はじめに
今回は、Autonomous Database(ADB)の DBMS_CATALOG を利用して、Snowflake Open Catalog / Polaris に同期した Iceberg テーブルを ADB から参照してみます。
前回👇の記事では、外部表を作成する際に Icebergテーブルの metadata.json を直接指定していました。
この方法でも Iceberg テーブルを参照できますが、指定しているのは特定時点の metadata.json です。そのため、新しいスナップショットが作成されたり、スキーマが変更されたりした場合には、新しい metadata.json を指定して外部表を作り直す必要があります。
また、metadata.json を直接指定する方式では、ADB 側に外部表を個別に作成しない限り、カタログのように「どの namespace や table が存在するか」を探索することはできません。
そこで今回は、Snowflake-managed Iceberg テーブルを Snowflake Open Catalog / Polaris に同期し、ADB から DBMS_CATALOG.MOUNT_ICEBERG を使って Iceberg REST Catalog としてマウントします。DBMS_CATALOG.MOUNT_ICEBERG を使って Iceberg REST Catalog をマウントすることで、マウント後は 「schema.table@ICEBERG_CAT」 のように SQL から参照できます。そして、カタログで管理をすることで REST Catalog でメタデータ、スキーマ、現在のスナップショットを解決し、最新スナップショットを反映することができます。
- 今回行う構成は次のとおりです。
Snowflake-managed Iceberg
→ Snowflake Open Catalog / Polaris に同期
→ ADB DBMS_CATALOG.MOUNT_ICEBERG
→ ADB上の同期ビュー
→ Select AI
- 前回の記事の構成
Snowflake-managed Iceberg
→ S3 metadata.json
→ ADB DBMS_CLOUD.CREATE_EXTERNAL_TABLE
→ Select AI
Snowflakeのドキュメントに、Snowflake-managed Iceberg テーブルを Open Catalog に同期して、外部エンジンから Iceberg REST Catalog 経由で参照できる流れが説明されています。同期された Snowflake-managed Iceberg テーブルは Open Catalog 側では読み取り専用になりますが、ADB から SELECT する用途であればこの流れで実行可能です。
目次
- 事前準備
- Step 1: Snowflake Open Catalog / Polaris に外部カタログを作る
- Step 2: Open Catalog 側で RBAC と Service Connection を作る
- Step 3: Snowflake-managed Iceberg テーブルを Open Catalog に同期する
- Step 4. ADB で ACL を追加する
- Step 5. 権限付与とCredentialの作成
- Step 6. ADB で Polaris Catalog をマウントする
- Step 7. ADB から Catalog 上の Table を確認する
- Step 8: ADB から直接 SELECT して確認する
- Step 9. Select AI 用にローカル同期ビューを作る
- Step 10: Select AI Profile を作成する
- Step 11: Select AIを試す
- Step 12: 新しい INSERT / Snapshot を追えるか試してみる
- Step 13: 新しい Iceberg テーブルをADBが発見できるか試してみる
事前準備
こちらの記事を参照し、■ Part E. OCI Autonomous Databaseを用意するまで実行されている前提で進めます。
Step 1: Snowflake Open Catalog / Polaris に外部カタログを作る
ここでは Snowflake Open Catalog、つまり Polaris 側に、S3 をストレージとする Iceberg Catalog を作ります。Oracle ドキュメント上でこの接続タイプを Snowflake Polaris として記載されています。ADB は Snowflake Polaris を Iceberg REST Catalog としてマウントできます。
1-1. S3 バケット条件を確認する
Snowflake Open Catalog で S3 を使う場合、バケットは Snowflake / Open Catalog と同じリージョンにあり、バケット名にドットを含めないことが推奨条件として示されています。前編のバケットがこの条件を満たしているか確認してください。
今回は、s3-iceberg-lab-202604で作成されています。
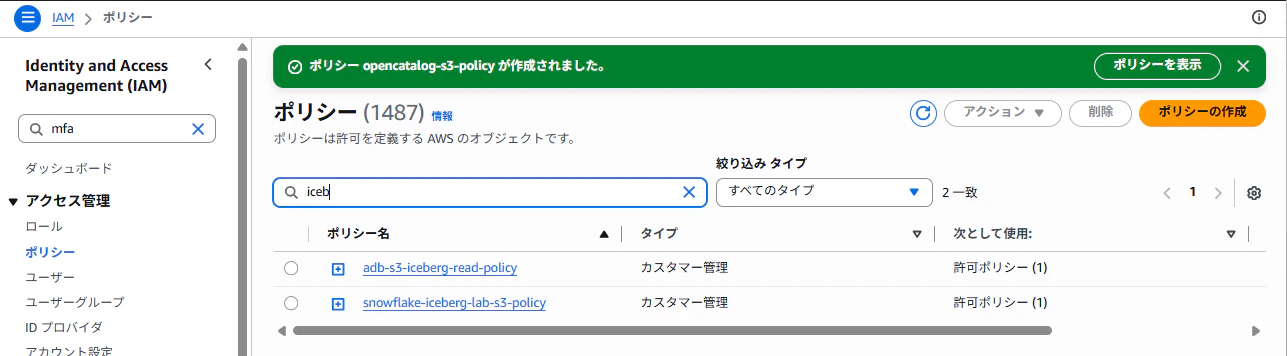
1-2. Open Catalog 用の IAM Policy を作る
元記事では Snowflake の External Volume 用 IAM Role を作りましたが、Open Catalog / Polaris 側も S3 を読む必要があります。
