はじめに
QuickStartの説明
Airflow公式ドキュメントのユースケース紹介ページの中に、ETL/ELTというページがありました。
ここに紹介されている、airflow-quickstartというチュートリアルを実施してみたので紹介します。
このチュートリアルは、Airflow、DuckDB、Streamlitを使って、天気情報をグラフや地図、表にしてwebページとして表示するという内容です。内容的にもとっつきやすいので、まずはGitHubのReadmeを見てみてください。
- DuckDBとは、OSSのOLAP向け軽量RDBMSです。OLAP版のSQLiteという説明が分かりやすいです
- Streamlitとは、PythonでUIを簡単に定義できるオープンソースのWebアプリケーションフレームワークです
実施した環境
Readmeでは、以下の2つの方法が推奨されています。
- GitHub Codespacesを使う
- Githubが提供しているクラウド開発環境で、VSCodeがクラウド上で直接使えます
- Astro CLIを使う
- AirflowのマネージドサービスのCLIで、デプロイなども実施できます
今回は、Astro CLIをWindows 10環境で使ってみました。使い方はチュートリアルにある以下のサイトを参考にしました。
wingetを使うと、WindowsでもLinuxのように簡単にインストールできます。
ここからは、一通り実施して重要だと感じた点と、躓きやすいと感じた点をそれぞれご紹介します。
重要な文法や概念
TaskFlow API
TaskFlow APIは、AirflowのDAG内でTask間の連携を定義する方法で、バージョン2.0から導入されました。以前の記法よりもTask間の依存関係が分かりやすく、スッキリと書けます。
チュートリアルの以下のコードが参考になります。
def extract_historical_weather_data():
@task
def get_lat_long_for_city(city):
####################### 省略 #######################
return city_coordinates
@task
def get_historical_weather(coordinates):
####################### 省略 #######################
return historical_weather_and_coordinates.to_dict()
coordinates = get_lat_long_for_city(city="Bern")
historical_weather = get_historical_weather(coordinates=coordinates)
@task(
outlets=[Dataset("duckdb://include/dwh/historical_weather_data")],
)
def turn_json_into_table(
duckdb_conn_id: str,
historical_weather_table_name: str,
historical_weather: dict,
):
####################### 省略 #######################
