■ はじめに
今回はIceberg入門として、
- 背景
- Apache Iceberg誕生の目的
- Apache Icebergの基本的な考え方
- Apache Icebergのアーキテクチャ
- Apache Icebergの主な機能
をまとめてみました。
■ 背景
まず前提として、Icebergが誕生する背景を簡単におさらいします。
Iceberg以前から使われていたHiveテーブルフォーマットは、データレイク上のファイルをテーブルとして扱うために広く使われてきました。一方で、テーブルを個々のデータファイルではなく、ディレクトリ構造をもとに管理するという設計には限界がありました。
Hiveの仕組みや課題の詳細は、前提知識として以下の記事で整理しています。
ここでは、その課題を受けて登場したモダンなテーブルフォーマットに焦点を当てます。
Iceberg、Apache Hudi、Delta Lakeなどの新しいテーブルフォーマットは、Hiveの制約を解決するために作られました。これらは、テーブルをディレクトリ単位ではなく、どのデータファイルがテーブルを構成しているのかをメタデータで正確に管理する方式を採用しています。
この設計により、従来のHiveテーブルフォーマットでは難しかった次のような機能が実現しやすくなりました。
-
ACIDトランザクション
- 処理が完全に成功するか、完全に取り消されるかを保証できる
-
複数ライターへの対応
- 複数の書き込み処理が同時に走っても、データの一貫性を保ちやすい
-
メタデータと統計情報の改善
- クエリエンジンが不要なファイルを避け、必要なファイルだけを効率よくスキャンできる
-
タイムトラベル
- 過去のある時点のテーブル状態を参照できる
つまり、モダンなテーブルフォーマットは、データレイク上のファイル群を、より安全かつ効率的に「テーブル」として扱うための仕組みです。
■ Apache Icebergとは何か?
Apache Icebergは、NetflixのRyan BlueとDaniel Weeksによって2017年に作成されたテーブルフォーマットです。
開発の背景には、Hiveテーブルフォーマットが抱えていた一貫性、パフォーマンス、同時実行性、スキーマ変更の難しさなどの課題がありました。Netflixは、Hiveの多くの問題が、テーブルをディレクトリやサブディレクトリとして管理していることに起因していると考えました。
そこでIcebergでは、テーブルをディレクトリ単位ではなく、ファイル単位で管理する方針が採用されました。
2018年にはIcebergがオープンソース化され、Apache Software Foundationに寄贈されました。その後、Apple、Dremio、AWS、Tencent、LinkedIn、Stripeなど多くの組織が関与するプロジェクトへと発展しています。
■ Apache Iceberg誕生の目的
Icebergは、従来のHiveテーブルフォーマットの制約を解消し、データレイクをよりデータウェアハウスに近い感覚で扱えるようにすることを目指して作られました。
主な目標は次の5つです。
一貫性
複数のパーティションにまたがる更新であっても、ユーザーに中途半端な状態を見せないことを重視しています。
たとえば、日次バッチで 2024-01-01 のデータを複数パーティションに書き込む場合、一部のファイルだけが追加された状態をユーザーが読んでしまうと、集計結果が不正確になります。
Icebergでは、ユーザーが見るのは更新前の状態か、更新後の状態のどちらかです。処理途中の不整合な状態は見えません。
