この記事は、OCI(Oracle Cloud Infrustructure) 上で、
- Oracle AI Data Platform(AIDP)
- Autonomous AI Lakehouse
- Oracle Analytics Cloud(OAC)
を活用し、航空会社の運航データ(遅延時間や飛行距離などの数値データ) とフライトに対するレビュー文 に対して、Generative AI による感情分析を行い、分析・可視化までのモダンなデータ分析パイプラインを構築するハンズオンを紹介します。
👉 後編はこちら
はじめに
近年、AIの活用によりデータ分析を取り巻く状況が変化する中で、
構造化データ(数値・テーブル) だけでなく、
非構造化データ(文章・レビュー・問い合わせ内容など) を
素早くかつ統合的に分析に活かすことが重要になってきています。
今回は、航空会社の運航データ(遅延時間や飛行距離などの数値データ) に加えて、
フライトに対するレビュー文 を扱い、これらを Lakehouse 上で統合・加工したうえで、
Generative AI を用いた感情分析 を行い、分析・可視化まで進めていきます。
また、今回実施していくプロセスの中では、AI を分析結果を補足するためのツールとして使うのではなく、データを分析に適した形へ変換する前処理プロセスに組み込む という使い方をしています。
こうした一連の処理を通して、いわゆる 「レイクハウス」アーキテクチャ の流れを紹介します。
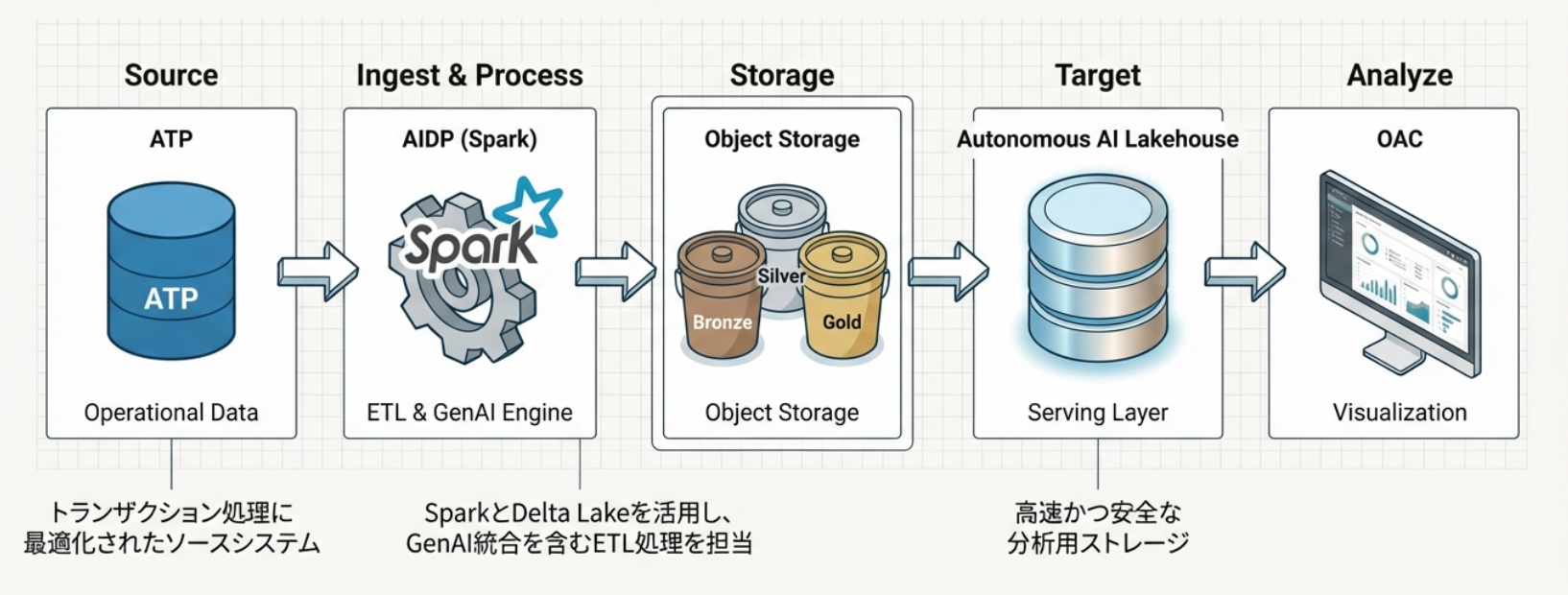
それぞれのプロセスで行う実際に使用するコードの中身も丁寧に解説しながら進めていきます。「レイクハウスって具体的にどう動かすの?」「AIをパイプラインにどう組み込むの?」という疑問を、手を動かしながら一緒に解消していきましょう!
ぜひ最後まで取り組んでみてください!
このハンズオンで学べること
- サンプルの航空会社データを用いたトランザクションソースシステムのセットアップ
- AIDP 上でメダリオンアーキテクチャ Bronze / Silver / Gold レイヤーを通じたデータ抽出・処理
- Generative AI を使ってレビュー文に 感情分析(Sentiment) を付与
- 整備された Gold データを Autonomous AI Lakehouse に公開
- OAC ダッシュボードでのインサイトや KPI の可視化
目的
このワークショップを完了すると、以下ができるようになります。
- Oracle Cloud サービスを用いたレイクハウスアーキテクチャの主要な考え方を理解する
- トランザクションソース(ATP)をセットアップし、データを抽出する
- AI Data Platform 上で Spark / Delta Lake を使った ETL(Extract, Transform, Load)パイプラインを構築する
- 分析に適したデータを Autonomous AI Lakehouse に準備・公開する
- Oracle Analytics Cloud(OAC)でデータ可視化やダッシュボードを設計する
アーキテクチャ

事前確認
以下のリソースを使用していきます。テナント・リージョンで以下のサービスにアクセスできることを確認しておきます。
- Autonomous Transaction Processing(ATP)
- Oracle AI Data Platform(AIDP)
- Autonomous AI Lakehouse
- Oracle Analytics Cloud(OAC)
- Generative AI
- Object Storage
ハンズオンの流れ
本ハンズオンは、前編・後編の2回構成 となっています。
- 前編(Step 1~Step 2) *本記事
- 後編(Step 3) 👉 こちら
Step 1: OCI リソースのセットアップ
- ATP のプロビジョニング
- ソーススキーマの作成
- AI Lakehouse のプロビジョニング
- AI Data Platform のプロビジョニング
- Object Storage バケットの作成
- Oracle Analytics Cloud のプロビジョニング
Step 2: AI Data Platform と Lakehouse でのデータ処理・整備
- ATP からデータを抽出
- AIDP でデータを処理
- AI Lakehouse の Gold スキーマに公開
Step 3: Oracle Analytics Cloud(OAC)でのインサイト獲得
- Gold スキーマへ接続
- 可視化の作成
- 自然言語で Assistant と対話
補足
- 今回はシカゴリージョンを利用して実施していきます。
- リソース名が一意である必要がある項目については、本ハンズオンでは
source_01のように末尾に01の数字を付ける命名規則としています。
ではこここから早速始めていきましょう!
◼︎ Step 1:OCIリソースの構築とセットアップ
この章では、トランザクション型の航空会社データのソースシステムとして Oracle Autonomous Transaction Processing(ATP) を設定し、ターゲットシステムとして Autonomous AI Lakehouse、さらに AI Data Platform インスタンス と Object Storage バケット を構築します。
これにより、運用データをレイクハウスパイプラインへ取り込むための、現実的な初期構成を作成します。
Oracle Autonomous Transaction Processing(ATP)、Oracle AI Data Platform(AIDP)、Autonomous AI Lakehouse とは
ATP :
フライト記録のような運用データを格納・管理する トランザクション処理(OLTP) ワークロードに最適化された自律型データベースサービスです。本ワークショップでは、分析のためにデータを抽出する 実運用を想定したトランザクションデータベース として ATP を利用します。
AI Data Platform(AIDP):
構造化データ・非構造化データ・バッチデータ・リアルタイムデータなど、あらゆる種類のデータを統合する オープンかつ連携されたプラットフォーム です。信頼できる AI 対応データパイプラインの基盤を提供し、個別ツールを連携させる複雑さを伴うことなく、組み込みツールや GenAI エージェントフレームワークを用いて AI アプリケーションを迅速に構築・展開できます。
Autonomous AI Lakehouse:
高速かつ安全な分析向けストレージを提供します。
これらを組み合わせることで、生データをインサイトへと変換する モダンなレイクハウス基盤 が実現されます。
実施内容
このラボでは、以下の作業を順番に実施します。
- ATP インスタンスを作成する
- ATP に Source_01 スキーマを作成する
- Autonomous AI Lakehouse をプロビジョニングする
- AI Lakehouse に Gold_01 スキーマを作成する
- AI Data Platform をプロビジョニングする
- Object Storage バケットを作成する
- Oracle Analytics Cloud をプロビジョニングする
◻︎ Task 1: コンパートメントの作成
- 「アイデンティティとセキュリティ」>「コンパートメント」から、ハンズオン用のコンパートメントを作成します。

今回は「AIDP」というコンパートメントの中で実施していきます。

◻︎ Task 2: ATP インスタンスのプロビジョニング
- 「Oracle AI Database」>「Autonomous AI Database」をクリックします。

- 作成するリージョンとコンパートメントを確認し、「Autonomous AI Databaseの作成」をクリックします。

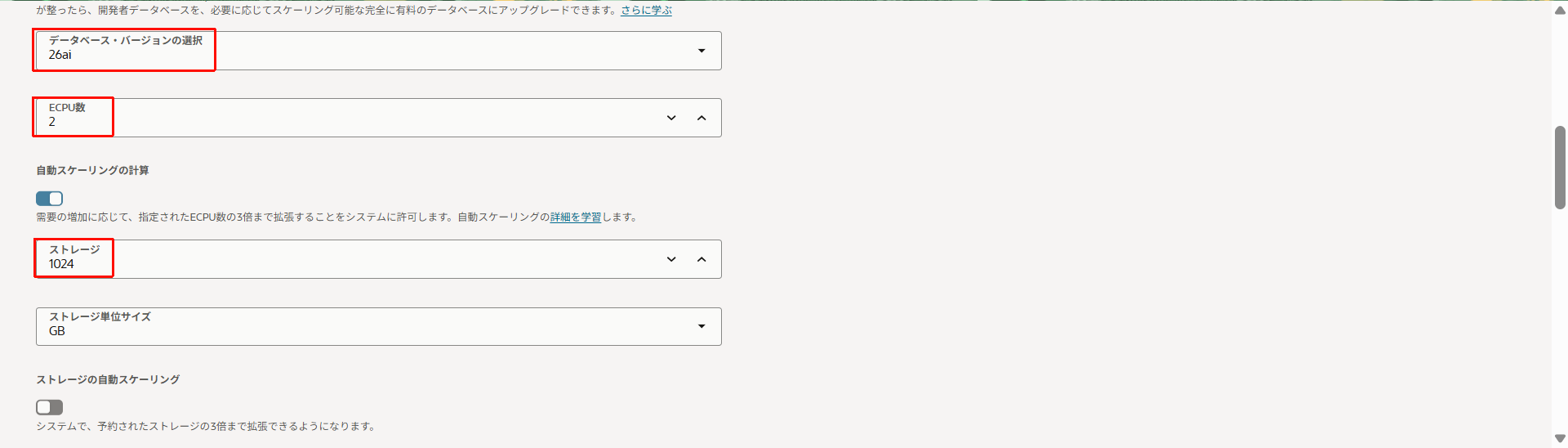
- 設定項目を以下のように入力していきます。(ここで記載している項目以外はデフォルトで構築します。)
- 表示名:任意(ここでは
airline-source-atp) - データベース名:任意(ここでは
AIRLINESOURCE01) - ワークロード・タイプ:
トランザクション処理
- 表示名:任意(ここでは

