概要
Data + AI Summit 2025 にて Databricks における Apache Iceberg™ の完全サポートがアナウンスされました。
現在 Unity Catalog は Iceberg REST API をサポートしており、Managed Iceberg の書き込みがサポートされているようです。
本記事では、この機能を利用して Databricks の外部から、Iceberg テーブルの書き込みを試してみます。
環境
Databricks Free Edition の aws us-east-2 リージョンで試しています。
事前準備
これらの事前準備は既に設定済みのワークスペースでは不要な場合があります。
メタストアの外部データアクセスを有効にする
以下の手順に従って、メタストアの外部データアクセスを有効にします。
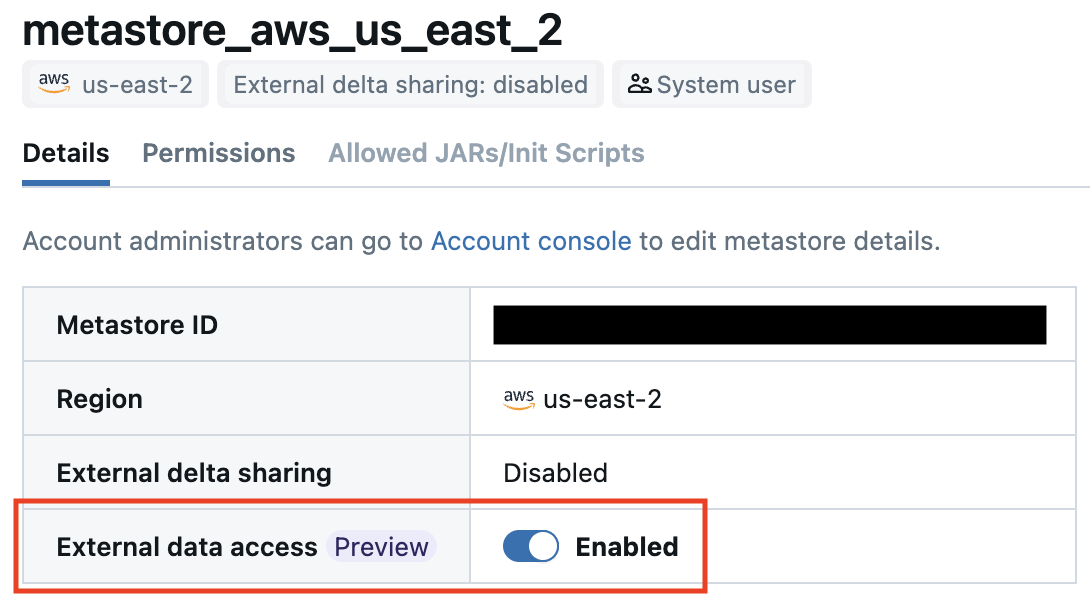
外部ロケーションを作成する
Free Edition などで使用されているデフォルトストレージでは、後述する EXTERNAL SCHEMA USE を設定することができないようです。
既にS3上に存在するカタログやスキーマが存在する場合はこの手順をスキップできます。
以下の手順に従って外部ロケーションを作成します。
外部ロケーションにカタログを作成し、スキーマを作成する
こちらも上記同様、既にS3上に存在するカタログやスキーマが存在する場合はこの手順をスキップできます。
スキーマのみがS3上にあれば良さそうですが、今回はカタログごと外部ロケーションで作成します。
UIからは以下のように作成できます。
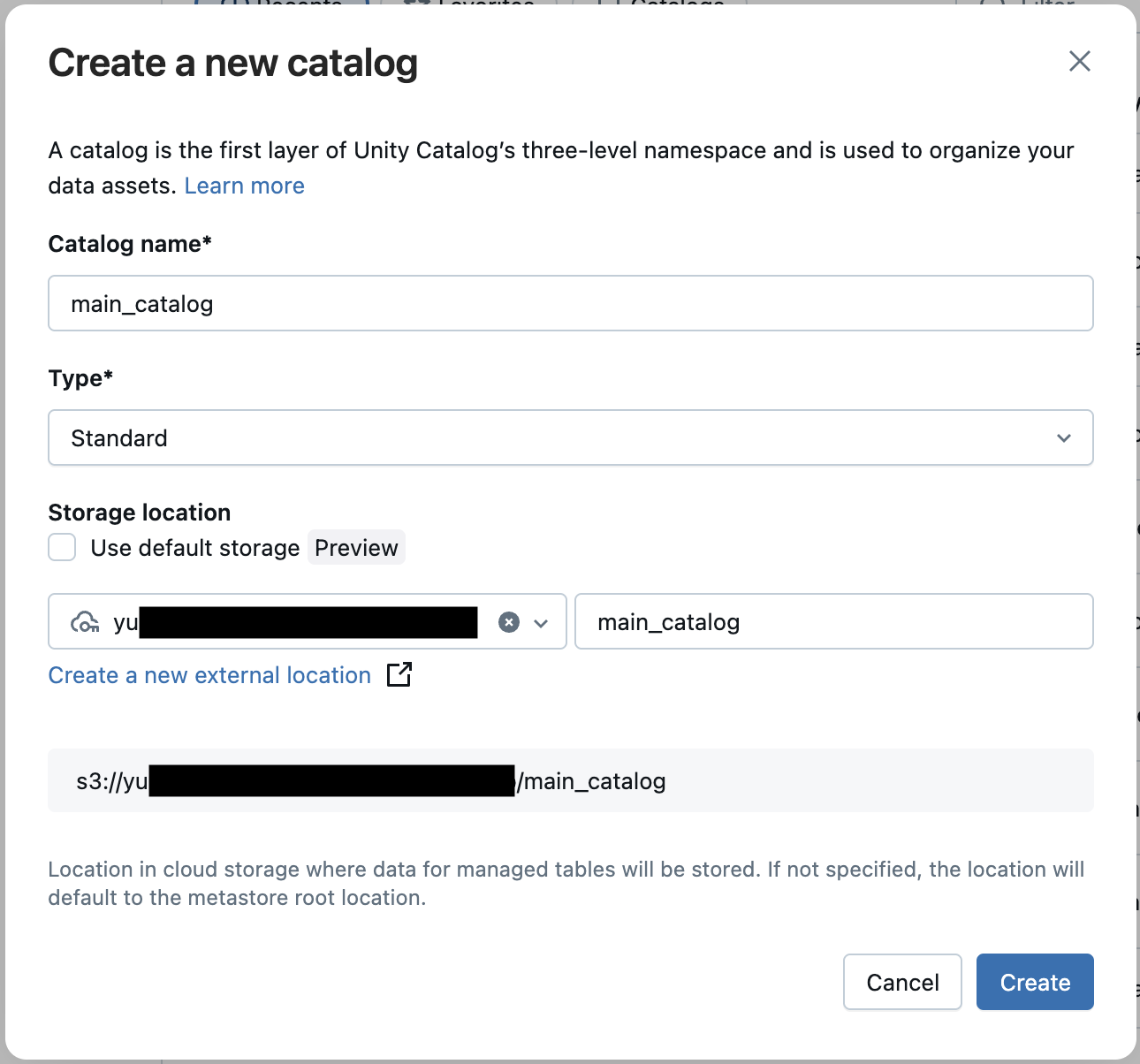
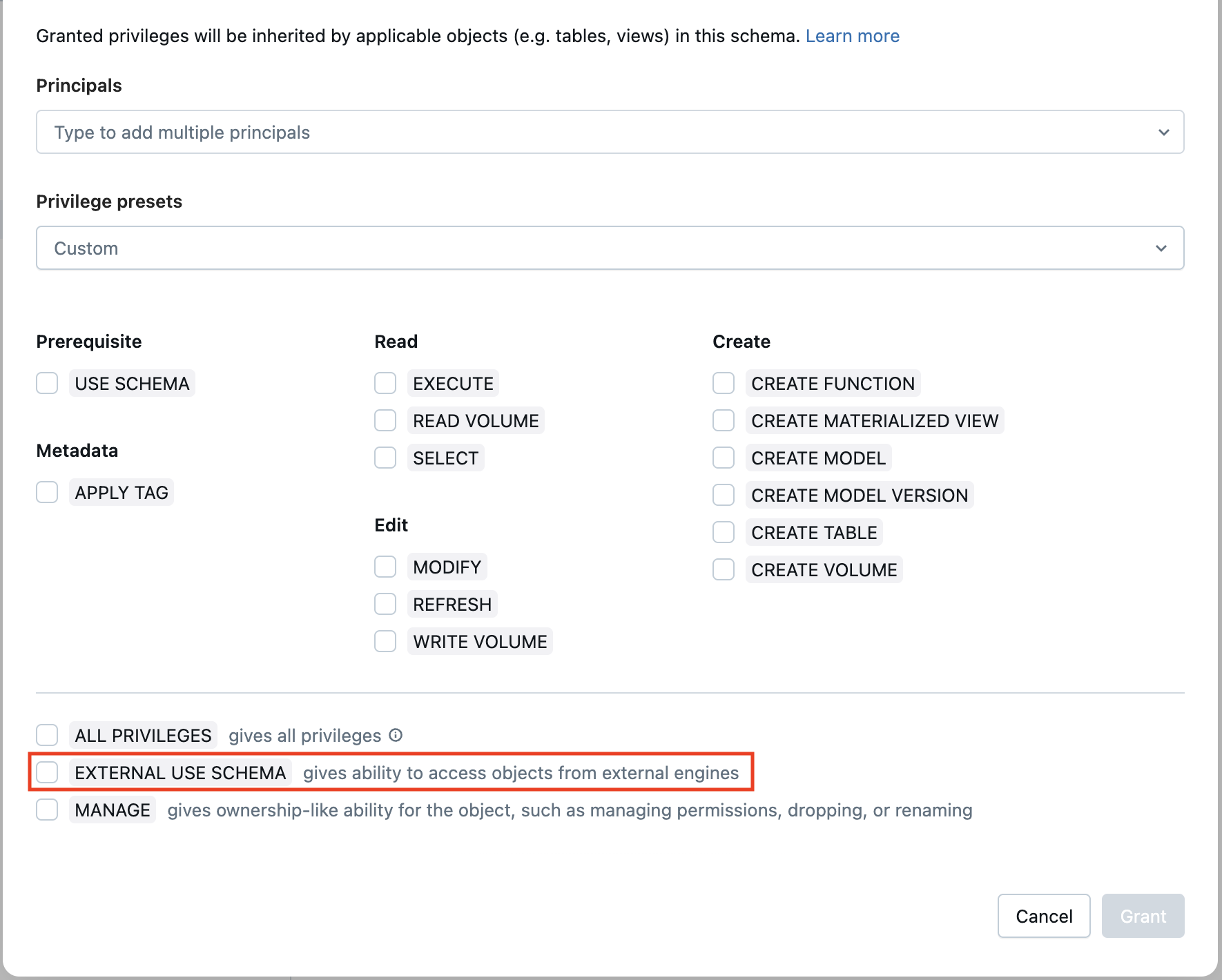
