
■ はじめに
業務で資料を探すとき、「ファイル名は分からないけれど、見た目や内容はなんとなく覚えている」 という場面はよくあります。
特に、ファイル名や保存場所が曖昧なまま、「あのページにあった図」や「見覚えのある画面」 を手がかりに探したいケースは多いのではないでしょうか。
そこで今回は、資料をページ単位で画像化し、Cohere Embed 4 によるベクトル検索で探せるアプリ、名付けて「資料見つかるくん」 を OCI 上に構築します。
PDF や PowerPoint、Wordなどの文書を取り込み、テキストだけでなくページの見た目そのものも含めて検索できるのが大きな特徴です。
本記事では、OCI の Resource Manager(Terraform)を使ってGUI操作でこの環境をデプロイし、実際に文書を取り込んで検索できるようになるまでを手順付きで紹介します。すぐに作成できるので、ぜひご自身のOCI環境で試してみてください!
この記事で分かること
- AI資料検索アプリ「資料見つかるくん」の特徴、テキストベースのRAGとの違い
- OCI 上での構築手順(Resource Managerを使ってGUIだけで!)
- 文書登録・ベクトル化・検索の基本的な使い方、チューニングポイント
目次
■「資料見つかるくん」の注目ポイント!

① テキストだけでなく、図や写真を検索対象にできる
一般的なテキストベースのRAGは、文書から抽出したテキストをチャンク化して検索します。一方、このアプリは文書のページ全体を1枚ごとに画像化してベクトル化するため、図・レイアウト・画面キャプチャを含むページ全体を検索対象にできます。
② Cohere Embed 4による画像のベクトル検索でOCRやテキスト抽出に依存しない
テキストベースのRAGでは、元文書から文字をうまく抽出できることが前提になります。ただし、Excel や PowerPoint はレイアウトが複雑で、各ファイルのレイアウトに合わせてテキストを抽出するなど前処理が重くなりやすいのが課題です。このアプリは、元のファイルのままファイルをアップロードするだけで、各文書をページ単位で画像化し、Cohere Embed 4 でベクトル化するため、文字抽出に頼らず検索できます。
③ 画像からの検索にも対応
テキストだけでなく、画像を入力として類似ページを検索できます。たとえば、エラー画面のスクリーンショットから関連する手順書を探す、製品の写真から対応するマニュアルや説明資料を探す、見覚えのある図や構成図の画像から元の提案書や設計資料を探すといった使い方ができます。
④ OCI上で完結、Terraformで短時間にGUIだけで構築できる
Compute、ADB、Object Storage を中心に、OCI の標準的なサービスで完結できる構成です。検索用のベクトルデータを ADB に格納し、ファイルやページ画像は Object Storage に保存するシンプルな構成で、またこれらはResource Manager(Terraform)を利用して簡単にデプロイできます。
補足
- このアプリは、回答を生成するのではなく、必要な資料そのものを探し出すことに主眼を置いています。一般的なテキストベースのRAGは、検索結果をもとに LLM が回答を返す構成が中心ですが、このアプリでは回答生成は行わず関連する資料やページを見つけることに特化しています。
■ アーキテクチャ
OCI上に構築するアーキテクチャは次のとおりです。
OCI大阪リージョンのVCN内に、ComputeとADBを配置します。Generative AI(LLM)は大阪リージョンもしくはより最新バージョンが利用可能なシカゴリージョンを利用します。
- 管理コンソールで文書管理と設定を行い、Dify からはチャット形式で検索を実行します。
- ファイル本体とページ画像は Object Storage、ベクトルは ADB に保存する構成です。
■ インフラアーキテクチャ(OCI)

■ アプリアーキテクチャ
主に文書管理を行う管理コンソールと、検索アプリの2画面を利用します。
検索は、Dify のチャットボット画面、または必要に応じて管理コンソールから実行できます。
◆ 管理コンソール
- フロントエンド:Vite + Vanilla JavaScript(ES Modules)+ Tailwind CSS + Font Awesome
- バックエンド:Python + FastAPI + Uvicorn
◆ 検索
-
Dify
管理コンソールのみでも実行可能です。チャットUIからの検索を行いたい場合に、Difyを有効にしてデプロイします。
■ 事前準備
デプロイを開始する前に、VCN、顧客管理キー、APIキーを作成しておきます。
① VCNの作成
必要に応じて、ComputeとADBを作成するVCN(仮想ネットワーク)を作成しておきます。
手順はこちらのチュートリアル(OCIチュートリアル:クラウドに仮想ネットワーク(VCN)を作る)を参考にしてください。
今回は上述のアーキテクチャのとおり、ComputeとADBを同一のPublic Subnetに作成していきます。
(今回はResource ManagerでTerraformスクリプトを用いて構築をしていきますが、手順の途中で設定を変更することでADBをPrivate Subnetに作成することもできます。)
■ VCN構成例
-
VCN:
10.0.0.0/16 -
Subnet
- Public Subnet:
10.0.0.0/24
- Public Subnet:
-
Gateway
- Internet Gateway
-
Root table
- RT-Public-Subnet:宛先-
0.0.0.0/0、ターゲット-インターネット・ゲートウェイ
- RT-Public-Subnet:宛先-
-
Security List
-
アクセス元IP- TCP 80: HTTP -
アクセス元IP- TCP 22: SSH -
Compute Public IP- TCP 80: HTTP ※このルールはリソース作成後に追加します。
-
② 顧客秘密キーの作成
手順はこちら(資料見つかるくん旧バージョンの作成手順)の「顧客秘密キーの作成」を参照してください。
③ APIキーの作成
手順はこちらの「APIキーの発行」をご覧ください。
■ 構築手順
アプリの構築作業は、おおよそ10分程度で完了できます。
(別途、リソースのデプロイに 5〜10分程度 かかります。)
では、さっそくやってみましょう!
Step 1. リソースマネージャーにてデプロイ
1-1 こちらのリンクを開きます。
こちらは、@engchina さんの大きな協力で作成しています!この場を借りて感謝申し上げます。
1-2 READMEの中にある「Deploy to Oracle Cloud」をクリックします。

