はじめに
Glueでjsonをロードしたいことはよくあると思います。
その時、jsonのレコードが全て同じキーで揃っていることが理想です。
ただ、実際のデータは想像よりも汚いものです。キーが揃っていない時、スキーマを指定してGlueでロードするとどうなるかを検証します。
知りたいこと
GlueでSparkのDataFrame(DynamicFrameではない)として、スキーマを指定してjsonをロードした時、そのjsonが以下の時の挙動を確認します。
① 特定のキーがないレコードが含まれる
② 余計なキーがあるレコードが含まれる
前提条件
- Glue version: 3.0
- Spark version: 3.1.1
- jsonファイルはS3に格納
- name, price, countの3つのカラムを持つスキーマを指定してロード
- DynamicFrameではなくSparkのDataFrameとしてロード
結論
jsonで特定のキーがないレコードは、そのキーがnullとして読み込まれる。
余分に特定のキーがあるレコードは、そのキーが読み込まれず指定されたスキーマのデータだけがロードされる。
実験内容
理想のjson
4つのレコードに、name, price, countのキーが含まれています。
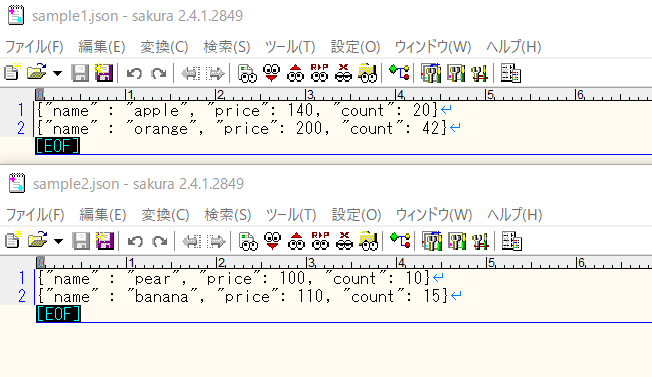
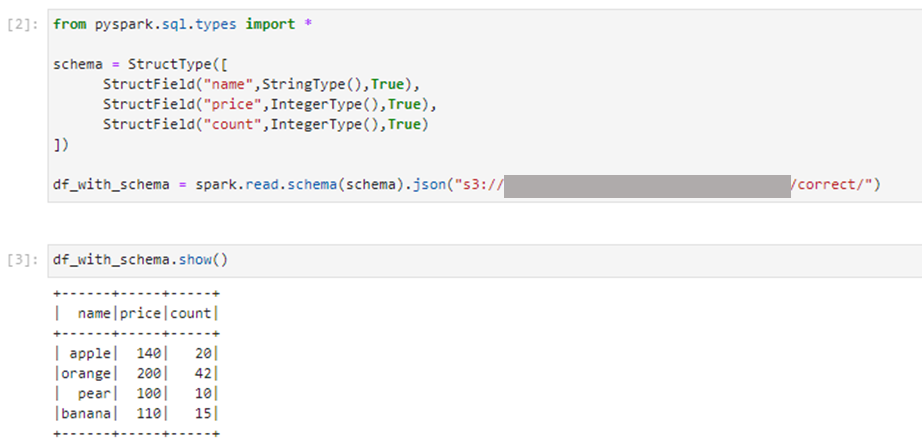
これを3つのカラムを指定して読み込んだところ、想定通り3つのカラムで4つのレコードが読み込まれました。
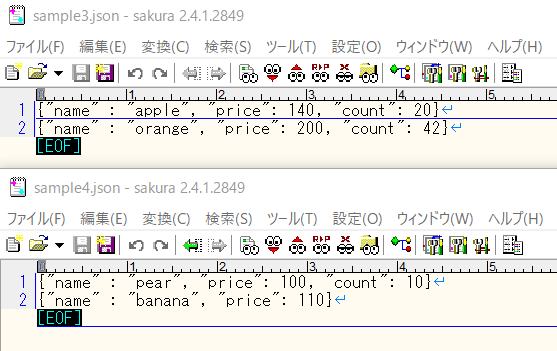
①(特定のキーがないレコードが含まれる)のjson
4レコード目のcountのキーがない状態です。
これを3つのカラムを指定して読み込んだところ、4レコード目のcountはnullとして読み込まれました。
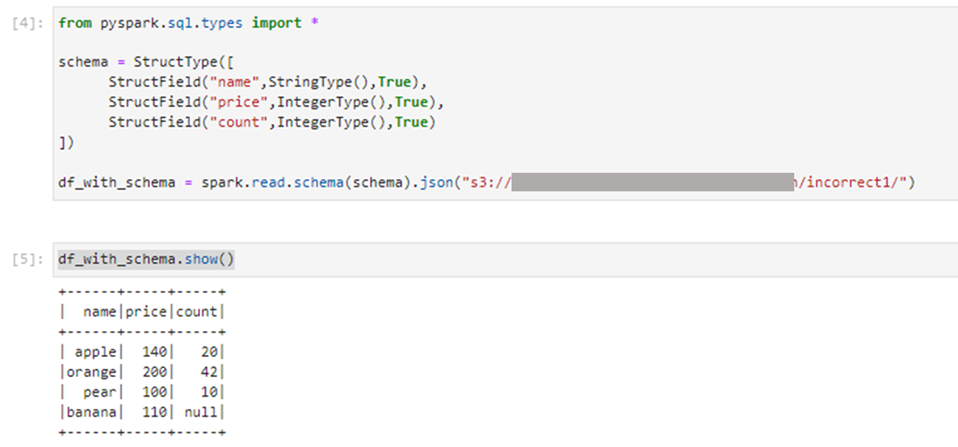
②(余計なキーがあるレコードが含まれる)のjson
3レコード目にupdate_dateという余計なキーが追加されています。
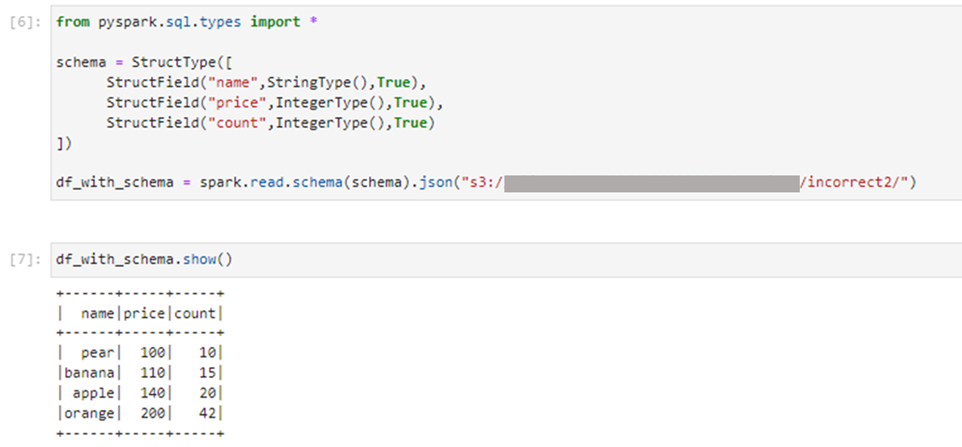