- データベース・バージョン:
26ai - ECPU数:任意
- ストレージ:任意(今回のハンズオン用途のみで使用する場合は、20GBに抑えて設定することができます。)
Adminユーザーのパスワードと、ネットワークアクセスのアクセス・タイプ(必要に応じてアクセスできるネットワークを制限)を選択します。

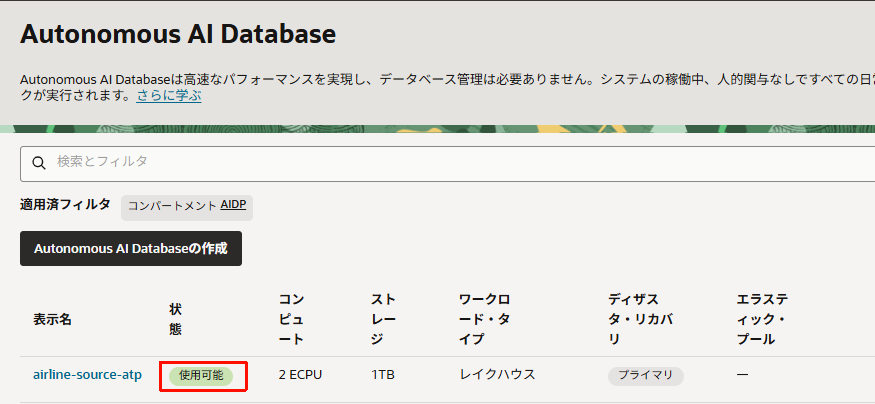
- 入力が完了したら、設定項目を確認の上、「作成」をクリックします。

数分経つとプロビジョニングが完了するので、「使用可能」になっていることを確認します。(今回は約5分で作成完了)
プロビジョニングがが完了したら次のステップに進みます。
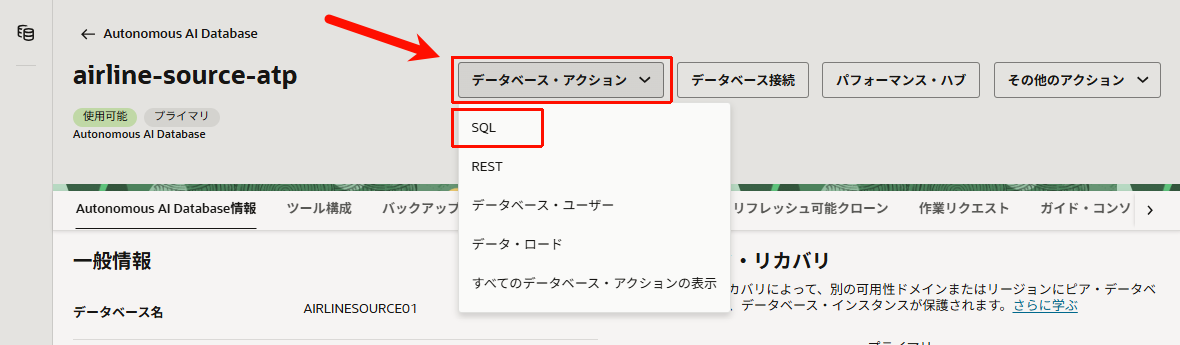
◻︎ Task 3: Source_01 スキーマの作成
- 先程作成したAutonomous AI Database (ATP)の詳細画面を開き、「データベース・アクション」>「SQL」をクリックします。
- 以下のコマンドを実行して、
Source_01スキーマを作成します。
CREATE USER Source_01 IDENTIFIED BY "任意のパスワード";
-- データ操作に必要な基本権限
GRANT CONNECT, RESOURCE TO Source_01;
-- セッション接続、テーブル・ビューなど各種オブジェクトの作成を許可
GRANT CREATE SESSION TO Source_01;
GRANT CREATE TABLE TO Source_01;
GRANT CREATE VIEW TO Source_01;
GRANT CREATE SEQUENCE TO Source_01;
GRANT CREATE PROCEDURE TO Source_01;
GRANT UNLIMITED TABLESPACE TO Source_01;
-- DBMS_CLOUD パッケージの実行権限を付与
GRANT EXECUTE ON DBMS_CLOUD TO Source_01;
-- DATA_PUMP_DIR へのアクセス権限を付与(Spark の saveAsTable 処理で使用)
GRANT READ, WRITE ON DIRECTORY DATA_PUMP_DIR TO Source_01;
実行後、すべてのコマンドが正しく実行されていることを確認します。

データベース・アクションのSQLを閉じます。
◻︎ Task 4: Source_01 スキーマに REST 機能を追加
-
source_01スキーマをREST有効化します。
続いて、ADBの詳細画面から「データベース・アクション」>「データベース・ユーザー」を開きます。
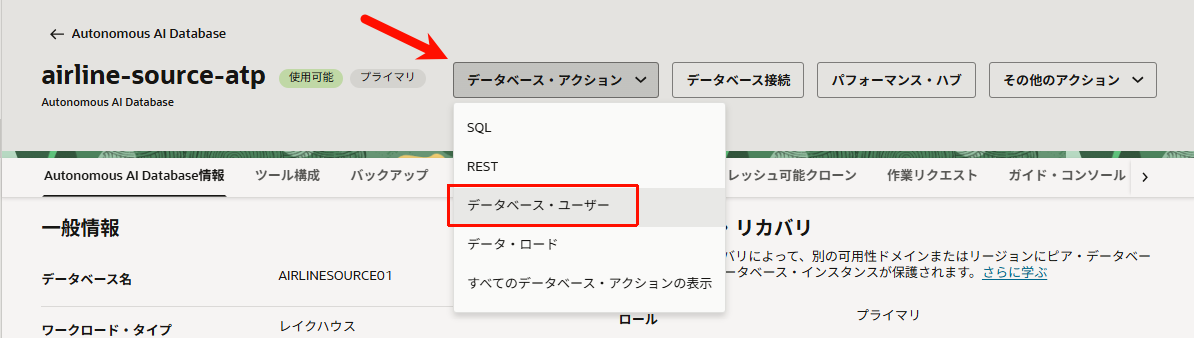
先程作成した「source_01」のスキーマを見つけて、「︙」から「RESTの有効化」をクリックします。

「REST対応ユーザー」をクリックします。(成功すると画面下にポップアップが出ます。)
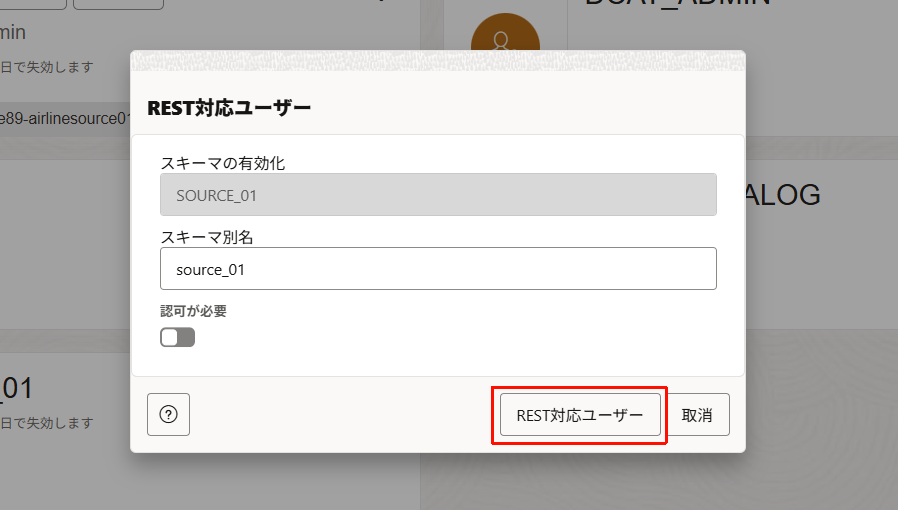
- 有効化後、Quota を Unlimited に変更します。
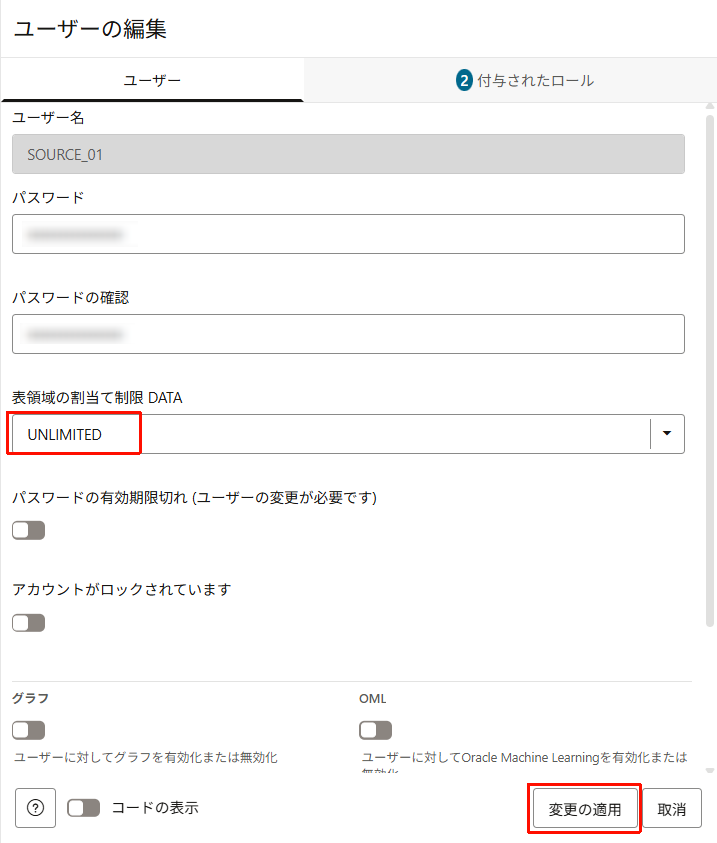
一つ前の手順によりsource_01スキーマに「RESTの有効化」が表示されていることを核にします。
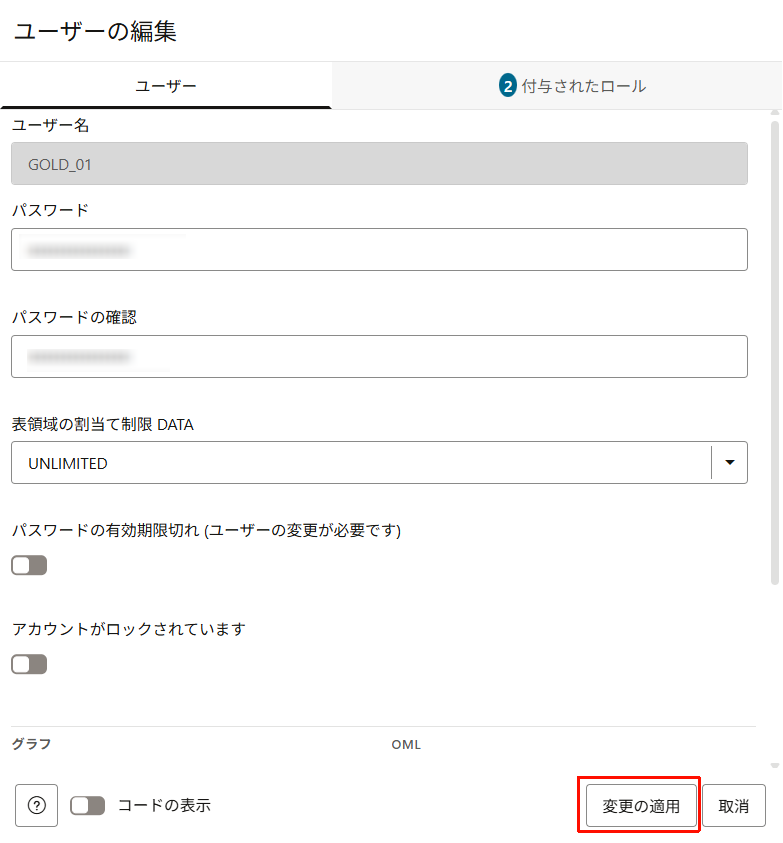
「︙」から「編集」をクリックします。