構築するOCIテナントにログインします。
1-3 Resource Managerの「スタックの作成」画面が開きます。

1-4 「スタック情報」設定項目を入力していきます。
- 「Oracle使用条件を確認した上でこれに同意します。」にチェックを入れます。
- 名前:デプロイを行うスタックの名前です。(デフォルトの値のままでOK。)
- 説明:任意の値(デフォルトの値でOK)

- コンパートメント:任意(スタックを作成するコンパートメントを選択します。)
入力出来たら「Next」をクリックします。

1-5 「変数の構成」設定項目を入力していきます。
- Create in Compartment:ADBなどのリソースを作成するコンパートメントを指定
- Availability domain:任意の値
-
Database name:DB名を入力(デフォルトは
AIDOCDB) -
Database display name:コンソール上の表示名を入力(オプション)(指定しない場合は、Database nameと同一になります。ここでは、
ADB-Document-Search) -
Database password:DBのAdminユーザーのパスワードを入力(デフォルトは
Orcl#1Orcl#)

-
Choose license:ADBについて、ライセンス持込
BRING_YOUR_OWN_LISENCEかライセンス込みLICENCE_INCLUDEDのいずれかを選択 -
Compute instance name:任意の値(デフォルトは
AIDOC_INSTANCE) - Operating System Image:変更しない
-
Compute Instance Shape:
VM.Standard.E5/E4のいずれかを選択 - VCN:事前準備で作成したVCNを選択
-
ADB Subnet Type:
PUBLIC/PRIVATEのいずれかを選択(ここではPUBLIC) - Subnet:ComputeとADBを作成するパブリックサブネットを選択
※ ADBをPrivate Subnetに作成する場合:
ADB Subnet Type でPRIVATEを選択後、Private Subnet for ADBにADBを作成するサブネット、次のSubnet欄でComputeを作成するサブネットを選択してください。