同じバケット・プレフィックスに対して Open Catalog 用の IAM Role を追加で作成します。
AWS上でポリシーの作成に進み、以下を貼ります。YOUR_BUCKET_NAME を自分のバケット名に変更してください。
今回はopencatalog-s3-policyという名前で保存しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "OpenCatalogObjectAccess",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME/snowflake-iceberg-lab/*"
},
{
"Sid": "OpenCatalogListAccess",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME",
"Condition": {
"StringLike": {
"s3:prefix": [
"snowflake-iceberg-lab",
"snowflake-iceberg-lab/*"
]
}
}
}
]
}
Snowflake Open Catalog の S3 設定では、Iceberg のデータ、メタデータ、マニフェストファイルへアクセスするために、オブジェクト操作権限とバケット参照権限が必要です。
1-3. Open Catalog 用 IAM Role を作る
AWS IAM で、たとえばpolaris-open-catalog-s3-roleの名前の Role を作ります。
(信頼されたエンティティタイプ:AWS アカウント、AWS アカウント:このアカウント)
先程作成したopencatalog-s3-policyを紐づけます。
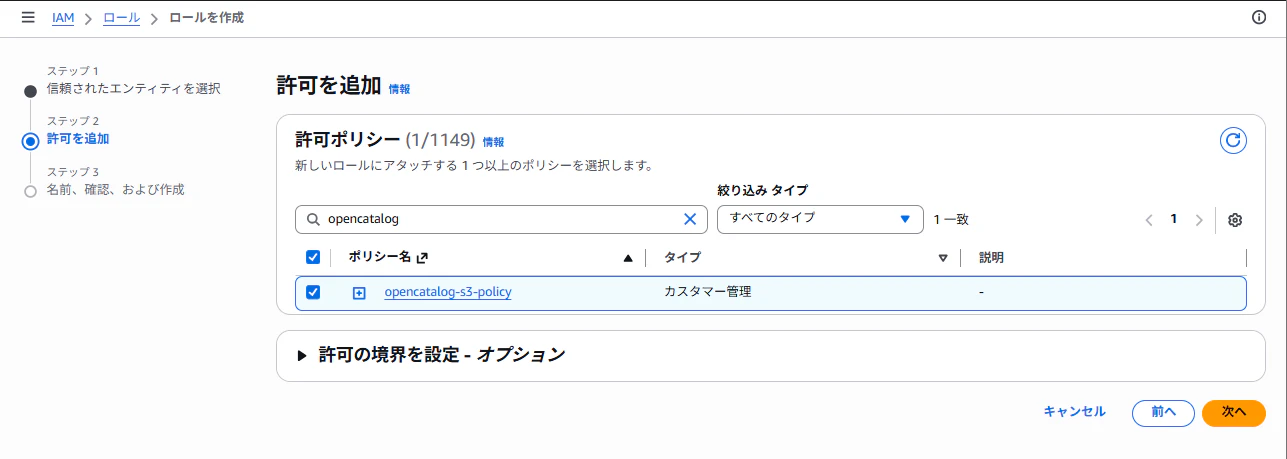
作成したら、ARN(arn:aws:iam::<aws_account_id>:role/polaris-open-catalog-s3-role)を控えておきます。
1-4. Open Catalog で Catalog を作成する
Snowflake Open Catalog の UI で、外部カタログを作成します。
Snowflake Snowsight > Admin > Accounts > Create Snowflake Open Catalog Account
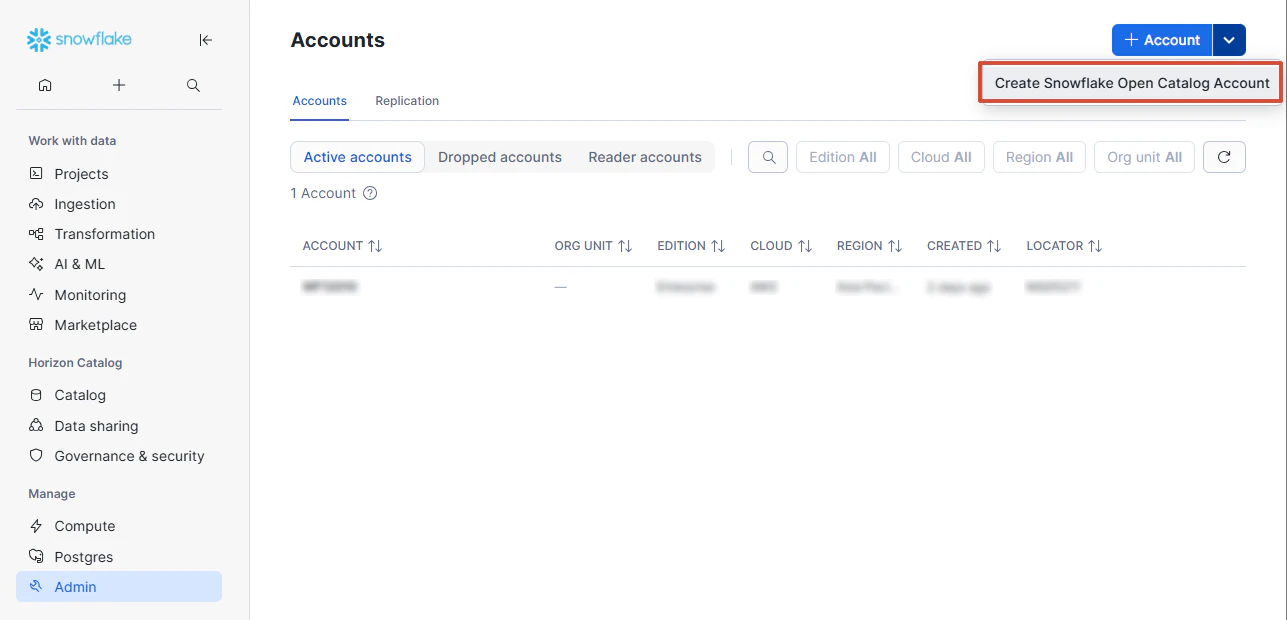
Open Catalog側のUIでカタログを作成します。
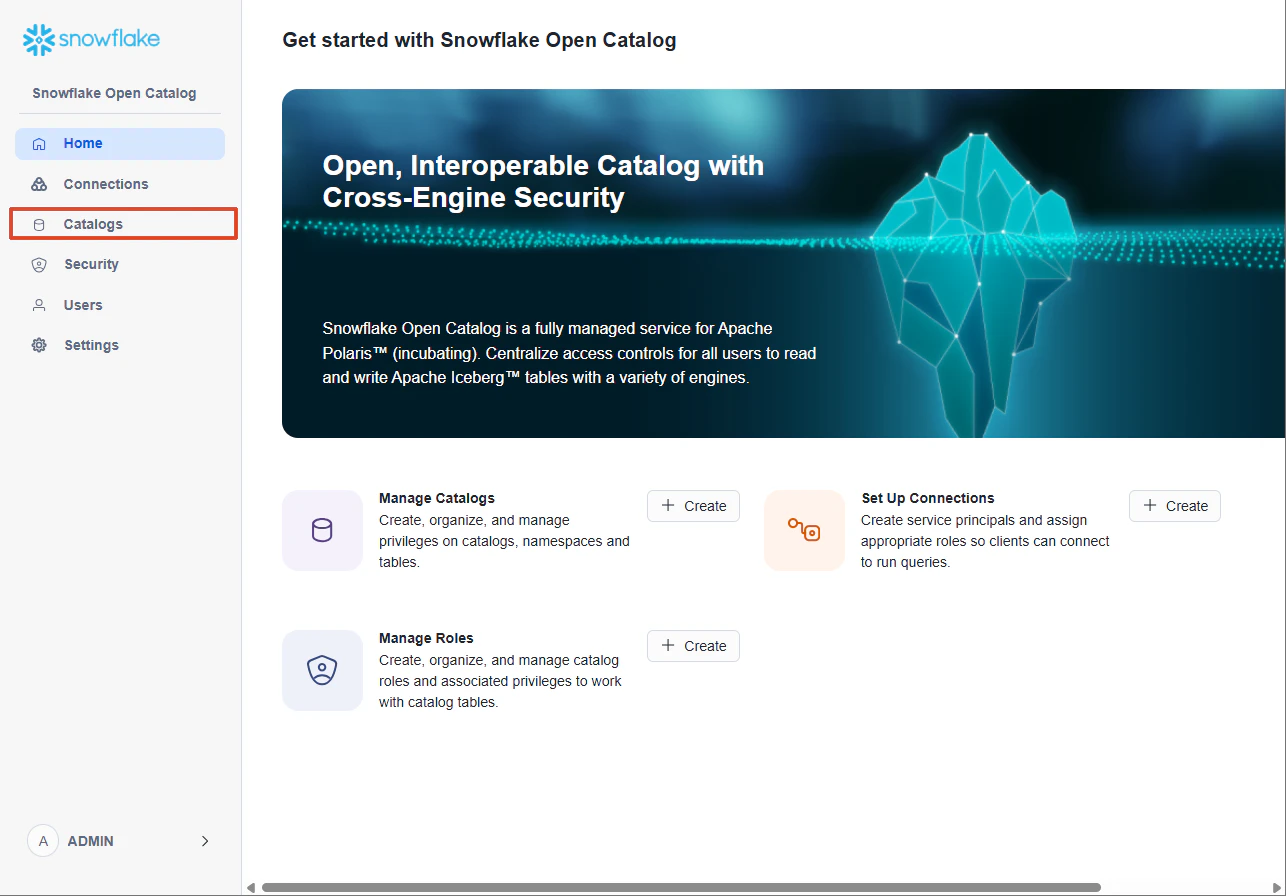
Catalog name: adb_iceberg_ext_catalog
External: ON
Storage provider: S3
Default base location: s3://YOUR_BUCKET_NAME/snowflake-iceberg-lab/
S3 Role ARN: arn:aws:iam::<aws_account_id>:role/polaris-open-catalog-s3-role
Open Catalog で External Catalog を作る場合、ストレージプロバイダ、デフォルトベースロケーション、S3 Role ARN を指定します。作成後、Open Catalog 側に IAM User ARN と External ID が表示されるので、それを AWS IAM Role の Trust Policy に反映します。
1-5. IAM Role の Trust Policy を更新する
Open Catalog 側で表示された以下を控えます。
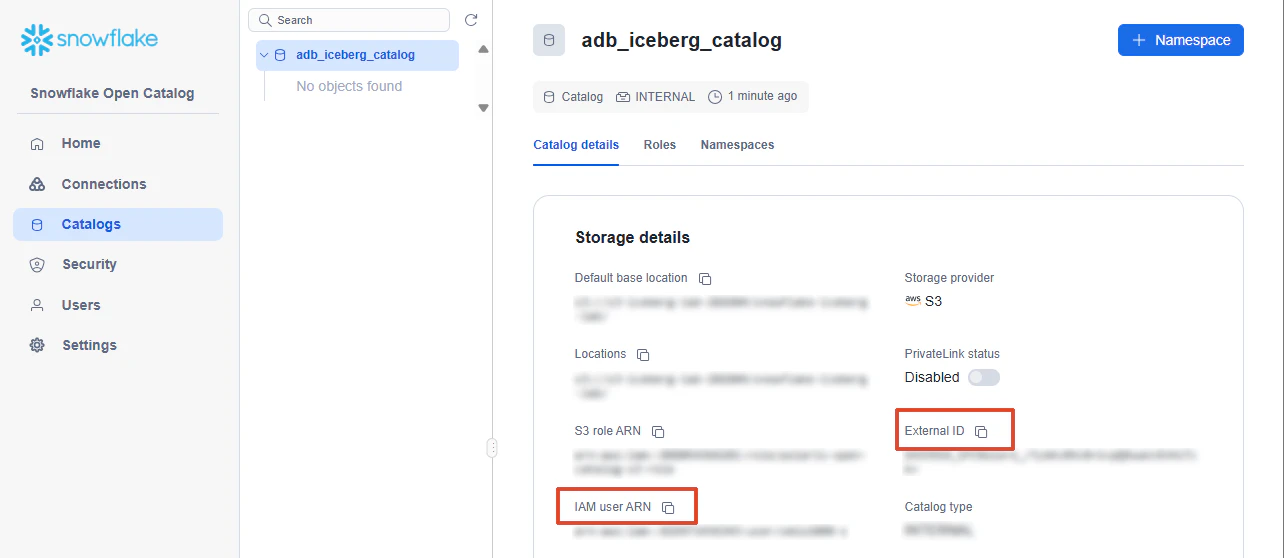
その値を使って、AWS IAM Role の Trust Policy を次のように更新します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<open_catalog_iam_user_arn>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<open_catalog_external_id>"
}
}
}
]
}
Step 2: Open Catalog 側で RBAC と Service Connection を作る
次に、Open Catalog / Polaris 側で2種類の接続用ユーザーを作ります。
- ① Snowflake から Open Catalog へ同期するための接続
- ② ADB から Open Catalog を読むための接続
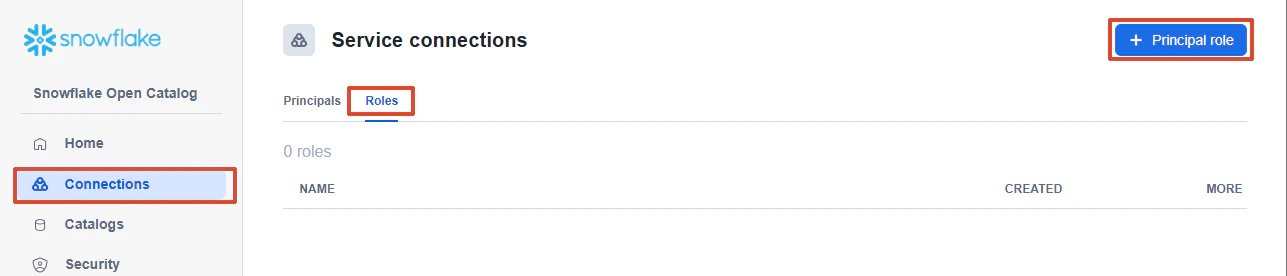
Snowflake Open Catalog は RBAC(Role-based access control) 方式で、Catalog Role を Principal Role に付与し、Principal Role を Service Principal に関連付ける形でアクセスを制御します。
2-1. Snowflake 同期用の Principal Role / Service Connection
Open Catalog 側で次を作ります。
Principal Role: SNOWFLAKE_SYNC_PR
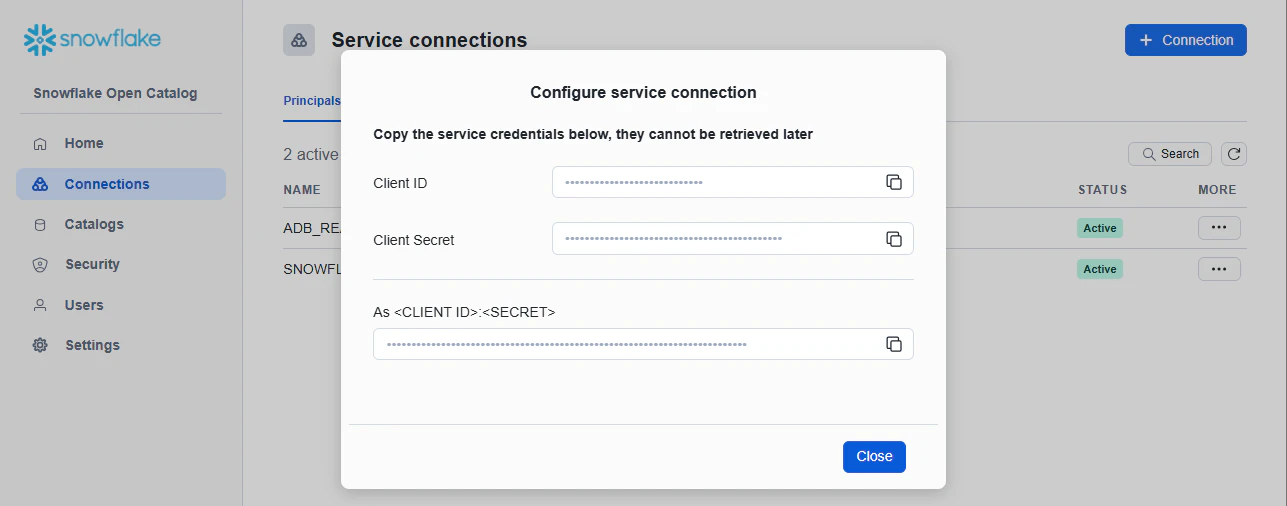
Service Connection: SNOWFLAKE_SYNC_CONN