cursor.close()
turn_json_into_table(
duckdb_conn_id=gv.CONN_ID_DUCKDB,
historical_weather_table_name=c.IN_HISTORICAL_WEATHER_TABLE_NAME,
historical_weather=historical_weather,
)
Taskを定義する関数の前に@taskを付けることで、AirflowがTaskとして認識します。また、Task間の依存関係は関数の呼び出し形式で定義します。
coordinates = get_lat_long_for_city(city="Bern")
historical_weather = get_historical_weather(coordinates=coordinates)
この部分で、get_lat_long_for_city関数が実行された後にget_historical_weather関数が実行されるという依存関係が認識されます。以前の記法では以下のように定義されていました。
get_lat_long_for_city >> get_historical_weather
TaskFlow APIでは、関数の返り値を次の関数の引数にすることでデータのやり取りが視覚的にわかりやすくなっています。
次のDatasetsもそうですが、Airflowはワークフローの中でデータの動きが分かるように進化しているように思えます。これはとても良い方向性の進化ですよね。
Datasets
Data-aware schedulingという機能で、Datasetsというデータの論理的なグループを定義し、そのDatasetsが更新されたタイミングでDAGを起動することができます。バージョン2.4から導入されました。
文字の説明だけだとよくわからないと思いますが、これを見ていただくと分かりやすいです。これ最初に見たとき、かなり感動しました。
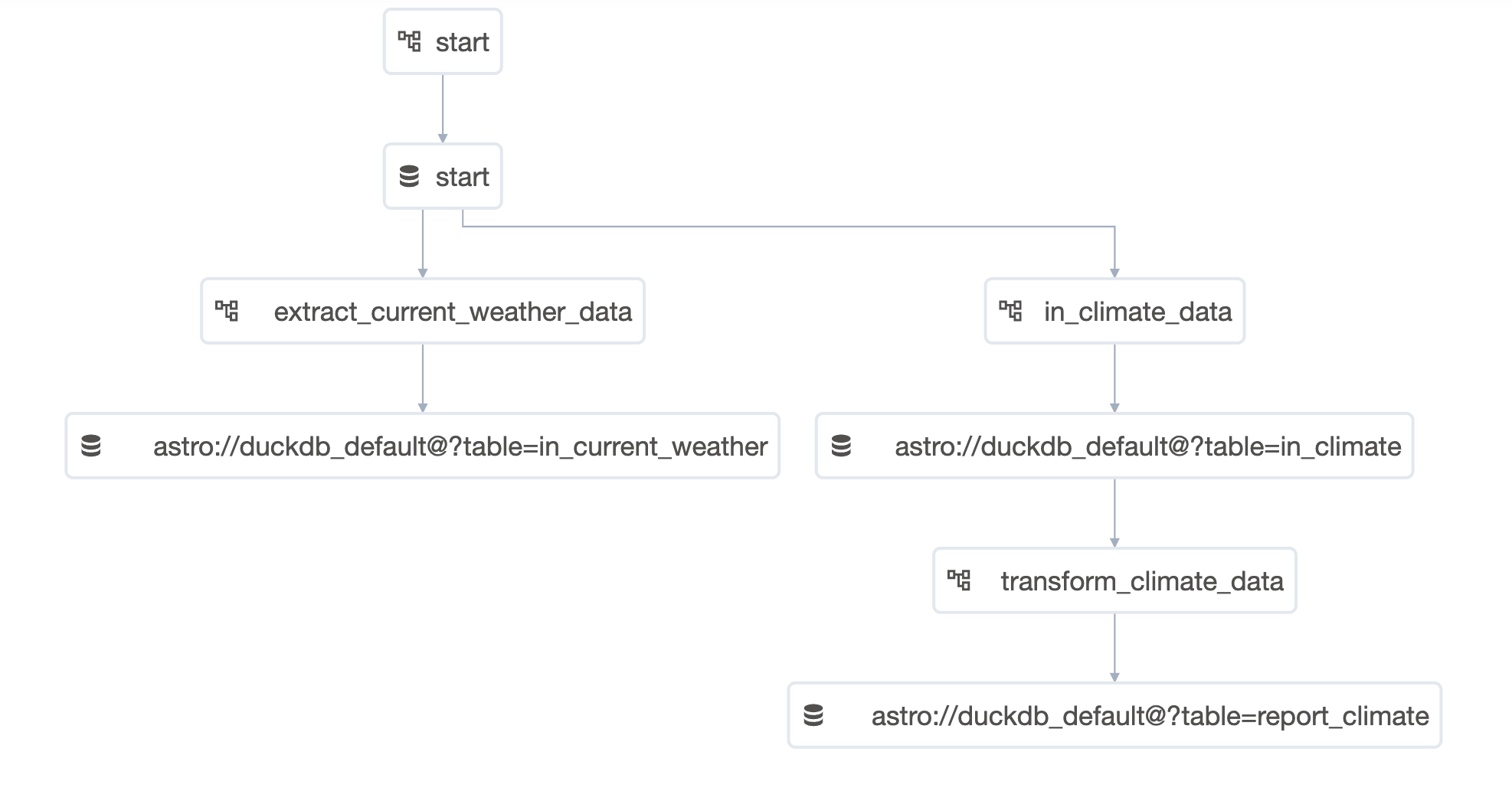
2つのアイコンがあると思います。データベースのようなアイコンがDatasetsで、四角に線がつながっているアイコンがDAGです。
ここで、2つのDAG、startとextract_current_weather_dataを見てみましょう。
start_dataset = Dataset("start")
@dag(
start_date=datetime(2023, 1, 1),
schedule="@once",
catchup=False,
default_args=gv.default_args,
description="Run this DAG to start the pipeline!",
tags=["start", "setup"],
)
def start():
create_duckdb_pool = BashOperator(
task_id="bash_task",
bash_command="airflow pools list | grep -q 'duckdb' || airflow pools set duckdb 1 'Pool for duckdb'",
outlets=[start_dataset],
)
start.pyの最初で以下のようにDatasetを定義していますね。
