はじめに
データ分析の現場では、すべてのデータが1つのデータベースにきれいに収まっているとは限りません。DWH、クラウドストレージ上のデータレイク、業務アプリケーションのデータベースなど、データはさまざまな場所に分散しています。
こうした分散したデータを扱ううえで、Apache Icebergのようなオープンテーブル形式は有効な選択肢になります。Icebergを使うと、AWS S3などのオブジェクトストレージ上に、複数の分析基盤から扱いやすいテーブル形式でデータを保持できます。
OCI Autonomous Databaseでは、クラウド上のIcebergテーブルを外部表として参照することができます。そのため、データをコピーすることなく、外部データであるIceberg形式のデータをOracle Database内のデータと同じSQLの世界で扱うことができます。さらにSELECT AI(NL2SQL)機能を組み合わせることで、Iceberg外部表に対しても自然言語からSQLを生成し、問い合わせることもできます。
今回試すのは、Snowflakeで作成したIcebergテーブルをAWS S3に保存し、それをAutonomous Databaseから外部表として参照したうえで、SELECT AIで自然言語検索する構成です。さらに、Oracle Database内のローカル業務データも追加し、S3上のIceberg外部表と統合することで、外部データと内部データをまたいだ分析にも発展させます。
(今回は外部表を作成するやり方で実施しています。ADBのカタログにIcebergテーブルのカタログをマウントする方法では以下の記事で試しています。併せてご参照ください。)
本記事は前編・後編の2本に分け、以下の流れで進めます。
-
前編 (本記事)
- SnowflakeでApache Icebergテーブルを作成する(AWS S3)
- OCI Autonomous DatabaseからS3上のIcebergデータを外部表として参照する
- SELECT AIでIceberg外部表に自然言語で問い合わせる
-
- Oracle Database内に売上、マーケティング、サポート問い合わせのローカルデータを追加する
- Iceberg外部表とOracle DB内データを統合した
V_CUSTOMER_360ビューを作成する
-統合データに対して横断的に問い合わせを行い顧客分析を試す
全体像
今回の全体像は以下の通りです。
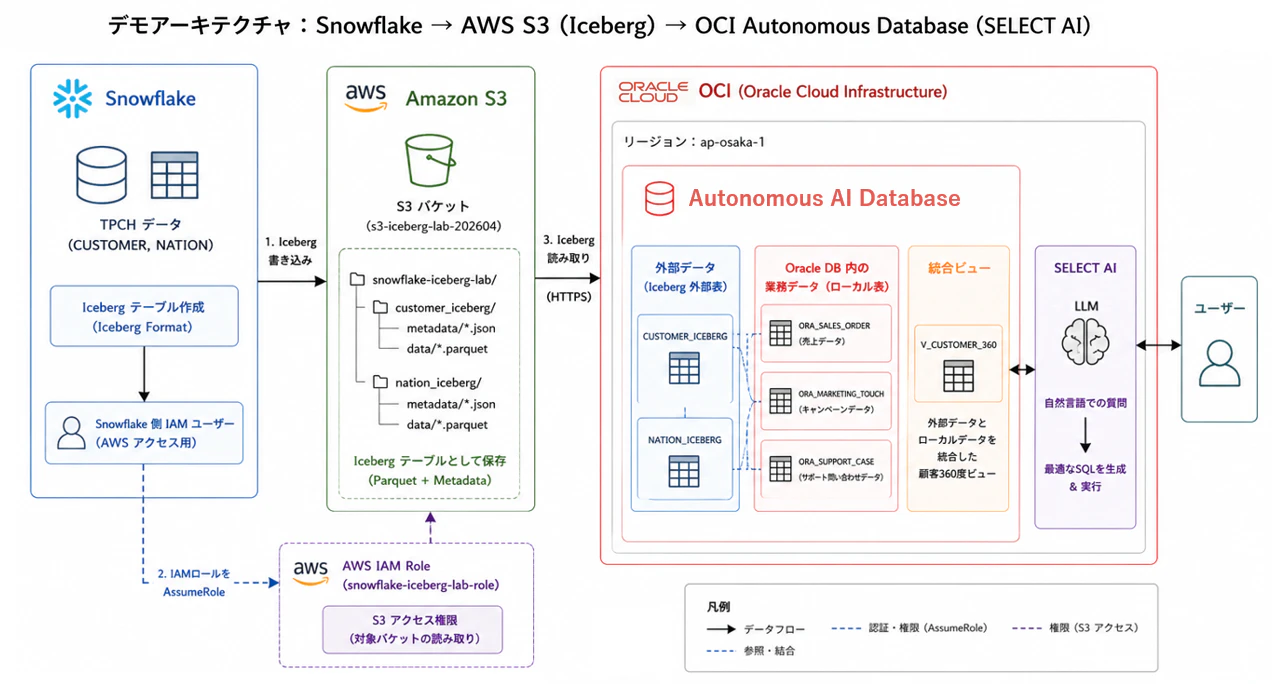
Snowflake
↓ Iceberg形式で書き込み
AWS S3 bucket
↓ metadata jsonを指定して外部表として読む
OCI Autonomous Database
↓ SELECT AI
OCI Generative AI
■ Part A. AWS S3を作る
1. S3バケットを作る
AWSコンソールで次の順に進みます。
AWS Console
→ S3
→ Create bucket
バケットを作成します。今回はs3-iceberg-lab-202604というバケットを作成しました。
作成後、バケットの中にフォルダを作ります。
snowflake-iceberg-lab/
■ Part B. SnowflakeがS3へ書けるようにする
2. AWS IAMポリシーを作る
AWSコンソールで次の順に進みます。
AWS Console
→ IAM
→ Policies
→ Create policy
→ JSON
ポリシーエディタに以下を貼ります。
YOUR_BUCKET_NAME は自分のS3バケット名に置き換えてください。
こちらをクリックして表示