作成後、snowflake_sync_client_idとsnowflake_sync_client_secretを控えておきます。
2-2. Snowflake 同期用の Catalog Role
同期用の Catalog Role を作ります。Catalog Role: SNOWFLAKE_SYNC_CR
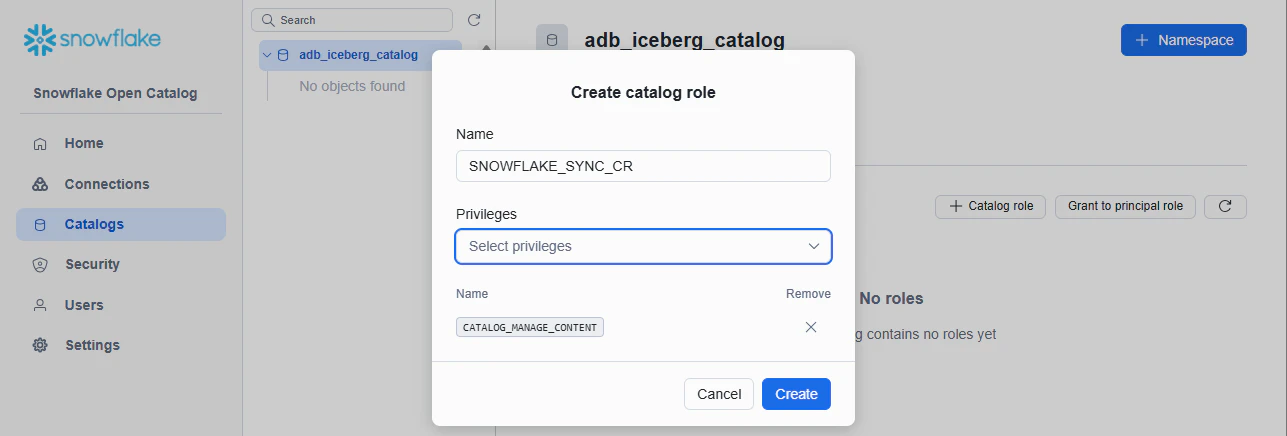
今回は検証環境なので強めの権限として CATALOG_MANAGE_CONTENT を付与しておきます。
画面上の Grant to Principal Role から、次のように設定します。
Catalog role: SNOWFLAKE_SYNC_CR
Principal role: SNOWFLAKE_SYNC_PR
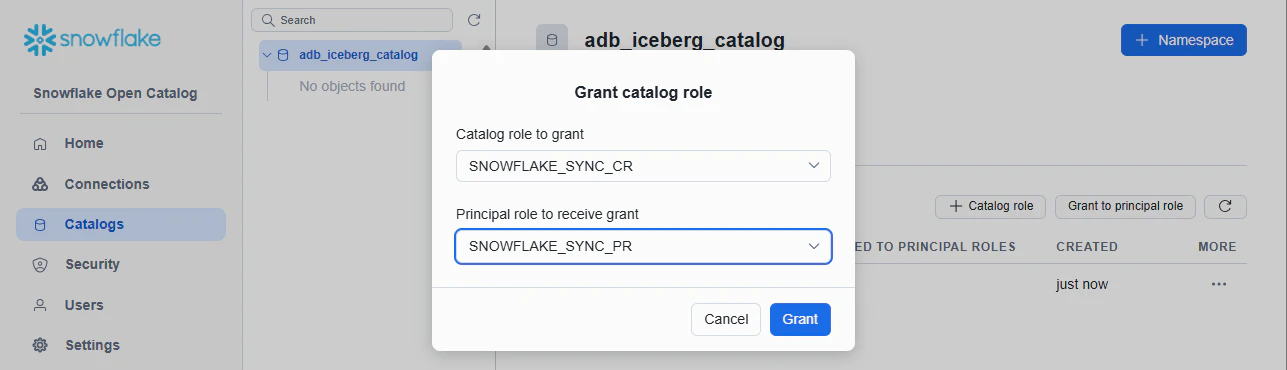
Open Catalog の Service Connection は principal role を使って service principal に権限を渡す仕組みです。Service Connection 作成時に principal role を指定し、その principal role に catalog role を付与することで、対象 engine が catalog にアクセスできます。
2-3. ADB 読み取り用の Principal Role / Service Connection
ADB から読むために、別の Service Connection を作ります。
Principal Role: ADB_READER_PR
Service Connection: ADB_READER_CONN
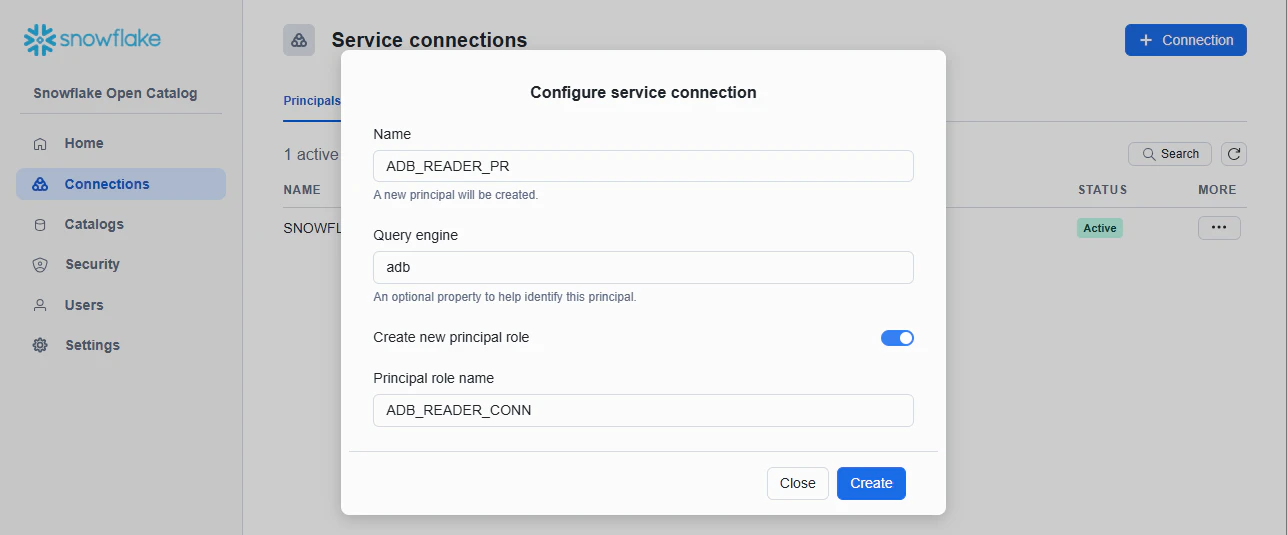
2-4. ADB 読み取り用の Catalog Role
ADB は読み取りしかしないため、読み取り用の Catalog Role を作ります。Catalog Role: ADB_READER_CR
CATALOG_READ_PROPERTIES, NAMESPACE_FULL_METADATA, NAMESPACE_LIST, NAMESPACE_READ_PROPERTIES, POLICY_READ, TABLE_FULL_METADATA, TABLE_LIST, TABLE_READ_DATA, TABLE_READ_PROPERTIESを付与しておきます。
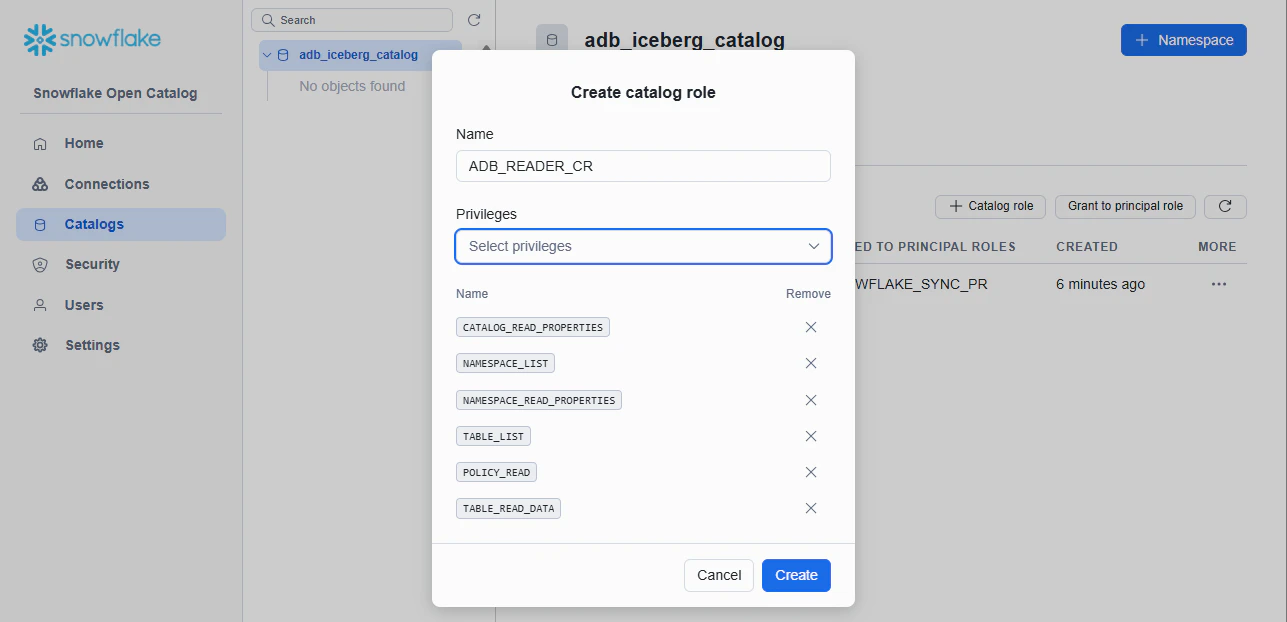
作成後、Grant to principal roleから ADB_READER_CR を ADB_READER_PR に grant します。
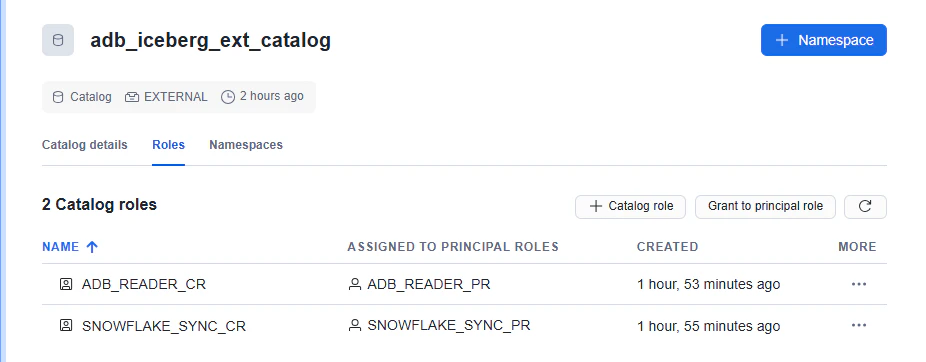
Open Catalog の権限反映には時間がかかる場合があり、Snowflake ドキュメントでは権限変更の反映に最大1時間かかる可能性があると説明されています。認証設定が正しいのに ADB 側からすぐ見えない場合は、この点も確認対象になります。
Step 3: Snowflake-managed Iceberg テーブルを Open Catalog に同期する
ここからは、前編で作った Snowflake-managed Iceberg テーブルを Open Catalog / Polaris に同期します。
前記事では、次のとおりSnowflake-managed Iceberg として作られています。
CATALOG = 'SNOWFLAKE'
このテーブルを Open Catalog に同期すると、外部エンジンからは Polaris Iceberg REST Catalog 経由で見えるようになります。
Snowflake のドキュメントでは、Snowflake database / schema は Open Catalog 側の catalog / namespace に対応すると説明されています。たとえば Snowflake 側の db1.public.table1 は、Open Catalog 側で catalog1.db1.public.table1 のように見えます。
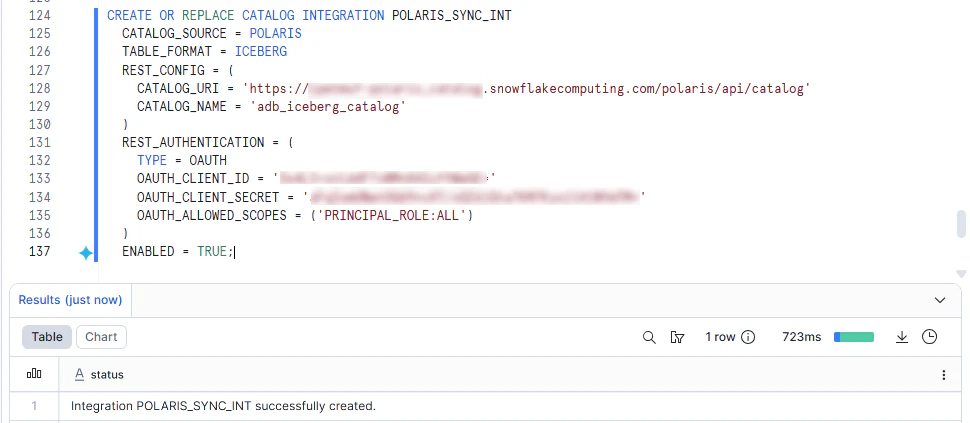
3-1. Snowflake 側で Catalog Integration を作る
Snowflake で実行します。
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE CATALOG INTEGRATION POLARIS_SYNC_INT
CATALOG_SOURCE = POLARIS
TABLE_FORMAT = ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<open_catalog_host>/polaris/api/catalog'
WAREHOUSE = 'adb_iceberg_ext_catalog'
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<SNOWFLAKE_SYNC_CONN_CLIENT_ID>'
OAUTH_CLIENT_SECRET = '<SNOWFLAKE_SYNC_CONN_CLIENT_SECRET>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED = TRUE;
ClientIDとSecretは、SNOWFLAKE_SYNC_CONN(Service Connection)で発行したものであることを注意してください。