- Add SSH keys:ComputeにアクセスするためのSSH鍵(.pub)をアップロードまたは貼り付け
-
OCI Object Storage Bucket Name:検索するドキュメントや画像を保存するバケット名(デフォルトは
semantic-doc-search) -
Show AI Assistant/Show Search Tab:基本的には ✓ を入れておく(一部機能を実装しない設定が可能です。以下の操作手順で説明します。)
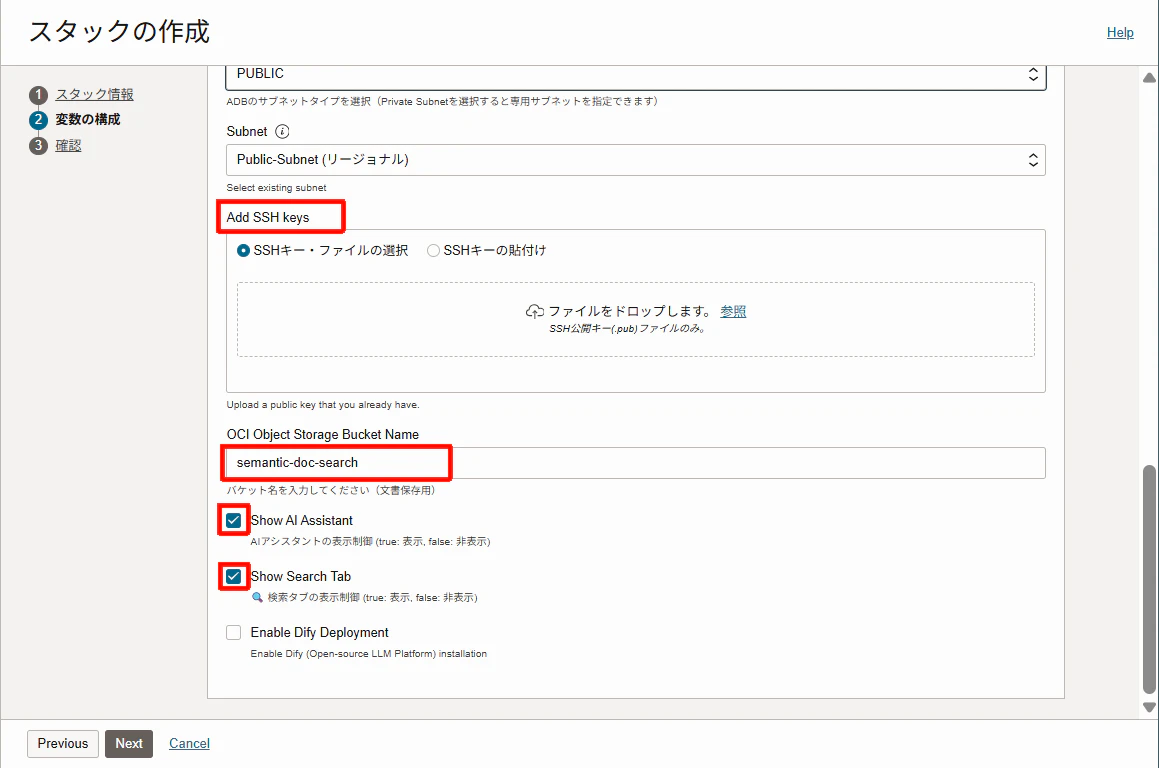
* Enable Dify Deploymentについて
#アーキテクチャに記載のとおり、検索機能は、Difyをデプロイしなくても、管理コンソールのみでも利用可能です。Difyを構築しない場合は、ここのチェックを外してください。
構築する場合は、以下の設定を行います。
- Enable Dify Deployment:✓
-
Dify Configuration
-
External API Keys:Dify内でAPIアクセス時の認証キーとして使用します(デフォルトは
secretですが、セキュリティ向上のため任意の値を指定してください。) -
Dify Branch/Tag:構築するDifyバージョンを指定(デフォルトは
1.12.1。必要に応じて最新バージョンに置き換えてください。) - OCI Access Key:顧客管理キーのAccess Key(事前準備で取得した値を入力)
- OCI Secret Key:顧客管理キーのSecret Key(事前準備で取得した値を入力)
-
External API Keys:Dify内でAPIアクセス時の認証キーとして使用します(デフォルトは
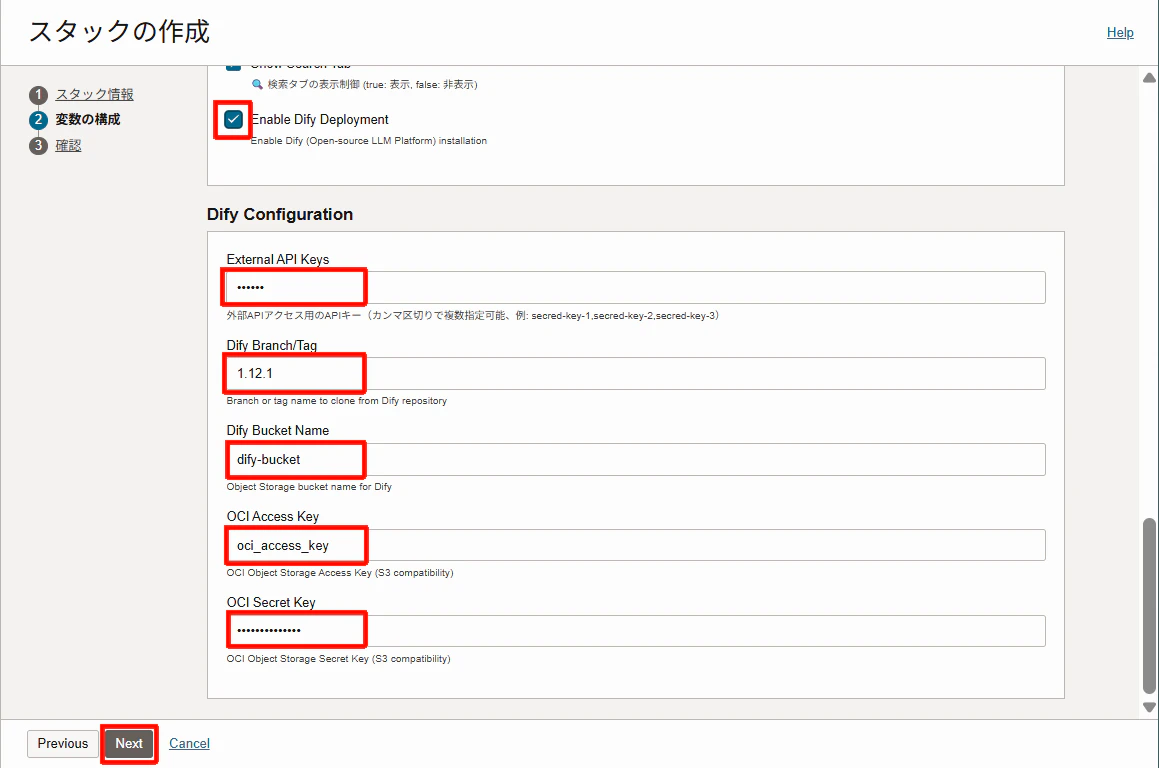
1-6 入力が完了したら、設定を確認後、「作成」をクリック