表領域の割り当て制限を「UNLIMITED」に変更します。
「変更の適用」をクリックします。
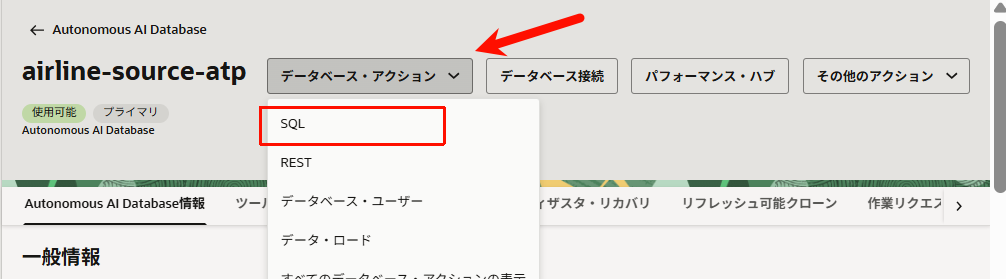
◻︎ Task 5: Source_01 スキーマとして SQL Developer にログイン
- Source_01ユーザーで正常にサインインできることを確認します。
ADBの詳細画面から「データベース・アクション」>「SQL」を開きます。
画面右上の 「ADMIN」 を選択し、「サインアウト」をクリックします。

ユーザー名に source_01 を指定し、前のタスクで設定したパスワードを入力し「サインイン」します。

Source_01ユーザーでログインできればOKです。

※もし上記の手順でログインできない場合は、「データベース・ユーザー」にadminユーザーでログインした上で、source_01ユーザーの以下に示したリンクへアクセスします。
◻︎ Task 6: Autonomous AI Lakehouse のプロビジョニング
- 「Oracle AI Database」>「Autonomous AI Database」をクリックします。

-
作成するリージョンとコンパートメントを確認し、「Autonomous AI Databaseの作成」をクリックします。
-
設定項目を以下のように入力していきます。「作成」をクリックして、構築を開始します。
- 表示名:任意(ここでは
aidp-db) - データベース名:任意(ここでは
aidpdb01) - ワークロード・タイプ:
レイクハウス - データベース・バージョン:
26ai -
Adminユーザーのパスワード:任意
- 表示名:任意(ここでは

- 数分後、作成できたことを確認します。
◻︎ Task 7: Gold_01 スキーマの作成
CREATE USER gold_01 IDENTIFIED BY "任意のパスワード";
-- データ操作に必要な基本権限
GRANT CONNECT, RESOURCE TO gold_01;
-- セッション接続、テーブル・ビューなど各種オブジェクトの作成を許可
GRANT CREATE SESSION TO gold_01;
GRANT CREATE TABLE TO gold_01;
GRANT CREATE VIEW TO gold_01;
GRANT CREATE SEQUENCE TO gold_01;
GRANT CREATE PROCEDURE TO gold_01;
GRANT UNLIMITED TABLESPACE TO gold_01;
-- DBMS_CLOUD パッケージの実行権限を付与
GRANT EXECUTE ON DBMS_CLOUD TO gold_01;
-- DATA_PUMP_DIR へのアクセス権限を付与(Spark の saveAsTable 処理で使用)
GRANT READ, WRITE ON DIRECTORY DATA_PUMP_DIR TO gold_01;
◻︎ Task 8: GOLD_01 スキーマに REST 機能を追加
Task 4と同様の手順で、「データベース・ユーザー」から「RESTの有効化」を行います。

さらにTask 4と同様の手順で、表領域の割り当て制限を「UNLIMITED」に変更します。
◻︎ Task 9: GOLD_01 スキーマとして SQL Developer にログイン
Task 5と同様の手順で、SQL Developer にログインできるか確認しておきます。
データベース・アクションに、Adminでログインされている状態からログアウトし、GOLD_01ユーザーとそのパスワードでログインします。
◻︎ Task 10: AI Data Platform インスタンスのプロビジョニング
-
「アナリティクスとAI」>「AIデータ・プラットフォーム・ワークベンチ」をクリックします。

-
「Create AI Data Platform Workbench」をクリックし作成を開始します。

- 設定項目を以下のように入力していきます。
- AI Data Platform Workbench name:
aidp-test - Workspace name:
aidp-workspace
- AI Data Platform Workbench name:

-
「Add policies」の項目でポリシーを追加します。
「ポリシーの追加」から以下のいずれかを選択します。今回は「Standard」を選択します。- Standard:テナント レベルでアクセス設定を広範囲に適用します。
- Advance:コンパートメント レベルできめ細かなアクセスを構成できます。
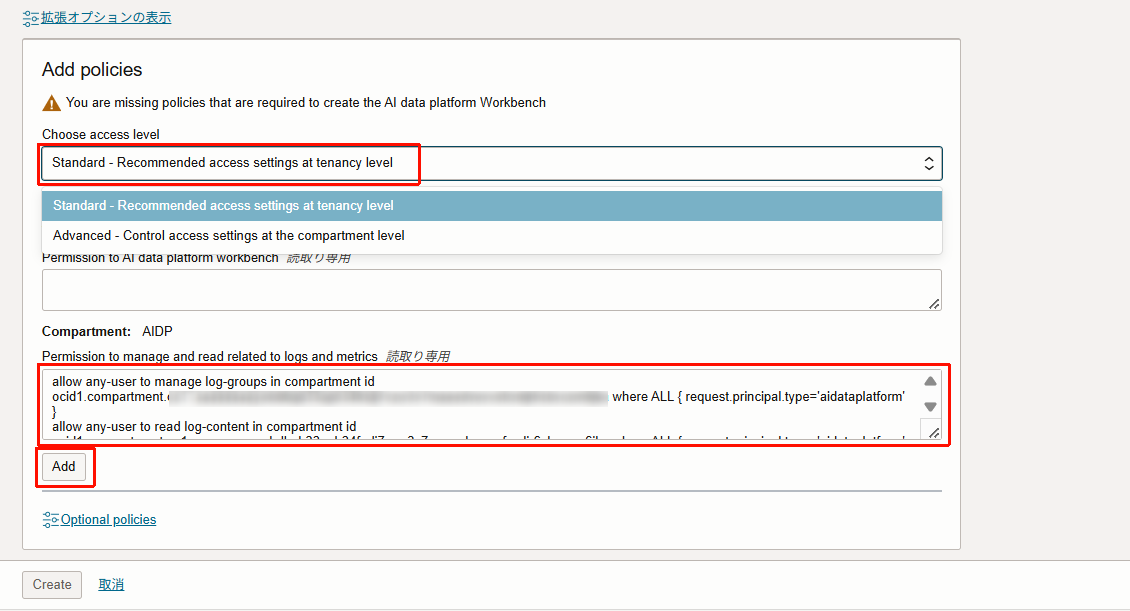
- 選択すると、不足しているポリシーがある場合は追加するべきポリシーが表示されます。ポリシーが不十分なままデプロイを開始すると、デプロイが失敗します。
「Add」をクリックし、ポリシーが追加されると「Policies added」と表示されます。

- 「Optinal policies」をクリックし追加で必要なポリシーを追加します。今回のハンズオンでは「
Enable object deletion」を追加します。

追加できました。

- 「Create」をクリックしてプロビジョニングを開始します。
数分後にインスタンスの作成が完了します。

◻︎ Task 11: Object Storage のセットアップ
- 「ストレージ」>「オブジェクト・ストレージとアーカイブ・ストレージ」から「バケット」を開きます。
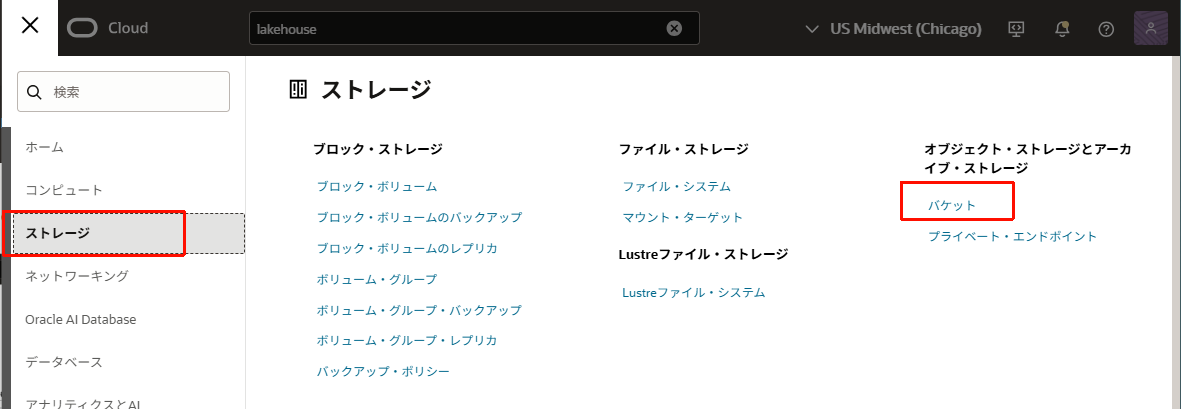
- 「バケットの作成」をクリックします。

- 以下を入力し、「バケットの作成」をクリックします。
- バケット名:任意(ここでは
aidp-demo-bucket_01) - その他の項目はデフォルト(デフォルト・ストレージ層は
標準)
- バケット名:任意(ここでは

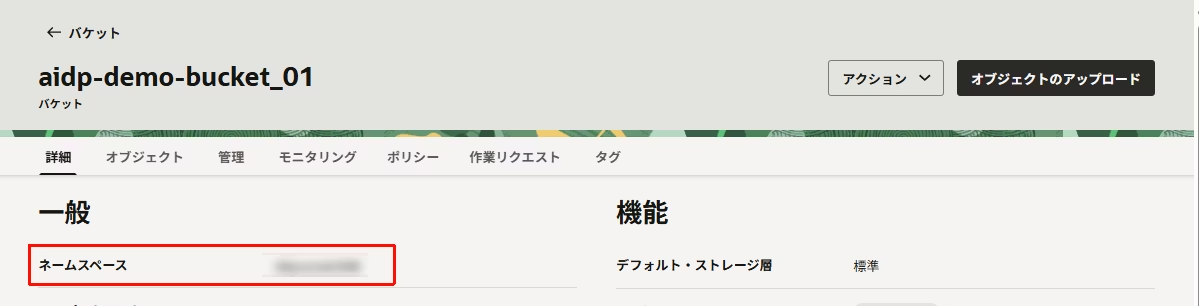
- 作成できたバケットをクリックします。

- ネームスペースを控えておきます。後程使用します。
- 「オブジェクト」>「アクション」から「新規フォルダの作成」をクリックします。

- フォルダ名を入力し、「フォルダの作成」をクリックします。
- 名前:
delta
- 名前:

Task 12: Oracle Analytics Cloud インスタンスのプロビジョニング
- 「アナリティクスとAI」>「アナリティクス・クラウド」をクリックします。