3-2. 既存の Schema に CATALOG_SYNC を設定する
前編と同じ database / schema を使います。
記事では、ICEBERG_TUTORIAL_DB.PUBLICという database / schema を使っています。
その schema に対して CATALOG_SYNC を設定します。
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
ALTER SCHEMA PUBLIC SET CATALOG_SYNC = 'POLARIS_SYNC_INT';
Snowflake の手順では、database または schema に CATALOG_SYNC を設定すると、そのスコープ内の Snowflake-managed Iceberg テーブルが Open Catalog に同期されます。
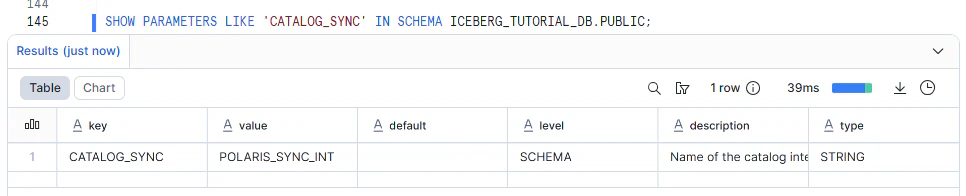
3-3. 同期状態を確認する
Snowflake 側で確認します。
SHOW PARAMETERS LIKE 'CATALOG_SYNC' IN SCHEMA ICEBERG_TUTORIAL_DB.PUBLIC;
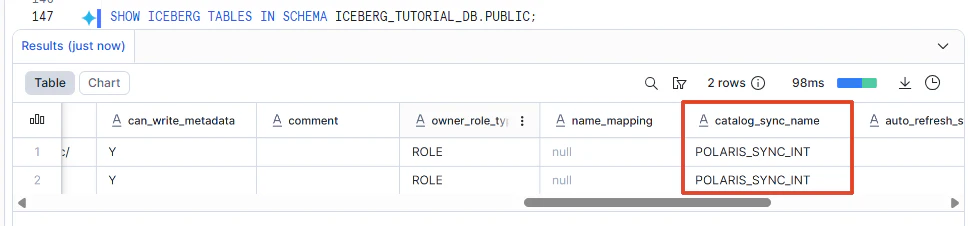
SHOW ICEBERG TABLES LIKE '%ICEBERG%' IN SCHEMA ICEBERG_TUTORIAL_DB.PUBLIC;
SHOW ICEBERG TABLES の結果で、catalog_sync_name に POLARIS_SYNC_INT が入っているか確認します。
Step 4. ADB で ACL を追加する
ADB からは2種類の外部アクセスが必要です。
-
- Polaris / Open Catalog の REST API
-
- S3 の Iceberg data / metadata / manifest files
Oracle ドキュメントでも、Iceberg REST Catalog 連携では外部サービス側とオブジェクトストレージ側の両方にネットワーク ACL が必要とされています。Snowflake Polaris + S3 の場合、Polaris ホスト、S3 の regional host、S3 の non-regional host が例示されています。
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => '<open_catalog_host>',
lower_port => 443,
upper_port => 443,
ace => xs$ace_type(
privilege_list => xs$name_list('http'),
principal_name => 'ADMIN',
principal_type => xs_acl.ptype_db
)
);
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'YOUR_BUCKET_NAME.s3.ap-northeast-1.amazonaws.com',
lower_port => 443,
upper_port => 443,
ace => xs$ace_type(
privilege_list => xs$name_list('http'),
principal_name => 'ADMIN',
principal_type => xs_acl.ptype_db
)
);
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'YOUR_BUCKET_NAME.s3.amazonaws.com',
lower_port => 443,
upper_port => 443,
ace => xs$ace_type(
privilege_list => xs$name_list('http'),
principal_name => 'ADMIN',
principal_type => xs_acl.ptype_db
)
);
END;
/
Step 5. 権限付与とCredentialの作成
5-1. 権限付与
DBMS_CATALOG を使うユーザーに DWROLE を付与します。
GRANT DWROLE TO ADMIN;
5-2. S3 Storage Credential を確認する
ADB で S3 Storage用の Credential を確認します。
前記事 Part E で作成した S3 読み取り用 Credential を利用できます。
Polaris を使う場合でも ADB 側には S3 読み取り用の Credential が必要になります。Polaris 連携で Credential Vending はサポートされず、ADB 側に明示的な S3 Access Key / Secret Key などを指定する必要があると説明されています。(参考)
5-3. ADB で Polaris Catalog 用 Credential を作る
次に、ADB から Open Catalog / Polaris REST API に接続するための OAuth Credential を作ります。
Open Catalog 側で作った ADB 読み取り用 Service Connection の値を使います。
- adb_reader_client_id
- adb_reader_client_secret