ここに書いてあるように、Datasetの名前はただの文字列です。最初に論理的なグループと言ったのはこれが理由です。
start_dataset = Dataset("start")
さて、同じくstart.pyの最後の方に、taskの引数としてoutletsを渡しています。これで、このTaskがこのDatasetを更新するものだとAirflowは認識します。このように書くだけで、先ほどの図のようにDAGのstartからDatasetのstartがつながるのです。
create_duckdb_pool = BashOperator(
task_id="bash_task",
bash_command="airflow pools list | grep -q 'duckdb' || airflow pools set duckdb 1 'Pool for duckdb'",
outlets=[start_dataset], #★★ココ
)
ちなみに、ここではTaskFlow APIの記法は使わず以前の方法で記載しています。TaskFlow APIで渡すときは、@task(outlets=[start_dataset])のように@taskの中に書きます。
ここまでは、全体のうちのこの部分でした。

次は、DatasetからDAGの部分のつながりを見てみます。
start_dataset = Dataset("start")
@dag(
start_date=datetime(2023, 1, 1),
schedule=[start_dataset], #★★ココ
catchup=False,
default_args=gv.default_args,
description="DAG that retrieves weather information and saves it to a local JSON.",
tags=["part_1"],
render_template_as_native_obj=True,
)
def extract_current_weather_data():
@task
def get_lat_long_for_city(city):
同じく最初にDatasetを定義した後に、@dagの中でschedule=[start_dataset]と定義しています。
こうすると、Datasetであるstart_datasetが更新されたとき(=outlets=[start_dataset]と定義されたTaskが実行されたとき)にこのDAGが実行されるようにスケジューリングされます。通常スケジューリングは時間ベースでしたが、このようにDatasetを記載することでデータの更新ベースで実行ができるようになりました。
ちなみに、先ほどはTask単位でoutletsを定義しましたが、今回はDAG単位での定義となります。
これで、全体のうち以下の部分のつながりを示したことになります。
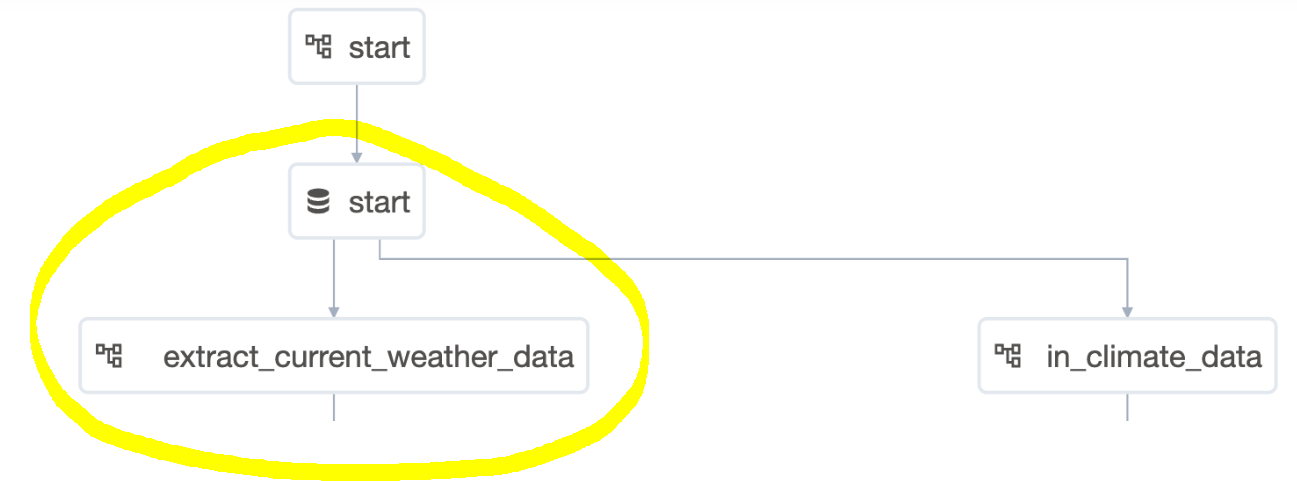
これをつなげていくことで、DAGとデータのつながり全体を追える、つまりはデータリネージの実現が可能となるのです。
データリネージとは、データや加工ジョブの流れを特定できるようにすることです。以下の記事が分かりやすかったです
データリネージ(Data Lineage)とは?