これを3つのカラムを指定して読み込んだところ、3レコード目のupdate_dateというキーは読み込まれませんでした。
追加実験
①(特定のキーがないレコードが含まれる)のとき、スキーマの指定では"count"のnullable = Trueとoptionで指定していました。つまり、nullを許容する状態でした。
これをFalseと指定してみましたが、結局スキーマとしてはnullable = trueの状態でした。
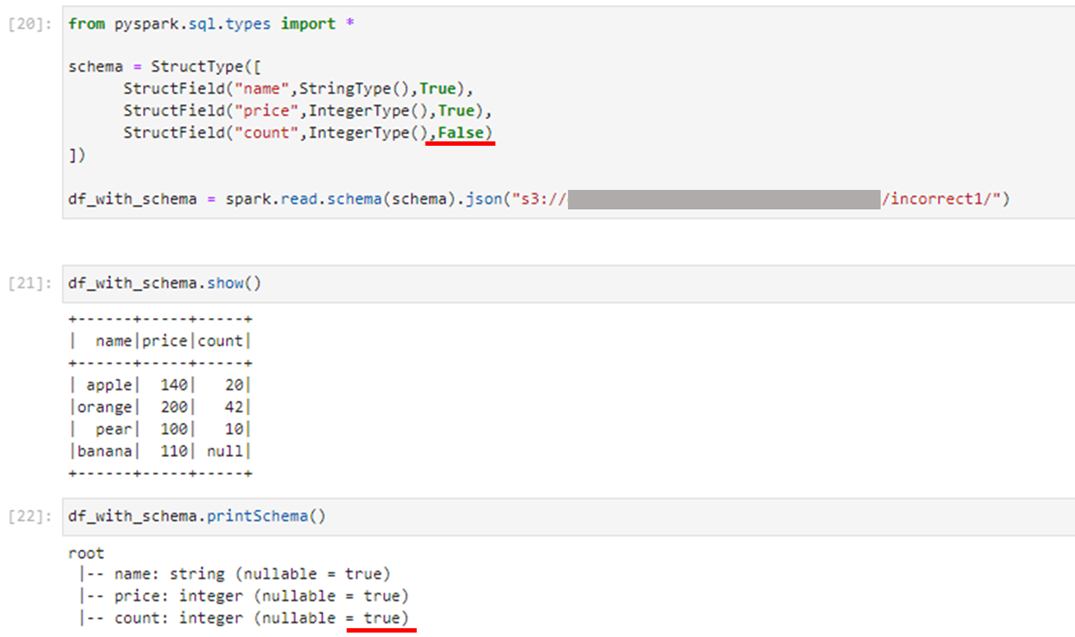
スキーマでnullableをFalseと指定しても、結局内部的にはtrueになってしまうので、スキーマを補正しないといけないようです。
おわりに
このあたりのスキーマに関するところは、Sparkを使うときに型の指定とともに悩まされるポイントですね。
これに関しては、Glueのデータカタログ + DynamicFrameで扱う方がやりやすそうだなと感じました。
SparkのDataFrameの処理を使いたい場合も、
DynamicFrameでデータカタログからロード ⇒ SparkのDataFrameで処理 ⇒ DynamicFrameでデータカタログに書き込み
という変換が可能です。
ただ、どうしてもSparkのDataFrameとしてロードさせたい(Choice型を最初から持ちたくない、など)場合は今回のようにスキーマを指定してあげたほうが無難そうです。
参考
実行したコードを以下に記載しておきます。
実験では、以下のコードのロードのパスを変えているだけです。
from pyspark.sql.types import *
schema = StructType([
StructField("name",StringType(),True),
StructField("price",IntegerType(),True),
StructField("count",IntegerType(),True)
])
df_with_schema = spark.read.schema(schema).json("s3://sample-bucket/correct/")
df_with_schema.show()