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SnowflakeWriteObjects",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME/snowflake-iceberg-lab/*"
},
{
"Sid": "SnowflakeListBucket",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME",
"Condition": {
"StringLike": {
"s3:prefix": [
"snowflake-iceberg-lab",
"snowflake-iceberg-lab/*"
]
}
}
}
]
}
ポリシー名をここでは、snowflake-iceberg-lab-s3-policy にします。
Snowflake-managed Iceberg tableでS3へ書き込む場合、PUT、GET、LIST、DELETE系の権限が必要です。
3. Snowflake用IAMロールを作る
AWSコンソールで次の順に進みます。
IAM
→ Roles
→ Create role
最初は仮で作ります。
Trusted entity type: AWS account
An AWS account: This account
Require external ID: ON
External ID: iceberg-lab-external-id
次の画面で、先ほど作ったポリシーを付けます。
snowflake-iceberg-lab-s3-policy
ロール名をここでは、snowflake-iceberg-lab-role にします。
作成したら、Role ARNをコピーしておきます。
arn:aws:iam::123456789012:role/snowflake-iceberg-lab-role
■ Part C. SnowflakeでIcebergテーブルを作る
4. SnowflakeでWarehouseとDBを作る
詳しい手順はこちらをクリック👇
トライアル環境で行いました。
SnowflakeのSnowsightでWorksheetを開きます。
最初にこのSQLを実行します。
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE WAREHOUSE ICEBERG_TUTORIAL_WH
WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE OR REPLACE DATABASE ICEBERG_TUTORIAL_DB;
USE WAREHOUSE ICEBERG_TUTORIAL_WH;
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
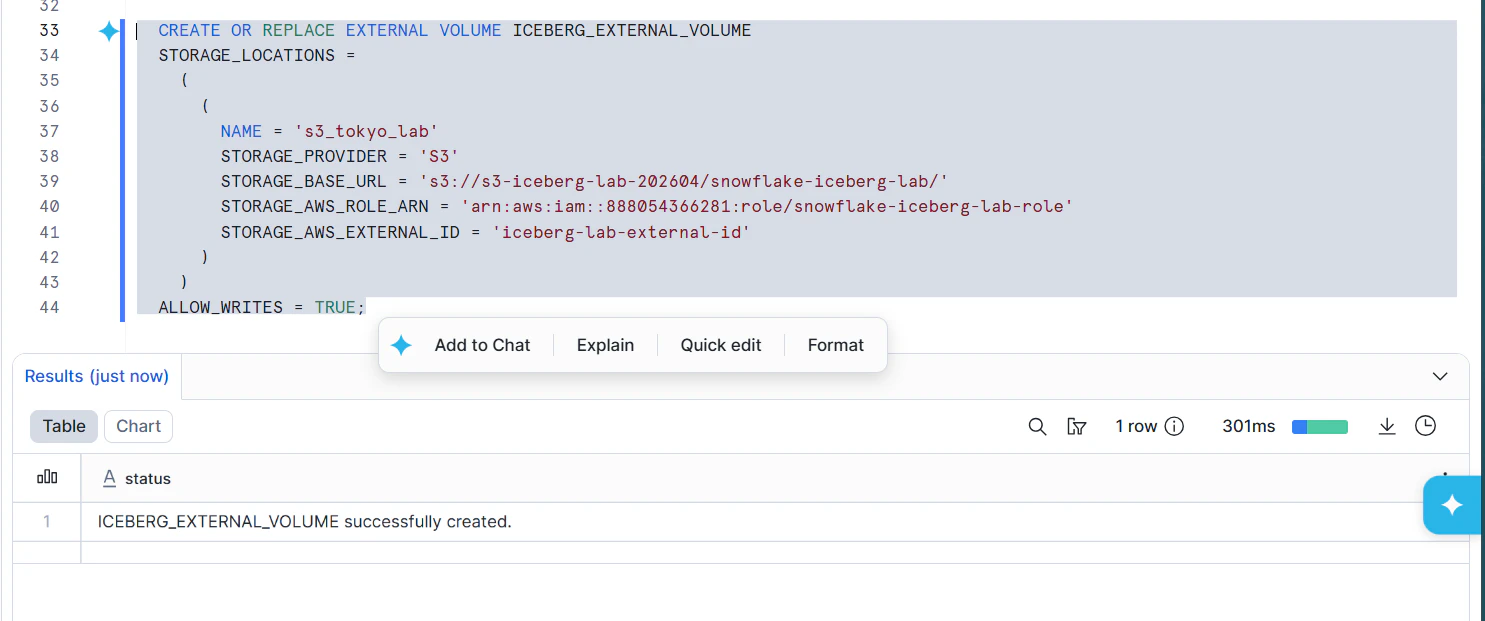
5. Snowflake external volumeを作る
詳しい手順はこちらをクリック👇
先ほどコピーしたAWS IAMロールARNを確認します。
YOUR_BUCKET_NAME と STORAGE_AWS_ROLE_ARN を置き換えて実行します。
CREATE OR REPLACE EXTERNAL VOLUME ICEBERG_EXTERNAL_VOLUME
STORAGE_LOCATIONS =
(
(
NAME = 's3_tokyo_lab'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://YOUR_BUCKET_NAME/snowflake-iceberg-lab/'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::123456789012:role/snowflake-iceberg-lab-role'