-
アナリティクス・インスタンスを構築します。「インスタンスの作成」をクリックします。

-
設定項目を確認して作成をクリックします。
- 名前:任意(ここでは
aidpoac01) - その他はデフォルトの設定でOK
- 名前:任意(ここでは

数分後にインスタンスの作成が完了します。(今回は約3分で構築されました。)
Step1は以上で終了です。必要なインフラの準備が整ったので、続いてStep2に進んで、ATP へのデータロードから、AI Data Platform と Lakehouse でのデータ抽出・処理を行います。
◼︎ Step 2:AI Data Platform と Lakehouse によるデータ処理・整備
Step2では、Step1で構築した環境を利用して、ATP にサンプルの航空会社データをロードし、トランザクションデータを Oracle AI Data Platform(AIDP) に取り込みます。
その後、Spark と Delta Lake を使用して、Bronze → Silver → Gold の各レイヤーでデータを段階的に加工・整備し、最終的に分析用に最適化された Gold データ をAutonomous AI Lakehouse に保管します。
実施内容
この章では、以下のタスクを行っていきます。
- サンプルの航空会社トランザクションデータを ATP にロードする
- AIDP を ATP(ソース)および AI Lakehouse に接続する
- ATP からデータを抽出し、AIDP の Bronze レイヤーに取り込む
- データのクレンジング・付加情報の付与・変換を行い、Silver/Gold レイヤーを作成する
- 整備された Gold データを AI Lakehouse の GOLD スキーマに公開する
◻︎ Task 1:ATP インスタンスの Source_01 スキーマにサンプル航空会社データをロード
Task 1-1
-
Step1で作成したATP データベース 「airline-source-atp」 のSQL Developer を開きます。

-
一度ログアウトして、
Source_01ユーザーでログインします。

-
AIRLINE_SAMPLEテーブルを作成します。
CREATE TABLE AIRLINE_SAMPLE (
FLIGHT_ID NUMBER,
AIRLINE VARCHAR2(20),
ORIGIN VARCHAR2(3),
DEST VARCHAR2(3),
DEP_DELAY NUMBER,
ARR_DELAY NUMBER,
DISTANCE NUMBER
);

Task 1-2
-
AIRLINE_SAMPLEテーブルにデータを格納します。
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1001, 'Skynet Airways', 'JFK', 'LAX', 10, 5, 2475);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1002, 'Sunwind Lines', 'ORD', 'SFO', -3, -5, 1846);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1003, 'BlueJet', 'ATL', 'SEA', 0, 15, 2182);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1004, 'Quantum Flyers', 'DFW', 'MIA', 5, 20, 1121);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1005, 'Nebula Express', 'BOS', 'DEN', 12, 8, 1754);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1006, 'Skynet Airways', 'SEA', 'ORD', -5, -2, 1721);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1007, 'Sunwind Lines', 'MIA', 'ATL', 7, 4, 595);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1008, 'BlueJet', 'SFO', 'BOS', 22, 18, 2704);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1009, 'Quantum Flyers', 'LAX', 'JFK', -1, 0, 2475);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1010, 'Nebula Express', 'DEN', 'DFW', 14, 20, 641);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1011, 'Skynet Airways', 'PHX', 'SEA', 3, -2, 1107);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1012, 'BlueJet', 'ORD', 'ATL', -7, -10, 606);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1013, 'Quantum Flyers', 'BOS', 'JFK', 9, 11, 187);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1014, 'Sunwind Lines', 'LAX', 'DFW', 13, 15, 1235);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1015, 'Nebula Express', 'SFO', 'SEA', 0, 3, 679);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1016, 'Skynet Airways', 'ATL', 'DEN', 6, 5, 1199);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1017, 'BlueJet', 'DFW', 'PHX', -2, 1, 868);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1018, 'Quantum Flyers', 'ORD', 'BOS', 8, -1, 867);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1019, 'Sunwind Lines', 'JFK', 'MIA', 10, 16, 1090);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1020, 'Nebula Express', 'DEN', 'ORD', -4, 0, 888);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1021, 'Skynet Airways', 'SEA', 'ATL', 16, 12, 2182);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1022, 'BlueJet', 'MIA', 'LAX', 5, 7, 2342);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1023, 'Quantum Flyers', 'DEN', 'BOS', 2, -2, 1754);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1024, 'Sunwind Lines', 'SFO', 'JFK', -6, -8, 2586);
INSERT INTO AIRLINE_SAMPLE (FLIGHT_ID, AIRLINE, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, DISTANCE) VALUES (1025, 'Nebula Express', 'ORD', 'MIA', 11, 13, 1197);

Task 1-3
- データが格納できたか確認します。
SELECT * FROM AIRLINE_SAMPLE;

◻︎ Task 2:AIDP を ATP(Source)に接続
Task 2-1, 2-2
- 作程作成したAIDPのインスタンス名の右のアイコンをクリックし、AIDPのコンソール画面を開きます。

Task 2-3
- AIDPのコンソールが開きました。

Task 2-4
- 左端のメニューバーの「Create」から「Catalog」をクリックします。
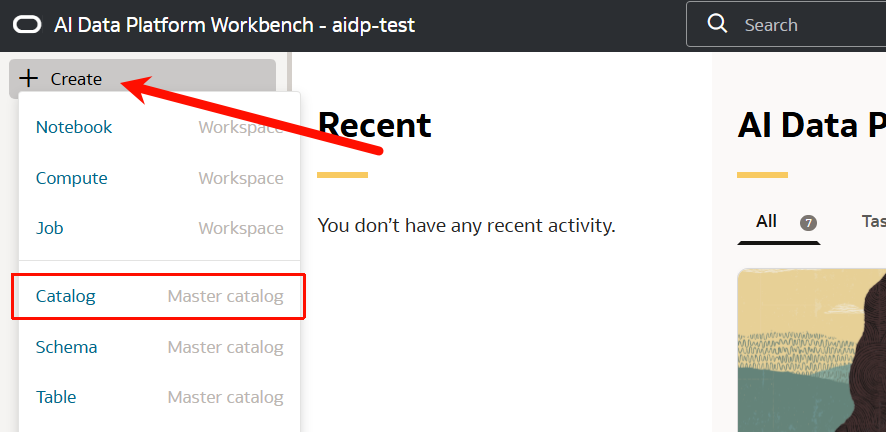
Task 2-5
- 以下の内容を入力・選択します。
- Catalog name:任意(ここでは
atp_external_catalog_01) - Catalog type:
External catalog - External source type:
Oracle Autonomous Transaction Processing
- Catalog name:任意(ここでは

Task 2-6 ~ 2-8
- External source method:
Choose ATP instance - Compartment:ATPを作成したコンパートメントを選択(ここでは
AIDP) - ATP instance:Step1で作成したATPインスタンス
airline-source-atp - Service:接続タイプを選択(ここでは
airlinesource01_medium)
Task 2-9

- Username:
source_01 - Password:設定したパスワード
Task 2-10
- ここまで入力した後、「Test Connection」をクリックし接続を確認します。

- 接続が成功すると、Connection stutus:が「Successuful」になりました。その後、「Create」をクリックします。

Task 2-11
- カタログの作成が開始します。

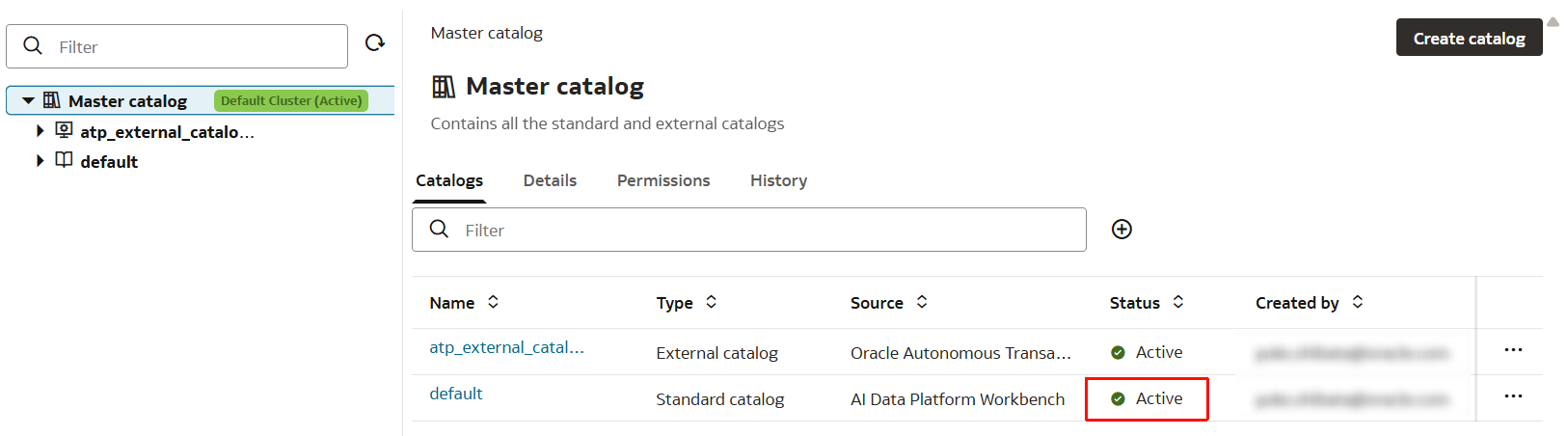
Task 2-12
- 数十秒待つと、Status が「Active」になりました。
Activeになったことを確認し、次のタスクに進みます。
◻︎ Task 3:AIDP のワークスペースとノートブックを起動
Task 3-1
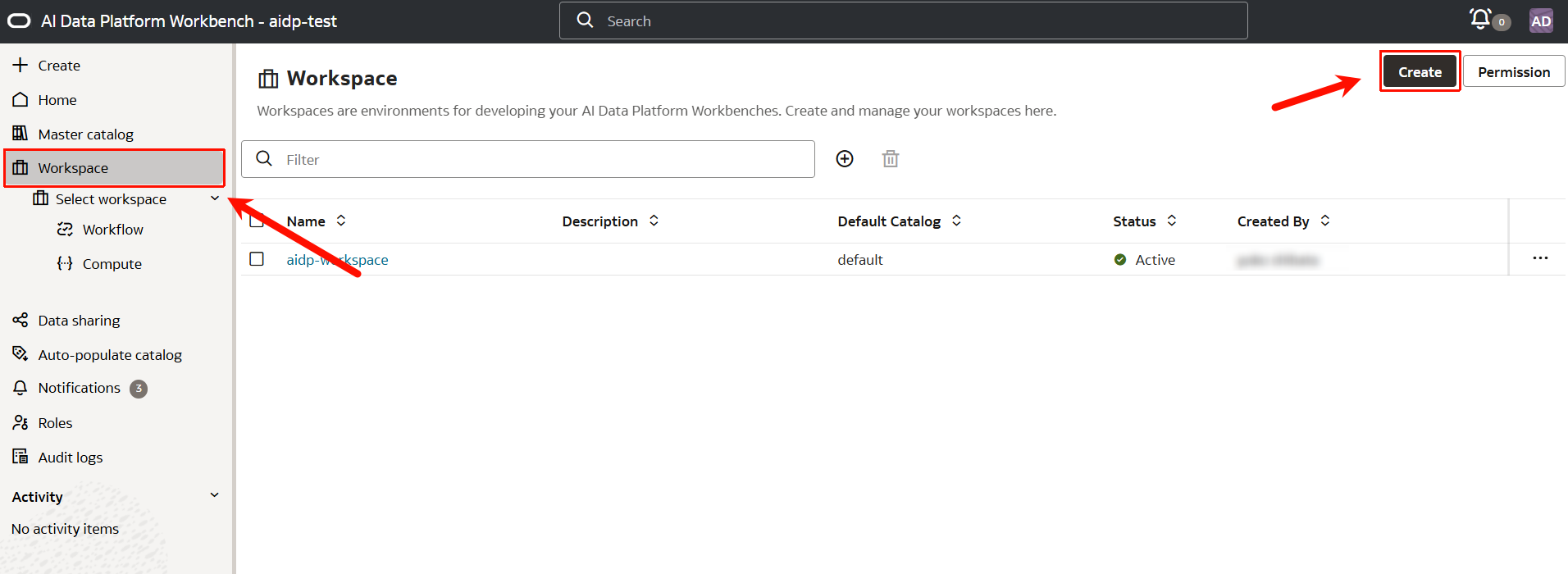
- AIDPコンソールで、新しいワークスペースを作成します。
左メニューバーから「Workspace」をクリックして、右上の「Create」をクリックします。
Task 3-2
- 以下の項目を入力し、「Create」をクリックします。
- Workspace name:任意(ここでは
airline-workspace_01) - Default catalog:Task 2で作成したカタログ
atp_external_catalog_01
- Workspace name:任意(ここでは