ADB上で以下を実行します。
BEGIN
DBMS_SHARE.CREATE_BEARER_TOKEN_CREDENTIAL(
credential_name => 'POLARIS_CATALOG_CRED',
bearer_token => 'DUMMY_INITIAL_TOKEN',
token_endpoint => 'https://<open_catalog_host>/polaris/api/catalog/v1/oauth/tokens',
client_id => '<adb_reader_client_id>',
client_secret => '<adb_reader_client_secret>',
token_scope => 'PRINCIPAL_ROLE:ALL'
);
END;
/
BEGIN
DBMS_SHARE.REFRESH_BEARER_TOKEN_CREDENTIAL(
credential_name => 'POLARIS_CATALOG_CRED'
);
END;
/
確認
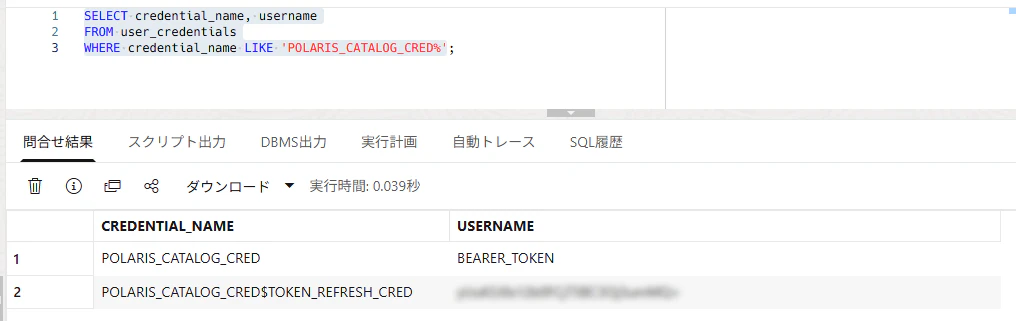
Usernameには ADB_READER_CONN の Client ID が表示されていることを確認します。
Step 6. ADB で Polaris Catalog をマウントする
前記事で利用していた DBMS_CLOUD.CREATE_EXTERNAL_TABLE の代わりに、DBMS_CATALOG.MOUNT_ICEBERG を使います。
DECLARE
config JSON_OBJECT_T := JSON_OBJECT_T();
BEGIN
config.put('namespacePath', 'ICEBERG_TUTORIAL_DB');
config.put('bucketRegion', 'ap-northeast-1');
DBMS_CATALOG.MOUNT_ICEBERG(
catalog_name => 'POLARIS_CAT',
endpoint => 'https://<open_catalog_host>/polaris/api/catalog/v1/adb_iceberg_ext_catalog',
catalog_credential => 'POLARIS_CATALOG_CRED',
data_storage_credential => 'S3_ICEBERG_CRED',
configuration => config,
catalog_type => 'ICEBERG_POLARIS'
);
END;
/
DBMS_CATALOG.MOUNT_ICEBERG は、Iceberg Catalog の endpoint、Catalog 認証用 Credential、データストレージ用 Credential、configuration、catalog_type を指定して Iceberg Catalog を ADB にマウントするプロシージャです。Polaris の場合、catalog_type には ICEBERG_POLARIS を指定します。
namespacePath には、ADB から参照したい Open Catalog 側の namespace を指定します。今回の例では、Snowflake 側の database に対応する ICEBERG_TUTORIAL_DB を指定しています。
参考:
- マウントを外す際のコマンド
BEGIN
DBMS_CATALOG.UNMOUNT('POLARIS_CAT');
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
/
- カタログ・メタデータのキャッシュクリア
BEGIN
DBMS_CATALOG.FLUSH_CATALOG_CACHE('POLARIS_CAT');
END;
/
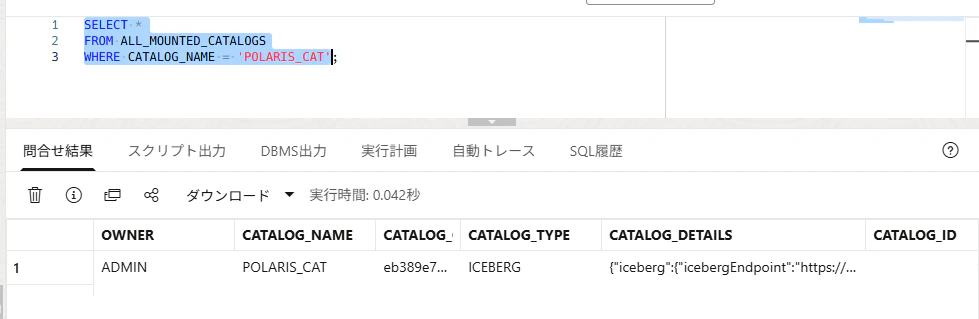
Step 7. ADB から Catalog 上の Table を確認する
Open CatalogのUIに、Icebergテーブルが見えることをまず確認しておきます。
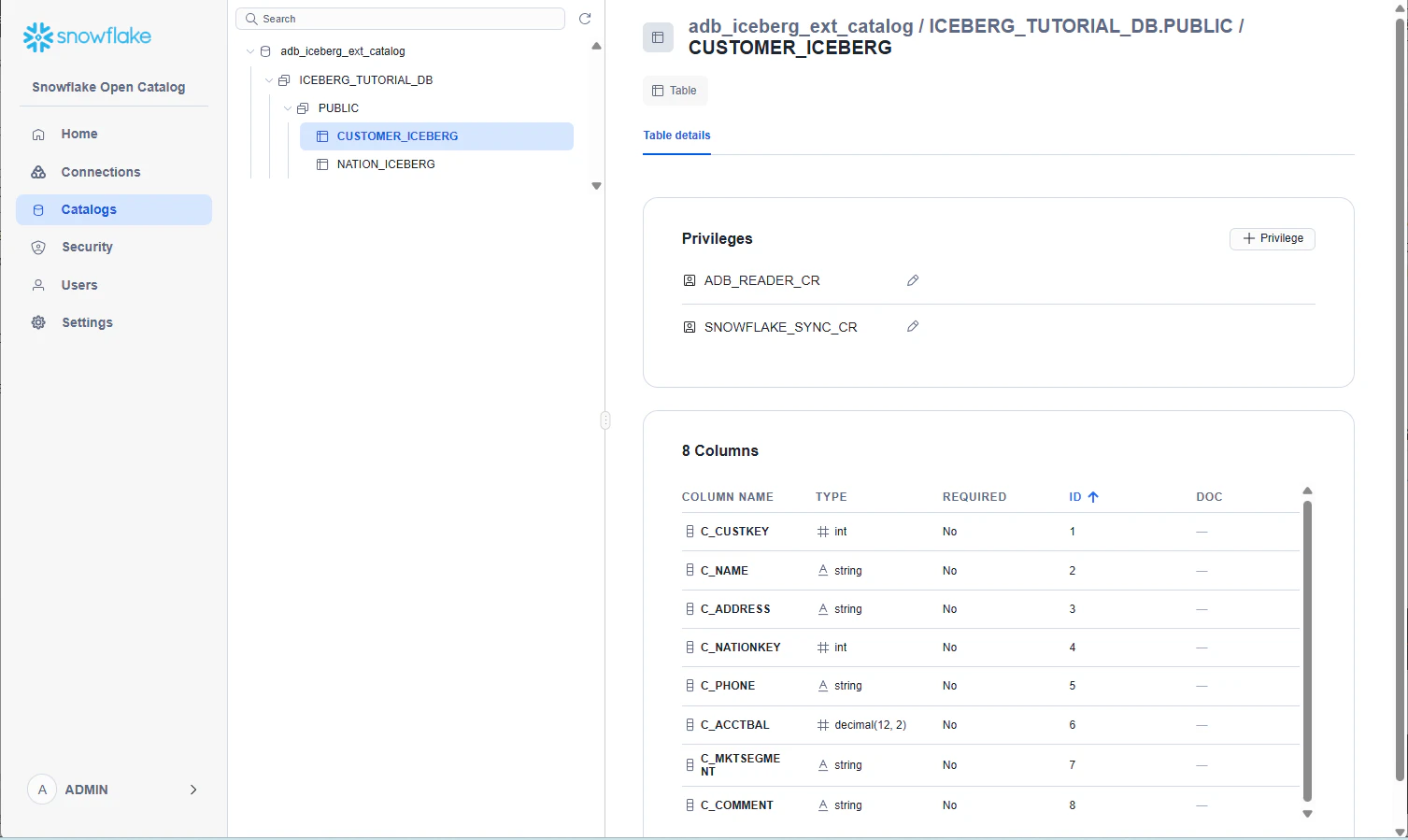
ADB上で以下を実行します。
まず schema / namespace の見え方を確認します。
SELECT *
FROM TABLE(DBMS_CATALOG.GET_SCHEMAS('POLARIS_CAT'));

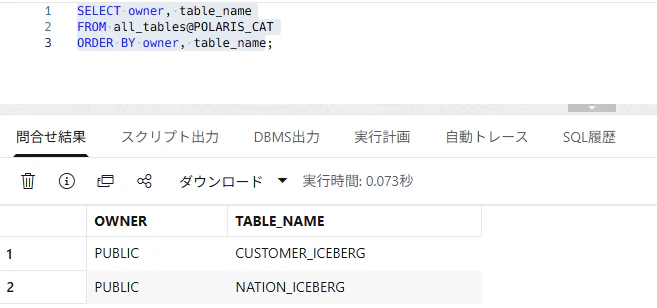
次に table 一覧を確認します。
SELECT owner, table_name
FROM all_tables@POLARIS_CAT
ORDER BY owner, table_name;
または、DBMS_CATALOG.GET_TABLES でも確認できます。
SELECT *
FROM TABLE(
DBMS_CATALOG.GET_TABLES(
catalog_name => 'POLARIS_CAT',
schema_name => 'PUBLIC'
)
);
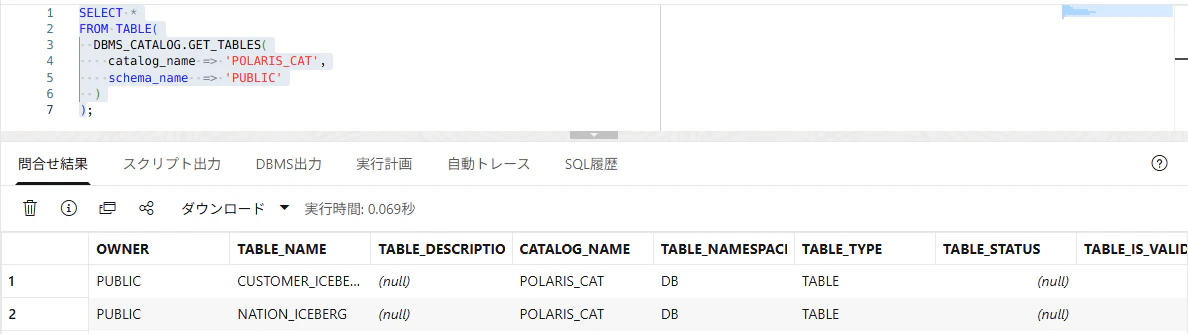
GET_SCHEMAS や GET_TABLES でカタログ上の schema / table を確認でき、マウント済みカタログは ALL_TABLES@catalog_name でも参照できます。
参考:DBMS_CATALOG の概要 GET_TABLEプロシージャ