Context
contextはAirflow側で管理している変数で、DAG名やrun_idなどのシステム情報を取得できます。特によく使われる変数がlogical_dateです。これは、Airflowが認識している日付で、データのフィルタリングなどに使えます。
@task
def get_current_weather(coordinates, **context #★★ココ):
# the logical_date is the date for which the DAG run is scheduled it
# is retrieved here from the Airflow context
logical_date = context["logical_date"] #★★ココ
city_weather_and_coordinates = get_current_weather_from_city_coordinates(
coordinates, logical_date
)
return city_weather_and_coordinates
Taskの関数の引数として**contextを指定しています。これで関数の中で使えるようになります。
実際に、関数の中でlogical_date = context["logical_date"]として取得していますね。
取得できる変数は、公式ドキュメントに記載がありますので覗いてみてください。
Dynamic Task mapping
Dynamic Task mappingは、DAG内のTaskを動的に作成できる機能です。list形式でパラメータを与えると、各要素を入力としてTaskが作成されます。バージョン2.3から導入されました。
これは、チュートリアルの中のPart 2 Instructions (Exercises)のExercise 2 - Dynamic Task Mappingで出てきます。提供されているコードではDynamic Task mappingをまだ適用していない形になっています。
以下のように、それぞれ2つのTaskをTaskFlow APIの記法で呼び出していますね。この状態では、Taskは1つずつしか作成されません。
@dag(
####################### 省略 #######################
)
def extract_historical_weather_data():
@task
def get_lat_long_for_city(city):
####################### 省略 #######################
@task
def get_historical_weather(coordinates):
####################### 省略 #######################
coordinates = get_lat_long_for_city(city="Bern") #★ココ
historical_weather = get_historical_weather(coordinates=coordinates) #★ココ
チュートリアル内では、「これを、3つの都市に対して動的にTask作成するよう修正してみよう」 とあるので以下はネタバレになってしまうのですが、それでも良い方はご覧ください。
以下のように.expandを付けてlistを渡すことで、これらを入力とした複数のTaskを生成できます。
coordinates = get_lat_long_for_city.expand(city=["Bern", "Luzern", "Zurich"])
historical_weather = get_historical_weather.expand(coordinates=coordinates)
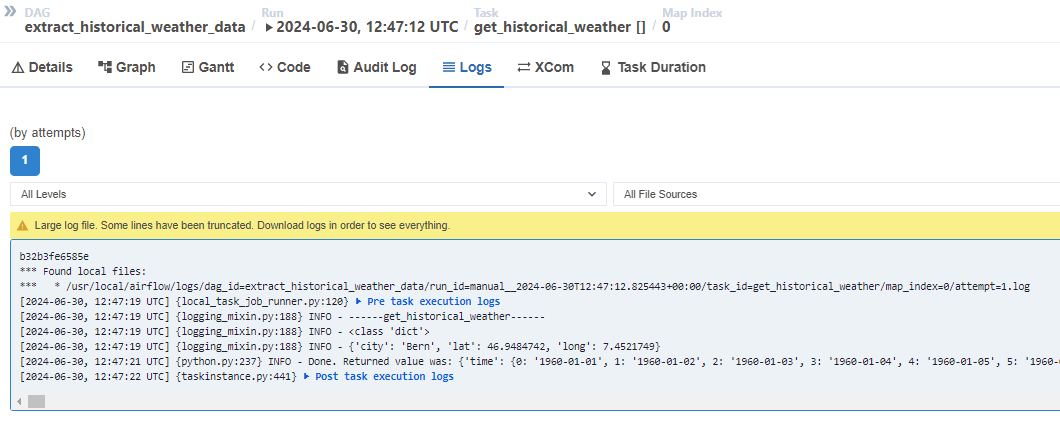
実際にAirflow UIで見てみると、以下のように[3]となっており3つのTaskが実行されています。

ちなみに、この1つのTaskをクリックして[] Mapped Tasksというタブを選択すると、以下のようにそれぞれの実行の履歴が見えます。さらにこれをクリックすると、それぞれのログも確認できます。

躓きポイント
3つほどハマった箇所があったので共有します。
[Part 1] DuckDBのパーミッションエラー
内容
一番最初のDAG実行のタイミングでエラーが発生しました。
内容を見ると、DuckDBへの書き込み時に以下のエラーが発生していました。