Task 3-3
- 作成が開始されます。
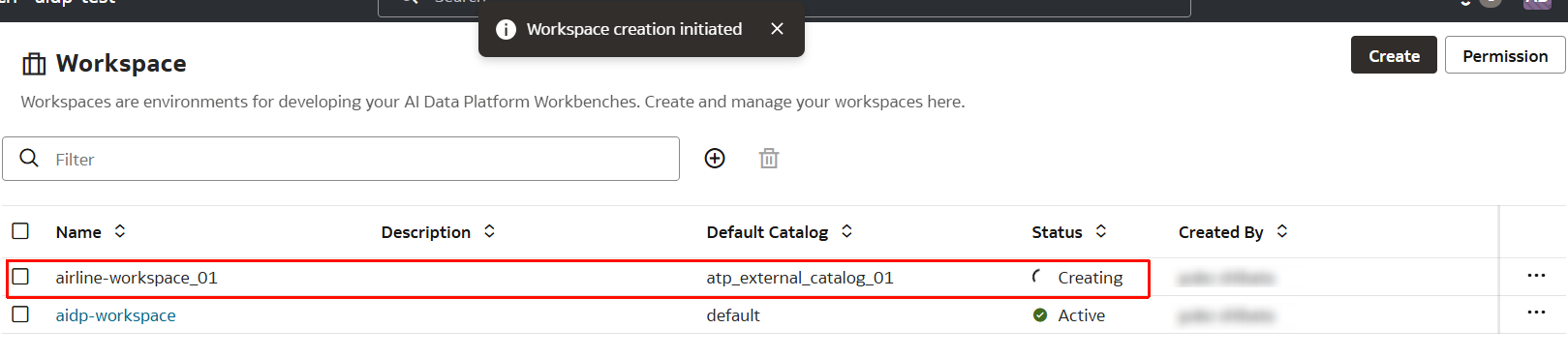
- ワークスペース
airline-workspace_01が作成されました。

- 作成されたワークスペース
airline-workspace_01をクリックします。
「+」マークから新規フォルダを作成します。

Task 3-4
- フォルダ名を
demoとし「Create」をクリックします。

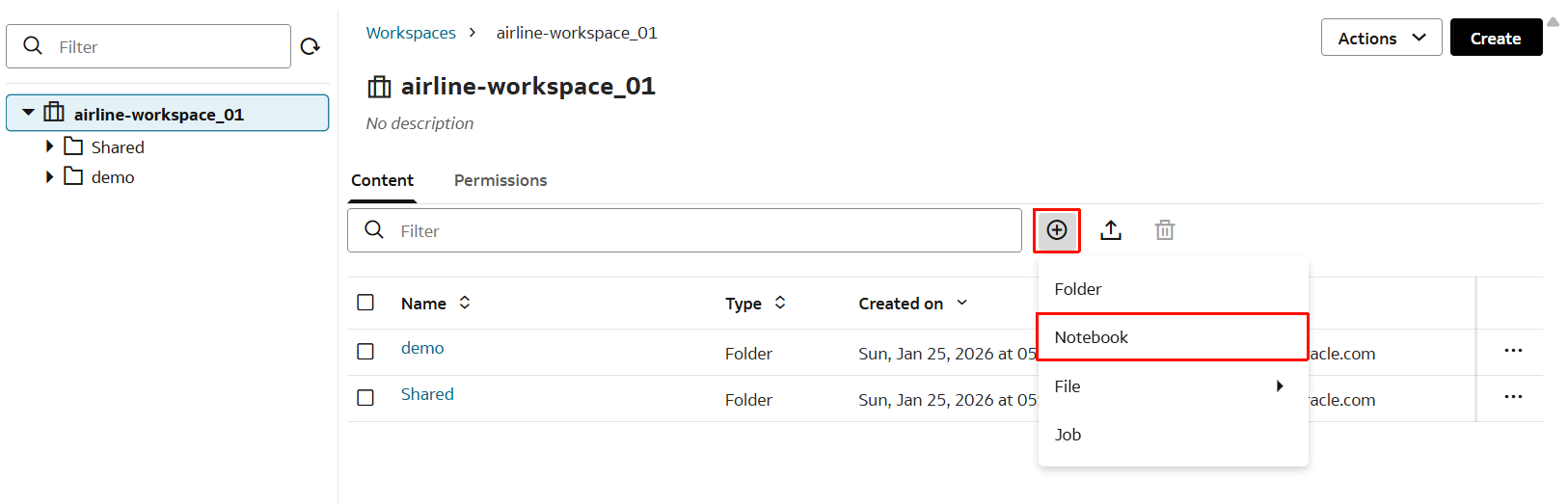
Task 3-5
- 続いてNotebookを作成します。「Notebook」をクリックします。
Task 3-6
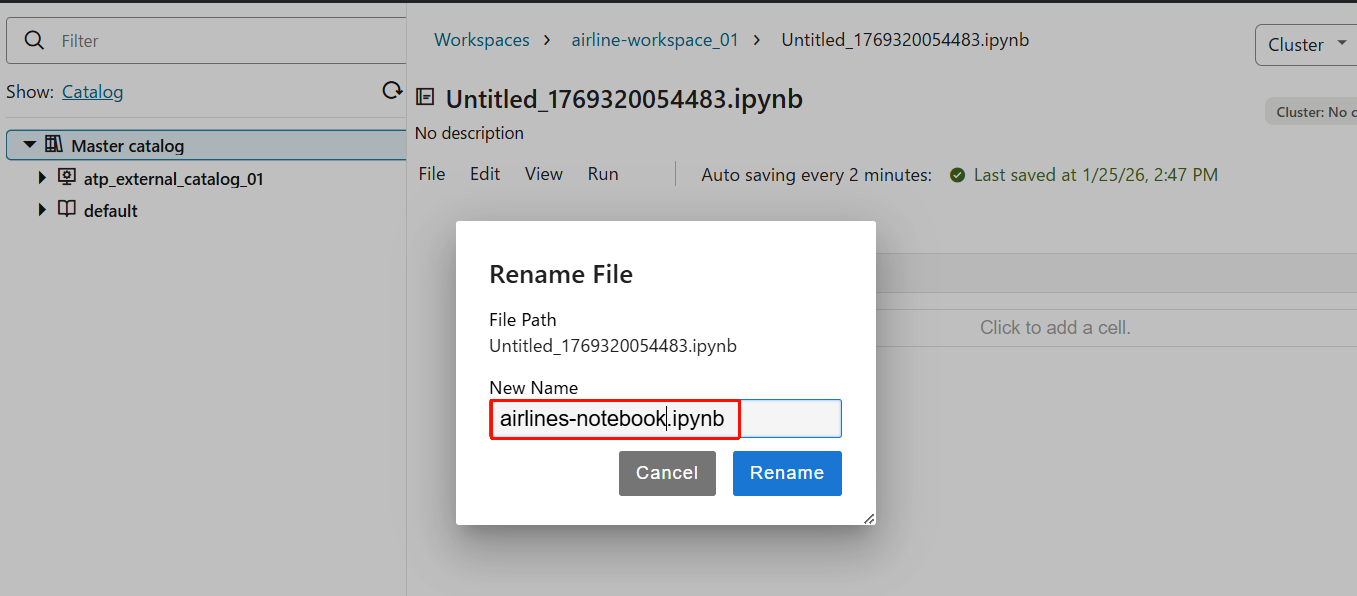
- 新規Notebookが作成されたので、ファイル名を分かりやすいように変更します。

- ファイル名を
airlines-notebook.ipynbとしておきます。
Task 3-7
- 「Cluster」>「Create cluster」をクリックします。

Task 3-8
- 以下を入力し、それ以外の項目はデフォルトのままで、「Create」をクリックします。
- Cluster name:
my_workspace_cluster_01
- Cluster name:

Task 3-9
- 約1分後にクラスターが作成されました。
Task 3-10
- 作成が完了すると、「Attach existing cluster」で作成したクラスターが見えるようになります。作成されたクラスターをクリックして、アタッチします。

Task 3-11
- アタッチが開始します。

Task 3-12
- アタッチが完了すると、
(Active)の表示に変わります。

◻︎ Task 4:ATP から Bronze レイヤーへデータを抽出
Task 4-1
-
airlines-notebookに以下のコードを貼り付けます。また、言語が Python に選択されていることを確認してください。
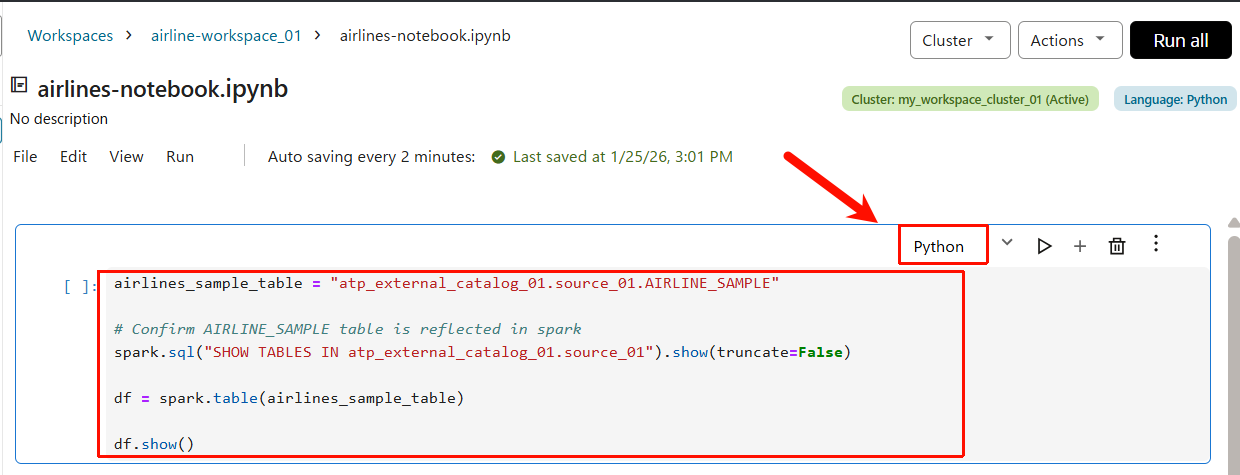
airlines_sample_table = "atp_external_catalog_01.source_01.AIRLINE_SAMPLE"
# Confirm AIRLINE_SAMPLE table is reflected in spark
spark.sql("SHOW TABLES IN atp_external_catalog_01.source_01").show(truncate=False)
df = spark.table(airlines_sample_table)
df.show()
こちらのプログラムで実行している内容は以下のとおりです。
| 内容 | |
|---|---|
| 1 | 読み込みたいテーブル名(完全修飾名)を文字列で用意する。AIDP(Spark)から参照する ATP 側のテーブルを指定する。 |
| 2 | Spark SQL を使って、Spark から見えるテーブル一覧を表示して、反映されているか確認する。AIRLINE_SAMPLE が一覧に出ればOK(ATP との接続・カタログ設定が正しく反映されている。 |
| 3 | ATP のテーブルを DataFrame(df)として読み込み。 |
| 4 | df の先頭の数行を表示し、読み込んだデータの中身を確認する。ATP → External Catalog → Spark(AIDP) の読み取りが成功していることが確認できる。 |
-
その後、Run ボタンをクリックして実行します。
-
結果が出力されました。

