はじめに
本記事は、以下の手順をまとめた記事です。
- ABEJA Platform SDKを用いて、ローカル環境でフォルダ分けした画像ファイルから、ABEJA PlatformのClassification用のデータセットを作成する
事前準備
- ローカル環境へのABEJA Platform SDKのインストール
データの用意
サンプルとしてStanford Dogs DatasetのImages (757MB)をダウンロードします。
DataLake Channelの作成
コンソールのDataLake Channelから'+Create Channel'をクリックして、Channelを作成します。
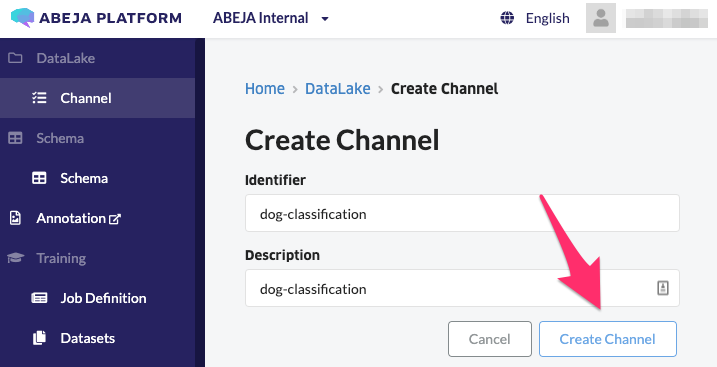
作成したChannelのIDを控えておきます。

DataLake Channelへのデータのアップロード
SDKを用いて、ローカルにダウンロードした画像ファイルをアップロードします。
カレントディレクトリをダウンロードしたimagesフォルダの直下に移動して、Pythonのインタプリタを起動します。
まず、画像ファイルの数を確認してみます。
from glob import glob
# load filenames for images
file_names = list(glob('./*/*'))
dir_names = list(glob('./*'))
# print number of images in dataset
print('There are %d total images.' % len(file_names))
全部で20,560枚あります。今回はこの中でブル系の犬種のデータのみを選定したいと思います。
# select directories
selected_dirnames = [d for d in dir_names if 'bull' in d]
print(selected_dirnames)
次に、ABEJA Platform SDKのクレデンシャルの設定を行います。
ユーザーID、パーソナルアクセストークン、オーガニゼーションIDは、コンソールの右上のアカウント名をクリックすると表示されます。
クレデンシャルのuser_idは、コンソールに表示されるユーザーID(13桁の数字)の冒頭に'user-'を付けたものです。
# set credential
credential = {
'user_id': 'user-XXXXXXXXXXXXX',
'personal_access_token': 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
}
organization_id='XXXXXXXXXXXXX'
Datalakeにデータをアップロードします。アップロード先として、先ほど記録したChannel IDを指定します。また、アップロードする際に、ラベル名をメタデータとして画像に付与します。
今回のデータセットは、フォルダ名が「n02096585-Boston_bull」という形式になっているため、フォルダ名から不要な数字・記号を削除して、大文字に変換したものをラベル名としました。
from abeja.datalake import Client as DatalakeClient
# set datalake channel_id
channel_id = 'XXXXXXXXXXXXX'