パフォーマンス
Hiveでは、クエリ実行前に大量のファイルやディレクトリを列挙する必要があり、プランニングが遅くなることがありました。
Icebergでは、テーブルを構成するファイル情報をメタデータとして管理します。さらに、各ファイルに含まれる値の範囲や件数などの統計情報も利用できます。
そのため、たとえば user_id = 123 のような条件がある場合、関係なさそうなファイルを事前に読み飛ばし、必要なファイルだけを効率よくスキャンできます。
使いやすさ
Icebergは、ユーザーがパーティション構造などの物理的なデータ配置を意識しなくても、自然なSQLで性能上のメリットを得られることを目指しています。
たとえばHiveでは、実際には月単位でパーティションされている場合、クエリ側でも月の条件を明示しないと効率が落ちることがありました。
SELECT *
FROM events
WHERE event_time >= TIMESTAMP '2024-01-01'
AND event_time < TIMESTAMP '2024-02-01';**
Icebergでは、こうした条件から内部的に必要なパーティションを判断できるため、利用者は物理的な配置を強く意識せずに済みます。
進化可能性
Hiveでは、スキーマ変更やパーティション変更に制約があり、場合によってはテーブル全体の書き直しが必要でした。
Icebergでは、列の追加・削除・名前変更や、パーティション定義の変更を安全に扱えるように設計されています。
たとえば、最初は日単位でパーティションしていたテーブルを、後から月単位のパーティション設計に変えたい場合でも、既存データをすべて書き直す前提ではなく、メタデータ管理によって段階的に扱いやすくします。
スケーラビリティ
Icebergは、Netflixのようなペタバイト規模のデータでも利用できるように設計されています。
大規模なデータレイクでは、ファイル数が数十万、数百万になることもあります。その状態で毎回ストレージ上のディレクトリを走査していると、クエリを実行する前の準備だけで大きな負荷になります。
Icebergは、ファイル一覧や統計情報をメタデータとして管理することで、データ量やファイル数が増えても、テーブルとして扱いやすい状態を維持することを目指しています。
■ Apache Icebergの基本的な考え方
Icebergは、データレイクハウスのテーブルを定義するためのメタデータ仕様です。
単にデータファイルを保存するだけではなく、次のような情報をメタデータとして管理します。
- どのファイルが現在のテーブルに含まれるのか
- テーブルのスキーマはどうなっているのか
- パーティションはどのように定義されているのか
- ソート情報はどうなっているのか
- 過去のテーブル状態はどう変化してきたのか
Icebergは、Apache SparkやApache Flinkなどの計算エンジンと組み合わせて使えるように設計されています。また、既存のストレージやデータ処理ツールのエコシステムに自然に組み込めることも重視されています。
最終的な狙いは、ユーザーがIcebergという内部フォーマットを強く意識せず、さまざまなツールから単に「テーブル」を操作している感覚でデータレイクを扱えるようにすることです。
■ Apache Icebergのアーキテクチャ
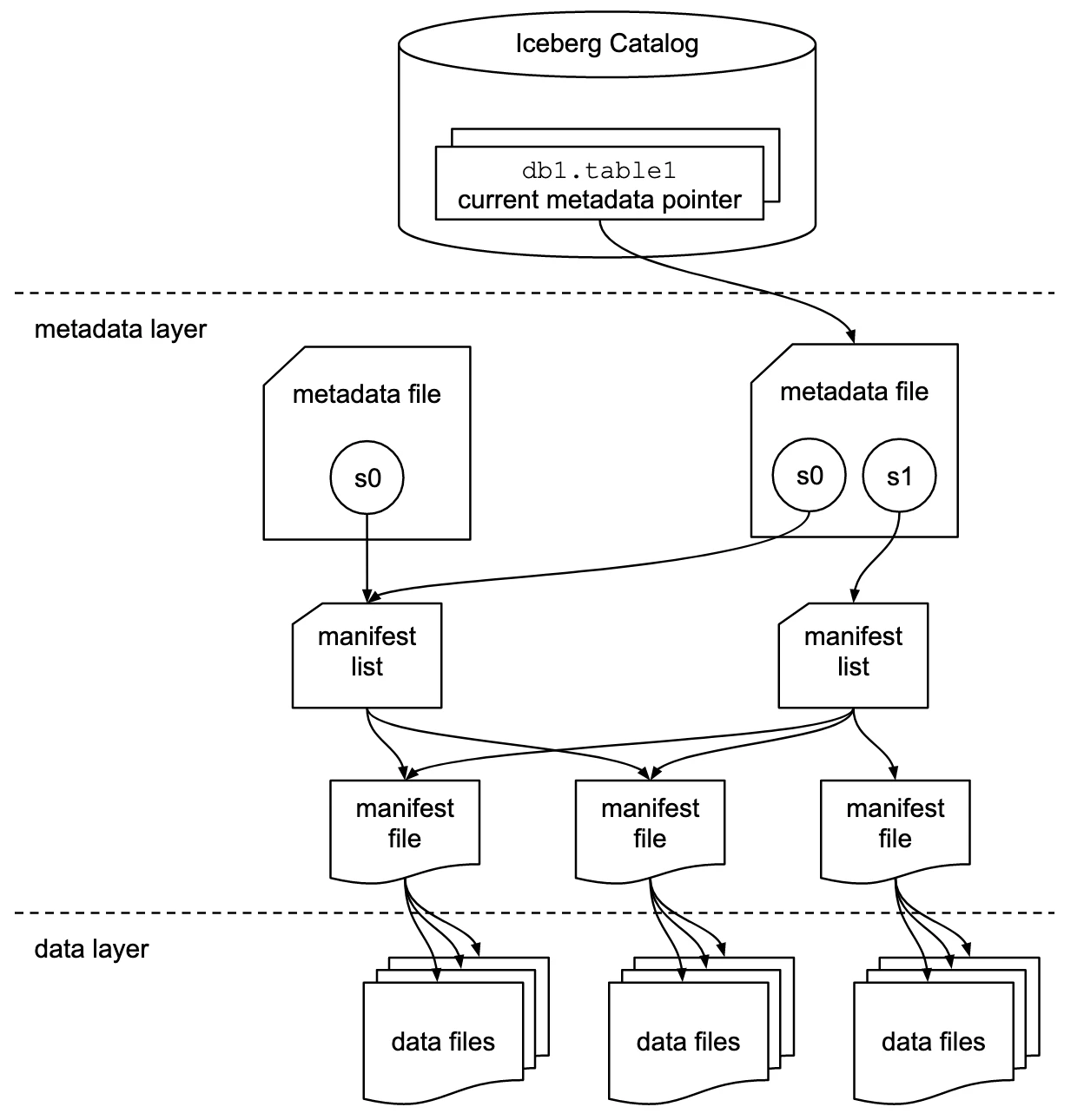
Icebergは、メタデータのツリー構造を使ってテーブルを管理します。