STORAGE_AWS_EXTERNAL_ID = 'iceberg-lab-external-id'
)
)
ALLOW_WRITES = TRUE;
次に、Snowflakeが使うAWS IAMユーザーARNを確認します。
DESC EXTERNAL VOLUME ICEBERG_EXTERNAL_VOLUME_DD
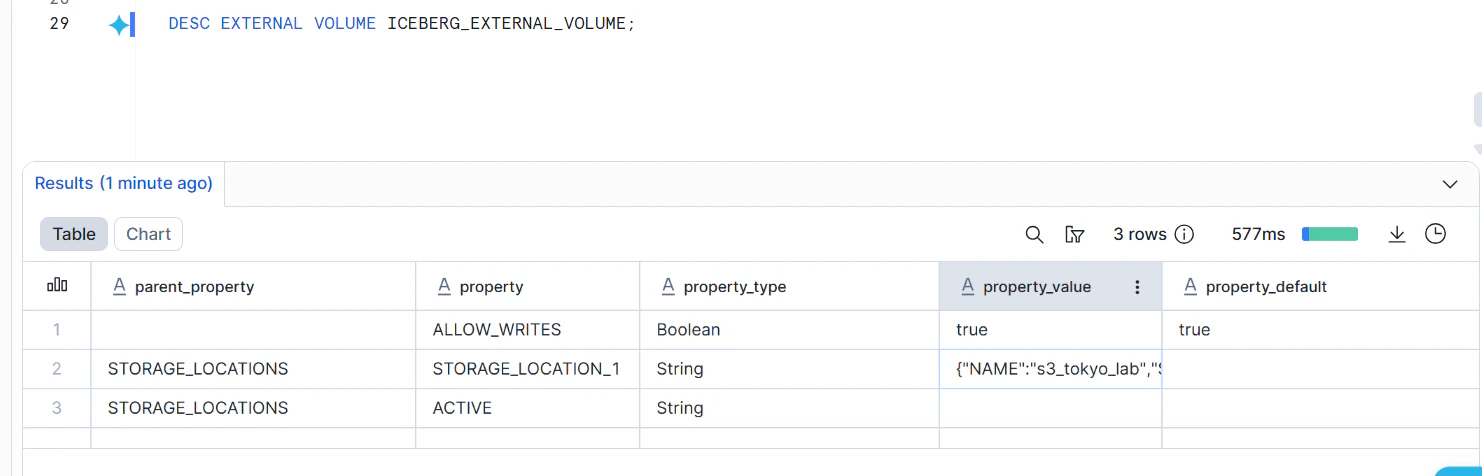
結果の中から、次の値を探してメモしておきます。
STORAGE_AWS_IAM_USER_ARN
STORAGE_AWS_EXTERNAL_ID
6. AWS IAMロールの信頼ポリシーを更新する
AWSコンソールに戻ります。
IAM
→ Roles
→ snowflake-iceberg-lab-role
→ Trust relationships
→ Edit trust policy
次のようにします。
こちらをクリックして表示👇
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SnowflakeAssumeRole",
"Effect": "Allow",
"Principal": {
"AWS": "ここにSnowflakeのSTORAGE_AWS_IAM_USER_ARNを貼る"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "iceberg-lab-external-id"
}
}
}
]
}
入力した後、保存します。
Snowflakeに戻り、外部ボリュームを確認します。
SELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('ICEBERG_EXTERNAL_VOLUME');
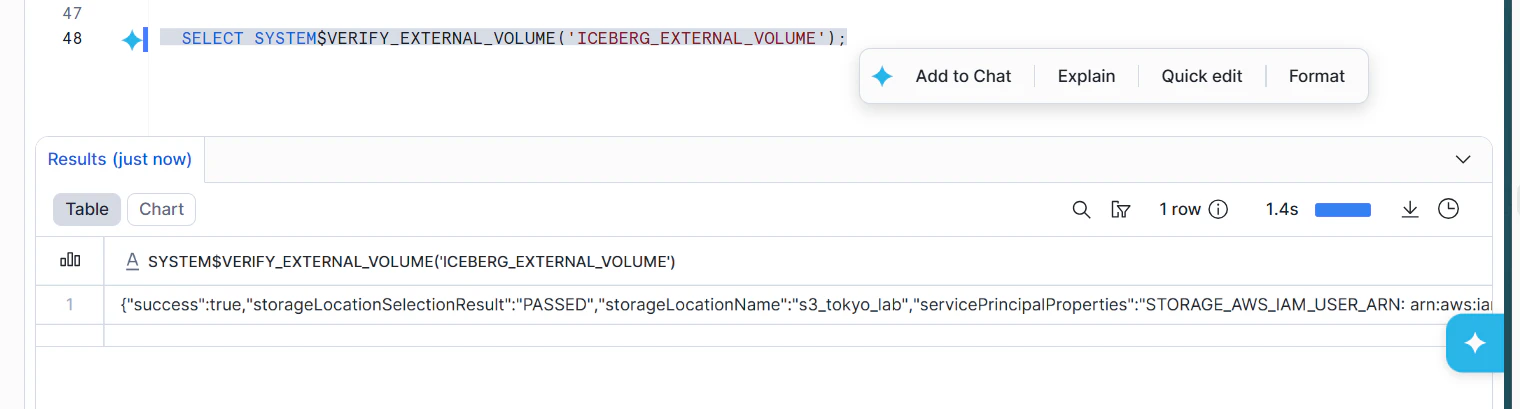
Iceberg external volume(S3)が確認できました。
7. Icebergテーブルの作成
ここではSnowflakeサンプルデータの TPCH_SF1.CUSTOMER とTPCH_SF1.NATION を使います。
Snowflakeで次を実行します。
USE ROLE ACCOUNTADMIN;
USE WAREHOUSE ICEBERG_TUTORIAL_WH;
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
CREATE OR REPLACE ICEBERG TABLE CUSTOMER_ICEBERG (
C_CUSTKEY INTEGER,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INTEGER,
C_PHONE STRING,
C_ACCTBAL NUMBER(12, 2),
C_MKTSEGMENT STRING,
C_COMMENT STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'ICEBERG_EXTERNAL_VOLUME'
BASE_LOCATION = 'customer_iceberg';
CREATE OR REPLACE ICEBERG TABLE NATION_ICEBERG (
N_NATIONKEY INTEGER,
N_NAME STRING,
N_REGIONKEY INTEGER,
N_COMMENT STRING
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'ICEBERG_EXTERNAL_VOLUME'