作成したスタックでジョブが開始して、リソースのデプロイが開始します。
デプロイに数分かかるので、数分待ちます。

ジョブが成功しました!
ADBやComputeなどのリソースの作成が無事完了しました。
【注意】
この後、Compute内でアプリケーションのデプロイが内部的に実行されます。ジョブが成功になったことを確認したうえで、少なくとも5分(余裕をもって10分程度)待ってから次の手順に進んでください。

Step 2. 初期設定
では、ComputeやADBが立ち上がったら最初に必要な設定・接続確認を行っていきます。
2-1 Security List設定
ジョブの詳細画面>左端 Resourcesから出力を確認します。
application_urlから作成されたComputeのパブリックIPを確認できます。
この IP アドレスについて、Security List で TCP/80 ポートへのアクセスを許可しておきます。

ではここで、作成された管理コンソールにアクセスしていきます!
出力から「application_url」を確認します。
このURLへブラウザからアクセスします。

「資料見つかるくん」管理コンソールへアクセスできました!
データーベース・ユーザーに基づいてログインしますので、ユーザー名 admin、パスワードはADB構築時に指定したものを入力してください。

2-2 OCI設定
ログインできたら、「設定」をクリックします。

「⚙設定」>「OCI設定」をクリックします。
「OCI APIキー設定」にて、事前に取得したAPIキーの情報を入力、鍵をアップロードします。入力後、「APIキーを保存」をクリックします。
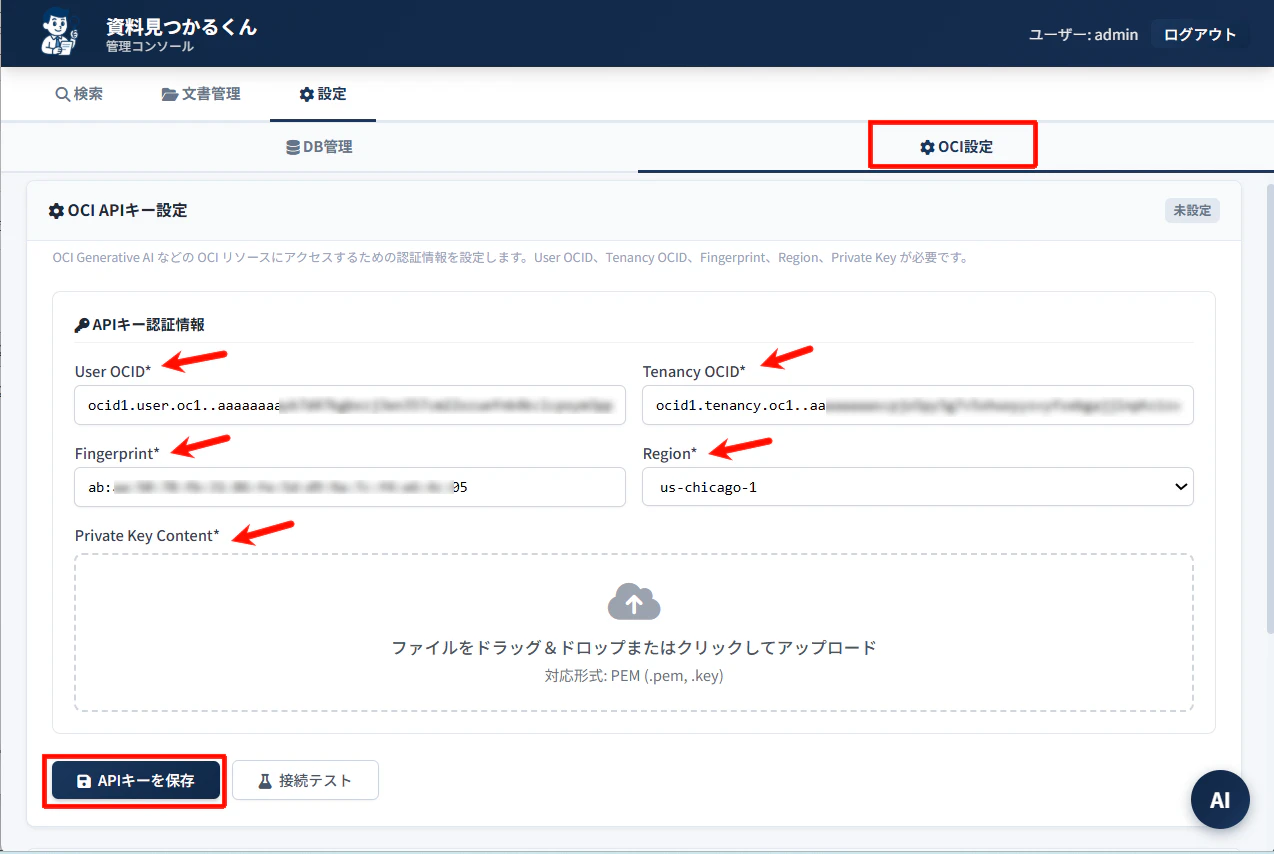
「APIキーを保存」した後、「接続テスト」をクリックします。
接続に成功したことを確認します。