従来のようにディレクトリをたどってデータファイルを探すのではなく、メタデータを参照することで、どのデータファイルを読み込めばよいかを効率的に判断します。
このメタデータツリーは、主に次の4つのコンポーネントで構成されます。
マニフェストファイル
マニフェストファイルは、データファイルのリストを持つファイルです。
各データファイルのパスや、そのファイルに関する主要なメタデータを保持します。これにより、クエリエンジンはすべてのファイルを直接確認しなくても、必要なファイルを絞り込めるようになります。
マニフェストリスト
マニフェストリストは、ある時点のテーブル状態、つまり単一のスナップショットを、マニフェストファイルの一覧として定義するファイルです。
また、各マニフェストに関する統計情報も持っているため、クエリ実行計画をより効率的に作成できます。
メタデータファイル
メタデータファイルは、テーブル全体の構造を定義するファイルです。
ここには、スキーマ、パーティション定義、スナップショットの一覧などが含まれます。Icebergテーブルの状態を理解するうえで中心となるファイルです。
カタログ
カタログは、テーブルの場所を追跡する仕組みです。
Hiveメタストアに似ていますが、役割は少し異なります。Hiveでは主に「テーブル名 → ディレクトリ」の対応を管理しますが、Icebergのカタログは 「テーブル名 → 最新のメタデータファイルの場所」 を管理します。
これにより、クエリエンジンは最新のメタデータファイルを起点として、現在のテーブル状態を正確に把握できます。
■ Apache Icebergの主な機能
Icebergのアーキテクチャは、Hiveの課題を解決するだけでなく、データレイクハウスに必要なさまざまな機能を提供します。
ACIDトランザクション
Icebergは、楽観的同時実行制御を使ってACIDトランザクションを実現します。
楽観的同時実行制御とは、基本的にはトランザクション同士が競合しないと考え、必要な場合にだけ競合をチェックする方式です。これにより、ロックを最小限に抑えながら、複数のリーダーやライターが同時に動く環境でも一貫性を保てます。
Icebergでは、トランザクションは成功してコミットされるか、失敗するかのどちらかです。中途半端な状態はありません。
また、同時実行の保証はカタログが担います。カタログが最新のメタデータファイルを管理することで、競合する更新によるデータ損失を防ぎ、アトミックなトランザクションを可能にします。
パーティション進化
従来のデータレイクでは、パーティション設計を変更するには、テーブル全体を書き直す必要があることが大きな問題でした。
Icebergでは、パーティション定義がメタデータとして管理されているため、テーブル全体のデータを書き直さずにパーティショニングを変更できます。
たとえば、以前は月単位でパーティショニングしていたテーブルを、ある時点から日単位のパーティショニングに変更できます。この場合、過去のデータは月単位のパーティションとして残り、新しいデータは日単位のパーティションとして書き込まれます。
読み取り時には、エンジンがそれぞれのデータに適用されるパーティション定義を理解したうえで、適切な実行計画を作成します。
隠しパーティション
Icebergでは、ユーザーが物理的なパーティション列を意識せずに、自然なクエリを書けるようにする隠しパーティションの仕組みがあります。
従来のHiveでは、たとえば実際のパーティションが event_year、event_month、event_day のような列で作られている場合、ユーザーが event_timestamp だけで絞り込むと、パーティションが効かずフルスキャンになることがありました。