BASE_LOCATION = 'nation_iceberg';
2つの表ができました。
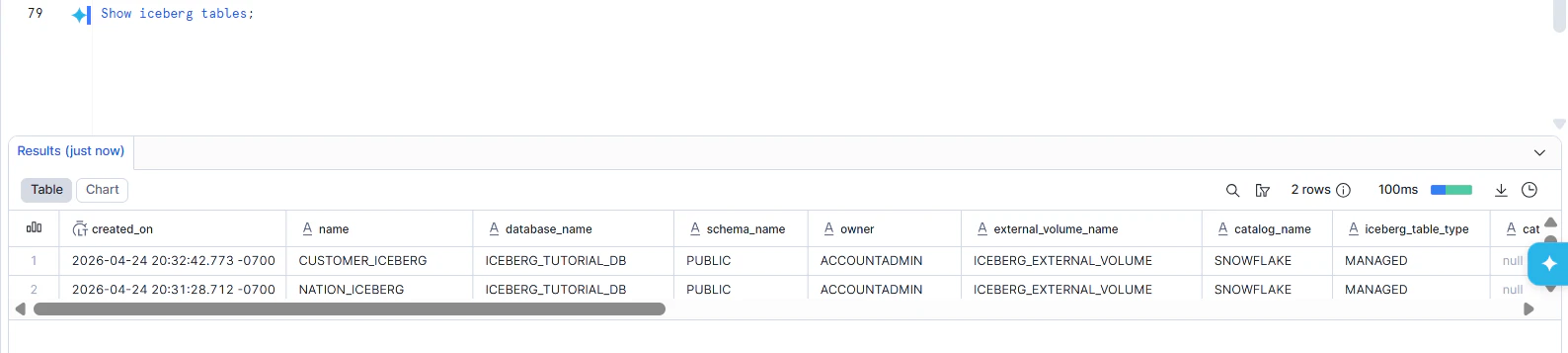
Icebergテーブルにデータを挿入します。
INSERT INTO CUSTOMER_ICEBERG
SELECT
C_CUSTKEY,
C_NAME,
C_ADDRESS,
C_NATIONKEY,
C_PHONE,
C_ACCTBAL,
C_MKTSEGMENT,
C_COMMENT
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;
INSERT INTO NATION_ICEBERG
SELECT
N_NATIONKEY,
N_NAME,
N_REGIONKEY,
N_COMMENT
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.NATION;
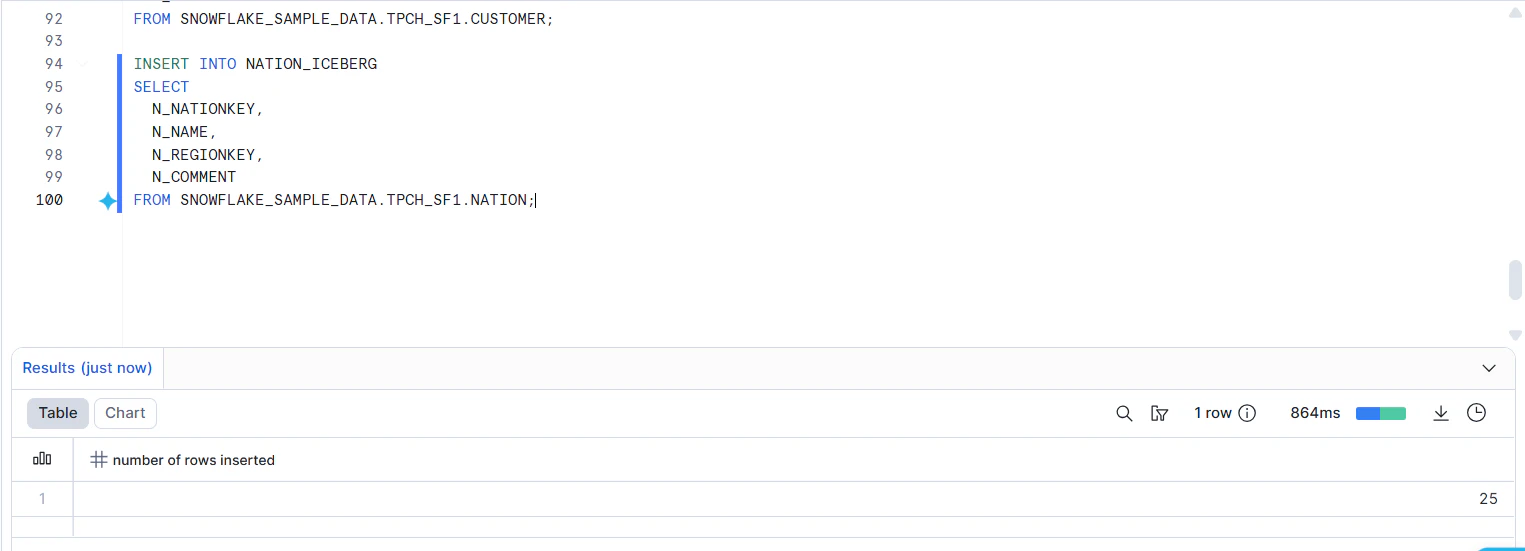
動作確認をします。
SELECT
c.C_NAME AS customer_name,
c.C_MKTSEGMENT AS market_segment,
n.N_NAME AS nation
FROM CUSTOMER_ICEBERG c
INNER JOIN NATION_ICEBERG n
ON c.C_NATIONKEY = n.N_NATIONKEY
LIMIT 15;
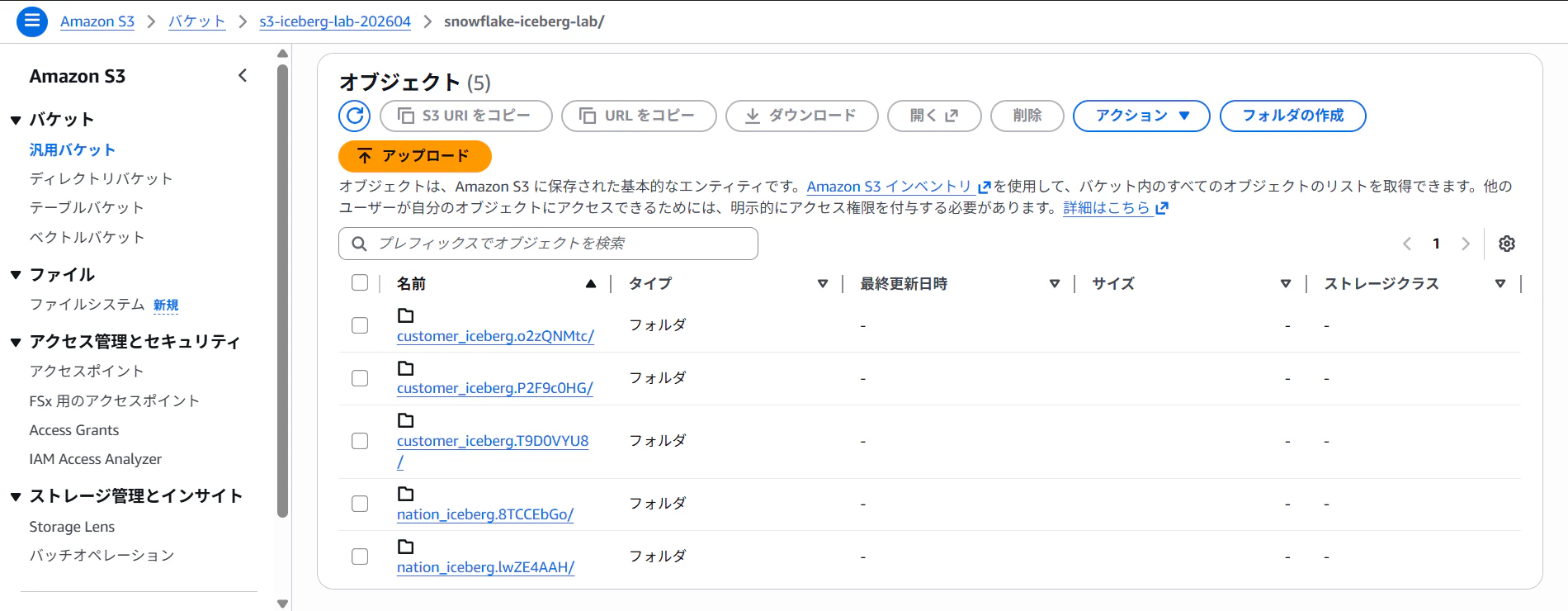
S3のバケット内を見ると、データが出来ていることを確認できます。
8. Iceberg metadata JSONの場所を確認する
OCI ADBは、SnowflakeがS3に作ったIcebergの metadata json を指定して外部表を作ります。
Snowflakeで次を実行します。
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('CUSTOMER_ICEBERG') AS INFO;
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('NATION_ICEBERG') AS INFO;
作成した Iceberg テーブルの Icebergメタデータ情報を確認するSQLです。
CUSTOMER_ICEBERG と NATION_ICEBERG という Iceberg テーブルについて、Snowflakeが管理している Iceberg 関連情報を取得しています。
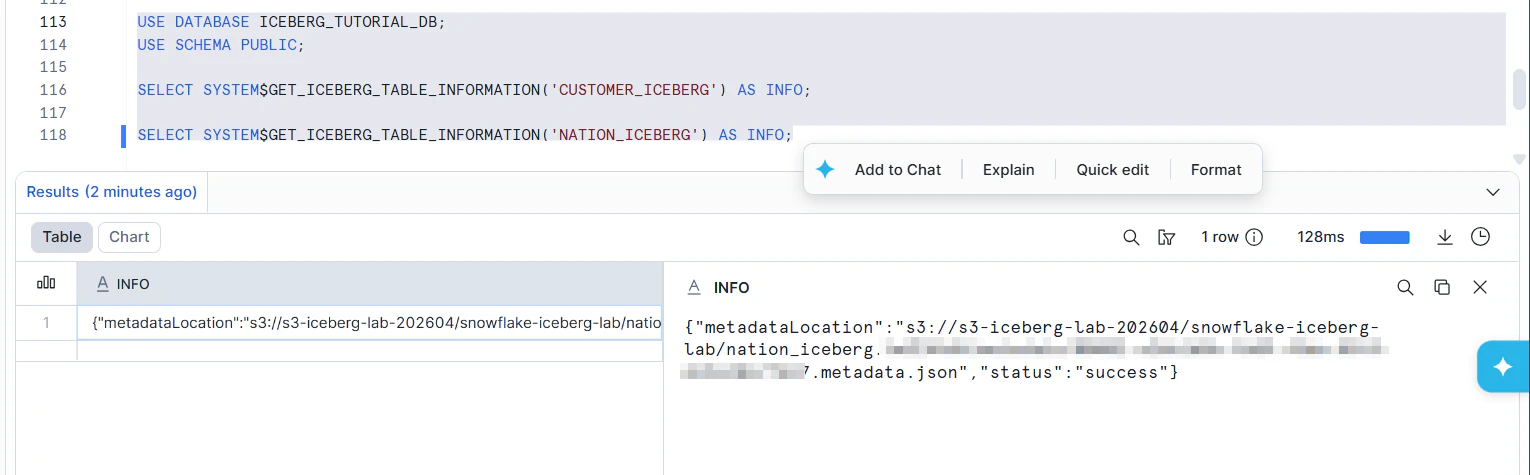
出力の中に、S3上のmetadataファイルの場所が出ます。次のようなパスです。
s3://s3-iceberg-lab-202604/snowflake-iceberg-lab/customer_iceberg.o2zQNMtc/metadata/00001-xxxxxxxxxxxxxxxx.metadata.json
これをADBで使えるHTTPS形式に変換します。
https://YOUR_BUCKET_NAME.s3.ap-northeast-1.amazonaws.com/snowflake-iceberg-lab/customer_iceberg/metadata/00001-xxxx.metadata.json
以下のようになります。CUSTOMER_ICEBERG と NATION_ICEBERG の2つ分をメモしておきます。
https://s3-iceberg-lab-202604.s3.ap-northeast-1.amazonaws.com/snowflake-iceberg-lab/customer_iceberg.o2zQNMtc/metadata/00001-xxxxxxxxxx.metadata.json