-
正しく実行出来ている場合は、以下のような結果になります。

Task 4-2
- 新しいセルに次のコードブロックを作成するため、「+」アイコンをクリックします。

- 以下のコードを貼り付け、実行します。
- Step1で作成したObject Storage バケットに新しいDataFrameを書き込みます。先程作成した、
aidp-demo-bucket_01を指定します。 - Step 1 - Task 11で確認した、ご自身のネームスペース名に書き換えたうえで実行します
- Step1で作成したObject Storage バケットに新しいDataFrameを書き込みます。先程作成した、
delta_path = "oci://aidp-demo-bucket_01@オブジェクトストレージのネームスペース名/delta/airline_sample"
df.write.format("delta").mode("overwrite").save(delta_path)

このコードを実行することで、Object Storage の aidp-demo-bucket_01 バケットのdelta/airline_sample配下に新しいフォルダ構成が作られます。その中にATP から読み込んだデータが、Spark によって Delta Lake 形式で Object Storage に保存され、次の分析・変換処理で使える状態になります。
- 正しく実行されると、以下のような結果になります。
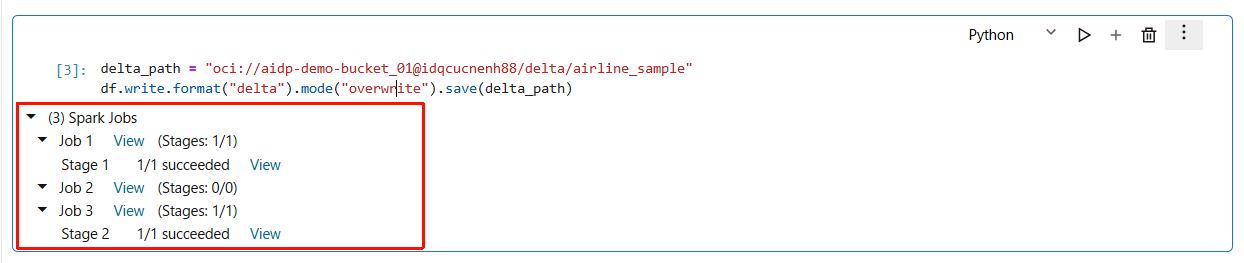
- Step 1 で作成した Object Storage バケット内を確認します。
delta/配下に次のようなファイル/フォルダ構成が作成されているはずです。

注: 1つの Delta パス(delta path)には、1つのテーブルしか紐付けられません。すでに別のテーブルに紐付いているパスに対して新しくテーブルを作成しようとすると、エラーになります。その場合は、紐付いている既存テーブルを削除したうえで、DataFrame をそのパスに 書き込み直す必要があります。
Task 4-3
- さらに新しいセルに次のコードブロックを作成するため、「+」アイコンをクリックします。
ここでは、メダリオンアーキテクチャの 第1段階(Bronze) として、Bronze テーブルを作成します。以前作成した外部カタログ(External Catalog)とは別に、新しい (標準)カタログ を作成します。カタログ名は airlines_data_catalog_01 とします。
airlines_data_catalog_01 は、メダリオンアーキテクチャの Bronze / Silver / Gold 各レイヤーのデータを保存するために使用します。
- 以下のコードブロックを貼り付け、実行します。
bronze_table = "airlines_data_catalog_01.bronze.airline_sample_delta"
# Create New Internal Catalog & Schema to store data
spark.sql("CREATE CATALOG IF NOT EXISTS airlines_data_catalog_01")
spark.sql("CREATE SCHEMA IF NOT EXISTS airlines_data_catalog_01.bronze")
# Drop the table if it exists, to avoid conflicts
spark.sql(f"DROP TABLE IF EXISTS {bronze_table}")
# Create new bronze table
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {bronze_table}
USING DELTA
LOCATION '{delta_path}'
""")
こちらのプログラムでは、Object Storage に保存した Delta データを「Bronze テーブル」として Spark(AIDP)に登録する処理をしています。
| 内容 | |
|---|---|
| 1 | 作成する Bronze テーブル名を定義する。 |
| 2 | Spark にairlines_data_catalog_01 という内部カタログ(標準カタログ) を作成する。これは External Catalog(ATP 用)とは別物 で、Bronze / Silver / Gold を管理するためのカタログ。 |
| 3 | Bronze レイヤー用スキーマを作成。メダリオンアーキテクチャの「生に近いデータを置く領域」 に相当する。 |
| 4 | 既存の Bronze テーブルがあれば削除 |
| 5 | Delta データを参照する Bronze テーブルを作成 |
- 正しく実行できている場合、以下のような出力となります。

Task 4-4
- さらに新しいセルに次のコードブロックを作成するため、「+」アイコンをクリックします。
以下のコードを使用し、データのクレンジングを行います。
Bronze テーブルに格納されているデータを確認し、「不正なレコード」 を削除します。これにより、後続の Silver / Gold レイヤーでは距離が正しいデータだけを扱えるようになります
spark.sql(f"""
DELETE FROM {bronze_table}
WHERE DISTANCE IS NULL OR DISTANCE < 0
""")
| 内容 | |
|---|---|
| 1 | 条件に一致する行が Bronze テーブルから削除される ◦ DISTANCE IS NULL → 距離データが入っていない(欠損している)レコード ◦ DISTANCE < 0 → 距離がマイナスになっている、業務的に不正なレコード 複雑な変換や集計はまだ行わず、「明らかに使えないデータを除外する」ステップ |
※Delta Lake 形式のためデータは物理的に即座に消えるのではなく、削除トランザクションとして記録されます。
- コードブロックを貼り付け、Run ボタンをクリックして実行します。

- 正しく実行されると、以下のような出力となります。

Task 4-5
- さらに新しいセルに次のコードブロックを作成するため、「+」アイコンをクリックします。
以下のコードを貼り付けます。
df_v0 = spark.read.format("delta").option("versionAsOf", 0).load(delta_path)
df_v0.show()
ここでは、Delta テーブルの バージョニング機能 を確認します。
Delta Lake の機能により、テーブルが更新される前の 過去バージョンのデータ を参照することができます。これにより、万が一データを壊してしまっても、元に戻せることを確認します。
このコードを実行して、前ステップで行った処理(距離(distance)が NULL、または 0 未満のレコードを削除)の前の状態であるバージョン 0 のデータを参照します。
- 実行します。

- 正しく実行されると、次のような結果が表示されます。

◻︎ Task 5:Silver メダリオンスキーマを作成し、Generative AI を用いてデータを拡張
次のステップです。
前タスクでBronze レイヤーの準備が整ったので、ここからメダリオンアーキテクチャの Silver レイヤー にデータを書き込み、データのエンリッチ(拡張)処理 を行っていきます。
Task 5-1
Bronze レイヤーでクレンジング済みのデータを Silver レイヤーとして確定・登録する処理を行います。
- 新しいセルに次のコードブロックを入力するため、「+」アイコンをクリックします。以下のコードを新しいセルに貼り付けます。
- Step1 - Task5で確認したObject Storage のネームスペース名に置き換えて、実行します。
df_clean = spark.table(bronze_table)
silver_path = "oci://aidp-demo-bucket_01@オブジェクトストレージのネームスペース名/delta/silver/airline_sample"
silver_table = "airlines_data_catalog_01.silver.airline_sample_delta"
# データを保存するための Silver スキーマを作成
spark.sql("CREATE SCHEMA IF NOT EXISTS airlines_data_catalog_01.silver")
# クレンジング済みの DataFrame を Delta 形式で Object Storage に書き込む
df_clean.write.format("delta").mode("overwrite").save(silver_path)
# 既にテーブル定義が存在する場合は削除して競合を防ぐ
spark.sql(f"DROP TABLE IF EXISTS {silver_table}")
# クレンジング済みデータを新しい Silver テーブルとして登録
spark.sql(f"""
CREATE TABLE {silver_table}
USING DELTA
LOCATION '{silver_path}'
""")
# データが正しくクレンジングされているか確認
spark.sql(f"SELECT * FROM {silver_table}").show()
- 正しく実行されると、以下のような結果が出力されます。
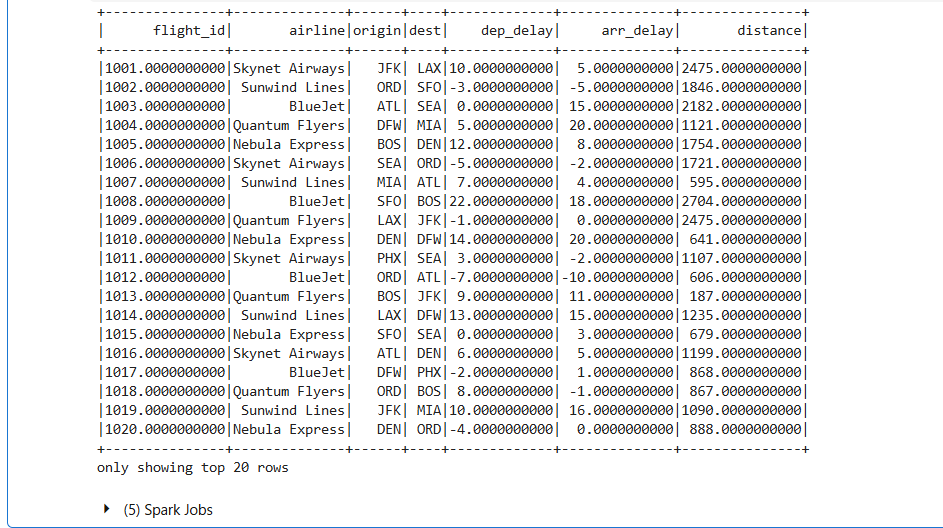
- コードが正しく実行されていれば、Step 1 で作成した Object Storage バケット内に、以下のような構成が確認できます。