続いて、画面下にスクロールして、「Object Storage設定」にて、「再取得」をクリックします。
ここでも「接続テスト」を行い、正常に接続できることを確認します。

2-3 DB設定
次はDBの設定です。
「DB設定」にて、「Autonomous AI Database 起動/停止」から「再取得」をクリックします。
ADBが起動している(AVAILABLEとなっている)ことを確認します。

なお、今後ADBの起動・停止はこちらから操作できます。アプリケーションの未使用時は起動・停止を切り替えることで、コストが抑えられます。
データベース接続設定でも「接続テスト」を行います。
正常に接続できることを確認します。

2-4 Dify設定
※構築時にDifyのデプロイを無効にした場合は、この手順はスキップします。
続いて、検索アプリのDify側の初期設定を行います。
ジョブの詳細画面>「出力」から、dify_urlを確認してブラウザでアクセスします。
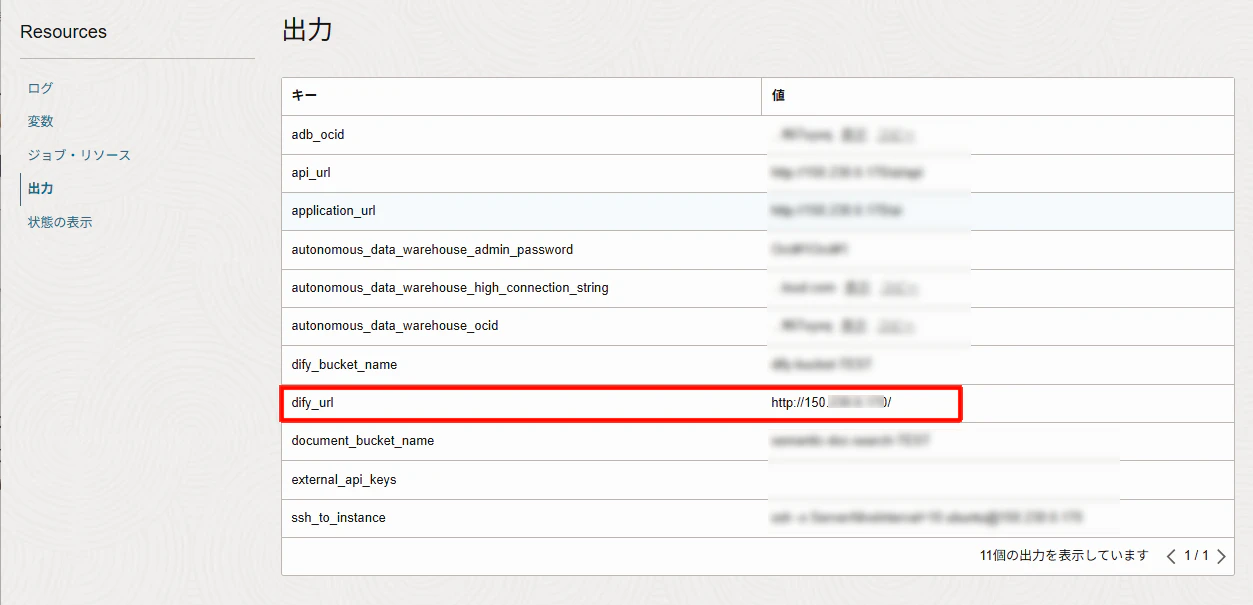
アクセスすると、「管理者アカウントの設定」画面になりますので、管理者アカウントのセットアップを行います。

※任意の値で設定してください。メールサーバーを設定しない限り、メールアドレスを使ったパスワードリセット等は利用できないため、実在するメールアドレスでなくても問題ありません。
管理者アカウントのセットアップができると、Difyのスタジオの画面が開きます。

検索アプリをインポートするため、「アプリを作成する」から「DSLファイルインポート」をクリックします。

「URLから」を選択し、以下のURLを入力します。
https://raw.githubusercontent.com/engchina/no.1-semantic-doc-search/refs/heads/main/dify/%E8%B3%87%E6%96%99%E8%A6%8B%E3%81%A4%E3%81%8B%E3%82%8B%E3%81%8F%E3%82%93_%E6%A4%9C%E7%B4%A2%E3%82%A2%E3%83%97%E3%83%AA.yml
検索アプリがインポートできました。
Difyのワークフロー編集画面が開きます。
「Search Images」というブロックを開きます。
「ヘッダー」>「Authorization」の値を、ApiKey 以降の値を、デプロイ時「External API Keys」として設定した値(デフォルトsecret)で置き換えます。