■ Part D. ADBがS3を読めるようにする
8. ADB用のS3読み取り専用IAMユーザーを作る
AWSコンソールで次の順に進みます。
IAM
→ Policies
→ Create policy
→ JSON
次のJSONを貼ります。YOUR_BUCKET_NAME を置き換えてください。
こちらをクリックして表示
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AdbReadIcebergObjects",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME/snowflake-iceberg-lab/*"
},
{
"Sid": "AdbListIcebergPrefix",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME",
"Condition": {
"StringLike": {
"s3:prefix": [
"snowflake-iceberg-lab",
"snowflake-iceberg-lab/*"
]
}
}
}
]
}
ポリシー名は次にします。
adb-s3-iceberg-read-policy
次にIAMユーザーを作ります。
IAM
→ Users
→ Create user
設定例です。
User name:
adb-s3-iceberg-reader
Attach policies directly:
adb-s3-iceberg-read-policy
作成後、アクセスキーを作ります。
adb-s3-iceberg-reader
→ Security credentials
→ Access keys
→ Create access key
用途はCLIなどを選びます。作成後に表示される次の2つを安全な場所に一時保存します。
AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY
このキーはADBに登録します。
■ Part E. OCI Autonomous Databaseを用意する
9. ADBの作成
Autonomous AI Database (26ai・レイクハウス)を作成します。
作成されたらDatabase Actionsを開きます。
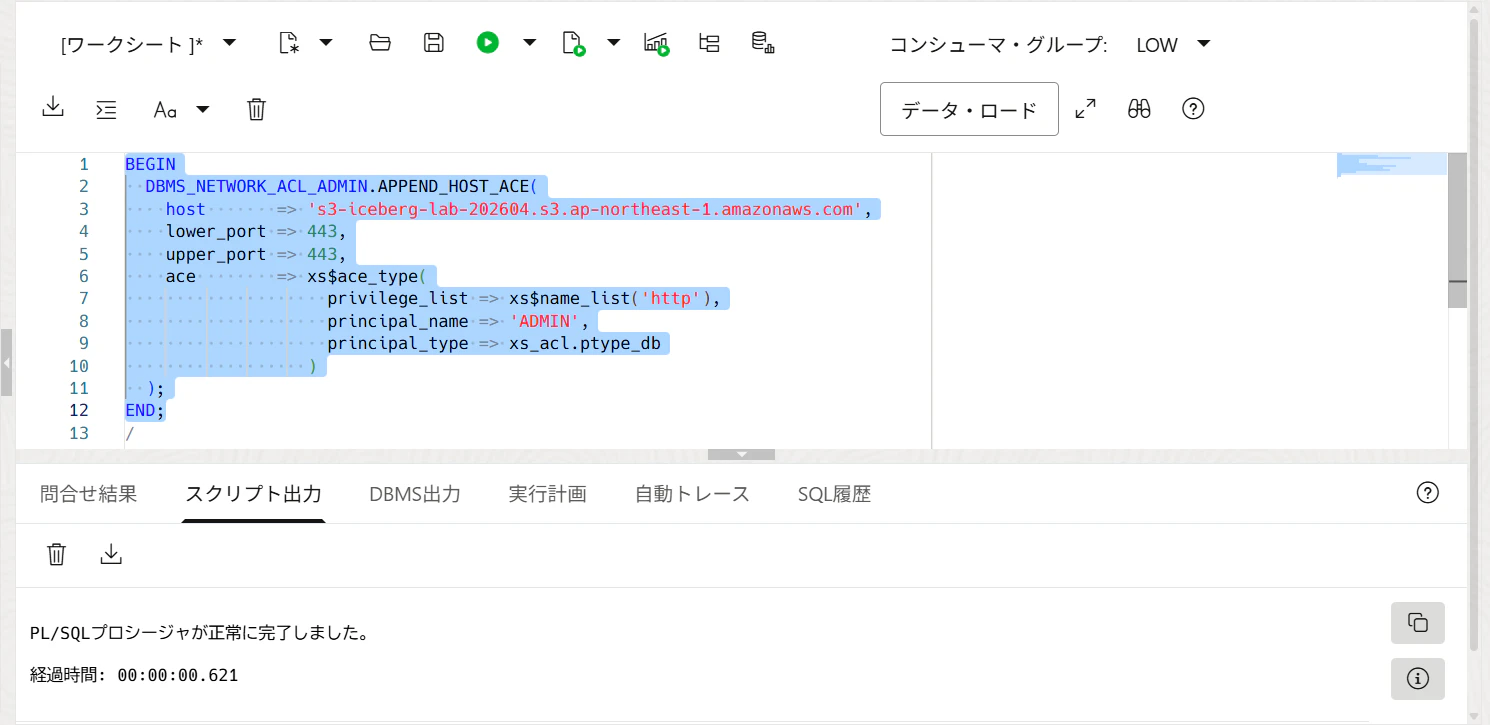
10. ADBからS3へHTTPSアクセスできるようにACLを追加する
ADBで次を実行します。YOUR_BUCKET_NAME を置き換えます。
外部サービスにアクセスするスキーマへネットワークACLを付与する必要があり、AWS S3の場合はS3ホスト名へのアクセスを許可します。
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'YOUR_BUCKET_NAME.s3.ap-northeast-1.amazonaws.com',
lower_port => 443,
upper_port => 443,
ace => xs$ace_type(
privilege_list => xs$name_list('http'),
principal_name => 'ADMIN',
principal_type => xs_acl.ptype_db
)
);
END;
/
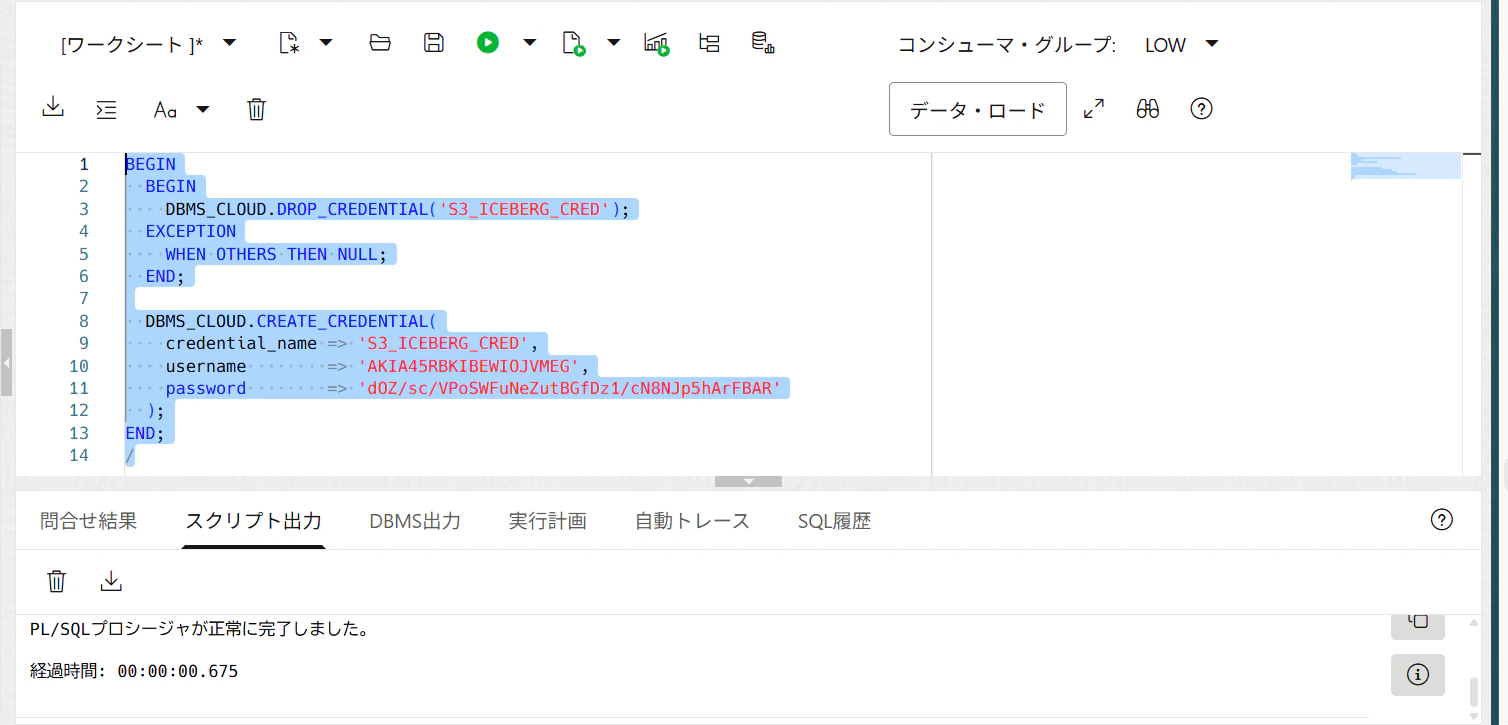
11. ADBにS3 credentialを作る
ADB上でSQL実行します。
BEGIN
BEGIN