Step 8: ADB から直接 SELECT して確認する
Select もしてみます。
GET_SCHEMAS または ALL_TABLES@POLARIS_CAT で確認した schema 名を使って SELECT します。
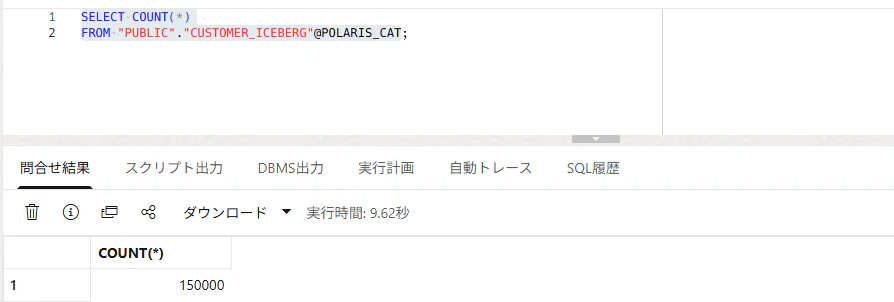
SELECT COUNT(*)
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT;
SELECT COUNT(*)
FROM "PUBLIC"."NATION_ICEBERG"@POLARIS_CAT;
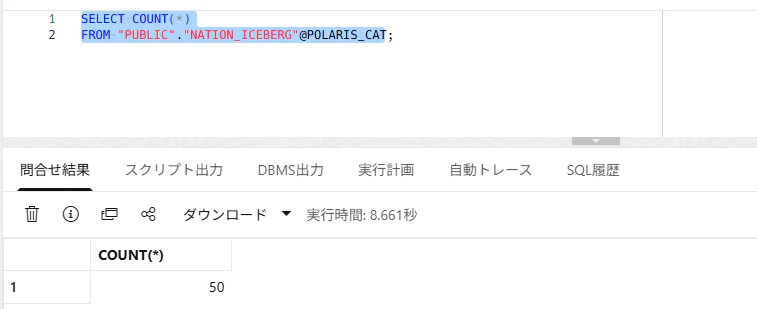
これが通れば、ADB から Polaris Catalog 経由で Iceberg テーブルを読めています。
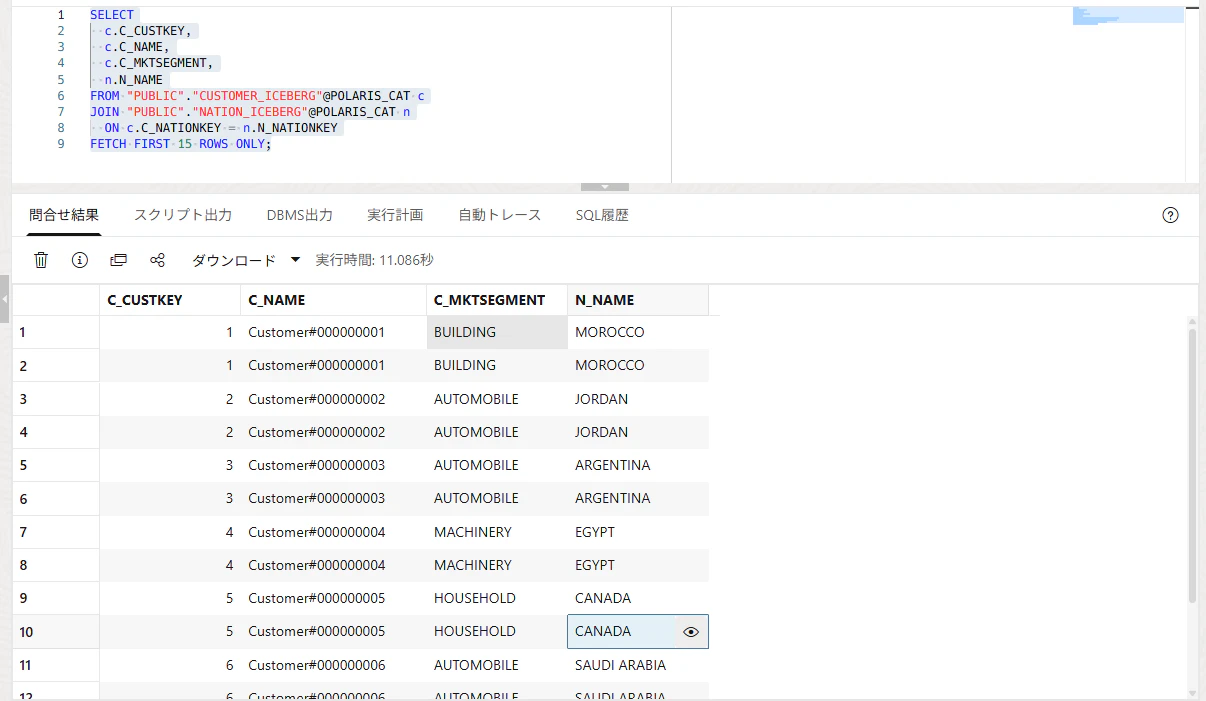
結合も確認します。
SELECT
c.C_CUSTKEY,
c.C_NAME,
c.C_MKTSEGMENT,
n.N_NAME
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT c
JOIN "PUBLIC"."NATION_ICEBERG"@POLARIS_CAT n
ON c.C_NATIONKEY = n.N_NATIONKEY
FETCH FIRST 15 ROWS ONLY;
schema 名にドットが含まれる場合はダブルクォートで囲んでください。実際の schema 名は ADB で確認した表示に合わせてください。
Step 9. Select AI 用にローカル同期ビューを作る
Select AI には、直接 @POLARIS_CAT 付きの外部カタログ表を渡すより、ADB 上にローカルビューを作って、そのビューを object_list に入れる方が扱いやすいため、ビューを作成していきます。
DBMS_CATALOG.CREATE_SYNCHRONIZED_VIEWS を使います。このプロシージャは、カタログ上の table に対して ADB 側に同期ビューを作成するプロシージャです。
引数として、catalog 名、schema 名、作成先 schema、対象 table 名、view prefix などを指定します。
参考:CREATE_SYNCHRONIZED_SCHEMASプロシージャ
BEGIN
DBMS_CATALOG.CREATE_SYNCHRONIZED_VIEWS(
catalog_name => 'POLARIS_CAT',
schema_name => 'PUBLIC',
target_schema => 'ADMIN',
table_names => 'CUSTOMER_ICEBERG,NATION_ICEBERG',
view_prefix => 'POL_',
replace_existing => TRUE,
ignore_errors => FALSE
);
END;
/
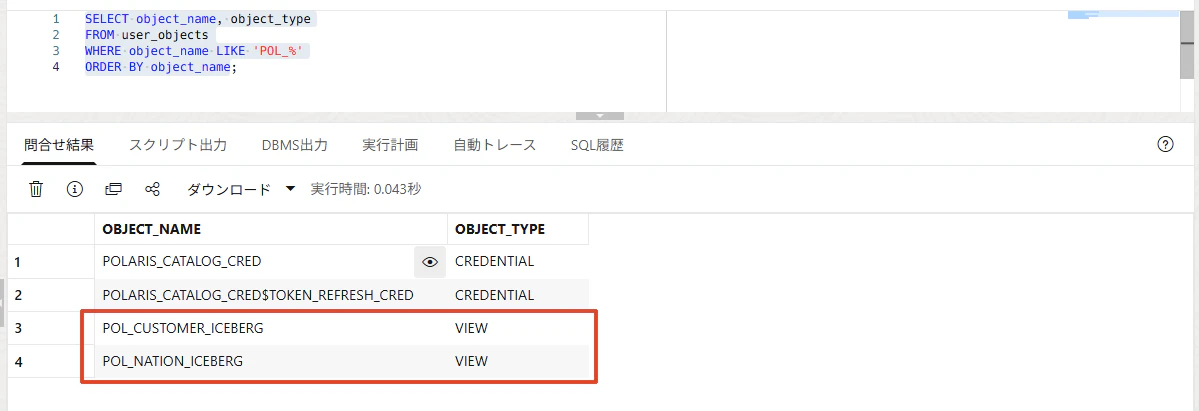
同期ビューが作成されたか確認します。
SELECT object_name, object_type
FROM user_objects
WHERE object_name LIKE 'POL_%'
ORDER BY object_name;
作成された同期ビューを参照して、件数を確認します。
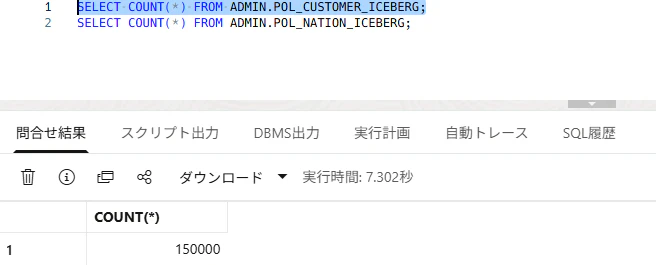
SELECT COUNT(*) FROM ADMIN.POL_CUSTOMER_ICEBERG;
SELECT COUNT(*) FROM ADMIN.POL_NATION_ICEBERG;
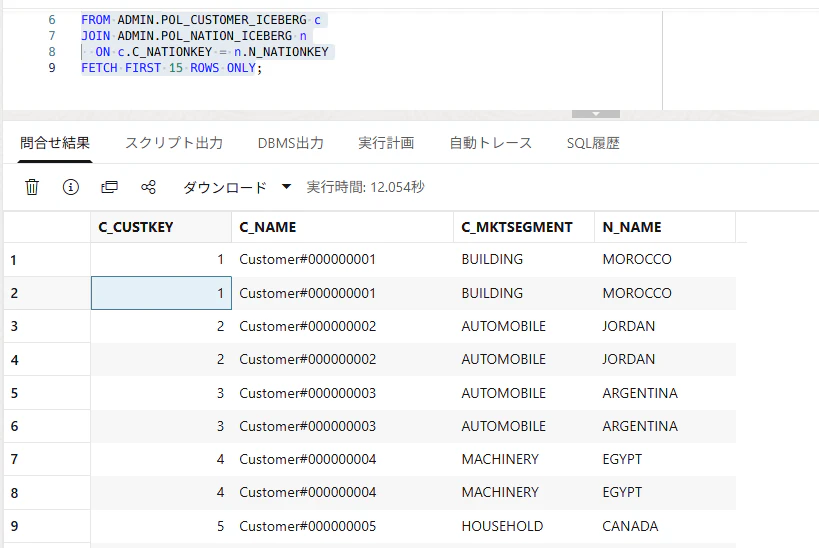
続いて、2 つのビューを結合して確認します。
SELECT
c.C_CUSTKEY,
c.C_NAME,
c.C_MKTSEGMENT,
n.N_NAME
FROM ADMIN.POL_CUSTOMER_ICEBERG c
JOIN ADMIN.POL_NATION_ICEBERG n
ON c.C_NATIONKEY = n.N_NATIONKEY
FETCH FIRST 15 ROWS ONLY;
ここまで成功すれば、Select AI に渡すためのローカル同期ビューの準備は完了です。
Step 10: Select AI Profile を作成する
Select AI に利用するプロファイルを作成します。
object_list には、前回の記事では直接 CUSTOMER_ICEBERG と NATION_ICEBERG を指定していましたが、今回は先程ADB 上に作成した同期ビューを指定します。
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'GENAI_XAI_POLARIS',
attributes => '{
"provider" : "oci",
"credential_name" : "OCI_GENAI",
"model" : "xai.grok-4",
"region" : "us-chicago-1",
"comments" : true,
"conversation" : "TRUE",
"object_list": [
{"owner": "ADMIN", "name": "POL_CUSTOMER_ICEBERG"},
{"owner": "ADMIN", "name": "POL_NATION_ICEBERG"}
]
}'
);
