で書かれているという点ですが、ある程度英語ができる方なら割と読めると思います。