DBMS_CLOUD.DROP_CREDENTIAL('S3_ICEBERG_CRED');
EXCEPTION
WHEN OTHERS THEN NULL;
END;
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'S3_ICEBERG_CRED',
username => 'AWS_ACCESS_KEY_IDをここに貼る',
password => 'AWS_SECRET_ACCESS_KEYをここに貼る'
);
END;
/
AWSアクセスキーIDを username、シークレットアクセスキーを password として DBMS_CLOUD.CREATE_CREDENTIAL に登録します。
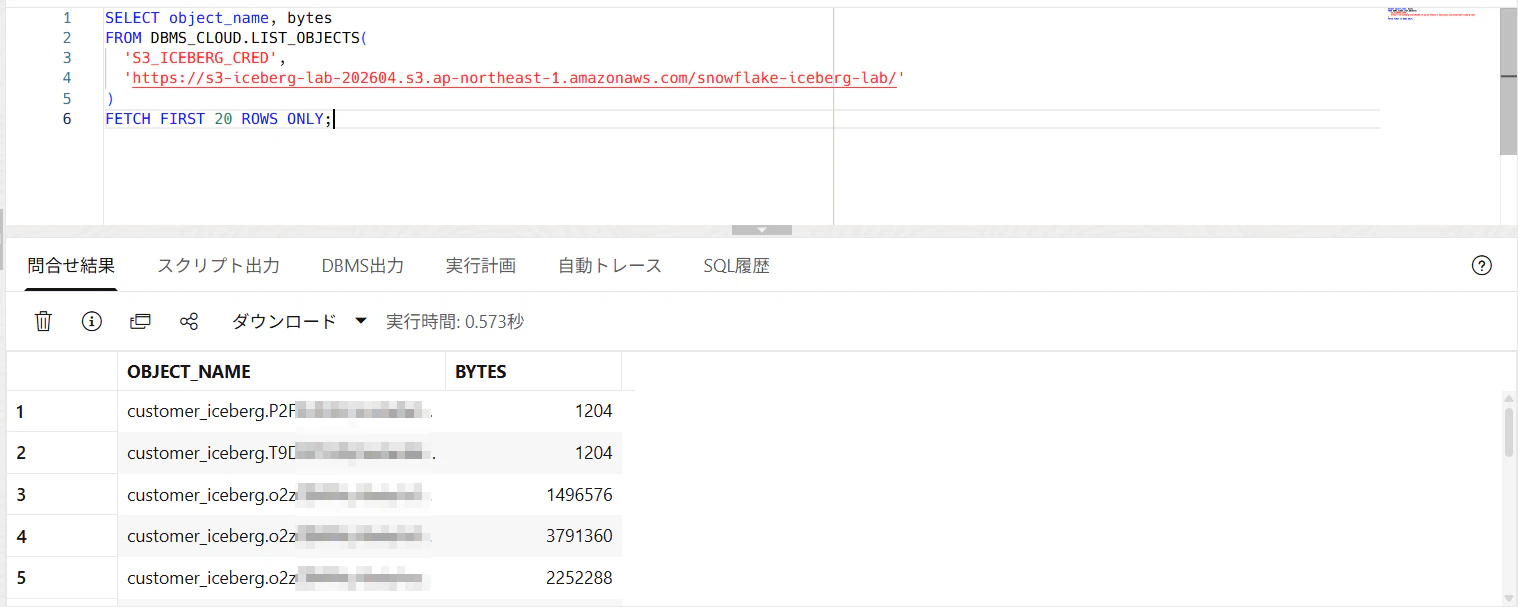
ADBからS3を参照できるか確認します。
SELECT object_name, bytes
FROM DBMS_CLOUD.LIST_OBJECTS(
'S3_ICEBERG_CRED',
'https://YOUR_BUCKET_NAME.s3.ap-northeast-1.amazonaws.com/snowflake-iceberg-lab/'
)
FETCH FIRST 20 ROWS ONLY;
DBMS_CLOUD.LIST_OBJECTS は、指定したクラウドストレージの中にあるファイル一覧を返します。
参照できました。
■ Part F. ADBでIceberg外部表を作る
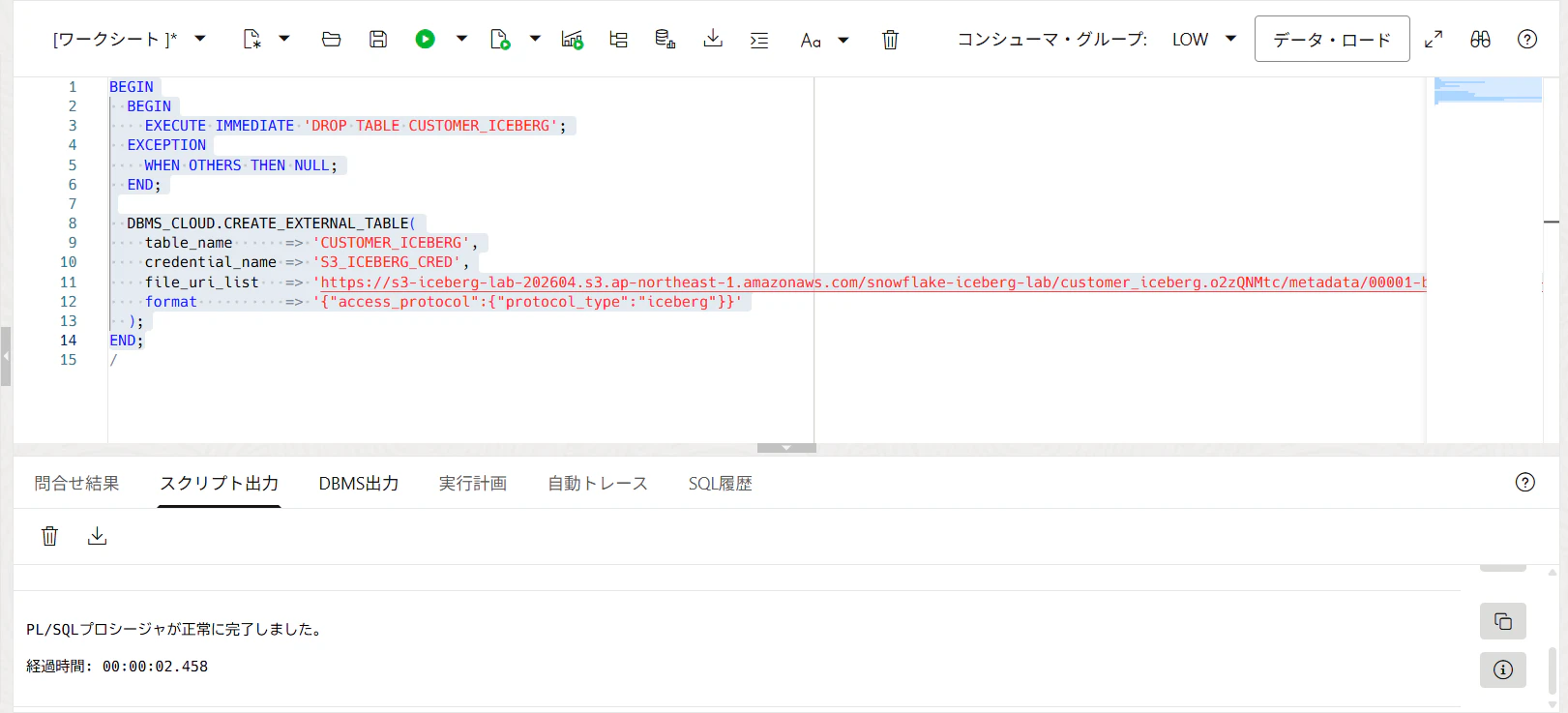
12. CUSTOMER_ICEBERG外部表を作る
Snowflakeで取得した CUSTOMER_ICEBERG のmetadata JSON URLを使います。
BEGIN
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE CUSTOMER_ICEBERG';
EXCEPTION
WHEN OTHERS THEN NULL;
END;
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name => 'CUSTOMER_ICEBERG',
credential_name => 'S3_ICEBERG_CRED',
file_uri_list => 'https://YOUR_BUCKET_NAME.s3.ap-northeast-1.amazonaws.com/snowflake-iceberg-lab/customer_iceberg/metadata/00001-xxxx.metadata.json',
format => '{"access_protocol":{"protocol_type":"iceberg"}}'
);
END;
/
Icebergのmetadata JSONを file_uri_list に指定し、format に {"access_protocol":{"protocol_type":"iceberg"}} を指定して外部表を作成します。
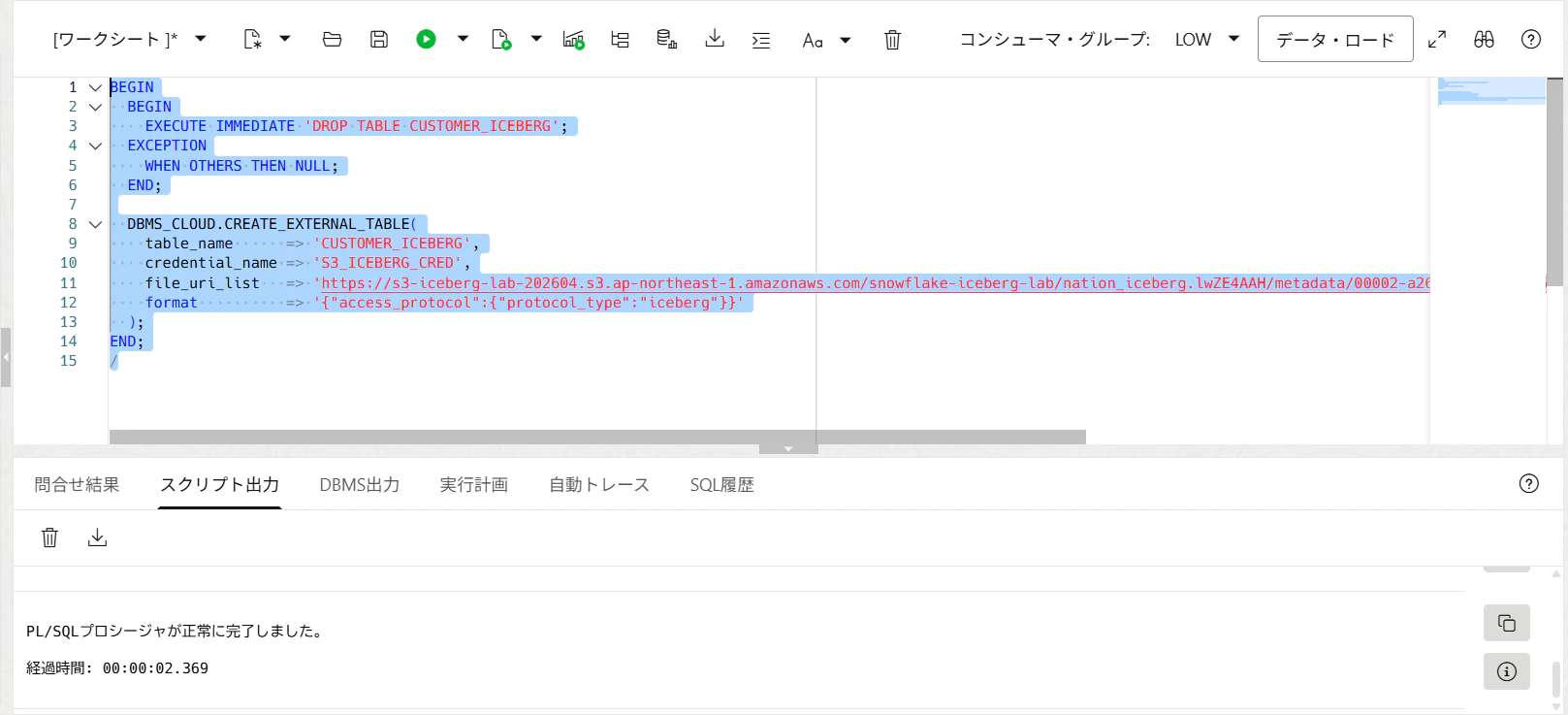
13. NATION_ICEBERG外部表を作る
同じく、NATION_ICEBERG のmetadata JSON URLを入れます。
14. ADBから読めるか確認する
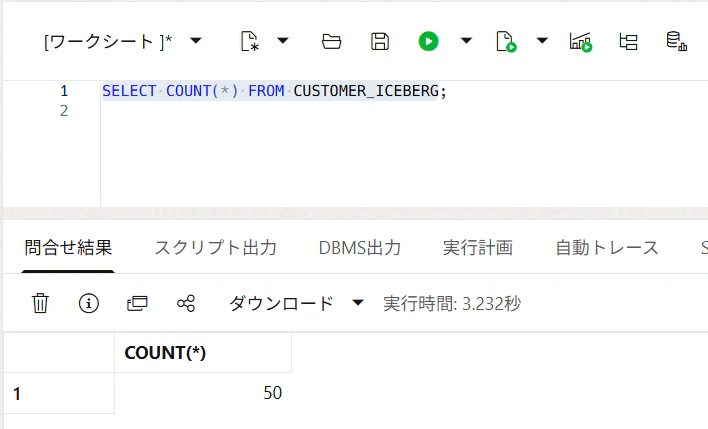
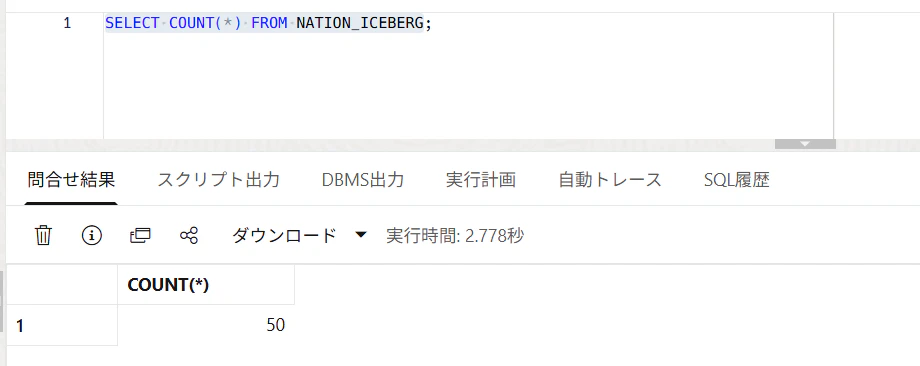
まず件数を確認します。
SELECT COUNT(*) FROM CUSTOMER_ICEBERG;
SELECT COUNT(*) FROM NATION_ICEBERG;
列名も確認してみます。