datalake_client = DatalakeClient(organization_id, credential)
channel = datalake_client.get_channel(channel_id)
import os
from tqdm import tqdm
# upload directory data to datalake
for d in tqdm(selected_dirnames):
# convert to uppercase and remove numbers
label_name = os.path.basename(d).upper()[10:]
metadata = {'label': label_name}
channel.upload_dir(d, metadata=metadata)
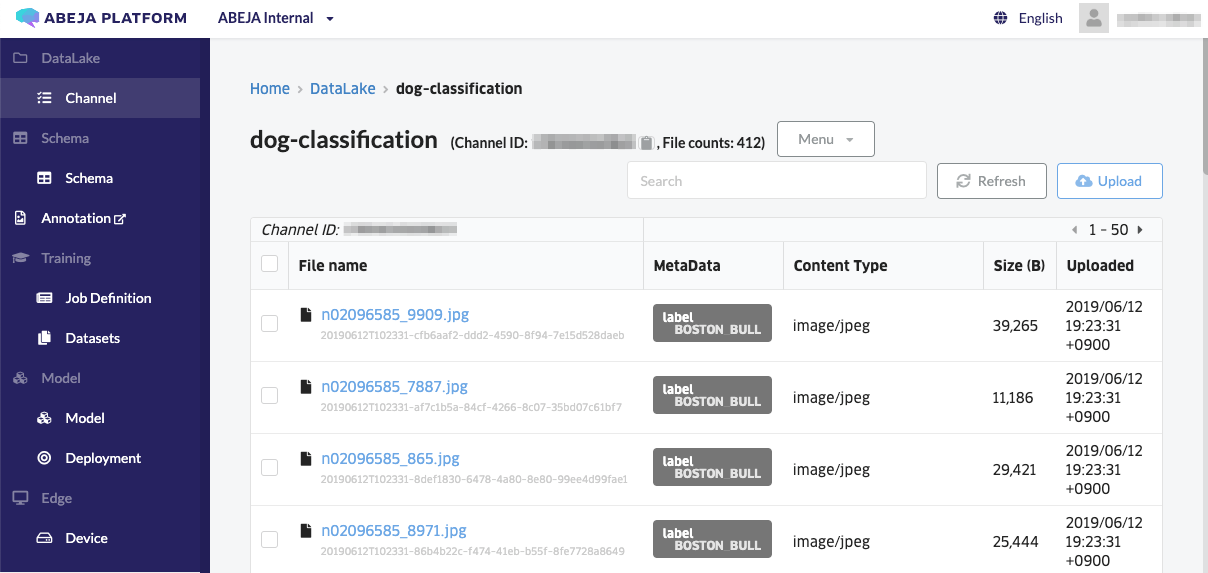
画像がアップロードされました。メタデータとしてラベル名が付与されていることも確認できました。
Datasetsの作成
続いて、Datasetsを作成します。
まず、画像分類用のDatasets(教師データ)のラベルを作成します。ABEJA Platformでは、ラベルをJSONで管理しています。
import json
labels = sorted([os.path.basename(d).upper()[10:] for d in selected_dirnames])
labels_and_id = []
label_to_id = {}
for i, name in enumerate(labels):
label_to_id[name] = i
labels_and_id.append({'label_id': i,
'label': name})
# define category name
category_name = 'bull-classificaiton'
# create dataset label
category = {
'category_id': 0,
'name': category_name,
'labels': labels_and_id}
props = {'categories': [category]}
json.dumps(props)
上記コマンドを入力すると、以下のラベルが出力されます。
{
"categories": [
{
"category_id": 0,
"labels": [
{
"label": "BOSTON_BULL",
"label_id": 0
},
{
"label": "BULL_MASTIFF",
"label_id": 1
},
{
"label": "FRENCH_BULLDOG",
"label_id": 2
},
{
"label": "STAFFORDSHIRE_BULLTERRIER",
"label_id": 3
}
],
"name": "bull-classificaiton"
}
]
}
コンソールのDatasetsから、'+Create Datasets'をクリックします。
データセットの名前とタイプ(今回はClassification)を入力しPropertiesにJSONのラベルをコピーペーストして、Datasetsを作成します。

最後に、Datalakeにアップロードしたデータを、Datasetsに登録します。
登録先として、先ほど作成したDatasetsのIDを指定します。