END;
/
ここでのポイントは、object_list に Open Catalog 側の table 名ではなく、ADB 側に作成した同期ビュー名を指定している点です。
Step 11: Select AIを試す
ではSelect AIを使って自然言語での問い合わせを試してみましょう。
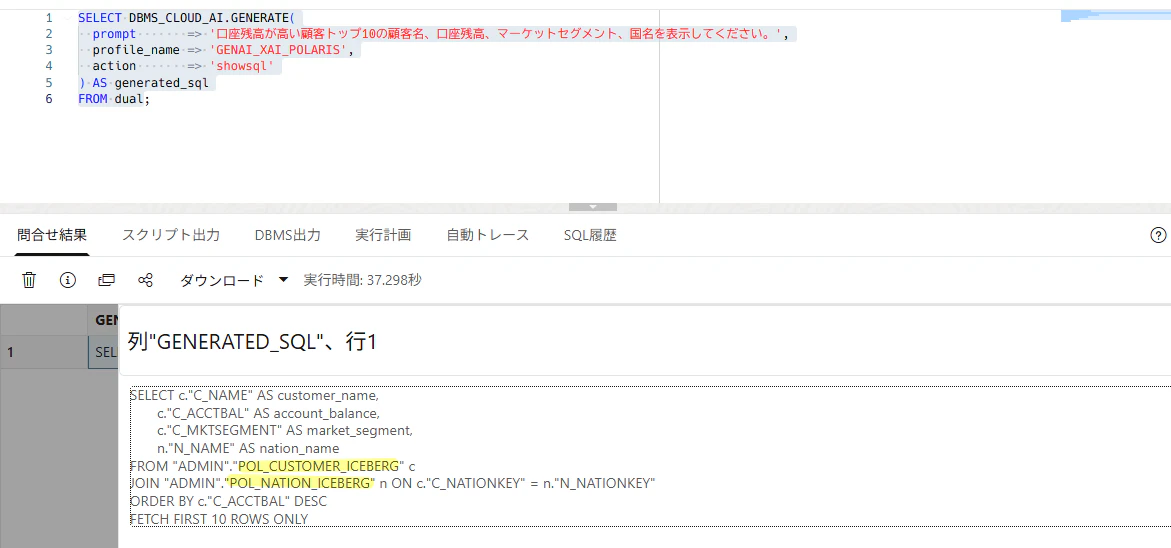
まずは showsql を使って、SELECT AI がどのような SQL を生成するか確認します。
生成される SQL では、次のように同期ビューが参照される想定です。
SELECT DBMS_CLOUD_AI.GENERATE(
prompt => '口座残高が高い顧客トップ10の顧客名、口座残高、マーケットセグメント、国名を表示してください。',
profile_name => 'GENAI_XAI_POLARIS',
action => 'showsql'
) AS generated_sql
FROM dual;
作成したビューを参照するSQLが生成されました。
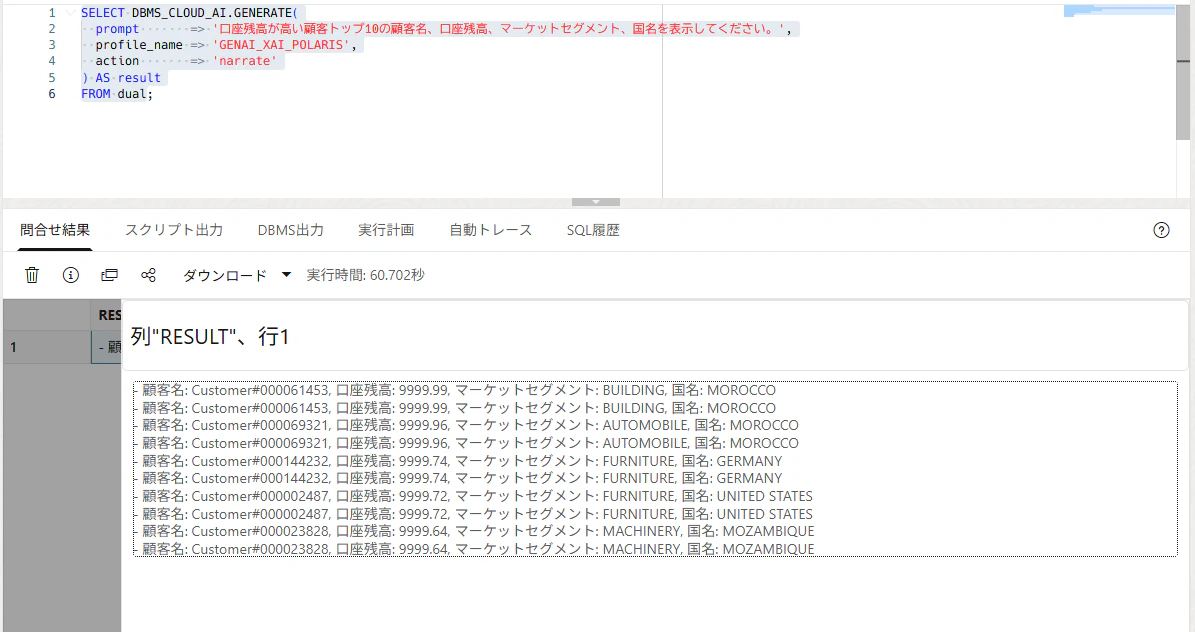
SQL 生成に問題がなければ、narrate で実行結果を自然言語として取得します。
無事生成できました!
■ おまけ:object_list に @POLARIS_CAT 付き table を直接指定するとどうなるか
object_listにNATION_ICEBERG@POLARIS_CATのような形で指定してみたところ、プロファイル作成は通りましたが、Generate 実行時に object_list の table name 検証が走り有効なテーブル名ではないエラーが出ました。
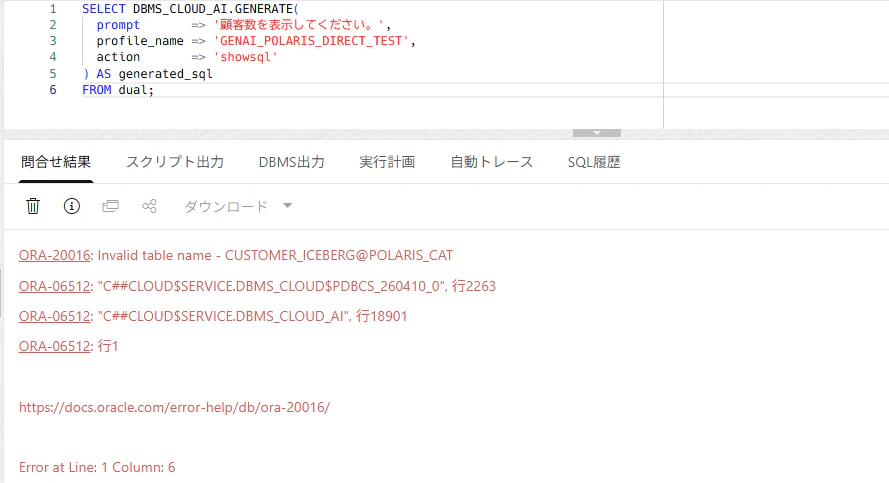
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'GENAI_POLARIS_DIRECT_TEST',
attributes => '{
"provider" : "oci",
"credential_name" : "OCI_GENAI",
"model" : "xai.grok-4",
"region" : "us-chicago-1",
"comments" : true,
"conversation" : "TRUE",
"object_list" : [
{"owner": "PUBLIC", "name": "CUSTOMER_ICEBERG@POLARIS_CAT"},
{"owner": "PUBLIC", "name": "NATION_ICEBERG@POLARIS_CAT"}
]
}'
);
END;
/
Step 12: 新しい INSERT / Snapshot を追えるか試してみる
元データのIcebergテーブルに変更があった場合、Catalog 経由で最新 snapshot を見に行けるかを確認します。
12-1. 現在件数を確認
Snowflake 側で現在件数を確認しておきます。
Snowflake で実行します。
USE ROLE ACCOUNTADMIN;
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
SELECT COUNT(*) AS cnt
FROM CUSTOMER_ICEBERG;
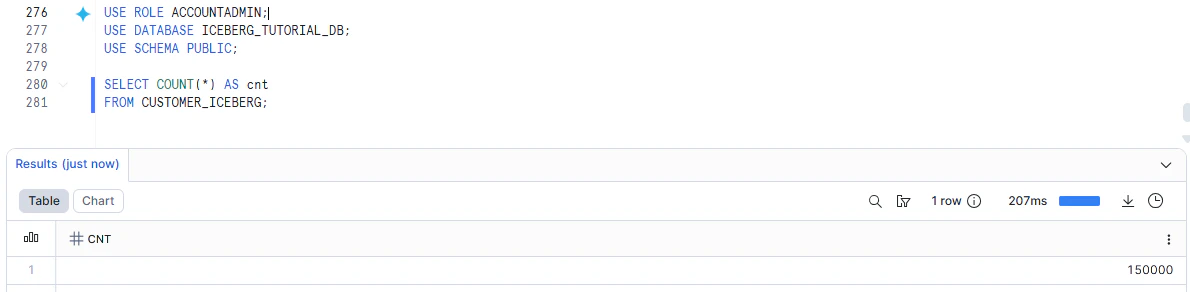
ADB上でも確認します。
SELECT COUNT(*) AS cnt
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT;
SELECT COUNT(*) AS cnt
FROM ADMIN.POL_CUSTOMER_ICEBERG;
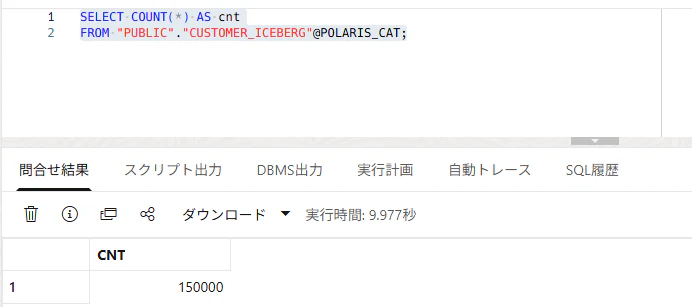
いずれも、150000件ですね。
12-2. Snowflake 側で1行追加
1行データを追加します。
INSERT INTO CUSTOMER_ICEBERG (
C_CUSTKEY,
C_NAME,
C_ADDRESS,
C_NATIONKEY,
C_PHONE,
C_ACCTBAL,
C_MKTSEGMENT,
C_COMMENT
)
VALUES (
999999999,
'ADB_CATALOG_TEST_CUSTOMER',
'TEST ADDRESS',
1,
'00-000-000-0000',
12345.67,
'BUILDING',
'Inserted after ADB catalog mount'
);
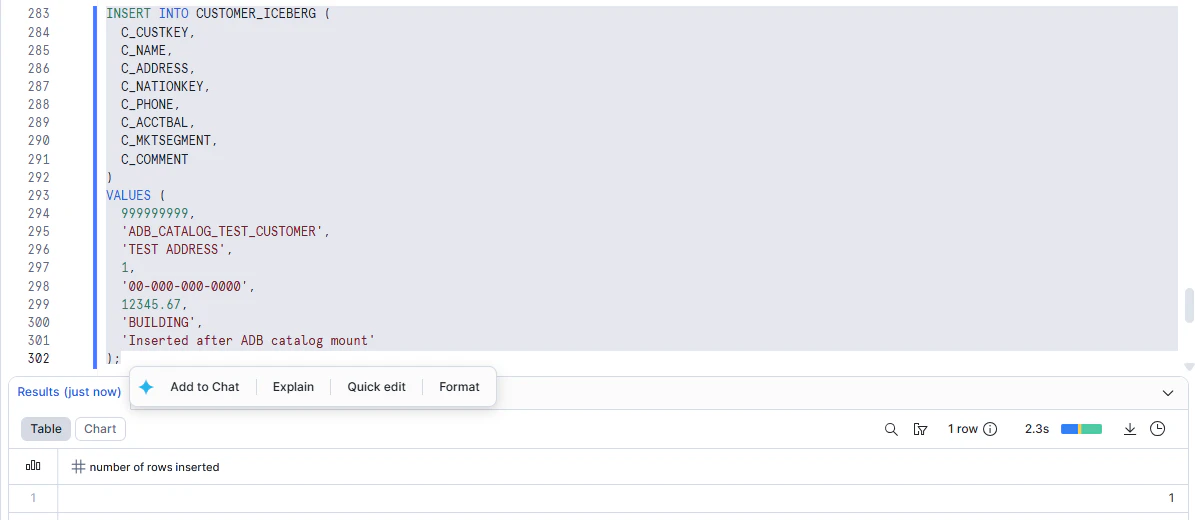
確認します。
SELECT COUNT(*) AS cnt
FROM CUSTOMER_ICEBERG;
SELECT *
FROM CUSTOMER_ICEBERG
WHERE C_CUSTKEY = 999999999;

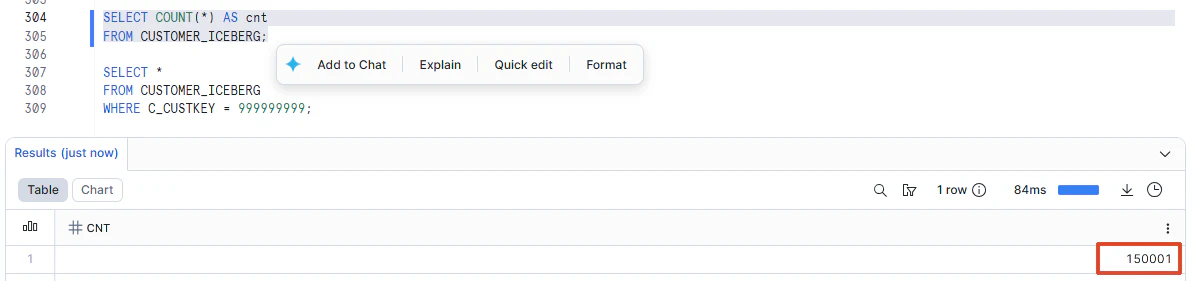
1件増えました。
12-3. ADB 側でキャッシュをクリアして確認
BEGIN
DBMS_CATALOG.FLUSH_CATALOG_CACHE('POLARIS_CAT');
END;
/
Selectしてみます。
SELECT *
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT
WHERE C_CUSTKEY = 999999999;
追加したデータを確認できました!