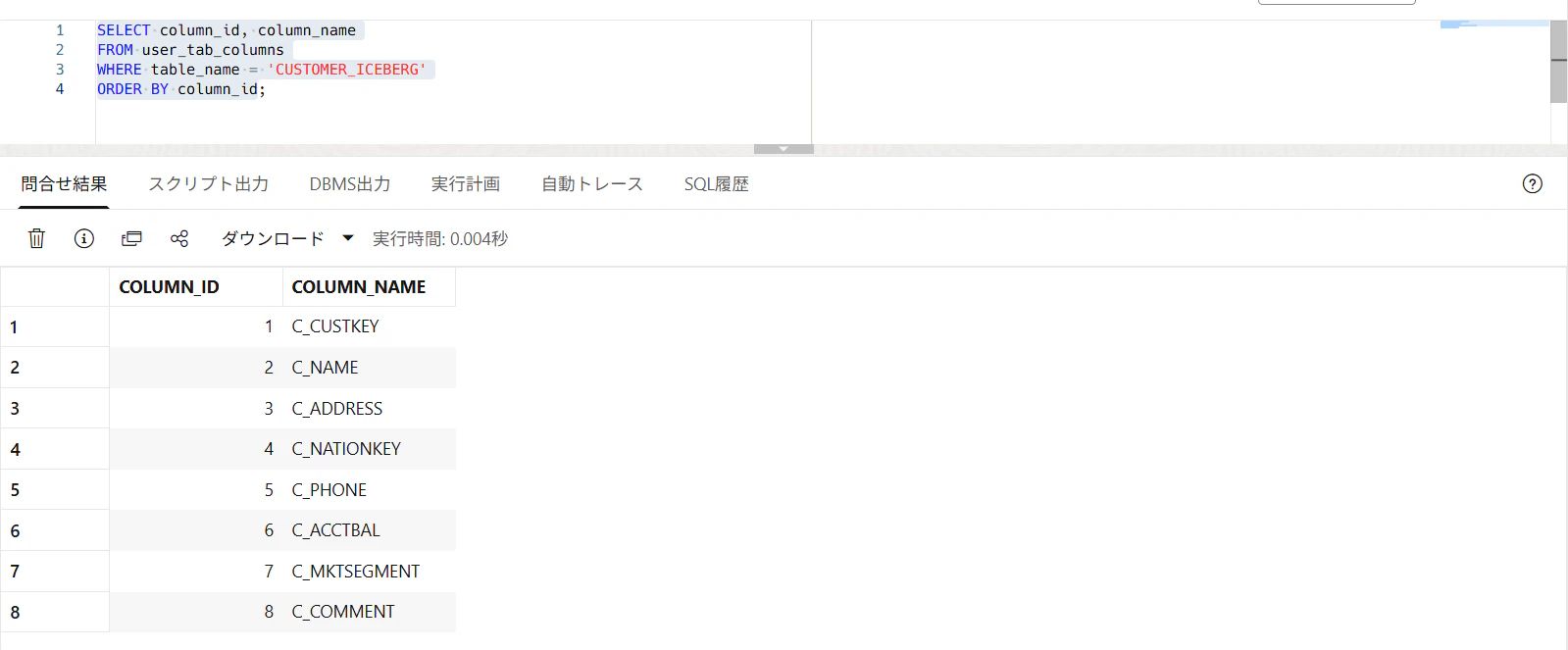
SELECT column_id, column_name
FROM user_tab_columns
WHERE table_name = 'CUSTOMER_ICEBERG'
ORDER BY column_id
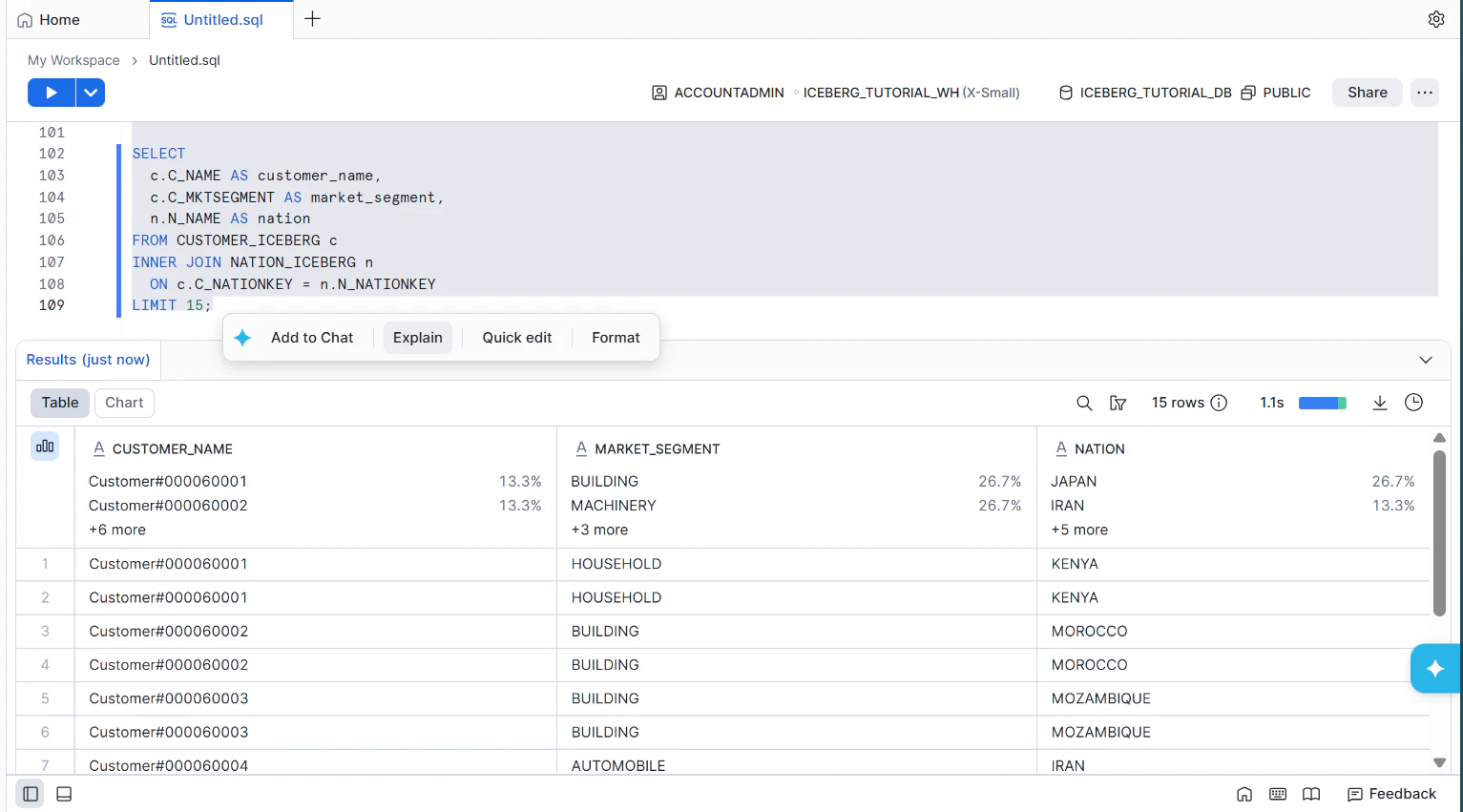
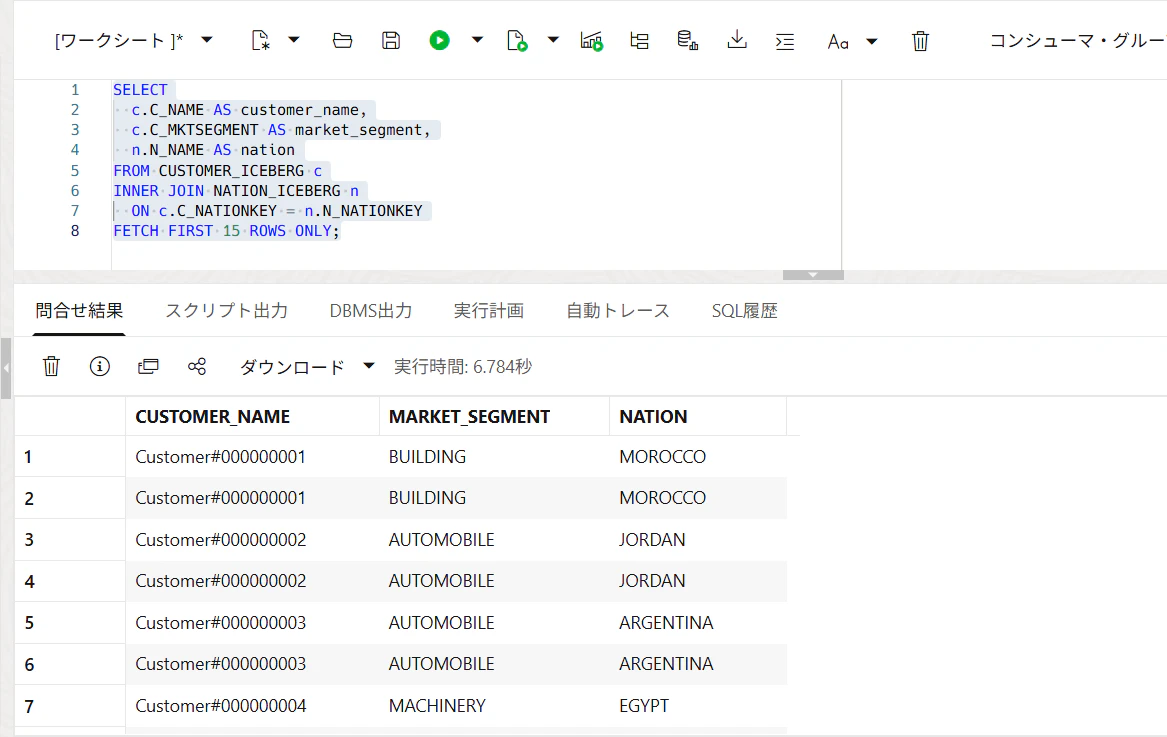
では、2つのテーブルから、顧客の国キーで結合して、顧客名・市場セグメント・国名を表示してみます。
SELECT
c.C_NAME AS customer_name,
c.C_MKTSEGMENT AS market_segment,
n.N_NAME AS nation
FROM CUSTOMER_ICEBERG c
INNER JOIN NATION_ICEBERG n
ON c.C_NATIONKEY = n.N_NATIONKEY
FETCH FIRST 15 ROWS ONLY;
この方式はmetadata JSONを直接指定するため、Snowflake側であとからINSERTやDELETEをした場合、ADB側は自動で最新スナップショットを追いかけません。更新後はSnowflakeで新しいmetadata JSONの場所を取り直して、ADBの外部表を作り直してください。Oracleドキュメントでも、metadata JSON直接指定方式はポイントインタイムであり、新しいスナップショットやスキーマ変更後は外部表の再作成が必要とされています。
■ Part G. SELECT AIを使う
SELECT AIは、AI profileを作成し、LLMに自然言語からSQLを生成・実行させる機能です。SELECT AIのprofileで対象オブジェクトを指定でき、外部表も対象にできます。
15. OCI Generative AIのIAMポリシーを確認する
OCIユーザーがAdministratorグループに入っていない場合は、以下のポリシー設定をします。
allow group <your-group-name> to manage generative-ai-family in compartment <your-compartment-name>
16. OCI APIキーを作る
OCIコンソールで、APIキーを作成します。
メモするものは4つです。
User OCID
Tenancy OCID
Fingerprint
Private key
17. ADBにOCI Generative AI credentialを作る
ADB SQLで実行します。
BEGIN
BEGIN
DBMS_CLOUD.DROP_CREDENTIAL('OCI_GENAI');
EXCEPTION
WHEN OTHERS THEN NULL;
END;
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'OCI_GENAI',
user_ocid => 'ocid1.user.oc1..xxxxx',
tenancy_ocid => 'ocid1.tenancy.oc1..xxxxx',
private_key => '-----BEGIN PRIVATE KEY-----
ここに秘密鍵
-----END PRIVATE KEY-----',
fingerprint => 'xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx'
);
END;
\
18. AI profileを作る
BEGIN
BEGIN
DBMS_CLOUD_AI.DROP_PROFILE('GENAI_XAI');
EXCEPTION
