やりたいこと
Glueで追加のデータを書き込む際に、以下のような書き込みがしたいことがありました。
- 追加データに含まれるパーティション内は上書き
- 含まれないパーティションはそのまま
具体例
以下2つのデータを考えます。
origin.csvが既存のデータで、add.csvが追加のデータです。
date,item,num,price
20230301,A,3,100
20230301,B,1,90
20230301,C,2,70
20230302,D,5,140
20230302,E,7,210
20230303,F,3,500
date,item,num,price
20230302,G,5,130
20230303,H,2,85
20230304,I,3,440
この場合、以下のような挙動を期待しています。
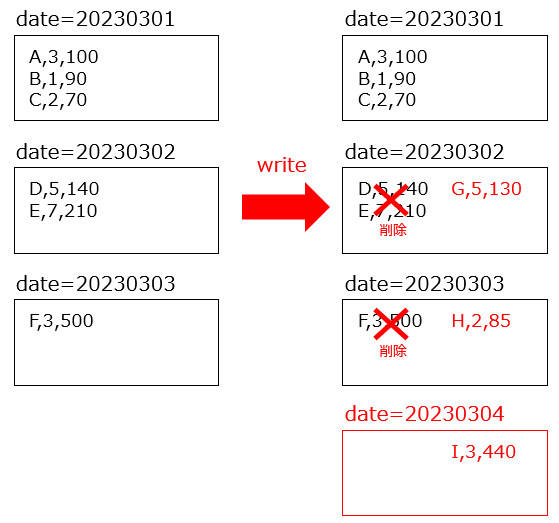
- date=20230301は追加のデータに含まれないためそのまま残る
- 既存のデータにも存在したdate=20230302, 20230303の2つのパーティション内は上書き
- 既存のデータに存在しないdate=20230304のパーティションは追加
これは、通常の上書き(overwrite)では実現できません。
overwriteをすると、以下のような挙動になってしまいます。

- 追加のデータのdate=20230302, 20230303, 20230304が上書きされる
- date=20230301は追加のデータに含まれないため削除されてしまう
前提条件
Glue version3.0を利用しています。
Sparkのversionは3.1.1です。
方法
Sparkの動的パーティション上書きモードを使って書き込むと、実現できます。
このモードは、Spark2.4から登場したそうです。Glueジョブversion3.0はSpark3.1.1なので利用できますね。
以下、サンプルコードです。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
### 処理ここから
input_s3_path="s3://test-bucket/input/add/"
output_s3_path="s3://test-bucket/output/"
# input
df = spark.read.csv(input_s3_path, header=True)
# output
df.write.mode("overwrite")\
.option("partitionOverwriteMode", "dynamic")\
.partitionBy("date")\
.parquet(output_s3_path)
### 処理ここまで
job.commit()
実際に実行してみる
上で出した例のcsvを用意して、まずは準備します。

それぞれのパーティションの中をS3 Selectで確認します。
date=20230301

date=20230302

date=20230303

上記のソースでGlueジョブを実行します。
期待通り、date=20230301は消えていません。
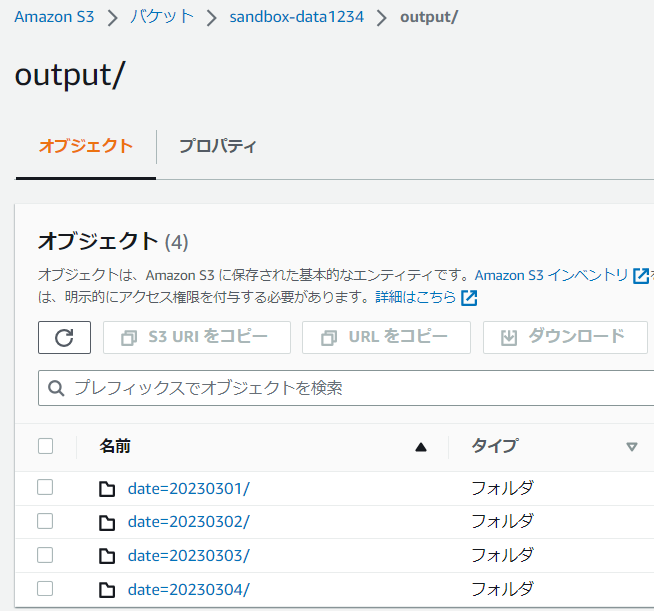
同じく、それぞれのパーティションの中をS3 Selectで確認します。
date=20230301

date=20230302

date=20230303

date=20230304

見事に、想定通りの出力になっていますね!
まとめ
通常の上書きでは、追加データにないパーティションのデータが消えてしまいましたが、動的パーティション上書きモードを使えば消えずに存在するパーティションだけを上書きできました。
モードの指定方法は、writeの際にoption("partitionOverwriteMode", "dynamic")と指定すればOKです。
これで、冪等性を担保して書き込みができますね!
ただし、同じパーティションに別のジョブからも書き込みがある場合は、動的パーティション上書きモードを利用すると他のジョブが書いたデータを上書きしてしまう可能性があるので注意してください。