Task 5-2
Silver レイヤーの明細データに「航空会社ごとの平均値」を付与して、データをエンリッチ(拡張) する処理をしています。
- 新しいセルに次のコードブロックを入力するため、「+」アイコンをクリックします。以下のコードを新しいセルに貼り付けます。
# Enrich data by adding aggregates/average delays and distance
from pyspark.sql import functions as F
df = spark.table("airlines_data_catalog_01.silver.airline_sample_delta")
# Calculate averages by airline
avg_df = df.groupBy("AIRLINE").agg(
F.avg("DEP_DELAY").alias("AVG_DEP_DELAY"),
F.avg("ARR_DELAY").alias("AVG_ARR_DELAY"),
F.avg("DISTANCE").alias("AVG_DISTANCE")
)
# Join with the detail table
enhanced_df = df.join(avg_df, on="AIRLINE", how="left")
enhanced_df.show()
こちらのプログラムでは、Silver テーブルの明細データを読み込み、航空会社(AIRLINE)ごとに
- 平均出発遅延
- 平均到着遅延
- 平均飛行距離
を計算、その平均値を 各フライト行に付け足すという処理を行っています。
| 内容 | |
|---|---|
| 1 | Spark SQL の集計関数を使う準備。Spark の標準的な集計・計算関数を .avg() のように使えるようにする。 |
| 2 | Silver レイヤーのテーブルを DataFrame として読み込む。 |
| 3 | AIRLINE 列でグループ化。各航空会社ごとに以下を算出。 ◦ 出発遅延の平均(AVG_DEP_DELAY) ◦ 到着遅延の平均(AVG_ARR_DELAY) ◦ 飛行距離の平均(AVG_DISTANCE) |
| 4 | 明細データに平均値を結合(JOIN)。元の明細データ(df)に航空会社ごとの平均値(avg_df)を、AIRLINE をキーに LEFT JOIN。各フライト行に「その航空会社の平均遅延・平均距離」が追加される。 |
| 5 | 結果を表示して確認。エンリッチされたデータの先頭行を表示します。 |
- 正しく実行されると、以下のような結果が出力されます。
新しい列(AVG_DEP_DELAY / AVG_ARR_DELAY / AVG_DISTANCE)が追加されていることが確認できます。
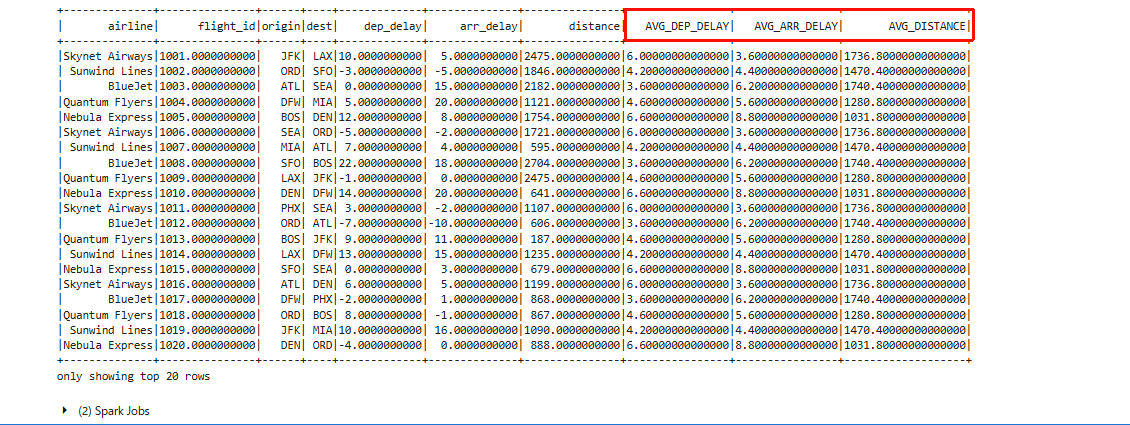
Task 5-3
各フライト行に「レビュー文」をランダムに付与して、感情分析(Sentiment Analysis)の準備をするための処理です。
- 新しいセルに次のコードブロックを入力するため、「+」アイコンをクリックします。以下のコードを新しいセルに貼り付けます。
各フライト行にポジティブ/ネガティブが混ざった短い「レビュー文」をランダムに付与して、この後行う感情分析(Sentiment Analysis)に使用するテキスト列を疑似的に作成しています。
# Add New Review Column for Sentiment Analysis
import random
sample_reviews = [
"The flight was on time and comfortable.",
"Long delay and unfriendly staff.",
"Quick boarding and smooth flight.",
"Lost my luggage, not happy.",
"Great service and tasty snacks."
]
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
random_review_udf = udf(lambda: random.choice(sample_reviews), StringType())
df_with_review = enhanced_df.withColumn("REVIEW", random_review_udf())
df_with_review.show()
以下のような流れで実行されます。
| 内容 | |
|---|---|
| 1 | 感情分析用のレビュー文サンプルを用意。 |
| 2 | Spark の UDF(ユーザー定義関数) を使うための import。UDF を使うことで、Python の関数をSpark の DataFrame 処理として実行できる。 |
| 3 |
sample_reviews の中からランダムに1つの文章を選んで返す関数を定義。この UDF は 各行ごとに実行される。 |
| 4 | 既存の enhanced_df に REVIEW 列を追加。各行には、前項で定義した UDF が実行され、ランダムなレビュー文が入る。 |
| 5 | 結果を表示して確認。 |
- 正しく実行されると、以下のような結果が出力されます。
REVIEW列が追加され、各行にレビュー文が入力されています。

Task 5-4*
AIDP(Spark)から LLM(xai.grok-4)を呼び出して、①モデル疎通確認 → ②レビュー文の感情分析を実行します。
- 新しいセルに次のコードブロックを入力するため、「+」アイコンをクリックします。以下のコードを新しいセルに貼り付けます。
まず以下のコードを実行して、LLMモデル(xai.grok-4)が利用できるかをテストします。
# test model
spark.sql("select query_model('xai.grok-4','OCIで提供されているExaDB-Dとは?') as questions").show(truncate=False)
- 以下のような結果が返ってきました。ちゃんと機能していますね。

AIDP では、利用できる生成AIモデルがAIDPインスタンスが作成されているリージョンに依存します。対応モデルは随時アップデートされるため、利用時点の最新情報をご確認ください。
- 続いて、先程追加したフライトレビュー(REVIEW 列)のデータを LLM に渡し、各行ごとに 感情分析(SENTIMENT)結果を生成します。さらに、その結果を新しい列(
SENTIMENT列)としてデータに追加します。
from pyspark.sql.functions import expr, from_json, col, regexp_replace
# --- 1. 出力構造の定義 ---
# LLMから返却されるJSONのキーと型を定義
json_schema = "label STRING, reason STRING"
# --- 2. プロンプトの構築 ---
# 感情(label)と理由(reason)をJSON形式で一括取得するための指示文
prompt_cmd = """
concat(
'Review: ', REVIEW,
'. Analyze the sentiment and briefly explain the reason. ',
'Return your response ONLY as a JSON object with keys "label" (Positive/Negative/Neutral) and "reason".'
)
"""
# --- 3. 分析パイプラインの実行 ---
enhanced_df = (
df_with_review
# A. LLMモデル(xai.grok-4)への問い合わせ実行
.withColumn("raw_output", expr(f"query_model('xai.grok-4', {prompt_cmd})"))
# B. レスポンスのクレンジング
# パースエラーを防ぐため、LLMが混入させることのあるマークダウン記号(```json)や改行を除去
.withColumn("cleaned_json", regexp_replace(col("raw_output"), r"(^```json|```$|\n)", ""))
# C. JSONパース
# 文字列を構造化データ(Struct型)に変換
.withColumn("parsed", from_json(col("cleaned_json"), json_schema))
# D. カラムの展開
# 構造体から「ラベル」と「理由」を個別のカラムとして抽出
.withColumn("SENTIMENT_LABEL", col("parsed.label"))
.withColumn("SENTIMENT_REASON", col("parsed.reason"))
)
# --- 4. 結果の確認 ---
# 必要なカラムのみを選択して表示
enhanced_df.select("REVIEW", "SENTIMENT_LABEL", "SENTIMENT_REASON").show(10, False)
以下のような流れで実行されます。
| 内容 | |
|---|---|
| 1 | LLMから返却されるJSONの項目(label と reason)とそのデータ型をあらかじめ定義し、Sparkが解釈できるように準備。 |
| 2 | LLMへのリクエスト実行。 ◦ REVIEW 列の内容をもとに、プロンプトを動的に生成。◦ 「ラベルと理由をセットでJSON形式で回答せよ」と指示しLLMを呼び出す。 |
| 3 | レスポンスのクレンジング ◦ regexp_replace を使用し、パース失敗の原因となる「マークダウンの囲み記号(```json)」や改行コードを機械的に除去。◦ from_json 関数により、文字列を構造化データ(Struct型)に変換。◦ 変換したデータから SENTIMENT_LABEL列(結論)とSENTIMENT_REASON列(根拠)を個別の列として抽出・追加。 |
| 4 | 元のレビュー文と新たに生成された「ラベル」「理由」の結果を並べてを表示。 |
- 以下のような結果が返ってきました。出力結果はLLMモデルにより変化します。

1レコードの中身を確認してみます。
+---------------------------------+---------------+-------------------------------------------------------------------------------------------------------------+
|REVIEW |SENTIMENT_LABEL|SENTIMENT_REASON |
+---------------------------------+---------------+-------------------------------------------------------------------------------------------------------------+
|Great service and tasty snacks. |Positive |The review uses positive words like 'Great' to describe the service and 'tasty' for the snacks, indicating overall satisfaction.|
SENTIMENT_LABEL列には、Positive、SENTIMENT_REASON列には、以下のような分析結果が記述されています。
サービスに対して『Great』、軽食に対して『tasty』などの前向きな言葉が使われており、利用者が全体的に好印象を持っていることがうかがえるレビューです。
ちょっと長かったですが、Task 5はここで終了です。
◻︎ Task 6:AIDP を Autonomous AI Lakehouse に接続
Task 6-1
- AIDPのコンソールから、「Create」>「Catalog」をクリックします。
- 次のように入力します。
- Catalog name:
airlines_external_adb_gold_01 - Catalog type:
External catalog - External source type:
Oracle Autonomous Data Warehouse
- Catalog name:

- 次のように入力します。入力出来たら「Test connection」で接続を確認します。
- External source method:
Choose ADW instance - リージョン:任意(ここでは
us-chicago-1) - コンパートメント:任意(ここでは
AIDP) - ADW instance:Step1で作成したADW
aidp-dbを選択 - Service:
aidpdb01_medium - Username:
gold_01 - Password:Step1で指定したパスワード
- External source method:
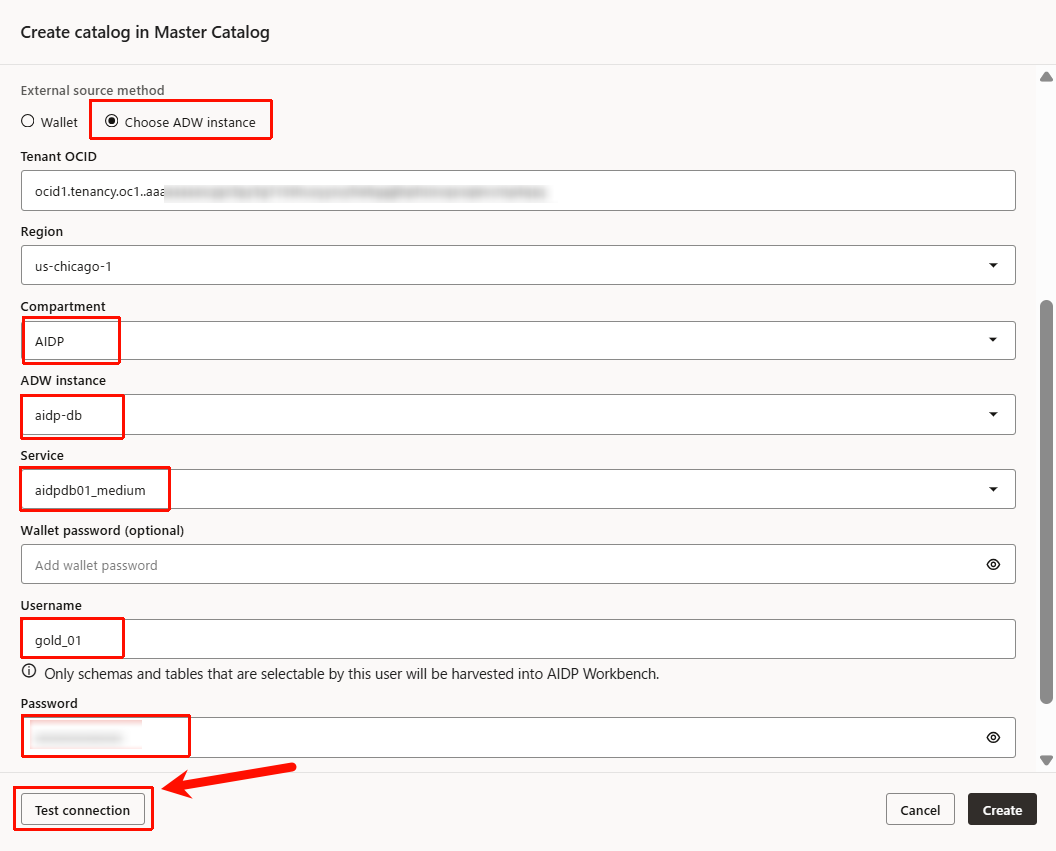
- 接続に成功したことを確認して、「Create」をクリックします。
- カタログが作成されました。

◻︎ Task 7:エンリッチしたデータを Gold スキーマへ書き込み
Task 7-1
- Notebookに戻ります。ワークスペース
airline-workspace_01をクリックし、airline-notebook.ipynbを開きます。