Icebergでは、パーティションを「列」と「変換式」の組み合わせで管理します。変換式には、year、month、day、hour、bucket、truncate などを使えます。
そのため、ユーザーは元のタイムスタンプ列に対して自然にフィルターを書くだけで、Iceberg側が対応するパーティションを利用できます。余計なパーティション列を意識する必要がなくなります。
行レベルのテーブル操作
Icebergは、行レベルの更新や削除にも対応できます。
行レベルの変更を扱う方式には、主に次の2つがあります。
コピーオンライト
コピーオンライトでは、あるデータファイル内の行が変更されると、そのファイル全体を新しいファイルとして書き直します。
たとえ1行だけの更新であっても、対象ファイル全体が書き直されます。読み取り時はシンプルですが、更新が多い場合は書き込みコストが大きくなります。
マージオンリード
マージオンリードでは、変更された行の情報を別ファイルとして書き込み、読み取り時に元データと変更情報を組み合わせます。
これにより、更新や削除が多いワークロードでは、書き込みを軽くできます。一方で、読み取り時にマージ処理が必要になります。
Icebergでは、ワークロードの性質に応じて、これらの方式を使い分けられる柔軟性があります。
タイムトラベル
Icebergは、不変のスナップショットを保持します。
そのため、過去のある時点のテーブル状態に対してクエリを実行できます。これがタイムトラベルです。
タイムトラベルを使うと、四半期末時点のレポートを再現したり、ある時点の機械学習モデルの入力や出力を確認したりできます。過去状態を保存するために、別の場所へデータをコピーしておく必要がありません。
バージョンのロールバック
Icebergでは、過去のスナップショットを参照するだけでなく、テーブルの現在状態を過去のスナップショットへ戻すこともできます。
これにより、誤ってデータを更新・削除してしまった場合でも、過去の正常な状態にロールバックできます。
スキーマ進化
データの利用が進むにつれて、テーブルのスキーマは変化します。
Icebergは、次のようなスキーマ変更に対応できます。
- 列の追加
- 列の削除
- 列名の変更
- 列のデータ型の変更
たとえば、int 型では扱いきれないほど値が大きくなった場合に、列の型を long に変更できます。
Icebergは、このような変更を安全に行えるように設計されています。
まとめ
Apache Icebergは、Hiveテーブルフォーマットに不足していた機能を補うために作られた、データレイクハウス向けのテーブルフォーマットです。
Icebergの中心的な特徴は、テーブルをディレクトリ構造ではなく、複数階層のメタデータツリーによって管理する点です。
この仕組みによって、Icebergは次のような機能を実現します。
- ACIDトランザクション
- 複数ライター環境での安全な更新
- パーティション進化
- 隠しパーティション
- 行レベルの更新・削除
- タイムトラベル
- バージョンのロールバック
- スキーマ進化
- 大規模データでの効率的なクエリ計画
Apache Icebergプロジェクトは、これらの機能を特定のエンジンだけに閉じたものではなく、さまざまなデータ処理ツールが利用できるオープンなテーブルフォーマットの仕様とライブラリとして提供しています。
つまりIcebergは、データレイク上のファイル群を、データウェアハウスのテーブルのように安全で柔軟に扱うための基盤です。