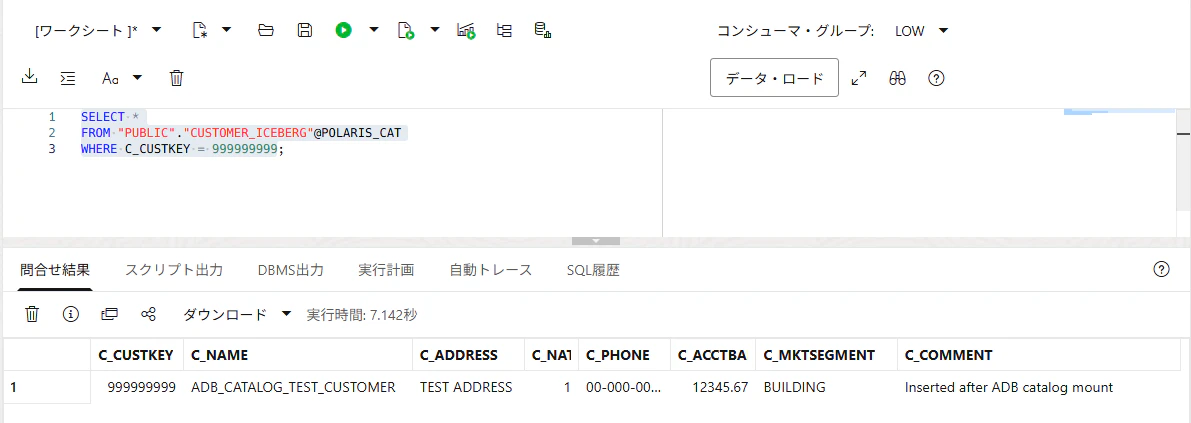
ビュー経由で件数を確認してみます。
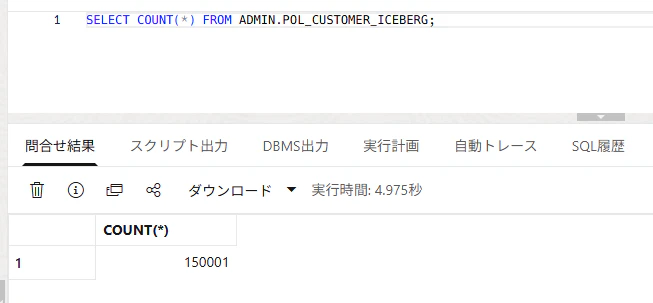
SELECT COUNT(*) FROM ADMIN.POL_CUSTOMER_ICEBERG;
1件増えているのが確認できました。
※前記事で行った metadata.json 直指定の外部表では、古い metadata.json を指している限り、この新しい行は見えないはずです。(新しい snapshot の metadata.json を指定して外部表を再作成すれば見える、という動きになります。)
Step 13: 新しい Iceberg テーブルをADBが発見できるか試してみる
Polaris Catalog に新しいテーブルが増えたことを ADB 側のカタログメタデータで検出できるかを確認します。
13-1. Snowflake 側で小さなテーブルを作成
検証用にもう1つ表を作成します。
USE ROLE ACCOUNTADMIN;
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
CREATE OR REPLACE ICEBERG TABLE ADB_CATALOG_DISCOVERY_TEST (
ID NUMBER(38, 0),
NOTE STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = ICEBERG_EXTERNAL_VOLUME
BASE_LOCATION = 'adb_catalog_discovery_test'
CATALOG_SYNC = 'POLARIS_SYNC_INT';
INSERT INTO ADB_CATALOG_DISCOVERY_TEST
VALUES
(1, 'created after catalog mount');
Open Catalog UI で以下が見えることを確認します。
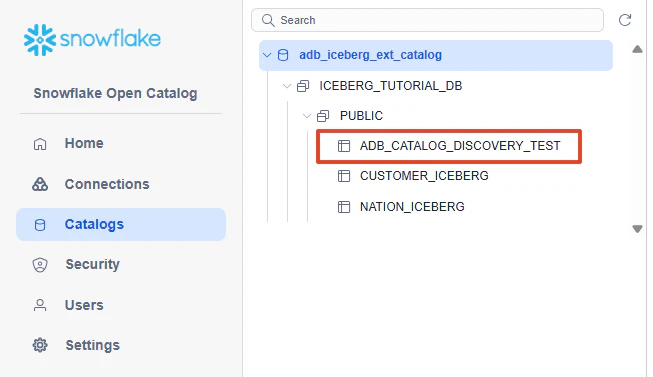
13-2. ADB 側で catalog cache をクリア
BEGIN
DBMS_CATALOG.FLUSH_CATALOG_CACHE('POLARIS_CAT');
END;
/
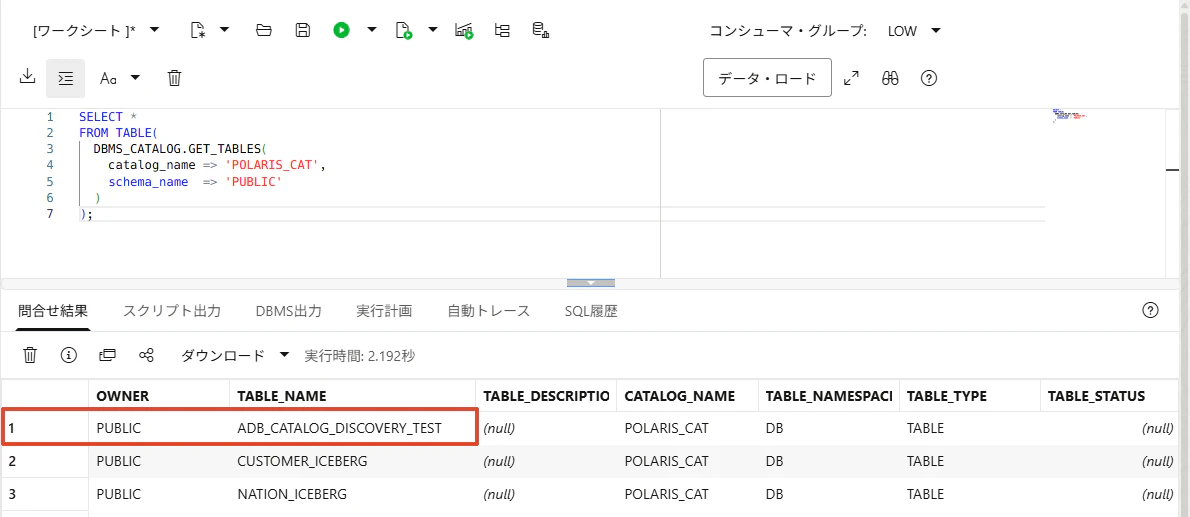
13-3. ADB 側でテーブル探索
マウント階層が ICEBERG_TUTORIAL_DB root になっていて、PUBLIC が schema として見える場合
SELECT *
FROM TABLE(
DBMS_CATALOG.GET_TABLES(
catalog_name => 'POLARIS_CAT',
schema_name => 'PUBLIC'
)
);
新しく増えたテーブルを確認できました。カタログが認識しているテーブルを ADB 側でも探索・参照できることがわかります。
終わりに
今回は、Snowflake-managed Iceberg テーブルを Snowflake Open Catalog / Polaris に同期し、ADB から DBMS_CATALOG.MOUNT_ICEBERG でマウントして参照しました。
metadata.json を直接指定する方法と比べると、カタログ経由では schema / table の探索ができ、現在のスナップショットを REST Catalog 側で解決できる点が大きな違いです。今回の検証でも、Snowflake 側で INSERT したデータを ADB 側から確認できました。
また、ADB 上に同期ビューを作成することで、Select AI の object_list にも通常のデータベースオブジェクトとして指定できました。
この構成により、Snowflake-managed Iceberg を ADB から参照する際に、個別の metadata.json に依存せず、カタログを介してより扱いやすく連携できることが確認できました。