Task 7-2
前タスクでSilver レイヤーの準備が整ったので、次のコードブロックでは エンリッチされたデータを書き込みます。
まず最初に Gold スキーマを作成し、平均値などを含む集計済みデータを Gold スキーマに保存します。
- 「+」アイコンをクリックし新しいセルを開きます。以下のコードを新しいセルに貼り付けます。オブジェクトストレージのネームスペース名はご自身のネームスペースに置き換えたうえで、コードを実行します。
# Save Averaged Data to Gold Schema
gold_path = "oci://aidp-demo-bucket_01@オブジェクトストレージのネームスペース名/delta/gold/airline_sample_avg"
gold_table = "airlines_data_catalog_01.gold.airline_sample_avg"
# Create Gold Schema
spark.sql("CREATE SCHEMA IF NOT EXISTS airlines_data_catalog_01.gold")
enhanced_df.write.format("delta").option("mergeSchema", "true").mode("overwrite").save(gold_path)
spark.sql(f"DROP TABLE IF EXISTS {gold_table}")
spark.sql(f"""
CREATE TABLE {gold_table}
USING DELTA
LOCATION '{gold_path}'
""")
df_gold = spark.table(gold_table)
df_gold.show()
以下のような流れで実行されます。
| 内容 | |
|---|---|
| 1 | Gold レイヤーの保存先とテーブル名の定義。 ◦ gold_path = Object Storage 上の Delta テーブルの実体が置かれる場所 ◦ Spark / Lakehouse の 論理的なテーブル名 |
| 2 | Gold スキーマの作成。 ◦ カタログ airlines_data_catalog_01 の中にgold スキーマを作成 |
| 3 | 集計・エンリッチ済みのDataFrame を Delta 形式で Object Storage に書き込み。 |
| 4 | 既存テーブル定義の削除。 |
- 正しく実行されると、以下のような結果が出力されます。

バケットの中にも以下のようにファイル構造が作成されていることが確認できます。

Task 7-3
すべての列名を大文字(UPPER CASE)に変換します。
これは、Oracle Analytics Cloud(OAC) では列名が大文字でないと可視化時にエラーが発生するためこの処理を実行しておきます。
- 「+」アイコンをクリックし新しいセルを開きます。以下のコードを新しいセルに貼り付けます。
# Before pushing dataframe, make sure all columns are upper case to prevent visualization issues in OAC
# (OAC needs all columns capitalized in order to analyze data)
for col_name in df_gold.columns:
df_gold = df_gold.withColumnRenamed(col_name, col_name.upper())
df_gold.show()
- 正しく実行されると、以下のような結果が出力されます。

元々小文字だった列名も含め、すべての列名が 大文字(UPPER CASE) になっていることが確認できます。

Task 7-4
Spark の DataFrame を、AI Lakehouse(Oracle DB)に入れられる形に成型します。
これは、型・順序・列名を一致させてOracle DBにデータを渡すために行います。
OAC 連携や本番投入前の 最後の整形ステップ です。
- 「+」アイコンをクリックし新しいセルを開きます。以下のコードを新しいセルに貼り付け、実行します。
from pyspark.sql.functions import col
from pyspark.sql.types import DecimalType, StringType
# Oracleテーブルの型定義に合わせたキャスト処理
df_gold_typed = (
df_gold
# 数値列のキャスト (OracleのNUMBER型に対応)
.withColumn("FLIGHT_ID", col("FLIGHT_ID").cast(DecimalType(38,10)))
.withColumn("DEP_DELAY", col("DEP_DELAY").cast(DecimalType(38,10)))
.withColumn("ARR_DELAY", col("ARR_DELAY").cast(DecimalType(38,10)))
.withColumn("DISTANCE", col("DISTANCE").cast(DecimalType(38,10)))
.withColumn("AVG_DEP_DELAY", col("AVG_DEP_DELAY").cast(DecimalType(38,10)))
.withColumn("AVG_ARR_DELAY", col("AVG_ARR_DELAY").cast(DecimalType(38,10)))
.withColumn("AVG_DISTANCE", col("AVG_DISTANCE").cast(DecimalType(38,10)))
# テキスト列のキャスト (OracleのVARCHAR2型に対応)
.withColumn("AIRLINE", col("AIRLINE").cast(StringType()))
.withColumn("ORIGIN", col("ORIGIN").cast(StringType()))
.withColumn("DEST", col("DEST").cast(StringType()))
.withColumn("REVIEW", col("REVIEW").cast(StringType()))
# 【修正箇所】SENTIMENTを削除し、ラベルと理由を追加
.withColumn("SENTIMENT_LABEL", col("SENTIMENT_LABEL").cast(StringType()))
.withColumn("SENTIMENT_REASON", col("SENTIMENT_REASON").cast(StringType()))
)
# Oracleテーブルの定義順に合わせてカラムリストを更新
col_order = [
"FLIGHT_ID", "AIRLINE", "ORIGIN", "DEST", "DEP_DELAY", "ARR_DELAY", "DISTANCE",
"AVG_DEP_DELAY", "AVG_ARR_DELAY", "AVG_DISTANCE", "REVIEW",
"SENTIMENT_LABEL", "SENTIMENT_REASON"
]
# カラムの選択と順序整理
df_gold_typed = df_gold_typed.select(col_order)
# スキーマの最終確認
print(df_gold_typed.printSchema())
# Spark SQL用の一時ビューとして登録
df_gold_typed.createOrReplaceTempView("df_gold")
以下のような流れで実行されます。
| 内容 | |
|---|---|
| 1 | データ型を Oracle の NUMBER 型 と正確に対応させるため、数値列を DECIMAL 型、文字列を STRING 型(VARCHAR2)に変換。 |
| 2 | Oracle テーブルの定義順とSpark DataFrame の列順を一致させる。INSERT INTO を安全に実行するための準備。 |
| 3 | 最終的な列名・型を確認し、Oracle テーブルと一致しているかをチェック。 |
| 4 |
df_gold という 一時ビューとして登録し、SQL で扱えるようになる。 |
- 正しく実行されると、以下のような結果が出力されます。

◻︎ Task 8:Gold テーブルの作成とデータの投入
Task 8-1
- OCIコンソールから、「Autonomous AI Database」>「aidp-db」(レイクハウス)を開きます。
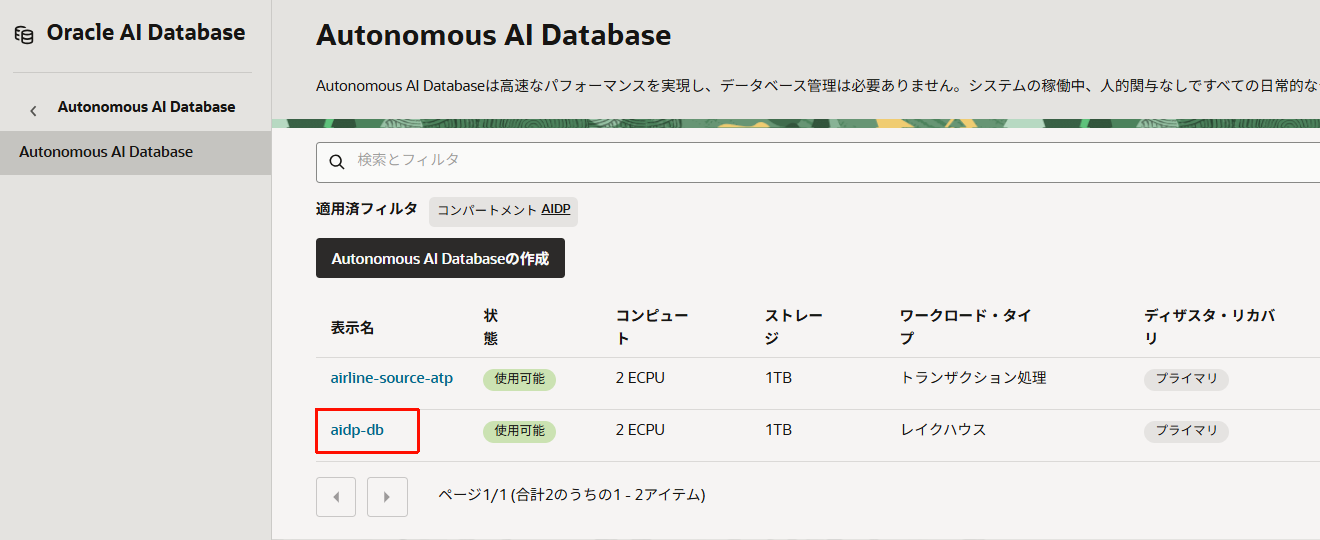
-
gold_01ユーザーでデータベース・アクションのSQLを開きます。

- 以下のコマンドを実行し、
AIRLINE_SAMPLE_GOLDテーブルを作成します。
CREATE TABLE AIRLINE_SAMPLE_GOLD (
FLIGHT_ID NUMBER,
AIRLINE VARCHAR2(20),
ORIGIN VARCHAR2(3),
DEST VARCHAR2(3),
DEP_DELAY NUMBER,
ARR_DELAY NUMBER,
DISTANCE NUMBER,
AVG_DEP_DELAY NUMBER,
AVG_ARR_DELAY NUMBER,
AVG_DISTANCE NUMBER,
REVIEW VARCHAR2(4000),
SENTIMENT_LABEL VARCHAR2(20),
SENTIMENT_REASON VARCHAR2(4000)
);
-
AIRLINE_SAMPLE_GOLDテーブルが作成されました。

Task 8-2
- AIDPのコンソールの「Master Catalog」>「airlines_external_adb_gold_01」を一度クリックし、その後右側のアイコンからExternal Catalogをリフレッシュします。

- 先程作成した
AIRLINE_SAMPLE_GOLDテーブルが表示されました。(表示されない場合、ブラウザのリフレッシュを行った後再度External Catalogをリフレッシュします。)

- カラムを確認することができます。

Task 8-3
Autonomous AI Lakehouse aidp-db 内の、airline_sample_goldテーブルにデータを挿入します。
-
Notebookに戻ります。ワークスペース
airline-workspace_01をクリックし、airline-notebook.ipynbを開きます。 -
「+」アイコンをクリックし新しいセルを開きます。以下のコードを新しいセルに貼り付けます。言語を「SQL」に指定して実行します。
%sql
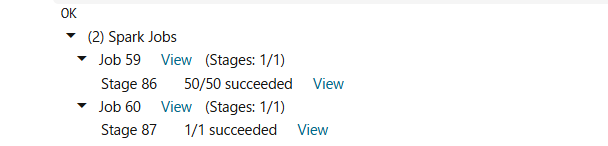
INSERT into airlines_external_adb_gold_01.gold_01.airline_sample_gold select * from df_gold

- 正しく実行されると、以下のような結果が出力されます。
注:
ここでは、Spark のネイティブな INSERT ではなく SQL の INSERT を使用しています。
これは、Spark を使うと 列名が小文字に変換されてしまい、その結果 OACでビジュアライゼーションでエラーが出るためです。SQL の INSERT INTO を使用することで、この問題を回避しています。
それでは、前編はここまでです!お疲れ様でした!
次は、いよいよAI Lakehouseに格納したデータを使って、Oracle Analytics Cloud(OAC) を使って、分析・可視化を行っていきます。
👉後編はこちらから!
参考
- Live Labs:Accelerate Analytics on OAC with Generative AI, AIDP Data Platform, and Autonomous AI Lakehouse
本ハンズオンは上記Live Labsを参考に実施しています。全体の構成は、こちらの内容に準拠していますが、一部内容を追加・変更しています。変更した項目については、項目名に「*」を付して示しています。
■ AIDP(Oracle AI Data Platform)に関連するブログ記事
- Oracle AI Data Platform(AIDP) がリリースされたので作成してみてみた
- 【OCI】新サービスのAIデータ基盤「Oracle AI Data Platform (AIDP)」を試す:ADBと連携してデータ結合
- Oracle AI Data Platform サービスのエッセンスをクイック・レビュー
- OCI の監査ログを AIデータ・プラットフォーム (AIDP) を使って分析してみた(Part 1~3)
- メダリオンアーキテクチャをOracle AI Data Platformで実装してみる
- Oracle×AI Trials #06: Oracle AI Data Platformを使ってみました~機能紹介編~