# create dataset by importing datalake files
from abeja.datasets import Client as DatasetClient
dataset_client = DatasetClient(organization_id, credential)
# define dataset id
dataset_id = 'XXXXXXXXXXXXX'
dataset = dataset_client.get_dataset(dataset_id)
for f in tqdm(channel.list_files()):
data_uri = f.uri
filename = f.metadata['filename']
label = f.metadata['label']
label_id = label_to_id[label]
if os.path.splitext(filename)[1].lower() == '.jpg' or \
os.path.splitext(filename)[1].lower() == '.jpeg':
content_type = 'image/jpeg'
elif os.path.splitext(filename)[1].lower() == '.png':
content_type = 'image/png'
else:
print('{} is invalid file type.'.format(filename))
continue
source_data = [{'data_uri': data_uri, 'data_type': content_type}]
attributes = {'classification': [{'category_id': 0, 'label_id': label_id, 'label': label}]}
dataset.dataset_items.create(source_data, attributes)
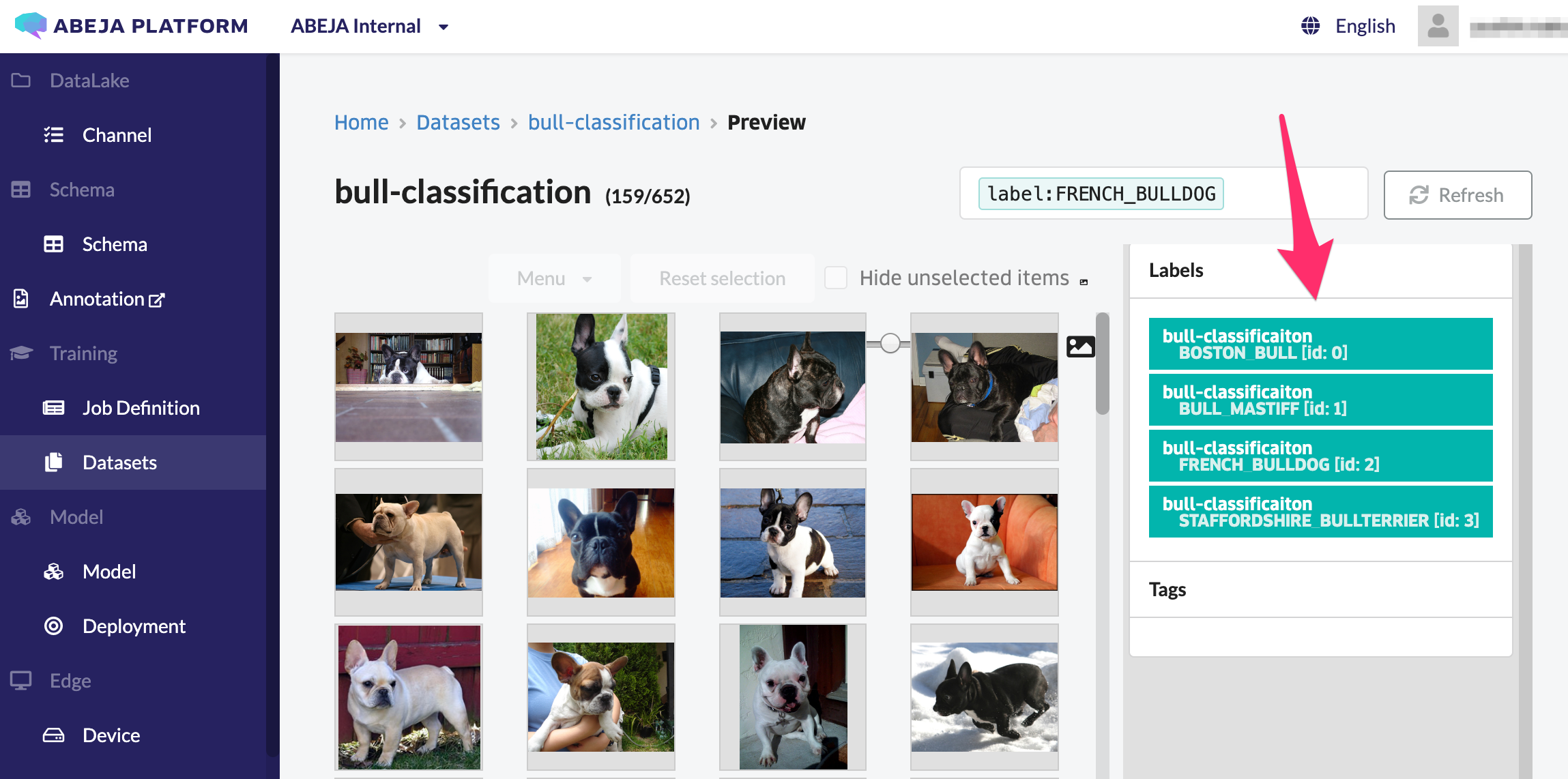
教師データの作成が完了しました!
ラベルをクリックすることで、ラベル毎にフィルターされた画像をプレビューで確認することができます。
まとめ
本記事では、ABEJA Platform SDKを用いて、ローカル環境でフォルダ分けした画像ファイルから、ABEJA PlatformのClassification用のデータセットを作成する手順をまとめました。今回、一部コンソールを使用しましたが、SDKを用いて全ての手順を実行することも可能です。詳細については、公式ドキュメントを参照下さい ![]()
https://sdk-spec.abeja.io/datalake/sample_tutorial.html#steps-1-create-a-datalake-channel
参考
サンプルコード(Jupyter Notebook形式)
https://github.com/abeja-inc/Platform_handson/blob/master/bulldog_classification/notebook/Create_ABEJA_Platform_dataset.ipynb
アノテーション済みデータをABEJA Platformにアップロードする
https://qiita.com/peisuke/items/6ebca3a2299ddbc67c6a