duckdb.IOException: IO Error: Cannot open file "/usr/local/airflow/include/dwh": Permission denied
原因と対応
上記のIssueに詳細は記載してありますが、Astro CLIで実施すると実行時のユーザーastroのUIDが50000で実行されるそうです。ホスト側のUIDは1000でそれと異なることからこのエラーが発生しているようです。
私の場合は、WSL2でコンテナにrootで入ってDuckDBの権限を777に変更して解決しました。
[Exercise 2]DuckDBのスキーマエラー
内容
Dynamic Task Mappingを利用するように自分でコードを修正するところでエラーが発生しました。
このDAGでは最後にDuckDBへデータを書き込みますが、型が異なるというエラーが発生しました。
duckdb.ConversionException: Conversion Error: Unimplemented type for cast (STRUCT("0" DOUBLE, "1" DOUBLE, ... , "23011" DOUBLE) -> DOUBLE)
原因と対応
上記のIssueに詳細は記載してありますが、後続の処理でDynamic Task Mappingの返り値の型がlistであるというIf文の条件式があり、そこにうまく入ってないことが原因でした。
typeで型を調べるとLazyXComAccess型だそうで、これは遅延プロキシ(a lazy proxy)と言って遅れて値が確定するオブジェクトとのことでした。確かに、expand([list])でいくつTaskが並列実行されるかは実行時にならないと分からないですよね。
対応はかなりショボいですが、if文を無視して中で実行されるコードを直接実行するように修正しました。これはIssue対応してもらえることを祈っています。
[Exercise 3]自分の誕生日以外の日付のデータも出力される
内容
最後のExerciseです。これは既存のバグとかではなく、1つ前のExerciseを何回か実行していたらInsertでデータがどんどん追加されてしまって、最後に表示されるデータが想定した誕生日のデータ以外のものも含まれてしまっていたというものです。
原因と対応
チュートリアルの指示通り誕生日のデータのみを抽出した後、重複行の削除と元のテーブルのレコード削除を行いました。
input_df = cursor.sql(
f"""
SELECT * FROM {input_table_name}
"""
).df()
####### 修正ここから ##########
# 誕生日のデータのみ抽出
output_df = input_df[input_df['time'] == '1987-06-03']
# 重複した行を削除
output_df = output_df.drop_duplicates()
# 全てのレコードを削除
cursor.sql(f"DELETE FROM {output_table_name}")
####### 修正ここまで ##########
output_df = input_df
# saving the output_df to a new table
cursor.sql(
f"CREATE TABLE IF NOT EXISTS {output_table_name} AS SELECT * FROM output_df"
)
cursor.sql(f"INSERT INTO {output_table_name} SELECT * FROM output_df")
cursor.close()
おわりに
チュートリアルということでボリュームはそこまでありませんでしたが、Airflow 2.0系以降で追加された便利機能がたくさん使われていてとても良かったです。特にDatasetsはうまく使うと複雑なフローも疎結合に管理できて良さそうに思えました。ぜひ業務にありそうなユースケースでこの機能を試してみたいです。ちなみに、AWSのAirflowマネージドサービスのMWAAは現在Airflow v2.8.1をサポートしている(2024年7月1日現在)ので、Datasetsの機能も使えます。
また、初めてastro CLIを使いましたが、コマンド一発でAirflowのDocker環境を立ち上げてくれて検証に便利ですね。クラウドサービス使うとお金かかるのでローカルでやりたい!という場合は、これ使うと便利です。
ということで、今後もAirflowの機能は試していきたいと思います。