カタログを作ったらその配下にスキーマを作成します。
通常の権限に加え、EXTERNAL USE SCHEMA (= 外部からの利用) の権限を付与してください。
テーブルの作成
今回は PyIceberg を用いて、適当なサンプルデータを書き込みます。
以下の定数を設定し、コードをローカルの Python で実行します。
-
DATABRICKS_HOST:https://<your-workspace-url> -
DATABRICKS_TOKEN: 個人用アクセストークン -
UC_CATATLOG_NAME: 事前準備で作成したカタログ -
UC_SCHEMA_NAME: 事前準備で作成したスキーマ -
TABLE_NAME: 作成するテーブル名
import pyarrow as pa
from pyiceberg.catalog import load_catalog
# カタログの接続設定
catalog = load_catalog(
"rest",
uri=f"{DATABRICKS_HOST}/api/2.1/unity-catalog/iceberg-rest",
warehouse=UC_CATATLOG_NAME,
token=DATABRICKS_TOKEN,
)
# サンプルデータを作成
sample_data = pa.Table.from_arrays(
[
pa.array([1, 2]),
pa.array(["Alice", "Bob"]),
],
names=["id", "name"],
)
# テーブルの作成
try:
table = catalog.create_table(
f"{UC_SCHEMA_NAME}.{TABLE_NAME}", schema=sample_data.schema