(任意)
「開始」ノード>「入力フィールド」の編集ボタンをクリックし、「デフォルト値」にhttp://<ComputeのPublic IP>/を入力します。あらかじめ設定しておくことで、チャット実行時に毎回入力する必要がなくなります。
これで設定は完了です!
Step 3. 使ってみる
準備が出来たので、早速ファイルをアップロードして検索を試してみましょう!
3-1 文書アップロード
「管理コンソール」(http://<ComputeのPublic IP>/ai/)にアクセスし、「文書管理」をクリックします。
「文書アップロード」から検索するファイルをアップロードします。
- 対応しているファイル形式は、
PDF,XLSX,XLS,DOCX,DOC,PPT,PPTX,PNG,JPG,JPEG,TXT,MDです。 - 10ファイルまで同時にアップロード可能です。(複数選択した上でドラッグアンドドロップ、もしくはクリックしてエクスプローラー上で複数選択してアップロードしてください。)
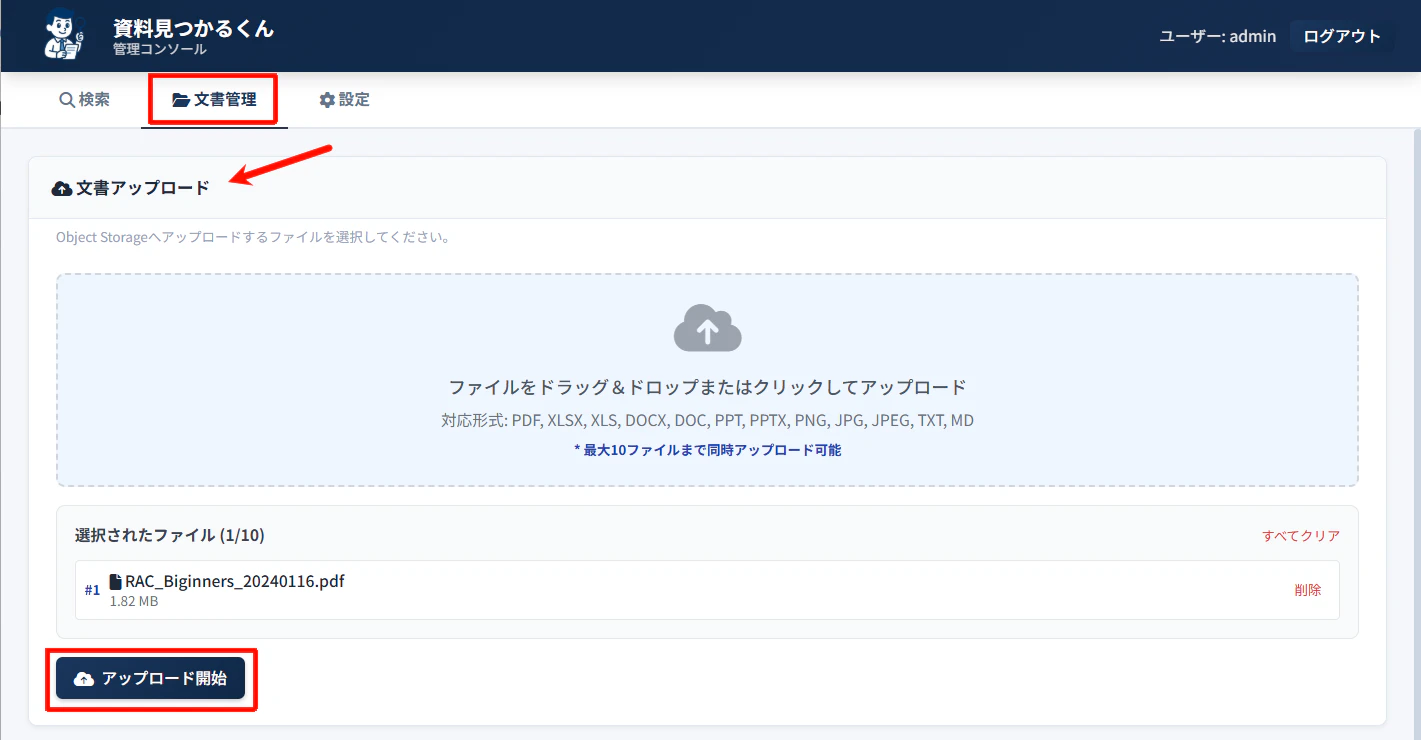
正常にアップロードできたことを確認します。
ファイルがObject Storageに格納されました。

続いて、「登録済み文書」にて「再取得」をクリックして、一覧を再読み込みします。
先程アップロードしたPDFファイルが表示されました。

アップロードしたファイルを検索できるようにベクトル化の処理を行います。
対象ファイルをクリックして「ベクトル化」をクリックします。
- 最大20ファイルまで同時にベクトル化処理を実行できます。
(ファイルの内容やサイズ、同時実行数によっては一部の処理が失敗する場合があるため、必要に応じて分割して実行してください。) - 処理が開始すると、内部的に以下のように動作します。
「ベクトル化」をクリック
→ PDF / PPTX などの複数ページファイルは、1ページごとに1枚の画像へ変換(Excel ファイルは一定の単位で分割され同様に画像化)
→ 生成した画像を Object Storage に保存(Object Storage 内では、ファイル名ごとにフォルダを作成し、その配下に画像を格納)
→ 各画像(1ページ)を1件のレコードとして Cohere Embed 4 でベクトル化
→ 生成されたベクトルをデータベースに格納