WHEN OTHERS THEN NULL;
END;
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'GENAI_XAI',
attributes => '{
"provider" : "oci",
"credential_name" : "OCI_GENAI",
"model" : "xai.grok-4",
"region" : "us-chicago-1",
"comments" : true,
"conversation" : "TRUE",
"object_list": [
{"owner": "ADMIN", "name": "CUSTOMER_ICEBERG"},
{"owner": "ADMIN", "name": "NATION_ICEBERG"}
]
}'
);
END;
/
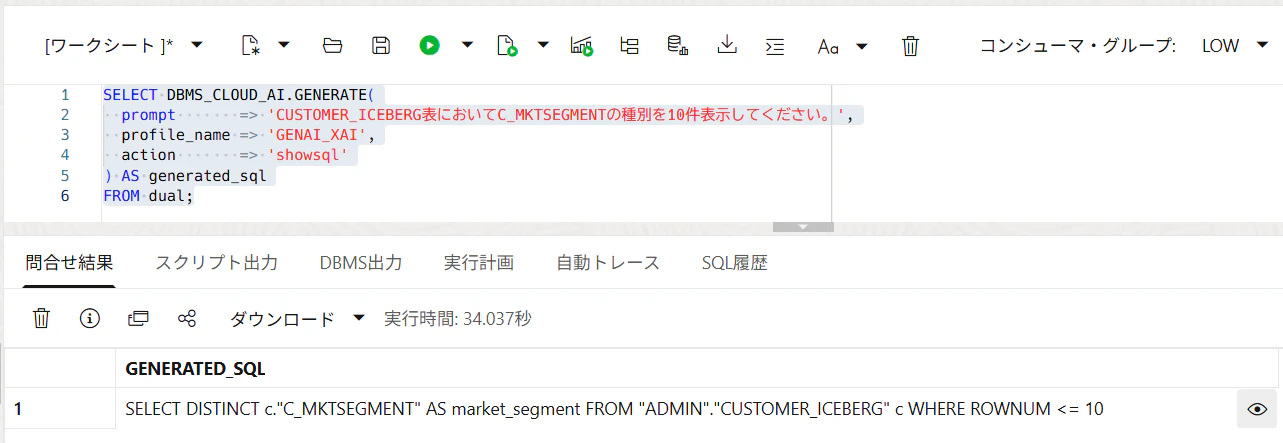
19. まず showsql でSQLだけ生成する
SELECT DBMS_CLOUD_AI.GENERATE(
prompt => 'CUSTOMER_ICEBERG表においてC_MKTSEGMENTの種別を10件表示してください。',
profile_name => 'GENAI_XAI',
action => 'showsql'
) AS generated_sql
FROM dual;
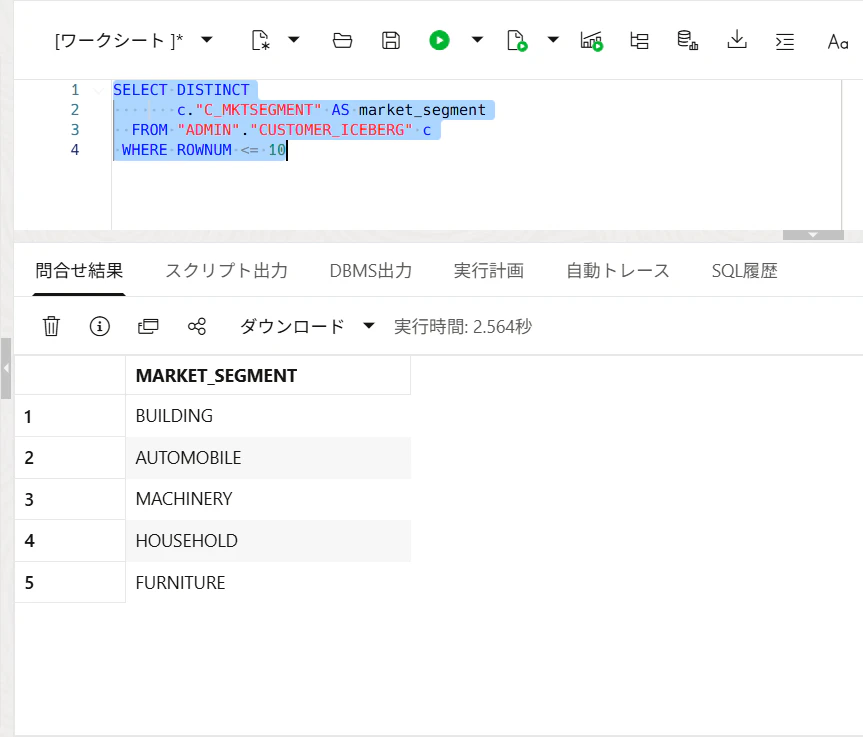
生成されたSQLを実行して確認してみます。
20. 自然言語で回答させる
パラメータを
action => 'runsql'
に変更して実行してみます。
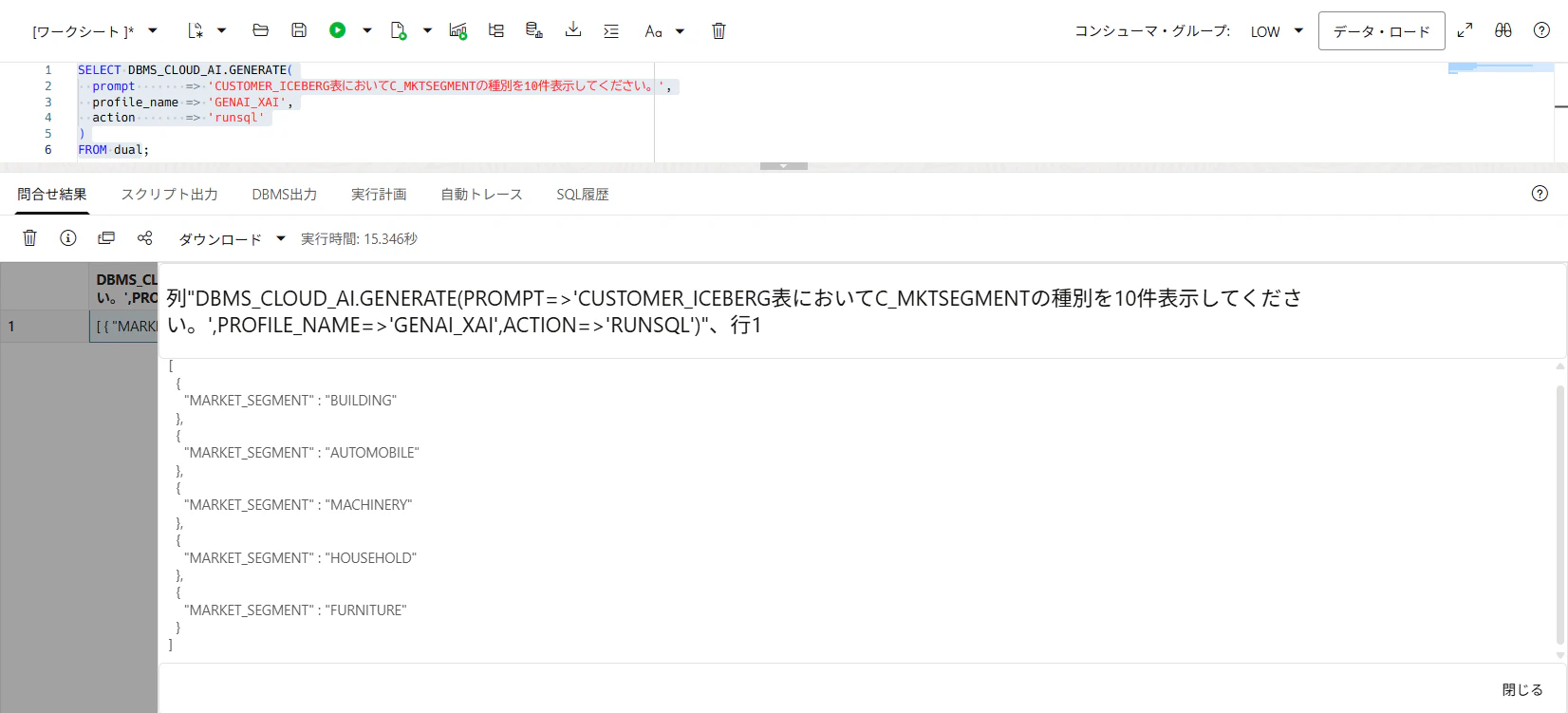
narrateに変更して実行してみます。
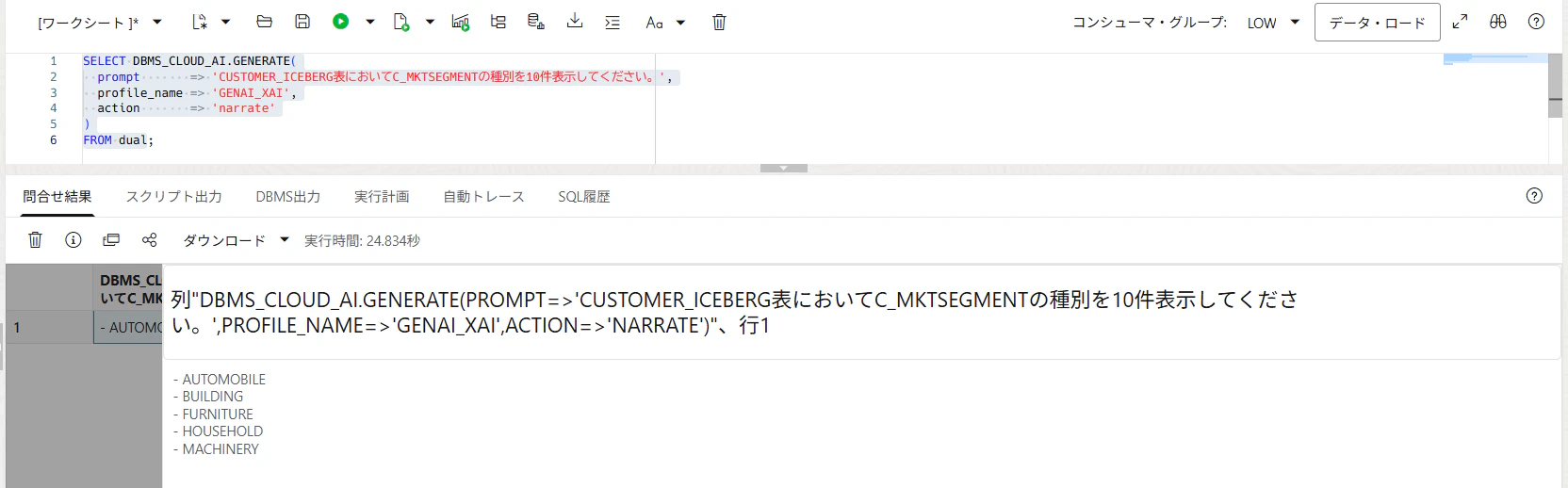
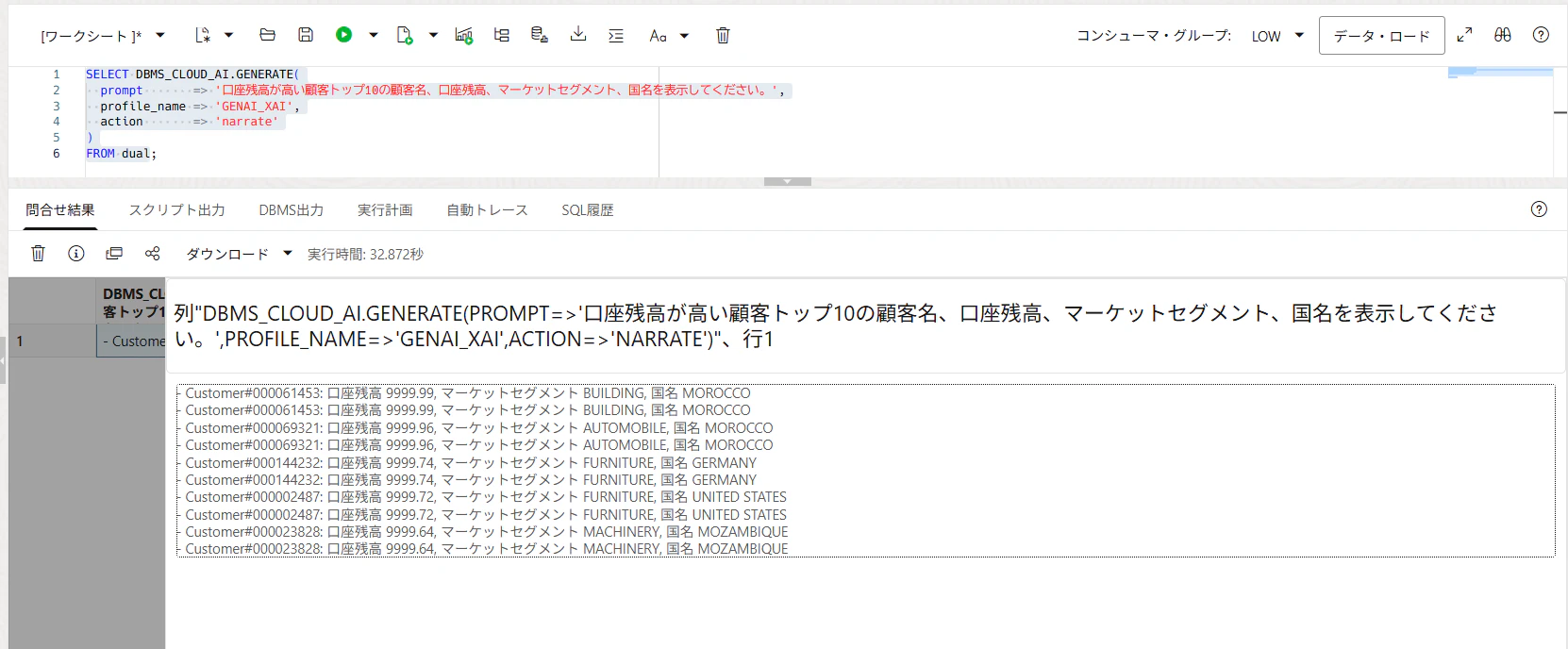
以下の問い合わせをしてみます。
SELECT DBMS_CLOUD_AI.GENERATE(
prompt => '口座残高が高い顧客トップ10の顧客名、口座残高、マーケットセグメント、国名を表示してください。',
profile_name => 'GENAI_XAI',
action => 'narrate'
)
FROM dual;
まとめ
前編では、Snowflakeで作成したIcebergテーブルをAWS S3に保存し、それをOCI Autonomous Databaseから外部表として参照しました。
さらにSELECT AIを設定することで、S3上のIcebergデータに対して自然言語で問い合わせるところまで確認できました。
今回のポイントは、データをADBへ物理的にロードするのではなく、S3上のIcebergデータを外部表として参照している点です。これにより、データレイク上のデータをOracle DatabaseのSQLやSELECT AIから扱えるようになります。
一方で、AI活用を見据えると、一つのデータ基盤上のデータだけで分析が完結することは少ないと思います。顧客情報の一部はデータレイクにあり、売上や問い合わせ履歴は業務DBにある、というように、データが複数の場所に分かれているケースが一般的です。
そこで後編では、ADB内に売上、マーケティング、サポート問い合わせのローカル表を追加し、今回作成したIceberg外部表と統合します。最終的には、外部データとOracle DB内の業務データを組み合わせた V_CUSTOMER_360 ビューを作成し、SELECT AIから自然言語で横断的に問い合わせてみます。
後編はこちら👇
参考
本記事はこちらのシナリオを参考にさせて頂き進めました。ありがとうございます!