)
except Exception as e:
print(f"Table creation failed: {e}")
# テーブルが既に存在する場合は取得
table = catalog.load_table(f"{UC_SCHEMA_NAME}.{TABLE_NAME}")
# 書き込み
table.append(sample_data)
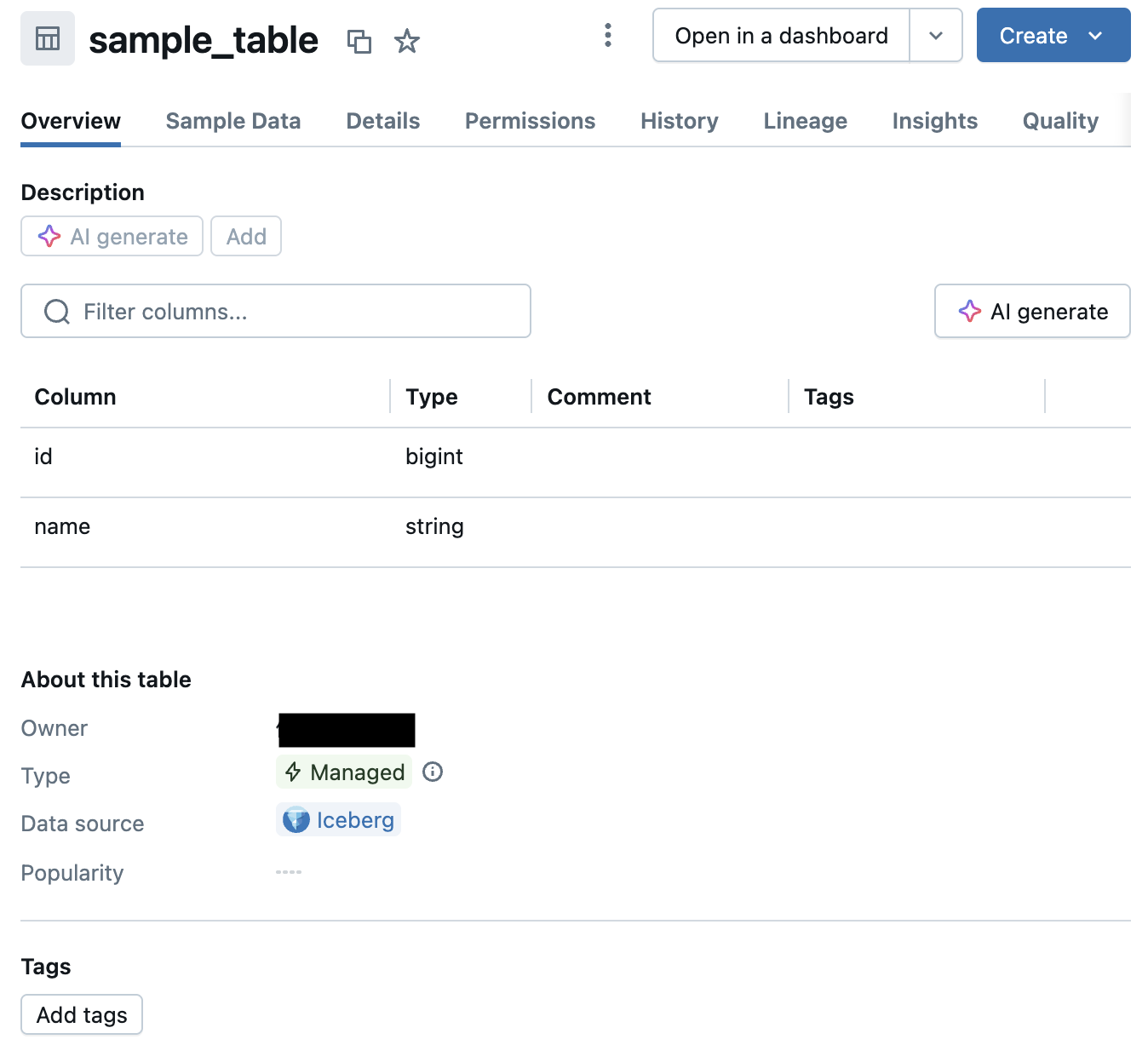
作成したテーブルの確認
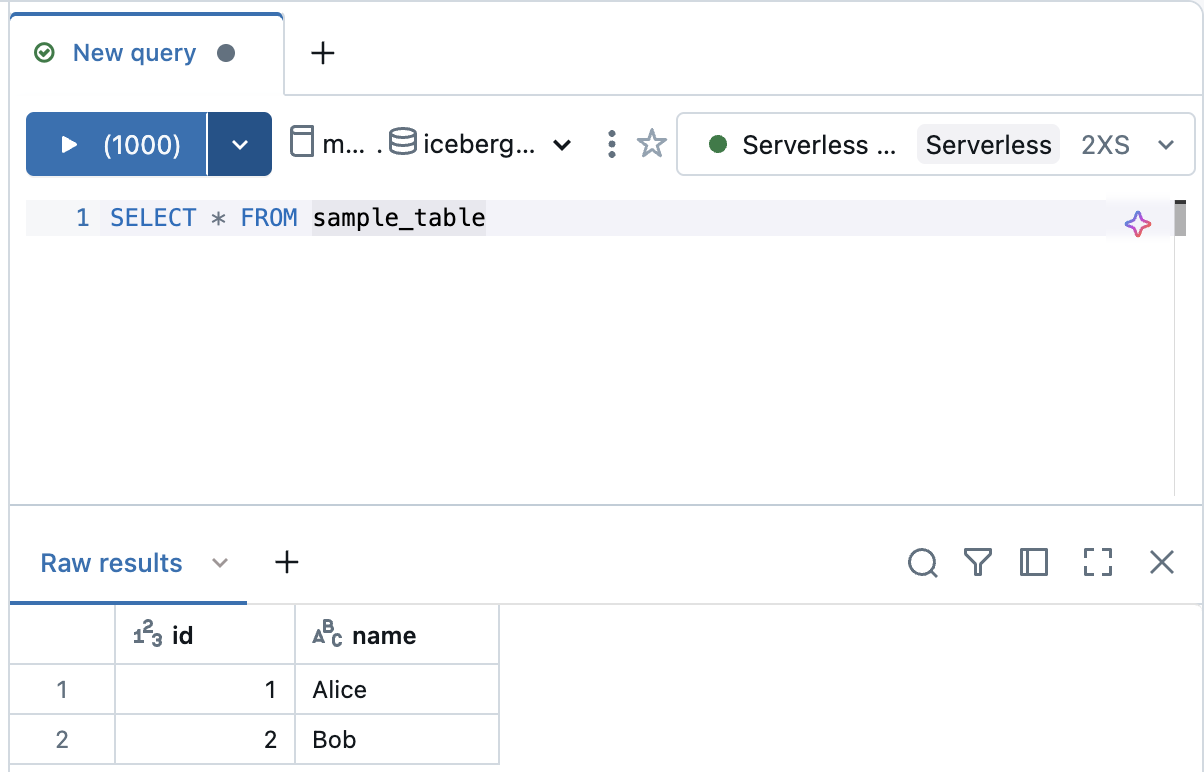
Unity Catalog 上で作成したテーブルを確認することができます。
Databricks 上からのクエリ
外部から作成した Managed Iceberg はもちろん Databricks 上からクエリすることもできます。