処理が進んでいく様子がプログレスバーと右上のポップアップ表示で確認できます。

ベクトル化が正常に完了しました。

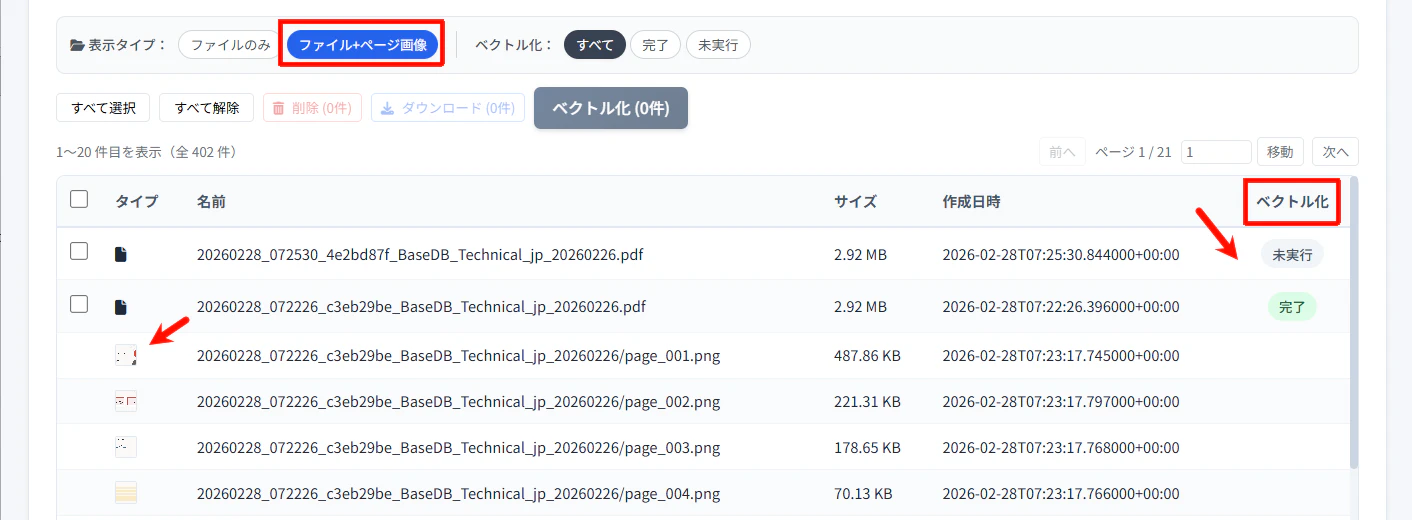
- 一覧の「ベクトル化」列を確認すると、ベクトル化が実行されているか未実行であるかステータスが確認できます。
- 表示タイプを「ファイルのみ」から「ファイル+ページ画像」に切り替えると、画像化した各ページが表示されます。「タイプ」列のサムネイルをクリックすると、画像を確認できます。
これでファイル登録作業は以上です!
* テーブルの確認
念のため、データベースの中身を確認してみましょう。
「設定」>「DB管理」の一番下に、「テーブル一覧」があるので「再取得」をクリックし、表示を再読み込みします。
- 2つのテーブルが作成されています。
-
FILE_INFO表:アップロードしたファイル情報が格納されています。 -
IMG_EMBEDDINGS表:ファイルのページごとに埋め込み(Embedding)が格納されています。(ベクトルストア)- EMBEDDING列に格納されているベクトル(数字の配列)は先頭一部が表示されています。
-

3-2 検索
では先程アップロードしたファイルを検索してみましょう。
検索は、① Dify の検索アプリ、または② 管理コンソールの検索機能のどちらからでも利用できます。
① Dify の検索アプリ:チャットボット形式で質問して、手軽に資料を確認できます。
② 管理コンソールの検索機能:検索結果を一覧表示し、類似度の確認や条件調整が可能です。また画像からの検索にも対応しています。
① Dify の検索アプリ
ブラウザからDifyにアクセスします。
http://<ComputeのPublic IP>/
アプリを開きます。

ワークフローの編集画面が開きます。「公開する」から、修正がある場合は「更新を公開」を押して編集を保存してから、「アプリを実行」をクリックします。

チャット画面が開きます。
チャット設定に、http://<ComputeのPublic IP>/を入力します。(Dify設定でデフォルト値に設定してある場合は、その値が自動的に入力されます。)
チャットボットに探している資料の特徴を入力すると資料が検索できます。

検索されたワードと意味合いの近い画像(資料内のページ)が複数表示され、そのファイルダウンロードURLとページ番号が表示されます。

Dify 検索アプリでのパラメータ変更
ベクトル検索では、類似度のしきい値(threshold) や 取得件数(limit) を調整することで、検索結果の表示内容を制御します。
質問が送信されると、ワークフロー内の2番目のノード 「Search images」 から API サーバーへリクエストが送信されます。
このリクエストに含めるパラメーターを変えることで、検索結果の絞り込み具合や表示件数を調整できます。
使用するパラメーターは次の3つです。
-
query:入力された質問文(必須) -
threshold:類似度のしきい値(任意) -
limit:取得件数(任意)
なお、threshold と limit を指定しない場合は、あらかじめ設定されたデフォルト値が使用されます。
◆ threshold(類似度のしきい値)
検索結果として採用する候補の上限値を設定します。しきい値を高くすると、質問と回答の距離がより遠い結果も出力されるため、検索結果は幅広く表示されます。デフォルト値は0.7です。
◆ limit(取得件数)
類似度の高い順に上位何件までを表示するか上限値を設定します(Top-K)。デフォルト値は10です。
② 管理コンソールの検索機能
ブラウザから管理コンソールにアクセスします。
http://<ComputeのPublic IP>/ai/
「検索」タブ>「テキスト検索」の検索クエリ欄に、資料の特徴を入力した上で「検索実行」をクリックします。

検索結果が表示されます。
- 類似度の高い順にファイルやファイル内のページ(画像)が表示されます。
- 質問に対しての画像のマッチ度、その平均として資料全体のマッチ度が表示されます。マッチ度とは、
マッチ率(%)≒(1−距離) ×100で計算されています。 - 画像毎に表示されている「距離」とは、質問文と資料内の画像のベクトル距離を表示しています。
- 最小値:
0
⇒ 2 つのベクトルが同じ方向を向いている(完全に類似) - 最大値:
2
⇒ 2 つのベクトルが正反対の方向を向いている(完全に不類似)
- 最小値:

管理コンソールでは、画像を入力して資料を検索することもできます。
たとえば、エラー画面のスクリーンショットから関連する手順書を探したり、特定の商品の写真から対応するマニュアルを探したりする場合に活用できます。
「画像検索」をクリックします。
ファイルを選択/ドラッグアンドドロップ、もしくはクリップボードから貼り付けで、画像をアップロードします。

アップロード出来たら、「画像検索実行」をクリックします。

テキスト検索時と同様、検索結果が表示されます。

管理コンソールでのパラメータ変更
管理コンソールで検索機能を実行する際にも、Difyと同じようにパラメータを設定することで表示される検索範囲を調整できます。

- 件数:類似度の高い順に上位何件までを表示するか上限値を設定します。(「limit」に相当)
- 最少スコア:質問文と資料のベクトル距離に対する、しきい値の上限を指定します(「threshold」に相当)
- ファイル名(任意):該当した資料に対し、ファイル名でフィルターを掛けて結果を表示
■ 検索のポイント
検索結果が思ったように出ない場合は、次の点を見直すと改善しやすくなります。
1. 「質問文(query)」を整える
この検索は、質問文と画像のベクトルの近さをもとに結果を返します。
そのため、質問文をより具体的で検索意図に近い内容にすると、欲しい結果に近づきやすくなります。
- 丁寧語や前置きは省く
- 例:
〜について教えての資料を出してくださいなどは削除
- 例:
- 製品名、機能名、画面名などの固有名詞を入れる
2. 「しきい値(threshold)」を調整する
threshold は、どの程度関連性の高い結果を返すかを調整する値です。
- 関係ない資料が多い
→thresholdを下げる(厳しくする) - 欲しい資料が見つからない
→thresholdを上げる(広く拾う)
3. 「取得件数(limit)」を調整する
limit は、上位何件まで表示するかを決める値です。
- まずは
limitを増やす- 例:
10 → 20/30
- 例:
- 欲しい資料が何件目に出るかを確認する
- ノイズが多い場合は、
thresholdを調整したうえでlimitを絞る
4. ファイル名で絞り込む
※ この機能は管理コンソールでの検索のみ利用できます。
検索対象を、「ファイル名」欄に入力したキーワードを含むファイルだけに絞り込めます。
対象ファイルをある程度特定できている場合は、この絞り込みを使うことで、検索結果の確実性を高めやすくなります。
- 「ファイル名」欄に入力したキーワードを含むファイルだけに絞り込める
- 対象ファイルがある程度分かっている場合は、結果の確実性を高めやすい
■ おわりに
今回は、マルチモーダルベクトル検索で資料を探せるアプリ「資料見つかるくん」の構築手順と使い方を紹介しました。
このアプリは、文書をページ単位で画像化して検索することで、テキストだけでは見つけにくい資料も探しやすくなるのがポイントです。
一般的なテキスト検索のように文字列だけを見るのではなく、図・レイアウト・画面キャプチャを含むページ全体を検索対象にできること、またアップロードするだけで複雑な前処理を意識せず使えることも魅力です。
AI活用というと、LLMによる回答生成が注目されることも多いですが、業務の中にある「資料が見つからない」「欲しい情報にたどり着きにくい」といった資料検索も身近な困りごとを解決するAI活用ユースケースの一つになります。こうした身近な課題に対するアプローチは取り入れやすい活用の形ではないでしょうか。
ぜひ実際に触って試してみてください!
* 関連記事
本記事で紹介したアプリは、別記事で紹介した「資料見つかるくん」のアップデート版です。
以前のバージョンは Dify 上で完結する構成でしたが、今回のバージョンでは、チャットボット形式では扱いにくいファイル管理や設定を、別画面の管理コンソールとして分離し、より運用しやすい形にしています。
このアプリを作った背景や、どのような考えで改善してきたのかといった経緯は別記事で詳しく紹介しているので、ぜひあわせてご覧ください。